用於正則表達式的編譯器的製作方法
2023-04-28 11:30:26 1
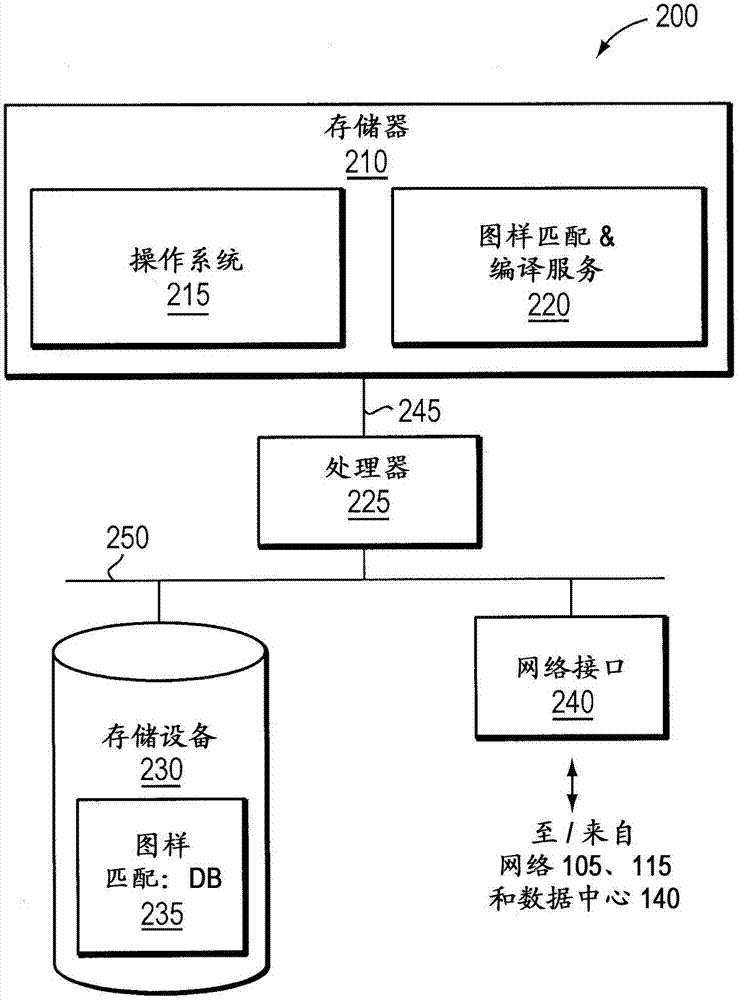
本申請是2012年6月20日遞交的第201280038799.2號發明專利申請的分案申請。相關申請本申請是2011年6月24日提交的美國申請no.13/168,450的繼續並且要求其優先權。上述申請的全部教導通過引用合併於此。本公開的非限制性示例一般地涉及通信網絡的
技術領域:
,並且更具體地涉及用於內容搜索的方法和裝置。
背景技術:
:開放系統互連(osi)參考模型定義了用於通過傳輸介質進行通信的7個網絡協議層(l1-l7)。上層(l4-l7)表示端對端通信並且下層(l1-l3)表示本地通信。聯網應用感知系統需要處理、濾波和切換l3到l7網絡協議層的範圍,例如,l7網絡協議層諸如超文本傳輸協議(http)和簡單郵件傳輸協議(smtp),以及l4網絡協議層諸如傳輸控制協議(tcp)。除了處理網絡協議層,聯網應用感知系統需要通過l4-l7網絡協議層來同時確保這些協議對基於訪問和內容的安全性,包括防火牆、虛擬專用網(vpn)、安全套接字層(ssl)、入侵檢測系統(tds)、網際網路協議安全(ipsec)、線速度的防病毒(av)和防垃圾郵件功能。網絡處理器可用於高吞吐量l2和l3網絡協議處理,即執行分組處理以線速度轉發分組。通常,通用處理器用於處理需要更多智能處理的l4-l7網絡協議。雖然通用處理器可以執行計算密集型任務,但是沒有足夠用於處理數據使得其能夠被以線速轉發的性能。內容感知聯網需要以「線速度」的對分組內容的檢查。可以對內容進行分析,以確定是否存在安全漏洞或入侵。應用大量正則表示式形式的圖樣和規則以確保所有的安全漏洞或入侵被檢測到。正則表示式是用於描述字符串的圖樣的緊湊型方法。由正則表示式所匹配的最簡單圖樣是單個字符或字符串,例如,/c/或/cat/。正則表示式還包括具有特殊含義的運算符和元字符。通過使用元字符,正則表示式可以用於更複雜的搜索,諸如「abc.*xyz」。也就是說,在不限制「abc」和「xyz」之間的字符數目的情況下,找到字符串「abc」,之後是字符串「xyz」。另一示例是正則表示式「abc..abc.*xyz;」,也就是找到字符串「abc」,後面兩個字符,然後是「abc」並且在不限制個數的字符後由串「xyz」跟隨。入侵檢測系統(ids)應用檢查所有流過網絡的獨立分組的內容,並且識別可能指示嘗試闖入或威脅系統的可疑圖樣。可疑圖樣的一個示例可以是分組中的特定文本串,該特定文本串在100個字符以後跟隨另一特定文本串。通常使用搜索算法來執行內容搜索以處理正則表示式,搜索算法諸如確定性有限自動機(dfa)或者非確定性有限自動機(nfa)。技術實現要素:一種方法和相應的裝置,涉及將用於給定的圖樣集合的非確定性有限自動機(nfa)圖形轉換成具有多個狀態的確定性有限自動機(dfa)圖形。dfa狀態中的每一個被映射成nfa圖形的一個或多個狀態。計算映射成每個dfa狀態的nfa圖形的一個或多個狀態的哈希值。對於給定圖樣,dfa狀態表將多個dfa狀態中的每一個與nfa圖形的一個或多個狀態的哈希值相關。可以確定與由nfa圖形和dfa圖形所識別的字母相關聯的給定圖樣的有效字符。基於該確定,該方法壓縮nfa圖形和dfa圖形以識別圖樣,該圖樣僅由與nfa圖形和dfa圖形所識別的字母相關聯的給定圖樣的有效字符組成。附圖說明從如在附圖中所示的本發明的示例性實施例的以下更具體的描述中,前述內容將顯而易見,在附圖中相同的附圖標記指代所有不同視圖中的相同部件。附圖不一定按比例,而是著重於圖示本發明的實施例。圖1是圖示系統的框圖,在該系統中操作安全設備以保護專用網絡。圖2是可以由本發明使用的安全設備的框圖。圖3是示例nfa的nfa圖形。圖4是示例dfa的dfa圖形。圖5a-g是圖示圖形爆炸的原理的nfa和dfa圖形和表。圖6a-b是將nfa圖形轉換成dfa圖形的方法的流程圖。圖7是用於確定nfa圖形中的狀態的埃普西隆終止的方法的流程圖。圖8a-c是用於將nfa圖形轉換成dfa圖形的方法的流程圖。圖9是用於確定nfa圖形中的狀態的埃普西隆終止的方法的流程圖。圖9a-9b是用於將nfa圖形轉換成dfa圖形的方法的流程圖。圖9c是用於確定用於一組nfa狀態的埃普西隆終止的流程圖。圖10圖示了用於使用aho-corasik算法來搜索例如圖樣「她的」、「他的」和「她」的圖樣匹配機制。圖11a圖示了圖樣匹配機制的每個狀態的故障值。圖11b圖示了圖樣匹配機制的狀態的輸出函數值。圖12圖示了例如錨定的圖樣「幫助」和「貝殼」的狀態樹。圖12a圖示了圖12的狀態樹的每個狀態的故障值。圖12b圖示了圖12的狀態樹的狀態14和19的輸出函數值。圖13a圖示了圖12中的狀態樹的每個狀態的故障值。圖13b圖示了圖12的狀態樹的狀態12、14、17和19的輸出函數值。具體實施方式在詳細描述本發明的示例性實施例之前,以下馬上描述其中可以實現實施例的示例安全應用以及使用dfa和nfa的典型處理,以有助於讀者理解本發明的發明特徵。正則表示式(regex)處理在許多分組處理系統中變得普遍。regex處理可以應用於傳統的安全系統(例如,入侵防止系統(ips)、防火牆和統一威脅管理(utm)設備)、較新的安全系統(例如,防惡意軟體、反間諜軟體、零日附加檢測)、在有線/無線網絡中用於計費,服務質量(qos)和網絡監控系統的新興的協議/應用識別系統。正則表示式處理可以被細分為兩個階段i)將籤名/圖樣編譯成二進位數據結構,諸如dfa圖形或nfa圖形,以及ii)根據編譯的圖形處理接收到的分組。存儲與性能的折衷要求在正則表示式處理的兩個階段均發生。分配有大的運行時間內存佔用的編譯器能夠以較高的速度和效率來編譯圖樣。類似地,相對於緊湊圖,用於分組檢查的較大的圖或等效二進位數據結構可以給出更好的分組檢查性能。而在實踐中,期望編譯器以儘可能少的內存佔用來非常快速地編譯規則。