模型訓練數據生成方法及裝置與流程
2024-04-15 12:28:05 4
1.本技術涉及計算機技術領域,特別涉及模型訓練數據生成方法。本技術同時涉及模型訓練數據生成裝置,一種計算設備,以及一種計算機可讀存儲介質。
背景技術:
2.不平衡數據集是指在多類別的數據集中,某些類別樣本的數目遠小於其他類別樣本的數目,各個類別樣本的數目存在著嚴重的不平衡現象。而傳統的機器學習方法是建立在訓練集類別平衡的基礎上的,對於數據偏差分布的情況敏感度較低,導致預測結果偏向多類數據集。
3.目前,通過對數目較小的數據集中的數據進行過採樣,使得各類別樣本的數目達到平衡狀態,從而進行模型訓練;但隨著業務數據的複雜度越來越高,各類別樣本數據集的分布性不夠廣泛,在進行過採樣處理時,就會出現一類過採樣的數據可能與其他類的樣本數據邊界模糊甚至重疊,導致過採樣後的數據集,數據精準度降低,進而影響後續對模型訓練的結果。
技術實現要素:
4.有鑑於此,本技術實施例提供了模型訓練數據生成方法。本技術同時涉及模型訓練數據生成裝置,一種計算設備,以及一種計算機可讀存儲介質,以解決現有技術中存在的模型訓練數據精準度較低,影響模型訓練效果。
5.根據本技術實施例的第一方面,提供了一種模型訓練數據生成方法,包括:
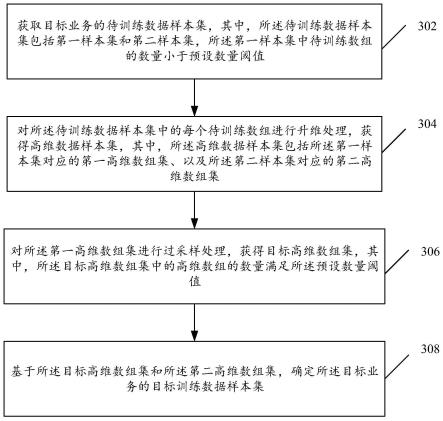
6.獲取目標業務的待訓練數據樣本集,其中,所述待訓練數據樣本集包括第一樣本集和第二樣本集,所述第一樣本集中待訓練數組的數量小於預設數量閾值;
7.對所述待訓練數據樣本集中的每個待訓練數組進行升維處理,獲得高維數據樣本集,其中,所述高維數據樣本集包括所述第一樣本集對應的第一高維數組集、以及所述第二樣本集對應的第二高維數組集;
8.對所述第一高維數組集進行過採樣處理,獲得目標高維數組集,其中,所述目標高維數組集中的高維數組的數量滿足所述預設數量閾值;
9.基於所述目標高維數組集和所述第二高維數組集,確定所述目標業務的目標訓練數據樣本集。
10.根據本技術實施例的第二方面,提供了一種模型訓練數據生成裝置,包括:
11.樣本集獲取模塊,被配置為獲取目標業務的待訓練數據樣本集,其中,所述待訓練數據樣本集包括第一樣本集和第二樣本集,所述第一樣本集中待訓練數組的數量小於預設數量閾值;
12.升維處理模塊,被配置為對所述待訓練數據樣本集中的每個待訓練數組進行升維處理,獲得高維數據樣本集,其中,所述高維數據樣本集包括所述第一樣本集對應的第一高維數組集、以及所述第二樣本集對應的第二高維數組集;
13.過採樣處理模塊,被配置為對所述第一高維數組集進行過採樣處理,獲得目標高維數組集,其中,所述目標高維數組集中的高維數組的數量滿足所述預設數量閾值;
14.樣本集確定模塊,被配置為基於所述目標高維數組集和所述第二高維數組集,確定所述目標業務的目標訓練數據樣本集。
15.根據本技術實施例的第三方面,提供了一種計算設備,包括存儲器、處理器及存儲在存儲器上並可在處理器上運行的計算機指令,所述處理器執行所述計算機指令時實現所述模型訓練數據生成方法的步驟。
16.根據本技術實施例的第四方面,提供了一種計算機可讀存儲介質,其存儲有計算機指令,該計算機指令被處理器執行時實現所述模型訓練數據生成方法的步驟。
17.本技術提供的模型訓練數據生成方法,獲取目標業務的待訓練數據樣本集,其中,所述待訓練數據樣本集包括第一樣本集和第二樣本集,所述第一樣本集中待訓練數組的數量小於預設數量閾值;對所述待訓練數據樣本集中的每個待訓練數組進行升維處理,獲得高維數據樣本集,其中,所述高維數據樣本集包括所述第一樣本集對應的第一高維數組集、以及所述第二樣本集對應的第二高維數組集;對所述第一高維數組集進行過採樣處理,獲得目標高維數組集,其中,所述目標高維數組集中的高維數組的數量滿足所述預設數量閾值;基於所述目標高維數組集和所述第二高維數組集,確定所述目標業務的目標訓練數據樣本集。
