基於協同過濾的內容推薦系統與方法與流程
2023-06-09 12:56:47 4
本發明涉及推薦算法及其系統,更具體地說,涉及一種基於協同過濾的內容推薦系統與方法。
背景技術:
隨著網際網路技術的流行,人們的生活越來越離不開網絡,越來越多的人選擇在網絡上進行娛樂或購物。面對日益擴大的用戶需求,以及越來越豐富的資源,如何能夠充分理解用戶的需求,快捷地為用戶找到自己需要的資源,成為吸引用戶的一個有力手段。基於此需求,個性化推薦技術漸漸受到重視,如今已經進入一個成熟發展的階段。
個性化推薦技術,是用戶行為分析技術的一個重要方面,簡單的說,它就是一個為用戶找到他可能感興趣的資源的過程。為了實現個性化的資源推薦,必須「懂」用戶、「懂」資源。通過對用戶資料及大量歷史行為的分析,從中得出用戶的興趣知識,然後以一種合理的方式來表示用戶興趣。同時對資源進行組織,選取合理表達方式來表達資源特徵。然後採用恰當的推薦算法,匹配用戶興趣與資源特徵,完成推薦。
基於內容的信息推薦方法的理論依據主要來自於信息檢索和信息過濾,所謂的基於內容的推薦方法就是根據用戶過去的瀏覽記錄來向用戶推薦用戶沒有接觸過的推薦項。主要是從兩個方法來描述基於內容的推薦方法:啟發式的方法和基於模型的方法。啟發式的方法就是用戶憑藉經驗來定義相關的計算公式,然後再根據公式的計算結果和實際的結果進行驗證,然後再不斷修改公式以達到最終目的。而對於模型的方法就是根據以往的數據作為數據集,然後根據這個數據集來學習出一個模型。
一般的推薦系統中運用到的啟發式的方法就是使用tf-idf的方法來計 算,跟還有tf-idf的方法計算出這個文檔中出現權重比較高的關鍵字作為描述用戶特徵,並使用這些關鍵字作為描述用戶特徵的向量;然後再根據被推薦項中的權重高的關鍵字來作為推薦項的屬性特徵,然後再將這個兩個向量最相近的(與用戶特徵的向量計算得分最高)的項推薦給用戶。在計算用戶特徵向量和被推薦項的特徵向量的相似性時,一般使用的是cosine方法,計算兩個向量之間夾角的cosine值。
然而,推薦系統在發展和應用的過程中,受到了各種問題不同程度的影響,特別是稀疏性問題和概念漂移問題已成為影響推薦質量的最主要問題。
技術實現要素:
針對現有技術中存在的稀疏性問題和概念漂移問題,本發明的目的是提供一種基於協同過濾的內容推薦系統與方法。
為實現上述目的,本發明採用如下技術方案:
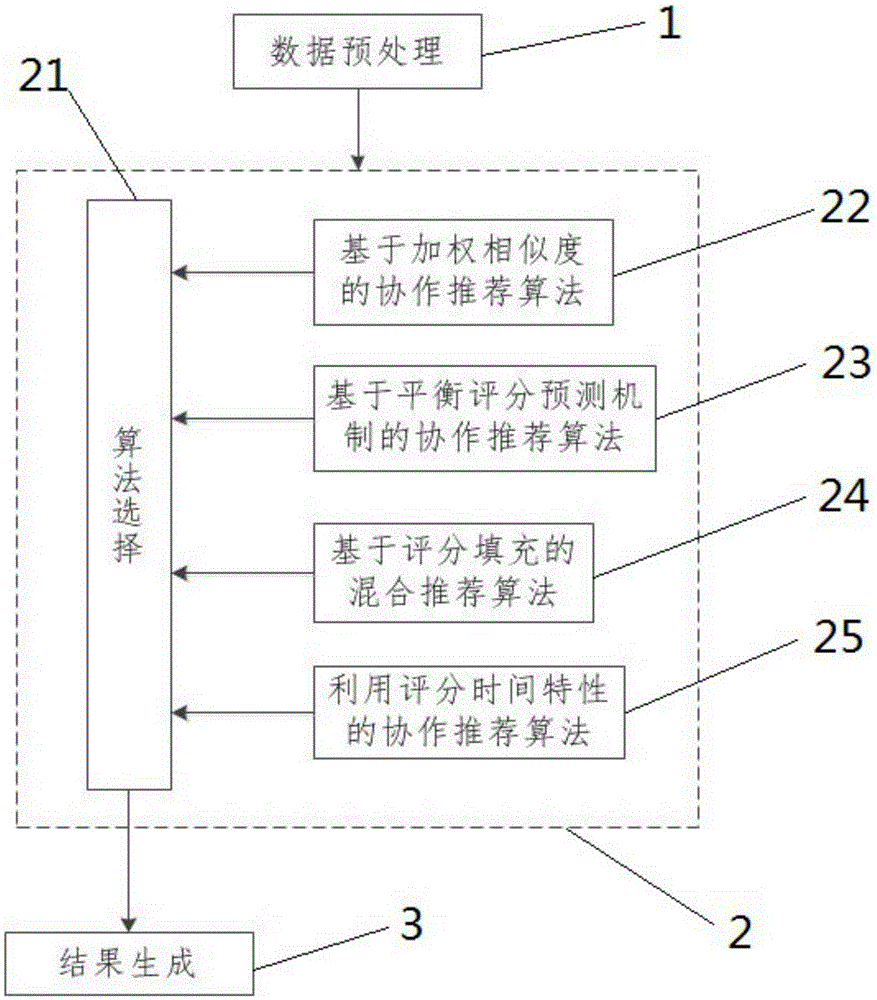
一種基於協同過濾的內容推薦系統,包括依次連接的數據預處理模塊、算法混合模塊、結果生成模塊。其中,算法混合模塊進一步包括算法選擇單元、基於加權相似度的協作推薦算法單元、基於平衡評分預測機制的協作推薦算法單元、基於評分填充的混合推薦算法單元、利用評分時間特性的協作推薦算法單元。算法混合模塊將預處理的數據分別輸入基於加權相似度的協作推薦算法單元、基於平衡評分預測機制的協作推薦算法單元、基於評分填充的混合推薦算法單元、利用評分時間特性的協作推薦算法單元,算法選擇單元選擇最匹配的算法結果,並將算法結果輸出至結果生成模塊。
根據本發明的一實施例,基於加權相似度的協作推薦算法單元執行以下操作:計算項目評分重合因子和基於項目的加權相似度;選擇鄰居項目;基於項目評分進行推薦預測。
