氣體傳感器、顆粒物傳感器的新校準方法與流程
2023-06-26 04:00:06 3
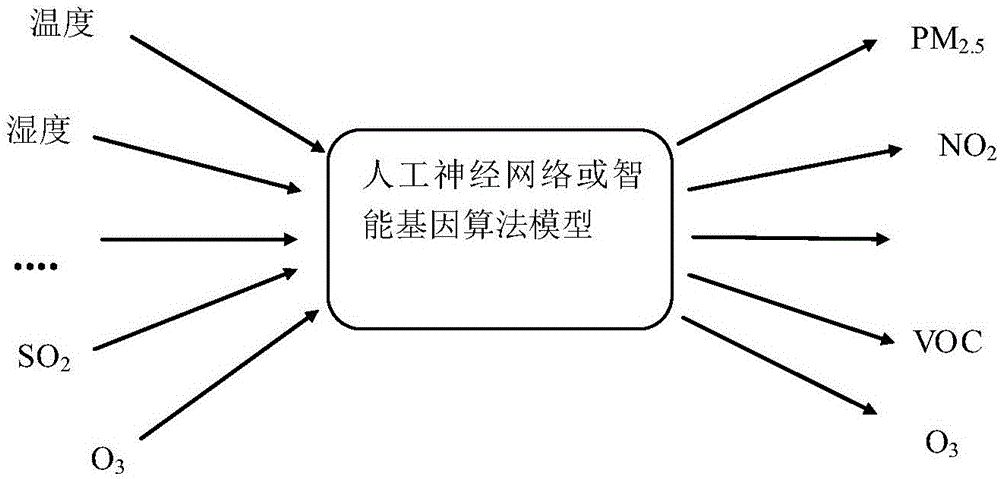
本發明涉及一種氣體傳感器、顆粒物傳感器的新校準方法。
背景技術:
當前的技術存在的氣體傳感器(SO2、NO2、CO、O3、VOC、NH3、HCHO、H2S)和顆粒物傳感器(PM2.5、PM10)在長時間使用過程中受溫度、溼度、其他氣體或因素交叉幹擾和傳感器元件老化等引起檢測結果漂移和檢測限下降。
由於氣體傳感器和顆粒物傳感器易受到溫度、溼度和其他氣體直接或間接導致檢測結果發生嚴重的漂移,致使檢測數據無效,此時傳感器需要進行有效的校準。
技術實現要素:
針對上述問題,本發明提供一種提高了傳感器穩定性和檢測結果有效性的氣體傳感器、顆粒物傳感器的新校準方法。
本發明氣體傳感器、顆粒物傳感器的新校準方法,包括:
建立傳感器校準模型;
試驗艙為校準模型提供校準數據,通過試驗艙提供的標準校準數據確定校準模型中的不同傳感器的影響因子的線性、非線性參數具體數值大小;
校準模型針對不同參數採用通用人工智慧大數據算法平臺,通過建立較深層數的人工神經網絡或智能基因算法模型,使傳感器能夠自動從試驗艙交叉實驗參數數據中提取並得到該傳感器的溫度、溼度、幹擾氣體或因素和時間老化的線性/非線性含有不同參數的交叉相應曲線,可映射任意複雜的非線性校準模型,具有很強的魯棒性和適應性。
進一步地,所述的建立傳感器校準模型具體包括:根據傳感器檢測原理、大氣環境化學知識,初步確定影響氣體傳感器和顆粒物傳感器的檢測精度的因素,通過實時測量獲得的傳感器檢測參數和其影響因素的時間序列,輸入人工神經網絡或智能基因算法,獲得各個影響因素的線性或非線性因子數值,即建立了校準模型。
進一步地,所述的校準模型針對不同參數採用通用人工智慧大數據算法平臺,具體步驟包括:獲取各個傳感器檢測參數的影響因素的實時檢測序列,將檢測參數和其影響因素的實時監測結果,進行數據對齊、數據誤差分析、汙染源事件分析,去除無效數據,然後將其輸入通過人工智慧大數據算法平臺,即可進行校準模型中未知因素的計算。
進一步地,根據不同的試驗艙實驗數據,形成的校準模型分為標物校準、組網校準、自適應校準和傳遞校準;
獲取傳感器和傳感器影響因素的實時檢測序列的方式,是通過試驗艙獲取的,根據實驗艙不同的氣體或顆粒物的實驗數據,選擇不同的校準模型,
如果在試驗艙中獲取各個影響因素是單一標準氣體,此時採用的算法是線性算法,校準模型中是一對一的關係,即為標物校準;
如果獲取各個影響因素是交叉標準氣體,即幾個影響因素的隨機排列組合,此時採用的算法是非線性算法,校準模型是多對多的交叉關係,即為組網校準;
如果在實驗艙中引入其他未知的影響因素,此時採多對多閉環反饋是神經網絡算法,通過反覆迭代,自適應計算各個影響因子的大小,即為自適用校準;
如果獲取的傳感器和各個影響因素的實時序列是通過可攜式標準儀器、移動監測車或者其他標準監測設備,自動判斷此類數據,針對不同參數啟動不同算法,此即為傳遞校準。
有益效果
本發明氣體傳感器、顆粒物傳感器的新校準方法與現有技術具備如下有益效果:
根據不同的試驗艙實驗數據,形成的校準模型可分為標物校準、組網校準、自適應校準和傳遞校準,校準模型體現了使微型站儘量脫離人類的經驗指導(標物校準模型),自動在海量標物和溫/溼度氣象環境數據中挖掘不同參數的響應曲線(即組網校準),進而形成通用人工智慧基於端對端的線性深度強化學習模型(即傳遞校準),利用雲校準平臺的互聯化、數據化和智能化自動幫助微型站能在不同的汙染源區域中生成一套校準模型框架(即自適應校準),從而校準模型能夠勝任不同的檢測環境。
附圖說明
圖1是本發明的校準模型示意圖。
具體實施方式
下面結合附圖對本發明做進一步的描述。