18.本技術一實施例,通過對待訓練數據樣本集中的每個待訓練數組均進行升維處理,獲得高維數據樣本集,再將高維數據樣本集中的第一樣本集對應的第一高維數組集進行過採樣處理,獲得目標高維數組集,即獲得了新的高維數組作為過採樣後的新樣本,進而,將目標高維數組集和高維數據樣本集中第二樣本集對應的第二高維數組集,作為最後的目標訓練數據樣本集;該種升維處理的方式,使得低維度數據映射到高維度數據,以提高數據之間的線性可分性,再對高維度數據進行過採樣,能夠更加準確地獲取到過採樣後的新樣本數據,避免了獲取與其他類樣本數據重疊的數據,進而,提升模型訓練的效果。
附圖說明
19.圖1是本技術一實施例提供的兩類樣本數據出現交錯情況的示意圖;
20.圖2是本技術一實施例提供的一種模型訓練數據生成方法的流程示意圖;
21.圖3是本技術一實施例提供的一種模型訓練數據生成方法的流程圖;
22.圖4是本技術一實施例提供的一種模型訓練數據生成方法的過採樣示意圖;
23.圖5是本技術一實施例提供的一種模型訓練數據生成裝置的結構示意圖;
24.圖6是本技術一實施例提供的一種計算設備的結構框圖。
具體實施方式
25.在下面的描述中闡述了很多具體細節以便於充分理解本技術。但是本技術能夠以很多不同於在此描述的其它方式來實施,本領域技術人員可以在不違背本技術內涵的情況下做類似推廣,因此本技術不受下面公開的具體實施的限制。
26.在本技術一個或多個實施例中使用的術語是僅僅出於描述特定實施例的目的,而非旨在限制本技術一個或多個實施例。在本技術一個或多個實施例和所附權利要求書中所
使用的單數形式的「一種」、「所述」和「該」也旨在包括多數形式,除非上下文清楚地表示其他含義。還應當理解,本技術一個或多個實施例中使用的術語「和/或」是指並包含一個或多個相關聯的列出項目的任何或所有可能組合。
27.應當理解,儘管在本技術一個或多個實施例中可能採用術語第一、第二等來描述各種信息,但這些信息不應限於這些術語。這些術語僅用來將同一類型的信息彼此區分開。例如,在不脫離本技術一個或多個實施例範圍的情況下,第一也可以被稱為第二,類似地,第二也可以被稱為第一。取決於語境,如在此所使用的詞語「如果」可以被解釋成為「在
……
時」或「當
……
時」或「響應於確定」。
28.首先,對本技術一個或多個實施例涉及的名詞術語進行解釋。
29.核函數:核函數源自於svm(支持向量機)模型,具體包括高斯核函數、線性核函數、多項式核函數等多種。
30.高斯核函數(gaussian kernel),也稱徑向基(rbf)函數,就是某種沿徑向對稱的標量函數,用於將有限維數據映射到高維空間。通常定義為空間中任意一點x到某一中心點x'之間的歐式距離的單調函數,可記作k(||x-x'||),其作用往往是局部的,即當x遠離x'時函數取值很小。
31.過採樣:在機器學習的分類任務中通常需要數據量大概相同的正負類樣本才能達到比較好的學習效果,但是在現實場景中正負類樣本的數據量往往是不平衡的,過採樣就是指對少數類的樣本進行擴充從而提高模型學習效果。
32.等核函數,其作用是將低維度數據映射到高維度數據中從而實現數據的線性可分。
33.smote(synthetic minority oversampling technique):即合成少數類過採樣技術,它是基於隨機過採樣算法的一種改進方案,由於隨機過採樣採取簡單複製樣本的策略來增加少數類樣本,這樣容易產生模型過擬合的問題,即使得模型學習到的信息過於特別(specific)而不夠泛化(general),smote算法的基本思想是對少數類樣本進行分析並根據少數類樣本人工合成新樣本添加到數據集中。
34.在遊戲內玩家對禮包或者道具的購買數據,或者是不夠買數據,可以看作為不平衡數據集。隨著玩家數量的增多,大多數所反應的現象就是夠買數據比較少,不夠買數據比較多,進而,在後續訓練模型的過程中,這種類別樣本數目的不平衡,較大程度上會影響模型訓練的精準度。