一個原因是,在網絡設備仍然在運行(例如檢查/轉發分組)時在網絡設備(例如,路由器、交換機、utm等)的欄位中更新圖樣。因此,需要使用在嵌入的路由器設備中的有限內存來編譯規則。因為規則/圖樣用於防止對系統的攻擊或停止被病毒感染的業務,所以需要儘可能早地應用規則/圖樣以便於優化系統的安全性。因此,編譯器應當能夠非常快地將規則編譯成二進位數據結構。一般的方法在中央伺服器上將新的圖樣或籤名編譯成圖形,該中央伺服器然後向路由器傳送編譯了的圖形。然後,路由器通過使分組經過每個圖形來根據接收到的圖形檢查到達的分組。高效的編譯器需要足夠的內存資源。如果編譯器沒有足夠的資源,那麼編譯器性能很慢。因此,簡單方法不在路由器上編譯新的圖樣或特徵,因為路由器通常沒有足夠的資源(即,隨機存取存儲器(ram)和cpu計算)。本發明的實施例在路由器上將新的圖樣/籤名編譯成圖形,同時保持中央伺服器編譯器的性能水平。圖1是圖示系統100的框圖,該系統包括安全設備110、受保護的網絡115和公共網絡105。公共網絡105可以包括不安全的廣域網(wan),諸如網際網路、無線網絡、區域網或者其他類型的網絡。受保護的網絡115可以包括安全的計算機網絡,諸如辦公室或數據中心的區域網。如所示,區域網可以是包括多個工作站125的企業網絡120。多個工作站125可操作地耦合到資料庫130、ftp(文件傳輸協議)伺服器135和網際網路伺服器140。在系統100中,安全設備110連接到公共網絡105和受保護的網絡115,使得從公共網絡105流動到受保護網絡115的網絡業務首先流動到安全設備110。安全設備110可以是獨立的網絡設備(例如,路由器)、另一網絡設備(例如,防火牆設備)的組件、在網絡設備上執行的軟體模塊或其它配置。通常,安全設備檢查來自公共網絡105的網絡業務,並且確定網絡業務是否包括任何計算機安全威脅。計算機安全威脅是獲取對敏感信息的訪問的嘗試、破壞組織的操作的嘗試或其他類型的攻擊。示例計算機安全威脅包括計算機病毒、間諜軟體、流氓軟體(rootkit)、猜測密碼的嘗試、釣魚郵件、與拒絕服務添加相關聯的請求以及其他類型的攻擊。計算機安全威脅可以與一個或多個符號圖樣相關聯,該一個或多個符號圖樣識別計算機安全威脅,但不識別無害的數據。與計算機安全威脅相關聯的符號圖樣在本文中被稱為「威脅籤名」。例如,特定的病毒可能總是包括指令序列中,當被執行時該指令序列執行惡意操作。如果安全設備110確定了給定的網絡業務流不包括任何計算機安全威脅,則安全設備110可以將網絡業務流傳遞到受保護的網絡115。否則,如果安全設備110確定了該流包括一個或多個計算機安全威脅,則安全設備110可以丟棄該網絡業務、記錄該網絡業務、將該業務轉發到業務分析器以用於進一步分析,和/或執行關於該網絡業務的一些其他動作。以該方式,安全設備110可以防止包括計算機安全威脅的網絡業務到達受保護的網絡115。為了檢測與一個或多個符號圖樣相關聯的安全威脅,安全設備110從安全數據中心104接收在來自公共網絡105的到達數據業務中要被監測的給定的圖形或符號序列。一旦安全設備接收到要監測的給定圖樣,安全設備就針對要監測的每個給定的圖樣創建有限狀態機。安全設備110使接收到的數據分組經過有限狀態機,以確定到達的數據分組是否包括潛在的安全威脅。圖2是可以和本發明一起使用的示例性安全設備200的高層框圖。安全設備包括經由存儲器總線245耦合到處理器225的存儲器210以及經由輸入/輸出(i/o)總線250耦合到處理器的存儲設備230和網絡接口240。應當注意,安全設備可以包括其他設備,諸如鍵盤、顯示單元等。網絡接口240將安全設備與安全網絡115、公共網絡105和安全數據中心104對接,並且使得數據(例如,分組)能夠在安全設備和系統100中的其他節點之間進行傳送。為此,網絡接口240包括常規電路,包含信號、電氣和機械特徵,以及交換電路,需要該交換電路以與系統100的物理介質和在該介質上運行的協議對接。存儲器210是實施為ram的計算機可讀介質,包括諸如dram設備和/或快閃記憶體設備的ram設備。存儲器210包含各種軟體以及由處理器225使用的數據結構,包括實施本發明的各方面的數據結構。具體地,存儲器210包括作業系統215和圖樣匹配/編譯服務220。作業系統215在功能上通過調用支持軟體處理的操作和在安全設備200上執行的服務來組織安全設備200,諸如圖樣匹配/編譯服務220。如下面將要描述的,圖樣匹配/編譯服務220包括計算機可執行指令,用於從給定圖樣編譯有限狀態機圖形和/或使到達的數據分組經過編譯的圖形。存儲設備230是常規的存儲設備(例如,磁碟或更可能的dram),其包括圖樣匹配資料庫(db)235,該圖樣匹配資料庫(db)235是配置成保持用於從給定圖樣編譯有限狀態機的各種信息的數據結構。信息可以包括籤名圖樣、有限狀態機圖形(例如,dfa圖形和nfa圖形)、埃普西隆終止(ec)高速緩存表以及dfa狀態哈希表。通常,內容感知應用處理使用確定性有限自動機(dfa)或非確定性有限自動機(nfa)來識別在接收到的分組的內容中的圖樣。dfa和nfa都是有限狀態機,即計算模型,計算模型中的每一個都包括狀態集合、開始狀態、輸入字母(所有可能的符號集合)和轉換函數。計算在啟動狀態中開始,並且根據轉換函數而改變為新的狀態。圖樣通常使用正則表示式來表述,正則表示式包括基本元素,例如,諸如a-z、0-9的正常文本字符以及諸如*、^和|的元字符。正則表示式的基本元素是要被匹配的符號(單個字符)。這些與允許級聯(+)、替換(|)和克林星號(*)元字符組合。用於級聯的元字符用於從單個字符(或子串)創建多個字符匹配模式,而用於替換(|)的元字符用於創建可以匹配兩個或更多個子串中任何一個的正則表示式。元字符克林星號(*)允許圖樣匹配任何數目,包括不出現前面字符或字符串。結合不同的運算符和單個字符允許構建複雜的表示式。例如,表示式(th(is|at)*)將匹配以下字符串:th,this,that,thisis,thisat,thatis或thatat。