一種信息系統運行狀態預測方法和裝置與流程
2023-05-21 12:19:22 5
本發明涉及IT運維中智能監控技術領域,更具體地,涉及信息系統運行狀態預測技術領域。
背景技術:
目前,隨著信息系統的日益廣泛以及不同領域的業務種類的日益豐富,基於海量數據存儲與處理的計算信息系統的應用變得越來越廣泛,由此,隨著用於大量運算速度及存儲量的主機、中間件及資料庫的數量的顯著增長,其發生故障的概率以及不良影響也越來越大,因此,對信息系統運行狀態進行有效的預測變得越來越重要。
在信息運維過程中,支撐應用系統運行的監控指標有很多,通過這些監控指標可以發現應用系統的運行狀況。
現有的技術方案存在如下問題需要解決:(1)如何識別關鍵監控指標(KPI),以減少不重要的監控指標;(2)如何通過這些關鍵的監控指標綜合判斷應用系統的運行狀況;(3)如何提前預測系統的運行狀況。
技術實現要素:
本發明提供一種克服上述問題或者至少部分地解決上述問題的方法和裝置。
根據本發明的一個方面,如圖1所示,提供了一種信息系統運行狀態預測方法,包括以下步驟,S1.基於信息系統數據,利用粗糙集算法識別出信息系統的關鍵監控指標;S2.基於信息系統數據,利用關聯規則挖掘算法建立各關鍵監控指標與信息系統運行狀態間的關聯規則;S3.基於信息系統實時監控數據,利用所得關聯規則,結合預測算法,進行信息系統運行狀態的預測。
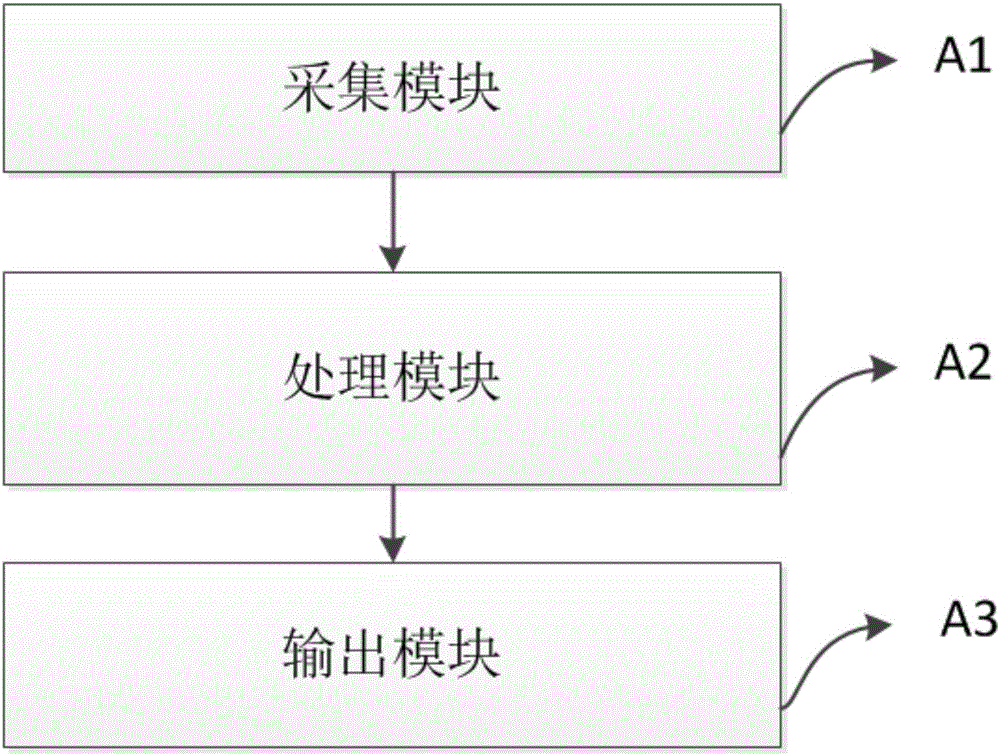
根據本發明的另一個方面,如圖2所示,提供了一種信息系統運行狀態預測裝置,包括以下模塊,採集模塊,用於採集信息系統數據;處理模塊,用於基於信息系統數據,利用粗糙集算法識別出信息系統的關鍵監控指標;基於信息系統數據,利用關聯規則挖掘算法建立各關鍵監控指標與信息系統運行狀態間的關聯規則;基於信息系統實時監控數據,利用所得關聯規則,結合預測算法,進行信息系統運行狀態的預測。
本申請提出一種信息系統運行狀態預測方法和裝置,利用粗糙集算法識別出信息系統的關鍵監控指標、利用關聯規則挖掘算法建立各關鍵監控指標與信息系統運行狀態間的關聯規則、利用預測算法技術以預測信息系統的運行狀況。本發明具有效率高、運用關鍵指標準確預測信息系統運行狀態的有益效果。
附圖說明
圖1為根據本發明實施例的信息系統運行狀態預測方法的總體流程示意圖;
圖2為根據本發明實施例的信息系統運行狀態預測裝置的總體結構示意圖。
具體實施方式
下面結合附圖和實施例,對本發明的具體實施方式作進一步詳細描述。以下實施例用於說明本發明,但不用來限制本發明的範圍。
在一個具體實施例中,以某營銷基礎數據平臺信息系統運行狀態預測為例,結合附圖對本發明進行進一步的說明。