搭建了傳感器試驗艙,獲取到對傳感器有影響的參數的交叉實驗數據,將大量的不同參數的實驗室數據輸入建立的校準模型,得到不同傳感器的線性、非線性校準參數。校準模型針對不同參數採用通用人工智慧大數據算法平臺,通過建立較深層數的人工神經網絡或智能基因算法模型,使傳感器能夠自動從試驗艙交叉實驗參數數據中提取並得到該傳感器的溫度、溼度、幹擾氣體或因素和時間老化的線性/非線性含有不同參數的交叉相應曲線,可映射任意複雜的非線性校準模型,具有很強的魯棒性和適應性。校準模型示意圖如圖1所示。
本實施例氣體傳感器、顆粒物傳感器的新校準方法,包括:
建立傳感器校準模型;
試驗艙為校準模型提供校準數據,通過試驗艙提供的標準校準數據可以確定校準模型中的不同傳感器的影響因子的線性、非線性參數具體數值大小。
校準模型可以理解為一個黑盒子,黑盒子裡面的線性、非線性因子具體數值,是通過試驗艙提供的標準數據確定的,確定了影響因子的大小,校準模型即為確定,此校準模型即可用於以後儀器的實時運行。校準模型針對不同參數採用通用人工智慧大數據算法平臺,通過建立較深層數的人工神經網絡或智能基因算法模型,使傳感器能夠自動從試驗艙交叉實驗參數數據中提取並得到該傳感器的溫度、溼度、幹擾氣體或因素和時間老化的線性/非線性含有不同參數的交叉相應曲線,可映射任意複雜的非線性校準模型,具有很強的魯棒性和適應性。
所述的建立傳感器校準模型具體包括:根據傳感器檢測原理、大氣環境化學知識,初步確定影響氣體傳感器和顆粒物傳感器的檢測精度的因素,通過實時測量獲得的傳感器檢測參數和其影響因素的時間序列,輸入人工神經網絡或智能基因算法,獲得各個影響因素的線性或非線性因子數值,即建立了校準模型。
所述的校準模型針對不同參數採用通用人工智慧大數據算法平臺,具體步驟包括:獲取各個傳感器檢測參數的影響因素的實時檢測序列,將檢測參數和其影響因素的實時監測結果,進行數據對齊、數據誤差分析、汙染源事件分析,去除無效數據,然後將其輸入通過人工智慧大數據算法平臺,即可進行校準模型中未知因素的計算。
根據不同的試驗艙實驗數據,形成的校準模型可分為標物校準、組網校準、自適應校準和傳遞校準,校準模型體現了使微型站儘量脫離人類的經驗指導(標物校準模型),自動在海量標物和溫/溼度氣象環境數據中挖掘不同參數的響應曲線(即組網校準),進而形成通用人工智慧基於端對端的線性深度強化學習模型(即傳遞校準),利用雲校準平臺的互聯化、數據化和智能化自動幫助微型站能在不同的汙染源區域中生成一套校準模型框架(即自適應校準),從而校準模型能夠勝任不同的檢測環境。
獲取傳感器和傳感器影響因素的實時檢測序列的方式,是通過試驗艙獲取的,實驗艙的優點是可以控制傳感器影響因素的個數,實時創造各種影響因素的組合方式,能夠進行正交交叉實驗,根據不同的實驗艙實驗數據,即實驗數據的不同,如果在試驗艙中獲取各個影響因素是單一標準氣體,此時平臺算法是線性算法,校準模型中是一對一的關係,即為標物校準;如果獲取各個影響因素是交叉標準氣體,即幾個影響因素的隨機排列組合,此時平臺算法是非線性算法,校準模型是多對多的交叉關係,即為組網校準;如果在實驗艙中引入其他未知的影響因素,此時採多對多閉環反饋是神經網絡算法,通過反覆迭代,自適應計算各個影響因子的大小,即為自適用校準;如果獲取的傳感器和各個影響因素的實時序列是通過可攜式標準儀器、移動監測車或者其他標準監測設備,平臺自動判斷此類數據,針對不同參數啟動不同算法,此即為傳遞校準。
對本發明應當理解的是,以上所述的實施例,對本發明的目的、技術方案和有益效果進行了進一步詳細的說明,以上僅為本發明的實施例而已,並不用於限定本發明,凡是在本發明的精神原則之內,所作出的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內,本發明的保護範圍應該以權利要求所界定的保護範圍為準。