基於內存的MapReduce引擎數據處理方法和裝置與流程
2023-05-03 20:47:31 4
本發明涉及到MapReduce引擎數據處理領域,特別是涉及到一種基於內存的MapReduce引擎數據處理方法和裝置。
背景技術:
自大數據處理技術Hadoop問世以來,其中的數據處理引擎MapReduce性能的優化一直是業界比較關心的問題。
以reduce為例,每個Map輸出文件(MOF)中的整個分區(partition,P1)會被拷貝到Reduce端,然後所有分區(P1,P1,P1)會合併成為一個有序的總的集合(P1),最後做Reduce,由於數據量的不可控,上述拷貝環節內存溢出不可避免,隨後合併及進行Reduce過程中也會產生更多硬碟IO的訪問。
目前業界在MapReduce中減少IO的方法主要是用壓縮(compression)與結合(combination),基於內存的mapreduce就是mellanox公司的UDA(Unstructured DataAccelerator)做過流水線化(Pipelining)的嘗試,但是它主要是基於硬體的加速技術,而且由於shuffle協議的設計限制,每個批次只shuffle少量數據,沒有實現大吞吐量。
技術實現要素:
本發明的主要目的為提供一種通過軟體實現的數據大吞吐量的基於內存的MapReduce引擎數據處理方法和裝置。
為了實現上述發明目的,本發明首先提出一種基於內存的MapReduce引擎數據處理方法,包括:
將每個分區的Map輸出結果數據進行粒度切割,並將切割後的粒度進行排序;
將每個分區切割後的粒度進行多批次shuffle,並將各批次的數據依次進行拷貝、合併和reduce的流水線式數據處理,將reduce進程處理的數據控制在內存中。
進一步地,所述將每個分區切割後的粒度進行多批次shuffle,並將各批次的數據依次進行拷貝、合併和reduce的流水線式數據處理,將reduce進程處理的數據控制在內存中的步驟,包括:
Reduce進程的每個處理過程為自主運行的子線程,各子線程之間通過共享的先進先出異步的消息隊列進行通信。
進一步地,所述將每個分區切割後的粒度進行多批次shuffle,並將各批次的數據依次進行拷貝、合併和reduce的流水線式數據處理,將reduce進程處理的數據控制在內存中的步驟,包括:
所述流水線式數據處理多批次並發運行,根據可用內存的大小除以每個批次配置的內存大小控制並發的批次數。
進一步地,所述將每個分區的Map輸出結果數據進行粒度切割,並將切割後的粒度進行排序的步驟之前,包括:
通過所述流水線式處理指定批次數據後,同步所有reduce一次;
所述將每個分區的Map輸出結果數據進行粒度切割,並將切割後的粒度進行排序的步驟之後,包括:
按相對bucket ID排序來存MOF文件,相應地按同樣順序來預緩存。
進一步地,所述將每個分區切割後的粒度進行多批次shuffle,並將各批次的數據依次進行拷貝、合併和reduce的流水線式數據處理,將reduce進程處理的數據控制在內存中的步驟,包括:
粒度內部數據選擇性地排序,如果粒度內部數據未排序,則拷貝後在reduce端進行排序。
本發明還提供一種基於內存的MapReduce引擎數據處理裝置,包括:
切割單元,用於將每個分區的Map輸出結果數據進行粒度切割,並將切割後的粒度進行排序;
流水線單元,用於將每個分區切割後的粒度進行多批次shuffle,並將各批次的數據依次進行拷貝、合併和reduce的流水線式數據處理,將reduce進程處理的數據控制在內存中。
