一種基於並行卷積神經網絡的圖像質量測試方法與流程
2023-06-14 02:17:47 5
本發明涉及圖像信號處理領域,特別涉及一種基於並行卷積神經網絡的圖像質量測試方法。
背景技術:
人類的美感感受和判斷雖然受到文化背景、個人經歷、時代背景等的影響,但是總體上具有很大的共性。無數繪畫、攝影和藝術作品作為人類共同的審美財富普遍受到人們的欣賞和喜愛。美學質量評估就是希望通過計算機,模擬人類高層感知來判斷圖像的美感,實現對圖像進行高質量或低質量分類,或者對圖像的質量程度給出評分。
傳統的圖像質量評估方法大多採用手選識別特徵的方式,圖像特徵的有效提取對分類結果具有至關重要的作用。例如嘗試借鑑攝影,藝術,繪畫等領域的規則、人類審美經驗、視覺注意機制,從圖像中提取各種各樣的圖像特徵,例如邊緣特徵,顏色直方圖特徵,三分法則特徵等等。還有一些使用局部特徵的方法,例如SIFT(Scale-invariant feature transform)算法,詞袋(Bag Of Words,Bow)算法,FisherVector(FV)算法,或者它們的改進算法等。這些方法都取得了較好的應用價值。
深度學習在解決傳統計算機視覺問題上有突破性進展,尤其是卷積神經網絡(Convolutional Neural Network,CNN)的應用。通過直接利用大量的數據訓練多層CNN,不需要先驗知識和經驗,人們發現網絡對於學習到的特徵具有較好的魯棒性,不僅省去了複雜繁瑣的手動特徵提取過程,更能從樣本中發現更為重要並難以理解的高層特徵。利用深度學習進行圖像質量評價研究中,賓夕法尼亞州立大學的學者Wang等人設計了一個雙通道的卷積神經網絡用於圖像質量分類人物。中國科學技術大學的田教授等人利用深度學習網絡來提取圖像特徵,然後使用支持向量機(Support Vector Machine,SVM)進行圖像質量分類。這些是深度學習方法在圖像質量評估方面的初步嘗試,取得了一定的效果。
然而不同場景類別的圖像差異大,這導致不同圖像特徵對於不同場景類別圖像的適應性較差。另外,圖像的一些複雜的構圖規則和質量評估規律在工程上難以被建模和量化,這成為圖像特徵提取上的瓶頸。
因此需要一種新的測試模型來克服現有技術中存在的問題。
技術實現要素:
為了克服現有技術的上述缺點與不足,本發明的目的在於提供一種基於並行卷積神經網絡的圖像質量測試方法,克服了傳統方法需要手工設計多種圖像特徵的缺點,深入分析和挖掘圖像質量特徵,泛化能力強,分類準確率高。
本發明的目的通過以下技術方案實現:
一種基於並行卷積神經網絡的圖像質量測試方法,包括以下步驟:
(1)採用並行卷積神經網絡建立圖像質量測試模型;所述圖像質量測試模型包括第一卷積層、第二卷積層、第三卷積層、第四卷積層、第五卷積層、第一全連接層、第二全連接層和第三全連接層;
所述第五卷積層為包含n個分支的並行結構網絡;1≤n≤10;
(2)輸入數據預處理與資料庫平衡化處理:對預訓練數據集的每個樣本進行裁剪和歸一化,並對預訓練數據集的樣本數量進行平衡化處理;
(3)模型的預訓練:採用預訓練數據集,對圖像質量測試模型進行預訓練學習,得到網絡權值;
所述預訓練學習,具體為:
用預訓練數據集中每一種類別圖像各自訓練一個深度CNN網絡,並且進行權值學習和提取;
所述權值學習和提取,具體包括以下步驟:
(3-1)深度CNN網絡權值初始化;
(3-2)對深度CNN網絡進行迭代訓練;