35.目前,可採用過採樣的方式,將少類別的樣本數據進行過採樣,使得少類別的數目增多,再進行模型訓練。當前使用smote過採樣時,可對玩家購買數據進行過採樣處理,以使少數類樣本進行擴充,以提高後續模型學習效果。但該方式僅限於在玩家購買數據和玩家不夠買數據這兩類數據界限比較明顯時有效,若兩類樣本數據交錯在一起,就會很容易合成錯誤的購買數據新樣本,可參見圖1,圖1是本技術一實施例提供的兩類樣本數據出現交錯情況的示意圖。
36.圖1中圓形可表示玩家購買數據對應的樣本點,矩形表示玩家不夠買數據對應的樣本點,這兩類樣本點交錯在一起,那麼,在對玩家購買數據的樣本點進行過採樣時,就會出現新樣本點與玩家不夠買數據對應的樣本點可能出現重疊,導致了過採樣的結果不準確;比如,圖1中,與x樣本點的相鄰樣本點,分別為y1、y2和y3,利用smote過採樣方法,將x樣
本點與相鄰樣本點y1、y2和y3之間分別進行連線,在每條連接線中選取的新樣本點,即n1、n2和n3;由於圓形和矩形這兩類樣本點交錯在一起,那麼對應的新樣本點n1、n2和n3,很有可能是玩家不夠買數據的樣本點,因此,在此種情況下,過採樣處理後的結果,即使解決了數據不平衡的問題,但是已經失去了數據精準度,同樣會影響後續模型訓練的效果。
37.基於此,本技術實施例提供的模型訓練數據生成方法,利用升維算法,將玩家購買數據和玩家不夠買數據這兩類樣本數據均映射到高維度空間,以使得兩類樣本數據的線性可分性增強,再利用過採樣算法對玩家購買數據進行過採樣,不僅能夠提高過採樣新樣本的質量,還能提高後續模型訓練的效果。
38.在本技術中,提供了模型訓練數據生成方法,本技術同時涉及模型訓練數據生成裝置,一種計算設備,以及一種計算機可讀存儲介質,在下面的實施例中逐一進行詳細說明。
39.圖2示出了根據本技術一實施例提供的一種模型訓練數據生成方法的流程示意圖。
40.圖2中可先獲取到待訓練數據樣本集,其中,該待訓練數據樣本集包括第一樣本集和第二樣本集,並對每個樣本集中的待訓練數組進行升維處理,獲得高維數據樣本集,包括第一高維數組集和第二高維數組集;由於第一高維數組集的數組數量較少,可對第一高維數組集進行過採樣處理,獲得目標高維數組集;最後,目標高維數組集和第二高維數組集,組成了目標訓練數據樣本集;即可利用該目標訓練數據樣本集對模型進行訓練,提高模型訓練的效果。
41.需要說明的是,本實施例僅將升維處理和過採樣處理過程進行示意性描述,具體的處理細節可參見下述實施例的描述。
42.圖3示出了根據本技術一實施例提供的一種模型訓練數據生成方法的流程圖,具體包括以下步驟:
43.需要說明的是,本實施例提供的模型訓練數據生成方法,可應用於各類數據不平衡需要過採樣處理,解決各類數據數目平衡的應用場景,本實施例對此不做具體限定;為了便於理解,下述實施例以遊戲場景內向玩家推送禮包為例進行介紹,玩家購買禮包的數據則稱為正樣本,玩家不夠買禮包的數據則稱為負樣本,且這種正負樣本的數目不平衡。
44.步驟302:獲取目標業務的待訓練數據樣本集,其中,所述待訓練數據樣本集包括第一樣本集和第二樣本集,所述第一樣本集中待訓練數組的數量小於預設數量閾值。
45.其中,目標業務可以理解為應用場景中用戶執行某一行為對應的業務,比如遊戲應用場景中玩家購買禮包的業務等。
46.待訓練數據樣本集可以理解為用戶針對目標業務的行為數據,所組成的樣本集,比如該樣本集中包括玩家購買禮包的數據、玩家不夠買禮包的數據。
47.實際應用中,伺服器可獲取到針對目標業務的待訓練數據樣本集,其中,該待訓練數據樣本集中包括兩類數據,一類是待訓練數組的數量小於預設數量閾值,另一類是待訓練數組的數量大於等於預設數量閾值;且待訓練數組可以理解為待訓練數據樣本集中的每條數據內容,該數據內容是數組形式的數據。
48.需要說明的是,待訓練數據樣本集中的數據需要執行過採樣處理,因此,該樣本集中的數據均為數組型數據,具體的,如何將結構化數據或者非結構化數據變為數組數據的
過程,在本實施例中不做過多描述。
49.進一步地,在遊戲場景中,待訓練數據樣本集中的各個數據應該為玩家購買禮包的數據和不夠買禮包的數據;具體的,所述獲取目標業務的待訓練數據樣本集,包括:
50.獲取預設時間區間內目標遊戲中目標道具對應的玩家數據,其中,所述玩家數據包括玩家屬性信息、玩家購買所述目標道具的結果信息;
51.將所述玩家數據,確定為待訓練數據樣本集。
52.實際應用中,伺服器可獲取到預設時間區間內,各個玩家在目標遊戲中針對目標道具對應的玩家數據,該玩家數據包括玩家個人的屬性信息、玩家是否購買該目標道具的結果信息,其中,玩家個人的屬性信息包括玩家帳號等級、玩家戰力信息、玩家的鑽石數量等,玩家是否購買該目標道具的結果信息包括購買和不夠買;進而,每個玩家在該預設時間區間內的所有行為動作,均可生成玩家數據,根據多個玩家數據,就組成了待訓練數據樣本集。
53.需要說明的是,玩家在遊戲中的帳號等級、戰力、鑽石數量,是否購買道具的結果等這些特徵記錄下來後,均可處理為數值,進而各個維度的數值,組成了待訓練數組,各個待訓練數組構成了待訓練數據樣本集;其中,每個數組包含的維度個數,根據獲取到的不同維度的數據確定,本實施例中對此不做具體限定。
54.步驟304:對所述待訓練數據樣本集中的每個待訓練數組進行升維處理,獲得高維數據樣本集,其中,所述高維數據樣本集包括所述第一樣本集對應的第一高維數組集、以及所述第二樣本集對應的第二高維數組集。
55.實際應用中,為了解決待訓練數據樣本集中各類待訓練數組的數目不平衡的問題,可對各個待訓練數組進行升維處理,即將各個低維度的待訓練數組映射到高維度空間中,獲得高維數據樣本集;相應地,對待訓練數據樣本集中的第一樣本集和第二樣本集中的待訓練數組進行升維處理,獲得第一樣本集對應的第一高維數組集,第二樣本集對應的第二高維數組集,即完成了對每一類的待訓練數組進行升維處理的過程。
56.進一步地,升維處理的過程,可採用多種實現方式,本實施例中可通過在預設升維算法集合中選擇一個目標升維算法,並利用該目標升維算法對各個待訓練數組進行升維處理;具體的,所述對所述待訓練數據樣本集中的每個待訓練數組進行升維處理,獲得高維數據樣本集,包括:
57.在預設升維算法集合中,確定目標升維算法;
58.基於所述目標升維算法,對所述待訓練數據樣本集中的每個待訓練數組進行升維處理,獲得高維數據樣本集。
59.其中,目標升維算法可以理解為對待訓練數據從低維度映射到高維度的算法,包括但不限定於高斯核函數、線性核函數、多項式核函數等多種核函數算法。
60.實際應用中,伺服器可從預設升維算法集合中,選取一個目標升維算法,其選取的方式本實施例中不做限定;比如,選取了高斯核函數作為目標升維算法,即可利用高斯核函數的算法過程,對待訓練數據樣本集中的各個待訓練數組進行升維處理,進而,獲得高維數據樣本集,其中,該高維數據樣本集為多個高維數組組成的樣本集,且還分為兩類,這兩類高維數組,在數量上相差比例較大,比如第一高維數組集包含5個高維數組,第二高維數組集中包含50個高維數組。
61.更進一步地,利用目標升維算法對每個待訓練數組進行升維處理,可利用到該待訓練數據樣本集中的所有待訓練數組,即可完成對各個待訓練數組的升維過程;具體的,所述基於所述目標升維算法,對所述待訓練數據樣本集中的每個待訓練數組進行升維處理,獲得高維數據樣本集,包括:
62.在所述待訓練數據樣本集中,確定目標待訓練數組以及多個參考待訓練數組;
63.基於所述目標待訓練數組以及所述多個參考待訓練數組,根據目標升維算法進行升維處理,獲得所述目標待訓練數組對應的高維數組;
64.基於所述目標待訓練數組對應的高維數組,生成高維數據樣本集。
65.其中,目標待訓練數組可以理解為待訓練數據樣本集中的任意一個待訓練數組,參考待訓練數組可以理解為在該待訓練數據樣本集中,除了目標待訓練數組以外,其餘剩餘的所有待訓練數組;比如,待訓練數據樣本集中包括三個待訓練數組,分別為待訓練數組1、待訓練數組2和待訓練數組3,那麼在目標待訓練數組確定為待訓練數組1時,則參考待訓練數組即確定為待訓練數組2和待訓練數組3。