字符類結構[...]允許列出要搜索的字符的列表,例如gr[ea]y查找grey和gray。破折號指示字符的範圍,例如[a-z]。元字符「.」匹配任何一個字符。對dfa或nfa狀態機的輸入通常是(8位)字節的串,即,字母是單個字節(一個字符或符號)。輸入流中的每個字節產生從一個狀態到另一狀態的轉換。dfa或nfa狀態機的狀態和轉換函數可以通過圖來解釋,其中圖中的每個節點表示狀態,並且圖中的圓弧表示狀態轉換。狀態機的當前狀態由選擇特定圖形節點的節點識別符來表示。使用dfa來處理正則表示式並且找到字符的輸入流中由正則表示式描述的一個或多個圖樣的特徵在於:1)確定的運行時間性能:dfa的下一個狀態可以從輸入字符(或符號)以及dfa的當前狀態來確定。換言之,每dfa狀態僅存在一次狀態轉換。這樣,dfa的運行時間性能被認為是確定的並且行為可以從輸入完全預測。2)支持跨多個分組匹配所需要的較小的每流上下文(例如,狀態或節點指針):在搜索跨越構成流的若干分組的輸入的圖樣中,搜索可能在一個分組處停止,並且然後在另一個分組處恢復。通常,確定要恢復搜索的狀態需要跟蹤、記住或以其他方式存儲(例如,作為狀態指針)直至搜索停止時所經歷的所有狀態。然而,在dfa中,為了恢復搜索,僅需要記錄搜索停止時的狀態。這樣,可以說,dfa被特徵化為需要較小的每流上下文,以支持跨多個輸入分組的圖樣匹配,例如,以幾字節的量級存儲狀態或節點指針。3)節點的數目(或圖形大小)隨著圖樣的大小呈指數增長的圖形。相比之下,使用nfa來處理正則表示式並且找到由字符的輸入流中的正則表示式描述的圖樣的特徵在於:1)非確定的運行時間性能:給定輸入字符(或符號)和nfa的當前狀態,可能存在要轉換到的多於一個nfa的下一狀態。換言之,nfa的下一狀態不能從nfa的輸入和當前狀態來確定。這樣,nfa的運行時間性能被認為是不確定的,並且行為不能完全從輸入預測。2)支持跨多個分組匹配所需要的較大的每流上下文(例如,狀態或節點指針):如前所述,圖樣跨多個輸入分組匹配,其中搜索在一個分組處停止,然後在另一分組處恢復,需要跟蹤直至在分組停止時所經歷的所有狀態。在nfa中,越多輸入被匹配,經歷的狀態和需要跟蹤的狀態的數目就越多。這樣,可以說,與dfa相比,nfa被特徵化為需要較大的每流上下文,以支持跨多個輸入分組的圖樣匹配。3)節點的數目(或圖形大小)隨著圖樣的大小呈線性增長的圖形。進一步參考附圖3、4和5-g來討論上述dfa和nfa的特徵。應當注意,為簡單起見,對於附圖中所示的所有dfa圖形,沒有示出到節點(狀態)0的弧(狀態轉換),並且也沒有示出對於相同字符的到與由節點0指向的節點相同的節點的弧。圖3示出了用於搜索圖樣「cavium.*networks」、「nitrox[^\r\n\t\v\s]{3}octeon」和「purevu.{5,10}videochips」的示例nfa的nfa圖形300。圖4示出了用於搜索相同的圖樣集合的示例dfa的dfa圖形400。如上所述,應當注意,dfa圖形400和本文中所提供的其他dfa圖形是出於繪製的目的而被「簡化」的。在附圖中沒有示出表示到dfa狀態0的狀態轉換的到節點0的弧。在附圖中也沒有示出對於相同字符的到與由節點0指向的節點相同的節點的弧。對於相同的圖樣集合,圖3的nfa圖形300具有69個節點,表示69個狀態,而圖4的dfa圖形400具有931個節點(在圖4中僅示出了其中的一部分),表示931個狀態。如示,對於給定的一個或多個圖樣,dfa狀態的數目可以大於nfa狀態的數目,通常多了幾百或幾千量級的狀態的。這是「圖形爆炸」的示例,這是dfa的標誌性特徵。為了進一步描述「圖形爆炸」的概念,考慮分別示出了對於圖樣「.*a[^\n]」、「.*a[^\n][^\n]」、「.*a[^\n][^\n][^\n]」的nfa圖形的圖5a、圖5b和圖5c,以及示出了對於相同圖樣的dfa圖形的圖5d、圖5e和圖5f。其中,在圖5d、5e、5f中沒有示出看到「\n」的情況下的來自每個狀態的返回箭頭。如圖5a-5f中所示以及由圖5g的表所總結的,對於一些圖樣,nfa可以線性增長,而dfa可以指數地增長而產生圖形爆炸。返回圖3,使用圖形300表示的nfa來搜索輸入流「purevuchipsarevideochips」中的圖樣,nfa處理或匹配開始於nfa的開始狀態0、2、19和36,由節點305a-d表示並且簡寫為nfastartstates={0,2,19,36}。關於輸入流的字符「p」,nfa轉換到狀態37(由節點310表示)並且跟蹤狀態0、2和19(簡寫為對「p」={0,2,19,37}),並且繼續如下:對「u」={0,2,19,38}對「r」={0,2,19,39}對「e」={0,2,19,40}對「v」={0,2,19,41}對「u」={0,2,19,42}對「c」={0,2,19,44}對「h」={0,2,19,45}…...等,使用圖4的dfa圖形400表示的dfa來搜索在相同輸入中的相同圖樣,dfa匹配開始於dfa開始狀態0,由節點405表示並且簡寫為dfastartstates={0}。對於輸入流的字符「p」,dfa轉換到狀態3,由節點410表示並且簡寫為對「p」={3},並且繼續如下:對「u」={6}對「r」={9}對「e」={12}對「v」={15}對「u」={18}對「c」={27}對「h」={41}…...等。如在上面的示例中所示,在nfa中,存在至少n+1個數目的nfa狀態要跟蹤,其中n是要搜索的圖樣的數目(例如,在要搜索3個圖樣的情況下,存在至少4個要跟蹤的狀態)。與此相反,在dfa中,每個輸入字符僅存在一個狀態要跟蹤。為了說明的目的,現在假定輸入流(stream)或流(flow)「purevuchipsarevideochips」跨越多個分組,其中第一分組以「purevuchips」的「h」結束,並且第二分組以「purevuchips」的「i」開始。