一種分布式集群訓練方法和裝置與流程
2023-04-30 17:53:51 4
本申請涉及機器學習技術領域,特別是涉及一種分布式集群訓練方法和一種分布式集群訓練裝置。
背景技術:
隨著大數據的應用,很多基於大數據的目標模型,比如預測用戶對商品的喜好的目標模型,都需要利用相應的樣本數據對目標模型中的權重進行訓練。該權重可以理解為目標模型的參數,比如以一個簡單的模型y=ax1+bx2+cx3,其中的a、b、c為權重,x1、x2、x3為輸入量,y為輸出量。而上述目標模型都需要利用機器學習訓練。
機器學習訓練一般包括單機訓練和集群訓練,單機訓練就是利用所有樣本,計算f(x)(f為損失函數,x為權重)的梯度:▽f(xt-1),然後更新權重:xt=xt-1-α▽f(xt-1),一直這樣迭代,直到收斂;而集群訓練,就是先按照一定規則,將訓練樣本分到各個機器上(各機器上數據都不一樣),每個機器計算出梯度,然後利用reduce技術,將梯度匯總,並進行權重更新。重複上述過程,直到收斂。事實上,由於現在數據量巨大,集群訓練已經成為工業界標配。
而單機上進行訓練,當樣本數據的數據量很大時,會出現因為數據量太大導致內存加載不下,導致無法進行訓練。在單機上訓練,沒有通信(網絡)代價,但無法支撐大數據(比如所有用戶在最近2周內的瀏覽日誌數據)。
基於單機訓練的上述問題,在先技術中採用了在分布式集群中執行機器學習任務。現有集群訓練方案:(1)將數據集t,按照一定規則,切分成n份,得到t={t1,t2,…,tn};(2)每個訓練伺服器得到一份數據,設為tx;(3)每個訓練伺服器利用得到的數據,計算對應的梯度▽ftx;(4)進行梯度匯總得到總梯度:totalgradient=∑1nfi;(5)根據規則更新權重(類似單機訓練的更新權重方法),並將新權重發給所有機器;(6)判定是否訓練結束,如果沒有結束,返回第三步。
在集群上訓練,能利用更多的訓練數據,取得更好的預測效果。由於每輪計算梯度後,都需要將梯度匯總,通信量巨大且頻繁,可能導致集群中網絡流量爆滿,而影響交換機,甚至整個集群的使用。
技術實現要素:
鑑於上述問題,提出了本申請實施例以便提供一種克服上述問題或者至 少部分地解決上述問題的一種分布式集群訓練方法和相應的一種分布式集群訓練裝置。
為了解決上述問題,本申請公開了一種分布式集群訓練方法,包括:
讀取樣本集;所示樣本集包括至少一條樣本數據;
在接收到匯集指令之前,利用所述樣本數據和當前權重,代入目標模型訓練函數進行迭代訓練,得到第一梯度;所述匯集指令由調度伺服器在集群系統環境符合閾值條件時發出;其中,如果在接收到匯集指令之前,有多輪迭代訓練,則基於前一次訓練得到的第一梯度生成第一權重作為後一輪迭代訓練的當前權重;
如果接收到匯集指令,則將所述第一梯度發送至匯集伺服器;所述匯集伺服器匯總各第一梯度並計算第二權重;
接收匯集伺服器發送的第二權重以更新當前權重。
本申請還公開了一種分布式集群訓練裝置,包括:
樣本讀取模塊,用於讀取樣本集;所示樣本集包括至少一條樣本數據;
迭代訓練模塊,用於在接收到匯集指令之前,利用所述樣本數據和當前權重,代入目標模型訓練函數進行迭代訓練,得到第一梯度;所述匯集指令由調度伺服器在集群系統環境符合閾值條件時發出;其中,如果在接收到匯集指令之前,有多輪迭代訓練,則基於前一次訓練得到的第一梯度生成第一權重作為後一輪迭代訓練的當前權重;
結果發送模塊,用於如果接收到匯集指令,則將所述第一梯度發送至匯集伺服器;所述匯集伺服器匯總各第一梯度並計算第二權重;
更新模塊,用於接收匯集伺服器發送的第二權重以更新當前權重。
本申請實施例包括以下優點:
本申請實施例,訓練伺服器可以利用其讀取的樣本集,在接收到匯集指令之前,利用該樣本集中的樣本數據和當前權重,不斷迭代訓練第一梯度;同時,調度伺服器可以監控集群系統環境是否符合閾值條件,當系統監控到集群系統環境符合閾值條件時,則可以發送匯集指令給各個訓練伺服器,各 個訓練伺服器則將訓練得到的第一梯度發送到匯集伺服器;該匯集伺服器匯總各第一梯度並計算第二權重,在各個訓練伺服器還未對其樣本數據訓練結束前,將該第二權重發送到各個訓練伺服器,更新期當前權重。如此,由於系統監控何時系統環境,控制何時發出匯集指令,相應的,訓練伺服器則在收到匯集指令後才將第一梯度發送到匯集伺服器。不會在整個過程中每輪訓練結束都將訓練結果發送至伺服器,降低了網絡通信量,降低對交換機的影響,避免影響整個集群的使用。
附圖說明
圖1是本申請的一種分布式集群訓練方法實施例的步驟流程圖;
圖2是本申請的另一種分布式集群訓練方法實施例的步驟流程圖;
圖3是本申請的另一種分布式集群訓練方法實施例的步驟流程圖;
圖4是本申請的另一種分布式集群訓練方法實施例的步驟流程圖;