66.實際應用中,伺服器在待訓練數據樣本集中確定了目標待訓練數組和多個參考待訓練數組以後,可根據目標升維算法,對目標待訓練數組進行升維處理,獲得了目標待訓練數組對應的高維數組;進而,在待訓練數據樣本集中,每一個待訓練數組均作為目標待訓練數據進行升維處理,在多輪升維處理後,可獲得多個高維數組,進而構成了高維數據樣本集;需要說明的是,多輪升維過程在此不做過多贅述。
67.具體實施時,通過確定各個待訓練數組之間的數組距離,來確定各個維度上的維度參數,並根據各個維度參數確定了每個待訓練數組對應的高維數組;具體的,所述基於所述目標待訓練數組以及所述多個參考待訓練數組,根據目標升維算法進行升維處理,獲得所述目標待訓練數組對應的高維數組,包括:
68.基於所述目標待訓練數組以及所述多個參考待訓練數組,根據目標升維算法確定所述目標待訓練數組與每個參考待訓練數組之間的參考數組距離;
69.基於所述參考數組距離,獲取所述目標待訓練數組對應的參考維度參數;
70.根據所述參考維度參數以及目標維度參數,生成所述目標待訓練數組對應的高維數組,其中,所述目標維度參數基於所述目標待訓練數組確定。
71.其中,參考數組距離可以理解為目標待訓練數組與參考待訓練數組之間的數組距離,參考維度參數可以理解為從該數組距離中提取的代表某一維度的參數。
72.實際應用中,伺服器可利用目標升維算法確定目標待訓練數組與各個參考待訓練數組之間的參考數組距離;再從各個參考數組距離中,獲取組成高維數組的各個參考維度參數;然後,根據各個參考維度參數與目標維度參數,生成了該目標待訓練數組對應的高維數組,其中,目標維度參數是指目標待訓練數組與自己本身的參考數組距離,即距離為0,則獲取到的維度參數也為0。
73.例如,目標升維算法為高斯核函數算法,可參考下述公式1計算參考數組距離:
[0074][0075]
若目標待訓練數組為[1,1],參考待訓練數組1為[2,1],參考待訓練數組2為[3,1]的情況下,利用上述公式1,計算k(xi,xj)
11
、k(xi,xj)
12
、k(xi,xj)
13
,其中,下角標
11
表示目標
待訓練數組與自己本身之間的參考數組距離,下角標
12
表示目標待訓練數組與參考待訓練數組1之間的參考數組距離,下角標
13
表示目標待訓練數組與參考待訓練數組2之間的參考數組距離;進一步地,在k(xi,xj)
11
中確定目標維度參數為0,在k(xi,xj)
12
中確定參考維度參數1為1,在k(xi,xj)
13
中確定參考維度參數2為2,那麼,目標待訓練數組對應的高維數組記作[0,1,2]。
[0076]
通過對各個待訓練數組進行升維處理,可獲得高維度的數組集合,通過將低維度的數組映射為高維度的數組,即增強了數組的可分性。
[0077]
步驟306:對所述第一高維數組集進行過採樣處理,獲得目標高維數組集,其中,所述目標高維數組集中的高維數組的數量滿足所述預設數量閾值。
[0078]
實際應用中,為了解決兩類高維數組之間數目不平衡的問題,可直接對數目小於預設數量閾值的第一高維數組集進行過採樣處理,以獲得目標高維數組集,且使得目標高維數組集中的高維數組的數量需要滿足預設數量閾值,即等於或大於預設數量閾值。
[0079]
進一步地,所述對所述第一高維數組集進行過採樣處理,獲得目標高維數組集,包括:
[0080]
在預設過採樣算法集合中,確定目標過採樣算法;
[0081]
基於所述目標過採樣算法,對所述第一高維數組集進行過採樣處理,獲得目標高維數組集。
[0082]
其中,預設過採樣算法集合可以理解為可進行過採樣處理的算法集合,包括smote算法,kmeans smote算法、svm smote算法等,本實施例對此不做具體限定;目標過採樣算法可以理解為從該過採樣算法集合中選取的目標過採樣算法,比如選取smote算法,本實施例中對此也不做過多限定。
[0083]
實際應用中,伺服器可利用選取的目標過採樣算法,對第一高維數組集中的各個高維數組進行過採樣處理,以擴充第一高維數組集中高維數組的數量,進而,獲得目標高維數組集。
