文件系統中的元數據索引搜索的製作方法
2023-05-21 10:13:51 1
本發明要求2015年8月20日遞交的發明名稱為「文件系統中的元數據索引搜索(METADATA INDEX SEARCH IN A FILE SYSTEM)」的美國非臨時申請案14/831,292和2014年8月28日遞交的發明名稱為「用於文件系統中的元數據索引搜索的系統和方法(SYSTEM AND METHOD FOR METADATA INDEX SEARCH IN A FILE SYSTEM)」的美國臨時專利申請案62/043,257的在先申請優先權,該在先申請的兩個內容以引用方式併入本文中,如同全文複製一般。
技術領域
無
背景技術:
在計算時,文件系統是用於組織文件且將文件存儲在硬碟驅動器、快閃記憶體驅動器或任何其它存儲設備上的方法和數據結構。文件系統將存儲設備上的數據分成稱為文件的單件。另外,文件系統可以存儲關於文件的數據,例如,文件名、權限、創建時間、修改時間和其它屬性。文件系統可以進一步提供編索引機構,使得用戶可以訪問存儲於存儲設備中的文件。例如,文件系統可以組織成多級目錄,所述多級目錄是文件系統對象,例如文件和/或子目錄的集合。為了到達文件系統中的特定文件系統對象,路徑可以用於指定文件系統中的文件系統對象存儲位置。路徑包括指示目錄、子目錄和/或文件名的字符串。存在多個不同類型的文件系統。不同類型的文件系統可以具有不同結構、邏輯、速度、靈活性、安全性和/或大小。
技術實現要素:
在一個實施例中,本發明包含一種裝置,所述裝置包括:輸入/輸出(input/output,IO)埠,用於耦合到可大規模擴展的存儲設備;存儲器,用於存儲所述可大規模擴展的存儲設備的文件系統的多個元數據資料庫(database,DB),其中所述多個元數據DB包括具有空值的密鑰值對;以及處理器,耦合到所述IO埠和所述存儲器,其中所述處理器用於按時間順序將所述文件系統中的目錄進行分組以將所述文件系統分成多個分區,並且將不同分區的元數據作為密鑰分別存儲在獨立的元數據DB中以為所述文件系統編索引。
在另一實施例中,本發明包含一種裝置,所述裝置包括:IO埠,用於耦合到可大規模擴展的存儲設備;存儲器,用於存儲包括所述可大規模擴展的存儲設備的文件系統的一部分的元數據編索引信息的關係DB以及包括所述元數據編索引信息的至少一部分的表示的布隆過濾器;以及處理器,耦合到所述IO埠和所述存儲器,其中所述處理器用於接收文件系統對象的查詢並且將所述布隆過濾器應用於所述查詢以確定是否搜索所述所查詢文件系統對象的所述關係DB。
在又一實施例中,本發明包含一種用於搜索可大規模擴展的存儲文件系統的方法,包括:接收文件系統對象的查詢,其中所述查詢包括所述所查詢文件系統對象的路徑名的至少一部分;將布隆過濾器應用於所述所查詢文件系統對象的所述路徑名的所述部分,其中所述布隆過濾器包括在所述可大規模擴展的存儲文件系統的特定部分中的路徑名的表示;當所述布隆過濾器傳回肯定結果時,在包括所述特定文件系統部分的元數據編索引信息的關係DB中搜索所述所查詢文件系統對象;以及當所述布隆過濾器傳回否定結果時,跳過搜索所述關係DB中的所述所查詢文件系統對象。
從以下結合附圖以及權利要求書進行的詳細描述將更清楚地理解這些以及其它特徵。
附圖說明
為了更透徹地理解本發明,現參考結合附圖和具體實施方式而描述的以下簡要說明,其中相同參考標號表示相同部分。
圖1是文件存儲系統的實施例的示意圖。
圖2是用作網絡中的節點的網絡元件(network element,NE)的實施例的示意圖。
圖3是文件系統子樹的實施例的示意圖。
圖4是散列表產生方案的實施例的示意圖。
圖5是散列表產生方法的實施例的流程圖。
圖6是布隆過濾器產生方案的實施例的示意圖。
圖7是元數據索引搜索查詢方案的實施例的示意圖。
圖8是元數據索引搜索查詢方法的實施例的流程圖。
圖9是日誌構造合併(Log-Structured Merge,LSM)樹存儲方案的實施例的示意圖。
圖10是文件系統元數據更新方法的實施例的流程圖。
具體實施方式
首先應理解,儘管下文提供一個或多個實施例的說明性實施方案,但所揭示的系統和/或方法可以使用任何數目的技術來實施,無論該技術是當前已知還是現有的。本發明決不應限於下文所說明的說明性實施方案、附圖和技術,包含本文所說明並描述的示例性設計和實施方案,而是可以在所附權利要求書的範圍以及其等效物的完整範圍內修改。
由於文件系統達到數十億個文件、數百萬個目錄和千兆字節數據,因此用戶組織、尋找和管理其文件變得愈加困難。儘管分層命名方案可以易化文件管理並且可以通過採用多級目錄和命名規範而減少文件名衝突,但是分層命名方案的益處在可大規模擴展的文件系統中受限。在可大規模擴展的文件系統中,基於元數據的搜索方案可能對於文件管理和分析更實用且信息量大。文件系統元數據是指與文件有關的任何數據和/或信息。元數據的一些實例可以包含文件類型(例如,文本文檔類型和申請案類型)、文件特徵(例如,音頻和視頻)、文件擴展名(用於文檔的.doc以及用於可執行文件的.exe)、所有者、組、創建日期、修改日期、連結數和大小。然而,在具有數十億文件的可大規模擴展的文件系統中,基於元數據的搜索可能較慢。
