一種汽車的自動駕駛方法及裝置與流程
2023-05-15 02:06:21 4
本發明屬於汽車自動駕駛技術領域,尤其涉及一種汽車的自動駕駛方法及裝置。
背景技術:
近年來,隨著經濟的發展和城鎮化的推進,全球汽車保有量和道路裡程逐步增加,諸如交通擁堵、事故、汙染、土地資源緊缺等一系列傳統汽車無法妥善解決的問題日益凸顯。智能汽車技術被視為有效解決方案,其發展備受矚目。美國電氣和電子工程師協會(ieee)預測,至2040年自動駕駛車輛所佔的比例將達到75%。
市面上已經出現了多種用於輔助駕駛系統的傳感器和產品,比如:雷射雷達、自適應巡航系統、車輛接近通報裝置、夜視輔助裝置、自適應前照明系統等,而目前輔助駕駛系統中使用的控制方法都是基於規則的控制決策,即根據已知的駕駛經驗,構建對車況信息輸出控制決策的專家規則系統。然而,自動駕駛場景類別多樣,路況複雜,自動駕駛中高度複雜的場景很難用有限的規則來定義清楚,因此,傳統的控制方法往往難以滿足自動駕駛的要求。類似專家規則系統利用了淺層學習算法,淺層學習算法可以看作是從被標記的數據之間尋找規則的過程,當規則很難被抽象成公式或簡單邏輯之時,淺層學習算法就難以達到預定的效果。深度學習算法對感知有非常強的能力,在圖像識別、語音識別等領域已經取得了極大的突破,然而,深度學習算法並不能把這種感知轉化為決策能力。
技術實現要素:
本發明的目的在於提供一種汽車的自動駕駛方法及裝置,旨在解決由於現有技術無法提供一種有效的自動駕駛動作決策方法,導致自動駕駛汽車在面臨駕駛場景類別多樣、路況複雜時難以做出及時、有效的駕駛動作的問題。
一方面,本發明提供了一種汽車的自動駕駛方法,所述方法包括下述步驟:
通過汽車上預設的傳感器獲取所述汽車當前位置的汽車狀態;
根據所述汽車狀態和預先建立的策略網絡模型,獲取所述汽車當前可用駕駛動作的回報值,所述策略網絡模型通過預設的深度強化學習算法建立;
將所述回報值中的最大回報值對應的當前可用駕駛動作設置為所述汽車下一執行動作並執行。
另一方面,本發明提供了一種汽車的自動駕駛裝置,所述裝置包括:
狀態獲取單元,用於通過汽車上預設的傳感器獲取所述汽車當前位置的汽車狀態;
回報值獲取單元,用於根據所述汽車狀態和預先建立的策略網絡模型,獲取所述汽車當前可用駕駛動作的回報值,所述策略網絡模型通過預設的深度強化學習算法建立;以及
動作執行單元,用於將所述回報值中的最大回報值對應的當前可用駕駛動作設置為所述汽車下一執行動作並執行。
本發明通過汽車上預設的傳感器獲取汽車當前位置的汽車狀態,根據該汽車狀態和預先通過深度強化學習算法建立的策略網絡模型,獲取汽車當前可用駕駛動作的回報值,將回報值中的最大回報值對應的當前可用駕駛動作設置為汽車下一執行動作並執行,從而在面臨駕駛場景類別多樣、路況複雜時及時、有效地獲取到較優的駕駛動作並執行,實現汽車的自動駕駛。
附圖說明
圖1是本發明實施例一提供的汽車的自動駕駛方法的實現流程圖;
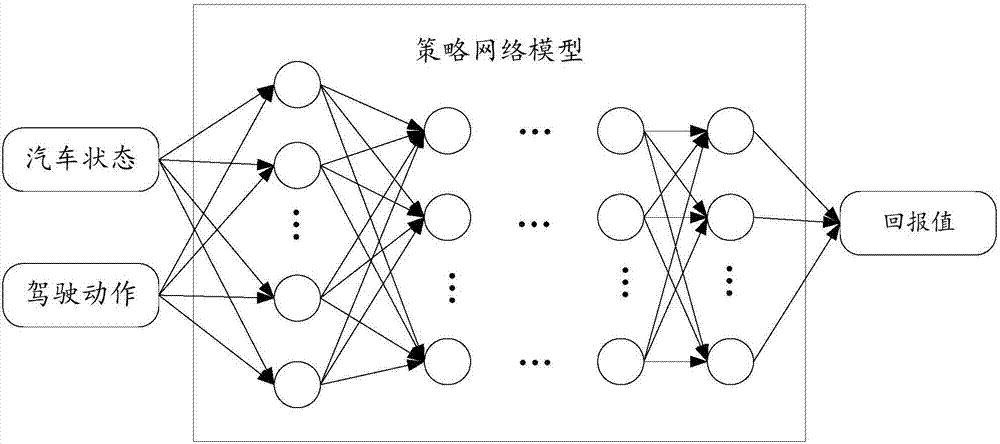
圖2是本發明實施例一提供的汽車的自動駕駛方法的實現示意圖;
圖3是本發明實施例二提供的汽車的自動駕駛裝置的結構示意圖;以及
圖4是本發明實施例三提供的汽車的自動駕駛裝置的結構示意圖。
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,以下結合附圖及實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅僅用以解釋本發明,並不用於限定本發明。
以下結合具體實施例對本發明的具體實現進行詳細描述:
實施例一:
圖1示出了本發明實施例一提供的汽車的自動駕駛方法的實現流程,為了便於說明,僅示出了與本發明實施例相關的部分,詳述如下:
在步驟s101中,通過汽車上預設的傳感器獲取汽車當前位置的汽車狀態。
本發明實施例適用於汽車、汽車上的自動駕駛平臺或設備,汽車狀態是指汽車行駛過程中的一種狀態,可用汽車輪胎、方向盤、發動機等各部件的當前參數值表示,具體可從汽車上設置或安裝的各類傳感器(例如,雷達、超聲、視覺傳感器等)獲取。作為示例地,狀態可通過表示汽車離道路中線的距離、汽車前進方向與道路切向的夾角以及汽車在道路切向上的速度分量等參數進行表示。
在步驟s102中,根據汽車狀態和預先建立的策略網絡模型,獲取汽車當前可用駕駛動作的回報值,策略網絡模型通過預設的深度強化學習算法建立。
在本發明實施例中,預先建立一策略網絡模型,該策略網絡模型通過預設的深度強化學習算法建立,從而汽車在實際高度複雜、易變的道路環境下快速準確地進行決策。如圖2所示,通過該策略網絡模型可準確獲得汽車當前可用駕駛動作的回報值,即每個駕駛動作的評價值或獎勵,可以認為評價值或獎勵越大,對應的駕駛動作越準確。
優選地,通過下述步驟建立該策略網絡模型:
a、對設置的策略網絡模型進行初始化,設定汽車駕駛動作的立即回報函數,並對立即回報函數的回報值進行初始化;
b、接收汽車當前訓練狀態的樣本,根據當前訓練狀態以及立即回報函數計算汽車的動作集中每個駕駛動作的立即回報值,獲取立即回報值中的最大立即回報值;
c、將所述汽車狀態和通過預設方式選擇的駕駛動作作為策略網絡模型的輸入值,將最大立即回報值和策略網絡模型不同駕駛動作下的最大回報值的累計折算值之和作為輸出值,對策略網絡模型進行訓練,並更新策略網絡模型的權值;
d、根據當前訓練狀態和立即回報值對應的駕駛動作,獲取汽車的下一狀態,判斷下一狀態是否為終止訓練狀態,是則返回策略網絡模型,否則將下一狀態設置為當前訓練狀態的樣本並傳送給步驟b,從而進入策略網絡模型的下一輪訓練。
在本發明實施例中,策略網絡模型具體為一系列函數,以在通過樣本訓練後得到較為精確的權值,從而在輸入汽車狀態和動作時,得到對應的回報值,而立即回報函數則反映了僅考慮當前狀態時實施一駕駛動作所得到的回報。作為示例地,例如,立即回報函數可以為r=δdis*cos(α*angle)*sgn(trackpos-threshold),其中,δdis表示相鄰狀態跑過的有效距離,angle表示行駛方向與道路切線夾角,α表示權重縮放因子,sgn符號函數在汽車離道路中線的距離trackpos大於預設閾值threshold的時候,取值無窮小,意在表達車輛太靠近道路邊界時的懲罰。
在本發明實施例中,在步驟c中選擇駕駛動作時,可按隨機選取或小概率隨機選取任一駕駛動作作為選擇的駕駛動作,否則將步驟b中最大回報值對應的駕駛動作作為選擇的駕駛動作。另外,由於有些駕駛動作並不能用於當前訓練狀態,因此,在根據當前訓練狀態以及立即回報函數計算汽車的動作集中每個駕駛動作的立即回報值時,優選地,可先根據當前訓練狀態對汽車的動作集中的駕駛動作進行篩選,根據當前訓練狀態以及立即回報函數計算篩選後的每個駕駛動作的立即回報值,從而減少遍歷動作集中動作的時間,提高策略網絡模型的訓練速度。
可選地,在對策略網絡模型進行訓練時,可通過後向傳播算法對策略網絡模型進行訓練,在通過後向傳播算法對策略網絡模型進行訓練時,將汽車狀態和通過預設方式選擇的駕駛動作作為策略網絡模型的輸入值,將該汽車狀態下的最大立即回報值和策略網絡模型不同駕駛動作下的最大回報值的累計折算值之和作為輸出值,從而在訓練時考慮駕駛中未來環境的不確定性,進一步提高策略網絡模型訓練時的真實性,提高策略網絡模型中權值的準確度。
在步驟s103中,將回報值中的最大回報值對應的當前可用駕駛動作設置為汽車下一執行動作並執行。
