地址標準化方法、裝置、存儲介質及計算機與流程
2024-04-02 10:12:05 3
本發明涉及一種地址標準化方法。
背景技術:
百分之八十的商業活動都離不開地址。準確的地址,不僅可幫助商業機構和政府機關減少郵件費用,甚至還可降低欺詐風險,促進社會和諧發展。對於商業機構來說,如何能在第一時間判斷出錯誤地址,不完整地址,並提醒客戶相關的正確地址,進而通過地理信息系統將這些地址空間化表達,實現各種信息在不同部門,不同行業之間的數據共享,這是提升競爭力和獲益能力的關鍵。
目前商業社會和政府部門都存有大量與地址有關的地理位置信息,這些數據大多是非空間信息,無法通過地理信息系統來實現行業之間的數據共享。因此,城市地址信息空間化是數字城市建設的重要組成部分。
地理編碼技術正是實現城市地址信息空間化的方法,它提供了一種將文本描述的地址信息轉換為地理坐標的方式,通過編碼技術和地址匹配來確定此地址數據在電子地圖上對應的地理實體位置。通過地理編碼技術,大量的社會經濟數據將變成坐標化的空間信息,從而進行更快速有效的空間分析,為政府決策和商業決策提供支持。
國內的地理編碼技術研究起步比較晚而且進展比較緩慢,從上世紀80年代才逐步開展了城市地址編碼的研究工作。最早是北京市城市規劃設計研究院1988年開始《北京市城市地理編碼》的研究,並組織相關單位編制了《城市基礎地理信息系統技術規範》提出了地名、門牌和樓牌的採集原則。之後還建設了北京市的地址編碼資料庫,研究了地址數據的採集工藝流程,建立了標準地址模型。隨後,國內的其他城市如上海、大連、廣州等,在建設城市地理信息系統的同時也開展了地理編碼的研究。
國內一些公司和科研單位也在研究適合我國使用的地址編碼技術和標準,並開發了一些應用軟體,例如:
北京長地公司的「尋址神」;北大方正的「小紅帽物流管理系統」;超圖的「客戶關係管理系統」;supermapobjects.net/java6r中的地址匹配模塊提供了中文地址模糊匹配搜索的功能。
圖信時代研發的地理編碼系統mapworldgeocodingsystem,包括數據轉換、數據清洗以及地址匹配三個子系統。建設了基礎地理信息庫,可以對不同的精度要求提供地址匹配服務,並將結果定位到地圖上進行可視化展示與應用。geocoding服務返回的結果可包括:地址的經緯度信息,國家行政區劃代碼,6位郵編號碼,人口普查信息鄉鎮街道名等等。
山海易繪的地址編碼系統提供了比較全面的地址信息編碼和匹配方案,可以快速地將以自然語言描述的地址信息定位到地圖上,使得以前傳統的mis數據和gis數據可以互相融合利用。
mapgis-ems是中地公司自主研發的面向嵌入式終端的gis開發平臺,全面應用構件技術、中間件技術,整合最新的gis技術、嵌入式作業系統和網絡通訊技術,實現了利用地址簿進行快速地址查詢及實現了模糊地址匹配。
由於區域面積比較小,地址編碼的工作量相應的就比較小。因此,香港特別行政區和臺灣省的地址匹配精確度相對於大陸是比較高的。香港的匹配精度可達到街道門牌和建築物,臺灣省可以達到街道和主要景點。
不同行業或部門都有自己不同的需求,以不同的形式採集、處理和傳播空間信息,因此採集的地址數據的格式和質量有很大區別,存在輸入拼寫錯誤或者表達模糊、地址殘缺等情況。比如由於地址規範不統一,同一個地址可能有好幾種不同寫法。同樣一個小區,開發商可能一個叫法,銷售商另外一個,老百姓約定俗成又是一個。銀行a可能記下來一個,保險公司b又是另外一個,水,電,煤,有線,電信,寬帶等等各行其是。