本文揭示用於可大規模擴展的文件系統的有效文件元數據索引搜索方案的各種實施例。文件元數據索引搜索方案採用用於將文件系統的元數據保持在多個元數據資料庫(database,DB)中的編索引引擎以及用於基於用戶的文件系統元數據查詢搜索文件系統對象的搜尋引擎。編索引引擎通過基於地點的時間順序散列目錄而將文件系統分成多個分區。例如,可大規模擴展的文件系統可以分成具有約2萬(20K)個目錄和/或約1百萬個文件的分區。可以通過爬行或掃描文件系統的目錄執行編索引。可以按路徑名的順序執行初始爬行(例如,深度優先搜索)。可以按更改時間的順序執行後續爬行或進行中的爬行。因此,基於爬行時間或更改時間組織分區。在初始爬行期間產生元數據DB並且在後續爬行期間更新元數據DB。不同分區的元數據存儲於不同元數據DB中。另外,不同類型的元數據(例如,路徑名、連結數、文件特性、自定義標籤)存儲於不同元數據DB中。因此,可以通過使同一組的文件系統對象相關聯而使多個元數據DB相關,其中多個元數據DB可以被稱為關係DB。通過採用但具有空值的密鑰值對存儲模型來實施元數據DB。空值密鑰值對的採用實現存儲器的更高效使用並且允許更快搜索。在實施例中,元數據DB通過採用LSM樹技術實現有效書寫和/或更新來存儲密鑰值記錄。基於LSM的DB的實例是levelDB。搜尋引擎採用布隆過濾器來減小查詢的搜索空間,例如,排出與查詢不相關的分區和/或元數據DB。在實施例中,不同布隆過濾器用於不同分區。在初始爬行期間在從目錄的散列創建分區之後產生布隆過濾器,並且在後續爬行之後更新布隆過濾器。布隆過濾器可以對路徑名或任何其它類型的元數據操作。在接收查詢之後,搜尋引擎將布隆過濾器應用於查詢以識別可能載送與查詢相關的數據的分區。當特定分區的布隆過濾器指示查詢的肯定匹配時,搜尋引擎進一步搜索與特定分區相關聯的元數據DB。由於布隆過濾器可以消除約百分之(%)90至95時間的不必要搜索,因此文件元數據查詢時間可以顯著減少,例如,查詢的搜索時間可以約為秒。因此,所揭示的文件元數據索引搜索方案允許快速和複雜文件元數據搜索,並且可以提供良好可擴展性以用於可大規模擴展的文件系統中。應注意,在本發明中,目錄名和路徑名是等效的並且可以互換使用。
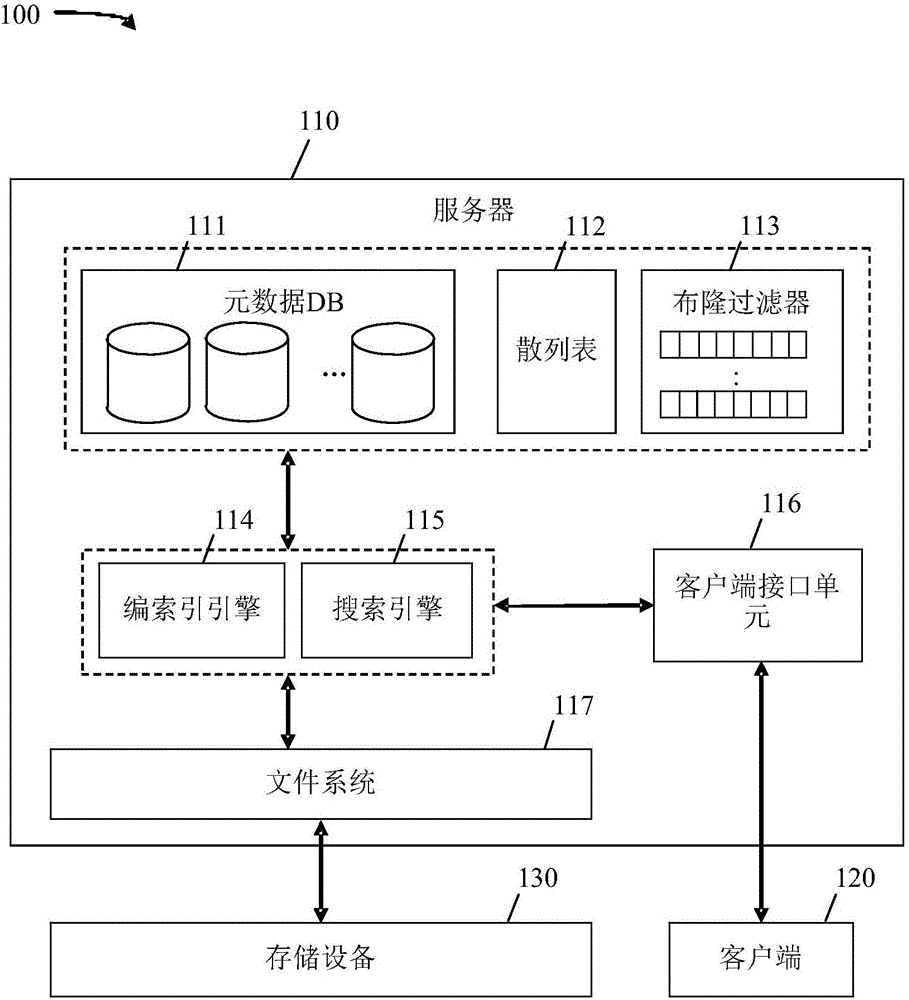
圖1是文件存儲系統100的實施例的示意圖。系統100包括伺服器110、客戶端120和存儲設備130。伺服器110以通信方式耦合到存儲設備130和客戶端120。存儲設備130是適用於存儲數據的任何設備。例如,存儲設備130可以是硬碟驅動器或快閃驅動器。在實施例中,存儲設備130可以是存儲數十億個文件、數百萬個目錄和/或千兆字節數據的可大規模擴展的存儲設備和/或系統。儘管存儲設備130說明為伺服器110的外部組件,但是存儲設備130可以是伺服器110的內部組件。伺服器110管理存儲設備130以用於文件存儲和訪問。客戶端120是向伺服器110查詢存儲於存儲設備130中的文件的用戶或用戶程序。另外,客戶端120可以將文件添加到存儲設備130,修改存儲設備130中的現有文件和/或從存儲設備130刪除文件。在一些實施例中,客戶端120可以通過網絡耦合到伺服器110,所述網絡可以是任何類型的網絡(例如,電網絡和/或光網絡)。
伺服器110是虛擬機(virtual machine,VM)、計算機器、網絡伺服器或用於管理存儲設備130上的文件存儲、文件訪問和/或文件搜索的任何設備。伺服器110包括多個元數據DB 111、散列表112、多個布隆過濾器113、編索引引擎114、搜尋引擎115、客戶端接口單元116和文件系統117。文件系統117是軟體組件,所述軟體組分例如通過輸入/輸出(input/output,IO)埠接口以通信方式耦合到存儲設備130並且用於管理存儲設備130中的文件的命名和存儲位置。例如,文件系統117可以包括到存儲在存儲設備130上的文件的多級目錄和路徑。編索引引擎114是用於管理存儲在存儲設備130上的文件的編索引的軟體組件。編索引引擎114通過元數據為文件編索引,所述元數據可以包含文件的基本名、文件的路徑名和/或任何文件系統屬性,例如,文件類型、文件擴展名、文件大小、文件訪問時間、文件修改時間,文件更改時間、與文件相關聯的連結數、用戶ID、組ID和文件權限。例如,對於在目錄/a/b/c下存儲的文件數據.c,基本名是.c且路徑名是/a/b/c。另外,元數據可以包含自定義屬性和/或標籤,例如,文件特徵(例如,音頻和視頻)和/或基於內容的信息(例如,運動圖像專家組層4視頻(mpeg4))。自定義屬性是為文件定製的特定元數據,例如,通過用戶或客戶端120產生的元數據。