在nfa中,搜索在「h」(第一分組的結束)停止,具有四種狀態要跟蹤(即,狀態0,2,19和45)。為了在「i」恢復搜索(第二分組的開始),需要記住這四個狀態。相反,在dfa中,搜索在「h」(第一分組的結束)停止,具有一個狀態被跟蹤(即,狀態41)。為了在「i」恢復搜索(第二分組的開始),需要記住這一個狀態。該示例示出,在nfa中,支持跨多個分組的匹配需要的的每流上下文是四個狀態(例如,通過存儲四個狀態指針),而在dfa中,每流上下文是一個狀態。因此,nfa需要的每流上下文比相同圖樣的dfa所需要的每流上下文更大。類似地,dfa需要的每流上下文比相同圖樣的nfa所需要的每流上下文更小。對於每個非確定性有限自動機,存在等效的確定性有限自動機。這兩者之間的等效以語言接受來定義。因為nfa是有限自動機,其中,對於輸入符號允許0、1或多次轉換,所以等效的dfa可以被構造為模擬關於特定輸入符號的並行的nfa的所有移動。由於nfa的dfa等效模擬(並行)nfa的移動,dfa的每個狀態是nfa的一個或多個狀態的組合。因此,dfa的每個狀態將由nfa的狀態集合的某個子集來表示;並且因此,從nfa到dfa的轉換通常被稱為「構建」子集。因此,如果給定的nfa具有n個狀態,則等效的dfa可以具有2n數目的狀態,其中初始狀態對應於子集{q0}。因此,從nfa到dfa的轉換涉及找到nfa的狀態集合的所有可能的子集,考慮每個子集是dfa的狀態,並且然後找到對於每個輸入符號從該狀態的轉換。如上所述,由於nfa的多個可能的轉換,由計算機系統對nfa圖形進行處理是困難的,因此nfa到dfa的轉換發生。圖6a-b是用於將nfa圖形轉換為dfa圖形的方法600的流程圖。該方法600開始於605。在該階段,dfa狀態集合「sd」為空。在610,dfa的開始狀態被確定並添加到dfa狀態集合「sd」作為未標記的狀態。dfa的開始狀態被確定為nfa圖形的開始狀態的埃普西隆終止。以下參考圖7來進一步描述確定nfa狀態集合的埃普西隆終止的方法。在615,確定dfa狀態集合「sd」是否包括未標記的dfa狀態。如果該dfa狀態集合「sd」的未標記的dfa狀態存在,則在620,未標記的狀態」s」被選擇並標記。在625,由nfa圖形所識別的語言「a」的字母(例如,文字)被選擇。在步驟630,dfa狀態「s」的nfa狀態「s」被選擇。此外,步驟630之前,用於保持nfa狀態集合的數據結構「st」被設置為「空」。在635,轉換函數「ttn=(s,a)」被使用字母「a」應用於nfa狀態「s」。如果接收到「a」的輸入,轉換函數確定從nfa狀態「s」到達的所有nfa狀態。然後,確定的nfa的狀態被添加到該數據結構「st」。在644,確定dfa狀態「s」是否包括其他的nfa狀態。如果是,則該方法重複步驟630和635,直到dfa狀態「s」的所有nfa狀態「s」已經被處理。如果已經處理了所有的nfa狀態,則該方法在步驟640繼續。在640,在數據結構「st」中的所有nfa狀態「s」的埃普西隆終止被確定並且被添加到數據結構「st」。在步驟645,將數據結構「st」與所有現有的dfa狀態「s」作比較,以確定dfa狀態「s」是否已經包括數據結構「st」中的所有nfa狀態「s」。當前的方法存儲與數據結構中的每個dfa狀態「s」相關聯的每個nfa狀態「s」。為了確定數據結構「st」中的nfa狀態是否已經與dfa狀態「s」相關聯,數據結構「st」的「每個nfa狀態「s」必須與每個dfa狀態「s」每個nfa狀態「s」作比較。因此,這樣的比較需要大量的時間和內存。以下表1說明了將dfa狀態數與nfa狀態集合相關聯的示例dfa狀態表。nfa狀態集合可以針對每個dfa狀態數被存儲在數據結構中,如上所述。表1dfa狀態數nfa狀態集合0{0,1,2,3,4}1{0,5,6,7}2{8,9,2,3}…………例如,根據數據結構的實現(包含dfa狀態及其相應的nfa狀態集合),以下參考表2來獲得在步驟645的操作的運行時間。表2列出了示例數據結構實現的存儲和維護成本。表2的注釋列提供了每個示例數據結構的描述。對於每個數據結構,假定存在「n」個dfa的狀態,並且進一步假設每個dfa狀態平均表示'm'個nfa狀態。表2繼續圖6a-b,如果dfa狀態「s」已經包括數據結構「st」的所有nfa狀態「s」,則該方法移動到步驟695.如果沒有,則該方法移動到步驟685.在685,數據結構「st」中的nfa狀態「s」被添加到dfa狀態集合「sd」作為新的dfa狀態「d」。在690,確定nfa狀態「s」中的任何一個是否屬於nfa圖形的最終狀態集合。如果是,則新的dfa狀態被確定為nfa圖形的最終接受狀態。在695,具有輸入「s」的從標記的dfa狀態「s」的轉換被設置為新的dfa狀態「d」。圖7是方法700的流程圖,該方法700用於確定對於nfa圖形的任何給定的nfa狀態「s」的埃普西隆終止。方法700開始於步驟705。在710,埃普西隆終止函數接收用於處理的nfa狀態「s」。在715,nfa的狀態「s」沒有被標記,並且被添加到未標記的nfa狀態集合「s」。在720,從未標記的nfa狀態「s」中選擇nfa狀態「s」。在725,確定從選擇的nfa狀態「s」的埃普西隆轉換。在步驟730,確定是否存在任何埃普西隆轉換。如果沒有,則在740,所選擇的nfa狀態's'被添加在埃普西隆終止集合中。如果存在轉換,那麼在步驟745,從選擇的nfa狀態's'的所有確定的nfa轉換被添加到集合「s」作為未標記的nfa狀態。步驟750確定在nfa狀態「s」中是否存在任何未標記的nfa狀態。如果有,則方法從步驟720繼續。如果沒有,該方法在步驟755結束。用於以上參考的方法的示例偽代碼#1(開始於圖6a的步驟615)如下:1.對於每個未標記的dfa狀態「d」(列-1——在dfa狀態表中,上述表1)1.對於字母集合中的每個字母「a」1.集合s={}2.對於「d」的每個nfa狀態「n」(列-2——在dfa狀態表,上述表1)1.