圖5是本申請的一種分布式集群訓練裝置實施例的結構框圖;
圖6是本申請的一種分布式集群訓練系統實施例的結構框圖。
具體實施方式
為使本申請的上述目的、特徵和優點能夠更加明顯易懂,下面結合附圖和具體實施方式對本申請作進一步詳細的說明。
本申請實施例的核心構思之一在於,由於在先技術中在集群中訓練目標模型時,每輪訓練完畢之後,都直接將集群中各訓練伺服器訓練得到的梯度進行匯總,導致通信量巨大而且頻繁,可能導致集群中網絡流量爆滿,從而影響交換機甚至整個集群的使用。本申請實施例中,訓練伺服器可以利用其讀取的樣本集,在接收到匯集指令之前,利用該樣本集中的樣本數據和當前權重,不斷迭代訓練第一梯度;同時,系統可以監控集群系統環境是否符合閾值條件,該閾值條件可以避免集群系統環境出現網絡流量爆滿,當系統監 控到集群系統環境符合閾值條件時,則可以發送匯集指令給各個訓練伺服器,各個訓練伺服器則將訓練得到的第一梯度發送到匯集伺服器;該匯集伺服器匯總各第一梯度並計算第二權重,在各個訓練伺服器還未對其樣本數據訓練結束前,將該第二權重發送到各個訓練伺服器,更新其當前權重。如此,由於系統監控何時系統環境,控制何時發出匯集指令,相應的,訓練伺服器則在收到匯集指令後才將第一梯度發送到匯集伺服器。不會在整個過程中每輪訓練結束都將訓練結果發送至伺服器,降低了網絡通信量,降低對交換機的影響,避免影響整個集群的使用。
實施例一
參照圖1,示出了本申請的一種分布式集群方法實施例的步驟流程圖,具體可以包括如下步驟:
步驟110,讀取樣本集;所示樣本集包括至少一條樣本數據;
在本申請實施例中,整個集群可以包括多臺訓練伺服器、至少一臺調度伺服器、至少一臺匯集伺服器。該訓練伺服器可以獲取其負責的樣本集進行迭代訓練,以得到第一梯度,調度伺服器可以監控整個系統的集群系統環境情況,並根據集群系統環境決定是否發出匯集指令到訓練伺服器。匯集伺服器可以接收各個訓練伺服器發送的第一梯度並計算第二權重。
在本申請實施例中,訓練伺服器、調度伺服器、匯集伺服器之間的通信數據都通過集群中的交換機傳輸。
可以理解,本申請實施例的調度伺服器可以將各訓練伺服器需要獲取的樣本集的獲取參數發送給各個訓練伺服器。那麼,對於一臺訓練伺服器來說,其收到獲取參數後,可以根據該獲取參數,從指定位置讀取其需要的樣本集。比如從交易日誌伺服器獲取該參數規定的一批交易日誌數據作為樣本集。當然,本申請實施例還可以從其他伺服器獲取相應樣本集,可以按照需求設定,本申請實施例不對其加以限制。
步驟120,在接收到匯集指令之前,利用所述樣本數據和當前權重,代入目標模型訓練函數進行迭代訓練,得到第一梯度;所述匯集指令由調度伺服器在集群系統環境符合閾值條件時發出;其中,如果在接收到匯集指令之 前,有多輪迭代訓練,則基於前一次訓練得到的第一梯度生成第一權重作為後一輪迭代訓練的當前權重;
對於一個訓練伺服器a而言,其讀取到樣本集後,在初始情況下,目標模型的各個當前權重是根據經驗預設的第二權重x0。此時可以從樣本集中按序逐個提取樣本數據,輸入目標模型進行訓練,訓練屬於該訓練伺服器a的第一梯度。
該訓練伺服器a,在未接收到匯集指令之前,可以一直讀取樣本數據進行迭代訓練。當然在實際應用中,各個訓練伺服器可以將其訓練的樣本全部讀到本地,然後進行訓練。比如第一輪利用樣本數據m1和當前權重x0,代入目標模型訓練函數,訓練第一梯度▽f(x0),然後利用▽f(x0)計算權重x1該x1以作為第二輪訓練的當前權重;然後利用樣本數據m2和當前權重x1,代入目標模型訓練函數,訓練第一梯度▽f(x1);以此類推,直到接收到匯集指令。其中xi(i=1、2、3……)是一個多維向量,其中每個維度對應目標模型中的一個參數。其中所述目標模型訓練函數可以為前述的損失函數f(x)
在實際應用中,以上述過程為例,在第一輪中,將第一個樣本數據代入損失函數f(x),其中,x為當前權重,然後計算f(x)的梯度▽f(x0),然後根據公式xt=xt-1-α▽f(xt-1)更新得到第一梯度▽f(x1)。其中,損失函數f(x)可以根據實際情況設定,在先技術對此有詳細過程,在此不在贅敘。對於第二輪類似。假設訓練伺服器訓練到第三輪,得到第一梯度▽f(x2),此時,接收到調度伺服器發送的匯集指令,則可以直接將第一梯度▽f(x2)通過交換機發送至匯集伺服器中。
在本申請實施例中,訓練伺服器在上一次匯集之後,會記錄第一梯度的訓練輪次。調度伺服器發送匯集指令時,則會控制訓練伺服器發送哪一輪的第一梯度。調度伺服器可以在發送匯集指令之前控制各訓練伺服器執行n輪訓練,n為大於0的整數。比如通知訓練伺服器在接收匯集指令之前,只進行三輪訓練,如果三輪訓練結束,則等待調度伺服器的指令。當然,實際應用中,可以對n做限制,也可根據實際需求的訓練精度誤差設置n的值。該 實際需求的訓練精度誤差可以根據歷史訓練結果的經驗設定。
