一種對話控制方法、裝置及機器人與流程
2023-12-04 17:58:56 3
本發明涉及通信領域,更具體的說,涉及一種對話控制方法、裝置及機器人。
背景技術:
隨著科學技術的不斷發展,在機器人領域的研究不斷深入。其中,機器人(robot)是自動執行工作的機器裝置。它既可以接受人類指揮,又可以運行預先編排的程序,也可以根據以人工智慧技術制定的原則綱領行動。它的任務是協助或取代人類工作的工作,例如生產業、建築業,或是危險的工作。
現在已經能夠實現人與機器人的中文的溝通交流,具體的,採集用戶輸入的中文語音,並針對該中文語音進行回復,但是現在僅能夠實現人與機器人的中文的溝通交流,會導致人與機器人的溝通交流方式單一。
技術實現要素:
有鑑於此,本發明提供一種對話控制方法、裝置及機器人,以解決現在僅能夠實現人與機器人的中文的溝通交流,會導致人與機器人的溝通交流方式單一的問題。
為解決上述技術問題,本發明採用了如下技術方案:
一種對話控制方法,應用於機器人,包括:
採集用戶輸入的語音;其中,所述語音為任一語種的語音;
對所述語音進行語音識別,得到所述語音對應的多個字符串;
基於多個所述字符串確定所述語音對應的語種,並查找與多個所述字符串對應的回答消息;其中,所述回答消息的語種與所述語音的語種相同;
輸出所述回答消息。
優選地,對所述語音進行語音識別,得到所述語音對應的多個字符串,包括:
根據所述語音中的靜音點,將所述語音拆分得到多個有效語音;
查詢與每個所述有效語音對應的所述字符串,得到所述語音對應的多個字符串。
優選地,查找與多個所述字符串對應的回答消息,包括:
將多個所述字符串翻譯成中文短句;
採用匹配算法,查找與所述中文短句相匹配的中文回答消息;
將所述中文回答消息翻譯成所述回答消息。
優選地,輸出所述回答消息包括:
將所述回答消息顯示在所述機器人的顯示屏幕上;
和/或,將所述回答消息語音輸出。
優選地,採集用戶輸入的語音後,還包括:
對所述語音進行降噪處理,得到降噪後的語音;
相應的,對所述語音進行語音識別,得到所述語音對應的多個字符串,具體包括:
對所述降噪後的語音進行語音識別,得到所述降噪後的語音對應的多個字符串。
一種對話控制裝置,應用於機器人,包括:
語音採集模塊,用於採集用戶輸入的語音;其中,所述語音為任一語種的語音;
語音識別模塊,用於對所述語音進行語音識別,得到所述語音對應的多個字符串;
語種確定模塊,用於基於多個所述字符串確定所述語音對應的語種;
查找模塊,用於查找與多個所述字符串對應的回答消息;其中,所述回答消息的語種與所述語音的語種相同;
語音輸出模塊,用於輸出所述回答消息。
優選地,所述語音識別模塊包括:
拆分子模塊,用於根據所述語音中的靜音點,將所述語音拆分得到多個有效語音;
查詢子模塊,用於查詢與每個所述有效語音對應的所述字符串,得到所述語音對應的多個字符串。
優選地,所述查找模塊包括:
第一翻譯子模塊,用於將多個所述字符串翻譯成中文短句;
匹配查找子模塊,用於採用匹配算法,查找與所述中文短句相匹配的中文回答消息;
第二翻譯子模塊,用於將所述中文回答消息翻譯成所述回答消息。
優選地,還包括:
降噪處理模塊,用於所述語音採集模塊採集用戶輸入的語音後,對所述語音進行降噪處理,得到降噪後的語音;
相應的,所述語音識別模塊用於對所述語音進行語音識別,得到所述語音對應的多個字符串時,具體用於:
對所述降噪後的語音進行語音識別,得到所述降噪後的語音對應的多個字符串。