如果「n」具有對「a」的到「m」弧的外出弧1.s=su{m}3.se=eclosure(s)4.將發現指定為「假」5.對於dfa狀態表中的每個dfa狀態,上述表11.使「p」是對應於dfa狀態「f」的nfa狀態集合2.如果集合「se」和「p」相等1.將發現指定為「真」2.去往1.66.如果發現為「真」1.設置轉換(「d」,「a」)=「f」7.其他1.添加新的dfa狀態「f」到dfa狀態表,表1以「se」作為col.2中的nfa狀態的集合2.設置轉換(「d」,「a」)=「f」2.將「d」設置為「標記的」上述參考方法的缺點如下:i)偽代碼的步驟1.1.3,表示方法700和600,總是計算埃普西隆終止(eclosure),因為在存儲器中沒有存儲埃普西隆終止的歷史;ii)步驟1.1.5.2由於集合等效測試而非常耗時。由該集合等效測試所消耗的時間取決於要比較的集合中的元素的數目(即,在dfa狀態中的nfa狀態數(如表1中示出);以及iii)表1中的條目不能被刪除因為條目對於執行集合等效測試的步驟1.1.5.2時需要的,由此需要大量的內存資源。在本發明的示例實施例中,nfa圖形被轉換為等效dfa圖形。圖8a-c是按照本發明的示例實施例的用於將nfa圖形轉換為nfa圖形的方法800的流程圖。該方法800開始於805。在該階段,dfa狀態的集合「sd」為空。在810,dfa的開始狀態被確定並被添加到dfa狀態的集合「sd」作為未標記的狀態。dfa的開始狀態被確定為nfa圖形的開始狀態的埃普西隆終止。以下參考圖9來進一步描述按照本發明的示例實施例的確定nfa狀態的埃普西隆終止的方法。在815,與dfa開始狀態相關聯的nfa狀態的加密/完美哈希值被計算並存儲表中,該表使dfa狀態與關聯於dfa狀態的nfa狀態的哈希值相關,如以下表4中所示。在820,nfa開始狀態的埃普西隆終止被存儲在在表5中進一步所示的埃普西隆高速緩存中。埃普西隆高速緩存被輸入nfa狀態的集合的哈希所檢索,並且所存儲的數據是計算的輸入nfa狀態的埃普西隆終止。加密哈希/完美哈希函數是確定性過程,該過程需要取得任意數據塊,並且返回固定大小的位串,該位串是加密的哈希值。示例加密哈希函數包括,例如,消息摘要算法(md5)或安全哈希算法(sha1/sha2)。在較大摘要(例如,對於md5為128b)的情況下,衝突的機會不太可能。然而,「完整性檢查」可以離線進行,以驗證不存在衝突(具有相同哈希值的不同數據集合),使得如果發生衝突,則可以校正圖形。在825,確定dfa狀態集合「sd」是否包括未標記的dfa狀態。如果不包括,該方法在步驟895結束。如果該dfa狀態集合「sd」的未標記的dfa狀態存在,則在830,未標記的狀態「s」被選擇並且標記。在835,由nfa圖形識別的語言「a」的字母(例如,文字)被選擇。此外,用於保持nfa狀態集合的數據結構「st」被設置為「空」。在步驟840,選擇與dfa狀態「s」相關聯的nfa狀態「s」。在850,使用字母「a」輸入值,將轉換函數「ttn=(s,a)」應用於nfa狀態「s」。如果接收到「a」的輸入,轉換函數確定從nfa的狀態」s」到達的所有nfa狀態。在855,確定的nfa的狀態然後被存儲在數據結構「st」中。在860,確定dfa狀態「s」是否包括額外的關聯的nfa狀態。如果包括,則該方法在步驟850和855重複,直到dfa狀態「s」的所有nfa狀態的「s」已經被處理。如果所有的nfa狀態已經被處理,則該方法在步驟865繼續。在865,數據結構「st」中的所有nfa狀態」s」的埃普西隆終止按照圖9被確定並且被添加到數據結構「se」。在步驟870,將數據結構「se」與所有存在的dfa狀態「s」作比較,以確定dfa狀態「s」是否將所有的nfa狀態「s」包括在數據結構「se」中。如以上參考方法600的步驟645所述,一般的方法將與每個dfa狀態「s」相關聯的nfa狀態「s」的集合存儲在數據結構中。為了確定數據結構「se」中的nfa狀態「s」是否已經與dfa狀態「s」相關聯,必須針對每個dfa狀態「s」來將數據結構「se」的每個nfa狀態集合「s」與每個nfa狀態集合「s」作比較。因此,這樣的比較需要大量的時間和內存,如表2中所示。在本實施例中,數據結構「se」中的nfa狀態的加密/完美哈希值被計算並且然後與表作比較,該表將dfa狀態數與其一個或多個nfa狀態的對應集合的哈希值相關。如果匹配哈希值存在,那麼,在步驟870,確定與數據結構「se」中的nfa狀態相關聯的dfa狀態是否已經存在,並且該方法移動到步驟890。在890,具有字母「a」的輸入的從dfa狀態「s」的轉換被設置為與匹配哈希值相關聯的現有dfa狀態。該方法移動到步驟845,其中作出關於另一字母「a」是否存在於語言『a』中的確定,如果存在,則該方法從步驟835重複。如果不存在,則該方法移動到步驟847。在步驟847,該方法刪除nfa狀態數集合,並且將狀態集合添加為標記的。然後,該方法在步驟825繼續。以下參考表3來獲得在步驟870處的操作的運行時間。表3列出了根據本發明的示例實施例的哈希匹配的儲存和維護成本。表3的注釋列提供了哈希匹配的描述。表3如以下所示的表4是dfa表,如上所述,該表將dfa狀態數與其一個或多個nfa狀態的對應集合的哈希值相關。表4dfa狀態數dfa狀態哈希nfa狀態數集合標記(m)/未標記(u)081237912891273刪除m109237504823405刪除m223894729379237{4,5,6,2,0,1}u389345798731278{4,2,3,7,1,8}u………繼續圖8,如果在步驟870不存在匹配哈希值,則該方法移動到步驟875。在875,數據結構「se」中的nfa狀態「s」被添加到dfa狀態集合「sd」作為新的未標記的dfa狀態(例如,「d」)。此外,nfa狀態「s」的加密/完美哈希值被計算,並且該新的dfa狀態被映射到上述表4中的哈希值。