在本申請實施例中,調度伺服器向各訓練伺服器發送的匯集指令中,包含了指定輪次。則各訓練伺服器將相應輪次訓練得到的第一梯度發送到匯集伺服器中。
在本申請實施例中,在各個訓練伺服器進行迭代訓練的過程中,調度伺服器會監控集群系統環境,當集群系統環境符合閾值條件時,調度伺服器向各個訓練伺服器發出匯集指令。該閾值條件可以限定訓練伺服器發送的頻率不太快,導致網絡擁堵,如網絡利用率低於30%等閾值條件。
在本申請另一優選的實施例中,所述匯集指令由調度伺服器在集群系統環境符合閾值條件時發出,包括:
所述匯集指令由調度伺服器在整個集群的集群網絡利用率符合第一閾值條件時發出。
在本申請實施例中,調度伺服器可以監控整個集群的集群網絡利用率,比如獲取每個伺服器的網卡的發包量和收包量,而網卡本身有一個最大流量限制,比如100m,那麼統計各個網卡的發包量和收包量,再除以所有網卡的總流量限制,則可以得到集群網絡利用率。當然,也可以計算每個伺服器的網卡的利用率,然後把各個網卡的利用率進行加權平均得到集群網絡利用率。在該種情況下,所述第一閾值條件包括:集群網絡利用率低於第一閾值;比如第一閾值設置為30%,那麼當調度伺服器監控得到的集群網絡利用率低於30%,則可以向各個訓練伺服器發送匯集指令。
在本申請另一優選的實施例中,所述匯集指令由調度伺服器在集群系統環境符合閾值條件時發出,包括:
所述匯集指令由調度伺服器在整個集群的集群故障率符合第二閾值條件時發出。
在本申請實施例中,整個集群中的各個伺服器可能出現故障,那麼本申請實施例可以監控各個伺服器的故障,然後根據出現故障的伺服器個數除以整個集群的伺服器的個數得到集群故障率。當然,在本申請實施例中,可以只監控訓練伺服器出現故障的第一個數,然後將該第一個數除以整個集群的 個數得到集群故障率;當然,該第一個數也可以除以所有訓練伺服器的個數得到集群故障率。該種情況下,所述第二閾值條件包括:集群故障率低於第二閾值。比如第二閾值設置為5%,那麼集群故障率低於5%時,調度伺服器可以向各個訓練伺服器發出匯集指令。
需要說明的是,前述伺服器的故障,包括伺服器本身崩潰沒響應、伺服器響應延遲超過一定時間。本申請實施例中,調度伺服器可以定期向各個伺服器發送測試命令,如果伺服器未在規定時間內響應,則可認為該伺服器出現故障。
當然,本申請實施例中,調度伺服器發出匯集指令之前,還可以監控各訓練伺服器的訓練情況,比如監控到距離上次發送匯集指令之後,各個訓練伺服器完成了至少一輪訓練才會在符合前述閾值條件下,發出匯集指令。
步驟130,如果接收到匯集指令,則將所述第一梯度發送至匯集伺服器;
步驟140,所述匯集伺服器匯總各第一梯度並計算第二權重;
在本申請實施例中,對於一個訓練伺服器,如果接收到匯集指令,則可以將最新更新的第一梯度發送至匯集伺服器。
由於匯集指令中有訓練輪次,各個訓練伺服器則將相同輪次的第一梯度發送至匯集伺服器。
在本申請實施例中,如果有多臺匯集伺服器,則各訓練伺服器可以根據預先設定的與匯集伺服器的對應關係,將其第一梯度發送至相應的匯集伺服器中。各個匯集伺服器對接收到的部分第一梯度進行匯總,然後各個匯集伺服器再將匯總後的第一梯度再匯總至一個匯集伺服器中,然後該匯集伺服器進行最後的匯總,然後基於最後匯總的第一梯度計算第二權重。
而對於匯集伺服器,在接收到所有訓練伺服器的第一梯度後,則可以對第一梯度進行匯總,然後根據匯總的結果計算第二權重。
此時,匯集伺服器可以判斷各個訓練伺服器是否訓練完畢,如果未訓練完畢,則將第二權重發送到各個訓練伺服器。
可以理解,在實際應用中,各個訓練伺服器在發送其第一梯度時,可以發送是否對樣本集的所有樣本數據訓練完畢的第一標識,如第一標識為no 表示未訓練完,第一標識為yes表示訓練完。匯集伺服器則可以根據該標識判斷訓練伺服器是否訓練完該樣本集的所有樣本數據。當然,實際應用中,匯集伺服器還可以通過其他方式去確定各個訓練伺服器是否訓練完其樣本集的所有樣本數據,本申請實施例不對其加以限制。
步驟150,接收匯集伺服器發送的第二權重以更新當前權重。
對於訓練伺服器而言,其在對所述樣本數據訓練結束前,可以接收到匯集伺服器發送的第二權重。那麼訓練伺服器則可以將該第二權重更新當前權重,然後讀取後續的樣本數據進行下一輪訓練。當然,如果樣本數據已經讀取到了本地,則可以從本地讀取下一輪的樣本數據進行下一輪訓練。