進一步地,所述流水線單元,包括:
共享通信模塊,用於Reduce進程的每個處理過程為自主運行的子線程,各子線程之間通過共享的先進先出異步的消息隊列進行通信。
進一步地,所述流水線單元,包括:
並發運行模塊,用於所述流水線式數據處理多批次並發運行,根據可用內存的大小除以每個批次配置的內存大小控制並發的批次數。
進一步地,所述基於內存的MapReduce引擎數據處理裝置,還包括:
同步單元,通過所述流水線式處理指定批次數據後,同步所有reduce一次;
存儲單元,按相對bucket ID排序來存MOF文件,相應地按同樣順序來預緩存。
進一步地,所述流水線單元,包括:
粒度內部數據處理模塊,用於粒度內部數據選擇性地排序,如果粒度內部數據未排序,則拷貝後在reduce端進行排序。
本發明的基於內存的MapReduce引擎數據處理方法和裝置,通過純軟體方式對MapReduce的reduce進程進行流水線化(pipelining)設計,即對數據進行了分批並發處理,每個批次的shuffle或拷貝,合併(merge)與reduce可控制在內存中(In-Memory)中進行,極大地減少了IO的訪問與延遲;還可以根據可用內存的多少來調節並發批次的數目,從而提高了mapreduce引擎的吞吐量與整體性能,實測結果是原來的1.6倍-2倍以上。
附圖說明
圖1為本發明一實施例的基於內存的MapReduce引擎數據處理方法的流程示意圖;
圖2為本發明一實施例的流水線化的Reduce進程示意圖;
圖3為本發明一實施例的基於內存的MapReduce引擎數據處理方法的流程示意圖;
圖4為本發明一實施例的Reduce進程間按批次同步處理基於zookeeper的示意圖;
圖5為本發明一實施例的bucket ID的映射關係的示意圖;
圖6為本發明一實施例的基於內存的MapReduce引擎數據處理裝置的結構示意框圖;
圖7為本發明一實施例的流水線單元的結構示意框圖;
圖8為本發明一實施例的基於內存的MapReduce引擎數據處理裝置的結構示意框圖。
本發明目的的實現、功能特點及優點將結合實施例,參照附圖做進一步說明。
具體實施方式
應當理解,此處所描述的具體實施例僅僅用以解釋本發明,並不用於限定本發明。
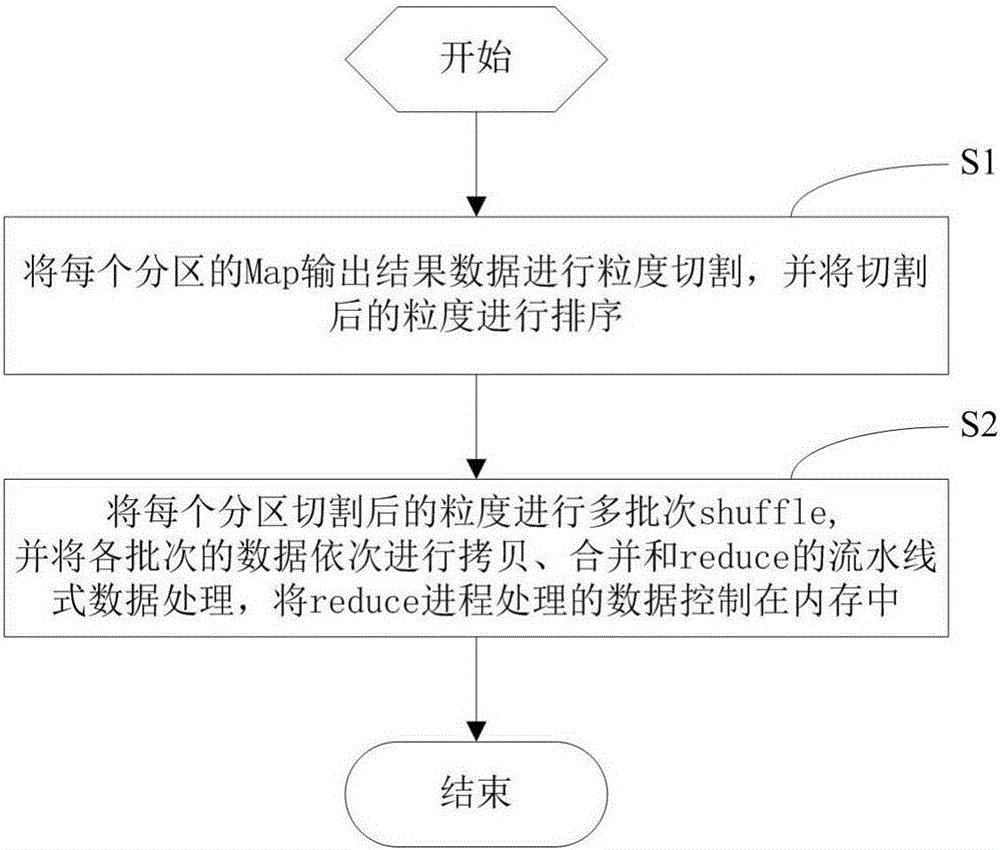
參照圖1,本發明實施例提供一種基於內存的MapReduce引擎數據處理方法,包括步驟:
S1、將每個分區的Map輸出結果數據進行粒度切割,並將切割後的粒度進行排序;
S2、將每個分區切割後的粒度進行多批次shuffle,並將各批次的數據依次進行拷貝、合併和reduce的流水線式數據處理,將reduce進程處理的數據控制在內存中。
如上述步驟S1所述,對原來每個分區(partition)的數據進行了更細粒度(bucket)的切割,為了實現後續流水化的數據處理,bucket之間必須有序。本實施例中,
如上述步驟S2所述,為了實現流水化作業,相比原生的shuffle整個分區的協議,新的shuffle協議會把一個分區進行多批次(pass)shuffle,每個批次只按次序拷貝原來整個分區數據的子集(bucket),這樣通過調整bucket的大小,reduce進程的處理的數據就可控制在內存中。通過純軟體方式對MapReduce的reduce進程進行流水線化(pipelining)設計,即對數據進行了分批次處理,每個批次的shuffle或拷貝,合併(merge)與reduce可控制在內存中(In-Memory)中進行,極大地減少了IO的訪問與延遲;還可以根據可用內存的多少來調節並發批次的數目,從而提高了mapreduce引擎的吞吐量與整體性能。