在880,確定nfa狀態「s」中的任何一個是否屬於nfa圖形的最終狀態集合。如果是,則新的dfa狀態被確定為nfa圖形的最終接受狀態。在885,具有輸入「a」從標記的dfa狀態「s」的轉換被確定為新的dfa狀態「d」。圖9是方法900的流程圖,該方法用於按照本發明的示例實施例確定nfa圖形中的狀態集合的埃普西隆終止。方法900開始於步驟905。在910,埃普西隆終止計算器接收到nfa狀態的集合。在915,將nfa狀態的集合與高速緩存內的條目作比較,以確定高速緩存是否包含匹配的nfa狀態的集合。高速緩存內的每個條目可以被存儲為哈希值,該哈希值表示映射到nfa狀態的輸入集合的埃普西隆終止的nfa狀態集合。計算器根據接收到的nfa狀態的集合計算哈希值,並且確定ec高速緩存是否具有與nfa狀態的集合相關聯的匹配哈希值條目。如以下所示,表5是埃普西隆終止高速緩存表,如上所述,該表將nfa狀態的集合映射到其埃普西隆終止。表5ec輸入集合哈希ec輸出集合78346782346782{3,4,1,2,7}89237489237492{8,3,2,5,19}……繼續圖9,如果發現匹配,則在920返回埃普西隆終止。然而,如果沒有發現匹配,則計算接收到的nfa狀態的集合的埃普西隆終止。如以上參考圖7描述的方法700所述來計算埃普西隆終止。一旦計算了埃普西隆終止,在930,埃普西隆終止被存儲作為埃普西隆高速緩存中的新的條目。在935,返回計算的埃普西隆終止。方法900通過消除冗餘處理而允許埃普西隆終止的高效處理。例如,方法900僅當還沒有計算埃普西隆終止時計算nfa狀態集合的埃普西隆終止。這消除了對於一個nfa集合進行多於一次的埃普西隆終止的處理的需要。參考以上參考圖6a-b描述的方法600,該方法可以多於一次地計算任何給定nfa節點的埃普西隆終止。然而,通過將先前計算的埃普西隆終止存儲在高速緩存中,方法900消除了不必要的數據處理的需要。以上所參考的方法的示例偽代碼#2(開始於圖8a的步驟825)如下:1.對於每個未標記dfa狀態「d」(列-1—在dfa狀態表中,上述表4)1.對於字母集合中的每個字母「a」1.設置s={}2.對於「d」的每個nfa裝置「n」(列-3—在dfa狀態表中,上述表4)1.如果「n」具有對於「a」的至「m」的外出弧1.s=su{m}3.獲取集合「s」的eclosure「se」,如以下給出1.計算集合「s」的哈希「hi」2.對於ec高速緩存表中的每個條目「e」,上述表51.使「he」是條目「e」處的哈希值(列-1—在上述ec高速緩存表中)2.如果「hi」和「he」是相同的1.se=ec輸出集合(e),即,列-2—在上述ec高速緩存表中2.前進到1.1.43.se=eclosure(s)4.以欄位「hi」和「se」將新的條目添加到上述ec高速緩存表4.將發現指定為「假」5.計算集合「se」的哈希「q」6.對於dfa狀態表中的每個dfa狀態「f」,上述表41.使得「p」是dfa狀態「f」的nfa狀態的哈希2.如果「p」和「q」相同1.將發現指定為「真」2.前進到1.1.77.如果發現為「真」1.設置轉換(「d」,「a」)=「f」8.其他1.將新的dfa狀態「f」添加到dfa狀態表,具有欄位「q」和「se」的表42.設置轉換(「d」,「a」)=「f」2.從dfa狀態表、表4中刪除dfa狀態「d」的nfa狀態數的集合,並且將「d」設置為標記的。上面所參考的方法的優點如下:i)如果已經計算過,則步驟1.1.3避免計算eclosure;ii)步驟1.1.6.2是哈希值的比較,其大小是恆定的,並且花費固定時間量用於比較,與集合等效測試相比更好。時間量是o(1),如以上表3中所示;以及iii)因為在進行處理之後刪除dfa狀態的nfa狀態集合,所以節省編譯器的大量內存佔用,如表4所示。另一優化在於,ec_cache還可以存儲直接dfa狀態數,而不是對應於(nfa狀態的)埃普西隆終止集合的nfa狀態集合,使得完全不需要步驟870。例如,如果在ec_cache中存在命中,則不需要搜索等效的dfa節點。如以下所示,表6是示例ec_cache表,其存儲對應於(nfa狀態的)埃普西隆終止集合的直接dfa狀態數。表6ec輸入集合哈希dfa狀態數78346782346782138923748923749214…因此,步驟870的處理表變為:表7圖9a-b是方法901的流程圖,按照本發明的示例實施例,該方法用於將nfa圖形轉換成dfa圖形。方法901開始於902。在該階段,dfa狀態集合「sd」為空。在903,dfa的開始狀態被確定並且被添加到dfa狀態集合「sd」作為未標記的狀態。dfa的開始狀態被確定為nfa圖形的開始狀態的埃普西隆終止。以下參考圖9c來進一步描述按照本發明的示例實施例的確定nfa狀態的埃普西隆終止的方法。在904,與dfa開始狀態相關聯的nfa狀態的加密/完美哈希值被計算,並且在906,dfa開始狀態和加密哈希的映射被存儲在表中,該表將dfa狀態與關聯於該dfa狀態的nfa狀態的哈希值相關,如上述表6中所示。在907,確定dfa狀態集合「sd」是否包括未標記的dfa狀態。如果不包括,則該方法在步驟908結束。如dfa狀態集合「sd」的未標記的dfa狀態存在,則在909,未標記的狀態「d」被選擇和標記。在911,由nfa圖形所識別的語言'a'的字母(如文字)被選擇。此外,用於保持nfa狀態集合的數據結構的「s」被設置為「空」。在步驟913,與dfa狀態「d」相關聯的nfa狀態'n'被選擇。在914,轉換函數「ttn=(s,a)」被應用於nfa狀態「n」,使用字母「a」輸入值。如果接收到「a」的輸入,則該轉換函數確定從nfa狀態「n」到達的所有nfa狀態。在916,然後將確定的nfa狀態存儲在數據結構「s」中。在917,確定dfa狀態'd'是否包括額外的相關聯的nfa狀態。如果是,則該方法在步驟913重複,直到dfa狀態「d」的所有nfa狀態'n'已經被處理。