本申請實施例中,訓練伺服器可以利用其讀取的樣本集,在接收到匯集指令之前,利用該樣本集中的樣本數據和當前權重,不斷迭代訓練第一梯度;同時,系統可以監控集群系統環境是否符合閾值條件,該閾值條件可以避免集群系統環境出現網絡流量爆滿,當系統監控到集群系統環境符合閾值條件時,則可以發送匯集指令給各個訓練伺服器,各個訓練伺服器則將訓練得到的第一梯度發送到匯集伺服器;該匯集伺服器匯總各第一梯度並計算第二權重,在各個訓練伺服器還未對其樣本數據訓練結束前,將該第二權重發送到各個訓練伺服器,更新期當前權重。如此,由於系統監控何時系統環境,控制何時發出匯集指令,相應的,訓練伺服器則在收到匯集指令後才將第一梯度發送到匯集伺服器。不會在整個過程中每輪訓練結束都將訓練結果發送至伺服器,降低了網絡通信量,降低對交換機的影響,避免影響整個集群的使用。
實施例二
參照圖2,示出了本申請的另一種分布式集群方法實施例的步驟流程圖,具體可以包括如下步驟:
步驟210,讀取樣本集;所示樣本集包括至少一條樣本數據;所述樣本數據包括時間信息;
在本申請實施例中,在樣本數據中除了傳統的數據,比如用戶id、用戶交易行為、收藏行為數據、瀏覽行為數據等數據,還額外增加了一列數據, 該列數據記錄了該條樣本數據產生的時間。比如最近一天的交易記錄數據、最近兩天的交易數據。
步驟220,利用每條樣本數據的時間信息,計算所述樣本數據的第三權重;
在本申請實施例中,距離當前越近的樣本數據,越能反應用戶真實的興趣與意圖,採用該樣本數據訓練出來的模型更精準。而本申請可以利用每條樣本數據的時間信息,計算所述樣本數據的第三權重。該第三權重表示該樣本數據的時間信息距離當前時間越近其權重越高,反之,其權重越低。
在本申請另一優選的實施例中,所述利用每條樣本數據的時間信息,計算所述樣本數據的第三權重的步驟包括:
子步驟221,將每條樣本數據的時間信息,代入指數函數的負的指數參數,計算第三權重。
在本申請實施例中,可以將時間信息距離當前時間轉換為數字信息,比如樣本數據n1的時間信息為1,表示樣本數據n1距離當前時間的距離為1天,樣本數據n2的時間信息為3,表示樣本數據n2距離當前時間的距離為3天。當然,將時間信息轉換為數字信息,也可以採用其他方式,本申請實施例不對其加以限制。
在本申請實施例中,指數函數的底數可以設置為自然數e,也可以設置為其他大於1的數。優選的採用自然數e。那麼本申請可以利用e-x計算第三權重,其中x為時間信息,比如對於n1,其第三權重為e-1,其他情況以此類推。當然該指數函數的底數可以為其他底數,比如2,那麼指數函數變為2-x。
步驟230,當所述第三權重小於第三閾值,則丟棄相應的樣本數據。
比如設置第三閾值為0.001,那麼當第三權重小於該第三閾值,則說明該樣本數據離當前時間太遠,該樣本數據對用戶的興趣和意圖影響不大,可以將其丟棄。從而可以降低計算量,從而節省系統資源。
步驟240,在接收到匯集指令之前,利用所述樣本數據和當前權重,代入目標模型訓練函數進行迭代訓練,得到第一梯度;所述匯集指令由調度服 務器在集群系統環境符合閾值條件時發出;其中,如果在接收到匯集指令之前,有多輪迭代訓練,則基於前一次訓練得到的第一梯度生成第一權重作為後一輪迭代訓練的當前權重;
步驟250,如果接收到匯集指令,則將所述第一梯度發送至匯集伺服器,以及將各個樣本數據的第三權重進行匯總得到的第一係數發送至匯集伺服器;
在本申請實施例中,訓練伺服器在對樣本集的數據進行訓練之前,可以計算各條樣本數據的第三權重,然後可以對各個保留下來的樣本數據第三權重進行匯總,得到第一係數。
步驟260,所述匯集伺服器根據各第一梯度及與各第一梯度相應的第一係數,進行加權計算得到第二梯度;
步驟270,所述匯集伺服器根據第二梯度計算第二權重。
比如訓練伺服器a發送第一梯度▽f(x1)a,其第一係數為0.8;訓練伺服器b發送第一梯度▽f(x1)b,其第一係數為0.7;訓練伺服器c發送第一梯度▽f(x1)c,其第一係數為0.5。那麼第二梯度為
(0.8▽f(x1)a+0.7▽f(x1)b+0.5▽f(x1)c)
然後再根據第二梯度計算第二權重。
然後可以按照實施例一中的描述,將第二權重發送至各個未訓練完畢的訓練伺服器。
步驟280,接收匯集伺服器發送的第二權重以更新當前權重。
本申請實施例中,訓練伺服器可以利用其讀取的樣本集,在接收到匯集指令之前,利用該樣本集中的樣本數據和當前權重,不斷迭代訓練第一梯度;同時,系統可以監控集群系統環境是否符合閾值條件,該閾值條件可以避免集群系統環境出現網絡流量爆滿,當系統監控到集群系統環境符合閾值條件時,則可以發送匯集指令給各個訓練伺服器,各個訓練伺服器則將訓練得到的第一梯度發送到匯集伺服器;該匯集伺服器匯總各第一梯度並計算第二權重,在各個訓練伺服器還未對其樣本數據訓練結束前,將該第二權重發送到 各個訓練伺服器,更新期當前權重。如此,由於系統監控何時系統環境,控制何時發出匯集指令,相應的,訓練伺服器則在收到匯集指令後才將第一梯度發送到匯集伺服器。不會在整個過程中每輪訓練結束都將訓練結果發送至伺服器,降低了網絡通信量,降低對交換機的影響,避免影響整個集群的使用。
