一種基於稀疏重構的單樣本人臉識別方法與流程
2023-05-26 00:16:51 4
本發明屬於生物特徵認證領域,涉及一種基於稀疏重構的單樣本人臉識別方法。
背景技術:
人臉識別技術作為一種新型的身份驗證技術,通過攝像頭採集圖像,經算法處理,與人臉資料庫進行比對,實現對人的鑑定識別。由於其在執法、銀行和海關的安全監控以及人機互動等場景中具有很高的應用前景,人臉識別技術已成為身份識別與驗證等領域的研究熱點。然而實際應用時,人臉資料庫中往往只有1幅訓練圖像,這使得在這些場合中使用傳統人臉識別技術並不能取得很好的識別效果,限制了人臉識別的應用範圍。所以對單訓練樣本條件下人臉識別技術的特別研究,已成為目前人臉識別領域研究的熱點。
人臉識別的識別率是人臉識別技術的核心指標,而現有的許多人臉識別算法在單訓練樣本條件下識別率會急劇下降有些甚至無法應用。為此如何在單訓練樣本條件下提高人臉識別的識別率是實際應用中面臨的問題之一。近年來對單樣本人臉識別的研究分為兩類:一類是無監督學習方法;另一類是有監督學習方法。李欣等人提出多模塊加權的改進(2d)2pca算法,這種方法在orl和cas-peal資料庫上取得了好於2dpca及2d2pca的識別率。王科俊等人李欣的基礎上提出融合全局與局部特徵的人臉識別方法,此方法在orl資料庫上也取得了不錯的實驗效果,同時其實驗結果表明分塊gabor特徵具有較好的分類能力,單獨基於gabor局部特徵的識別率就可以達到86.94%。kan等人提出將多個人臉樣本的通用數據輔助構造註冊集中單樣本人臉的類內散度矩陣的算法,該方法在feret數據集的fafb取得了90.1%的識別率,與gabor特徵進行結合後達到了98.1%的識別率。但在自然條件下,在人臉圖像拍攝時的角度、光照、遮擋以及設備帶來的噪聲等因素時,僅僅通過滑動窗口、位平面、重採樣和鏡像變換的方法對原始訓練樣本進行圖像處理得到虛擬樣本的方法並不能很好地解決噪聲等帶來的影響,現有的很多算法識別率都有所下降。
技術實現要素:
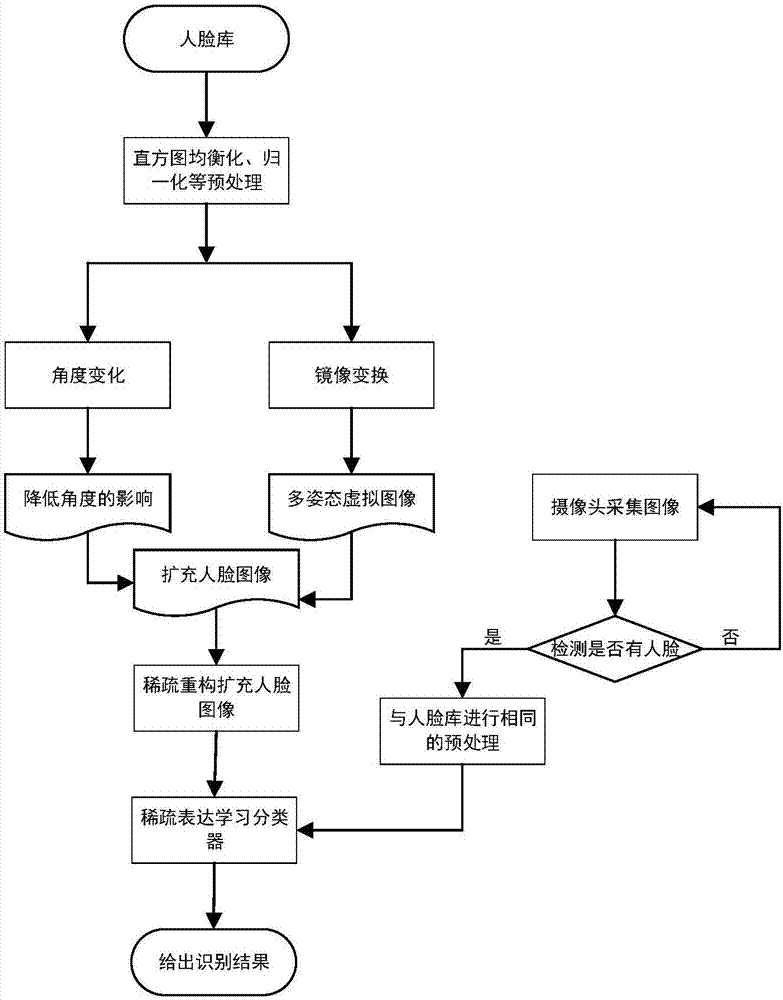
本發明針對自然條件下單樣本人臉圖像的識別問題,提出一種基於稀疏重構的單樣本人臉識別方法。基本思路是首先構建人臉資料庫,對人臉圖像進行預處理,然後通過圖像幾何變換技術擴充人臉資料庫,再利用稀疏重構技術進一步擴充人臉資料庫,最後利用稀疏表達學習分類器,對待識別的人臉圖像進行識別。本方法能夠更為有效而充分地處理自然條件下的單樣本人臉圖像的識別問題,抑制噪聲和遮擋帶來的影響,提高了人臉圖像的識別率。
技術方案:一種基於單樣本的人臉識別方法,包含以下步驟:
步驟一:通過攝像頭採集圖像,構建人臉資料庫;
步驟二:對採集到的人臉圖像進行預處理;
步驟三:通過圖像幾何變換技術擴充人臉資料庫;
步驟四:利用稀疏重構技術進一步擴充人臉資料庫;
步驟五:對攝像頭採集到的圖像進行人臉檢測;
步驟六:對人臉圖像進行與步驟二相同的預處理;
步驟七:利用稀疏表達學習分類器,對待識別的人臉圖像進行識別;
與現有的單樣本人臉識別算法相比,本發明充分利用稀疏重構技術構建虛擬人臉圖像,一方面擴充了人臉資料庫,解決了單樣本問題,另一方面抑制了噪聲和遮擋對圖像識別的影響,提高了單訓練樣本條件下人臉識別的識別率。
附圖說明
圖1為本發明具體實施流程圖;
圖2為角度變換得到的擴充人臉圖像;