如果所有的nfa狀態已經被處理,則該方法在步驟918繼續。在918,根據字母「a」的從dfa狀態「d」的轉換被按照圖9c確定。在步驟919,具有字母「a」的輸入的從dfa狀態「d」的轉換狀態「f」被設置並存儲在dfa狀態表中。在921,從數據結構「s」中刪除存儲的nfa轉換狀態的集合。圖9c是方法922的流程圖,根據本發明的示例實施例,該方法用於確定nfa圖形中的狀態集合的埃普西隆終止。該方法922開始於步驟923。在924,埃普西隆終止計算器接收nfa狀態集合併且針對接收到的nfa狀態集合來計算哈希值「hi」。在926,將哈希值「hi」與在埃普西隆高速緩存內的條目作比較,以確定該高速緩存是否包含匹配。高速緩存中的每個條目可以被存儲為哈希值,該哈希值表示映射到dfa狀態的nfa狀態的集合。計算器根據接收到的nfa狀態集合計算哈希值,並且確定ec高速緩存是否具有與nfa狀態集合相關聯的匹配哈希值條目,該nfa狀態集合與dfa狀態相關。如果找到匹配,則在933,返回映射到高速緩存表的匹配哈希值的dfa狀態「f」。然而,如果沒有找到匹配,則在步驟928,計算接收到的nfa狀態的集合的埃普西隆終止。可以如以上參考圖7描述的方法700如上所述計算埃普西隆終止。一旦計算了埃普西隆終止,在929,埃普西隆終止的加密哈希被計算並作為新條目被存儲在埃普西隆高速緩存中。在931,對應於nfa狀態集合的哈希值的新dfa狀態「f」被映射到ec高速緩存表中的哈希值。在932,返回新dfa狀態「f」。上述所參考的方法的示例偽代碼#3如下:1.對於每個未標記dfa狀態「d」(列-1—在dfa狀態表、上述表4中)1.對於字母集合中的每個字母「a」1.設置s={}2.對於「d」的每個nfa狀態「n」(列-3—在dfa狀態表、上述表4中)1.如果「n」具有對於「a」的至「m」的外出弧1.s=su{m}3.獲取dfa狀態「d」的關於字母「a」的轉換dfa狀態「f」如下1.計算集合「s」的哈希「hi」2.對於ec高速緩存表、上述表6中的每個條目「e」,1.使「he」是條目「e」處的哈希值(列-1——上述ec高速緩存表6中)2.如果「hi」和「he」是相同的1.向條目「e」的dfa狀態數指派「f」,即,列-2—在上述ec高速緩存表中2.前進到1.1.53.se=eclosure(s)4.計算集合「se」的哈希「q」5.將發現指定為「假」6.對於上述dfa狀態表中的每個dfa狀態「g」1.使得「p」是dfa狀態「g」的nfa狀態的哈希2.如果「p」和「q」相同1.將發現指定為「真」並且將「g」指派給為「f」2.前進到1.1.3.77.如果發現為「真」1.前進到1.1.48.使用「q」和「se」將新的未標記dfa狀態「f」添加到dfa狀態表4.使用哈希「hi」和dfa狀態數「f」將新的條目添加在eceache表中5.設置轉換(「d」,「a」)=「f」2.從dfa狀態表、上述表4中刪除dfa狀態「d」的nfa狀態數的集合,並且將狀態設置為「標記的」。ec_cache的大小根據允許的運行時間內存佔用是可配置的並且是有限的。如果運行時間內存佔用是有限的,則需要有替換策略。例如,替換策略可能保留nfa狀態集合的最近最少使用的埃普西隆終止(ec)或者完全沒有替換。在後一種情況下,ec_cache僅保持固定數目的nfa狀態集合的預定ec。後一種情況已被發現是非常有用的。上面所參考的方法的優點如下:i)如果已經計算過,則步驟1.1.3.2避免計算eclosure;ii)如果可能(先前算法、偽代碼#2中的步驟1.1.6.2),給定其eclosure,將dfa節點數目而不是eclosure集合存儲在ec高速緩存表中避免搜索dfa節點;以及iii)因為在表4中,進行處理之後刪除dfa狀態的nfa狀態集合,所以節省編譯器的大量內存佔用。如上文所述,通常使用搜索算法,諸如,確定性有限自動機(dfa)或者非確定性有限自動機(nfa)來執行內容搜索以處理正則表示式。可以實現的另一類型的串搜索算法是aho-corasik算法。aho-corasik算法可以被用於從文本串集合中創建有限狀態圖樣機,該文本串集合可以被用於處理單次通過中的輸入淨荷。例如,給定串集合,aho-corasik算法創建用於處理任何的任意文本字串的有限圖樣匹配機,該任意文本字串可以經由通信網絡中的分組接收。創建的圖樣匹配機的行為是由三個函數來控制:i)前往函數「g」,ii)故障函數「f」,以及iii)輸出函數「輸出」。圖10示出了用於使用aho-corasik算法來搜索圖樣「hers」、「his」和「she」的圖樣匹配機1000。去往函數'g'將由狀態和輸入符號組成的對映射到狀態或消息「故障」。故障函數「f」將狀態映射到狀態,並且每當前往函數「g」報告「故障」時進行查詢。輸出函數「輸出」將一組關鍵字(可能為空)與每個狀態相關聯。開始狀態是狀態0(由節點1005表示)。在任何給定的狀態下,如果前往函數「g(s,a)=t」(「s」是有限機的當前狀態,「a」是輸入值,並且「t」是轉換狀態),則圖樣匹配機1000進入狀態「t」,並且輸入嚴格的下一個符號變成當前輸入符號。例如,參考圖10,如果處於狀態0(節點1005)並且接收到's'輸入值,則圖樣匹配機1000將轉換為狀態3(節點1015)。然而,如果前往函數「g(s,a)=故障」並且故障函數「f(s)=「s」」,那麼該圖樣匹配機以「s」作為當前狀態並且以輸入字母「a」作為當前輸入符號而重複該循環。圖11a示出了對於圖樣匹配機1000的每個狀態的現有技術故障值。圖11b示出了對於狀態2、5、7和9的輸出函數值。例如,參考圖10,任意輸入串「ushers」由處理機處理如下:處理或匹配在開始狀態0(由節點1005表示)開始。對於輸入流的字符「u」,處理機保持處於狀態0(節點1005)。