一種利用植物維生素C合成途徑構建生產維生素C大腸桿菌菌株的方法與流程
2024-02-28 18:13:15 3
本發明屬於微生物合成生物學領域,具體涉及一種利用植物維生素c合成途徑構建大腸桿菌菌株合成維生素c的方法。
背景技術:
維生素c(簡寫vc),又名抗壞血酸,是一種水溶性維生素。人類、猿猴、天竺鼠和一些魚類、鳥類無法自行合成維生素c,需通過食物來供應身體所需。vc是一種必需維生素,參與膠原蛋白的合成,可預防動脈硬化;vc是一種強抗氧化劑,具有保護細胞、解毒和保護肝臟作用;vc還可用於增強肌體免疫力,預防感冒等急、慢性傳染病,還可用於病後恢復期、創傷癒合期及過敏性疾病的輔助治療,vc缺乏引起壞血病,造成牙齦萎縮、出血等等病症。人類vc的主要食物來源:柑桔類水果、蔬菜等。食物中的vc能被人體小腸吸收,分布到體內所有的水溶性結構中,普通成人體內vc代謝活性池中vc量1500mg左右。
維生素c主要應用在製藥、保健品、軟飲料及飼料添加等領域,主要消費市場在歐美等發達國家。目前,全球vc市場需求量約12萬噸。我國是全球最大的c生產國和出口國,每年出口超過10億美元。但是,每當人們提到vc產業,自然就會聯想到無情的價格戰,以羅氏(roche)為主的跨國公司試圖擠垮中國的vc企業,從1996年至2001年,出現兩次降價狂潮,使vc價格從12美元/kg降到2001年的2.8美元/kg,使我國20多家企業被迫停產。在幾輪競爭中,由於中國企業首創「兩步發酵法」生產vc核心技術,在人力等成本上也有明顯競爭優勢,保住了vc產業的一席之地,使國內企業與roche(dsm)和basf形成了三足鼎立之勢。但是vc產業化技術的研發工作並沒有停息,如:eastman與genencor合作開發的生化觸媒法,即用多個酶進行多步轉化,從玉米製造維生素c。其他國際大廠也都在不斷降低製造成本,如巴斯夫除了致力於將目前的製造工藝進行優化外,也在開發或引進新的低成本製造工藝。目前,歐美廠商目前都在積極探索vc新的合成路徑。國內在「二步發酵法」生產vc研究和應用領域均處於世界領先水平,但新的途徑研究投入不足,在細菌「一步發酵法」合成vc研究領域已經處於明顯劣勢。
在二步發酵法中,依次在d-山梨醇脫氫酶(sldh)、l-山梨糖脫氫酶(sdh)及l-山梨酮脫氫酶(sndh)的作用下,可以有效地將d-山梨醇轉化為維生素c的前體物質2-klg(尹光琳等,微生物學報,1980,20(3),246-251)。細菌山梨醇「一步發酵法」研發工作走在最前列的首推dsm,取得一系列領先成果,包括葡糖桿菌gluconobacteroxydansdsm17078全部kga代謝密切相關的基因(l-山梨酮脫氫酶基因、d-山梨醇脫氫酶基因,以及l-山梨糖脫氫酶基因a、b、c、d)的分離克隆(usptopatent,20110250636),及以上基因敲除或過表達對kga生物合成的影響;糖轉運蛋白基因sts24和sts01的敲除或過表達對kga生物合成的影響(unitedstatespatent5437989);pqq生物合成基因對kga合成的影響(yuan等bmcbiotechnology,2016,16,1-14);以及其他基因(vcs01和vcs08等)對kga合成的影響(europeanpatentapplicationep1103603)。此外,還嘗試了多種技術手段對葡糖桿菌進行基因改良,取得了理想的研究效果。申報相關國際發明專利30多項,專利覆蓋了50多個細菌相關基因以及10多個細菌種類的利用,包括大腸桿菌、假單胞菌、泛菌、穀氨酸棒桿菌、普通酮古龍酸菌、氧化葡萄糖酸桿菌、醋細菌和葡糖醋桿菌等。
大部分的植物和動物都可以通過一系列的酶促反應轉化d-葡萄糖合成維生素c。在真核生物中,維生素c可以通過兩個不同的生化途徑合成。在鼠類及其它的哺乳動物中,葡萄糖通過一個複雜途徑轉化成l-古洛糖酸-1,4-內酯。這一途徑是由終端酶l-古洛糖酸-1,4-內酯氧化酶在動物界中的普遍存在推斷而來的。而在人類及其它一些動物中,編碼l-古洛糖酸-1,4-內酯氧化酶的基因發生了突變,造成其合成維生素c能力的喪失。大多數的植物細胞中都有大量維生素c的合成,它在過氧化物、臭氧及自由基的解毒方面起著至關重要的作用。另外,維生素c在通過水溶性抗氧化劑(α-生育酚)、玉米黃質和ph介導的psii活性的再生調節光合作用活性的過程中是必不可少的。植物細胞可以積累大量的維生素c,特別是在綠色組織和貯藏器官中。因為在植物細胞中存在由d-半乳糖生成維生素c的完整合成途徑,目前研究人員已經開始嘗試利用植物細胞或微藻培養物通過發酵生產維生素c。據報導,running等人分離得到的小球藻突變體產維生素c的產量從0.64mg/g幹細胞提高到45mg/g細胞(journalofappliedphycology,1994,6(2),99-104),但是這與工業上採用的經典二步發酵法的高產量尚無競爭性。進一步提高利用植物細胞或藻類一步生產維生素c的產量需要進行系統的代謝工程改造,然而植物中維生素c合成途徑的研究進展非常緩慢使得代謝工程改造很難操作。
植物中初始的維生素c合成模型是根據動物中的合成機理建立的。然而,植物細胞中是不含l-古洛糖酸-1,4-內酯氧化酶的,多年來一直未得到植物中維生素c合成途徑的直接證據,直到後來利用擬南芥中影響維生素c生物合成突變體的鑑定,提出了經過gdp-甘露糖和l-半乳糖的維生素c從頭合成途徑。在隨後的幾年間,研究者提出了植物細胞中還可能存在一些其它的維生素c合成途徑,但目前對這些新合成途徑的認識比較有限。
植物細胞中維生素c從葡萄糖開始合成途徑涉及10個酶,擬南芥中這10個酶包括:athxk1、atpgi、atdin9、atpmm、atvtc1、atgme、atvtc2、atvtc4、atgaldh和atgldh(conklin,genetics,2000,154,847-856)。葡萄糖在己糖激酶hxk催化下轉化為葡萄糖-6-磷酸,再經磷酸葡萄糖異構酶pgi轉化為果糖-6-磷酸,磷酸甘露糖異構酶(pmi或din9)將果糖-6-磷酸轉化為d-甘露糖-6-磷酸,在甘露糖變位酶(pmm)催化下轉化為d-甘露糖-1-磷酸,進一步經過gdp-甘露糖焦磷酸化酶(vtc1)催化形成gdp-d-甘露糖,再經過gdp-甘露糖-3』5』異構酶(gme)作用下合成gdp-l-半乳糖。gdp-l-半乳糖通過半乳糖途徑合成vc,其中需要gdp-l-半乳糖磷酸化酶(vtc2)將gdp-l-半乳糖轉化為l-甘露糖-1-磷酸,l-半乳糖-1-磷酸酯酶(vtc4)將l-甘露糖-1-磷酸轉化為l-半乳糖,l-半乳糖脫氫酶(galdh)將l-半乳糖轉化為l-半乳糖-1,4-內酯,最後在l-半乳糖-1,4-內酯脫氫酶(gldh)作用下合成維生素c。植物中維生素c合成途徑的發現使得實現由葡萄糖、澱粉或者纖維素直接發酵生產維生素c成為可能。