一種機器人,包括:語音採集模塊、處理器和語音輸出模塊;
其中,所述語音採集模塊,用於採集用戶輸入的語音;其中,所述語音為任一語種的語音;
所述處理器,用於對所述語音進行語音識別,得到所述語音對應的多個字符串,以及基於多個所述字符串確定所述語音對應的語種,並查找與多個所述字符串對應的回答消息;其中,所述回答消息的語種與所述語音的語種相同;
所述語音輸出模塊,用於輸出所述回答消息。
相較於現有技術,本發明具有以下有益效果:
本發明提供了一種對話控制方法、裝置及機器人,本發明中通過採集用戶輸入的語音,對所述語音進行語音識別,得到所述語音對應的多個字符串,基於多個所述字符串確定所述語音對應的語種,並查找與多個所述字符串對應的回答消息以及輸出所述回答消息的方式來實現人與機器人的多語種的溝通交流,進而使人與機器人的溝通交流方式更豐富。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的實施例,對於本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據提供的附圖獲得其他的附圖。
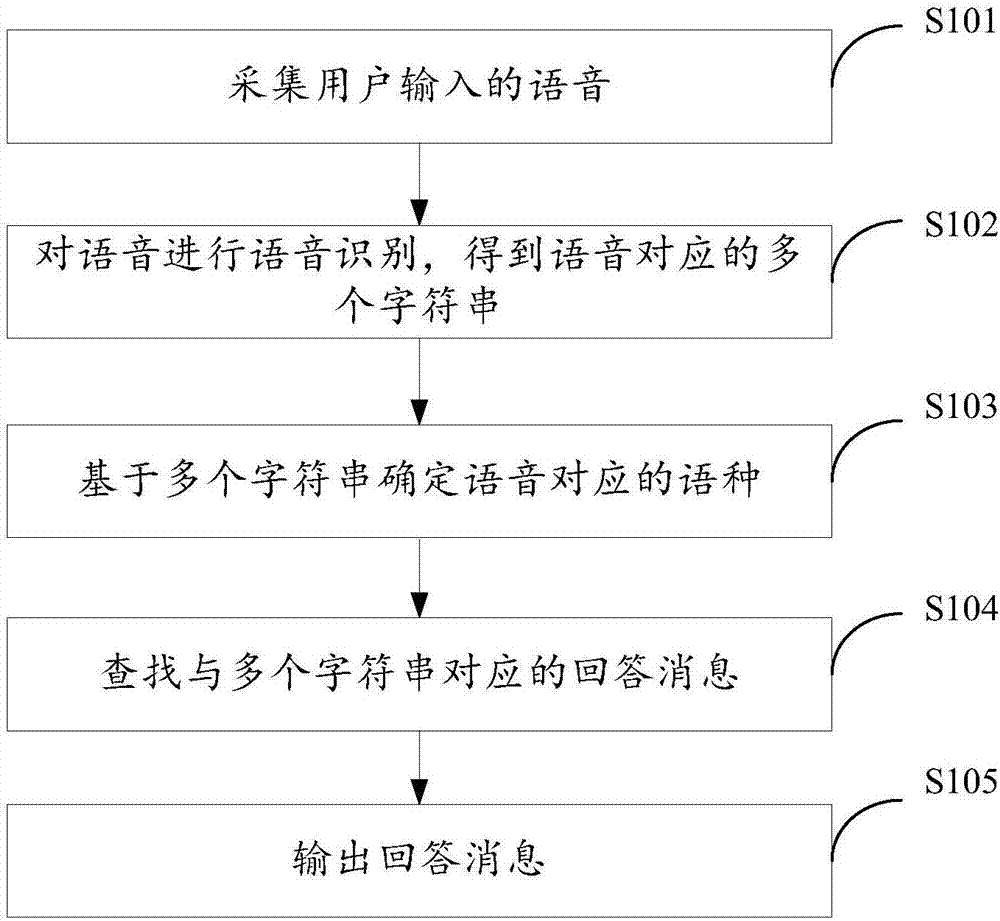
圖1為本發明提供的一種對話控制方法的方法流程圖;
圖2為本發明提供的另一種對話控制方法的方法流程圖;
圖3為本發明提供的一種對話控制裝置的結構示意圖;
圖4為本發明提供的另一種對話控制裝置的結構示意圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。基於本發明中的實施例,本領域普通技術人員在沒有做出創造性勞動前提下所獲得的所有其他實施例,都屬於本發明保護的範圍。
本發明實施例提供了一種對話控制方法,應用於機器人,包括:
s101、採集用戶輸入的語音;
其中,所述語音為任一語種的語音,語種可以包括英語、俄語、西班牙等語種。
其中,用戶為與機器人進行溝通交流的人員,用戶輸入的語音可以為英文語音。
需要說明的是,可選的,在本實施例的基礎上,採集用戶輸入的語音後,對語音進行降噪處理,得到降噪後的語音。
其中,用戶在輸入語音時,機器人的語音採集裝置可能會採集到雜音,此時可以使用降噪處理方法對雜音進行降噪處理,其中,降噪處理可以採用採樣除燥法、噪聲門等方式。
對語音進行降噪處理,能夠去除雜音對採集的語音的影響。
s102、對語音進行語音識別,得到語音對應的多個字符串;
其中,語音識別是將語音轉換成字符串的過程。需要說明的是,得到語音對應的多個字符串後,可以將得到的多個字符串顯示在顯示屏幕上,即用戶界面ui上。
需要說明的是,當採集用戶輸入的語音後,對語音進行降噪處理,得到降噪後的語音後,本步驟就相應的更改為:
對降噪後的語音進行語音識別,得到降噪後的語音對應的多個字符串。
可選的,在本實施例的基礎上,步驟s102包括:
1)根據語音中的靜音點,將語音拆分得到多個有效語音;
其中,由於用戶在說出語音時,中間會有停頓,所以會出現靜音點,靜音點的地方是沒有用戶輸入的語音的,即靜音點的地方為無效語音。
進而,就可以根據語音中的靜音點,將語音拆分得到多個有效語音。其中,有效語音是指包含用戶輸入的有效的語音。
2)查詢與每個有效語音對應的字符串,得到語音對應的多個字符串。
具體的,根據預先存儲的多個語音與字符串的對應關係,查找與每個有效語音對應的字符串,得到語音對應的多個字符串。