參照圖2,本實施例中,上述將每個分區切割後的粒度進行多批次shuffle,並將各批次的數據依次進行拷貝、合併和reduce的流水線式數據處理,將reduce進程處理的數據控制在內存中的步驟S2,包括:
S21、Reduce進程的每個處理過程為自主運行的子線程,各子線程之間通過共享的先進先出異步的消息隊列進行通信。
如上述步驟S21所述,拷貝線程(fetcher)完成後會通知合併線程(merger),合併線程完成後會通知reduce線程(reducer),由於每個批次間保持有序,reducer可以不必等剩餘的數據拷貝過來而直接做reduce計算,整個過程中,數據訪問可以控制在內存中進行,延遲會大幅度地降低。
本實施例中,上述將每個分區切割後的粒度進行多批次shuffle,並將各批次的數據依次進行拷貝、合併和reduce的流水線式數據處理,將reduce進程處理的數據控制在內存中的步驟S2,包括:
S22、上述流水線式數據處理多批次並發運行,根據可用內存的大小除以每個批次配置的內存大小控制並發的批次數。
如上述步驟S22所述,根據內存的可用大小適配地進行並發運行,相比原生方法,吞吐量極大提高。
本實施例中,上述將每個分區切割後的粒度進行多批次shuffle,並將各批次的數據依次進行拷貝、合併和reduce的流水線式數據處理,將reduce進程處理的數據控制在內存中的步驟,包括:
S23、上述粒度內部數據選擇性地排序,如果粒度內部數據未排序,則拷貝後在reduce端進行排序。
如上述步驟S23所述,如果粒度內部的數據不排序,則可以拷貝後在reduce端進行排序,這樣就把一些排序的cpu消耗從map端轉移到了reduce端,這對map端cpu成為瓶頸的作業具有減壓幫助。
參照圖3、圖4和圖5,本實施例中,上述將每個分區的Map輸出結果數據進行粒度切割,並將切割後的粒度進行排序的步驟S1之前,包括:
S11、同步單元,通過所述流水線式處理指定批次數據後,同步所有reduce一次;
上述將每個分區的Map輸出結果數據進行粒度切割,並將切割後的粒度進行排序的步驟S1之後,包括:
S12、存儲單元,按相對bucket ID排序來存MOF文件,相應地按同樣順序來預緩存。
如上述步驟S11所述,由於reduce啟動順序的差異化,以及節點計算能力還有網絡的差異化,每個reduce運行的批次(pass)差異化有時會很明顯,比如一個reduce在運行pass 0,另一個reduce在運行pass 5,如此對於MOF的按批次的預緩存是個考驗,內存可能不夠cache這麼多從0到5批次的數據,需要一種同步機制來鎖住(lock)批次,等所有reduce完成相同批次的處理後,統一進入下一批次的處理,以保證MOF的cache被擊中(hit)。參照圖4,由於各個reduce可能分布在不用的節點上,本實施例採用了hadoop系統中的節點同步機制zookeeper來實現,控制每隔開指定數量的批次同步一次所有reduce,也就是說reduce之間差異化不會超過指定數量個批次。
參照圖5,如上述步驟S12所述,由於多批次shuffle,每個reduce都從相對的bucket 0開始按順序進行,我們按相對bucket ID排序來存MOF文件,相應地按同樣順序來預緩存(cache)的新方法,有效地減少了隨機IO的機率,增加了cache擊中(hit)機率。