技術實現要素:
本發明的目的在於提供一種利用大腸桿菌生產維生素c的方法,該方法通過將植物維生素c合成途徑中的11個基因轉化到大腸桿菌中,使大腸桿菌能夠直接利用葡萄糖為碳源,轉化為維生素c。
為達到上述目的,本發明的技術方案是。
一種利用植物的維生素c合成途徑創製一步發酵合成維生素c大腸桿菌菌株的方法:將植物的維生素c合成的基因構建多基因單順反子組成的原核表達載體;將所述原核表達載體轉化到大腸桿菌中。
優選地,所述植物的維生素c合成的基因來源於草莓。
優選地,所述植物的維生素c合成的基因通過多基因定點突變方法消除了基因中常用的限制性內切酶位點。這些位點包括ecori、sali、bamhi、kpni,xbai、saci和hindiii。
優選地,多基因單順反子組成的原核表達載體由t7表達系統組成,11個改造的維生素c合成基因全部使用t7啟動子和終止子控制,構建基因表達元件。
所述維生素c合成的原核表達載體的構建方法為:利用改良的「重疊延伸pcr技術」構建維生素c合成所有11個基因的表達盒。在pcambia-1301載體的基礎上,通過在ecori和hindiii限制性內切酶切點間插入的多克隆位點片段,可以構成多基因表達單元,該載體的ecori和sali,sali和bamhi,bamhi和kpni,kpni和xbai,xbai和hindiii限制性內切酶切點之間均可以插入基因表達盒,從而構成多基因表達載體。
所述構建的大腸桿菌表達載體pyb2130通過電擊法導入到大腸桿菌中。
優選地,所述大腸桿菌包括bl21(de3)等所有含有t7rna聚合酶的菌株。
本發明的有益效果如下。
1,當大腸桿菌獲得植物的維生素c合成基因後能夠合成維生素c。
2,通過本發明構建的大腸桿菌菌株可以直接將葡萄糖轉化為維生素c。
3,該套體系操作簡單,避免了使用兩步發酵過程的麻煩。
附圖說明
圖1為本發明實施例中構建的維生素c原核表達載體pyb2130。
圖2為本發明實施例中大腸桿菌發酵後檢測。
具體實施方式
以下實施例中涉及的構建維生素c合成原核表達載體pyb2130,其具體的構建方法如下。
草莓果實總rna,cdna合成試劑盒為clontech公司產品;dna柱回收試劑盒購置amersham公司;試劑rna抽提試劑盒rneasyplantminikit為qiagen公司產品;各種限制性內切酶和t4dnaligase均購自上海takara公司。總rna採用qiagen公司的rneasyplantminikit提取。
取約50µl草莓草莓果實總rna進行cdna合成,cdna的合成按clontech公司smartcdnalibraryconstructionkit說明書操作進行第一鏈合成。
1、構建改造的草莓己糖磷酸激酶基因(fvhxk1)。
從草莓中克隆己糖磷酸激酶基因並利用定點突變方法將90位xhoi限制性內切酶位點;229位hindiii限制性內切酶位點;632位saci限制性內切酶位點;720位kpni限制性內切酶位點;935和1148位bgii限制性內切酶位點;1238位bamhi限制性內切酶位點;1342位ecori限制性內切酶位點消除。
以合成的cdna第一鏈為模板,擴增引物:hxk1:atggggaaggtggcggtgggt(seqidno.1所示),hxk2:ttaggagtcctcgacaccaag(seqidno.2所示)。pcr反應條件:98℃預變性3min;94℃變性30s,60℃退火30s,72℃延伸90s,30個循環;72℃保溫10min。pcr結束後,採用酚:氯仿抽提,再加入2倍體積的無水乙醇進行沉澱。沉澱用30µl水溶解,取1µl為模板。
90位xhoi限制性內切酶位突變引物:90z:gagattgaaaagcttgagga(seqidno.3所示);90f:tcctcaagcttttcaatctc(seqidno.4所示)。
229位hindiii限制性內切酶位突變引物:229z:agcaagcctaagatgctcatcag(seqidno.5所示);229f:ctgatgagcatcttaggcttgct(seqidno.6所示)。
632位saci限制性內切酶位突變引物:632z:cagagttcaccaaatcagtgga(seqidno.7所示);632f:tccactgatttggtgaactctg(seqidno.8所示)。
720位kpni限制性內切酶位突變引物:720z:aggtaacacaatccgcatgt(seqidno.9所示);720f:acatgcggattgtgttacct(seqidno.10所示)。
935位bglii限制性內切酶位突變引物:935z:agaactttgagaagattatttc(seqidno.11所示);935f:gaaataatcttctcaaagttct(seqidno.12所示)。
1148位bglii限制性內切酶位突變引物:1148z:gaaggatatcttagagacct(seqidno.13所示);1148f:aggtctctaagatatccttc(seqidno.14所示)。
1238位bamhi限制性內切酶位突變引物:1238z:ctgggattctgggagtcctta(seqidno.15所示);1238f:taaggactcccagaatcccag(seqidno.16所示)。
以引物hxk1和90f;90z和229f;229z和632f;632z和720f;720z和935f;935z和1148f;1148z和1238f;1238z和hxk2進行pcr擴增,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,1min。共25個循環,pcr結束後,dna片斷用10%丙烯醯胺膠回收,將上述8個回收片斷取10-100ng為模板混合,以hxk1和hxk2為引物將上述片斷拼接,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,2min。共25個循環。pcr結束後,dna柱回收pcr片斷。將片段進行ta克隆,獲得質粒t1,並將質粒t1高效轉化到大腸桿菌dh5α感受態細胞中。