根據本發明的一實施例,基於平衡評分預測機制的協作推薦算法單元 執行以下操作:計算基於項目的相似度;統計項目評分的中位數和權重平衡參數;選擇鄰居項目;基於項目評分進行推薦預測。
根據本發明的一實施例,基於評分填充的混合推薦算法單元執行以下操作:表示推薦項目內容;基於內容用戶模型進行學習;計算基於內容的相似度;基於CBF的評分預測與填充;計算基於評分的相似度;選擇鄰居項目;基於項目評分進行推薦預測。
根據本發明的一實施例,利用評分時間特性的協作推薦算法單元執行以下操作:計算項目評分排序和時間權重;計算項目間基於時間的加權相似度;選擇鄰居項目;基於項目的加權評分進行推薦預測。
為實現上述目的,本發明採用如下技術方案:
一種基於協同過濾的內容推薦方法,包括以下步驟:數據預處理;將預處理的數據分別進行基於加權相似度的協作推薦算法、基於平衡評分預測機制的協作推薦算法、基於評分填充的混合推薦算法、利用評分時間特性的協作推薦算法;選擇最匹配的算法結果,並將算法結果作為推薦內容。
根據本發明的一實施例,基於加權相似度的協作推薦算法包括以下步驟:計算項目評分重合因子和基於項目的加權相似度;選擇鄰居項目;基於項目評分進行推薦預測。
根據本發明的一實施例,基於平衡評分預測機制的協作推薦算法包括以下步驟:計算基於項目的相似度;統計項目評分的中位數和權重平衡參數;選擇鄰居項目;基於項目評分進行推薦預測。
根據本發明的一實施例,基於評分填充的混合推薦算法包括以下步驟:表示推薦項目內容;基於內容用戶模型進行學習;計算基於內容的相似度;基於CBF的評分預測與填充;計算基於評分的相似度;選擇鄰居項目;基於項目評分進行推薦預測。
根據本發明的一實施例,利用評分時間特性的協作推薦算法包括以下步驟:計算項目評分排序和時間權重;計算項目間基於時間的加權相似度;選擇鄰居項目;基於項目的加權評分進行推薦預測。
在上述技術方案中,本發明的基於協同過濾的內容推薦系統與方法較好地解決了推薦系統中的稀疏性問題和概念漂移問題,使得結果與實際情況的匹配度更高。
附圖說明
圖1是本發明基於協同過濾的內容推薦系統的結構示意圖;
圖2是評分時間權重衰減曲線示意圖。
具體實施方式
下面結合附圖和實施例進一步說明本發明的技術方案。
參照圖1,本發明公開一種基於協同過濾的內容推薦系統及其對應的方法。如圖1所示,本發明的系統包括依次連接的數據預處理模塊1、算法混合模塊2、結果生成模塊3,並且算法混合模塊2進一步包括算法選擇單元21、基於加權相似度的協作推薦算法單元22、基於平衡評分預測機制的協作推薦算法單元23、基於評分填充的混合推薦算法單元24、利用評分時間特性的協作推薦算法單元25。
根據圖1所示的結構,算法混合模塊2將預處理的數據分別輸入基於加權相似度的協作推薦算法單元22、基於平衡評分預測機制的協作推薦算法單元23、基於評分填充的混合推薦算法單元24、利用評分時間特性的協作推薦算法單元25,而算法選擇單元21選擇最匹配的算法結果,並將算法結果輸出至結果生成模塊3。
下面來進一步詳細說明上述各個單元所執行的算法。
1.基於加權相似度的協作推薦算法單元22:
本發明針對稀疏性問題,通過對推薦的各執行過程的相似性計算進行必要修正克服和緩解稀疏性問題的影響,提出了基於加權相似度的協作推薦算法,引用了適應不同項目評分數量分布的重合因子(Overlap Factor),並通過重合因子實現對傳統相似度計算的修正和改進。