另外,本申請實施例可以根據數據的時效性,自動對新的數據加大權重,對老數據降權,並丟棄部分舊數據,從而使目標模型更契合用戶當前的行為習慣,並且可以降低計算量。
實施例三
參照圖3,示出了本申請的另一種分布式集群方法實施例的步驟流程圖,具體可以包括如下步驟:
步驟310,讀取樣本集;所示樣本集包括至少一條樣本數據;所述樣本數據包括時間信息;
步驟312,對樣本集中的各樣本數據進行歸併;
步驟314,對歸併後的樣本數據,記錄所述樣本數據的歸併數量。
在本申請實施例中,對於相同內容的樣本數據,可以按照相同時間段進行歸併。比如對於用戶a,其在2015-12-31的上午10點,買了商品a,在在2015-12-31的下午3點,買了商品a。那麼這兩條樣本數據則可以歸併,得到用戶a在2015-12-31購買了商品a,歸併數量為2。
在實際中,對於樣本數據,還可以在其中添加一列歸併數量列,把歸併數量填入該列。
步驟316,利用每條樣本數據的時間信息,計算降權係數;
在本申請實施例中,可以利用每條樣本數據的時間信息,計算降權係數,距離當前時間越近其降權係數越高,反之,其降權係數越低。
在本申請另一優選的實施例中,所述利用每條樣本數據的時間信息,計算降權係數的步驟包括:
子步驟c11,將每條樣本數據的時間信息,代入指數函數的負的指數參數,計算降權係數。
在本申請實施例中,可以將時間信息距離當前時間轉換為數字信息,比如樣本數據n1的時間信息為1,表示樣本數據n1距離當前時間的距離為1天,樣本數據n2的時間信息為3,表示樣本數據n2距離當前時間的距離為3天。當然,將時間信息轉換為數字信息,也可以採用其他方式,本申請實施例不對其加以限制。
那麼本申請可以利用e-x計算降權係數,其中x為時間信息,比如對於n1,其降權係數為e-1,其他情況以此類推。當然該指數函數的底數可以為其他底數,比如2,那麼指數函數變為2-x。
步驟318,計算所述降權係數與歸併數量之積,得到第三權重。
由於本申請實施例中,對於樣本數據進行了歸併,那麼樣本集中的樣本數據則為歸併後的樣本數據,那麼可以將該樣本數據的歸併數據乘以其降權係數,得到第三權重。
可以理解,步驟316-318可以為實施例二中步驟220優選的步驟。
步驟320,當所述第三權重小於第三閾值,則丟棄相應的樣本數據。
步驟322,在接收到匯集指令之前,利用所述樣本數據和當前權重,代入目標模型訓練函數進行迭代訓練,得到第一梯度;所述匯集指令由調度伺服器在集群系統環境符合閾值條件時發出;其中,如果在接收到匯集指令之前,有多輪迭代訓練,則基於前一次訓練得到的第一梯度生成第一權重作為後一輪迭代訓練的當前權重;
步驟324,如果接收到匯集指令,則將所述第一梯度發送至匯集伺服器,以及將各個樣本數據的第三權重進行匯總得到的第一係數發送至匯集伺服器;
步驟326,所述匯集伺服器根據各第一梯度及與各第一梯度相應的第一係數,進行加權計算得到第二梯度;
步驟328,接收匯集伺服器發送的第二權重以更新當前權重。
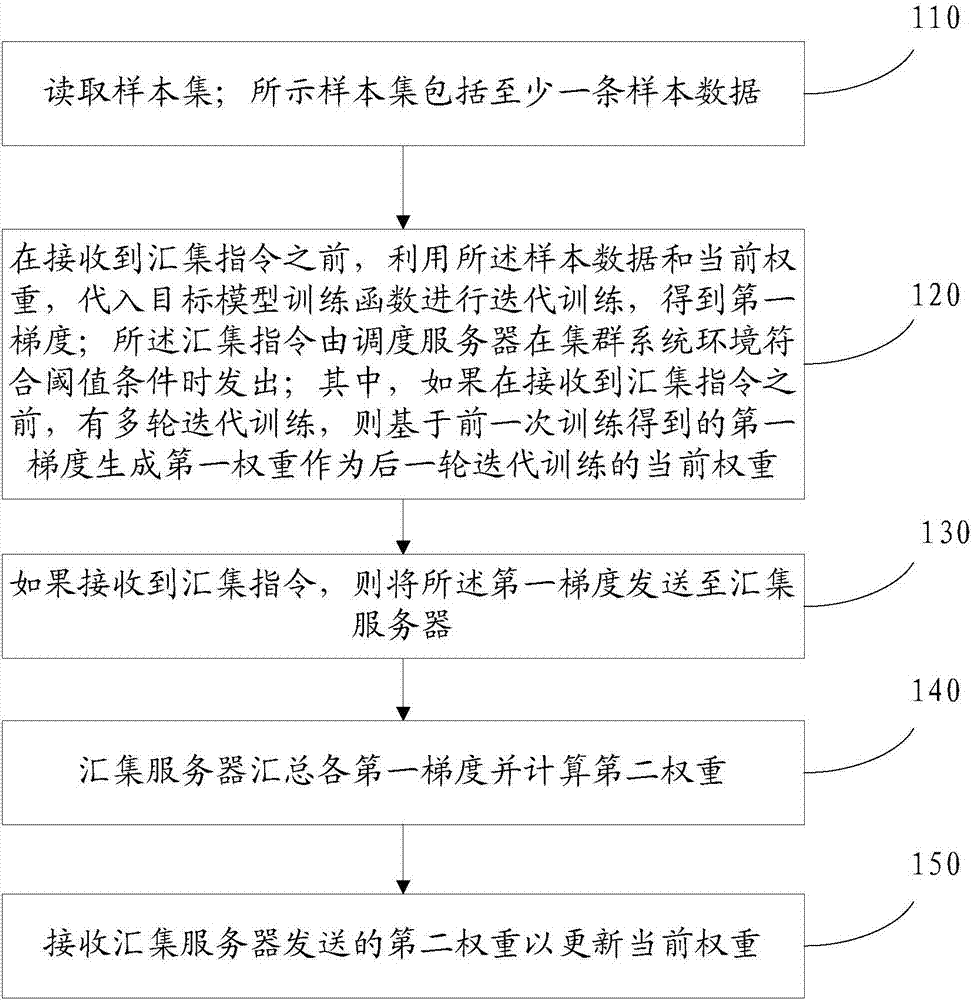
本申請實施例由於調度伺服器監控系統環境,控制何時發出匯集指令,相應的,訓練伺服器則在收到匯集指令後才將第一梯度發送到匯集伺服器。不會在整個過程中每輪訓練結束都將訓練結果發送至伺服器,降低了網絡通 信量,降低對交換機的影響,避免影響整個集群的使用。
另外,本申請實施例對樣本數據進行了歸併,減少了訓練的樣本數量,能夠提高訓練速度。
再者,本申請實施例可以根據數據的時效性,自動對新的數據加大權重,對老數據降權,並丟棄部分舊數據,從而使目標模型更契合用戶當前的行為習慣,並且可以降低計算量。
實施例四
參照圖4,示出了本申請的另一種分布式集群方法實施例的步驟流程圖,具體可以包括如下步驟:
步驟410,訓練伺服器讀取樣本集;所示樣本集包括至少一條樣本數據;所述樣本數據包括時間信息;
步驟412,訓練伺服器對樣本集中的各樣本數據進行歸併;
步驟414,訓練伺服器對歸併後的樣本數據,記錄所述樣本數據的歸併數量。
步驟416,訓練伺服器利用每條樣本數據的時間信息,計算降權係數;
步驟418,訓練伺服器計算所述降權係數與歸併數量之積,得到第三權重。
可以理解,步驟416-418可以為實施例二中步驟220優選的步驟。
步驟420,訓練伺服器當所述第三權重小於第三閾值,則丟棄相應的樣本數據。
步驟422,訓練伺服器在接收到匯集指令之前,利用所述樣本數據和當前權重,代入目標模型訓練函數進行迭代訓練,得到第一梯度;其中,如果在接收到匯集指令之前,有多輪迭代訓練,則基於前一次訓練得到的第一梯度生成第一權重作為後一輪迭代訓練的當前權重;
步驟424,調度伺服器在集群系統環境符合閾值條件時發出匯集指令;