2、構建改造的草莓己糖磷酸異構酶(pgi)基因fvpgi。
從草莓中克隆草莓己糖磷酸異構酶並利用定點突變方法將264位xbai限制性內切酶位點;293位saci限制性內切酶位點;1126位bamhi限制性內切酶位點;1294位sphi限制性內切酶位點;1504位bgii限制性內切酶位點消除。
擴增引物為:pgi1:5』-atggcatctatctctggtatctgttc-3』(seqidno.17所示)pgi2:5』-taggagtacagtgcatcgacgttg-3』(seqidno.18所示)。pcr反應條件:98℃預變性3min;94℃變性30s,60℃退火30s,72℃延伸120s,30個循環;72℃保溫10min。pcr結束後,採用酚:氯仿抽提,再加入2倍體積的無水乙醇進行沉澱。沉澱用30µl水溶解,取1µl為模板。
264位xbai和293位saci限制性內切酶位突變引物:264z:tcttgactggctgtaccagcacaaggagttcg(seqidno.19所示);264f:cgaactccttgtgctggtacagccagtcaaga(seqidno.20所示)。
1126位bamhi限制性內切酶位突變引物:1126z:ggaaccaaggatatggttgttct(seqidno.21所示);1126f:agaacaaccatatccttggttcc(seqidno.22所示)。
1294位sphi限制性內切酶位突變引物:1294z:ggagcacggatcagcttgca(seqidno.23所示);1294f:tgcaagctgatccgtgctcc(seqidno.24所示)。
1504位bglii限制性內切酶位突變引物:1504z:gaagaagtaacacctagaact(seqidno.25所示);1504f:agttctaggtgttacttcttc(seqidno.26所示)。
以引物pgi1和264f;264z和1126f;1126z和1294f;1294z和1504f;1504z和pgi2進行pcr擴增,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,1min。共25個循環,pcr結束後,dna片斷用10%丙烯醯胺膠回收,將上述8個回收片斷取10-100ng為模板混合,以pgi1和pgi2為引物將上述片斷拼接,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,2min。共25個循環。pcr結束後,dna柱回收pcr片斷。將片段進行ta克隆,獲得質粒t2,並將質粒t2高效轉化到大腸桿菌dh5α感受態細胞中。
3、構建改造的草莓磷酸甘露糖異構酶(pmi)基因fvpmi。
從草莓中克隆甘露糖異構酶基因並利用定點突變方法將817位hindiii限制性內切酶位點;1038位kpni限制性內切酶位點;1110和1221位psti限制性內切酶位點消除。
以合成的cdna第一鏈為模板,擴增引物為:pmi1:5』-atggagaagtccatgatcgagaagtc-3』(seqidno.27所示)pmi2:5』-ttatggcagctggaagaacatggagt-3』(seqidno.28所示)。pcr反應條件:98℃預變性3min;94℃變性30s,60℃退火30s,72℃延伸90s,30個循環;72℃保溫10min。pcr結束後,採用酚:氯仿抽提,再加入2倍體積的無水乙醇進行沉澱。沉澱用30µl水溶解,取1µl為模板。
817位hindiii限制性內切酶位突變引物:817z:ctcaactatgtcaaggtt(seqidno.29所示);817f:aaccttgacatagttgag(seqidno.30所示)。
1038位kpni和1110位psti限制性內切酶位突變引物:1038z:ggttcctcccaccttttgacgagtttgaggtcgatcggtgccatcttccccagggagaatcagtggaatttcctgaag(seqidno.31所示);1038f:cttcaggaaattccactgattctccctggggaagatggcaccgatcgacctcaaactcgtcaaaaggtgggaggaacc(seqidno.32所示)。
1221位psti限制性內切酶位突變引物:1221z:cttttcgtgcctgaaggt(seqidno.33所示);1221f:accttcaggcacgaaaag(seqidno.34所示)。
以引物pmi1和817f;817z和1038f;1038z和1221f;1221z和720f;720z和935f;935z和1148f;1148z和1238f;1238z和pmi2進行pcr擴增,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,1min。共25個循環,pcr結束後,dna片斷用10%丙烯醯胺膠回收,將上述8個回收片斷取10-100ng為模板混合,以pmi1和pmi2為引物將上述片斷拼接,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,2min。共25個循環。pcr結束後,dna柱回收pcr片斷。將片段進行ta克隆,獲得質粒t3,並將質粒t3高效轉化到大腸桿菌dh5α感受態細胞中。
4、構建改造的草莓磷酸甘露糖變位酶(pmm)基因fvpmm。
從草莓中克隆磷酸甘露糖變位酶基因並利用定點突變方法將139位bamhi限制性內切酶位點;537位hindiii限制性內切酶位點消除。
以合成的cdna第一鏈為模板,擴增引物為:pmm1:5』-atggctgtcatgaagcctggtgtc-3』(seqidno.35所示)pmm2:5』-ttaggaagagaagaacagagccttaac-3』(seqidno.36所示)。pcr反應條件:98℃預變性3min;94℃變性30s,60℃退火30s,72℃延伸60s,30個循環;72℃保溫10min。pcr結束後,採用酚:氯仿抽提,再加入2倍體積的無水乙醇進行沉澱。沉澱用30µl水溶解,取1µl為模板。