本實施例中,由於流水線化後成了基於內存的計算,內存的使用與管理對性能的影響也非常大,基於Java虛擬機(JVM)管理的內存受垃圾回收(Garbbage Collection)性能的限制,明顯不適合本發明。本發明採用了從系統直接分配內存然後自己管理,而不使用JVM。
在一具體實施例中,做一種對比試驗,進行4、實驗數據比較分析,如下:
(1)測試環境:4數據節點
hadoop軟體-三大供應商CDH,HDP,MAPR結果類似
CPU 2x8核
RAM 128GB
Disk 2TBx12
(2)實測結果,如下表:
從上表可以看出,本發明顯著提高了MapReduce自身的數據處理能力,大概是原來的1.6倍-2倍。
本實施例的基於內存的MapReduce引擎數據處理方法,通過純軟體方式對MapReduce的reduce進程進行流水線化(pipelining)設計,即對數據進行了分批並發處理,每個批次的shuffle或拷貝,合併(merge)與reduce可控制在內存中(In-Memory)中進行,極大地減少了IO的訪問與延遲;還可以根據可用內存的多少來調節並發批次的數目,從而提高了mapreduce引擎的吞吐量與整體性能,實測結果是原來的1.6倍-2倍以上。
參照圖6,本發明實施例還提供一種基於內存的MapReduce引擎數據處理裝置,包括:
切割單元10,用於將每個分區的Map輸出結果數據進行粒度切割,並將切割後的粒度進行排序;
流水線單元20,用於將每個分區切割後的粒度進行多批次shuffle,並將各批次的數據依次進行拷貝、合併和reduce的流水線式數據處理,將reduce進程處理的數據控制在內存中。
如上述切割單元10,對原來每個分區(partition)的數據進行了更細粒度(bucket)的切割,為了實現後續流水化的數據處理,bucket之間必須有序。本實施例中,
如上述流水線單元20,為了實現流水化作業,相比原生的shuffle整個分區的協議,新的shuffle協議會把一個分區進行多批次(pass)shuffle,每個批次只按次序拷貝原來整個分區數據的子集(bucket),這樣通過調整bucket的大小,reduce進程的處理的數據就可控制在內存中。通過純軟體方式對MapReduce的reduce進程進行流水線化(pipelining)設計,即對數據進行了分批次處理,每個批次的shuffle或拷貝,合併(merge)與reduce可控制在內存中(In-Memory)中進行,極大地減少了IO的訪問與延遲;還可以根據可用內存的多少來調節並發批次的數目,從而提高了mapreduce引擎的吞吐量與整體性能。
參照圖7,本實施例中,上述流水線單元20,包括:
共享通信模塊21,用於Reduce進程的每個處理過程為自主運行的子線程,各子線程之間通過共享的先進先出異步的消息隊列進行通信。
如上述共享通信模塊,拷貝線程(fetcher)完成後會通知合併線程(merger),合併線程完成後會通知reduce線程(reducer),由於每個批次間保持有序,reducer可以不必等剩餘的數據拷貝過來而直接做reduce計算,整個過程中,數據訪問可以控制在內存中進行,延遲會大幅度地降低。
本實施例中,上述流水線單元20,包括:
並發運行模塊22,用於所述流水線式數據處理多批次並發運行,根據可用內存的大小除以每個批次配置的內存大小控制並發的批次數。
