一種基於數據一致性校驗算法的優化算法的製作方法
2023-05-15 08:38:56 6
本發明涉及數據一致性檢測技術,尤其是一種基於數據一致性校驗算法的優化算法。
背景技術:
隨著計算機的發展,數據作為企業的重要資源越來越受到重視,為了防止各種災難讀技術局的損壞或者摧毀,建立一個可以保證數據安全和服務連續性的容災系統具有十分重要的意義。在容災系統中,當災難法神後,使用備份數據中心提供的數據可以快速的恢復本地數據中心的數據,保持業務的連續性,將損失降到最低。但是如果備份數據和被損壞前數據不一致,這就說明備份市局不能用來進行對元數據的恢復,這樣就會造成無法挽回的損失,所以為了確保備份數據在數據恢復時具有高可用性,就需要定期的對元數據和備份數據進行數據一致性檢測。
數據一致性檢測技術是檢測源數據與備份數據是否一致來確保備份數據高可用性的技術。現有的數據一致性檢測方法主要通過快照技術、數據分塊技術和計算摘要值等技術來對源數據與備份數據同時進行操作,得到對應數據塊的摘要值,通過對摘要值的比對完成數據一致檢測,如果摘要值相同,源數據與備份數據就一致;不同則不一致。這其中對摘要值的計算是數據一致性校驗中的重要環節。
在摘要值計算中,對摘要值算法的效率有一定的要求,因為數據一致性檢測不能佔用非常多的時間,這樣會影響系統的正常工作。對於摘要值算法,摘要值算法到的散列值越長其所能保證的數據一致性越高,但是長的散列值就要花費大量的計算資源和時間,md5算法產生128位散列值,雖然不是最長的,但是作為摘要值算法很好的中和了散列值長度和計算性能的矛盾。
技術實現要素:
針對以上問題,本發明提出了一種基於數據一致性校驗算法的優化算法。針對原有的md5摘要算法進行研究,對原有的md5值校驗算法進行優化,通過流程和策略的優化從而提高數據校驗算法的準確性和計算效率。
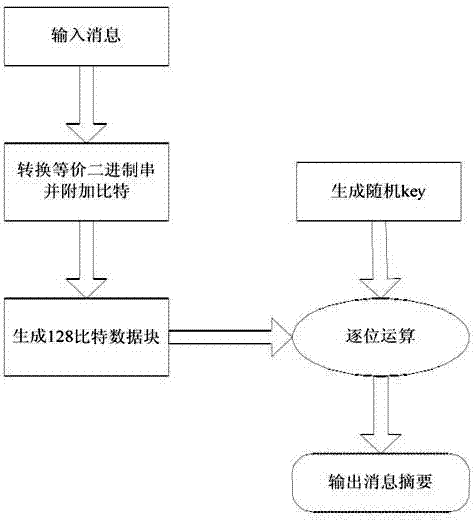
本發明改進的算法是以任意長的消息作為輸入,同樣產生128比特的消息摘要。
本發明的技術方案是:
一種基於數據一致性校驗算法的優化算法,
具體步驟如下:
步驟一:輸入信息;
步驟二:通過二進位的轉化,將信息串轉化為等價的二進位串;
步驟三:(1)為二進位串添加01比特序列,使因此產生的字符串的長度比512的倍數少64比特;(2)掃描步驟三(1)中產生的字符串的任意位置,再附加64比特;
步驟四:(1)將步驟二產生的二進位串劃分成長度為128比特的數據塊;(2}使用隨機數發生器生成一個128比特的二進位鍵;(3)在128比特數據塊和128比特隨機鍵中進行逐位運算;(4)將步驟四(3)中的輸出作為逐步的消息摘要進行保存;
步驟五:(1)在現在的消息摘要和之前的消息摘要之間進行逐位運算;(2)返回步驟四,直至所有的輸入信息塊都處理完畢;
步驟六:將步驟五產生的輸出值轉化成相應的特徵值,並且將此值作為最後的消息摘要值保存。
作為輸入的信息是任意類型,包括字母,數字以及特殊字符:
message=((a-z)+(a-z)+(0-9)+(!一;))*
對於任何字符,都轉化為相應的二進位碼,產生的二進位串包含任何數字編號;然後追加一個位序列,以輸入二進位字符串,使生成的字符串的長度比512的倍數少64;
數學形式:二進位串長度%512=448。
對在產生的字符串的任意位置再附加64比特來說,它的起始點從[字符串的長度//3」開始。
在原有數據一致性校驗算法md5的基礎上通過流程和策略的優化從而提高數據校驗算法的準確性和計算效率。
附圖說明
圖1是md5算法流程圖圖;
圖2是優化後數據摘要算法的流程圖。
具體實施方式
下面對本發明的內容進行更加詳細的闡述:
圖1是標準md5值在數據一致性校驗中進行數據摘要的過程。md5算法的具體實現過程是經過初始化後,md5將輸入文本劃分為16個32位的分組,通過四輪計算,會得到四個32位分組的值,而md5最後所得的128位摘要值就是將這四個值級聯得出的。
圖1是標準md5值在數據一致性校驗中進行數據摘要的過程。md5算法的具體實現過程是經過初始化後,md5將輸入文本劃分為16個32位的分組,通過四輪計算,會得到四個32位分組的值,而md5最後所得的128位摘要值就是將這四個值級聯得出的。
