一種融合處理有效信息並動態捕捉及預警方法與流程
2023-06-12 19:04:26 2
本發明屬於圖像數據處理技術領域,尤其涉及一種融合處理有效信息並動態捕捉及預警方法。
背景技術:
目標物比如人臉識別的研究,起源於19世紀末法國人sirfranisgalton。以allen和parke為代表主要研究面部特徵;人機互動式識別及用幾何特徵參數來研究的以harmon和lesk為代表,以kaya和kobayashi為代表採用了統計識別方法;eyematic公司和我國清華大學研發了「人臉識別系統」,但對視頻監控模糊圖像的識別率不高,並且對目標物進行動態捕捉預警技術研究處於初始階段。
隨著視頻監控技術的不斷發展,我國目前視頻監控在智慧城市、數字城市、平安園區等各類項目得以廣泛應用。監控視頻已經成為公安部門進行案件偵查的重要依據和線索,視頻偵查已逐步成為繼刑偵,技偵,網偵之後的第四大偵查手段。在公安視頻監控中,模糊圖像的目標物檢測識別及動態捕捉預警技術具有直接、方便、快捷以及非侵犯性的特點,在刑事偵查、維護國家安全和人民生命財產安全以及在反恐、防恐中具有重要意義,極具研究價值和潛力。視頻監控於20世紀80年代正式在我國開始啟用,110指揮中心最早使用了視頻監控,用於監控城市的治安情況。隨著社會的發展,視頻監控已經廣泛應用於公安機關的治安、刑偵、交通管理、禁毒等多個職能部門具體業務工作中。但由於目前視頻監控模糊圖像的識別率不高,缺乏有效的信息技術支撐,在公安視頻偵查過程中仍然面臨圖像調取及格式不統一、視頻信息管理及協同難、效率不高等問題,針對公安視頻監控模糊圖像,對嫌疑人人臉或車輛進行檢測識別以及動態捕捉、預警等必要的視頻圖像處理技術,顯得尤為重要。
技術實現要素:
本發明的目的在於提供一種融合處理有效信息並動態捕捉及預警方法,旨在解決目前散焦模糊、噪聲及解析度低等問題。
本發明是這樣實現的,一種融合處理有效信息並動態捕捉及預警方法,所述融合處理有效信息並動態捕捉及預警方法為:通過圖像在不同尺度空間中的特性和圖像關鍵點的確立進行驗證及採用sift算法,採用稀疏冗餘模型算法進行圖像增強進過濾掉視頻圖像中無用的信息或幹擾信息、自動識別不同物體;分析抽取視頻中關鍵有用信息,快速、準確得定位事故現場,判斷監控畫面中的異常情況;最後融合處理有效信息並以最快和最佳的方式發出警報或觸發其它動作。
進一步,採用sift算法自動運動匹配、噪聲幹擾處理及超解析度方法,融合處理有效信息並提取相關特徵進行動態捕捉及預警。
進一步,採用稀疏冗餘模型算法進行圖像增強的方法包括:
首先,原圖像收到了加性高斯噪聲的汙染,則汙染後的圖像稱之為退化圖像,而圖像恢復的過程是退化圖像的逆過程,圖像的退化模型即加性高斯噪聲為:
g=hu+v;
g表示含噪圖像,hu表示原圖像,v表示噪聲;
則圖像的恢復模型表示為:
表示恢復圖像,g表示含噪圖像,hu表示原圖像;對恢復模型施加一個正則性約束;則恢復模型即變為變分模型:
表示恢復圖像,g表示含噪圖像,hu表示原圖像,r(u)即為正則項,該項是與圖像的本身性質有關,利用稀疏冗餘字典模型來描述r(u),λ表示約束參數。
進一步,利用sift算法進行特徵提取匹配方法為:建立尺度空間;檢測空間中的極值點;確定關鍵點的位置;確定關鍵點的方向;確定關鍵點描述子,最終實現特徵提取匹配。
進一步,通過圖像在不同尺度空間中的特性和圖像關鍵點的確立進行驗證的方法包括:
利用靠高斯模糊建立尺度空間,通過尺度參數不同的變化,觀察圖像在不同尺度空間中的特性,確立高斯卷積核為尺度空間內核唯一合理的線性核;
在一個圖像的尺度空間為:
l(x,y,σ)=g(x,y,σ)*i(x,y);
其中,l(x,y,σ)表示一個圖像的尺度空間,x和y表示圖像像素位置的橫坐標和縱坐標,σ為尺度參數,g(x,y,σ)表示一個變化尺度的高斯函數,i(x,y)表示原圖像,m,n表示高斯模板的維度,通過對尺度參數的改變,觀察圖像特性。
進一步,圖像關鍵點的確立方法為:
利用高斯差分函數:
d(x,y,σ)=(g(x,y,kσ)-g(x,y,σ))*i(x,y)=l(x,y,kσ)-l(x,y,σ);
