一種風力發電機組偏航自動矯正控制方法與流程
2023-05-04 20:34:01 3
本發明涉及風力發電機組偏航控制的技術領域,尤其是指一種風力發電機組偏航自動矯正控制方法。
背景技術:
風力發電機組在運行過程中,常常需要調度機艙進行偏航,使風機正確對風,以跟蹤最佳風速來獲得更高的風能轉化效率,從而得到優質的發電功率。而偏航的前提是準確獲知風輪附近的風向,這要求機艙上的風向儀能夠正確工作。然而隨著機械部件的磨損或傳感部件的靈敏度衰減等原因,風向儀硬體上無法保證傳回數據有足夠的準確度,此時寄望於通過軟體的適當處理,使風機獲取正確的偏航對風角度偏移量。
當前,已有一些文獻對偏航矯正提出改進的方法,如:金風科技提出了一種通過分風速段篩選出偏航角度實測值及對應發電功率,並通過數據擬合獲取最終偏移量的方法[1],文中只設計了結構框架,未對具體的數據分析處理辦法做出描述。此外,金風還提出了一種根據實測偏航角度以及從功率計算出的理論偏航角度求差值,進而推算出偏航誤差角的方法[2],該方法僅以當前檢測偏航角度為比較對象,而單一採樣數據可能存在一定的偶然性,如果能進一步考慮充足的樣本數,則能將偶然性降得更低。普華億能則提出了一種風速風向校準系統[3],該系統需要標準風速計和風向計,測試風速計和風向計共四個硬體儀器,通過測試組與標準組的對比,判斷是否存在故障,該系統需要進行硬體上的擴充,在一定程度上增加風機成本。
風機組在實際運行的時候,會將偏航角度實測值和發電機功率等參數數據大量記錄下來,一般而言,這種原始的採樣點往往不會非常顯著而直觀地呈現出某種趨勢或規律,需要通過統計和分析加工之後才會顯現出來。我們在後期可以利用MATLAB等高級數據分析工具進行處理,得到我們想要的結果。而當前風機組控制器一般為PLC(可編程邏輯控制單元),採用結構化文本(ST語言)進行程序編寫,雖然已可提供相當的運算處理能力和算法實現的可能性,但仍然難以完成複雜度過高的算法,基於上述原因,以及控制程序本身的體量,希望將加入的擴展程序的運算量控制在一定程度以下。故針對現有硬體水平,我們設計了一種計算量小,結構簡潔,但精確度較高的獲取偏移量數據分析處理方法,根據本方法完成偏航自動矯正處理。
參考文獻及專利:
[1]風力發電機組對風矯正控制方法、裝置和系統
[2]偏航誤差角獲得方法及偏航控制方法/裝置和風力發電機組
[3]一種風速風向校準系統
技術實現要素:
本發明的目的在於克服現有技術的缺點和不足,提供一種風力發電機組偏航自動矯正控制方法,該方法計算量小,並能夠獲取精確度較高的偏移量數據,可以很好地完成偏航自動矯正處理。
為實現上述目的,本發明所提供的技術方案為:一種風力發電機組偏航自動矯正控制方法,包括以下步驟:
1)數據採集工作
設定數據篩選條件:根據機組運行狀態(限功率、正常併網、結冰等),將機組運行情況進行初步篩選,獲取同一風速附近的機組功率及對應的風機位置與風向偏差角度值等有效數據,為防止冗餘計算,先對往年的偏航動作發生風速段進行統計,將「風速」設定為偏航次數發生較多的風速段;