如上述並發運行模塊,根據內存的可用大小適配地進行並發運行,相比原生方法,吞吐量極大提高。
本實施例中,上述流水線單元20,包括:
粒度內部數據處理模塊23,用於粒度內部數據選擇性地排序,如果粒度內部數據未排序,則拷貝後在reduce端進行排序。
如上述粒度內部數據處理模塊23,如果粒度內部的數據不排序,則可以拷貝後在reduce端進行排序,這樣就把一些排序的cpu消耗從map端轉移到了reduce端,這對map端cpu成為瓶頸的作業具有減壓幫助。
參照圖8,本實施例中,上述基於內存的MapReduce引擎數據處理裝置,還包括:
同步單元110,通過所述流水線式處理指定批次數據後,同步所有reduce一次;
存儲單元120,按相對bucket ID排序來存MOF文件,相應地按同樣順序來預緩存。
如上述同步單元110,由於reduce啟動順序的差異化,以及節點計算能力還有網絡的差異化,每個reduce運行的批次(pass)差異化有時會很明顯,比如一個reduce在運行pass 0,另一個reduce在運行pass 5,如此對於MOF的按批次的預緩存是個考驗,內存可能不夠cache這麼多從0到5批次的數據,需要一種同步機制來鎖住(lock)批次,等所有reduce完成相同批次的處理後,統一進入下一批次的處理,以保證MOF的cache被擊中(hit)。參照圖4,由於各個reduce可能分布在不用的節點上,本實施例採用了hadoop系統中的節點同步機制zookeeper來實現,控制每隔開指定數量的批次同步一次所有reduce,也就是說reduce之間差異化不會超過指定數量個批次。
參照圖5,如上述存儲單元120,由於多批次shuffle,每個reduce都從相對的bucket 0開始按順序進行,我們按相對bucket ID排序來存MOF文件,相應地按同樣順序來預緩存(cache)的新方法,有效地減少了隨機IO的機率,增加了cache擊中(hit)機率。
本實施例中,由於流水線化後成了基於內存的計算,內存的使用與管理對性能的影響也非常大,基於Java虛擬機(JVM)管理的內存受垃圾回收(Garbbage Collection)性能的限制,明顯不適合本發明。本發明採用了從系統直接分配內存然後自己管理,而不使用JVM。
在一具體實施例中,做一種對比試驗,進行4、實驗數據比較分析,如下:
(1)測試環境:4數據節點
hadoop軟體-三大供應商CDH,HDP,MAPR結果類似
CPU 2x8核
RAM 128GB
Disk 2TBx12
(2)實測結果,如下表:
從上表可以看出,本發明顯著提高了MapReduce自身的數據處理能力,大概是原來的1.6倍-2倍。
本實施例的基於內存的MapReduce引擎數據處理裝置,通過純軟體方式對MapReduce的reduce進程進行流水線化(pipelining)設計,即對數據進行了分批並發處理,每個批次的shuffle或拷貝,合併(merge)與reduce可控制在內存中(In-Memory)中進行,極大地減少了IO的訪問與延遲;還可以根據可用內存的多少來調節並發批次的數目,從而提高了mapreduce引擎的吞吐量與整體性能,實測結果是原來的1.6倍-2倍以上。
以上所述僅為本發明的優選實施例,並非因此限制本發明的專利範圍,凡是利用本發明說明書及附圖內容所作的等效結構或等效流程變換,或直接或間接運用在其他相關的技術領域,均同理包括在本發明的專利保護範圍內。