[0084]
具體的,所述基於所述目標過採樣算法,對所述第一高維數組集進行過採樣處理,獲得目標高維數組集,包括:
[0085]
在所述第一高維數組集中,確定待處理高維數組;
[0086]
基於所述待處理高維數組,確定與所述待處理高維數組具有關聯關係的多個相鄰高維數組;
[0087]
基於所述待處理高維數組、以及所述多個相鄰高維數組進行過採樣處理,獲得所述待處理高維數組對應的候選高維數組;
[0088]
基於所述候選高維數組,生成目標高維數組集。
[0089]
其中,待處理高維數組可以理解為第一高維數組集中任意一個高維數組。
[0090]
實際應用中,在確定了待處理高維數組之後,可確定與該待處理高維數組具有關聯關係的多個相鄰高維數組,其中,該關聯關係可以理解為數組映射在維度空間中的相鄰距離關係,本實施例對此不做具體限定;進一步地,根據待處理高維數組以及各個相鄰高維數組,執行過採樣的處理過程,進而,獲得待處理高維數組對應的多個候選高維數組,將該多個候選高維數組作為過採樣處理後的新樣本數組,並根據各個候選高維數組、待處理高維數組、以及多個相鄰高維數組,構成了目標高維數組子集;最後,在第一高維數組集中的
各個高維數組作為待處理高維數組進行過採樣之後,可分別獲得對應的多個候選高維數組,進而,將所有的候選高維數組作為第一高維數組集的擴充高維數組,以獲得目標高維數組集。
[0091]
通過將第一高維數組集中的每個高維數組作為待處理高維數組,進行上述過採樣處理後,均可獲得一批新的數組樣本,進而,擴展了第一高維數組集的數量,生成目標高維數組集。
[0092]
進一步地,所述基於所述待處理高維數組、以及所述多個相鄰高維數組進行過採樣處理,獲得所述待處理高維數組對應的候選高維數組,包括:
[0093]
確定所述待處理高維數組對應的待處理坐標點,確定每個相鄰高維數組對應的相鄰坐標點;
[0094]
將所述待處理坐標點與每個相鄰坐標點之間進行直線連接,獲得多個相鄰連接線;
[0095]
基於預設比例因子,在所述多個相鄰連接線中確定候選坐標點,並將所述候選坐標點對應的高維數組,確定為候選高維數組。
[0096]
實際應用中,伺服器可根據待處理高維數組映射在維度空間中獲得待處理坐標點,同樣地,相鄰高維數組也可進行映射處理獲得相鄰坐標點;然後,將待處理坐標點與每個相鄰坐標點之間進行連線,獲得多個相鄰連接的直線;再根據預設比例因子,在各條相鄰連接線上確定對應的候選坐標點;最後,將候選坐標點對應的高維數組確定為候選高維數組;需要說明的是,預設比例因子為過採樣算法中,隨機選擇[0,1]範圍的縮放因子,根據該縮放因子,確定在相鄰連接線上放置的新點,以作為新的樣本點,並將該信的樣本點對應的高維數組,確定為候選高維數組。
[0097]
參見圖4,圖4示出了本技術一實施例提供的一種模型訓練數據生成方法的過採樣示意圖。
[0098]
圖4中所顯示的為兩類高維數組集,圓形表示玩家購買數據對應的高維數組集,矩形表示玩家不夠買數據對應的高維數組集,那麼,在x為待處理高維數組時,其相鄰的多個相鄰高維數組可為y1、y2和y3,在x分別與y1、y2和y3之間進行直線連接後,根據隨機選擇[0,1]範圍的縮放因子z,可在每條直線的(z*100)%處放置一個新點,作為候選坐標點n1、n2和n3,即玩家購買數據的新樣本,此時,n1、n2和n3中對應的高維數組也不會與矩形表示的高維數組有重合的部分,保證了過採樣後的結果的準確性。
[0099]
通過對第一高維數組集中的高維數組進行過採樣處理,能夠更加準確地獲得新的樣本點,提高了目標高維數組集中數據的精準度。
[0100]
步驟308:基於所述目標高維數組集和所述第二高維數組集,確定所述目標業務的目標訓練數據樣本集。
[0101]
實際應用中,在對少類的數組數據進行過採樣處理後,在與第二高維數組集進行結合,以獲得針對目標業務的目標訓練數據樣本集,進而,實現了目標訓練數據樣本集中各類數組數據的不平衡問題,同時精準度也有所提高。
[0102]