前述由於地址規範不統一,導致的同一個地址可能有好幾種不同寫法的問題,除了對商業機構本身造成困擾,也會對機關間的合作造成極大不便,客戶信息無法充分整合,資源極大浪費。歸根到底,這是由於地址不規範,不完整,不準確的原因。
因此,在進行地理編碼之前,需要將這些來源不同的混亂數據進行清洗和預處理,並按照確定的標準地址模型進行修改,使地址數據用一致的形式表現出來。
技術實現要素:
為解決地址不規範不統一造成的前述問題,根據本發明的一個方面,提出一種地址標準化方法,又叫做地址規範化方法,其通過地址拆分、修改或去除錯誤地址、完善模糊地址等方法對地址數據進行處理,使其滿足確定的地址模型的要求。具體技術方案包括:
建立地址分層系統模型,並針對每個層級預置字典庫;
根據字典庫確定每個層級的地址要素通名;
接收第三方地址信息;
按照通名,利用正則表達式對第三方地址信息初步劃分層級;
將正則表達式劃分的結果與地址分層系統進行正則匹配;
對匹配成功後不完整的地址信息進行補齊;
將補齊後的地址信息作為標準地址保存在標準地址庫;以及
將標準化結果匯總輸出。
進一步地,在正則匹配的步驟之後還包括:
分詞匹配步驟,對接收的無法匹配或無法拆分的部分地址信息進行分詞匹配處理;以及
地址信息修正的步驟,將分詞後仍無法匹配的地址信息按照預置的修正標準與標準地址庫進行對比修正,如果得到的修正結果唯一,則將地址信息替換為修正後的地址信息,並將修正後的地址信息保存在標準地址庫中。
進一步地,修正標準包括通名修正、別名修正、舊名修正、同音修正和別字修正。
進一步地,地址分層系統為四級六層地址分層系統;四級分別為行政區級、路弄級、樓棟級和室級;六層分別為屬於行政區級的區縣、街道、居委,屬於路弄級的路弄,屬於樓棟級的樓號和屬於室級的室號。
進一步地,分詞匹配處理採用逆向最大匹配法。
根據本發明的另一個方面,提出一種地址標準化裝置,包括:
地址分層系統模型建立單元,地址分層系統模型建立單元被配置為建立地址分層系統模型,並針對每個層級預置字典庫;
通名確定單元,通名確定單元根據字典庫確定每個層級的地址要素通名;
接收單元,接收單元接收第三方地址信息;
層級劃分單元,層級劃分單元按照通名,利用正則表達式對第三方地址信息初步劃分層級;
正則匹配單元,正則匹配單元將正則表達式劃分的結果與地址分層系統進行正則匹配;
補齊單元,補齊單元對匹配成功後不完整的地址信息進行補齊;
存儲單元,存儲單元將補齊後的地址信息作為標準地址保存在標準地址庫中;以及
輸出單元,輸出單元將標準化結果匯總輸出。
進一步地,還包括:
分詞匹配單元,分詞匹配單元對接收的無法匹配或無法拆分的部分地址進行分詞匹配處理;以及
地址信息修正單元,地址信息修正單元將分詞後仍無法匹配的地址信息按照預置的修正標準與標準地址庫進行對比修正,如果得到的修正結果唯一,則將地址信息替換為修正後的地址信息,並將修正後的地址信息保存在標準地址庫中。
根據本發明的另一個方面,提出一種非易失性存儲介質,在存儲介質上存儲有地址標準化程序,地址標準化程序被計算機執行以實施前述的地址標準化方法。
根據本發明的另一個方面,提出一種計算機,包括:
存儲器,存儲器存儲有計算機可以執行的地址標準化程序;以及
處理器,連接至存儲器,並且被配置為執行地址標準化程序以實現前述的地址標準化方法。
本發明是地址匹配的重要組成部分,不論是標準地址編碼資料庫的建設,還是原始地址匹配,都要通過地址標準化這一過程才能完成。本發明能夠有效解決前述地址規範不統一的問題,為商業機構鋪橋墊路,打造智慧城市的基礎。