編索引引擎114通過將文件系統117分成多個分區、限制分區的最大大小以及由分區產生元數據索引來提供靈活性和可擴展性。例如,在具有約十億個文件的可大規模擴展的存儲設備中,假設每一目錄具有約50個文件的平均值,則編索引引擎114可以將文件系統117分成具有約1百萬個文件或約2萬(20K)個目錄的約1000個分區。通過將文件系統117分成多個分區,可以更有效地執行搜索,如下文更充分地描述。編索引引擎114通過將散列函數應用於目錄名而將文件系統117分成分區。例如,編索引引擎114可以採用提供均勻隨機分布的任何散列方案,例如,通過將位移和異或函數應用於偽隨機數字而產生散列值的BuzHash方案。編索引引擎114基於地點的時間順序執行分割和編索引。在文件系統117的初始爬行或第一時間爬行期間,編索引引擎114類似於深度優先搜索技術按路徑名的順序穿越或掃描文件系統117。深度優先搜索開始於目錄樹的根處,例如,通過選擇根節點開始,並且在回溯之前儘可能深地沿著每個分支穿越。因此,通過按路徑名的順序掃描和編索引,在初始爬行期間的分割根據掃描時間分組文件和/或目錄。在後續爬行期間,文件編索引引擎114按更改時間的順序穿越文件系統117並且因此根據更改時間穿越文件和/或目錄。文件編索引引擎114在散列表112中生成每個文件系統目錄的條目。例如,散列表112可以包括將目錄名和/或路徑名映射到對應於分區的散列碼的條目,如下文更充分地論述。
在將文件系統117分成分區之後,編索引引擎114產生用於分區的布隆過濾器113。例如,針對每個分區產生布隆過濾器113。布隆過濾器113使搜尋引擎115能夠快速識別可能載送與查詢相關的數據的分區,如下文更充分地論述。布隆過濾器113是最初設定成零的位向量。可以通過將k個(例如,k=4)散列函數應用於元素以在位向量中產生k個位位置並且將位設定成1而將元素添加到布隆過濾器113。元素可以是目錄名(例如,/a/b/c)或目錄名的一部分(例如,/a,/b,/c)。隨後,可以通過用相同散列函數k次散列元素以獲得k個位位置並且檢查對應的位值來測試元素(例如,目錄名)是否出現或存在於集合(例如,分區)中。如果位中的任一個包括零值,元素肯定不是集合的成員。否則,元素在集合中或是誤報。
除了產生布隆過濾器113之外,編索引引擎114產生元數據DB 111,用於存儲與文件系統117相關聯的元數據。在掃描目錄時,編索引引擎114可以產生元數據。因此,基於與目錄的掃描相同的時間順序為文件系統117編索引並且組織元數據DB 111,其中時間順序在初始爬行期間基於掃描時間並且在後續爬行期間基於更改時間。在實施例中,編索引引擎114例如通過採用Unix系統調用stat來檢索文件屬性而單獨地檢查文件系統117中的每個文件以產生文件的元數據。編索引引擎114將元數據映射到索引節點(inode)數目和設備數目。設備數目識別文件系統117。索引節點數目在文件系統117內是唯一的並且識別文件系統117中的文件系統對象,其中文件系統對象可以是文件或目錄。例如,文件可以與多個字符串名稱和/或路徑相關聯,文件可以由索引節點數目和設備數目的組合唯一地識別。在一些實施例中,伺服器110可以包括對應於一個或多個存儲設備130的多個文件系統117。在此類實施例中,編索引引擎114可以單獨地分割每個文件系統117並且針對每個文件系統117單獨地產生和保持散列表112、元數據DB 111和布隆過濾器113。
舉例來說,具有索引節點數目12和設備數目2048的命名為「/proj/a/b/c/data.c」的文件的不同類型元數據可以存儲於不同元數據DB111中。例如,文件的路徑名可以存儲於第一元數據DB 111中,表示為PATH元數據DB。與文件相關聯的多個連結可以存儲於第二元數據DB 111中,表示為LINK元數據DB。文件的不同名稱與文件的索引節點數目和設備數目之間的反向關係可以存儲於第三元數據DB 111中,表示為INVP元數據DB。例如,可以創建硬連結以使文件與不同名稱「/proj/data.c」相關聯。文件的自定義元數據可以存儲於第四元數據DB 111中,表示為CUSTOM元數據DB。例如,文件可以用自定義數據(例如,非文件系統屬性),例如,mpeg-4格式標記。元數據DB 111將每個條目存儲在具有空值的密鑰值對中。空值配置使能夠更快地搜索元數據DB 111並且可以提供有效存儲。下表示出元數據DB 111中的條目的實例:
表1-元數據DB 111條目的實例