此外,本技術實施例還提供了利用目標訓練數據樣本集,對初始業務模型進行訓練的過程;具體的,所述基於所述目標高維數組集和所述第二高維數組集,確定所述目標業務的目標訓練數據樣本集之後,還包括:
[0103]
基於所述目標訓練數據樣本集,對初始業務模型進行訓練,獲得目標業務模型。
[0104]
實際應用中,對初始業務模型的類型不做具體限定,可以為玩家購買禮包的預測模型、玩家行為的分析模型等;均可利用該目標訓練數據樣本集,對該初始業務模型進行多輪迭代訓練,以獲得目標業務模型。
[0105]
綜上,本技術實施例提供的模型訓練數據生成方法,通過將升維算法與過採樣算法進行結合,將可分性不強的低維數組數據處理為高維數組數據,進而在提高了可分性之後,再對少數類的樣本進行過採樣處理,能夠提高新樣本的質量,以提高最終的模型訓練效果。
[0106]
與上述方法實施例相對應,本技術還提供了模型訓練數據生成裝置實施例,圖5示出了本技術一實施例提供的一種模型訓練數據生成裝置的結構示意圖。如圖5所示,該裝置包括:
[0107]
樣本集獲取模塊502,被配置為獲取目標業務的待訓練數據樣本集,其中,所述待訓練數據樣本集包括第一樣本集和第二樣本集,所述第一樣本集中待訓練數組的數量小於預設數量閾值;
[0108]
升維處理模塊504,被配置為對所述待訓練數據樣本集中的每個待訓練數組進行升維處理,獲得高維數據樣本集,其中,所述高維數據樣本集包括所述第一樣本集對應的第一高維數組集、以及所述第二樣本集對應的第二高維數組集;
[0109]
過採樣處理模塊506,被配置為對所述第一高維數組集進行過採樣處理,獲得目標高維數組集,其中,所述目標高維數組集中的高維數組的數量滿足所述預設數量閾值;
[0110]
樣本集確定模塊508,被配置為基於所述目標高維數組集和所述第二高維數組集,確定所述目標業務的目標訓練數據樣本集。
[0111]
可選地,所述升維處理模塊504,進一步被配置為:
[0112]
在預設升維算法集合中,確定目標升維算法;
[0113]
基於所述目標升維算法,對所述待訓練數據樣本集中的每個待訓練數組進行升維處理,獲得高維數據樣本集。
[0114]
可選地,所述升維處理模塊504,進一步被配置為:
[0115]
在所述待訓練數據樣本集中,確定目標待訓練數組以及多個參考待訓練數組;
[0116]
基於所述目標待訓練數組以及所述多個參考待訓練數組,根據目標升維算法進行升維處理,獲得所述目標待訓練數組對應的高維數組;
[0117]
基於所述目標待訓練數組對應的高維數組,生成高維數據樣本集。
[0118]
可選地,所述升維處理模塊504,進一步被配置為:
[0119]
基於所述目標待訓練數組以及所述多個參考待訓練數組,根據目標升維算法確定所述目標待訓練數組與每個參考待訓練數組之間的參考數組距離;
[0120]
基於所述參考數組距離,獲取所述目標待訓練數組對應的參考維度參數;
[0121]
根據所述參考維度參數以及目標維度參數,生成所述目標待訓練數組對應的高維數組,其中,所述目標維度參數基於所述目標待訓練數組確定。
[0122]
可選地,所述過採樣處理模塊506,進一步被配置為:
[0123]
在預設過採樣算法集合中,確定目標過採樣算法;
[0124]
基於所述目標過採樣算法,對所述第一高維數組集進行過採樣處理,獲得目標高
telephone network)、區域網(lan,local area network)、廣域網(wan,wide area network)、個域網(pan,personal area network)或諸如網際網路的通信網絡的組合。接入設備640可以包括有線或無線的任何類型的網絡接口(例如,網絡接口卡(nic,network interface controller))中的一個或多個,諸如ieee802.11無線區域網(wlan,wireless local area network)無線接口、全球微波互聯接入(wi-max,worldwide interoperability for microwave access)接口、乙太網接口、通用串行總線(usb,universal serial bus)接口、蜂窩網絡接口、藍牙接口、近場通信(nfc,near field communication)接口,等等。