附圖說明
圖1是根據本發明的一個實施例的四級六層地址分層系統示意圖。
圖2是根據本發明的一個實施例的地址標準化方法流程圖。
圖3是根據本發明的另一實施例的地址標準化方法流程圖。
圖4是根據本發明的一個實施例的正向最大匹配法的分詞流程示意圖。
圖5是根據本發明的一個實施例的更細層次的分層模型示意圖。
圖6是根據本發明的一個實施例的地址標準化裝置示意圖。
具體實施方式
下面結合具體實施例和附圖對本發明做進一步說明。
要進行地址的標準化,首先要確定一個當前適用的標準地址模型。地址模型的建立要結合中文地址的特點。中文地址通常有以下特點:
1.日常生活中所用的地址很多都不是傳統的街道地址形式。例如地址欄位上海市武東路財大科技園13f,對比正確的地址上海市楊浦區武東路財大科技園13f,缺少了必要的「區」以及道路信息,這加大了地址匹配的難度。
2.由於一些歷史遺留問題,或者地方性的約定俗成的習慣,有些地名地址還是歷史地址,沒有重新規劃命名,也造成了城市地名地址的偏僻、混亂或重複現象。
3.漢語字符串的組成較之英文多了一層,英文單詞獨立成詞且有符號進行分割,而漢語詞組是由字組成的,而且中文地址的表達沒有空格或者逗號之類的符號。
下面首先引入一些地址組成的基本概念:
1.地址串:就是一般的地址,日常的通信門牌地址。例如:上海市楊浦區武東路198號。
2.地址要素:組成地址串的若干詞組,如前述的地址就是由4個地址要素組成的,分別是「上海市」、「楊浦區」、「武東路」和「198號」,每個地址要素相對獨立。
3.地址通名:顧名思義,就是地址要素中通用的那些欄位。例如:地址要素「楊浦區」中「區」為地址通名,「武東路」中「路」為地址通名。地址要素都表示一個地理區域,按照這個區域的範圍大小,可以把地址要素分類。同一類地址要素的字符串中都有相同的欄位,這些欄位就是地址通名。
4.地址專名:例如:「楊浦區」中「楊浦」為地址專名。地址要素中去掉地址通名後剩餘的部分就稱為地址專名。城市的地址模型是一種複雜的層次模型。為了準確地分析並描述地址模型,需要確定最小地址要素,最小地址要素是指不可再分的地址要素,具有最小的地址意義。
例如,漢中路就是一個最小地址要素,如果再將漢中路拆分為漢、中和路就沒有意義了。
根據本發明的一個實施例,可以將地址要素分為3大類,分別是:行政區界、地址部分和子地址部分。
1.行政區界
行政區劃部分:它包括以下幾層:
國家:可以預設;
省級:可預設。通名:省、直轄市、自治區、特別行政區;
市級:不能為空。通名:市、盟、自治州等;
區縣:可以為空。通名:區、(縣級)市、縣、旗等;
鄉級:鄉、鎮、街道辦等;
村級:社區、小區、村、莊、屯、裡等。
2.地址部分:它是一條地址數據的核心組成部分,描述地址的具體內容。這部分不可以為空。它主要包括:道路和門牌號。
道路通名:路、街、道、大街、大道、胡同、巷、弄、條等。
門牌通名:號、#等。
3.子地址部分:它是一條地址數據中剩餘的部分,描述地址的補充信息。該部分可以為空。它包括樓牌號、住宅小區、社區。
社區通名:社區、園等。
住宅小區通名:小區、公寓、苑、花園、街坊等。例:翠園小區。
樓牌號通名:門、棟、號樓、樓、館、堂等。