如圖所示,密鑰中的不同欄位或元數據通過分隔符(示為冒號)分隔開。應注意,分隔符可以是不用於路徑名的任何字符(例如,統一碼字符)。搜尋引擎115可以使用分隔符以在搜索期間檢查不同元數據欄位。除了上述實例元數據DB 111之外,編索引引擎114可以產生用於例如文件類型、文件大小、文件更改時間等的其它類型的元數據DB 111。存儲同一文件系統對象的元數據索引的元數據DB 111(例如,PATH元數據DB、LINK元數據DB和INVP元數據DB)的組可以共同形成關係DB,其中可以在元數據DB 111的組之中建立定義明確的關係。或者,與同一文件系統對象相關聯的不同類型的元數據可以作為駐留在單個元數據DB 111中的單獨表(例如,PATH表、LINK表和INVP表)存儲,所述單個元數據DB是關係DB。
編索引引擎114可以另外將文件的所有元數據集中在第五元數據DB 111中,表示為MAIN元數據DB。然而,MAIN元數據DB包括非空值。表2說明用於由索引節點數目12和設備數目2048識別的文件的MAIN元數據DB條目的實例。例如,文件是具有權限0644的常規文件(例如,呈八進位格式)。通過用戶標識符(user identifier,ID)100識別的用戶以及通過組ID101識別的組擁有所述文件。文件含有65,536個字節並且包括1000000001秒的訪問時間、1000000002秒的更改時間以及1000000003秒的修改時間。
表2-MAIN元數據DB條目的實例
客戶端接口單元116是用於連接查詢且查詢客戶端120與搜尋引擎115之間的結果的軟體組件。例如,當客戶端接口單元116從客戶端120接收文件查詢時,客戶端接口單元116可以解析和/或格式化查詢,使得搜尋引擎115可以對查詢操作。當客戶端接口單元116從搜尋引擎115接收查詢結果時,客戶端接口單元116可以例如根據伺服器-客戶端協議格式化查詢結果並且將查詢結果發送到客戶端120。
搜尋引擎115是用於執行以下操作的軟體組件:通過客戶端接口單元116從客戶端120接收查詢;通過布隆過濾器113確定包括與查詢相關的數據的分區;搜索與分區相關聯的元數據DB 111;以及通過客戶端接口單元116將查詢結果發送到客戶端120。在實施例中,布隆過濾器113對路徑名或目錄名操作。因此,文件的查詢可以包含路徑名的至少一部分,如下文更充分地論述。當搜尋引擎115接收查詢時,搜尋引擎115將布隆過濾器113應用於查詢。如上所述,可以根據布隆過濾器113散列函數散列查詢。當布隆過濾器113對於散列後的位位置全部傳回1時,對應於布隆過濾器113的分區可能載送與查詢相關的數據。隨後,搜尋引擎115可以進一步搜索與對應分區相關聯的元數據DB 111。
隨後,當在文件系統117中更改文件或目錄時,編索引引擎114可以執行另一爬行來更新散列表112、布隆過濾器113和元數據DB 111。在實施例中,元數據DB 111實施為levelDB,levelDB可以採用LSM技術來提高有效更新,如下文更充分地論述。應注意,系統100可以如圖所示構造成或可替代地如由本領域普通技術人員所確定構造成實現類似功能。
圖2是在例如系統100的文件存儲系統中用作節點的NE 200,例如伺服器110、客戶端120和/或存儲設備130的實例實施例的示意圖。NE 200可以用於實施和/或支持本文中所描述的元數據編索引和/或搜索機制。NE 200可以在單個節點中實施或NE 200的功能可以在多個節點中實施。本領域的技術人員將認識到,術語「NE」涵蓋寬廣範圍的設備,其中NE 200僅僅是一個實例。出於清楚地論述的目的,包含NE 200,但絕非意圖將本發明的應用限制於特定NE實施例或NE實施例的類別。本發明中描述的特徵和/或方法中的至少一些可以在例如NE 200等的網絡裝置或模塊中實施。舉例來說,本發明中的特徵和/或方法可以使用硬體、固件和/或被安裝成在硬體上運行的軟體來實施。如圖2中所示,NE 200可以包括一個或多個IO接口埠210和一個或多個網絡接口埠220。處理器230可以包括可以用作數據存儲裝置、緩存器等的一個或多個多核處理器和/或存儲器設備232。處理器230可以實施為通用處理器或可以是一個或多個專用集成電路(application specificintegrated circuits,ASIC)和/或數位訊號處理器(digital signal processor,DSP)的一部分。處理器230可以包括文件系統元數據索引和搜索處理模塊233,其可以執行伺服器或客戶端的處理功能並且實施如下文更充分地論述的方法500、800和1000以及方案300、400、600、700和900和/或本文論述的任何其它方法。因此,包含文件系統元數據索引和搜索處理模塊233以及相關聯方法和系統能提供NE 200的功能性的改進。此外,文件系統元數據索引和搜索處理模塊233實現特定物品(例如,文件系統)到不同狀態的變換。在替代實施例中,文件系統元數據索引和搜索處理模塊233可以實施為可以由處理器230執行的存儲於存儲器設備232中的指令。存儲器設備232可以包括用於臨時存儲內容的高速緩衝存儲器,例如,隨機存取存儲器(random-access memory,RAM)。