首先要對輸入信息進行填充,填充的方法是在信息後面附上一個1,然後1的後面按照要求附上若干多個0。將填充完的信息再加上64位信息再填充之前的長度後,剛好使整個信息的長度是512的整數倍。進行這樣操作的目的是保證不同信息經過填充後不相同,方便以後的操作。
下面是四個md5算法中的連結變量:
a=0x01234567
b=0x89abcdef
c=0xfedcba98
d=0x76543210
計算信息中512位分組的數量,並將此數值作為循環的次數開始md5算法的主循環。為了四個連結變量a,b,c,d不發生改變,使用四個中間變量表示它們。md5算法的主循環一共有四輪,每一輪都要通過固有的函數進行16次計算。這個過程是從四個中間變量中選出二個,將這二個作一次非線性函數運算,將剩餘的變量加到由非線性函數運算所有的結果中,然後將加上文本的一個子分組和一個常數的結果右移不定位,從四個中間變量中選出來一個然後加上那個結果。再從四個中間變量中選出一個,然後用剛才得到的那個結果進行替換
下面是每輪要用到的非線性函數,一共是四個:
f(x,y,z)=(x&y)}|((~x)&z)
g(x,y,z)=(x&z)}|(y&(~z))
h(x,y,z)=x^y^z
i}x,y,z)=y^(x|(~z))
(&:與,|:或,~:非,^:異或)
函數f的操作方式是逐位的操作:如果x,那麼y,否則z。函數h是逐位奇偶操作符。四種操作為:
ff(a,b,c,d,mj,s,ti)表示a=b+((a+(f(b,c,d)+mj+ti)<<<s)
gg(a,b,c,d,mj,s,ti)表示a=b+((a+(g(b,c,d)+mj+ti)<<<s)
hh(a,b,c,d,mj,s,ti)表示a=b+((a+(h(b,c,d)+mj+ti)<<<s)
ii(a,b,c,d,mj,s,ti)表示a=b+((a+(i(b,c,d)+mj+ti)<<<s)
其中a,b,c,d就是替換四個連結變量的中間變量,<<<s表示循環左移s位,變量mj表示的含義旱信良的第j個子分組。
這四輪(64步)是:
第一輪:
ff(a,b,c,d,m0,7,0xd76aa478)
ff(d,a,b,c,m1,12,0xe8c7b756)
ff(c,d,a,b,m2,17,0x242070db)
ff(b,c,d,a,m3,22,0xclbdceee)
ff(a,b,c,d,m4,7,0xf57c0faf)
ff(d,a,b,c,ms,12,0x4787c62a)
ff(c,d,a,b,m6,17,0xa8304613)
ff(b,c,d,a,m7,22,0xfd469501)
ff(a,b,c,d,m8,7,0x698098d8)
ff(d,a,b,c,m9,12,0x8b44f7af)
ff(c,d,a,b,m10,17,0xffff5bb1)
ff(b,c,d,a,m11,22,0x895cd7be)
ff(a,b,c,d,m12,7,0x6b901122)
ff(d,a,b,c,m13,12,0xfd987193)
ff(c,d,a,b,m14,17,0xa679438e)
ff(b,c,d,a,m15,22,0x49b40821)
第二輪:
gg(a,b,c,d,m1,5,0xf61e2562)
gg(d,a,b,c,m6,9,0xc040b340)
gg(c,d,a,b,m11,14,0x265e5a51)
gg(b,c,d,a,m0,20,0xe9b6c7aa)
gg(a,b,c,d,m5,5,0xd62f105d)
gg(d,a,b,c,m10,9,0x02441453)
gg(c,d,a,b,m15,14,0xd8ale681)
gg(b,c,d,a,m4,20,0xe7d3fbc8)
gg(a,b,c,d,m9,5,0x21e1cde6)
gg(d,a,b,c,m14,9,0xc33707d6)
gg(c,d,a,b,m3,14,0xf4d50d87)
gg(b,c,d,a,m8,20,0x45sa14ed)
gg(a,b,c,d,m13,5,0xa9e3e905)
gg(d,a,b,c,m2,9,0xfcefa3f8)
gg(c,d,a,b,m7,14,0x676f02d9)
gg(b,c,d,a,m12,20,0x8d2a4c8a)
第二輪:
hh(a,b,c,d,m5,4,0xfffa3942)
hh(d,a,b,c,mb,11,0x8771f681)
hh(c,d,a,b,m11,16,0x6d9d6122)