圖3為鏡像變換的四種組合方式;
圖4為鏡像變換得到的擴充人臉圖像;
圖5為對概率進行降序累加的過程示意圖;
圖6為利用處理後的3組和字典di虛擬生成圖像。
具體實施方式
下面結合說明書附圖進一步闡明本發明,應理解這些實施例僅用於說明本發明而不用於限制本發明的範圍,在閱讀了本發明之後,本領域技術人員對本發明的各種等價形式的修改均落於本申請所附權利要求所限定的範圍。
如圖1所示,本發明的實施主要包含四個步驟:(1)人臉圖像預處理;(2)對圖像進行角度和鏡像變換擴充人臉庫;(3)利用稀疏重構技術進一步擴充人臉庫;(4)利用稀疏表達學習分類器,對檢測到的人臉圖像進行識別,並輸出識別結果。
步驟一:通過攝像頭採集圖像,構建人臉資料庫;
使用高清攝像頭對用戶進行人臉圖像採集,構成n個用戶的單人臉資料庫x11、x21、x31……xn1。
步驟二:預處理;
由於採集到的自然場景下的人臉圖像與預期樣本存在很大差別,存在光照不均勻等因素幹擾,所以對步驟一中採集到的人臉樣本進行預處理,主要包括人臉圖像的直方圖均衡化、歸一化等;
步驟三:通過圖像幾何變換技術擴充人臉圖像庫;
①角度變換:如圖2所示,以原圖像xi1為基準,旋轉角度θ=0.2×m(m為整數,且-4≤m≤4),得到的圖像依次記為xi2~xi9。
②鏡像變換:如圖3所示,將原圖像左右平均分為a、b兩部分,將a通過鏡像得到a',b通過鏡像得到b',然後將a、b、a'、b'組合生成圖像aa'、bb'、b'a',依次記為xi10~xi12。圖4為通過鏡像變換得到的
虛擬圖像xi10~xi12。
步驟四:利用稀疏重構技術進一步擴充人臉圖像庫;
①將步驟三得到的第i個擴充人臉圖像作為字典di,即xi2~xi12,通過求解以下稀疏優化問題計算第i個用戶原圖的稀疏表達係數αi:
其中xi1表示原圖像,λ表示平衡係數
②得到n個用戶的稀疏表達係數αi。對於每一個用戶的稀疏表達係數αi,都有11個特徵值分別對應字典di中的xi2~xi12;
③對於第i個用戶人臉圖像,將11個稀疏表達係數求和記為對每一個稀疏表達係數求概率記為
將得到的概率進行降序排列(保證所對應的xi(j+1)不變),從左到右依次記為p1,p2,...,p11,再對排列後的pk進行累加記為具體操作如圖5所示;
④分別取閾值為85%、90%、95%三個值,當達到所取閾值時,停止累加,並記錄此時的k值,找到pk+1,...,p11所對應的概率和並令對應的其他值保持不變,得到處理後的係數取不同的閾值時即可得到3組不同的處理後係數
⑤利用處理後的3組和字典di虛擬生成圖像y',記為xi13~xi15;
步驟五:對攝像頭採集到的圖像進行人臉檢測;
接下來進行人臉識別過程,使用高清攝像頭拍攝,並對拍攝到的畫面進行人臉檢測,如果沒有檢測到人臉,給出提示。
步驟六:對人臉圖像進行與步驟二相同的預處理,處理後的圖像記為y;
包括人臉圖像的直方圖均衡化、歸一化等。
步驟七:利用稀疏表達學習分類器,對待識別的人臉圖像進行識別;
①由擴充後的第i個人臉圖像組成字典hi,即xi1~xi15。利用如下優化問題得到預處理後的圖像y在字典hi的稀疏表達:
得到稀疏表達係數wi;
②計算圖像y在稀疏表達係數wi下的偏差εi;
③獲得圖像y在用不同字典hi下的偏差εi後,尋找最小值,輸出最小值對應的下標i,即為識別的類別或對應的用戶。