一種基於非易失性存儲器的頻繁模式挖掘方法與流程
2023-05-03 13:50:11 6
本發明屬於存儲器技術領域,具體涉及一種用於NVM的頻繁模式挖掘方法。
背景技術:
中國專利文獻CN106250549A於2016年12月21日公開了一種基於內存的頻繁模式挖掘方法,它包括以下步驟:步驟1,構建頻繁模式初始樹,創建頻繁模式樹的根結點T,以「null」標記;再次掃描資料庫,將讀取的每條事務中的頻繁項選出並按L中的次序排序;排序後以null為根結點構建一條頻繁模式樹的路徑,只對路徑上位於最末的結點的計數加1,路徑上的其他結點的計數保持不變;依次掃描完整個資料庫中所有事務後獲得頻繁模式初始樹;步驟2,用深度優先搜索算法對頻繁模式初始樹依次進行遍歷,遍歷結點的計數器值為該結點本身的值加上其所有孩子結點的值。該專利能減少對NVM的寫操作,能快速的構建頻繁模式樹;且能減少對靠近根結點的結點計數域大量密集的寫操作,延長了NVM壽命。
但是,當待挖掘的數據集非常大,用該專利的方法構建樹的效率很低,有必要探索一種快速構建頻繁模式樹的方法。
技術實現要素:
針對現有技術中存在的技術問題,本發明所要解決的技術問題就是提供一種基於非易失性存儲器的頻繁模式挖掘方法,它在挖掘大數據集時,能夠快速構建頻繁模式樹。
本發明所要解決的技術問題是通過這樣的技術方案實現的,它包括以下步驟:
步驟1、利用多核系統對頻繁模式樹進行並行構建
先將資料庫中的多條交易記錄大致均勻地分配到每個核中,利用CN106250549A記載的方法,在每一個核上構建一棵本地頻繁模式樹;
步驟2、對步驟1所構建的頻繁模式樹進行合併
將本地頻繁模式樹的信息搜集起來,合併成一棵大的全局頻繁模式樹。
由於本發明採用並行構建頻繁模式樹,大幅度縮短了構建的時間,提高了構建頻繁模式樹的效率,解決了挖掘大數據集時構建樹的速度慢的問題。
附圖說明
本發明的附圖說明如下:
圖1為本發明構建頻繁模式樹的示意圖;
圖2為brute-force合併樹的流程圖;
圖3為本發明合併樹的流程圖;
圖4為實驗中讀操作的測試效果圖;
圖5為實驗中寫操作的測試效果圖;
圖6為實驗中構建全局樹時間的測試效果圖;
圖7為本發明與現有並行構建樹時間的對比圖。
具體實施方式
下面結合附圖和實施例對本發明作進一步說明:
本發明應用於多核系統中,硬體包含有CPU、存儲器管理單元MMU、作為內存的NVM等,NVM直接連接在內存總線上。發明應用的上下文環境為:上層是應用層,下層具體的硬體,存儲器包括NVM以及SSD等。應用層發出操作請求,對作為內存的NVM進行操作。
如圖1所示,對本發明包括以下步驟:
步驟1、利用多核系統對頻繁模式樹進行並行構建
先將資料庫中的多條交易記錄大致均勻地分配到每個核中,利用CN106250549A記載的方法,在每一個核上構建一棵本地頻繁模式樹;例如總共十條交易記錄以及3個核,大致均勻分配後每個核的交易記錄條數為3、3、4;每個核根據分配到的交易記錄來構建一棵樹。
步驟2、對步驟1所構建的頻繁模式樹進行合併
將本地頻繁模式樹的信息搜集起來,合併成一棵大的全局頻繁模式樹。
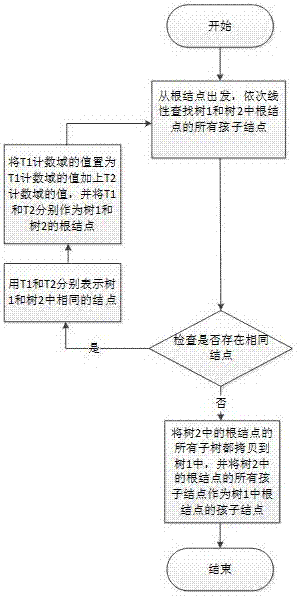
Brute-force是現有的一種合併樹的方法,用brute-force方法合併樹1和樹2的步驟,流程圖如圖2所示:
步驟1)、從根結點出發,依次線性查找樹1和樹2中根結點的所有孩子結點,檢查是否存在相同結點,如存在,用T1和T2分別表示樹1和樹2中相同的結點,然後執行步驟2);如不存在,則執行步驟3);
步驟2)、T1計數域的值=T1計數域的值+T2計數域的值,並將T1和T2分別作為樹1和樹2的根結點,返回步驟1);
步驟3)、將樹2中的根結點的所有子樹都拷貝到樹1中,並將樹2中根結點的所有孩子結點作為樹1中根結點的孩子結點;
步驟4)、程序結束。
採用本發明上述步驟構建頻繁模式樹時,如果沒有優化的管理,會產生許多不必要的讀寫操作,帶來巨大的內存開銷,降低構建樹的效率,且大量的讀寫操作會導致NVM的使用壽命減少。
針對合併過程中多次拷貝操作帶來的寫開銷的問題,在上述步驟1中,構建本地頻繁模式樹時,採用左孩子右兄弟鍊表結構來存儲結點信息。(左孩子右兄弟鍊表結構的參見文獻:T. H. Cormen, C. Stein, R. L. Rivest, and C. E. Leiserson. Introduction to Algorithms.McGraw-Hill Higher Education, 2nd edition, 2001. ( T. H. Cormen, C. Stein, R. L. Rivest, and C. E. Leiserson. 算法導論.McGraw-Hill高等教育, 第二版, 2001.))
