一種與銀屑病相關的分類模型的構建方法與流程
2023-06-14 05:39:36 3
本發明涉及醫學檢測技術領域,具體涉及一種與銀屑病相關的分類模型的構建方法。
背景技術:
銀屑病又稱牛皮癬是一種常見的複雜疾病,有報導銀屑病的發生與遺傳因素相關,尤其是人類白細胞抗原區域(hla),但真正相關的位點並未可知。
隨著測序技術的發展和基因組研究的深入,在去年《自然遺傳》上就有報導中國人mhc區域的高深度測序和精準變異檢測,在其基因組關聯分析中定位了數個銀屑病的易感位點。但是目前尚缺乏基於hla區域的易感位點的分類和預測模型。所以急需開發相關的分類預測工具利用hla區域易感位點對數據進行分類預測。
銀屑病與hla最顯著相關,但目前的技術缺乏對hla區域針對性的運用。近期hla區域進行精準變異檢測得到突破,精準的定位了hla上與銀屑病相關的易感位點。本發明針對這些易感位點對其進行編碼和再用機器學習模型adaboost進行分類,可以整合利用hla區域找到的易感位點信息。利用機器學習模型對數據進行綜合分析,提高分類準確性,為銀屑病的預防篩查提供依據。
技術實現要素:
本發明的目的是解決上述現有技術的不足,基於對mhc區域的全覆蓋找到與銀屑病相關的生物標記,基於hla區域獨立相關的易感位點,利用svm-adaboost構建銀屑病的分類模型,提供一種與銀屑病相關的分類模型的構建方法,為銀屑病的預防篩查提供依據。
本發明是通過以下技術方案實現的:
1數據處理和轉換
將各個樣本的變異進行編碼。通過高通量測序數據獲得變異信息,包括hla型別(c*06:02、c*07:04、dpb1*05:01),單核苷酸多態性位點(snp位點)和胺基酸(snp31443520、b:y33y、b:y91c、b:y140s、snp32472030)。
然後對每樣本,根據易感位點,轉化為本發明所需要的輸入數據。針對hla型別採用編輯距離打分,snp和胺基酸採用0/1打分。具體方法如下:①針對易感hla型別,計算每個個體該型別與易感型別的編輯距離並打分;②針對snp位點,如果突變存在記為1,不存在記為0;③針對胺基酸突變,如果突變存在記為1,不存在記為0。
打分完成後,將數據隨機拆分,拆分為測試集和訓練集,注意測試集和訓練集數據沒有重疊。樣本數少的時候,可以按照5折交叉法(或10折交叉法)將數據分成5份(10份),每次取出1作為測試集,其餘的作為訓練集。
2利用adaboost-svm模型進行數據的分類
本發明利用adaboost方法來集成支持向量機(svm)分類器,整合利用所有的易感位點信息,提高數據的分類的正確率。
2.1關於分類模型的構建
2.1.1子分類模型svm
支持向量機模型svm是經典的機器學習分類軟體,屬於有監督式學習。本發明首先利用的高斯核函數(公式1)將數據投射到高維度空間。
其中,x為空間中任意一點,y為所選空間中心,σ為寬度參數,k(x,y)為x到y的空間距離。
之後高維度空間中用svm模型構建分隔平面。分隔平面構建主要是通過距離分隔平面最近的數個點來確定(如圖1所示a點就是最近的點之一),並且將最近的點到分隔平面的連線稱為支持向量,當支持向量達到最大化時候的平面就設為分隔平面,也即是通過分隔平面將數據最大地分開。本發明採用基於python2的svm模型(參考網站https://www.manning.com/books/machine-learning-in-action)。
2.1.2分類模型集成算法adaboost
adaboost是一種基於錯誤提升分類器性能的集成方法,通過每一個樣本多次訓練,通過錯誤率反覆修正分類器最後整合得到集成後的結果。具體方法:首先對樣本賦予一樣同等的權重。然後在訓練數集數據上訓練svm並計算該分類器的錯誤率(ε,公式2)。
