一種基於語法格式的分詞檢索方法及系統與流程
2023-11-30 09:36:16 3
本發明涉及大數據檢索領域,具體涉及一種基於語法格式的分詞檢索方法及系統。
背景技術:
隨著網際網路行業的飛速發展,網際網路上的文本規模越來越大,信息資源也不斷增加,冗餘信息量也隨之增加,導致從海量數據中獲取有價值信息的難度增加,用戶感興趣的信息容易淹沒在大量的冗餘信息中。
為了海量數據中獲取有價值的信息,通常需要對自然語言進行處理,進而將與檢索詞相匹配的的結果按一定的順序排列,即相關度排列,不同搜尋引擎對文本索引方案不相同,導致檢索結果也各不相同。
當下比較流行的一些索引方案為:基於詞庫的分詞索引、基於正則表達式的分詞索引、基於空格等特殊字符的分詞索引以及一些自定義分詞索引。其中基於詞庫的分詞索引是目前搜尋引擎中應用最為廣泛、分詞檢索效果最好的方案,比如Apache Lucene(Apache旗下的一款開源全文檢索項目),Apache Solr(Apache旗下的一款開源全文檢索項目),ElasticSearch(一個基於Lucene的搜索伺服器。它提供了一個分布式多用戶能力的全文搜尋引擎)等。
但是基於詞庫的分詞索引在使用前,需要一個強大且充足的詞庫,否則難以得到較好的分詞、檢索效果;但是,詞庫需要實時更新和維護,需要耗費大量的人力,成本較高。
技術實現要素:
針對現有技術中存在的缺陷,本發明的目的在於提供一種基於語法格式的分詞檢索方法及系統,能夠降低更新和維護的頻率,進而降低維護成本。
為達到以上目的,本發明採取的技術方案是:
一種基於語法格式的分詞檢索方法,
根據中文語法大全定義的語法標準,將詞和詞組進行分類並建立語法分詞資料庫,所述語法標準包括詞組的構詞規則和構形規則,所述構詞規則根據中文語法中的詞性定義中心詞和無意義詞;所述構形規則定義詞組的文序;
從用戶的檢索詞中篩選出含有中心詞且符合構詞規則的詞組,將篩選出的詞組中無意義的詞去除後索引分詞結果。
在上述技術方案的基礎上,從用戶的檢索詞中篩選出含有中心詞且符合構詞規則的詞組具體包括以下步驟:判斷檢索詞是否包含中心詞,將包含中心詞的檢索詞作為潛在語法文本;
以潛在語法文本中的中心詞為中心,按照構形規則將潛在語法文本分隔成詞組,將僅包含一個當前構形規則的語法詞組作為合法詞組,即所對應的檢索詞符合語法分詞資料庫。
在上述技術方案的基礎上,所述構詞規則中的詞性將詞分為名詞、動詞、形容詞、數詞、量詞和代詞,所述中心詞為動詞。
在上述技術方案的基礎上,將篩選出的詞中無意義的詞去除後,判斷分詞後的詞組是否超過八個字節,並在超過八個字節時採用語法分詞資料庫之外的資料庫進行分詞,再索引分詞結果。
在上述技術方案的基礎上,所述步驟S1之後還包括以下步驟:將不符合語法分詞資料庫的檢索詞採用語法分詞資料庫之外的資料庫進行分詞,並得到索引分詞結果。
在上述技術方案的基礎上,所述語法分詞資料庫之外的資料庫為細粒度標準分詞資料庫。
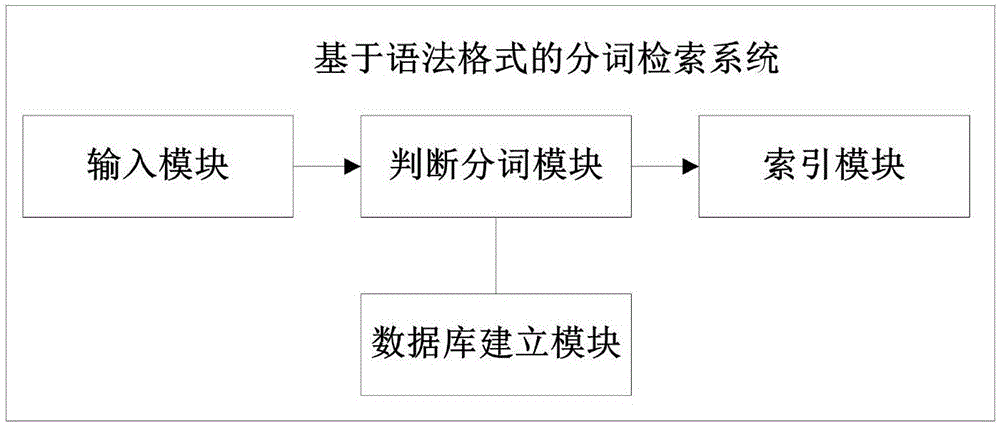
一種基於語法格式的分詞檢索系統,該系統包括資料庫建立模塊、輸入模塊、判斷分詞模塊和索引模塊;