重合因子從數量上度量了項目間公共評分在項目全局評分中所佔比重,刻劃了項目間公共評分的重合程度,強調了公共評分重合度在相似性度量中的重要性,通過將其作用於基於項目的相似度,可以從評分重合的角度區分相似度計算結果的可信度,即評分重合程度越高,則計算得到的相似度就越能反映項目間的真實相關性,反之,相似度計算的可信度則越低。對於參加項目間相似度計算的任意兩項目ti和tj,已分別對兩項目進行過評分的用戶集合為Ui={uc|uc∈U∧rci≠0}和Uj={u|uc∈U∧rcj≠0},則評分重合因子可形式化為
式2-1
不同於顯著性權重只與公共評分的絕對數量相關,通過公式2-1計算獲得的重合因子不僅正比於兩項目的公共評分數量,還反比於兩項目各自的用戶評分數量,保證評分重合因子可以適應不同項目的評分數量分布。通過使用重合因子可對傳統相似度進行修正,形成對應的加權夾角餘弦相似度(Weighted COsine SIMilarity,WCOSIM)和加權皮爾遜相關係數(Weighted Pearson Correlation Coefficient,WPCC),二者形式上可表示為傳統相似度與重合因子的乘積,如公式所示。
式2-2
式2-3
需要注意,本發明提出的重合因子都是全局相似度修正方案,是對CF 中的所有項目間相似度進行的整體調整,而非局部獨立相似度的修正,這種全局修正相似度只在整體使用時有意義。在此基礎之上,通過將上述加權相似度集成到傳統IBCF推薦過程中,本發明提出了基於加權相似度的協作推薦算法WSBCF(Weighted Similarity-Boosted Collaborative Filtering),WSBCF算法的執行過程可分為以下3步:
(1)項目評分重合因子和基於項目的加權相似度計算
根據評分矩陣按照公式2-1計算任意項目ti和tj之間的重合因子,並通過公式計算任意項目間的加權相似度。
(2)鄰居項目選擇
針對目標用戶uc的任意未訪問項目根據步驟(1)獲得的項目間加權相似度,對用戶uc的已訪問項目進行降序排序,並根據相對鄰居選擇閾值參數θ,選擇top-θ部分項目作為項目ti的鄰居集合Tci。
(3)基於項目的評分預測
針對目標用戶uc的任意未訪問項目根據目標用戶uc的已有評分、項目ti的鄰居項目集合Tci及相似度sim,採用如下公式對項目ti進行評分預測
式2-4
WSBCF算法在評分預測過程中,採用了傳統加權評分聚合方法,根據目標用戶的已有評分和目標項目的鄰居,以鄰居與目標項目的相似度為權重,通過加權求和實現對目標項目的評分預測。WSBCF的總時間複雜度為O(mn)+O(mn2)+O(n),這對傳統IBCF的時間複雜度O(mn2)的影響有限。
2.基於平衡評分預測機制的協作推薦算法單元23:
為了從評分預測角度減少稀疏性問題對IBCF推薦算法的影響,可在個性化評分與全局評分之間建立一種動態平衡。本發明建立了一種結合個 性化評分與全局評分的動態平衡評分預測機制,並提出了一種基於平衡評分預測機制的協作推薦算法。
為使兩類評分在基於項目的評分預測中都能發揮各自的作用,本發明提出的動態平衡評分預測機制是一種關於兩類評分的線性組合。同時,為了保持兩類評分的動態平衡,可通過權重的變化來動態調整二者所發揮的作用,而將全局評分數據的分布特性作為權重動態調整的主要依據。針對推薦系統的任意用戶uc及其未訪問項目ti,集成兩類評分的動態平衡評分預測可形式化為