根據本發明的一個實施例,結合國家和區域標準,提出四級六層的地址分層系統模型,如圖1所示,並針對每個層級預置一個字典庫。字典庫包括該層級的通用信息,例如,以上海為例,圖1中的區縣層可以包括上海的16個轄區。此外,地址舊名也可以納入字典庫中,並與新名建立映射關係,例如,原來的上海南市區,其對應於現在的黃浦區。
需要注意的是,該四級六層的地址分層系統僅僅是分層模型的一個示範性實例,在其他實施例中,也可以採用其他層級劃分方式。
根據本發明的一個實施例的地址標準化裝置如圖6所示,包括:地址分層系統模型建立單元,所述地址分層系統模型建立單元被配置為建立地址分層系統模型,並針對每個層級預置字典庫;通名確定單元,所述通名確定單元根據所述字典庫確定每個層級的地址要素通名;接收單元(圖中未示出),所述接收單元接收第三方地址信息;層級劃分單元,所述層級劃分單元按照所述通名,利用正則表達式對所述第三方地址信息初步劃分層級;正則匹配單元,所述正則匹配單元將正則表達式劃分的結果與所述地址分層系統進行正則匹配;分詞匹配單元,所述分詞匹配單元對接收的無法匹配或無法拆分的部分地址進行分詞匹配處理;地址信息修正單元,所述地址信息修正單元將所述分詞後仍無法匹配的地址信息按照預置的修正標準與標準地址庫進行對比修正,如果得到的修正結果唯一,則將所述地址信息替換為修正後的地址信息,並將修正後的地址信息保存在所述標準地址庫中;補齊單元,所述補齊單元對匹配成功後不完整的地址信息進行補齊;存儲單元,所述存儲單元將所述補齊後的地址信息作為標準地址保存在標準地址庫中;以及輸出單元(圖中未示出),所述輸出單元將標準化結果匯總輸出。可選擇地,在一些實施例中,根據不同需求,可以包括其他合適的單元,以上單元中的一部分也可以省略。
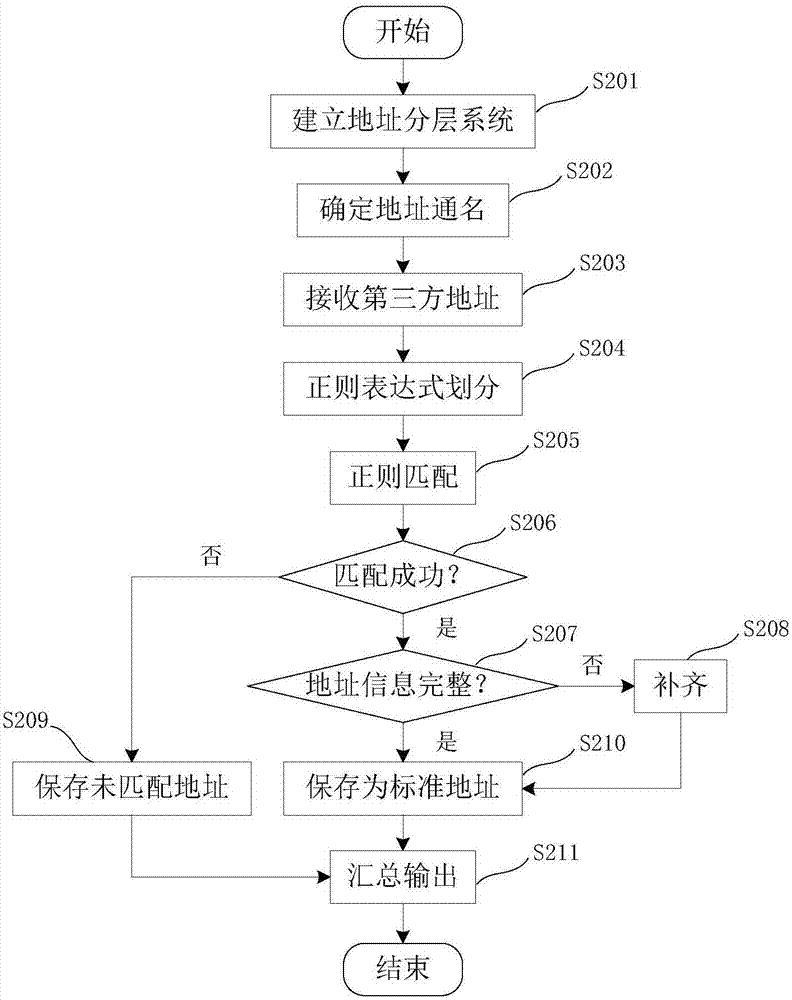
下面參照圖2介紹根據本發明的一個實施例的地址標準化方法。根據本發明的一個實施例,建立四級六層的地址分層系統(步驟s201)後,根據所述字典庫確定每個層級的地址要素通名(步驟s202),接收批量的第三方地址(步驟s203)後,按照所述通名,利用正則表達式對地址信息初步劃分層級(步驟s204)。
根據本發明的一個實施例的地址解析正則表達式處理方法如下:
首先進行地址預處理,包括以下步驟:
1.去除地址進行前後和中間空格,去除「:」、「.」等特殊符號,去除地址中以「下」結尾的,縣替換「區」,去除「農場村」(農場路除外);
2.去除區縣(解析到區縣返回)、鎮,去除地址中的「複式」關鍵字;
3.去除帶「層」信息,「號幢」替換「號」,去除帶「幢」信息,去除帶「單元」的信息。
可選擇地,在其他實施例中,根據不同需求,以上地址預處理的步驟可以包括其他未示出的步驟,也可以省略其中的一些或者全部。
地址預處理後,首先利用正則表達式進行常規正則匹配(步驟s205),解析出路、弄、樓棟號、室等常規信息。
隨後,進行非常規正則匹配,包括:小區樓棟匹配:小區、樓棟特殊關鍵字;路弄樓棟匹配:路弄、樓棟特殊關鍵字;小區樓棟房間匹配:小區、樓棟、房間特殊關鍵字匹配;房間解析方法:匹配地址中「全幢室」、「樓層-室」等。可選擇地,根據不同地區的地址特點,還可以加入其它正則匹配方式。
查看匹配結果(步驟s206),對於匹配成功後的地址信息與地址分層系統模型進行對比,判斷地址信息是否完整(步驟s207),對其中不完整的地址信息按照四級六層的系統模型進行補齊(步驟s208);對於補齊後的地址信息,將保存為標準地址庫(步驟s210);對於其餘匹配不上的地址信息,輸出列表並保存(步驟s209);最後將信息匯總輸出(步驟s211),可選擇地,可以同時輸出匹配率等信息,其中匹配率的計算方式為:匹配通過的地址數量/全部地址數量。