另外,存儲器設備232可以包括用於相對更長地存儲內容的長期存儲裝置,例如,只讀存儲器(read-only memory,ROM)。舉例來說,高速緩衝存儲器和長期存儲裝置可以包含動態RAM(dynamic RAM,DRAM)、固態驅動器(solid-state drive,SSD)、硬碟或其組合。存儲器設備232可以用於存儲例如元數據DB 111的元數據DB、例如散列表112的散列表以及例如布隆過濾器113的布隆過濾器。IO接口埠210可以耦合到IO設備,例如存儲設備130,並且可以包括用於從IO設備讀出數據和/或將數據寫入到IO設備的硬體邏輯和/或組件。網絡接口埠220可以耦合到計算機數據網絡並且可以包括用於從網絡中的其它網絡節點,例如客戶端120接收數據幀和/或將數據幀傳輸到其它網絡節點的硬體邏輯和/或組件。
應理解,通過將可執行指令編程和/或加載到NE 200上,處理器230和/或存儲器設備232中的至少一個改變,從而將NE 200部分地變換為具有本發明所教示的新穎功能性的特定機器或裝置,例如,多核轉發架構。對於電力工程和軟體工程技術來說重要的是,可以通過將可執行軟體加載到計算機中而實施的功能性可以通過熟知設計規則轉換為硬體實施方案。在軟體還是硬體中實施概念之間的決策通常取決於對設計的穩定性和待產生的單元的數目的考慮,而非從軟體域轉移到硬體域所涉及的任何問題。通常,仍在經受頻繁改變的設計可以優選在軟體中實施,因為重改硬體實施方案比重改軟體設計更為昂貴。一般來說,將以較大量產生的穩定的設計可以優選在硬體中實施,例如在ASIC中實施,因為運行硬體實施方案的大型生產可能比軟體實施方案便宜。通常,設計可以軟體形式開發和測試,並且隨後通過熟知設計規則轉換為用於硬線連接軟體的指令的ASIC中的等效硬體實施方案。以與由新ASIC控制的機器為特定機器或裝置相同的方式,同樣,已經編程和/或加載有可執行指令的計算機可以被看作特定機器或裝置。
圖3是文件系統分割方案300的實施例的示意圖。文件伺服器編索引引擎,例如,伺服器110中的編索引引擎114採用方案300來將例如文件系統117的文件系統分成多個分區,用於編索引和搜索。當創建和/或更新文件系統對象時執行方案300。方案300通過採用散列函數320將文件系統目錄310映射到分區330(例如,分區1至N)。如圖所示,方案300開始於掃描(例如,爬行)文件系統目錄310並且將散列函數320應用於每個文件系統目錄310。例如,深度優先搜索技術可以用於掃描文件系統目錄310,如下文更充分地論述。散列函數320產生每個目錄的散列值。散列函數320可以是產生均勻隨機分布的任何類型的散列函數。例如,散列函數320可以是通過旋轉隨機數以及對隨機數進行異或運算而產生散列值的BuzHash函數。散列至同一值的文件系統目錄310被分組到同一分區330中,如下文更充分地論述。在實施例中,方案300將文件系統分成具有約20K個目錄的分區330。文件系統目錄330或目錄名存儲於散列表340,例如散列表112中。例如,被分配到同一分區的文件系統目錄310可以存儲在對應於分區330的散列代碼下。隨後,當更新文件系統目錄310(例如,添加和/或刪除文件和/或子目錄或重定位目錄)時,方案300可以應用於更新分區330。在後續掃描或爬行期間,文件系統目錄310根據更改時間重新分割。因此,方案300按時間順序創建分區330,這基於在初始創建期間的掃描時間並且基於在後續更新期間的更改時間。應注意,分區330的大小可以可替代地如由本領域普通技術人員所確定構造成實現類似功能。
圖4是文件系統掃描方案400的實施例的示意圖。當首次將文件系統分成分區,例如分區330時(例如,在初始爬行期間),文件伺服器編索引引擎,例如伺服器110中的編索引引擎114採用方案400來掃描例如文件系統117的文件系統中的所有目錄410,例如,文件系統目錄310。方案400可以與方案300結合使用。例如,方案400可以用於將文件系統目錄310饋送到方案300中的散列函數320中。如圖所示,方案400可以對包括目錄A、B和C 410的文件系統操作。目錄A 410包括目錄A.1和A.2 410。目錄B 410包括目錄B.1 410。目錄C 410包括目錄C.1 410。方案400通過採用深度優先搜索技術掃描目錄410,在到達分支的最大深度之前,所述深度優先搜索技術逐分支掃描目錄410。在步驟421處,掃描目錄A 410。在步驟422處,在掃描目錄A410之後,掃描目錄A.1 410。在步驟423處,在掃描目錄A.1 410之後,掃描目錄A.2 410。在步驟424處,在掃描目錄A.2 410之後,掃描目錄B 410。在步驟425處,在掃描目錄B 410之後,掃描目錄B.1 410。在步驟426處,在掃描目錄B.1 410之後,掃描目錄C 410。在步驟427處,在掃描目錄C 410之後,掃描目錄C.1 410。