[0143]
在本技術的一個實施例中,計算設備600的上述部件以及圖6中未示出的其他部件也可以彼此相連接,例如通過總線。應當理解,圖6所示的計算設備結構框圖僅僅是出於示例的目的,而不是對本技術範圍的限制。本領域技術人員可以根據需要,增添或替換其他部件。
[0144]
計算設備600可以是任何類型的靜止或移動計算設備,包括移動計算機或移動計算設備(例如,平板計算機、個人數字助理、膝上型計算機、筆記本計算機、上網本等)、行動電話(例如,智慧型手機)、可佩戴的計算設備(例如,智能手錶、智能眼鏡等)或其他類型的行動裝置,或者諸如臺式計算機或個人計算機(pc,personal computer)的靜止計算設備。計算設備600還可以是移動式或靜止式的伺服器。
[0145]
其中,處理器620執行所述計算機指令時實現所述的模型訓練數據生成方法的步驟。
[0146]
上述為本實施例的一種計算設備的示意性方案。需要說明的是,該計算設備的技術方案與上述的模型訓練數據生成方法的技術方案屬於同一構思,計算設備的技術方案未詳細描述的細節內容,均可以參見上述模型訓練數據生成法的技術方案的描述。
[0147]
本技術一實施例還提供一種計算機可讀存儲介質,其存儲有計算機指令,該計算機指令被處理器執行時實現如前所述模型訓練數據生成方法的步驟。
[0148]
上述為本實施例的一種計算機可讀存儲介質的示意性方案。需要說明的是,該存儲介質的技術方案與上述的模型訓練數據生成方法的技術方案屬於同一構思,存儲介質的技術方案未詳細描述的細節內容,均可以參見上述模型訓練數據生成方法的技術方案的描述。
[0149]
上述對本技術特定實施例進行了描述。其它實施例在所附權利要求書的範圍內。在一些情況下,在權利要求書中記載的動作或步驟可以按照不同於實施例中的順序來執行並且仍然可以實現期望的結果。另外,在附圖中描繪的過程不一定要求示出的特定順序或者連續順序才能實現期望的結果。在某些實施方式中,多任務處理和並行處理也是可以的或者可能是有利的。
[0150]
所述計算機指令包括電腦程式代碼,所述電腦程式代碼可以為原始碼形式、對象代碼形式、可執行文件或某些中間形式等。所述計算機可讀介質可以包括:能夠攜帶所述電腦程式代碼的任何實體或裝置、記錄介質、u盤、移動硬碟、磁碟、光碟、計算機存儲器、只讀存儲器(rom,read-only memory)、隨機存取存儲器(ram,random access memory)、電載波信號、電信信號以及軟體分發介質等。需要說明的是,所述計算機可讀介質包含的內容可以根據司法管轄區內立法和專利實踐的要求進行適當的增減,例如在某些司法管轄
區,根據立法和專利實踐,計算機可讀介質不包括電載波信號和電信信號。
[0151]
需要說明的是,對於前述的各方法實施例,為了簡便描述,故將其都表述為一系列的動作組合,但是本領域技術人員應該知悉,本技術並不受所描述的動作順序的限制,因為依據本技術,某些步驟可以採用其它順序或者同時進行。其次,本領域技術人員也應該知悉,說明書中所描述的實施例均屬於優選實施例,所涉及的動作和模塊並不一定都是本技術所必須的。
[0152]
在上述實施例中,對各個實施例的描述都各有側重,某個實施例中沒有詳述的部分,可以參見其它實施例的相關描述。
[0153]
以上公開的本技術優選實施例只是用於幫助闡述本技術。可選實施例並沒有詳盡敘述所有的細節,也不限制該發明僅為所述的具體實施方式。顯然,根據本技術的內容,可作很多的修改和變化。本技術選取並具體描述這些實施例,是為了更好地解釋本技術的原理和實際應用,從而使所屬技術領域技術人員能很好地理解和利用本技術。本技術僅受權利要求書及其全部範圍和等效物的限制。