所述資料庫建立模塊用於建立語法分詞資料庫;
所述輸入模塊用於向檢索系統中輸入檢索詞並發送給判斷分詞模塊;
所述判斷分詞模塊用於判斷檢索詞是否符合語法分詞資料庫,並將符合語法分詞資料庫的檢索詞進行分詞,生成分詞結果,並將分詞結果發送給索引模塊;
所述索引模塊用於根據分詞結果進行檢索。
在上述技術方案的基礎上,所述判斷分詞模塊包括中心詞判斷模塊、分隔模塊、構形判斷模塊、去除模塊和字節判斷模塊;
所述中心詞判斷模塊用於判斷檢索詞中是否包括中心詞,並將包括中心詞的檢索詞發送至分隔模塊;
所述分隔模塊用於以中心詞為中心將檢索詞分隔成語法詞組,並將語法詞組發送至構形判斷模塊;
所述構形判斷模塊用於判斷語法詞組的排列方式是否僅包含一個與構形規則相匹配的語法詞組,並將匹配的語法詞組即合法詞組發送至去除模塊;
所述去除模塊用於去除合法詞組中無意義的詞組,並將去除後的詞組發送至字節判斷模塊;
所述字節判斷模塊用於判斷去除無意義詞組後的合法詞組是否超過八個字節,並將不超過八個字節的詞組發送至索引模塊。
與現有技術相比,本發明的優點在於:
(1)本發明的一種基於語法格式的分詞檢索方法及系統,根據語法規則對檢索詞進行分詞,通過判斷檢索詞中是否存在中心詞、詞組是否與構形規則相匹配、合法詞組是否超過八個字節,進而來判斷該檢索詞是否採用語法分詞,判斷方法比較簡單;且根據語法建立詞庫的方法比較簡單,與現有的資料庫相比,語法分詞資料庫不僅比較強大,而且分詞效果較好,得到的結果比較準確;在使用時,由於語法本身的更新較慢,因此,能夠降低語法分詞資料庫更新和維護的頻率,進而降低維護成本。
附圖說明
圖1為本發明實施例中基於語法格式的分詞檢索方法的流程圖;
圖2為本發明實施例中基於語法格式的分詞檢索系統的結構框圖。
具體實施方式
以下結合附圖及實施例對本發明作進一步詳細說明。
參見圖1所示,本發明實施例提供一種基於語法格式的分詞檢索方法,包括以下步驟:
首先根據中文語法大全定義的語法標準,將詞和詞組進行分類並建立語法分詞資料庫,語法標準包括詞組的構詞規則和構形規則,構詞規則根據中文語法中的詞性定義中心詞和無意義詞;構詞規則中的詞性將詞分為名詞、動詞、形容詞、數詞、量詞和代詞,定義構詞規則中任一一種詞作為中心詞,本實施例中的中心詞為動詞,無意義詞為擬聲詞、形容詞、數詞和量詞,構形規則定義詞組的文序,如詞組的組成為名稱+動詞+名詞;
然後從用戶的檢索詞中篩選出含有中心詞且符合構詞規則的詞組,將篩選出的詞組中無意義的詞去除後索引分詞結果。
參見圖1所示,本實施例中,根據上述語法分詞資料庫進行分詞檢索的具體步驟為:
S1、輸入檢索詞,轉入步驟S2。
S2、判斷檢索詞是否包含中心詞,若是,將該中心詞作為潛在語法文本,轉入步驟S3;否則轉入步驟S6,使用語法分詞資料庫之外的資料庫對檢索詞進行分詞。
S3、以潛在語法文本中的中心詞為中心,按照構形規則將潛在語法文本分隔成若干詞組,轉入步驟S4。
S4、判斷若干詞組的排列方式是否僅包含一個與構形規則相匹配的語法詞組,若是,該詞組為合法詞組,轉入步驟S5;否則,使用語法分詞資料庫之外的資料庫進行分詞,轉入步驟S7。