圖5是文件系統分割方法500的實施例的流程圖。通過文件伺服器編索引引擎,例如伺服器110中的編索引引擎114以及NE 200實施方法500。當創建和/或更新文件和/或目錄時,實施方法500。方法500類似於方案300,其中散列技術用於通過目錄名分割文件系統,例如,文件系統117。方法500可以通過分區,例如分區330將目錄名存儲在例如散列表112的散列表中。例如,散列表可以包括由散列代碼編索引的多個集合,其中每個集合可以對應於分區並且可以存儲對應於分區的目錄名。在步驟510處,通過應用BuzHash函數計算目錄名的散列值,以用於舉例說明。在步驟520處,確定是否在計算出的散列值與散列表中的散列代碼之間找到匹配。如果找到匹配,接下來在步驟560中,目錄名存儲在由所匹配散列代碼識別的分區(例如,集合)中。例如,可以產生用於將目錄名映射到所匹配散列代碼的條目。否則,方法500前進到步驟530。在步驟530處,確定當前操作分區是否包括多於20K個目錄(例如,分區的最大大小)。如果當前操作分區包括少於20K個目錄,接下來在步驟570處,目錄名存儲於當前操作分區中。例如,可以產生用於將目錄名映射到當前操作分區的散列代碼的條目。否則,方法500前進到步驟540。應注意,最大分區大小可以可替代地如由本領域普通技術人員所確定構造成實現類似功能。
在步驟540處,創建新分區並且在計算出的散列值下為所述新分區編索引。在步驟550處,目錄名存儲在新分區中。例如,可以產生用於將目錄名映射到計算出的散列代碼的條目。因此,當方法500首先應用於分割文件系統時,取決於第一掃描目錄用散列值為第一分區編索引,並且在第一分區達到最大分區大小之前,可以將後續目錄放入同一分區中。對於文件系統中的下一目錄,可以重複方法500。如上所述,在文件系統的初始爬行期間,例如通過採用方案400基於目錄名掃描目錄。因此,按目錄名的順序並且基於爬行時間分割文件系統。由於文件和/或目錄更新引起的後續爬行基於更改時間。因此,在初始分割之後按更改時間的順序分割文件系統。
圖6是布隆過濾器產生方案600的實施例的示意圖。文件伺服器搜尋引擎,例如,伺服器110中的搜尋引擎115採用方案600。在例如文件系統117的文件系統670例如通過採用如在方案300和400以及方法500中描述的類似機構分成多個分區630,例如分區330之後實施方案600。在當文件和/或目錄被創建和/或插入文件系統時的初始分割以及當更改文件系統時的重新分割期間,可以採用方案600。例如,分區630的目錄名存儲於例如散列表112和340的散列表中。在方案600中,針對每個分區630產生布隆過濾器640,例如布隆過濾器113。布隆過濾器640是被設計成測試元素(例如,目錄名)是否存在於集合(例如,在分區630中)中的概率型結構數據。布隆過濾器640允許誤報匹配,但不允許漏報匹配。因此,布隆過濾器640減少查詢搜索所需的分區630的數目(例如,減少約90%至95%)。在實施例中,當分區630包括約30K個目錄時,布隆過濾器640可以構造成約32K個位長的位向量。為了產生布隆過濾器640,首先將布隆過濾器640中的所有位初始化為零並且將對應分區630中的目錄名添加到布隆過濾器640以創建集合。為了將目錄名添加到布隆過濾器640,k次散列目錄名(例如,通過k個散列函數)以在布隆過濾器640的位向量中產生k個位位置並且位設定成1,其中k可以約為4。在一個實施例中,每個目錄名作為一個元素添加到布隆過濾器640,其中k個散列函數應用於全部目錄名。在一些其它實施例中,目錄名(例如,/a/b/c)可以分成多個元素(例如,/a,/b,/c),並且每個元素作為單獨元素添加在布隆過濾器640中,其中k個散列函數單獨應用於每個元素。應注意,取決於分區630中的目錄名的數目以及誤報匹配的所需可能性,布隆過濾器640可以配置有不同長度和/或不同數目的散列函數。
圖7是元數據索引搜索查詢方案700的實施例的示意圖。文件伺服器搜尋引擎,例如,伺服器110中的搜尋引擎115可以採用方案700。當例如從客戶端,例如客戶端120接收文件系統對象(例如,文件或目錄)的查詢760時實施方案700。例如,例如文件系統117和670的文件系統分成多個分區,例如分區330和630,針對每個分區產生布隆過濾器740,例如布隆過濾器113和640,並且針對每個分區產生一個或多個元數據DB 750,例如元數據DB 111。可以通過採用如在方案300和400以及方法500中所描述的類似機構來分割文件系統。可以通過採用如在方案600中所說明的類似機構來產生布隆過濾器740。如上所述,可以基於目錄名分割文件系統並且可以通過散列對應分區中的目錄名以產生對應分區中的目錄名的表示(例如,編碼後的散列信息)來產生布隆過濾器740。例如,布隆過濾器B(P1)至B(PN)740分別是文件系統的分區P1至PN中的目錄名的表示。