hh(b,c,d,a,m14,23,0xfde5380c)
hh(a,b,c,d,m1,4,0xa4beea44)
hh(d,a,b,c,m4,11,0x4bdecfa9)
hh(c,d,a,b,m7,16,0xf6bb4b60)
hh(b,c,d,a,m10,23,0xbebfbc70)
hh(a,b,c,d,m13,4,0x289b7ec6)
hh(d,a,b,c,m0,11,0xeaa127fa)
hh(c,d,a,b,m3,16,0xd4ef3085)
hh(b,c,d,a,m6,23,0x04881d05)
hh(a,b,c,d,m9,4,0xd9d4d039)
hh(d,a,b,c,m12,11,0xe6db99e5)
hh(c,d,a,b,m15,16,0x1fa27cf8)
hh(b,c,d,a,m2,23,0xc4ac5665)
第四輪:
ii(a,b,c,d,m0,6,0xf4292244)
ii(d,a,b,c,m7,10,0x432aff97)
ii(c,d,a,b,m14,15,0xab9423a7)
ii(b,c,d,a,m5,21,0xfc93a039)
ii(a,b,c,d,m12,6,0x655b59c3)
ii(d,a,b,c,m3,10,0x8foccc92)
ii(c,d,a,b,m10,15,0xffeff47d)
ii(b,c,d,a,m1,21,0x85845dd1)
ii(a,b,c,d,m8,6,0x6fa87e4f)
ii(d,a,b,c,m15,10,0xfe2ce6e0)
ii(c,d,a,b,m6,15,0xa3014314)
ii(b,c,d,a,m13,21,0x4e0811a1)
ii(a,b,c,d,m4,6,0xf7537e82)
ii(d,a,b,c,m11,10,0xbd3af235)
ii(c,d,a,b,m2,15,0x2ad7d2bb)
ii(b,c,d,a,m9,21,0xeb86d391)
常數ti可以如下選擇:
在第i步中,ti是4294967296*abs(sin(i))的整數部分,ti的單位是弧度(2的32次方)。完成這四輪所有的操作後將最後所得的四個分組值進行級聯起來就是最後的輸出值。以上是md5算法的整個操作流程。
圖2是優化後數據摘要算法的流程圖。本發明改進的算法是以任意長的消息作為輸入,同樣產生128比特的消息摘要。算法的具體步驟如下:
步驟一:輸入信息。
步驟二:通過二進位的轉化,將信息串轉化為等價的二進位串。
步驟三:(1)為二進位串添加01比特序列,使因此產生的字符串的長度比512的倍數少64比特;(2)通過掃描步驟二(1)中產生的字符串的任意位置(在這種情況下,可以用規則[字符串的長度/3]來定義起始點),再附加64比特。
步驟四:(1)將步驟二產生的二進位串劃分成長度為128比特的數據塊;(2}使用隨機數發生器生成一個128比特的二進位鍵;(3)在128比特數據塊和128比特隨機鍵中進行逐位運算,例如與,或,異或,然後是左移,右移,零填轉移等;c4)將步驟四(3)中的輸出作為逐步的消息摘要進行保存。
步驟五:(1)在現在的消息摘要和之前的消息摘要之間進行逐位運算;(2)返回步驟四,直至所有的輸入信息塊都處理完畢。
步驟六:將步驟五產生的輸出值轉化成相應的特徵值,並且將此值作為最後的消息摘要值保存。
作為輸入的信息可以是任意類型的(空字符也被接受),它可以包括字母,數字以及特殊字符:
message=((a-z)+(a-z)+(0-9)+(!一;))*
對於任何字符,都可以轉化為相應的二進位碼,漢字也是如此,可以找到相應漢字的二進位碼,例如「知行者」的二進位碼就是「1000000000000101",所以這個對與漢字同樣適用。
由此產生的二進位串可以包含任何數字編號。然後追加一個位序列(例如「01"),以輸入二進位字符串,使生成的字符串的長度比512的倍數少64。
數學形式:二進位串長度%512=448
對於在產生的字符串的任意位置再附加64比特來說,它的起始點可以從[字符串的長度//3」開始。現在的字符串的長度是512的整數倍,然後將字符串劃分成長度為128比特的數據塊。
產生的關鍵key也是128比特的,這個key可以用任何一個隨機數字生成方法來生成,這裡舉例:
key=(key*39)%967
keyf=(key)。