以下為本發明中合併樹1和樹2的步驟,流程圖如圖3所示:
步驟(1)、從根結點出發,將樹1的根結點的最末孩子結點的兄弟指針指向樹2的根結點的第一個孩子結點;
步驟(2)、利用所建立的哈希表查找樹1和樹2根結點的孩子結點中是否存在相同結點,如存在,用T1和T2分別表示樹1和樹2中相同的結點,然後執行步驟(3);如不存在,則執行步驟(5);
步驟(3)、T1計數域的值=T1計數域的值+T2計數域的值,並將T2結點從該鍊表中刪除;
步驟(4)、將T1和T2分別作為樹1和樹2的根結點,返回步驟(1);
步驟(5)、結束程序。
上述步驟(1)-(5)直接將相同父結點的所有孩子結點結點連結起來,如果在這些孩子結點中有重複的結點,則將這些孩子結點的計數域的值相加並存儲到其中一個結點中,再將其他重複的孩子結點從孩子結點鏈中刪除。通過連結結點的方式避免了在內存空間中拷貝已經存儲過的結點,能夠有效減少合併本地頻繁模式樹的過程中大量的不必要的內存寫操作,減少寫開銷,提高性能,降低能耗。
針對合併過程中對指定結點查找效率低的問題以及避免多次查找指定結點操作帶來的讀開銷問題,在上述步驟1中,在構建頻繁模式初始樹過程中創建新節點時,為根結點T以下的孩子結點建立了哈希表(建立哈希表參見文獻:T. H. Cormen, C. Stein, R. L. Rivest, and C. E. Leiserson. Introduction to Algorithms.McGraw-Hill Higher Education, 2nd edition, 2001. ( T. H. Cormen, C. Stein, R. L. Rivest, and C. E. Leiserson. 算法導論.McGraw-Hill高等教育, 第二版, 2001.))。在建立哈希表時僅存儲孩子結點的項目名稱以節省空間,用該結點的孩子結點數目作為關鍵字,採用直接取餘法建立哈希表,並利用鍊表法解決哈希衝突。
由於為結點建立了哈希表,在合併頻繁模式樹時能夠快速定位到指定結點,能避免線性查找法對子結點進行挨個查找。當某些結點的孩子結點較多時,可有效減少對結點的讀操作,提高查找效率,加快樹的合併。
試驗測試
選取不同類型的數據集進行試驗,統計各個數據集的讀寫操作總量和總的構建樹的時間。這些數據集的名稱分別為T10I4D100K、T40I10D100K、retail、chess、mushroom、pumsb*、connect、pumsb、accidents、C73D10、C20D10、T20I6D100。
測試時,本發明與單核採用背景技術方法構建的樹以及多核採用brute-force方法合併的樹相對比,其中以單核構建方法作為基準對結果進行歸一化處理,實驗結果參見圖4至圖7。
圖4中,縱坐標代表讀的總量,橫坐標代表各個數據集,從圖4看出,本發明減少了大量的讀操作;
圖5中,縱坐標代表寫的總量,橫坐標代表各個數據集,從圖5看出,本發明減少了大量的寫操作;
圖6中,縱坐標代表總的構建樹的時間,橫坐標代表各個數據集,從圖6看出,本發明減少了構建樹的時間,本發明最少可減少的建樹時間為15.45%(發生在數據集C73D10),最大可減少58.09%(發生在數據集T10I4D100K),極大地增加了構建樹的效率。
圖7中,縱坐標代表總的構建樹的時間,橫坐標代表不同的核數,從圖7看出,隨著核數的增多,本發明減少了構建樹的時間,且減少得比brute-force算法多。