在本發明實施例中,若通過汽車狀態和訓練好的策略網絡模型獲取到最大回報值,則說明該最大回報值對應的駕駛動作是當前汽車在當前位置汽車狀態下的最佳選擇,因此,將該最大回報值對應的當前可用駕駛動作設置為汽車下一執行動作並執行。
在本發明實施例中,通過汽車上預設的傳感器獲取汽車當前位置的汽車狀態,根據該汽車狀態和預先通過深度強化學習算法建立的策略網絡模型,獲取汽車當前可用駕駛動作的回報值,將回報值中的最大回報值對應的當前可用駕駛動作設置為汽車下一執行動作並執行,從而在面臨駕駛場景類別多樣、路況複雜時及時、有效地獲取到較優的駕駛動作並執行,實現汽車的自動駕駛。
本領域普通技術人員可以理解實現上述實施例方法中的全部或部分步驟是可以通過程序來指令相關的硬體來完成,所述的程序可以存儲於一計算機可讀取存儲介質中,所述的存儲介質,如rom/ram、磁碟、光碟等。
實施例二:
圖3示出了本發明實施例二提供的汽車的自動駕駛裝置的結構,為了便於說明,僅示出了與本發明實施例相關的部分,其中包括:
狀態獲取單元31,用於通過汽車上預設的傳感器獲取汽車當前位置的汽車狀態;
回報值獲取單元32,用於根據汽車狀態和預先建立的策略網絡模型,獲取汽車當前可用駕駛動作的回報值,其中,策略網絡模型通過預設的深度強化學習算法建立;以及
動作執行單元33,用於將回報值中的最大回報值對應的當前可用駕駛動作設置為汽車下一執行動作並執行。
在本發明實施例中,自動駕駛裝置的各單元可由相應的硬體或軟體單元實現,各單元可以為獨立的軟、硬體單元,也可以集成為一個軟、硬體單元,在此不用以限制本發明。各單元的具體實施方式可參考實施一的描述,在此不再贅述。
實施例三:
圖4示出了本發明實施例三提供的汽車的自動駕駛裝置的結構,為了便於說明,僅示出了與本發明實施例相關的部分,其中包括:
初始化單元41,用於對設置的策略網絡模型進行初始化,設定汽車駕駛動作的立即回報函數,並對立即回報函數的回報值進行初始化;
最大值獲取單元42,用於接收汽車當前訓練狀態的樣本,根據當前訓練狀態以及立即回報函數計算汽車的動作集中每個駕駛動作的立即回報值,獲取立即回報值中的最大立即回報值;
動作篩選單元43,用於隨機選取任一駕駛動作作為選擇的駕駛動作,否則將最大回報值對應的駕駛動作作為選擇的駕駛動作;
權值更新單元44,用於將汽車狀態和通過預設方式選擇的駕駛動作作為策略網絡模型的輸入值,將最大立即回報值和策略網絡模型不同駕駛動作下的最大回報值的累計折算值之和作為輸出值,對策略網絡模型進行訓練,並更新策略網絡模型的權值;
結果處理單元45,用於根據當前訓練狀態和立即回報值對應的駕駛動作,獲取汽車的下一狀態,判斷下一狀態是否為終止訓練狀態,是則返回策略網絡模型,否則將下一狀態設置為當前訓練狀態的樣本並傳送給最大值獲取單元;
狀態獲取單元46,用於通過汽車上預設的傳感器獲取汽車當前位置的汽車狀態;
回報值獲取單元47,用於根據汽車狀態和預先建立的策略網絡模型,獲取汽車當前可用駕駛動作的回報值,其中,策略網絡模型通過預設的深度強化學習算法建立;以及
動作執行單元48,用於將回報值中的最大回報值對應的當前可用駕駛動作設置為汽車下一執行動作並執行。
在本發明實施例中,最大值獲取單元42包括回報值計算單元421,用於根據當前訓練狀態對汽車的動作集中的駕駛動作進行篩選,根據當前訓練狀態以及立即回報函數計算篩選後的每個駕駛動作的立即回報值。權值更新單元44包括模型訓練單元441,用於通過後向傳播算法對策略網絡模型進行訓練。
在本發明實施例中,自動駕駛裝置的各單元可由相應的硬體或軟體單元實現,各單元可以為獨立的軟、硬體單元,也可以集成為一個軟、硬體單元,在此不用以限制本發明。各單元的具體實施方式可參考實施一的描述,在此不再贅述。
以上所述僅為本發明的較佳實施例而已,並不用以限制本發明,凡在本發明的精神和原則之內所作的任何修改、等同替換和改進等,均應包含在本發明的保護範圍之內。