139位bamhi限制性內切酶位突變引物:139z:cagtgggcattgttggaggaacc(seqidno.37所示);139f:ggttcctccaacaatgcccactg(seqidno.38所示)。
537位hindiii限制性內切酶位突變引物:537z:gatatgctttgatgtttttcctc(seqidno.39所示);537f:gaggaaaaacatcaaagcatatc(seqidno.40所示)。
以引物pmm1和139f;139z和537f;537z和pmm2進行pcr擴增,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,1min。共25個循環,pcr結束後,dna片斷用10%丙烯醯胺膠回收,將上述8個回收片斷取10-100ng為模板混合,以pmm1和pmm2為引物將上述片斷拼接,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,2min。共25個循環。pcr結束後,dna柱回收pcr片斷。將片段進行ta克隆,獲得質粒t4,並將質粒t4高效轉化到大腸桿菌dh5α感受態細胞中。
5、構建改造的草莓gdp-d-甘露糖焦磷酸化酶(gmpase,vtc1)基因fvvtc。
從草莓中克隆gdp-d-甘露糖焦磷酸化酶基因並利用定點突變方法將367位ecori限制性內切酶位點;904位sphi限制性內切酶位點消除。
以合成的cdna第一鏈為模板,擴增引物為:vtc1z:5』-atgaaggcactgattctggtcggt-3』(seqidno.41所示)vtc1f:5』-ttacatgacgatctcaggcttc-3』(seqidno.42所示)。pcr反應條件:98℃預變性3min;94℃變性30s,60℃退火30s,72℃延伸60s,30個循環;72℃保溫10min。pcr結束後,採用酚:氯仿抽提,再加入2倍體積的無水乙醇進行沉澱。沉澱用30µl水溶解,取1µl為模板。
367位ecori限制性內切酶位突變引物:367z:tggattccataaatcccatg(seqidno.43所示);367f:catgggatttatggaatcca(seqidno.44所示)。
904位sphi限制性內切酶位突變引物:904z:tcggatcaagaagcttgcttg(seqidno.45所示);904f:caagcaagcttcttgatccga(seqidno.46所示)。
以引物vtc1z和367f;367z和904f;904z和vtc1f進行pcr擴增,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,1min。共25個循環,pcr結束後,dna片斷用10%丙烯醯胺膠回收,將上述8個回收片斷取10-100ng為模板混合,以vtc1z和vtc1f為引物將上述片斷拼接,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,2min。共25個循環。pcr結束後,dna柱回收pcr片斷。將片段進行ta克隆,獲得質粒t5,並將質粒t5高效轉化到大腸桿菌dh5α感受態細胞中。
6、構建改造的草莓gdp-d-甘露糖-3,5-表異構酶(gme)fvgme。
從草莓中克隆gdp-d-甘露糖-3,5-表異構酶基因並利用定點突變方法將217位ecori限制性內切酶位點;667位psti限制性內切酶位點消除。
以合成的cdna第一鏈為模板,擴增引物為:gme1:5』-atgggttctgctggtgagtctg-3』(seqidno.47所示)gme2:5』-ttactccttaccatcagcagcac-3』(seqidno.48所示)。pcr反應條件:98℃預變性3min;94℃變性30s,60℃退火30s,72℃延伸60s,30個循環;72℃保溫10min。pcr結束後,採用酚:氯仿抽提,再加入2倍體積的無水乙醇進行沉澱。沉澱用30µl水溶解,取1µl為模板。
217位ecori限制性內切酶位突變引物:217z:gagttccatcttgtggatctcag(seqidno.49所示);217f:ctgagatccacaagatggaactc(seqidno.50所示)。
667位psti限制性內切酶位突變引物:667z:ctgaagaaaggctctcacatccac(seqidno.51所示);667f:gtggatgtgagagcctttcttcag(seqidno.52所示)。
以引物gme1和217f;217z和667f;667z和gme2進行pcr擴增,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,1min。共25個循環,pcr結束後,dna片斷用10%丙烯醯胺膠回收,將上述8個回收片斷取10-100ng為模板混合,以gme1和gme2為引物將上述片斷拼接,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,2min。共25個循環。pcr結束後,dna柱回收pcr片斷。將片段進行ta克隆,獲得質粒t6,並將質粒t6高效轉化到大腸桿菌dh5α感受態細胞中。
7、構建改造的草莓gdp-l-半乳糖磷酸化酶(ggp,vtc2)基因fvvtc2。
從草莓中克隆gdp-l-半乳糖磷酸化酶基因並利用定點突變方法將258位sphi限制性內切酶位點;624位hindiii限制性內切酶位點;1070位ndei限制性內切酶位點;1236位bamhi限制性內切酶位點;1337位psti限制性內切酶位點消除。
以合成的cdna第一鏈為模板,擴增引物為:vtc2z:5』-atgatgctgaagatcaagcgtg-3』(seqidno.53所示);vtc2f:5』-ttactggagaaccagacactcct-3』(seqidno.54所示)。pcr反應條件:98℃預變性3min;94℃變性30s,60℃退火30s,72℃延伸90s,30個循環;72℃保溫10min。pcr結束後,採用酚:氯仿抽提,再加入2倍體積的無水乙醇進行沉澱。沉澱用30µl水溶解,取1µl為模板。