(3-3)提取每一個深度CNN網絡第五卷積層學習得到的卷積核權值;
(4)並行模型訓練:初始化圖像質量測試模型,基於預訓練初始化後的圖像質量測試模型,進行並行模型訓練,得到已訓練的圖像質量評估模型;
(5)對目標圖像使用已訓練的質量評估模型進行測試。
步驟(2)所述輸入數據預處理,具體為:將所有的樣本的長寬統一歸一化為256*256,在模型輸入接口的匹配中,每一次讀取輸入圖像數據時,被隨機裁剪到規格為227*227的大小。
步驟(2)所述資料庫平衡化處理,具體為:對預訓練數據集中的每個樣本進行旋轉處理,並左右鏡像一次,產生新的樣本。
步驟(3)所述預訓練學習中,第一~第四卷積層初始設為AlexNet模型前四層網絡權值,採用隨即梯度下降方式進行訓練,學習率設置為初始值0.0001,第五卷積層提取層和全連接層則設置初始學習率為0.001。
步驟(4)所述初始化圖像質量測試模型,基於預訓練初始化後的圖像質量測試模型,進行並行模型訓練:
(4-1)模型初始化;
(4-2)設置訓練參數;
(4-3)加載訓練數據,所述訓練數據包括訓練集和驗證集;
(4-4)採用隨即梯度下降算法對初始化後的圖像質量測試模型進行迭代訓練,在訓練集上,每迭代1000次保存一次模型參數,經過不斷迭代,取得網絡最優解,取在驗證集上誤差最小的模型作為已訓練的圖像質量評估模型。
步驟(4-1)所述模型初始化,具體為:
引用AlexNet模型的權值來初始化圖像質量測試模型的第一~第四卷積層,第五層的並行結構由步驟(3)中預訓練階段得到的權值進行初始化,全連接層的則權值採用隨機初始化方式。
步驟(4-2)所述設置訓練參數,具體為:
第一~第五卷積層的初始學習率設置為0.0001;全連接層參數的初始學習率為0.001;訓練過程設為每8次遍歷樣本集後,學習率降低40%。
所述深度網絡模型結構,具體如下:
第一卷積層有96個卷積核,大小為11*11*3;第二卷積層有256個卷積核,大小為5*5*48;第三卷積層有384個核,大小為3*3*256;第四卷積層有384個核,大小為3*3*192;第5卷積層有64*n個核,大小為3*3*64;第一和第二全連接層有512和神經元,第三全連接層有2個神經元;
第一層卷積層依次經第一池化層、第一正則化層與第二卷積層連接;第二卷積層經第二池化層、第二正則化層與第三卷積層連接;第一池化層、第二池化層參數與AlexNet模型參數相同;第三卷積層直接與第四卷積層連接;第四卷積層直接與第五卷積層連接;第五卷積層經第五池化層與第一全連接層連接,第五池化層採用均值池化方法,池化單元大小z*z取2*2,池化步長s取2;第一全連接層依次連接第二全連接層和第三全連接層。
與現有技術相比,本發明具有以下優點和有益效果:
(1)本發明採用並行深度卷積神經網絡模型,並行多個獨立分支,有效結合了傳統的特徵融合方法,具有很好的可擴展性,同時提高了模型的特徵表達能力。
(2)本發明提出的預訓練過程中具有先進性,具體表現在:選取噪聲小、乾淨的數據集作為模型預訓練數據;第五卷積層多個分支可以全面的學習到圖像質量信息;借用現今模型的優點進一步優化提升模型性能。
(3)在全連接層和卷積層之間使用均值池化層,降低噪聲對特徵數據的影響,增強分類效果。
(4)提出一種利用多種數據集完成圖像質量分類系統的訓練和測試方法,有利於在大數據量的圖像庫中進行快速質量分類,方法簡單有效,可靠性高。
附圖說明