規定數據採集時間:根據經驗判斷設定具體的限定範圍,可統計一段時間內偏航次數,計算出相鄰兩次偏航間隔時間,結合算法本身運算量,確定合適的採樣時間;或以獲取數據的量作為判準,當統計存儲的數據量達到指定目標時,完成數據採集;
2)數據分析處理工作
2.1)數據預處理:設定數據剔除條件,將不合理的大誤差點剔除,完成二次篩選;
2.2)將二次篩選後的數據視作平面上分布的點群,再對平面進行區域劃分;其中,先確定好平面的區域範圍,這裡即指同一風速附近下發電機功率上、下限pmax和pmin以及對應偏航角度值的最大、最小值θmax和θmin;
2.3)當pmax、pmin、θmax和θmin值確定後,在平面坐標下劃出該風速附近數據採樣點分布的範圍,並將數據分布的矩形平面按照指定步長分成多個網格,如下:
2.3.1)將偏航角度設定為每N度為一個間隔,即將橫坐標[θmin,θmax]以N為步長進行等分,N為正數(可以根據精確度及計算量的需求,在控制器允許的精度範圍內折中選取一個量值),[θmin+N·(i-1),θmin+N·i]為第i列的坐標範圍,其中θmin+N·i≤θmax,i=1,2,3,…,n;
2.3.2)將發電機功率設定為每M千瓦為一個間隔,即將縱坐標[pmin,pmax]以M為步長進行等分,M為正數(可以根據精確度及計算量的需求,在控制器允許的精度範圍內折中選取一個量值),[pmin+M·(j-1),pmin+M·j]為第j行的坐標範圍,其中pmin+M·j≤pmax,j=1,2,3,…,m;
2.4)根據步驟2.3)的劃分,得到每一個網格的坐標範圍,而不同數據點分屬於各網格內,易知計算精度與同一平面內的網格數呈正相關關係,當網格尺度越小,同一平面內網格數越多,擬合出的結果精度越高,網格尺度即前述橫縱坐標的步長,其網格尺度可根據精確度的要求自由調整;
2.5)根據每一個採樣點的坐標,判斷其分屬於哪個網格之內,統計出每一網格內採樣點的數目kji;
2.6)接著統計出相同橫坐標間隔內,縱向所有網格,即一列網格內所有採樣點的數目rj;
2.7)將單個網格內點的數目比上網格所在列的總採樣點數,即ωji=kji/rj,把該比值作為網格所佔權重;
2.8)將網格的中心點,即矩形對角線的交點的坐標(θmin+N·i-0.5N,pmin+M·j-0.5M)作為網格的坐標,對同一列的全體網格,將其中心點縱坐標值乘以所佔權重,相加結果作為該列的縱坐標橫坐標(θmin+N·i-0.5N)作為該列中點坐標,即對應偏航角度值;
2.9)將計算結果ci,即相應發電機功率值的大小根據冒泡法排序,得到發電機功率最高的在前的一些點,對這些點的橫坐標(θmin+N·i-0.5N)進行求平均值處理,將最終的結果作為風機偏航的偏移量;
2.10)將偏航對風角度實測值減去此偏移量,作為後續偏航對風角度值。
本發明與現有技術相比,具有如下優點與有益效果:
1、本發明充分考慮了風力發電機組的控制器運算處理單元的計算能力和所帶程式語言的結構特點,設計了一種精簡而易處理,運算量較小且具備足夠精度的數據處理分析方法。
2、本發明方法可內置於主控程序中,隨風機的運行而不斷收集數據,當獲取一定量的採樣點後,經預處理,將數據按行列分組,對分組後的數據求加權平均值,其處理過程僅涉及將數據分類存儲、加權運算以及排序處理,運算量小且易於實現。
3、根據統計學原理,樣本數據足夠大的時候,出現在某一區域數據點的數目與總數的比值可近似表徵數據點落入該區域的概率,故通過將概率化為權值的處理辦法,可以在理論上保證其保有足夠的精確度。
附圖說明
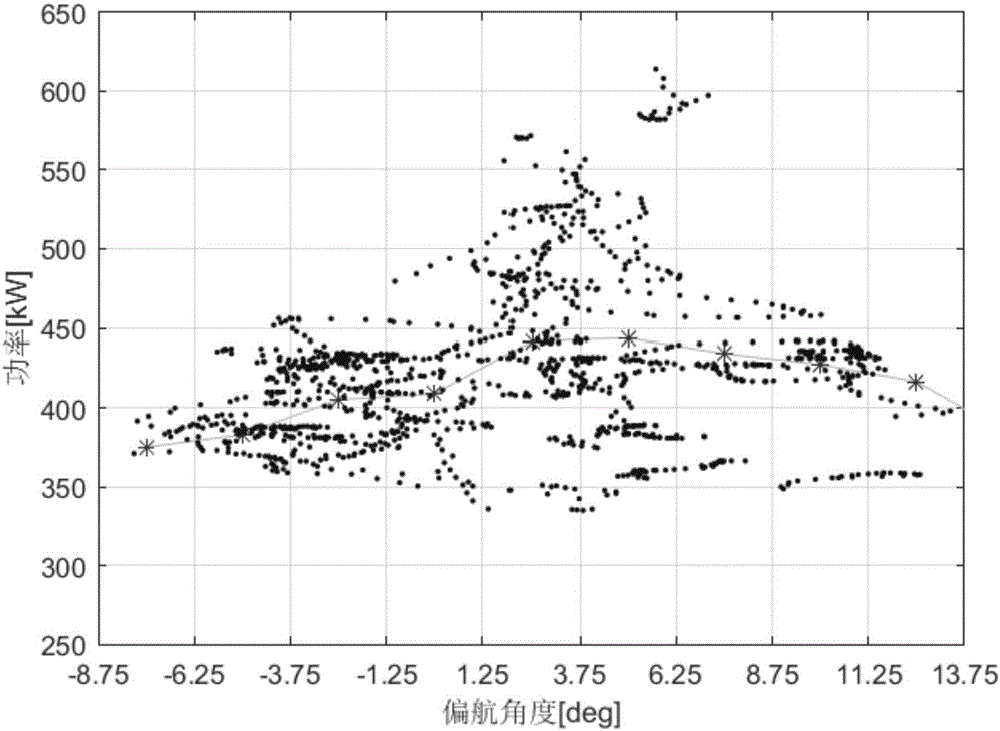
圖1為風機的功率與偏航角度的關係圖。
圖2為風機的功率與偏航角度的數據點分布圖。
圖3為本發明方法的流程圖。
圖4a為算法擬合與Matlab函數擬合結果對比圖之一。
圖4b為算法擬合與Matlab函數擬合結果對比圖之二。
圖4c為算法擬合與Matlab函數擬合結果對比圖之三。
具體實施方式
下面結合具體實施例對本發明做進一步的說明。
由風力發電機組偏航基本原理可知,如圖1所示,同一風速條件下,風機正對風的時候,對應著發電機的功率峰值,所以在理想狀態,即風向儀不存在誤差的時候,其功率峰值應當在零點或其附近的位置出現。當一定時間內,偏航角度-發電機功率關系統計結果顯示發電機功率峰值對應偏航角度不為0時,說明風向儀的測量結果產生了偏差,而在實際風機組中獲取的數據結果是如圖2所示的大量零散的點,根據這些數據點進行統計分析以及進一步的處理,計算出此時的功率峰值對應偏航角度的值,然後將此偏差量換算成偏航角度的偏移量,並在程序中進行修正,即可在軟體上完成風向儀矯正處理,使得風機能繼續正確偏航。在此基礎上,本實施例提供的風力發電機組偏航自動矯正控制方法,如圖3所示,包括以下步驟:
1)數據採集工作
首先,需要設定好具體數據篩選條件:根據機組運行狀態(限功率、正常併網、結冰等),將機組運行情況進行初步篩選,獲取同一風速附近的機組功率及對應的風機位置與風向偏差角度值等有效數據,為防止冗餘計算,先對往年的偏航動作發生風速段進行統計,將「風速」設定為偏航次數發生較多的風速段;然後規定具體的數據採集時間:根據經驗判斷設定具體的限定範圍,可統計一段時間內偏航次數,計算出相鄰兩次偏航間隔時間,結合算法本身運算量,確定合適的採樣時間;或以獲取數據的量作為判準,當統計存儲的數據量達到指定目標時,完成數據採集。
2)數據採集工作完畢以後,進行數據分析處理工作
2.1)數據預處理:設定數據剔除條件,將不合理的大誤差點剔除,以風速為例,最小風速為0m/s,最大風速取風場過去一年內統計風速最大值,範圍之外的數據屬於顯著誤差,予以剔除;完成二次篩選;
2.2)將二次篩選後的數據視作平面上分布的點群,再對平面進行區域劃分;其中,先確定好平面的區域範圍,這裡即指同一風速附近下發電機功率上、下限pmax和pmin以及對應偏航角度值的最大、最小值θmax和θmin;