258位sphi限制性內切酶位突變引物:258z:gcttgcagaaagggctatttc(seqidno.55所示);258f:gaaatagccctttctgcaagc(seqidno.56所示)。
624位hindiii限制性內切酶位突變引物:624z:gaaaccttcttgcttgcacttc(seqidno.57所示);624f:gaagtgcaagcaagaaggtttc(seqidno.58所示)。
1070位ndei限制性內切酶位突變引物:1070z:caccacatgtccactaatttc(seqidno.59所示);1070f:gaaattagtggacatgtggtg(seqidno.60所示)。
1236位kpni限制性內切酶位突變引物:1236z:gaggaaccagatgtcaatcctc(seqidno.61所示);1236f:gaggattgacatctggttcctc(seqidno.62所示)。
以引物vtc2z和258f;258z和624f;624z和1070f;1070z和1236f;1236z和vtc2f進行pcr擴增,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,1min。共25個循環,pcr結束後,dna片斷用10%丙烯醯胺膠回收,將上述8個回收片斷取10-100ng為模板混合,以vtc2z和vtc2f為引物將上述片斷拼接,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,2min。共25個循環。pcr結束後,dna柱回收pcr片斷。將片段進行ta克隆,獲得質粒t7,並將質粒t7高效轉化到大腸桿菌dh5α感受態細胞中。
8、構建改造的草莓l-半乳糖-1-磷酸酶(gpp,vtc4)基因fvvtc4。
從草莓中克隆l-半乳糖-1-磷酸酶基因並利用定點突變方法將42位psti限制性內切酶位點;161位saci限制性內切酶位點;270位bamhi限制性內切酶位點消除。
以合成的cdna第一鏈為模板,擴增引物:vtc4z:atggctgaaaatgattcgcttgctctgttcttggcctctgcagt(seqidno.63所示),vtc4f:ttaggagtcctcgacaccaag(seqidno.64所示)。pcr反應條件:98℃預變性3min;94℃變性30s,60℃退火30s,72℃延伸90s,30個循環;72℃保溫10min。pcr結束後,採用酚:氯仿抽提,再加入2倍體積的無水乙醇進行沉澱。沉澱用30µl水溶解,取1µl為模板。
161位saci限制性內切酶位突變引物:161z:gagttcatatttaatcatctca(seqidno.65所示);161f:tgagatgattaaatatgaactc(seqidno.66所示)。
270位bamhi限制性內切酶位突變引物:270z:gtggaacccctggatggcac(seqidno.67所示);270f:gtgccatccaggggttccac(seqidno.68所示)。
以引物vtc4z和161f;161z和270f;270z和vtc4f進行pcr擴增,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,1min。共25個循環,pcr結束後,dna片斷用10%丙烯醯胺膠回收,將上述8個回收片斷取10-100ng為模板混合,以vtc4z和vtc4f為引物將上述片斷拼接,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,2min。共25個循環。
pcr結束後,dna柱回收pcr片斷。將片段進行ta克隆,獲得質粒t8,並將質粒t8高效轉化到大腸桿菌dh5α感受態細胞中。
9、構建改造的草莓l-半乳糖醛酸內酯脫氫酶(galdh)基因fvgaldh。
從草莓中克隆l-半乳糖醛酸內酯脫氫酶基因並利用定點突變方法將678位ndei限制性內切酶位點消除。
以合成的cdna第一鏈為模板,擴增引物為:galdh1:5』-atgactatccactactctgtcg-3』(seqidno.69所示)galdh2:5』-ttaggactgctggataccagaag-3』(seqidno.70所示)。pcr反應條件:98℃預變性3min;94℃變性30s,60℃退火30s,72℃延伸60s,30個循環;72℃保溫10min。pcr結束後,採用酚:氯仿抽提,再加入2倍體積的無水乙醇進行沉澱。沉澱用30µl水溶解,取1µl為模板。
678位xhoi限制性內切酶位突變引物:678z:ctttaggaattttcacatatgt(seqidno.71所示);678f:acatatgtgaaaattcctaaag(seqidno.72所示)。
以引物galdh1和678f;678z和galdh2進行pcr擴增,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,1min。共25個循環,pcr結束後,dna片斷用10%丙烯醯胺膠回收,將上述8個回收片斷取10-100ng為模板混合,以galdh1和galdh2為引物將上述片斷拼接,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,2min。共25個循環。pcr結束後,dna柱回收pcr片斷。將片段進行ta克隆,獲得質粒t9,並將質粒t9高效轉化到大腸桿菌dh5α感受態細胞中。
10、構建改造的草莓l-半乳糖脫氫酶(gldh)基因fvgldh。
從草莓克隆l-半乳糖脫氫酶基因並利用定點突變方法將12和263位saci限制性內切酶位點;340位xhoi限制性內切酶位點;602位ecori限制性內切酶位點;611和1625位psti限制性內切酶位點;1320位bgii限制性內切酶位點;1419位hindiii限制性內切酶位點消除。
以合成的cdna第一鏈為模板,擴增引物為:gldhz:5』-atgcaacgagcactgactctgaag-3』(seqidno.73所示)gldhf:5』-ttagatggtgtcagaggatggga-3』(seqidno.74所示)。pcr反應條件:98℃預變性3min;94℃變性30s,60℃退火30s,72℃延伸120s,30個循環;72℃保溫10min。pcr結束後,採用酚:氯仿抽提,再加入2倍體積的無水乙醇進行沉澱。沉澱用30µl水溶解,取1µl為模板。
