一種不同軌跡間相似度度量系統及其度量方法與流程
2023-09-15 13:28:10 2
本發明屬於數據挖掘技術領域,特別涉及一種不同軌跡間相似度度量系統及其度量方法。
背景技術:
數據挖掘(datamining)是一種從海量的歷史業務數據中,透過數理分析模式提取出蘊藏於其中的潛在信息的過程。時空軌跡數據挖掘則是專門針對時空軌跡數據進行有效信息發掘的一種過程,隨著移動通訊設備和視頻監控設備的快速發展,軌跡數據與日劇增,針對移動對象的分析和研究也越來越受到人們的重視。如何有效管理和利用移動對象的各種信息已成為目前研究的熱點之一。軌跡數據處理主要包括數據採集、數據預處理、數據分析、結果可視化等流程。
時空軌跡數據挖掘中軌跡間相似度計算已有很多經典算法,這些算法適用於軌跡聚類,缺乏對軌跡數據多維度的分析,而軌跡間最相似軌跡段的計算尚無比較統一的方法。目前尚無面向用戶的純粹的軌跡相似度度量的系統,軌跡相似度計算多從屬於一些移動端應用的模塊等。
技術實現要素:
發明目的:針對現有技術中存在的問題,本發明提供一種結果更加準確,同時利用最長公共子序列的方法來構造軌跡間的最相似段的不同軌跡間相似度度量系統及其度量方法。
技術方案:為解決上述技術問題,本發明提供一種不同軌跡間相似度度量系統,包括用戶參與的軌跡數據文件上傳模塊和計算結果可視化模塊,其中軌跡數據文件上傳模塊通過數據預處理模塊後經過軌跡間相似度計算模塊得到最相似段構造模塊,最後通過計算結果可視化模塊傳送給用戶;
軌跡數據文件上傳模塊用於通過web上傳方式獲取數據;
數據預處理模塊用於讀取從數據採集模塊獲取的軌跡數據,判斷軌跡數據是否為經緯度或經緯度帶時間定義的合法數據;
軌跡間相似度計算模塊用於在保留軌跡整體特徵的情況下對已經過預處理的兩條軌跡進行軌跡點的匹配,然後對匹配結果進行統計分析,結合動態時間規整得出的特徵值計算出軌跡間的相似度大小;
最相似段構造模塊用於按順序考慮每一對軌跡點是否可以構造一對臨近點對,最終得出全局最優結果,並從構造結果內得出不同對子軌跡段,進而從子軌跡段對中找出最相似軌跡段;
計算結果可視化模塊用於將分析的結果通過gis形式進行展現。
進一步的,所述計算結果可視化模塊包括顯示器和含有gps定位功能的地圖軟體。
一種如上所述的不同軌跡間相似度度量系統的度量方法,具體步驟如下:
步驟一:通過軌跡數據文件上傳模塊實現數據上傳,具體的:使用web上傳方式採集數據,通過監聽web客戶端的數據上傳請求,建立客戶端和數據存儲伺服器的socket連接,再使用javai/o流將數據集寫入到數據存儲伺服器的文件系統中;
步驟二:讀取步驟一中軌跡數據文件上傳模塊獲取的軌跡數據,判斷軌跡數據文件是否合法,即是否為經緯度或經緯度帶時間定義的軌跡;如果判斷文件合法則進入步驟三,如果判斷文件不合法則進行錯誤提示並返回步驟一;
步驟三:通過數據預處理模塊對合法的文件進行預處理,預處理主要包括異常點檢測並去除,利用k-means算法對一條軌跡進行聚類,若某個類中僅有單獨一個軌跡點,則認定該軌跡點為異常點,將其去除,通過預處理提取出軌跡數據對象;
步驟四:通過軌跡間相似度計算模塊對軌跡間的相似度進行評價,具體的:基於經典的動態時間規整算法,在保留軌跡整體特徵的情況下對已經預處理的兩條軌跡進行軌跡點的匹配,然後對匹配結果進行統計分析,從經過臨近的點、經過各點的順序、經過各點的時間接近程度這三個方面考量軌跡間的相似度,最終歸一化處理計算出軌跡間的相似度大小;