需要說明的一點是,在查詢與每個有效語音對應的字符串時,應該參考前後有效語音查詢得到的字符串的識別結果來提高查詢與每個有效語音對應的字符串的準確度。
本實施例中,將語音轉換成字符串是因為查找字符串對應的回答消息的準確度高於直接查找語音對應的回答消息的準確度。
s103、基於多個所述字符串確定所述語音對應的語種;
具體的,得到多個字符串後,每個字符串在進行保存時,是以一串數字的形式進行保存,如01110,查看每個字符串對應的數字所屬的標準代碼,其中,標準代碼包括美國信息交換標準代碼ascii碼、unicode碼等。
將得到的每個字符串對應的標準代碼確定出來之後,由於每種語言對應的標準代碼是不同的,進而就能夠得到多個字符串對應的語種。
需要說明的是,上述確定語種的方法適用於用戶的語音為同一種語種,如:如用戶說的是英語或者是日語,上述確定語種的方法不適用於混合語音,如中英混合,i去吃飯了,即為中英文混合,在這種情況下,只要是確定有中文,就認為用戶說的是漢語。
s104、查找與多個字符串對應的回答消息;其中,所述回答消息的語種與所述語音的語種相同;
其中,已經預先存儲了多個不同的一串字符串對應的回答消息,此時只需要查找與本方案中的多個字符串對應的回答消息即可。
s105、輸出回答消息。
可選的,在本實施例的基礎上,步驟s105具體包括:
將回答消息顯示在機器人的顯示屏幕上,和/或,將回答消息語音輸出。
具體的,將回答消息顯示在機器人的顯示屏幕上,即將回答消息顯示在機器人的ui上。
此外,將回答消息語音輸出,具體包括:
將回答消息分割成多個發音單位,為每個發音單位匹配一個音頻數據,最後將多個音頻數據進行組合,得到一段音頻數據,進而將一段音頻數據輸出即可。可選的,可以通過機器人的麥克風輸出。
本實施例中,通過採集用戶輸入的語音,對語音進行語音識別,得到語音對應的多個字符串,基於多個所述字符串確定所述語音對應的語種,並查找與多個字符串對應的回答消息以及輸出回答消息的方式來實現人與機器人的多語種的溝通交流,進而使人與機器人的溝通交流方式更豐富。
可選的,在上述任一實施例的基礎上,參照圖2,步驟s104包括:
s201、將多個字符串翻譯成中文短句;
具體的,將每個字符串通過機器人內置的翻譯引擎翻譯成中文詞組,再將得到的多個中文詞組按照字符串的排列順序進行組合,得到中文短句。
其中,在將得到的多個中文詞組按照字符串的排列順序進行組合時,可以根據中文詞組的前後中文詞組的組合方式,適當性的調整每個字符串翻譯得到的中文詞組,使其得到的中文短句更通順。
s202、採用匹配算法,查找與中文短句相匹配的中文回答消息;
具體的,資料庫中保存有成對、一對多或者多對一的對話語句,其中,對話短句包含用戶問句和資料庫問句,將得到的中文短句與每個用戶問句、資料庫問句進行匹配,將匹配度最高的用戶問句或者是資料庫問句作為與中文短句相匹配的問題,進而查找與匹配度最高的用戶問句或者是資料庫問句相對應的答案即可,相應的答案即為與中文短句相匹配的中文回答消息。
s203、將中文回答消息翻譯成回答消息。
具體的,通過機器人內置的翻譯引擎,將中文回答消息翻譯成回答消息即可。
本實施例中,可以通過將字符串翻譯成中文短句,查找與中文短句相匹配的中文回答消息,並通過翻譯中文回答消息的方式來得到回答消息。
可選的,本發明的另一實施例中提供了一種對話控制裝置,應用於機器人,包括:
語音採集模塊101,用於採集用戶輸入的語音;其中,所述語音為任一語種的語音;
語音識別模塊102,用於對所述語音進行語音識別,得到所述語音對應的多個字符串;
語種確定模塊103,用於基於多個所述字符串確定所述語音對應的語種;
查找模塊104,用於查找與多個所述字符串對應的回答消息;其中,所述回答消息的語種與所述語音的語種相同;
語音輸出模塊105,用於輸出所述回答消息。
可選的,進一步,所述語音識別模塊102包括:
拆分子模塊,用於根據所述語音中的靜音點,將所述語音拆分得到多個有效語音;
查詢子模塊,用於查詢與每個所述有效語音對應的所述字符串,得到所述語音對應的多個字符串。
可選的,進一步,還包括:
降噪處理模塊,用於所述語音採集模塊101採集用戶輸入的語音後,對所述語音進行降噪處理,得到降噪後的語音;
相應的,所述語音識別模塊102用於對所述語音進行語音識別,得到所述語音對應的多個字符串時,具體用於:
對所述降噪後的語音進行語音識別,得到所述降噪後的語音對應的多個字符串。
可選的,進一步,所述語音輸出模塊105用於輸出所述回答消息時,具體用於:
將所述回答消息顯示在所述機器人的顯示屏幕上;
和/或,將所述回答消息語音輸出。
本實施例中,通過採集用戶輸入的語音,對語音進行語音識別,得到語音對應的多個字符串,基於多個所述字符串確定所述語音對應的語種,並查找與多個字符串對應的回答消息以及輸出回答消息的方式來實現人與機器人的多語種的溝通交流,進而使人與機器人的溝通交流方式更豐富。
需要說明的是,本實施例中的各個模塊的工作過程,請參照上述實施例中的相應部分,在此不再贅述。
可選的,在圖3對應的實施例的基礎上,參照圖4,所述查找模塊104包括:
第一翻譯子模塊1041,用於將多個所述字符串翻譯成中文短句;
匹配查找子模塊1042,用於採用匹配算法,查找與所述中文短句相匹配的中文回答消息;
第二翻譯子模塊1043,用於將所述中文回答消息翻譯成所述回答消息。
本實施例中,可以通過將字符串翻譯成中文短句,查找與中文短句相匹配的中文回答消息,並通過翻譯中文回答消息的方式來得到回答消息。
需要說明的是,本實施例中的各個模塊的工作過程,請參照上述實施例中的相應部分,在此不再贅述。
可選的,本發明的另一實施例中提供了一種機器人,包括:語音採集模塊、處理器和語音輸出模塊;
其中,所述語音採集模塊,用於採集用戶輸入的語音;其中,所述語音為任一語種的語音;
所述處理器,用於對所述語音進行語音識別,得到所述語音對應的多個字符串,以及基於多個所述字符串確定所述語音對應的語種,並查找與多個所述字符串對應的回答消息;其中,所述回答消息的語種與所述語音的語種相同;
所述語音輸出模塊,用於輸出所述回答消息。
本實施例中,通過採集用戶輸入的語音,對語音進行語音識別,得到語音對應的多個字符串,基於多個所述字符串確定所述語音對應的語種,並查找與多個字符串對應的回答消息以及輸出回答消息的方式來實現人與機器人的多語種的溝通交流,進而使人與機器人的溝通交流方式更豐富。
對所公開的實施例的上述說明,使本領域專業技術人員能夠實現或使用本發明。對這些實施例的多種修改對本領域的專業技術人員來說將是顯而易見的,本文中所定義的一般原理可以在不脫離本發明的精神或範圍的情況下,在其它實施例中實現。因此,本發明將不會被限制於本文所示的這些實施例,而是要符合與本文所公開的原理和新穎特點相一致的最寬的範圍。