圖1給出了根據本發明實施例的一種信息系統運行狀態預測方法的總體流程示意圖。總的來說,該方法包括:S1.基於信息系統數據,利用粗糙集算法識別出信息系統的關鍵監控指標;S2.基於信息系統數據,利用關聯規則挖掘算法建立各關鍵監控指標與信息系統運行狀態間的關聯規則;S3.基於信息系統實時監控數據,利用所得關聯規則,結合預測算法,進行信息系統運行狀態的預測。利用大數據技術及數據挖掘方法對業務系統進行關聯規則挖掘,可以發現支撐業務系統運行的主機、中間件及資料庫等資源與業務系統的關聯關係,同時也可以挖掘出業務系統之間的關聯關係,這對與業務系統故障定位及提前預判有著重要意義,是自動化巡檢中的一個關鍵技術。此外,對於一些重要的系統(比如營銷系統)運行狀況的提前預判,可以讓我們能夠及時處理將來可能發生的問題,從而提升客戶體驗。
在本發明一個具體實施例中,所述步驟S1包括,
1)確定條件屬性C和決策屬性D,並且用字母編號決策表中數據。
2)對條件屬性進行約簡,刪除多餘的屬性,本文利用屬性的依賴度分析方法來完成約簡和求核。
在本發明另一個具體實施例中,步驟S2中所述「關聯規則挖掘算法」還包括以下步驟:
利用改進的Apriori算法建立各監控指標與信息系統運行狀態的關聯規則;所述算法改進點在於:利用頻繁項目集Lk-1對所述數據進行篩選,如果Lk-1沒有包含集合k,則不對該頻繁項目集Lk-1進行後續計算。
在本發明另一個具體實施例中,步驟S2中所述「關聯規則挖掘算法」還包括以下步驟:利用Apriori算法建立各監控指標與信息系統運行狀態的關聯規則。
在本發明另一個具體實施例中,步驟S3還包括以下步驟:利用數據擬合技術進行信息系統運行狀態的預測。可以理解為,本發明用於實現信息系統運行狀態的預測不僅限於數據擬合算法,還可以利用但不限於以下算法:簡易平均算法、移動平均算法、指數平滑算法、線性回歸算法
在本發明另一個具體實施例中,所述步驟S1前還包括以下步驟,S001.採集信息系統數據S002.將所述信息系統數據歸一化處理,將數據都限定在[0,1]範圍內。
在本發明另一個具體實施例中,步驟S12具體方式如下:
①求出條件屬性C的等價集;
②求出決策屬性D的等價集;
③求出決策屬性的各等價集的下近似集;
④以條件屬性A為例,計算條件屬性C相對於決策屬性D的重要性γ(C,D),以及γ(C-{A},D);
⑤求A的重要度Sig(A,C,D)
Sig(A,C,D)=γ(C,D)-γ(C-{A},D)
Sig(A,C,D)>0表示屬性是重要的,否則表示屬性是不必要冗餘的,去掉它們後對分類結果不產生任何影響。通過這種方法就可以識別出關鍵的監控指標(KPI)。
在本發明的又一個實施例中,所述「關聯規則挖掘算法」還包括以下步驟:
S21.若|Lk-1|<k,則輸出Ck=φ;若|Lk-1|≥k,則計算出候選k項目集Ck;
S22.若CK≠φ,則計算出候選項目集Ck的各個候選項目支持度,求得k項目集合Lk。
在本發明另一個具體實施例中,所述「關聯規則挖掘算法」還包括以下步驟:
S21.若|Lk-1|<k,則輸出Ck=φ;若|Lk-1|≥k,則計算出候選k項目集Ck;
S22.若CK≠φ,則計算出候選項目集Ck的各個候選項目支持度,求得k項目集合Lk。
單個信息系統通常由主機、中間件和資料庫構成的有機整體,它們之間是相互關聯的。因此我們需要挖掘出各監控指標與信息系統運行狀態的關聯規則,這樣就可以通過它們之間的關聯關係預判信息系統是否存在問題。我們以營銷基礎數據平臺系統為例,進行關聯分析。
營銷基礎數據平臺系統主要包括2臺資料庫伺服器和4臺應用伺服器(包括主機和中間件)。
這裡我們進行關聯分析的監控指標包括資料庫的「資料庫表空間」與「資料庫狀態」兩個指標、中間件的「JVM運行時間」一個指標、主機的「CPU利用率」一個指標,總共4個監控指標。通過對資料庫中各監控指標的各個欄位的分析和研究,我們發現可以根據各個監控指標的category欄位(good\warning\error)來進行關聯分析。在本文中,我們利用改進的Apriori算法進行關聯規則的挖掘,以發現各個監控指標之間的關聯關係。在這裡,所有支持度大於最小支持度的項集稱為頻繁項集,簡稱頻集。為了便於分析,我們分別對各個指標的category欄位的值進行標記,標記規則如表I所示。
表I標記規則
我們對2016年3月1日至3月8日的某公司信息中心的監控數據進行了關聯分析,分析出不同的最小支持度和可信度時的關聯規則,結果如下:
當min_support=60000,min_confidence=0.9時,其關聯規則有:
比如關聯規則"a11"^"c11"->"b11"^"a21":0.98922274432,表示資料庫表空間是good、JVM運行時間good時,CPU利用率是good,那麼應用系統的狀態是good(正常狀態),這個關聯規則的可信度為98.9%。
通過預測算法預測出資料庫表空間、JVM運行時間和CPU利用率在將來的某個時刻的狀態,就可以通過它們之間的關聯規則,預測出應用系統在將來的某個時刻的運行狀態。
在本發明的又一個實施例中,步驟S002更具體地,主要包括以下的步驟:
其中,為歸一化後的數據,xmin和xmax分別為原始數據的最小值和最大值,以為數據個數。
如圖2所示,本發明的一種信息系統運行狀態預測裝置的總體結構示意圖,包括:
A1採集模塊,用於採集信息系統數據;
A2處理模塊,用於基於信息系統數據,利用粗糙集算法識別出信息系統的關鍵監控指標;基於信息系統數據,利用關聯規則挖掘算法建立各關鍵監控指標與信息系統運行狀態間的關聯規則;基於信息系統實時監控數據,利用所得關聯規則,結合預測算法,進行信息系統運行狀態的預測;
A3輸出模塊,用於輸出信息系統運行狀態的預測結果。
最後,本申請的方法僅為較佳的實施方案,並非用於限定本發明的保護範圍。凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。