伺服器的硬體監控裝置的製作方法
2023-05-16 06:01:21 3
本發明涉及伺服器技術領域,具體來說,涉及一種伺服器的硬體監控裝置。
背景技術:
在現代數據中心(Internet DataCenter,IDC)中,伺服器節點的數量越來越多,相應的運維工作負擔也越來越重,如何能夠更早更準確的發現伺服器存在的硬體問題,成為了保證數據中心業務正常運轉的首要問題。
現有的對伺服器進行監控的方法是,IDC的運維人員需要每隔一段時間到機房去巡檢一次,以便於及時的發現問題,但是,機房巡檢也只能通過伺服器的指示燈去觀察硬體的狀態,一些隱藏的問題(例如,內存可修正錯誤導致CPU性能下降)是無法發現的。
現有技術中的另外一種對伺服器進行監控的方法是,為伺服器統一提供一種BMC(Baseboard Management Controller,基板管理控制器)機制去獲取硬體健康狀態,但是BMC無法獲取伺服器所有硬體的狀態。
針對相關技術中的上述問題,目前尚未提出有效的解決方案。
技術實現要素:
針對相關技術中的上述問題,本發明提出一種伺服器的硬體監控裝置,能夠遠程對伺服器的硬體狀態進行監控,從而有效降低人工巡檢強度。
本發明的技術方案是這樣實現的:
根據本發明的一個方面,提供了一種伺服器的硬體監控裝置,包括:第一獲取模塊,用於通過伺服器的作業系統獲取CPU的狀態數據、內存的狀態數據、硬碟的狀態數據;第二獲取模塊,用於通過BMC獲取主板狀態數據、風扇狀態數據、電源狀態數據、和溫度狀態數據;以及處理及報警模塊,連接於第一獲取模塊和第二獲取模塊,用於根據需要對CPU的狀態數據、內存的狀態數據、硬碟的狀態數據、主板狀態數據、風扇狀態數據、電源狀態數據、和溫度狀態數據進行監控,還用於當其中的任意一種超出相應的設定閾值時判斷對應的硬體出現故障並進行報警。
根據本發明的一個實施例,第一獲取模塊包括:CPU及內存數據獲取單元,用於通過MCE機制獲取CPU的狀態數據和內存的狀態數據。
根據本發明的一個實施例,CPU的狀態數據包括TLB狀態數據、Cache狀態數據、和總線狀態數據;當TLB狀態數據、Cache狀態數據、和總線狀態數據之中的任意一種發生故障時,處理及報警模塊進行報警。
根據本發明的一個實施例,第一獲取模塊包括硬碟數據獲取單元;其中,硬碟的狀態數據包括SMART信息。
根據本發明的一個實施例,硬碟包括RAID卡;以及硬碟的狀態數據包括RAID卡的晶片狀態數據、RAID卡的緩存狀態數據、RAID卡的溫度狀態數據、和RAID卡的鏈路狀態數據;其中,硬碟數據獲取單元通過RAID卡工具獲取RAID卡的晶片狀態數據、RAID卡的緩存狀態數據、RAID卡的溫度狀態數據、和RAID卡的鏈路狀態數據。
根據本發明的一個實施例,RAID卡的鏈路狀態數據包括Invalid DWORD count指標,當Invalid DWORD count指標在運行期間出現上漲時,處理及報警模塊進行報警。
根據本發明的一個實施例,溫度狀態數據包括:CPU溫度數據、內存溫度數據、伺服器環境溫度數據、伺服器出風口溫度數據、和BMC溫度數據。
根據本發明的一個實施例,內存的狀態數據包括內存可修正錯誤發生的次數和內存不可修正錯誤發生的次數;當內存不可修正錯誤發生的次數在1次以上時,處理及報警模塊進行報警;當24小時內內存可修正錯誤發生的次數在1次以上時,處理及報警模塊進行報警。
根據本發明的一個實施例,RAID卡的緩存狀態數據包括緩存可修正錯誤發生的次數和緩存不可修正錯誤發生的次數;當緩存不可修正錯誤發生的次數在1次以上時,處理及報警模塊進行報警;當24小時內緩存可修正錯誤發生的次數在1次以上時,處理及報警模塊進行報警。
根據本發明的一個實施例,伺服器的作業系統為Linux作業系統。