步驟五:通過最相似段構造模塊尋找出最為相似的兩條軌跡,具體的:利用統計分析找出兩條軌跡上軌跡點之間區分臨近的一個距離閾值,利用該閾值進行最長公共子序列的構造,結合動態規劃思想,按順序考慮每一對軌跡點是否可以構造一對臨近點對,最終得出全局最優結果;然後從構造結果內得出不同對子軌跡段,繼而計算每對子軌跡段之間的相似度大小,子軌跡段之間相似度的計算按照步驟四中的計算方法依然考慮經過臨近的點、經過各點的順序、經過各點的時間接近程度這三個方面,從子軌跡段對中找出最相似軌跡段即為兩條軌跡最相似段;
步驟六:通過計算結果可視化模塊將計算結果顯示出來。
與現有技術相比,本發明的優點在於:
本發明充分分析影響軌跡間相似度的軌跡點之間距離、順序差、時間差等因素,綜合這些因素來評價軌跡間的相似度,將統計分析的思想與經典的動態時間規整算法相結合,深入考慮了軌跡間相似度的語義背景,相較於單一利用歐氏距離度量、利用動態時間規整距離度量、或者利用編輯距離度量等軌跡間相似度度量方法,計算結果更符合語義需要,更準確,可信度也更高。同時基於本相似度度量方法創新地利用最長公共子序列算法的思想來構造軌跡間的最相似段,提供了一種查詢軌跡間最相似軌跡段的方案,該方案查詢結果滿足需要,並且利用動態規劃思想實現最長公共子序列算法也使得這種構造方法效率較高。
附圖說明
圖1為本發明的結構示意圖;
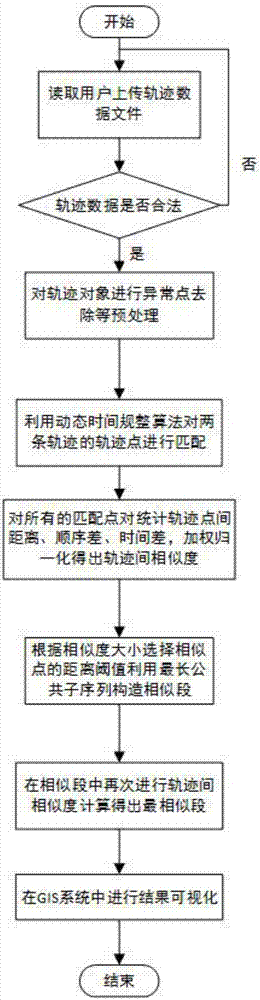
圖2為本發明的總體流程圖。
具體實施方式
下面結合附圖和具體實施方式,進一步闡明本發明。
如圖1所示,本發明涉及的軌跡相似度度量系統為用戶提供了經緯度或經緯度帶時間定義的不同軌跡間相似度的度量以及最相似軌跡段的查詢功能,用戶只需在軌跡數據上傳模塊提交軌跡數據文件,即可在結果可視化模塊查看所提交軌跡的計算結果,非常便捷。
本發明設計並實現軌跡數據文件上傳模塊使用web上傳方式獲取數據,其處理機制是通過監聽web客戶端的數據上傳請求,建立客戶端和數據存儲伺服器的socket連接,再使用javai/o流將數據集寫入到數據存儲伺服器的文件系統中。對於單個軌跡數據文件或者軌跡數據文件集,分別採取不同處理方法。
軌跡數據預處理模塊先讀取從數據採集模塊獲取的軌跡數據,判斷軌跡數據是否為經緯度或經緯度帶時間定義的合法數據。若不合法則返回錯誤提示,若合法則繼續進行必要的預處理,包括異常點檢測、缺失值處理、數據壓縮,避免異常數據以及冗餘數據。
本發明提出的系統的核心思想是引入統計分析的思想,對軌跡間的相似度進行評價。基於經典的動態時間規整算法,在保留軌跡整體特徵的情況下對已經過預處理的兩條軌跡進行軌跡點的匹配,然後對匹配結果進行統計分析,結合動態時間規整得出的特徵值計算出軌跡間的相似度大小。
本發明提出的系統是利用統計分析找出兩條軌跡上軌跡點之間區分臨近的一個距離閾值,利用該閾值進行最長公共子序列的構造。結合動態規劃思想,按順序考慮每一對軌跡點是否可以構造一對臨近點對,最終得出全局最優結果。從構造結果內得出不同對子軌跡段,進而從子軌跡段對中找出最相似軌跡段。
本發明對於軌跡相似度分析的展示結果使用gis形式,調用了百度地圖api來實現的。
本發明所述的度量方法主要包括以下步驟;
步驟1:設計並實現軌跡數據文件上傳模塊。使用web上傳方式採集數據,通過監聽web客戶端的數據上傳請求,建立客戶端和數據存儲伺服器的socket連接,再使用javai/o流將數據集寫入到數據存儲伺服器的文件系統中。考慮到軌跡數據可以是單個軌跡數據文件或者軌跡數據文件集,應分別採取不同處理方法。