在方案700中,在接收查詢760之後,查詢760可以穿過每個布隆過濾器740以測試對應分區是否可以包括與查詢760相關的數據。由於布隆過濾器740是目錄名的表示,因此查詢760可以包括目錄名的至少一部分。例如,為了搜索文件/a/b/c/data.c,查詢760可以包含路徑名的至少一部分,例如/a、/a/b或/a/b/c。查詢760可以另外包含其它元數據,例如與文件data.c相關聯的文件基本名(例如,data.c)、文件類型、用戶ID、組ID、訪問時間和/或自定義屬性,如下文更充分地論述。為了測試特定分區中的匹配,k次散列查詢760以獲得k個位位置。當布隆過濾器740對於所有k個位傳回值1時,特定分區可以包括用於查詢760的可能匹配。當k個位中的任一個包括零值時,特定分區肯定不包括與查詢760相關的數據。因此,如果對應布隆過濾器740指示可能匹配,可以僅進行特定分區中的進一步搜索。例如,當布隆過濾器B(P1)740傳回查詢760的可能匹配時,搜索分區P1的元數據DB 750。否則,搜索跳過分區P1的元數據DB 750。在實施例中,Unix系統調用strtok可以用於從存儲於元數據DB 750中的密鑰提取路徑名,其中密鑰可以類似於表1中所示的密鑰。應注意,布隆過濾器740可以可替代地用於表示其它類型的元數據,其中查詢760可以用於包含由布隆過濾器740表示的與元數據相關聯的至少一個元素。
圖8是元數據索引搜索查詢方法800的實施例的流程圖。文件伺服器搜尋引擎,例如,搜尋引擎115以及NE 200實施方法800。方法800採用如在方案700中所描述的類似機構。當搜索例如文件系統117的可大規模擴展的存儲文件系統中的文件系統對象時實施方法800。例如,可以通過採用方案300和方法500將文件系統分成多個分區,例如,分區330和630。當例如從例如客戶端120的客戶端接收文件系統對象的查詢時,方法800開始於步驟810處。文件系統對象可以是文件或目錄。通過路徑名識別文件系統對象。查詢包含路徑名的至少一部分。在步驟820處,在接收查詢之後,布隆過濾器應用於所查詢文件系統對象的路徑名的部分。布隆過濾器類似於布隆過濾器113、640和740。布隆過濾器包括例如通過採用方案600產生的可大規模擴展的存儲文件系統的特定部分的文件系統對象路徑名的表示。在步驟830處,確定布隆過濾器是否傳回指示所查詢文件系統對象可能映射到特定文件系統部分的肯定結果。在一個實施例中,可以通過添加每個路徑名的條目來產生布隆過濾器。在此實施例中,查詢包括所查詢文件系統對象的路徑名並且布隆過濾器應用於所查詢文件系統對象路徑名。在另一實施例中,可以通過添加路徑名(例如,/a/b/c)的每個組分(例如,/a、/b和/c)的條目來產生布隆過濾器。在此實施例中,所查詢文件系統對象路徑名(例如,/x/y/z)被分成多個組分(例如,/x、/y和/z)並且布隆過濾器應用於每個路徑名組分。肯定結果對應於所有路徑名組分的肯定匹配。否定結果對應於路徑名組分中的任一個的否定匹配。
如果布隆過濾器傳回肯定結果,接下來在步驟840處,針對所查詢文件系統對象搜索包括特定文件系統部分的元數據編索引信息的關係DB。關係DB可以類似於元數據DB 111。例如,關係DB可以包括多個表,其中每個表可以存儲與特定文件系統部分中的文件系統對象相關聯的特定類型的元數據。表可以存儲密鑰值對中的元數據,如在上述表1和2中示出。例如,元數據類型可以與基本名、完整路徑名、文件大小、文件類型、文件擴展名、文件訪問時間、文件更改時間、文件修改時間、組ID、用戶ID、權限和/或自定義文件屬性相關聯。在實施例中,查詢可以包括文件系統對象的路徑名和文件系統對象的元數據,其中下文更充分地描述查詢的格式。可以通過首先定位與所查詢文件系統對象的路徑名對應的設備數目和索引節點數目(例如,根據PATH表)來搜索關係DB。隨後,可以通過定位具有設備數目和索引節點數目的條目以及確定是否在所查詢元數據與所定位條目之間找到匹配來檢索關係DB中的其它表。
如果布隆過濾器在步驟830處傳回指示所查詢文件系統對象未映射到特定文件系統部分的否定結果,方法800前進到步驟850。在步驟850處,跳過對關係DB中的所查詢文件系統對象的搜索。應注意,布隆過濾器可以傳回誤報匹配,但不可以傳回漏報匹配。對於表示文件系統的另一部分的另一布隆過濾器,可以重複步驟820至850。