根據本發明的一個實施例,在以上步驟完成後,可選擇地,可以人工對匹配不上的地址進行檢查,確定入庫或修改的地址,通過更新程序更新。
下面根據附圖3介紹根據本發明的另一實施例的地址標準化方法。如圖3所示,步驟s301-s306與前述實施例的步驟s201-s206相同,此處不再贅述。與前述實施例不同的是,在正則匹配的步驟之後,還包括分詞匹配的步驟和地址信息修正的步驟。
而對於步驟s306中被判斷為無法匹配或無法拆分的部分地址可以進行分詞匹配處理(步驟s307)。現有的中文分詞方法多種多樣,都各有自己的特點。常用的中文分詞方法概括可以分為四大類:基於字典匹配的分詞方法、基於理解的分詞方法、基於統計的分詞方法和基於語義的分詞方法。由於基於語義的分詞方法實現難度大,目前研究較少而不成熟,故不在本研究範圍之內。下面詳細的介紹其他幾種方法。
1.基於字典的分詞方法
又叫做基於字符串的分詞方法或機械分詞方法。由於這種方法是基於詞典的,因此要事先準備好一個「充分大的」分詞詞典,「充分大」就是說字典包含的詞語儘量多,儘可能的減少未登錄詞。然後將待切分的漢語字符串,如句子,按照一定的掃描規則與詞典中的詞條進行匹配。如果在詞典中找到了句子中的某個字符串,則將這個詞切分出來,這就成功匹配識別出一個詞。待切分句子可以按照任意長度或順序分為若干字符串,所以要進行數次匹配,才能將句子切分為詞。
在字典中進行查詢匹配時的規則有很多種,根據掃描方向的不同,可以分為正向匹配和逆向匹配;按照不同長度優先匹配的情況,可以分為最大(最長)匹配和最小(最短)匹配。目前最常用的是最大匹配法,有正向和逆向兩種方式。由於漢語單字成詞的特點,最小匹配法一般很少使用。下面分別介紹基於字符串的幾種分詞方法:
(1)正向最大匹配法
最大匹配,意思就是說用最長的中文切分方式,使切分結果中的詞組儘可能最大長度而其總數最少。例如,待切分的中文句子「武東路上的財大科技園」,如果在詞典中匹配成功就將詞切分出來,那麼切分的結果應該是「武東路/上/的/財大/科技園」。而按照最大匹配的原則,「財大科技園」就是一個詞,有時更符合我們的要求。
它的基本思想是:首先創建一個用於自動分詞的中文詞典,可以得知詞典中的最長詞條的漢字個數,假設個數為n。然後,取待切分句子的前n個字符作為匹配欄位,在分詞詞典中進行欄位的查詢匹配。如果詞典中有這樣的欄位,則匹配成功。這樣,由n個字符組成的欄位被切分出來,作為一個詞。如果詞典中不存在這樣的欄位,則匹配失敗,將欄位末尾減去一個漢字,剩下的n-1個字符作為新的欄位,再進行匹配,如此重複,直到匹配成功為止。例如句子「武東路上的財大科技園」,假設字典的最長詞長為5,它的正向最大匹配法的分詞流程如圖4所示。
這種分詞方法過程比較簡單,切分精度與中文詞典的數據量和數據結構有關,分詞正確率並不是很高。實驗表明,該分詞方法的錯誤率為1/169。
(2)逆向最大匹配法。
它的分詞過程與正向最大匹配法基本相同,不再重複說明。它與正向最大匹配法不同的是從句子末尾開始切分,如果匹配不成功則減掉最前面的一個字。逆向最大匹配的切分精度略高於正向。通過實驗表明,其分詞錯誤率為1/245。從以上實驗可以看出,逆向匹配的切分精度相對於正向匹配要略高,而且歧義現象也較少。
(3)最少切分詞方法,就是使切分後得到得詞組數量儘可能的少。
(4)逐詞遍曆法。