本發明能夠實現通過計算機遠程獲取伺服器的硬體狀態,從而有效降低人工巡檢強度;同時能夠更為即時地發現伺服器故障,並可以準確的對故障硬體進行定位,進而提高了維修效率。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對於本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1是根據本發明實施例的伺服器的硬體監控裝置的框圖;
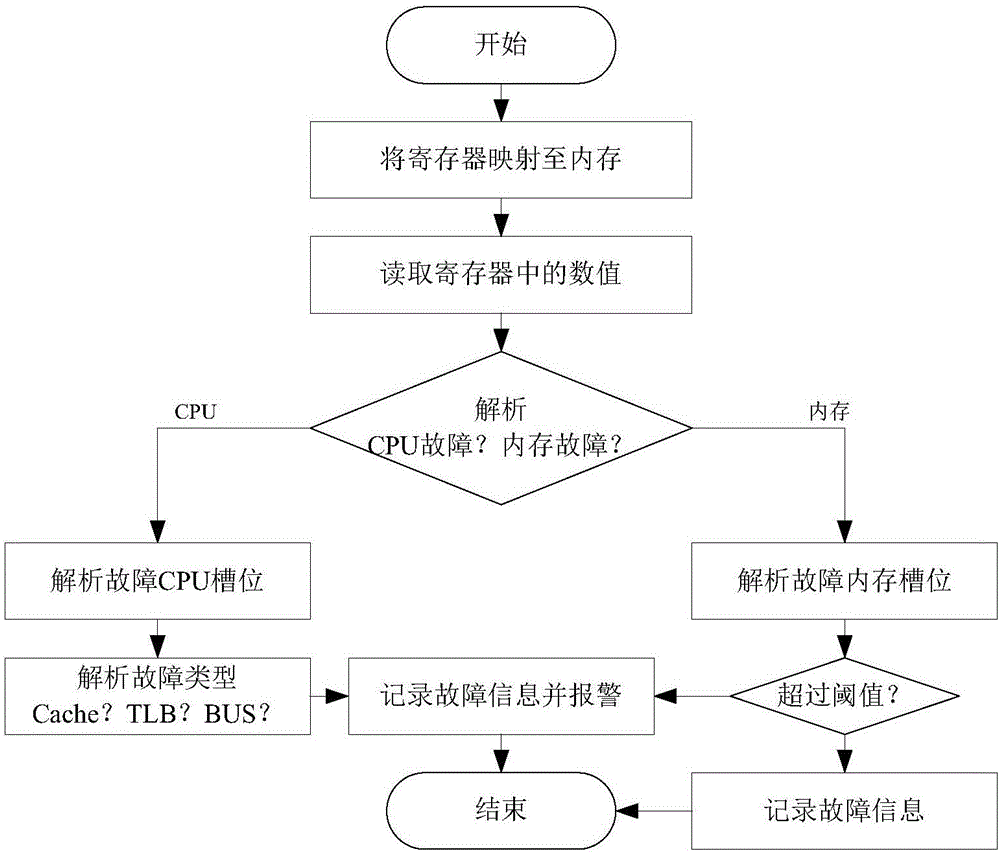
圖2是根據本發明實施例的伺服器的硬體監控裝置對CPU和內存進行監控的流程圖;
圖3是根據本發明實施例的伺服器的硬體監控裝置對硬碟進行監控的流程圖;
圖4是根據本發明實施例的伺服器的硬體監控裝置的RAID卡工具獲取RAID卡數據的示意圖;
圖5是根據本發明實施例的伺服器的硬體監控裝置的通過BMC進行監控的示意圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。基於本發明中的實施例,本領域普通技術人員所獲得的所有其他實施例,都屬於本發明保護的範圍。
根據本發明的實施例,提供了一種伺服器的硬體監控裝置。
如圖1所示,根據本發明實施例的伺服器的硬體監控裝置包括:第一獲取模塊10、第二獲取模塊20、和連接於所述第一獲取模塊10和所述第二獲取模塊20的處理及報警模塊30;其中,第一獲取模塊10用於通過伺服器的作業系統獲取CPU的狀態數據、內存的狀態數據、硬碟的狀態數據;第二獲取模塊20用於通過BMC(Baseboard Management Controller,基板管理控制器)獲取主板狀態數據、風扇狀態數據、電源狀態數據、和溫度狀態數據;處理及報警模塊30用於根據需要對CPU的狀態數據、內存的狀態數據、硬碟的狀態數據、主板狀態數據、風扇狀態數據、電源狀態數據、和溫度狀態數據進行監控,當其中的任意一種超出相應的設定閾值時,則處理及報警模塊30判斷對應的硬體出現故障並進行報警。
通過本發明的上述技術方案,使得運維人員能夠實現通過計算機遠程獲取伺服器的硬體狀態,從而有效降低人工巡檢強度;同時能夠更為即時地發現伺服器故障,並可以準確的對故障硬體進行定位,進而提高了維修效率。
在一個實施例中,伺服器的作業系統為Linux作業系統。
在一個實施例中,第一獲取模塊10可以包括CPU及內存數據獲取單元11,用於通過MCE(Machine Check Exception)機制獲取CPU的狀態數據和內存的狀態數據,MCE機制是英特爾CPU中用於獲取CPU和內存健康狀態的一種機制。具體地,結合圖2所示,CPU及內存數據獲取單元11可利用英特爾CPU提供的MCE機制,通過讀取CPU中的一組寄存器的數值並對這些數值進行翻譯,從而獲得CPU和內存控制器的健康狀態。
其中,CPU的狀態數據包括TLB(Translation Lookaside Buffer,翻譯後備緩衝器)狀態數據、Cache(高速緩衝存儲器)狀態數據、和總線(BUS)狀態數據;當TLB狀態數據、Cache狀態數據、和總線狀態數據之中的任意一種發生故障時,處理及報警模塊30進行報警。即本發明的伺服器的硬體監控裝置可以監控TLB、Cache、總線三類硬體故障,三類硬體故障報警的規則為只要發生一次,則立刻觸發報警。
進一步地,內存的狀態數據包括內存可修正錯誤發生的次數和內存不可修正錯誤發生的次數;當內存不可修正錯誤發生的次數在1次以上時,處理及報警模塊30進行報警;當24小時內內存可修正錯誤發生的次數在1次以上時,處理及報警模塊30進行報警。即本發明針對內存,主要監控內存可修正錯誤發生的次數和內存不可修正錯誤發生的次數。處理及報警模塊30針對內存的故障報警規則為:內存可修正錯誤在24小時內如果發生的次數超過1次則觸發報警,內存不可修正錯誤只要發生1次就觸發報警。