263位saci限制性內切酶位突變引物:263z:gagttccacaccgtctctaac(seqidno.75所示);263f:gttagagacggtgtggaactc(seqidno.76所示)。
340位xhoi限制性內切酶位突變引物:340z:gagctggagaaagtggtcaag(seqidno.77所示);340f:cttgaccactttctccagctc(seqidno.78所示)。
602位ecori限制性內切酶位突變引物:602z:gaactctgcaggttggtgcacatggtac(seqidno.79所示);602f:gtaccatgtgcaccaacctgcagagttc(seqidno.80所示)。
1320位bglii限制性內切酶位突變引物:1320z:agttctaaaacagctaatag(seqidno.81所示);1320f:ctattagctgttttagaact(seqidno.82所示)。
1419位bglii限制性內切酶位突變引物:1419z:aaggttaaaggaggatgatata(seqidno.83所示);1419f:tatatcatcctcctttaacctt(seqidno.84所示)。
1625位psti限制性內切酶位突變引物:1625z:caaagaacagcttaccactctgaag(seqidno.85所示);1625f:cttcagagtggtaagctgttctttg(seqidno.86所示)。
以引物gldhz和263f;263z和340f;340z和602f;602z和1320f;1320z和1419f;1419z和1625f;1625z和gldhf進行pcr擴增,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,1min。共25個循環,pcr結束後,dna片斷用10%丙烯醯胺膠回收,將上述8個回收片斷取10-100ng為模板混合,以gldhz和gldhf為引物將上述片斷拼接,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,2min。共25個循環。pcr結束後,dna柱回收pcr片斷。將片段進行ta克隆,獲得質粒t10,並將質粒t10高效轉化到大腸桿菌dh5α感受態細胞中。
11、構建改造的草莓脫氫抗壞血酸還原酶(dhar)基因fvdhar。
從草莓中克隆脫氫抗壞血酸還原酶基因並利用定點突變方法將33位psti限制性內切酶位點;339位bamhi限制性內切酶位點;453和521位hindiii限制性內切酶位點消除。
以合成的cdna第一鏈為模板,擴增引物為:dharz:5』-atggctcttgaggttgctgccaaggctgctggag-3』(seqidno.87所示)dharf:5』-ttacttaggattgaccttaggttc-3』(seqidno.88所示)。pcr反應條件:98℃預變性3min;94℃變性30s,60℃退火30s,72℃延伸60s,30個循環;72℃保溫10min。pcr結束後,採用酚:氯仿抽提,再加入2倍體積的無水乙醇進行沉澱。沉澱用30µl水溶解,取1µl為模板。
339位bamhi限制性內切酶位突變引物:339z:gacattcctcaagagcaaggaacc(seqidno.89所示);339f:ggttccttgctcttgaggaatgtc(seqidno.90所示)。
453位hindiii限制性內切酶位突變引物:453z:gtcactgctgctgatctaaccttg(seqidno.91所示);453f:caaggttagatcagcagcagtgac(seqidno.92所示)。
521位hindiii限制性內切酶位突變引物:521z:ctaaaggtttgacccattaccat(seqidno.93所示);521f:atggtaatgggtcaaacctttag(seqidno.94所示)。
以引物dharz和339f;339z和453f;453z和521f;521z和dharf進行pcr擴增,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,1min。共25個循環,pcr結束後,dna片斷用10%丙烯醯胺膠回收,將上述8個回收片斷取10-100ng為模板混合,以dharz和dharf為引物將上述片斷拼接,擴增條件為:94℃預熱1min;94℃,30s,60℃,30s,72℃,2min。共25個循環。pcr結束後,dna柱回收pcr片斷。將片段進行ta克隆,獲得質粒t11,並將質粒t11高效轉化到大腸桿菌dh5α感受態細胞中。
實施例1,構建葡萄糖合成維生素c原核表達載體。
將上述11個改造的維生素c合成基因全部使用t7啟動子和終止子控制,構建基因表達元件。首先,我們利用「重疊延伸pcr技術」構建維生素c合成所有11個基因的表達盒。啟動子、基因和終止子之間不含限制性內切酶位點。構建的大腸桿菌表達單元為:t7fvhxk1s、t7fvpgis、t7fvpmis、t7fvpmms、t7fvvtc1s、t7fvgmes、t7fvvtc2s、t7fvvtc4s、t7fvgaldhs、t7fvgldhs、t7fvdhars。
t7啟動子序列為:gaattcctcgagcgatcccgcgaaattaatacgactcactataggggaattgtgagcggataacaattcccctctagaaataattttgtttaactttaagaaggagatatacc(seqidno.95所示)。
t7終止子序列為:ctagcataaccccttggggcctctaaacgggtcttgaggggttttttggtcgacggtgacgttgagcatggtaagctt(seqidno.96所示)。
構建的表達單元在puc18載體上兩兩拼接,完成後消除內在的酶切位點,然後依次插入載體pcambia-1301,最終構建成大腸桿菌維生素c合成載體pyb2130。
實施例2,葡萄糖合成維生素c原核表達載體pyb2130大腸桿菌轉化
1)大腸桿菌感受態細胞製備。