這種方法比較另類,它是把詞典中的詞與待切分句子進行匹配,詞典中的每個詞全部都要與切分目標句子匹配一遍。
另外還有很多中文分詞方法,如設立切分標誌法、最佳匹配法、聯想匹配法、二次掃描法等等。
2.基於理解的分詞方法
它一般有三個部分:分詞子系統、句法語義子系統和總控部分。專家系統分詞法和神經網絡分詞法等都是基於理解的分詞方法。這種方法要利用語法、句法分析來進行分詞,還要結合語義分析,根據上下文提供的信息來分析詞的切分,判斷分詞歧義現象。這是一種人工智慧的分詞方法,需要使用大量的語言知識和信息,也可以應用在本發明的實施例中。
3.基於統計的分詞方法
這種方法又稱為無字典分詞,也也就是說不用分詞詞典。在概率學上,單個字組合成詞組的概率是比較大的。當相鄰的字經常在語句中出現,那麼這幾個相鄰字很有可能就是一個詞。因此字與字相鄰出現的概率或頻率能較好反映成詞的可信度。在對待切分語言資料分詞的時候,統計相鄰字組合出現的頻度。如果相鄰字組合出現的頻率遠大於單個字出現的頻率之積,超過了某個閾值,則認為相鄰的字串就是一個詞組。該方法需要應用很多統計模型,主要有:n元文法模型、隱markov模型和最大熵模型等。
以上分詞方法各有優劣,根據本發明的一個實施例,優選基於字符串的逆向最大匹配法,在具體的應用中,這些方法均可以單獨或組合使用,以便提高分詞的速度和精度。
根據本發明的一個實施例,在分詞階段,可以不局限於標準地址四級六層的層次結構,先劃分為較細的層次,如圖5所示,以便於進行邏輯判斷,在最終標準化輸出時根據映射關係轉化為標準層次。
分詞匹配完後再次查看匹配結果(步驟s308),判斷地址信息是否完整(步驟s312),對於其中不完整的地址信息按照四級六層的系統模型進行補齊(步驟s313)。
根據本發明的一個實施例,在分詞匹配後,還包括對於無法匹配的部分地址按照層次結構分別進行修正的步驟(步驟s309)。修正可以包括以下幾類:
1.通名修正
和標準庫相比,名稱相同而通名不同(或通名缺失),如果修正結果唯一,則進行自動修正,並標記類型為通名修正。
比如寶安路與寶安公路
比如號甲與甲號
2.別名修正
針對有多個別名的小區,小區名稱無法與標準庫中的小區名稱匹配上,但可以和小區別名匹配上的,取得小區地址,並替換小區名稱為標準名稱,同時標記類型為別名修正。
除了名稱之外,地址也存在地址別名的情況。如漢中路333弄。處理方法參照別名修正。
3.舊名修正
針對行政區、道路、地址存在舊名的情況,名稱無法標準名稱匹配,但可以和舊名匹配上的,用新名替換舊名,並標記類型為舊名修正。
4.同音修正
和標準庫相比,文字不同而發音相同,如果修正結果唯一,則進行自動修正,並標記類型為同音修正。比如浦東大道與普東大道。
5.別字修正
和標準庫相比,名稱無法標準名稱匹配,但可以和別字匹配上的,如果修正結果唯一,則進行自動修正,並標記類型為通名修正。比如大渡河路與大渡可路。
當然,修正的結果並不能保證百分百的正確,在本實施例中,可以根據統計結果為各種修正結果賦予不同的置信度,在出現衝突時,優選置信度較高的結果作為最終結果。
判斷修正是否成功(步驟s310),對於修正成功的地址信息,判斷地址信息是否完整(步驟s312),對其中不完整的地址信息按照四級六層的系統模型進行補齊(步驟s313)。
補齊操作後,將補齊後的地址信息保存為標準地址庫(步驟s314)。對於其餘匹配不上的、修正不成功的地址及小區,輸出列表並保存(步驟s311),最後將信息匯總輸出(步驟s315),可選擇地,可以同時輸出匹配率等信息,其中匹配率的計算方式為:匹配通過的地址數量/全部地址數量。