2.3)當pmax、pmin、θmax和θmin值確定後,在平面坐標下劃出該風速附近數據採樣點分布的範圍,並將數據分布的矩形平面按照指定步長分成多個網格(如圖2所示),如下:
2.3.1)將偏航角度設定為每2.5度為一個間隔,即將橫坐標[θmin,θmax]以2.5為步長進行等分,[θmin+2.5·(i-1),θmin+2.5·i]為第i列的坐標範圍,其中θmin+2.5·i≤θmax,i=1,2,3,…,n;
2.3.2)將發電機功率設定為每50kW為一個間隔,即將縱坐標[pmin,pmax]以50為步長進行等分,[pmin+50·(j-1),pmin+50·j]為第j行的坐標範圍,其中pmin+50·j≤pmax,j=1,2,3,…,m;
2.4)根據步驟2.3)的劃分,我們容易得到每一個網格的坐標範圍,而不同數據點分屬於各網格內,易知計算精度與同一平面內的網格數呈正相關關係,當網格尺度越小,同一平面內網格數越多,擬合出的結果精度越高,網格尺度即前述橫縱坐標的步長,其網格尺度可根據精確度的要求自由調整;
2.5)根據每一個採樣點的坐標,判斷其分屬於哪個網格之內,統計出每一網格內採樣點的數目kji;
2.6)接著統計出相同橫坐標間隔內,縱向所有網格,即一列網格內所有採樣點的數目rj;
2.7)將單個網格內點的數目比上網格所在列的總採樣點數,即ωji=kji/rj,把該比值作為網格所佔權重;
2.8)將網格的中心點(即矩形對角線的交點)坐標(θmin+2.5·i-1.25,pmin+50·j-25)作為網格的坐標,對同一列的全體網格,將其中心點縱坐標值乘以所佔權重,相加結果作為該列的縱坐標橫坐標(θmin+2.5·i-1.25)作為該列中點坐標,即對應偏航角度值;
2.9)將計算結果ci,即相應發電機功率值的大小根據冒泡法排序,得到發電機功率最高的前10%的點,對這些點的橫坐標(θmin+2.5·i-1.25)求平均值處理,將最終的結果作為風機偏航的偏移量;
2.10)將偏航對風角度實測值減去此偏移量,作為後續偏航對風角度值。
綜上所述,本發明充分考慮了風力發電機組的控制器運算處理單元的計算能力和所帶程式語言的結構特點,設計了一種精簡而易處理,運算量較小且具備足夠精度的數據處理分析方法。本方法可內置於主控程序中,隨風機的運行而不斷收集數據,當獲取一定量的採樣點後,經預處理,將數據按行列分組,對分組後的數據求加權平均值,其處理過程僅涉及將數據分類存儲、加權運算以及排序處理,運算量小且易於實現;而根據統計學原理,樣本數據足夠大的時候,出現在某一區域數據點的數目與總數的比值可近似表徵數據點落入該區域的概率,故通過將概率化為權值的處理辦法,可以在理論上保證其保有足夠的精確度,如圖4a至圖4c所示,經MATLAB自帶函數大量擬合結果對比證明本方法具備相當的精度,值得推廣。
以上所述實施例只為本發明之較佳實施例,並非以此限制本發明的實施範圍,故凡依本發明之形狀、原理所作的變化,均應涵蓋在本發明的保護範圍內。