大腸桿菌菌株為bl21(de3),或bl21-ai等含有t7rna聚合酶的菌株。挑取單菌在25mllb培養基37℃培養過夜,取5ml菌液轉接到100mllb培養基,培養至od600=0.7-0.8,菌液冰上放置10分鐘,5000rpm離心10min,4℃,收集菌體,加入100ml無菌雙蒸水清洗兩次。加入4ml10%甘油懸浮菌體,轉到50ml離心管。5500rpm離心10min,4℃。收集菌體,加入500µl10%甘油懸浮菌體,轉到1.5ml離心管。
2)維生素c原核表達載體yb2130經電擊法導人大腸桿菌中。
取70µl農桿菌感受態細胞,加入1µl表達載體pyb2130。混勻,轉到0.1cm電擊杯中。電擊參數:200ω,1.7kv,2.5f,電擊後立即加入800µlsoc培養液。培養1小時後,取100µl塗50µg/l卡那黴素抗性板篩選轉化子,37℃培養。篩選生長良好的菌落培養後-70℃甘油管凍存。
3)驗證大腸桿菌利用葡萄糖合成維生素c。
將在-70℃甘油管凍存的工程菌接種於裝有所需培養基的小試管中,接種含卡那黴素(kmp,30mg/l)的3mllb試管,在30℃培養過夜,過夜菌再以2%接種50ml含抗生素的lb搖瓶,在30℃培養2-6h後,加入iptg或iptg+0.2%阿拉伯糖誘導培養24-72小時,轉速均為200r/min。加入葡萄糖終濃度10mg/ml。測定發酵終止液的菌體光密度值和維生素c的含量。
4)維生素c含量hplc檢測。
取10ml發酵菌液,離心收集菌體,液氮研磨,加0.1%草酸1ml,冰浴1小時,超聲處理5min。10000rpm離心10min,取上清,過0.45μm濾膜。發酵上清樣品用等體積0.2%草酸稀釋,過0.45μm濾膜。
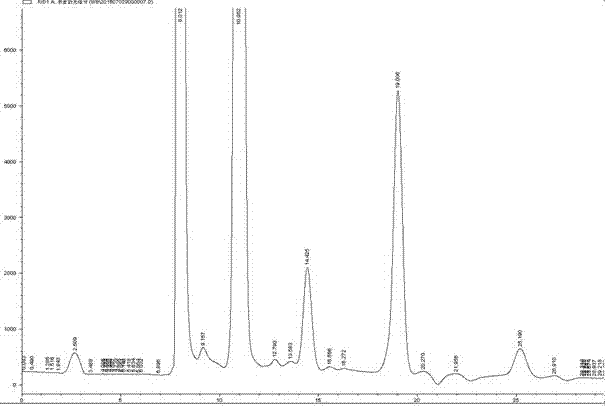
高效液相(hplc)條件:色譜柱:symmetryshieldrp18柱(5μm,150x4.6mm)。流動相為甲醇:0.1%草酸=5:95,檢測波長245nm,柱溫為30℃,流速1.0ml/min,外標法定量。樣品每次進樣10μl,將與標品相同保留時間處的峰的峰面積代入標準曲線方程,計算樣品中維生素c的含量。
色譜圖結果表明:大腸桿菌誘導培養3天後,可以檢測到維生素c,維生素c的含量為0.5-1μg/ml。
序列表
上海市農業科學院
一種利用植物維生素c合成途徑構建生產維生素c大腸桿菌菌株的方法
2017
96
patentinversion3.3
1
21
dna
人工序列
1
atggggaaggtggcggtgggt21
2
21
dna
人工序列
2
ttaggagtcctcgacaccaag21
3
20
dna
人工序列
3
gagattgaaaagcttgagga20
4
20
dna
人工序列
4
tcctcaagcttttcaatctc20
5
23
dna
人工序列
5
agcaagcctaagatgctcatcag23
6
23
dna
人工序列
6
ctgatgagcatcttaggcttgct23
7
22
dna
人工序列
7
cagagttcaccaaatcagtgga22
8
22
dna
人工序列
8
tccactgatttggtgaactctg22
9
60
dna
人工序列
9
aggtaacacaatccgcatgt20
10
20
dna
人工序列
10
acatgcggattgtgttacct20
11
22
dna
人工序列
11
agaactttgagaagattatttc22
12
22
dna
人工序列
12
gaaataatcttctcaaagttct22
13
20
dna
人工序列
13
gaaggatatcttagagacct20
14
20
dna
人工序列
14
aggtctctaagatatccttc20
15
21
dna
人工序列
15
ctgggattctgggagtcctta21
16
21
dna
人工序列
16
taaggactcccagaatcccag21
17
26
dna
人工序列
17
atggcatctatctctggtatctgttc26
18
25
dna
人工序列
18
taggagtacagtgcatcgacgttgc25
19
32
dna
人工序列
19
tcttgactggctgtaccagcacaaggagttcg32
20
32
dna
人工序列
20
cgaactccttgtgctggtacagccagtcaaga32
21
23
dna
人工序列
21
ggaaccaaggatatggttgttct23
22
23
dna
人工序列
22
agaacaaccatatccttggttcc23
23
20
dna
人工序列
23
ggagcacggatcagcttgca20
24
20
dna
人工序列
24
tgcaagctgatccgtgctcc20
25
21
dna
人工序列
25
gaagaagtaacacctagaact21
26
21
dna
人工序列
26
agttctaggtgttacttcttc21
27
26
dna
人工序列
27
atggagaagtccatgatcgagaagtc26
28
26
dna
人工序列
28
ttatggcagctggaagaacatggagt26
29
18
dna
人工序列
29
ctcaactatgtcaaggtt18
30
18
dna
人工序列
30
aaccttgacatagttgag18
31
76
dna
人工序列
31
ggttcctcccaccttttgacgagtttgaggtcgatcggtgccatcttccccagggagaat60
cagtggaatttcctgaag78
32
78
dna
人工序列
32
cttcaggaaattccactgattctccctggggaagatggcaccgatcgacctcaaactcgt60
caaaaggtgggaggaacc78
33
18
dna
人工序列
33
cttttcgtgcctgaaggt18
34
18
dna
人工序列
34
accttcaggcacgaaaag18
35
25
dna
人工序列
35
atggctgtcatgaagcctggtgtc25
36
27
dna
人工序列
36
ttaggaagagaagaacagagccttaac27
37
22
dna
人工序列
37
cagtgggcattgttggaggaac22
38
22
dna
人工序列
38