S5、去除合法詞組中無意義的詞組,無意義詞組包括介詞和擬聲詞,轉入步驟S6。
S6、判斷將去掉無意義詞組後的合法詞組是否超過八個字節,若是,轉入步驟S7;否則,轉入步驟S8。
S7、使用語法分詞資料庫意外的資料庫對檢索詞進行分詞,轉入步驟S8。
S8、索引分詞結果。
下面,通過三個實施例對本發明進行詳細說明。
定義構形規則為名詞+動詞+名詞,中心詞為動詞如「吃」「喝」,「踢」,「拽」等。
實施例1
以「我踢足球」為檢索詞,系統先查找改檢索詞中的動詞,並確認包括動詞「踢」,判斷該檢索詞為潛在語法文本。
以「踢」為中心,分隔檢索詞:「我」,「踢」,「足球」,有且只有一個符合構形規則名詞+動詞+名詞,且不包含其他語法格式,為合法語法結構。
將分隔後的檢索詞作為分割詞組,判斷得到該詞組不超過八個字符,將該詞組輸入語法分詞資料庫進行檢索,得到索引分詞結果。
實施例2
以「我看小明踢足球」為檢索詞,系統先查找該檢索詞中的動詞,並確認包括動詞「踢」,判斷該檢索詞為潛在語法文本。
以「踢」為中心,分隔檢索詞:「我看小明」,「踢」,「足球」,符合構形規則為名詞+動詞+名詞,但是,「我看小明」本身也符合構形規則為名詞+動詞+名詞,即該詞組中存在兩個符合構形規則的詞組,則該詞組不能判定為合法語法結構,需要通過語法分詞資料庫之外的資料庫進行分詞再進行索引。
實施例3
以「葉公好龍」為檢索詞,系統先查找該檢索詞中的動詞,並確認包括動詞「好」,判斷該檢索詞為潛在語法文本。
以「好」為中心,分隔檢索詞:「葉公」,「好」,「龍」,有且只有一個符合構形規則名詞+動詞+名詞,且不包含其他語法格式,為合法語法結構。
將分隔後的檢索詞作為分割詞組,判斷得到該詞組不超過八個字符,將該詞組輸入語法分詞資料庫進行檢索,得到索引分詞結果。
參見圖2所示,本發明實施例提供一種基於語法格式的分詞檢索系統,包括資料庫建立模塊、輸入模塊、判斷分詞模塊和索引模塊。
資料庫建立模塊用於建立語法分詞資料庫,輸入模塊用於向檢索系統中輸入檢索詞並發送給判斷分詞模塊。
判斷分詞模塊用於判斷檢索詞是否符合語法分詞資料庫,並將符合符合語法分詞資料庫的檢索詞進行分詞,發送給索引模塊。
索引模塊用於根據分詞結果進行檢索。
本實施例中的判斷分詞模塊包括中心詞判斷模塊、分隔模塊、構形判斷模塊、去除模塊和字節判斷模塊。
中心詞判斷模塊用於判斷檢索詞中是否包括中心詞,並將包括中心詞的檢索詞發送至分隔模塊。
分隔模塊用於以中心詞為中心將檢索詞分隔成語法詞組,並將語法詞組發送至構形判斷模塊。
所述構形判斷模塊用於判斷語法詞組的排列方式是否僅包含一個與構形規則相匹配的語法詞組,並將匹配的語法詞組即合法詞組發送至去除模塊。
去除模塊用於去除合法詞組中無意義的詞組,並將去除後的詞組發送至字節判斷模塊。
字節判斷模塊用於判斷去除無意義詞組後的合法詞組是否超過八個字節,並將不超過八個字節的詞組發送至索引模塊。
本發明不局限於上述實施方式,對於本技術領域的普通技術人員來說,在不脫離本發明原理的前提下,還可以做出若干改進和潤飾,這些改進和潤飾也視為本發明的保護範圍之內。本說明書中未作詳細描述的內容屬於本領域專業技術人員公知的現有技術。