錯誤率ε=正確分類數目/總樣本數目(公式2)
然後調整高斯核函數σ,之後在同一數據集上再次svm。在分類器的第二次訓練當中,將會重新調整每個樣本的權重(這裡的權重是一個多維度的向量),其中分類正確樣本的下次分類權重將會降低,分類錯誤的樣本的下次權重將會提高。也就是說,最終達到分類正確時候的權重會比分類錯誤的權重佔比要大。具體方法是根據錯誤率計算每個分類器的權重α。
計算出α之後可以對權重進行更新。
分類正確:
分類錯誤:
α為基本分類器在最終分類器中的權重,ε為分類器的錯誤率;(t)代表順序,t代表本次,t+1代表下一次;di為第i個訓練樣本權值。
計算權值d之後,開始進入下一輪迭代。不斷地重複訓練和調整權重的過程,直到訓練錯誤率為0或者弱分類器的數目達到指定值。本發明採用基於python2的adaboost集成框架(參考網站https://www.manning.com/books/machine-learning-in-action)
3對數據進行分類和評估
構建好輸入訓練集和測試集之後,代入構建的adaboost-svm模型中進行分類。通過分類模型的結果與實際患病與否的情況進行比較。通過計算準確率和繪製roc曲線來對結果進行評估。
roc曲線是用於選擇最佳的信號模型的方法。通常可計算roc曲線下方面積(auc)來判斷分類模型好壞,具體參考表1。
表1
本發明的有益效果在於:
目前缺乏相關的技術來對銀屑病數據進行分類和預測,只停留在判斷位點有無來推斷患病情況。本發明利用有效的機器學習分類器svm進行分類,並通過了adaboost框架來集成svm,提高分類器的準確性。該模型可以整合snp、胺基酸和型別數據進行分類,綜合考慮各個維度的信息,提高了數據了分類結果的準確性。
附圖說明
圖1為高維度空間中用svm模型構建分隔平面的示意圖;
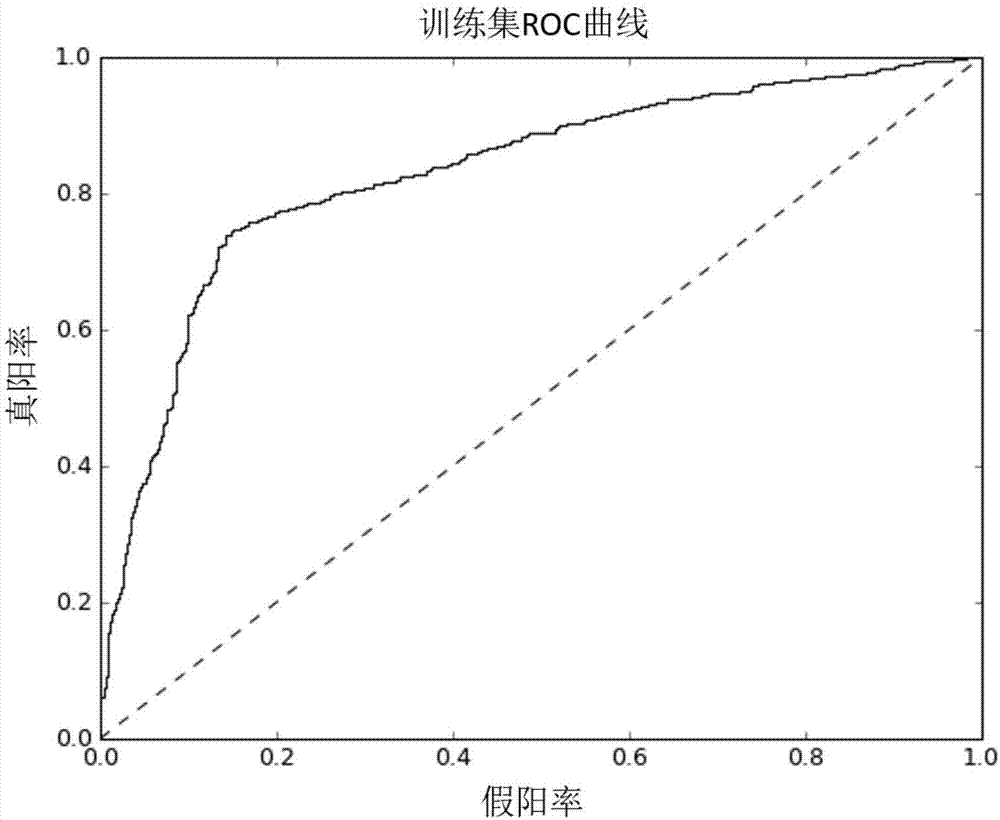
圖2為本發明訓練集分類結果的roc曲線;
圖3為本發明測試集分類結果的roc曲線。
具體實施方式
為更好理解本發明,下面結合實施例及附圖對本發明作進一步描述,以下實施例僅是對本發明進行說明而非對其加以限定。
實施例1
選擇了銀屑病30歲以下樣本進行研究共計5168例。利用基於python2語言的adaboost-svm模型針對易感位點構建模型進行分類。
1數據的處理和轉換
本實施案例中,首先通過變異檢測獲得樣本的變異信息ped和map文件。之後根據易感位點(表2)提取出hla區域變異信息。其中型別(1、2、7)的打分按照編輯距離進行打分(打分矩陣見表3),胺基酸位點和snp位點(3、4、5、6、8)按照存在與否進行打分,存在打分為1,不存在打分為0。
表2易感位點
表3編輯距離打分矩陣
得到數據列表,由於數據量5168例,所以本案選擇2000例作為訓練集,餘下樣本作為測試集。
2代入模型
將處理好的數據代入本發明構建的adaboost-svm模型中進行計算,本案設置9個svm分類器,σ取值從30到3,從大到小逐次遞減。
3得到結果
如圖2和3所示,本案分類錯誤率為23.9%,訓練集auc(roc曲線下面積)為0.833,測試集auc為0.868,說明本發明在本實施例中達到良好效果。
以上所述實施方式僅僅是對本發明的優選實施方式進行描述,並非對本發明的範圍進行限定,在不脫離本發明設計精神的前提下,本領域普通技術人員對本發明的技術方案作出的各種變形和改進,均應落入本發明的權利要求書確定的保護範圍內。