ggttcctccaacaatgcccactg22
39
23
dna
人工序列
39
gatatgctttgatgtttttcctc23
40
37
dna
人工序列
40
gaggaaaaacatcaaagcatatc23
41
23
dna
人工序列
41
atgaaggcactgattctggtcgg23
42
23
dna
人工序列
42
ttacatgacgatctcaggcttct23
43
20
dna
人工序列
43
tggattccataaatcccatg20
44
20
dna
人工序列
44
catgggatttatggaatcca20
45
21
dna
人工序列
45
tcggatcaagaagcttgcttg21
46
21
dna
人工序列
46
caagcaagcttcttgatccga21
47
22
dna
人工序列
47
atgggttctgctggtgagtctg22
48
23
dna
人工序列
48
ttactccttaccatcagcagcac23
49
23
dna
人工序列
49
gagttccatcttgtggatctcag23
50
23
dna
人工序列
50
ctgagatccacaagatggaactc23
51
24
dna
人工序列
51
ctgaagaaaggctctcacatccac24
52
24
dna
人工序列
52
gtggatgtgagagcctttcttcag24
53
22
dna
人工序列
53
atgatgctgaagatcaagcgtg22
54
23
dna
人工序列
54
ttactggagaaccagacactcct23
55
21
dna
人工序列
55
gcttgcagaaagggctatttc21
56
21
dna
人工序列
56
gaaatagccctttctgcaagc21
57
22
dna
人工序列
57
gaaaccttcttgcttgcacttc22
58
22
dna
人工序列
58
gaagtgcaagcaagaaggtttc22
59
21
dna
人工序列
59
caccacatgtccactaatttc21
60
21
dna
人工序列
60
gaaattagtggacatgtggtg21
61
22
dna
人工序列
61
gaggaaccagatgtcaatcctc22
62
22
dna
人工序列
62
gaggattgacatctggttcctc22
63
44
dna
人工序列
63
atggctgaaaatgattcgcttgctctgttcttggcctctgcagt44
64
21
dna
人工序列
64
ttaggagtcctcgacaccaag21
65
22
dna
人工序列
65
gagttcatatttaatcatctca22
66
22
dna
人工序列
66
tgagatgattaaatatgaactc22
67
20
dna
人工序列
67
gtggaacccctggatggcac20
68
20
dna
人工序列
68
gtgccatccaggggttccac20
69
22
dna
人工序列
69
atgactatccactactctgtcg22
70
23
dna
人工序列
70
ttaggactgctggataccagaag23
71
22
dna
人工序列
71
ctttaggaattttcacatatgt22
72
22
dna
人工序列
72
acatatgtgaaaattcctaaag22
73
24
dna
人工序列
73
atgcaacgagcactgactctgaag24
74
23
dna
人工序列
74
ttagatggtgtcagaggatggga23
75
21
dna
人工序列
75
gagttccacaccgtctctaac21
76
21
dna
人工序列
76
gttagagacggtgtggaactc21
77
21
dna
人工序列
77
gagctggagaaagtggtcaag21
78
21
dna
人工序列
78
cttgaccactttctccagctc21
79
28
dna
人工序列
79
gaactctgcaggttggtgcacatggtac28
80
28
dna
人工序列
80
gtaccatgtgcaccaacctgcagagttc28
81
20
dna
人工序列
81
agttctaaaacagctaatag20
82
20
dna
人工序列
82
ctattagctgttttagaact20
83
22
dna
人工序列
83
aaggttaaaggaggatgatata22
84
22
dna
人工序列
84
tatatcatcctcctttaacctt22
85
25
dna
人工序列
85
caaagaacagcttaccactctgaag25
86
25
dna
人工序列
86
cttcagagtggtaagctgttctttg25
87
34
dna
人工序列
87
atggctcttgaggttgctgccaaggctgctggag34
88
24
dna
人工序列
88
ttacttaggattgaccttaggttc24
89
24
dna
人工序列
89
gacattcctcaagagcaaggaacc24
90
24
dna
人工序列
90
ggttccttgctcttgaggaatgtc24
91
24
dna
人工序列
91
gtcactgctgctgatctaaccttg24
92
24
dna
人工序列
92
caaggttagatcagcagcagtgac24
93
23
dna
人工序列
93
ctaaaggtttgacccattaccat23
94
23
dna
人工序列
94
atggtaatgggtcaaacctttag23
95
113
dna
人工序列
95
gaattcctcgagcgatcccgcgaaattaatacgactcactataggggaattgtgagcgga60
taacaattcccctctagaaataattttgtttaactttaagaaggagatatacc113
24
78
dna
人工序列
96
ctagcataaccccttggggcctctaaacgggtcttgaggggttttttggtcgacggtgac60
gttgagcatggtaagctt78