式2-5
其中,表示針對目標項目ti基於項目的個性化評分,該個性化評分採用了公式2-12所描述的IBCF評分預測方法,gi為目標項目的全局評分,而αi為個性化評分與全局評分之間的權重平衡參數。
針對稀疏性問題對評分預測過程的影響,結合上述動態平衡評分預測機制,通過對傳統IBCF評分預測過程進行必要的修正,形成一種基於平衡評分預測機制的協作推薦算法IBCFBP(Item-Based Collaborative Filtering integrating Balanced Prediction),該算法的執行過程主要包括以下4步:
(1)基於項目的相似度計算
基於已有評分數據,通過基於項目的相似度計算方法度量項目之間的相似度,對於任意項目ti和tj,基於項目的COSIM相似度可表示為
式2-6
或者採用基於項目的PCC相似度,可表示為
式2-7
(2)統計項目評分中位數和權重平衡參數
根據任意項目ti已獲得的評分數據,統計該項目的全局評分中位數gi,並採用公式2-5、2-6或者2-7之一統計該項目全局評分數據的分散性,以表示平衡評分預測機制的權重平衡參數αi。
(3)鄰居項目選擇
針對目標用戶uc的任意未訪問項目ti,根據該用戶對已訪問項目的評分,結合步驟(1)計算獲得的項目間相似度,對用戶uc的已訪問項目進行降序排序,並選擇top-θ部分項目作為項目ti的鄰居項目集合Tci。
(4)基於項目的評分預測
針對用戶uc的任意未訪問項目ti,根據該用戶的已有評分、項目ti的鄰居項目集合Tci以及相關相似度,採用公式對項目ti進行平衡評分預測。
IBCFBP的總時間複雜度為O(n)+O(mn2)+O(n),與傳統協作推薦算法的時間複雜度O(mn2)相當,而且項目中位數和權重平衡參數的計算均可離線完成,所以二者對推薦的計算效率影響基本可以忽略。
3.基於評分填充的混合推薦算法單元24:
本發明提出了一種基於評分填充的混合推薦算法HRRF(Hybrid Recommendation based on Rating Filling),該算法可根據用戶已訪問項目的信息內容實現自動化用戶建模,並將基於內容的用戶模型用於實現對用戶未訪問項目的個性化評分填充,提高了評分矩陣的整體密度,進而基於經填充處理的評分矩陣,採用IBCF推薦框架實現評分的預測,HRRF從評分填充的角度,減少了稀疏性問題通過評分矩陣對CF相似度計算和評分預測過程的影響。
基於內容的用戶模型是HRRF實現評分填充的依據,HRRF基於內容 的用戶模型在本質上起到了Filterbot的作用,但不同於Filterbot人工構造的方式,HRRF的用戶模型是通過機器學習自動構造的。將用戶模型的構造理解為一種基於機器學習的文本分類任務,根據已訪問項目的內容信息,通過一定的機器學習算法可以自動訓練針對不同用戶的分類模型,並將該模型作為相應的用戶描述,HRRF採用了Rocchio學習算法來實現基於內容的用戶建模,也可以根據實際推薦環境選擇其他機器學習算法來訓練用戶模型。
HRRF混合推薦算法的整體執行過程可以描述為以下7個步驟:
(1)推薦項目內容表示
