基於主成分分析與支持向量機的變壓器絕緣狀態評估方法與流程
2023-05-12 09:21:56 6
本發明屬於電力變壓器設備狀態檢測技術領域,特別涉及一種基於主成分分析與參數尋優支持向量機的變壓器絕緣狀態評估方法。
背景技術:
隨著電網容量的增大和用戶對供電可靠性要求的提高,電力設施維修費用佔電力成本的比例也在不斷提高,電力設備狀態維修管理的重要性日益顯現。如何採取合理的維修策略與制定正確的維修計劃,以保證在不降低可靠性的前提下節省維修費用,成為電力部門面臨的重要課題。狀態檢修是以設備的當前實際工作狀況為依據,通過先進的狀態監測手段、可靠的評價手段與壽命的預測手段來判斷設備的狀態,並根據分析診斷結果在設備性能下降到一定程度或故障將要發生之前進行維修。然而由於變壓器是一個固體、液體複合絕緣的複雜系統,其老化、故障機理複雜,具有不確定性,因此,變壓器絕緣狀態評估是一項複雜而艱巨的任務。
支持向量機是數據挖掘中的一項新技術。它具有嚴格的理論和數學基礎,基於結構風險最小化原則,其泛化能力優越,算法具有全局最優性。將支持向量機應用到變壓器絕緣狀態評估中,可以可靠地尋找出變壓器各項指標數據與變壓器運行狀態的之間的聯繫和規律。
主成分分析是一種基於多元統計分析的數據壓縮與信息提取技術,通過構造新的變量組來降低原始數據空間維數,再從新的映射空間提取統計特徵向量,來反映原始數據空間的數據特性,使問題變的更加簡單、直觀。
技術實現要素:
本發明的目的在於提供一種基於主成分分析與參數尋優支持向量機的變壓器絕緣狀態評估方法,該方法可以通過變壓器的相關指標數據判斷出變壓器的運行狀態,並且具有較高的準確率和可靠度。
為了達到上述目的,本發明所採用的技術方案是:
基於主成分分析與支持向量機的變壓器絕緣狀態評估方法,評估步驟如下:
步驟一、分別獲取變壓器油中溶解氣體數據、變壓器電氣試驗數據以及絕緣油特性試驗數據作為訓練支持向量機的輸入數據;獲取變壓器對應的絕緣狀態等級數據作為訓練支持向量機的輸出數據;
步驟二、用半嶺模型對各項輸入數據進行預評估並實現數據的歸一化;
半嶺模型的評分函數包括降半嶺模型評分函數與升半嶺模型評分函數兩種,其公式分別為:
其中,a和b是模型的閾值,分別對應每項變壓器評分參數的初始值和注意值;x是評分參數的實際測量值,f(x)為評分的結果值;對於f(x)數值越大越好的指標,採用升半嶺模型,反之採用降半嶺模型;
將步驟一所述的輸入數據分別作為步驟二對應公式的自變量x的值,求得因變量f(x)的值即為該項數據的預評估結果;預評估結果f(x)的取值範圍在0到1之間;
步驟三、利用主成分分析法對預評估後的輸入數據進行降維處理,得到新的輸入樣本集;
步驟四、用改進的粒子群算法對支持向量機的核函數參數g和懲罰參數c進行尋優;
其中,粒子群算法的改進內容為,設置可以非線性自適應調整的慣性權重w,從而更好地平衡局部和全局搜索能力;慣性權重w描述了粒子上一代速度對當前代速度的影響水平,對其採用改進的非線性遞減算法,通過在粒子群算法早期加快慣性權重的遞減速度,使該算法更快地進入局部搜索;改進後粒子群算法的速度更新公式及慣性權重w的表達式分別如下:
式中,v為當前粒子的速度;x為當前粒子的位置;p為個體最優位置;g為全局最優位置;c1、c2為學習因子,分別用於調節粒子向個體最優位置p和全局最優位置g飛行的步長;r1、r2為介於[0,1]之間的隨機數;k為當前迭代次數;i為當前粒子標號;d是維數的標號;w為慣性權重,它描述了粒子上一代速度對當前代速度的影響水平;kmax為最大允許迭代次數;k為當前的迭代次數;wmax和wmin分別是最大慣性權重和最小慣性權重;
步驟五、用降維處理後的輸入樣本集與變壓器對應的絕緣狀態等級數據訓練支持向量機,得到最終的支持向量機模型;
步驟六、用最終的支持向量機模型處理待評估的變壓器溶解氣體數據、變壓器電氣試驗數據以及絕緣油特性試驗數據,從而獲得變壓器的絕緣狀態等級。
所述步驟一中,所述變壓器油中溶解氣體數據包括H2、C2H2、CH4、C2H6、C2H4、總烴等各種氣體的含量,總烴的產氣速率以及CO2與CO氣體含量的比值;所述變壓器電氣試驗數據包括變壓器介質損耗因數、繞組洩漏電流、絕緣電阻、吸收比、繞組直流電阻相間差;所述絕緣油特性試驗數據包括絕緣油介損、油中含水量、糠醛含量;所述變壓器絕緣狀態等級數據包括優秀、良好、注意、異常、嚴重五種狀態。
所述步驟三中,利用主成分分析法對預評估後的輸入數據進行降維處理的步驟為:
a)計算m維樣本數據的線性組合相關係數矩陣R:
首先求取m維樣本數據X的均值向量μ,其中m維樣本數據X=(X1,X2,…Xm)T,Xi=(Xi1,Xi2,…Xin)表示第i組輸入樣本數據的值,其中i表示樣本序號,i=1,2,…n,n表示總樣本數;其次對所得的樣本數據X去均值化,得到去均值後的樣本向量然後對樣本向量構建協方差矩陣即得到相關係數矩陣R;
b)計算相關係數矩陣R的特徵值與特徵向量:
求出相關係數矩陣R的特徵值λi(i=1,2,…,m),並將λi按從大到小的順序排列,即λ1≥λ2≥…≥λm≥0,λi的大小表示對應的主成分對變壓器評估特徵的貢獻程度;然後分別求出對應於特徵值λi的特徵向量;
c)確定累計貢獻率ci,當累計貢獻率ci≥ρ時,取前k個特徵向量Wk=[w1,w2…,wk],作為子空間的基,其中ρ為常數,取ρ≥85%;其中,
d)確定所提取的k個主成分為其中k<n,F即為用主成分分析法降維後的新的樣本集。
所述步驟四中,用改進的粒子群算法對支持向量機的核函數參數g和懲罰參數c進行優化的過程如下:
過程1:初始化粒子群粒子的位置和速度,並初始化支持向量機的參數:懲罰參數c和RBF核函數參數g;
過程2:評價粒子群中每個粒子的適應度,計算每個粒子的適應度函數;
過程3:對於每個粒子,將其當前位置的適應度與其經歷過的最好位置pbest的適應度作比較,選擇適應度最大時的位置作為當前粒子的最好位置pbest;
過程4:對每個粒子,將其適應度與經歷過的全局最好位置gbest的適應度作比較,如果粒子的適應度更好則重新設置gbest;
過程5:用改進的粒子速度更新公式更新粒子的位置和速度;
過程6:當迭代次數或者適應值滿足條件,則終止迭代,獲得優化最佳的支持向量機參數;否則返回步驟過程3。
本發明的有益效果在於:
(1)本發明利用主成分分析與參數尋優支持向量機相結合的方法對變壓器絕緣狀態進行評估,能夠更加準確、可靠地識別變壓器的狀態等級,從而為變壓器的維修策略提供依據。
(2)本發明用主成分分析法對對變壓器評估數據的樣本集進行降維處理,可以剔除無效特徵、提取有效特徵,提高評估結果的精度。
(3)本發明用改進的粒子群算法對支持向量機的參數進行尋優,參數尋優過程自適應性好、簡單、高效。改進的粒子群算法的慣性權重可以非線性地自適應調整,從而更好地平衡其全局搜索與局部搜索能力。
(4)本發明用半嶺模型對變壓器的原始數據進行預評估,降低了原始數據冗餘信息的幹擾,提高了評估數據的有效性。
附圖說明
圖1為本發明的變壓器絕緣狀態評估方法的流程圖。
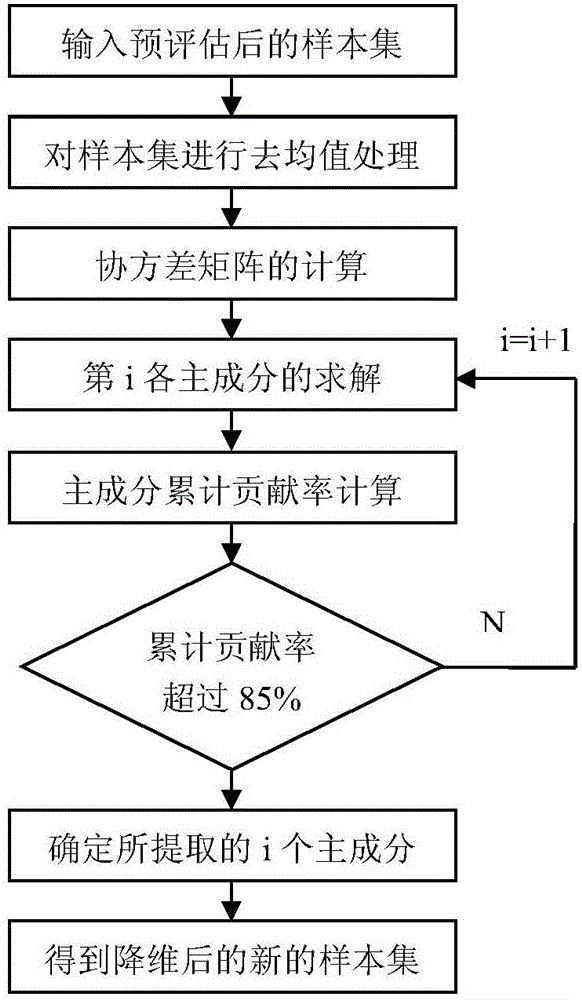
圖2為本發明中用主成分分析法對樣本數據進行降維處理的流程圖。
圖3為本發明中改進的粒子群算法的流程圖。
具體實施方式
下面結合附圖和具體實施方式對本發明進行詳細說明。
本發明一種基於主成分分析與支持向量機的變壓器絕緣狀態評估方法,其流程圖如圖1所示,具體按照以下步驟實施:
步驟一、分別獲取變壓器油中溶解氣體數據、變壓器電氣試驗數據以及絕緣油特性試驗數據作為訓練支持向量機的輸入數據;獲取變壓器對應的狀態等級數據作為訓練支持向量機的輸出數據;
其中,變壓器油中溶解氣體數據包括H2、C2H2、CH4、C2H6、C2H4、總烴等各種氣體的含量,總烴的產氣速率以及CO2與CO氣體含量的比值;變壓器電氣試驗數據包括變壓器介質損耗因數、繞組洩漏電流、絕緣電阻、吸收比、繞組直流電阻相間差;絕緣油特性試驗數據包括絕緣油介損、油中含水量、糠醛含量;變壓器絕緣狀態等級數據包括優秀、良好、注意、異常、嚴重五種狀態,分別用數字1、2、3、4、5表示;變壓器絕緣狀態等級與其數字代碼、狀態描述以及對應的維修策略如下表所示:
步驟二、用半嶺模型對各項輸入數據進行預評估並實現數據的歸一化;
半嶺模型的評分函數包括降半嶺模型評分函數與升半嶺模型評分函數兩種,其公式分別為:
其中,a和b是模型的閾值,分別對應每項變壓器評分參數的初始值和注意值;x是評分參數的實際測量值,f(x)為評分的結果值。對於f(x)數值越大越好的指標,採用升半嶺模型,反之採用降半嶺模型。
將步驟一所述的輸入數據分別作為步驟二對應公式的自變量x的值,求得因變量f(x)的值即為該項數據的預評估結果。預評估結果f(x)的取值範圍在0到1之間。
步驟三、利用主成分分析法對預評估後的輸入數據進行降維處理,得到新的輸入樣本集;
如圖2所示,利用主成分分析法對預評估後的m維樣本數據進行降維處理的步驟為:
a)計算m維樣本數據的線性組合相關係數矩陣R:
首先求取m維樣本數據X的均值向量μ,其中m維樣本數據X=(X1,X2,…Xm)T,Xi=(Xi1,Xi2,…Xin)表示第i組輸入樣本數據的值,其中i表示樣本序號,i=1,2,…n,n表示總樣本數;其次對所得的樣本數據X去均值化,得到去均值後的樣本向量然後對樣本向量向量構建協方差矩陣即得到相關係數矩陣R;
b)計算相關係數矩陣R的特徵值與特徵向量:
求出相關係數矩陣R的特徵值λi(i=1,2,…,m),並將λi按從大到小的順序排列,即λ1≥λ2≥…≥λm≥0,λi的大小表示對應的主成分對變壓器評估特徵的貢獻程度;然後分別求出對應於特徵值λi的特徵向量;
c)確定累計貢獻率ci,當累計貢獻率ci≥ρ時,優選地取前k個特徵向量Wk=[w1,w2…,wk],作為子空間的基,其中ρ為常數,一般取ρ≥85%;其中,
d)確定所提取的k個主成分為其中k<n,F即為用主成分分析法降維後的新的樣本集。
步驟四、用改進的粒子群算法對支持向量機的核函數參數g和懲罰參數c進行尋優;
如圖3所示,用改進的粒子群算法對支持向量機的核函數參數g和懲罰參數c進行優化的過程如下:
過程1:初始化粒子群粒子的位置和速度,並初始化支持向量機的參數:懲罰參數c和RBF核函數參數g;
過程2:評價粒子群中每個粒子的適應度,計算每個粒子的適應度函數;
適應度函數選擇支持向量機的輸出分類決策函數,其公式為:
其中,a1為每個訓練樣本所對應的拉格朗日係數;佔K(zi,z)為核函數(K(zi,z)=exp(-|zi-z|2/g2));C為懲罰參數,b為偏置。
過程3:對於每個粒子,將其當前位置的適應度與其經歷過的最好位置pbest的適應度作比較,選擇適應度最大時的位置作為當前粒子的最好位置pbest;
過程4:對每個粒子,將其適應度與經歷過的全局最好位置gbest的適應度作比較,如果粒子的適應度更好則重新設置gbest;
過程5:用改進的粒子速度更新公式更新粒子的位置和速度;
其中,粒子群算法的改進內容為,設置可以非線性自適應調整的慣性權重w,從而更好地平衡局部和全局搜索能力。慣性權重w描述了粒子上一代速度對當前代速度的影響水平,對其採用改進的非線性遞減算法,通過在粒子群算法早期加快慣性權重的遞減速度,使該算法更快地進入局部搜索。改進後粒子群算法的速度更新公式及慣性權重w的表達式分別如下:
式中,v為當前粒子的速度;x為當前粒子的位置;p為個體最優位置;g為全局最優位置;c1、c2為學習因子,分別用於調節粒子向個體最優位置p和全局最優位置g飛行的步長;r1、r2為介於[0,1]之間的隨機數;k為當前迭代次數;i為當前粒子標號;d是維數的標號;w為慣性權重,它描述了粒子上一代速度對當前代速度的影響水平;kmax為最大允許迭代次數;k為當前的迭代次數;wmax和wmin分別是最大慣性權重和最小慣性權重;
過程6:當迭代次數或者適應值滿足條件,則終止迭代,獲得優化最佳的支持向量機參數;否則返回步驟過程3。
步驟五、用降維處理後的輸入樣本集與變壓器對應的狀態等級數據訓練支持向量機,得到最終的支持向量機模型;
步驟六、用該支持向量機模型處理待評估的變壓器溶解氣體數據、變壓器電氣試驗數據以及絕緣油特性試驗數據,從而獲得變壓器的絕緣狀態等級。
最後,對變壓器絕緣狀態評估實例進行分析,選取50組變壓器樣本數據訓練支持向量機,對另外6組變壓器數據進行評估,最終,其評估結果與變壓器的實際狀態一致。
上面雖然結合附圖對本發明的具體實施方式進行了描述,但並非對本發明保護範圍的限制,在本發明的技術方案的基礎上,本領域技術人員不需要付出創造性勞動即可做出的各種修改或變形仍在本發明的保護範圍以內。