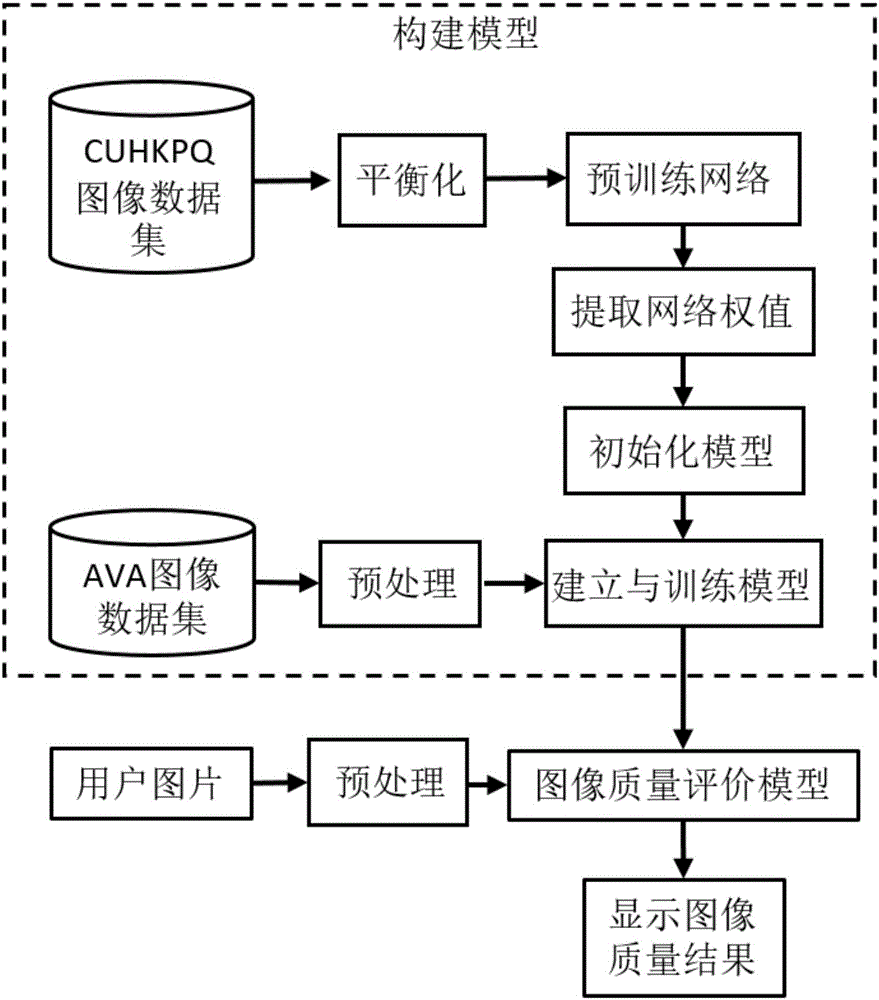
圖1為本發明的實施例的基於並行卷積神經網絡的圖像質量測試方法的訓練和工作流程圖。
圖2為本發明的圖像質量測試模型結構圖。
圖3為本發明的在預訓練階段用於權值學習的卷積神經網絡模型結構圖。
具體實施方式
下面結合實施例,對本發明作進一步地詳細說明,但本發明的實施方式不限於此。
實施例
如圖1所示,本實施例的基於並行卷積神經網絡的圖像質量測試方法,包括以下步驟:
(1)採用並行卷積神經網絡建立圖像質量測試模型;所述圖像質量測試模型包括第一卷積層、第二卷積層、第三卷積層、第四卷積層、第五卷積層、第一全連接層、第二全連接層和第三全連接層;所述第五卷積層為包含n個分支的並行結構網絡;1≤n≤10。
如圖2所示,本實施例的圖像質量測試模型一個包含5層卷積層和3個全連接層的8層的深度卷積神經網絡,此模型前四層卷積層借用了Alexnet[A.Krizhevsky,I.Sutskever,G.E.Hinton,ImageNet classification with deep convolution neural networks,in:Proceedings of the Annual Conference on Neural Information Processing System(NIPS),2012,pp.1097-1105.]的前四層網絡結構與參數。第五層定義為場景卷積層,本實施例由7組卷積核並行構成,用於學習不同場景類別下的圖像特徵。每個分支分別連接第四層與第五層中的一組卷積網絡。
第一卷積層有96個卷積核,大小為11*11*3;第二卷積層有256個卷積核,大小為5*5*48;第三卷積層有384個核,大小為3*3*256;第四卷積層有384個核,大小為3*3*192;第5卷積層有64*n個核,大小為3*3*64;第一和第二全連接層有512和神經元,第三全連接層有2個神經元;
第一層卷積層依次經第一池化層、第一正則化層與第二卷積層連接;第二卷積層經第二池化層、第二正則化層與第三卷積層連接;第一池化層、第二池化層參數與AlexNet模型參數相同;第三卷積層直接與第四卷積層連接;第四卷積層直接與第五卷積層連接;第五卷積層經第五池化層與第一全連接層連接,第五池化層採用均值池化方法,池化單元大小z*z取2*2,池化步長s取2;第一全連接層依次連接第二和第三全連接層;
(2)輸入數據預處理與資料庫平衡化處理:對預訓練數據集的每個樣本進行裁剪和歸一化,並對預訓練數據集的樣本數量進行平衡化處理;
步驟(2)所述輸入數據預處理,具體為:
將所有的樣本的長寬統一歸一化為256*256,在模型輸入接口的匹配中,每一次讀取輸入圖像數據時,被隨機裁剪到規格為227*227的大小。通過這樣的方式,確保不會丟失圖像的全局信息。
不平衡的訓練數據集會對分類結果產生不良影響,弱化學習得到特徵的表達能力。預訓練階段用到的CUHKPQ資料庫包含有17690張圖片,圖片集一共有7個類別,分別是"animal","plant","static","architecture","landscape","human"和"night"。每一種類別圖片都標有相同的兩個標籤,高質量和低質量。這個數據集噪聲小,被選用來做預訓練階段的訓練數據。此外,由於該數據集不平衡,CUHKPQ數據集的高質量圖片與低質量圖片之比大約是1比3,在把數據分為訓練集和測試集之後,本發明所提方法對訓練集做了平衡化處理,以確保預訓練得到模型的有效性。具體做法如下:
對訓練集中的每張高質量圖片進行旋轉270°處理,並左右鏡像一次,產生兩張額外新的樣本。使高質量圖像的數量達到和低質量圖片數量大致相等。
(3)模型的預訓練:採用預訓練數據集,對圖像質量測試模型進行預訓練學習,得到網絡權值;
所述預訓練學習,具體為:
用預訓練數據集中每一種類別圖像各自訓練一個深度CNN網絡,並且進行權值學習和提取;預訓練學習中,第一~第四卷積層初始設為AlexNet模型訓練後的參數後,採用隨即梯度下降方式進行訓練,學習率設置為初始值0.0001,第五卷積層提取層和全連接層則設置初始學習率為0.001。
所述權值學習和提取,具體包括以下步驟:
(3-1)深度CNN網絡權值初始化;
(3-2)對深度CNN網絡進行迭代訓練;
(3-3)提取每一個深度CNN網絡第五卷積層學習得到的卷積核權值;
圖3所示為用於權值學習的卷積神經網絡模型結構圖。對於每種場景類型圖像,分別進行場景圖像特徵的學習。訓練時是單通道深度學習網絡結構,前四層卷積層與圖3的卷積層一樣,第五層為圖3第五層的一個卷積組,全連接層的神經元個數為512,網絡的最後一層是2個神經元連接著Softmax函數作為輸出。它表示輸入圖像是屬於高質量或低質量類別。
在本實施例中,將第5層學習到的權值表徵為場景圖像特徵。這樣,一一用圖3所示網絡對7種類別的圖像進行訓練和學習,取出第五層的7組學習到的卷積核權值,用這些權值初始化並行網絡的第五層網絡,完成了模型預訓練過程。
在深度CNN網絡的學習階段中,採用基本的Softmax計算損失函數,在而分類任務的情況下,變換為簡單的邏輯回歸函數,圖像輸入為x,標籤為y。損失函數的計算如下列公式所示:
其中,m表示為圖片數量,預測函數hθ(xi)的表達是:
其中,xi為第i張輸入圖像,yi為第i輸入圖像所對應的標籤數據。
(4)並行模型訓練:初始化圖像質量測試模型,基於預訓練初始化後的圖像質量測試模型,進行並行模型訓練,得到已訓練的圖像質量評估模型,具體步驟如下:
(4-1)模型初始化:引用AlexNet模型的權值來初始化圖像質量測試模型的第一~第四卷積層,第五層的並行結構由步驟3中預訓練階段得到的權值進行初始化,全連接層的則權值採用隨機初始化方式;
(4-2)設置訓練參數:第一~第五卷積層的初始學習率設置為0.0001;全連接層參數的初始學習率為0.001;訓練過程設為每8次遍歷樣本集後,學習率降低40%;
(4-3)加載訓練數據,所述訓練數據包括訓練集和驗證集;採用總共約有25萬張圖像的AVA大規模數據集對網絡模型進行訓練,對應網絡的輸入大小,所有樣本統一歸一化到256*256的大小。每張圖片具有兩個高、低質量兩個標籤中的一個;
(4-4)採用隨即梯度下降算法對初始化後的圖像質量測試模型進行迭代訓練,在訓練集上,每迭代1000次保存一次模型參數,經過不斷迭代,取得網絡最優解,取在驗證集上誤差最小的模型作為已訓練的圖像質量評估模型。
(5)對目標圖像使用已訓練的質量評估模型進行測試。本發明的評價模型在AVA測試集上的分類準確率達到76.94%。
上述實施例為本發明較佳的實施方式,但本發明的實施方式並不受所述實施例的限制,其他的任何未背離本發明的精神實質與原理下所作的改變、修飾、替代、組合、簡化,均應為等效的置換方式,都包含在本發明的保護範圍之內。