因為HRRF的用戶模型是建立在推薦對象的內容基礎上的,所以首先需要對信息對象的內容進行表示,HRRF採用了傳統的VSM模型表示推薦對象的內容,設推薦系統包含由n個推薦項目構成的項目集合T={ts|1≤s≤n},用於描述項目內容的特徵空間為X={x1,x2,...,xd},推薦對象ti的特徵向量為其中特徵分量表示特徵xj對於項目ti的權重。設表示特徵xj在項目ti內容中出現的詞頻,而dfj表示包含特徵xj的項目個數,則特徵權重可表示為
式2-8
(2)基於內容用戶模型的學習
HRRF的用戶模型使用了與推薦項目相同的特徵空間X={x1,x2,...,xd},設推薦系統的用戶集合U={uc|1≤c≤m},用戶ui基於內容的用戶模型表示為根據用戶已有正例評分項目集合T+和負例評分項目集合T-,評分分類的閾值選擇該目標用戶的評分均值,根據Rocchio學習算法訓練用戶模型的特徵權重可表示為
式2-9
由於Rocchio學習算法是一種批學習算法(Batch Learning),所以用戶模型必須進行周期性更新,但模型的更新可以離線完成,不會對推薦系統的在線計算性能造太大影響。
(3)基於內容的相似度計算
根據步驟(2)所獲得的基於內容的用戶模型,針對推薦系統中的任意用戶ui,通過傳統基於內容的相似度計算方法度量該用戶與其任意未評分項目tj在內容上的相似度,例如,可以採用公式2-10的COSIM相似度計算形式。
式2-10
(4)基於CBF的評分預測與填充
為了提高評分矩陣的整體密度,根據步驟(3)獲得的用戶模型與未評分項目間的相似度,採用傳統CBF對用戶的未訪問項目進行評分預測,並使用預測評分填充相應的評分矩陣位置,形成用戶-項目評分全矩陣。在評分值域範圍為[min,max]的推薦系統中,對於用戶ui以及其任意未訪問項目tj,則預測評分值為
r′ij=min+s(i,j)|max-min| 式2-11
(5)基於評分的相似度計算
通過步驟(1)-(4)的處理,原始稀疏用戶評分矩陣已得到了填充處理, 後續步驟將採用IBCF算法實現推薦,對於任意項目ti和tj,二者間基於項目的COSIM相似度為
式2-12
注意,需要根據用戶是否已訪問過項目ti,決定選擇基於內容的填充評分值r′ci或原始評分值rci來表示公式2-12中的評分r″ci,即
式2-13
(6)鄰居項目選擇
針對目標項目ti,根據步驟(5)獲得的項目間相似度,對所有其他項目進行降序排序,並選擇最相似的k個項目構成項目ti的鄰居集合Ti。
(7)基於項目的評分預測
針對目標用戶ui的任意未訪問項目tj,通過IBCF方法進行該項目的評分預測。鑑於通過CBF生成的填充評分在可信度上要低於真實評分,在評分預測過程中,通過適當縮小相似度來降低評分填充值在評分預測中的作用,評分預測的計算可表示為
式2-14
TIBCF算法只在相似度計算和評分預測過程中引入了時間權重,從計算量上來看,時間權重的加入對推薦的整體計算複雜度影響有限。
4.利用評分時間特性的協作推薦算法單元25:
目前的推薦算法沒有建立感知用戶興趣變化的動態機制,所形成的用戶興趣模型是一種靜態模型,隨著概念漂移的發生,推薦系統的推薦質量將表現的不穩定,特別是用戶興趣發生突變時,推薦的準確性將急劇惡化。因此,發明針對時漂移問題,發明提出了一種利用評分時間特性的協作推薦算法TIBCF(Temporal Item-Based Collaborative Filtering,TIBCF)。