調度伺服器將匯集指令發送給各個訓練伺服器。
步驟426,訓練伺服器如果接收到匯集指令,則將所述第一梯度發送至匯集伺服器,以及將各個樣本數據的第三權重進行匯總得到的第一係數發送 至匯集伺服器;
步驟428,匯集伺服器根據各第一梯度及與各第一梯度相應的第一係數,進行加權計算得到第二梯度;
步驟430,匯集伺服器根據第二梯度計算第二權重;
步驟432,匯集伺服器將新得到的第二權重進行備份,並將新的第二權重發送至各訓練伺服器。
在本申請實施例中,匯集伺服器在得到新的第二權重之後,可以將該第二權重進行備份。
在本申請另一優選的實施例中,所述匯集伺服器將新得到的第二權重進行備份包括:
步驟d11,所述匯集伺服器判斷新得到的第二權重與至少前一次備份的第二權重之間的變化量是否超過變化閾值;
步驟d12,如果超過變化閾值,則對所述新得到的第二權重進行備份。
在本申請實施例中,匯集伺服器得到新的第二權重,則會與之前的備份的至少一次的第二權重進行變化量的計算。比如與之前備份的最近一次的第二權重之間的變化量是否小於變化閾值,如5%,如果小於5%,則拋棄新的第二權重,如果大於等於,則備份該第二權重,如此可以減少備份量。使步驟c13中,可以不用更新給外部的業務伺服器的目標模型,避免無謂的影響業務伺服器對該目標模型的使用,比如測試。
可以理解,因為進行了權重備份,如果某個時刻整個訓練失敗,則在重新訓練時,調度伺服器可以通知匯集伺服器,將備份的最新的第二權重發送給訓練伺服器,使訓練伺服器可以將該最新的第二權重作為初始的當前權重,結合之前的樣本繼續進行訓練。提高訓練的效率。
當然,本申請實施例中,訓練失敗之後,也可以從第一個樣本開始進行訓練,但是其當前權重為備份的最新的第二權重。
匯集伺服器將最新的第二權重發送至各訓練伺服器。
步驟434,訓練伺服器接收匯集伺服器發送的第二權重以更新當前權重。
在本申請另一優選的實施例中,所述匯集伺服器將新得到的第二權重進 行備份之後,還包括:
子步驟c13,匯集伺服器將所述第二權重代入目標模型,並輸出至業務伺服器。
在本申請實施例中,對於備份的第二權重,可以直接將其代入目標模型,輸出給業務伺服器,使業務方可以直接利用該目標模型進行使用。
本申請具備如下幾個方面的優點:
(1)懶惰通信機制:根據集群環境以及迭代情況,自動判斷是否需要所有機器進行權重匯總動作,從而避免每輪訓練都匯集一次,導致可能出現網絡佔滿的情況。
(2)權重備份機制:根據規則,自動備份權重,一旦某些機制出現問題,可以從備份拉回以前的權重,繼續進行訓練,從而不用從頭再此訓練,提高訓練效率。
(3)數據切分裝置:根據數據的時效性,自動對新的數據加大權重,對老數據降權,並丟棄部分舊數據。
需要說明的是,對於方法實施例,為了簡單描述,故將其都表述為一系列的動作組合,但是本領域技術人員應該知悉,本申請實施例並不受所描述的動作順序的限制,因為依據本申請實施例,某些步驟可以採用其他順序或者同時進行。其次,本領域技術人員也應該知悉,說明書中所描述的實施例均屬於優選實施例,所涉及的動作並不一定是本申請實施例所必須的。
實施例五
參照圖5,示出了本申請的一種分布式集群訓練裝置實施例的結構框圖,具體可以包括如下模塊:
樣本讀取模塊510,用於讀取樣本集;所示樣本集包括至少一條樣本數據;
迭代訓練模塊520,用於在接收到匯集指令之前,利用所述樣本數據和當前權重,代入目標模型訓練函數進行迭代訓練,得到第一梯度;所述匯集指令由調度伺服器在集群系統環境符合閾值條件時發出;其中,如果在接收 到匯集指令之前,有多輪迭代訓練,則基於前一次訓練得到的第一梯度生成第一權重作為後一輪迭代訓練的當前權重;
結果發送模塊530,用於如果接收到匯集指令,則將所述第一梯度發送至匯集伺服器;所述匯集伺服器匯總各第一梯度並計算第二權重;
更新模塊540,用於接收匯集伺服器發送的第二權重以更新當前權重。
在本申請另一優選的實施例中,所述匯集指令由調度伺服器在集群系統環境符合閾值條件時發出,包括:
所述匯集指令由調度伺服器在整個集群的集群網絡利用率符合第一閾值條件時發出,和/或由調度伺服器在整個集群的集群故障率符合第二閾值條件時發出。
在本申請另一優選的實施例中,所述第一閾值條件包括:集群網絡利用率低於第一閾值;
所述第二閾值條件包括:集群故障率低於第二閾值。
在本申請另一優選的實施例中,所述樣本讀取模塊之後,還包括:
第三權重計算模塊,用於利用每條樣本數據的時間信息,計算所述樣本數據的第三權重;
樣本丟棄模塊,用於當所述第三權重小於第三閾值,則丟棄相應的樣本數據。
在本申請另一優選的實施例中,所述第三權重計算模塊包括:
指數計算模塊,用於將每條樣本數據的時間信息,代入指數函數的負的指數參數,計算第三權重。
在本申請另一優選的實施例中,在第三權重計算模塊之前,還包括:
歸併模塊,用於對樣本集中的各樣本數據進行歸併;
歸併記錄模塊,用於對歸併後的樣本數據,記錄所述樣本數據的歸併數量。
在本申請另一優選的實施例中,所述第三權重計算模塊,包括:
降權係數計算模塊,用於利用每條樣本數據的時間信息,計算降權係數;
第一計算模塊,用於計算所述降權係數與歸併數量之積,得到第三權重。
在本申請另一優選的實施例中,所述結果發送模塊還用於,如果接收到匯集指令,將各個樣本數據的第三權重進行匯總得到的第一係數發送至匯集伺服器;
則,所述匯集伺服器包括:第一加權匯總模塊,用於根據各第一梯度及與各第一梯度相應的第一係數,進行加權計算得到第二梯度;
第二權重計算模塊,用於根據第二梯度計算第二權重。
在本申請另一優選的實施例中,所述匯集伺服器還包括:
備份模塊,用於將新得到的第二權重進行備份。
在本申請另一優選的實施例中,所述備份模塊包括:
變化計算模塊,用於所述匯集伺服器判斷新得到的第二權重與至少前一次備份的第二權重之間的變化量是否超過變化閾值;
第一備份模塊,用於如果超過變化閾值,則對所述新得到的第二權重進行備份。
在本申請另一優選的實施例中,所述備份模塊之後,還包括:
輸出模塊,用於將所述第二權重代入目標模型,並輸出至業務伺服器。
本申請具備如下幾個方面的優點:
(1)懶惰通信機制:根據集群環境以及迭代情況,自動判斷是否需要所有機器進行權重匯總動作,從而避免每輪訓練都匯集一次,導致可能出現網絡佔滿的情況。
(2)權重備份機制:根據規則,自動備份權重,一旦某些機制出現問題,可以從備份拉回以前的權重,繼續進行訓練,從而不用從頭再此訓練,提高訓練效率。
(3)數據切分裝置:根據數據的時效性,自動對新的數據加大權重,對老數據降權,並丟棄部分舊數據。
對於裝置實施例而言,由於其與方法實施例基本相似,所以描述的比較簡單,相關之處參見方法實施例的部分說明即可。
實施例五
參照圖6,示出了本申請的一種分布式集群訓練裝置實施例的結構框圖, 具體可以包括如下模塊:
包括調度伺服器610、匯集伺服器620、多臺訓練伺服器630。
所述調度伺服器610包括:
集群監控模塊611,用於監控集群系統環境是否符合閾值條件,如果符合,則向各訓練伺服器630發出匯集指令。
在本申請另一優選的實施例中,集群監控模塊611具體用於在整個集群的集群網絡利用率符合第一閾值條件時發出匯集指令,和/或在整個集群的集群故障率符合第二閾值條件時發出匯集指令。
在本申請另一優選的實施例中,所述第一閾值條件包括:集群網絡利用率低於第一閾值;
所述第二閾值條件包括:集群故障率低於第二閾值。
所述訓練伺服器630包括:
樣本讀取模塊631,用於讀取樣本集;所示樣本集包括至少一條樣本數據;
迭代訓練模塊632,用於在接收到匯集指令之前,利用所述樣本數據和當前權重,代入目標模型訓練函數進行迭代訓練,得到第一梯度;其中,如果在接收到匯集指令之前,有多輪迭代訓練,則基於前一次訓練得到的第一梯度生成第一權重作為後一輪迭代訓練的當前權重;
結果發送模塊633,用於如果接收到匯集指令,則將所述第一梯度發送至匯集伺服器;
更新模塊634,用於接收第二權重以更新當前權重;
在本申請另一優選的實施例中,所述樣本讀取模塊631之後,還包括:
第三權重計算模塊,用於利用每條樣本數據的時間信息,計算所述樣本數據的第三權重;
樣本丟棄模塊,用於當所述第三權重小於第三閾值,則丟棄相應的樣本數據。
在本申請另一優選的實施例中,所述第三權重計算模塊包括:
指數計算模塊,用於將每條樣本數據的時間信息,代入指數函數的負的 指數參數,計算第三權重。
在本申請另一優選的實施例中,在第三權重計算模塊之前,還包括:
歸併模塊,用於對樣本集中的各樣本數據進行歸併;
歸併記錄模塊,用於對歸併後的樣本數據,記錄所述樣本數據的歸併數量。
在本申請另一優選的實施例中,所述第三權重計算模塊,包括:
降權係數計算模塊,用於利用每條樣本數據的時間信息,計算降權係數;
第一計算模塊,用於計算所述降權係數與歸併數量之積,得到第三權重。
在本申請另一優選的實施例中,所述結果發送模塊633還用於,如果接收到匯集指令,將各個樣本數據的第三權重進行匯總得到的第一係數發送至匯集伺服器。
所述匯集伺服器620包括:
匯集計算模塊621,用於匯總各第一梯度並計算第二權重;
第二權重發送模塊622,用於向各訓練伺服器發送最新的第二權重。
在本申請另一優選的實施例中,所述匯集伺服器包括:
第一加權匯總模塊,用於根據各第一梯度及與各第一梯度相應的第一係數,進行加權計算得到第二梯度;
第二權重計算模塊,用於根據第二梯度計算第二權重。
在本申請另一優選的實施例中,所述匯集伺服器還包括:
備份模塊,用於將新得到的第二權重進行備份。
在本申請另一優選的實施例中,所述備份模塊包括:
變化計算模塊,用於所述匯集伺服器判斷新得到的第二權重與至少前一次備份的第二權重之間的變化量是否超過變化閾值;
第一備份模塊,用於如果超過變化閾值,則對所述新得到的第二權重進行備份。
在本申請另一優選的實施例中,所述備份模塊之後,還包括:
輸出模塊,用於將所述第二權重代入目標模型,並輸出至業務伺服器。
本說明書中的各個實施例均採用遞進的方式描述,每個實施例重點說明的都是與其他實施例的不同之處,各個實施例之間相同相似的部分互相參見即可。
本領域內的技術人員應明白,本申請實施例的實施例可提供為方法、裝置、或電腦程式產品。因此,本申請實施例可採用完全硬體實施例、完全軟體實施例、或結合軟體和硬體方面的實施例的形式。而且,本申請實施例可採用在一個或多個其中包含有計算機可用程序代碼的計算機可用存儲介質(包括但不限於磁碟存儲器、cd-rom、光學存儲器等)上實施的電腦程式產品的形式。
在一個典型的配置中,所述計算機設備包括一個或多個處理器(cpu)、輸入/輸出接口、網絡接口和內存。內存可能包括計算機可讀介質中的非永久性存儲器,隨機存取存儲器(ram)和/或非易失性內存等形式,如只讀存儲器(rom)或快閃記憶體(flashram)。內存是計算機可讀介質的示例。計算機可讀介質包括永久性和非永久性、可移動和非可移動媒體可以由任何方法或技術來實現信息存儲。信息可以是計算機可讀指令、數據結構、程序的模塊或其他數據。計算機的存儲介質的例子包括,但不限於相變內存(pram)、靜態隨機存取存儲器(sram)、動態隨機存取存儲器(dram)、其他類型的隨機存取存儲器(ram)、只讀存儲器(rom)、電可擦除可編程只讀存儲器(eeprom)、快閃記憶體或其他內存技術、只讀光碟只讀存儲器(cd-rom)、數字多功能光碟(dvd)或其他光學存儲、磁盒式磁帶,磁帶磁磁碟存儲或其他磁性存儲設備或任何其他非傳輸介質,可用於存儲可以被計算設備訪問的信息。按照本文中的界定,計算機可讀介質不包括非持續性的電腦可讀媒體(transitorymedia),如調製的數據信號和載波。
本申請實施例是參照根據本申請實施例的方法、終端設備(系統)、和電腦程式產品的流程圖和/或方框圖來描述的。應理解可由電腦程式指令實現流程圖和/或方框圖中的每一流程和/或方框、以及流程圖和/或方框 圖中的流程和/或方框的結合。可提供這些電腦程式指令到通用計算機、專用計算機、嵌入式處理機或其他可編程數據處理終端設備的處理器以產生一個機器,使得通過計算機或其他可編程數據處理終端設備的處理器執行的指令產生用於實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能的裝置。
這些電腦程式指令也可存儲在能引導計算機或其他可編程數據處理終端設備以特定方式工作的計算機可讀存儲器中,使得存儲在該計算機可讀存儲器中的指令產生包括指令裝置的製造品,該指令裝置實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能。
這些電腦程式指令也可裝載到計算機或其他可編程數據處理終端設備上,使得在計算機或其他可編程終端設備上執行一系列操作步驟以產生計算機實現的處理,從而在計算機或其他可編程終端設備上執行的指令提供用於實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能的步驟。
儘管已描述了本申請實施例的優選實施例,但本領域內的技術人員一旦得知了基本創造性概念,則可對這些實施例做出另外的變更和修改。所以,所附權利要求意欲解釋為包括優選實施例以及落入本申請實施例範圍的所有變更和修改。
最後,還需要說明的是,在本文中,諸如第一和第二等之類的關係術語僅僅用來將一個實體或者操作與另一個實體或操作區分開來,而不一定要求或者暗示這些實體或操作之間存在任何這種實際的關係或者順序。而且,術語「包括」、「包含」或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者終端設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者終端設備所固有的要素。在沒有更多限制的情況下,由語句「包括一個……」限定的要素,並不排除在包括所述要素的過程、方法、物品或者終端設備中還存在另外的相同要素。
以上對本申請所提供的一種分布式集群訓練方法和一種分布式集群訓練裝置,進行了詳細介紹,本文中應用了具體個例對本申請的原理及實施方式進行了闡述,以上實施例的說明只是用於幫助理解本申請的方法及其核心思想;同時,對於本領域的一般技術人員,依據本申請的思想,在具體實施方式及應用範圍上均會有改變之處,綜上所述,本說明書內容不應理解為對本申請的限制。