在一個實施例中,第一獲取模塊10包括硬碟數據獲取單元12;其中硬碟的狀態數據包括SMART信息。結合圖3所示,硬碟的健康狀態獲取主要來源於硬碟內部的SMART信息。SMART信息能夠提供一組數據來表明硬碟的當前狀態。本發明通過解析SMART信息來確定硬碟是否存在故障。
在一個實施例中,硬碟包括RAID(Redundant Arrays of Independent Disks,磁碟陣列)卡;以及硬碟的狀態數據包括RAID卡的晶片狀態數據、RAID卡的緩存狀態數據、RAID卡的溫度狀態數據、和RAID卡的鏈路狀態數據;其中,硬碟數據獲取單元12通過RAID卡工具獲取RAID卡的晶片狀態數據、RAID卡的緩存狀態數據、RAID卡的溫度狀態數據、和RAID卡的鏈路狀態數據。
進一步地,RAID卡的鏈路狀態數據包括Invalid DWORD count指標,當Invalid DWORD count指標在運行期間出現上漲時,處理及報警模塊30進行報警。如圖4所示,對於RAID卡,可以使用RAID卡廠商提供的RAID卡監控工具(例如storcli工具)來獲取RAID卡的狀態數據。使用本發明可以監控RAID卡的晶片狀態、緩存狀態、溫度狀態以及鏈路狀態。其中,RAID卡的鏈路狀態數據包括SMART信息中用於監控鏈路狀態的4個指標:Invalid DWORD count,Running disparity error count,Loss of DWORD synchronization,Phy reset problem,該4個指標若出現上漲則存在鏈路故障的風險。其中Invalid DWORD count為最重要指標,在本發明中其閾值為:從監控運行開始到當前時間該指標不能出現上漲。
在一個實施例中,RAID卡的緩存狀態數據包括緩存可修正錯誤發生的次數和緩存不可修正錯誤發生的次數;當緩存不可修正錯誤發生的次數在1次以上時,處理及報警模塊30進行報警;當24小時緩存可修正錯誤發生的次數在1次以上時,處理及報警模塊30進行報警。具體地,可通過RAID卡廠商提供的RAID卡監控工具獲取到RAID卡的緩存狀態數據出錯類型和相應的次數。出錯類型分為可修正錯誤和不可修正錯誤。可以通過設定閾值的方式來出發故障報警。對於可修正錯誤,閾值為每24小時超過1次報警。對於不可修正錯誤,閾值為只要發生就立刻報警。
另外,還可以通過RAID卡監控工具獲取RAID卡的溫度狀態數據,進而通過將RAID卡的溫度狀態數據與其對應的閾值進行比較,並在超出其對應的閾值時進行報警。在本實施例中,RAID卡的溫度狀態數據對應的閾值設定為100℃。
如圖1和圖5所示,可以通過BMC獲取主板狀態數據、風扇狀態數據、電源狀態數據、和溫度狀態數據。可以使用BMC監控工具,例如ipmitool工具(一種可用在Linux系統下的管理工具),來獲取BMC各個傳感器的數值。通過對這些傳感器數值進行分析,從而確定主板、風扇、電源等硬體是否正常工作。其中,第二獲取模塊20可以包括用於獲取主板狀態數據的主板數據獲取單元21、用於獲取風扇狀態數據的風扇數據獲取單元22、用於獲取溫度狀態數據的溫度數據獲取單元23、和用於獲取電源狀態數據的電源數據獲取單元24。
具體地,溫度狀態數據可以包括:CPU溫度數據、內存溫度數據、伺服器環境溫度數據、伺服器出風口溫度數據、和BMC溫度數據。
以上所述僅為本發明的較佳實施例而已,並不用以限制本發明,凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。