步驟2:設計並實現數據預處理模塊。讀取軌跡數據文件上傳模塊獲取的軌跡數據,判斷軌跡數據文件是否合法,即是否為經緯度或經緯度帶時間定義的軌跡。若數據不合法則進行錯誤提示,對於合法的數據進一步進行必要的預處理,包括異常點檢測、缺失值處理、數據壓縮,避免異常數據以及冗餘數據對軌跡相似度度量的影響。軌跡數據經預處理提取出軌跡數據對象,供後續軌跡間相似度的度量。
步驟3:設計並實現相似度評價模型模塊。引入統計分析的思想,對軌跡間的相似度進行評價。基於經典的動態時間規整算法,在保留軌跡整體特徵的情況下對已經過預處理的兩條軌跡進行軌跡點的匹配,然後對匹配結果進行統計分析,從經過臨近的點、經過各點的順序、經過各點的時間接近程度這三個方面考量軌跡間的相似度,最終歸一化處理計算出軌跡間的相似度大小。
步驟4:設計並實現軌跡間最相似段構造模塊。利用統計分析找出兩條軌跡上軌跡點之間區分臨近的一個距離閾值,利用該閾值進行最長公共子序列的構造,結合動態規劃思想,按順序考慮每一對軌跡點是否可以構造一對臨近點對,最終得出全局最優結果。從構造結果內得出不同對子軌跡段,繼而計算每對子軌跡段之間的相似度大小,子軌跡段之間相似度的計算依然考慮經過臨近的點、經過各點的順序、經過各點的時間接近程度這三個方面,從子軌跡段對中找出最相似軌跡段即為兩條軌跡最相似段。
步驟5:設計並實現結果可視化顯示模塊。首先將相似度計算結果進行展示,同時可以通過調用可訪問百度地圖進行軌跡的展示,充分表現軌跡的經緯度信息並在途中標註出最相似軌跡段。
如圖2所示,本發明所述的不同軌跡間相似度度量系統的度量方法,具體步驟如下:
步驟一:通過軌跡數據文件上傳模塊實現數據上傳,具體的:使用web上傳方式採集數據,通過監聽web客戶端的數據上傳請求,建立客戶端和數據存儲伺服器的socket連接,再使用javai/o流將數據集寫入到數據存儲伺服器的文件系統中;
步驟二:讀取步驟一中軌跡數據文件上傳模塊獲取的軌跡數據,判斷軌跡數據文件是否合法,即是否為經緯度或經緯度帶時間定義的軌跡;如果判斷文件合法則進入步驟三,如果判斷文件不合法則進行錯誤提示並返回步驟一;
步驟三:通過數據預處理模塊對合法的文件進行預處理,預處理主要包括異常點檢測並去除,利用k-means算法對一條軌跡進行聚類,若某個類中僅有單獨一個軌跡點,則認定該軌跡點為異常點,將其去除,通過預處理提取出軌跡數據對象;
步驟四:通過軌跡間相似度計算模塊對軌跡間的相似度進行評價,具體的:基於經典的動態時間規整算法,在保留軌跡整體特徵的情況下對已經預處理的兩條軌跡進行軌跡點的匹配,然後對匹配結果進行統計分析,從經過臨近的點、經過各點的順序、經過各點的時間接近程度這三個方面考量軌跡間的相似度,最終歸一化處理計算出軌跡間的相似度大小;
步驟五:通過最相似段構造模塊尋找出最為相似的兩條軌跡,具體的:利用統計分析找出兩條軌跡上軌跡點之間區分臨近的一個距離閾值,利用該閾值進行最長公共子序列的構造,結合動態規劃思想,按順序考慮每一對軌跡點是否可以構造一對臨近點對,最終得出全局最優結果;然後從構造結果內得出不同對子軌跡段,繼而計算每對子軌跡段之間的相似度大小,子軌跡段之間相似度的計算按照步驟四中的計算方法依然考慮經過臨近的點、經過各點的順序、經過各點的時間接近程度這三個方面,從子軌跡段對中找出最相似軌跡段即為兩條軌跡最相似段;
步驟六:通過計算結果可視化模塊將計算結果顯示出來。
以上所述僅為本發明的實施例子而已,並不用於限制本發明。凡在本發明的原則之內,所作的等同替換,均應包含在本發明的保護範圍之內。本發明未作詳細闡述的內容屬於本專業領域技術人員公知的已有技術。