對於輸入流的字符「s」,處理機轉換到狀態3(節點1015),並如下繼續:對「h」={4}對「e」={5}對「r」={8}對「s」={9}在狀態4(節點1020),因為前往函數g(4,「e」)=5,並且處理機1000進入狀態5,關鍵字「she」和「he」在文本串「ushers」中位置4的末尾被匹配,並且輸出函數發出輸出(5)(如在圖11b中看到的)。在狀態5對於輸入符號「r」,該機1000進行兩次狀態轉換。因為g(5,r)=故障,機1000進入狀態2=f(5)。此外,因為g(2,r)=8,所以機1000進入狀態8並且前進到下一輸入符號。已經描述了其中可以實現本發明的示例實施例的示例安全應用和使用aho-corasik機1000的典型處理,以下馬上具體描述本發明的示例實施例。如上所述,aho-corasik機1000在任意輸入串的每個位置處檢測關鍵字或圖樣的出現。在某些情況下,給定圖樣或關鍵字僅在輸入串的特定區域或位置中被找到才是有意義的。例如,http協議請求解析器僅在關鍵字「get」在請求的開始時發生才對其感興趣,並且此後不對任何其他「get」感興趣。這樣的圖樣可以被稱作錨定圖樣。本發明的實施例使得能夠創建識別非錨定圖樣和錨定圖樣兩者的aho-corasik圖樣匹配機。如上所述,圖樣匹配機1000使用aho-corasik算法來識別未錨定的圖樣「hers」、「his」和「she」。通過修改aho-corasik算法,圖樣匹配機可以被創建為識別額外的錨定圖樣「help」和「shell」。給定圖樣集合,錨定的圖樣必須與非錨定的圖樣進行區分。錨定的圖樣可以具有附加的宏,其指定該圖樣被錨定。例如,「{@0}」可以被添加到圖樣的開始以指定圖樣是錨定圖樣。因此,給定圖樣列表「he,she,his,hers,{@0}help和{@0}shell」,編譯器能夠識別關鍵字「help」和「shell」是錨定圖樣。一旦編譯器接收到關鍵字/圖樣列表時,編譯器也能夠將非錨定圖樣從錨定圖樣中區分。然後,編譯器使用如上所述的去往函數'g',創建針對所有錨定圖樣的獨立狀態樹和針對非錨定圖樣的獨立狀態樹(圖10中所示的機1000)。圖12圖示了針對錨定圖樣「help」和「shell」的狀態樹1200。圖12a圖示了按照現有技術針對狀態樹1200的每個狀態的故障值(即,假設這些圖樣被作為非錨定圖樣編譯)。圖12b圖示了狀態樹1200的狀態14和狀態19的輸出函數值。一旦創建了針對錨定圖樣和非錨定圖樣的狀態樹,編譯器計算兩個狀態數的故障函數「f」。對於表示非錨定圖樣的狀態樹,編譯器實現如以上參考圖10和11a描述的故障函數。按照本發明的示例實施例,錨定圖樣的故障函數按照如下規則被構建:a)錨定樹的根節點的故障被設置為等於非錨定狀態樹的根節點。因此,如果沒有錨定圖樣被匹配,則跟蹤非錨定圖樣。例如,狀態10(節點1205)的故障「f」被設置為等於開始狀態0(圖10中的節點1005)。b)一旦確定了錨定樹的開始狀態的故障,錨定樹的每個狀態的故障「f」被確定,使得如圖13a所示,非錨定關鍵字與錨定關鍵字的部分匹配也被使用前往函數「g」而跟蹤。錨定圖樣的輸出函數被單獨計算,但是看起來保持與非錨定圖樣的重疊,如圖13b中所示。此後,按照本發明的示例實施例,錨定的狀態樹的根節點被設置為最終狀態樹的根節點(錨定及非錨定狀態樹的組合)。現在,錨定狀態樹和非錨定狀態樹已經有效地合併成單個狀態樹。例如,參考圖10、圖11a-b、圖12和圖13a-b,任意輸入的串「ushers」由處理機處理如下:處理或匹配在開始狀態10(由節點1205表示)開始。對於輸入流的字符「u」,該機按照圖13a中所示的故障函數轉換到狀態0(圖10中的節點1005),並且在節點0(1005)處再次處理「u」,並且機器停留在節點「0」(1005)處。對於輸入流的字符「s」,該機轉換到狀態3(節點1015),並如下繼續:對「h」={4}對「e」={5}對「r」={8}對「s」={9}在狀態4(節點1020),因為去往函數g(4,「e」)=5,而該機1000進入狀態5,關鍵字「she」和「he」在文本串「ushers」中位置4的末尾被匹配,並且輸出函數發出輸出(5)(如在圖11b中看到的)。在狀態5對於輸入符號「r」,該機1000轉換到狀態8。在狀態8對於輸入符號「s」,機1000轉換到狀態9,關鍵字「hers」被匹配並且輸出函數發出輸出(9)(如在圖11b中看到的)。在另一示例中,參考圖10、圖11a-b、圖12和圖13a-b,任意輸入串「shell」由處理機處理如下:處理或匹配在開始狀態10(由節點1205表示)開始。對輸入流的字符「s」,對狀態15(圖12)的機器轉換如下繼續:對「h」={16}對「e」={17}對「l」={18}對「l」={19}在狀態16(圖12)中,因為去往函數g(16,'e')=17,並且機1200進入狀態17,關鍵字「she」和「he」在文本串「shell」的位置三的末尾被匹配,並且輸出函數發出輸出(17)(如在圖13b中看到的)。在狀態17中對於輸入符號「l」,機1200轉換到狀態18。在狀態18對於輸入符號「l」,機1200轉換到狀態19,關鍵字「shell」被作為錨定圖樣匹配,並且輸出函數發出輸出(19)(如在圖13b中看到的)。如上所述,對dfa或nfa狀態機的輸入通常是(8位)字節的串,即,字母是單個字節(一個字符或符號)。因此,整個字母集合的大小可以是256。此外,在輸入流中的每個字節產生了從一個狀態到另一狀態的轉換。然而,沒有多少圖樣、串或正則表示式使用整個字母集合。大多數圖樣使用字母集合的小子集,其在以下可以被簡稱為「有效字符」集合。例如,可以只有可列印ascii字母(例如,包括a-z、a-z、0-9以及一些符號)被使用。本發明實施例壓縮nfa和nfa圖形以僅識別「有效字符」集合。按照本發明的一個示例實施例,偽代碼#1、#2和#3在每個偽代碼的步驟1.1期間僅處理「有效字符」集合中的字母。儘管本發明已經參考其示例實施例被具體地示出和描述,但是本領域技術人員可以理解,在不背離由所附權利要求所涵蓋的本發明的範圍和精神的情況下,可以在其中進行形式和細節上的各種改變。當前第1頁12