圖9是元數據DB存儲方案900的實施例的示意圖。文件伺服器編索引引擎,例如,伺服器110中的編索引引擎114採用方案900來實施例如元數據DB 117和670的文件系統元數據DB,用於文件系統編索引。方案900採用LSM樹技術以通過推遲更新以及分批更新提供有效的編索引更新。在方案900中,元數據dB由兩個或多於兩個樹狀組分數據結構910(例如,C0至Ck)組成。數據結構910包括類似於在上述表1和2中所示的條目的密鑰值對。如圖所示,第一級數據結構C0 910存儲於例如文件伺服器110的文件伺服器或NE 200的本地系統存儲器981,例如存儲器設備232中,其中本地系統存儲器可以提供快速訪問。在後續級中的數據結構C1至Ck 910存儲在例如硬碟驅動器的磁碟982上,所述磁碟與本地系統存儲器981相比可以包括較慢訪問速度。駐留在本地系統存儲器981中的數據結構C0 910的大小通常小於存儲在磁碟982上的數據結構C1至Ck 910。另外,對於每個後續級,數據結構C1至Ck 910的大小可以增加。數據結構C0 910用於存儲最近更新的元數據。當數據結構C0 910達到特定大小時或在特定時間之後,數據結構C0 910移轉到磁碟982中。當數據結構C0 910轉移到磁碟982中時,數據結構C0 910合併到下一級數據結構C1 910中並且在下一級數據結構C1 910中分類。對於後續級的數據結構C2至Ck-1 910,可以重複合併-分類過程。因此,當採用LSM樹技術來實施元數據DB時,延遲更新並且分批執行更新。當檢索元數據DB時,搜索可以首先掃描駐留在本地系統存儲器981中的數據結構C0 910。當未找到匹配時,搜索可以繼續到下一級數據結構910。因此,方案900還可以允許有效搜索。應注意,levelDB是採用方案900中所示的LSM技術的資料庫的類型。
圖10是文件系統元數據更新方法1000的實施例的流程圖。通過文件伺服器編索引引擎,例如伺服器110中的編索引引擎114以及NE 200實施方法1000。在文件伺服器編索引引擎已為文件系統編索引之後實施方法1000。例如,可以通過如在方案300和400以及方法500中所描述的散列技術由目錄名分割文件系統。例如分區330和630的分區可以存儲在例如散列表112和340的散列表中。另外,例如通過採用方案600和方法800產生分區的布隆過濾器,例如,布隆過濾器113、640和740。此外,例如可以通過採用方案900產生分區的元數據DB,例如,元數據DB 111和750。當在例如文件系統117的文件系統中檢測到更改時,方法1000開始於步驟1010處。更改可以是文件或目錄移除、添加、移動或文件更新。一些作業系統(例如,Unix和Linux)可以提供應用程式編程接口(application programming interface,API)或系統調用(例如,inotify),以監視文件系統更改。在步驟1020處,在檢測到文件系統更改之後,通過更新散列表,例如通過採用如在方案300和方法500中所示的類似機構重新分割文件系統。在步驟1030處,在重新分割文件系統之後,例如通過採用方案600更新一個或多個對應布隆過濾器。例如,當移動目錄時,前一個路徑名可以從前一個分區移除並且更新後的路徑名可以添加到更新後的分區。因此,可以更新與前一個分區和更新後的分區對應的布隆過濾器。在步驟1040處,通過更新對應於更新後的分區的一個或多個元數據DB,例如通過採用方案900來為文件系統重新編索引。
在實施例中,例如客戶端120的客戶端可以將例如查詢760的查詢發送到例如文件伺服器110的文件伺服器,以搜索例如文件系統117的文件系統中的文件系統對象(例如,文件或目錄)。可以如下所示格式化查詢:
&,
其中變量可以是任何類型的文件系統元數據,例如,路徑名、基本名、用戶ID、組ID、文件大小、與文件相關聯的多個鏈路、權限(例如,八進位0644)、文件類型、文件訪問時間、文件更改時間、文件修改和自定義文件屬性。下表概括查詢變量:
表3-查詢變量的實例
relop可以表示關係運算符,例如大於(例如,>)、大於或等於(例如,>=)、小於(例如,<)、小於或等於(例如,<=)、等於(例如,=)或不等於(例如,)。應注意,當文件伺服器基於路徑名採用布隆過濾器,例如布隆過濾器113時,查詢可以包括對應於所查詢文件系統對象的路徑名的至少一部分的至少一個變量。例如,查詢中的第一變量可以是路徑名變量。因此,當執行元數據索引搜索時可以採用前綴搜索。以下列出查詢的一些實例:
path=/proj/a/b/c/&base=random.c
path=/proj/a/b/c/&links>1。
雖然本發明中已提供若干實施例,但應理解,在不脫離本發明的精神或範圍的情況下,所揭示的系統和方法可以以許多其它特定形式來體現。本發明的實例應被視為說明性而非限制性的,且本發明並不限於本文本所給出的細節。例如,各種元件或組件可以在另一系統中組合或合併,或者某些特徵可以省略或不實施。
另外,在不脫離本發明的範圍的情況下,各種實施例中描述和說明為離散或單獨的技術、系統、子系統和方法可以與其它系統、模塊、技術或方法進行組合或合併。展示或論述為彼此耦合或直接耦合或通信的其它項也可以採用電方式、機械方式或其它方式通過某一接口、設備或中間組件間接地耦合或通信。變化、替代和改變的其它實例可以由本領域的技術人員在不脫離本文所揭示的精神和範圍的情況下確定。