根據本發明的實施例,在修正完成後,可選擇地,可以人工對匹配不上的地址進行檢查,確定入庫或修改的地址,通過更新程序更新。
下面介紹標準地址的匹配方法。地址數據經過清洗和規範化,並由地址分詞處理得到一系列的地址要素詞組,然後將這些地址要素按照一定的規則在標準地址庫中進行查詢匹配的過程,就是資料庫匹配。顯然,如何減少查詢和比較的次數,關係到匹配的效率和成功率。一種方法是採集的地址信息和地址庫中的信息一一對應,但該方法精度高卻效率低。為了提高地址匹配的效率,在與資料庫進行匹配之前,可以根據地址中地址要素的組成形式來制定地址匹配的規則,以及地址匹配的模式。地址的組成形式有很多,常見的包括以下幾類,如:街道+門牌,街道+門牌+樓牌,住宅小區+樓牌,街道+建築物等。
常見的地址匹配的方式有三種:定位到街道,定位到區域的,如居民小區、配送點式區域等,以及兩種方式結合的方法。另外還有基於郵政編碼的和基於邊界的地址匹配方法。
1.定位到街道的方法
是通過道路名和門牌號碼進行匹配。這種匹配方式的標準地址庫中每一個路段都具有道路名和起止門牌號碼信息,在地理編碼時,首先根據地址信息中道路名找到參考主題中相同名稱的路段(一般情況下有多個路段),然後根據地址信息中的門牌號及每個路段的起止門牌號碼信息找到門牌號所在路段,最後根據門牌號及該路段的起止門牌號碼信息進行內插確定該記錄在該路段上的位置。這種方式利用了數值逼近方法中的插值原理進行模糊定位。另外,如果待匹配地址的門牌號在資料庫中查找不到,可以查找和它最臨近的建築物門牌號,由此來輔助定位,可以提高插值定位的精度。
插值定位的方法不受道路形狀的影響,定位的精度比較高,它是根據地址記錄的門牌號以及其與街道的垂直距離進行準確的定位。這種方法比較適用於國外的定位到街道的地址匹配,因為國外的門牌號碼一般是按奇偶數分別排在路的兩端,門牌號的分布比較有規律,這樣插值時點位的位置不會出現太大的誤差。然而我國的道路門牌號體系複雜多樣,存在很多問題。例如城市建設中道路拆除或者改名,但門牌號沒有重新編制、門牌號丟失、門牌樓牌混編等情況。這些問題使得利用插值方法時容易出現較大的誤差,定位的精確度不高。
2.定位到區域的方法
待匹配地址具有區域屬性記錄,在地址資料庫中查詢與之相應的區域屬性記錄並進行比較,若匹配成功,則將記錄以點要素的形式生成在地圖的相應區域內。若匹配失敗,可以利用地址模型的層級關係,查找上一級地址要素來進行模糊定位。
這種方法的定位精度與資料庫中地址的區域屬性所代表的空間範圍大小有關,空間範圍越小則精度越高。如定位到居民小區的精度高於定位到行政區的精度。
優選地,本實施例中將定位到街道的方法與定位到區域的方法結合起來使用,以提高匹配的精度。在其他實施例中,也可以單獨使用其中的一種或者其他未進行說明的匹配方法。
根據本發明的又一實施例,還包括一種分易失性存儲介質,在存儲介質上存儲有地址標準化程序,地址標準化程序被計算機執行以實施前述地址標準化方法。
根據本發明的又一實施例,還包括一種計算機,包括:存儲器,存儲有計算機可以執行的地址標準化程序;以及處理器,連接至存儲器,並且被配置為執行地址標準化程序以實現前述地址標準化。
上面結合附圖對本發明的實施例做了詳細說明,但本發明並不限於上述實施例,在本領域普通技術人員所具備的知識範圍內,在不脫離本發明宗旨的前提下做出的各種變化,均應歸屬於本發明專利涵蓋範圍。