本發明提出的TIBCF算法在克服概念漂移的過程中,需要根據評分的生成時間對評分的重要性進行區分。因此,TIBCF算法對傳統評分矩陣進行了必要的完善,除記錄評分數值外,還記錄了評分的產生時間信息,TIBCF算法中的用戶-項目評分矩陣可表示為:
R(m×n)={<rij,dij>|(ui∈U)∧(tj∈T)∧(0≤rij≤q)∧(dij=NULL∨dij∈DateTime)}
用戶ui針對項目tj的評分信息在評分矩陣R(m×n)表示為二元組<rij,dij>,rij和dij分別對應評分值和評分時間。為了在相似度計算和評分預測中從時間角度區分評分的重要性,TIBCF算法引入了時間權重的概念,為不同時間產生的評分賦予相應的時間權重。針對用戶ui在時間dij對項目tj所產生的評分rij,TIBCF根據公式的指數衰減函數形式計算該評分的時間權重w(i,j)。
式2-15
其中,Ri為用戶ui的歷史評分有序集合,RK函數表示評分rij在Ri中的位置編號。結合文獻中AWS的方法,TIBCF設置評分權重的半衰期(Half-Life Span)為λ/log(|Ri|),其既與用戶的評分數量相關,又與衰減參數λ相關。通過衰減參數λ可以調整半衰期的長度,λ的選擇與具體應用的評分分布有關,可以通過實驗獲得,也可依據推薦系統準確性的變化而動態調整。對於具有500個評分的用戶,圖2展示了λ=300和λ=500時評分權重衰減曲線的示例。
在根據公式計算獲得用不同評分的時間權重後,TIBCF在傳統IBCF算法的相似度計算和評分預測中都集成了該權重,從而分別實現相應基於時間的加權相似度計算和加權評分預測,通過對IBCF兩個關鍵過程進行基於時間的修正,可以最大限度地減少概念漂移問題對推薦的影響。TIBCF推薦算法的執行過程可以分為以下4個步驟:
(1)項目評分排序和時間權重計算
針對任意用戶按照該用戶已有評分的產生時間由近至遠,對其所有歷史評分進行按時間的排序生成歷史評分有序集合Ri,計算用戶ui的任意歷史評分rij的時間權重w(i,j)。
(2)項目間基於時間的加權相似度計算
通過步驟(1)獲得所有評分的時間權重後,對系統中的任意兩項目ti和tj,按照公式2-15或2-16計算二者間基於時間的加權皮爾遜相關係數(Temporal Pearson Correlation Coefficient,TPCC)或基於時間的加權夾角餘弦相似度(Temporal COsine SIMilarity,TCOSIM)。
式2-16
式2-17
(3)鄰居項目選擇
針對目標用戶uc的任意未訪問項目ti,根據步驟(2)獲得的項目間相似度,對用戶uc的所有已訪問項目進行降序排序,並選擇top-θ部分項目作為項目ti的鄰居項目集合Tci。
(4)基於項目的加權評分預測
針對目標用戶uc的任意未訪問項目ti,根據用戶uc的已有評分、ti的鄰居項目集合Tci、評分時間權重w及相應加權相似度sim,通過如下公式對項目ti進行評分預測
式2-18
TIBCF算法只在相似度計算和評分預測過程中引入了時間權重,從計算量上來看,時間權重的加入對推薦的整體計算複雜度影響有限,仍可以保持與傳統IBCF算法O(mn2)相當的計算時間複雜度水平。
本技術領域中的普通技術人員應當認識到,以上的實施例僅是用來說明本發明,而並非用作為對本發明的限定,只要在本發明的實質精神範圍內,對以上所述實施例的變化、變型都將落在本發明的權利要求書範圍內。