其中,d(x,y,σ)表示高斯差分函數,是通過對兩個相鄰高斯函數(g(x,y,kσ),g(x,y,σ))進行相減與i(x,y)表示的原圖像相乘得到的,k表示常量,並取得該函數的極值點,從而初步測得關鍵點。l(x,y,kσ),l(x,y,σ)表示兩個相鄰的尺度空間。
本發明通過在視頻監控系統中增加智能分析功能模塊,通過改進視頻模糊圖像中目標物特徵點的提取及匹配算法,進而過濾掉視頻圖像中無用的信息或幹擾信息、自動識別不同物體;進一步分析抽取視頻中關鍵有用信息,快速、準確得定位事故現場,判斷監控畫面中的異常情況;最後融合處理有效信息並以最快和最佳的方式發出警報或觸發其它動作,從而有效進行事前預警、事中處理以及事後取證的全自動實時監控的智能系統。對公安視頻監控模糊圖像,採用模糊神經網絡和rs理論等,對目標物進行檢測識別,改進並提出新的算法,提高模糊圖像辨識率;融合處理有效信息並動態提取目標物特徵進行動態捕捉及預警,達到國家先進水平;視頻監控於20世紀80年代正式在我國開始啟用,110指揮中心最早使用了視頻監控,用於監控城市的治安情況。支持與前端視頻監控的對接,自動將有價值的視頻聯網採集到搜索視頻中,減少視頻採集的工作量;快速定位目標物出現區域,以便公安刑偵人員有針對性的加強警力部署或就近增加監控攝像頭等;通過動態捕捉視頻信息與自動預警機制建立關聯,提示目標物的出現以便公安刑偵人員及時採取措施,同時自動提取有關聯信息的視頻,便於偵查人員進行串併案分析及視頻比對分析處理,找到有價值的線索等;對不同的監控視頻格式自動識別其格式封裝和碼流,並以在線流媒體方式供偵查人員調閱,支持主流dvr,nvr廠家的視頻格式直接播放,也支持主流dv、手機所拍攝的視頻格式,實現多種視頻格式的在線播放、視頻快速查閱等。本發明解決了目前散焦模糊、噪聲及解析度低等問題。
附圖說明
圖1是本發明實施例提供的sift算法流程圖;
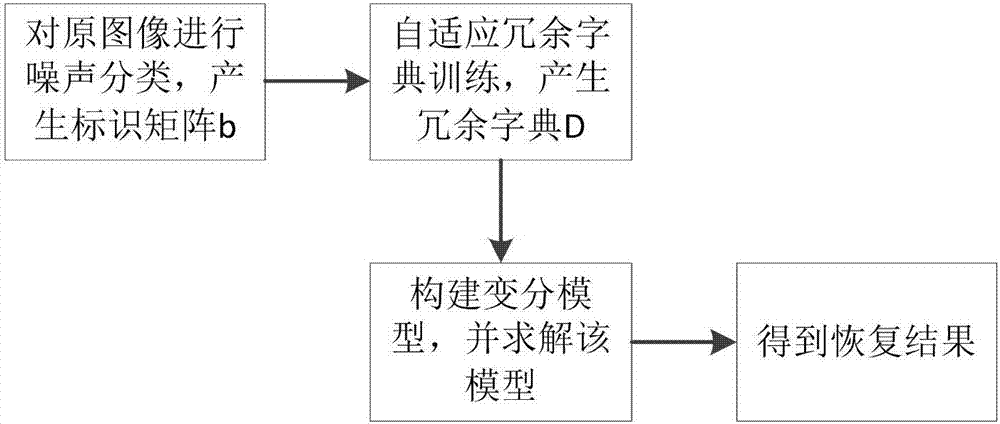
圖2是本發明實施例提供的整個恢復增強算法流程圖。
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,以下結合實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅僅用以解釋本發明,並不用於限定本發明。
下面結合附圖對本發明的應用原理作進一步描述。
本發明實施例提供的融合處理有效信息並動態捕捉及預警方法包括:通過圖像在不同尺度空間中的特性和圖像關鍵點的確立進行驗證及採用sift算法,採用稀疏冗餘模型算法進行圖像增強進過濾掉視頻圖像中無用的信息或幹擾信息、自動識別不同物體;分析抽取視頻中關鍵有用信息,快速、準確得定位事故現場,判斷監控畫面中的異常情況;最後融合處理有效信息並以最快和最佳的方式發出警報或觸發其它動作。
進一步,採用sift算法自動運動匹配、噪聲幹擾處理及超解析度方法,融合處理有效信息並提取相關特徵進行動態捕捉及預警。
進一步,採用稀疏冗餘模型算法進行圖像增強的方法中,對自然圖像中在小波基下呈現近零元素係數很多,而非零元素係數很少的變換係數向量的「稀疏性」,進行建立係數冗餘模型;具體包括:
首先,假定原圖像收到了加性高斯噪聲的汙染,則汙染後的圖像稱之為退化圖像,而圖像恢復的過程是退化圖像的逆過程,假定圖像的退化模型即加性高斯噪聲為:
g=hu+v;
g表示含噪圖像,hu表示原圖像,v表示噪聲;
則圖像的恢復模型表示為:
表示恢復圖像,g表示含噪圖像,hu表示原圖像;對恢復模型施加一個正則性約束;則恢復模型即變為變分模型:
表示恢復圖像,g表示含噪圖像,hu表示原圖像,r(u)即為正則項,該項是與圖像的本身性質有關,利用稀疏冗餘字典模型來描述r(u),λ表示約束參數。
進一步,超解析度為:
進一步,融合處理有效信息並提取相關特徵進行動態捕捉及預警方法為:
利用sift算法進行特徵提取匹配方法為:
進一步,驗證圖像特徵點的提取及匹配方法為:通過圖像在不同尺度空間中的特性和圖像關鍵點的確立進行驗證;
圖像在不同尺度空間中的特性:
利用靠高斯模糊建立尺度空間,通過尺度參數不同的變化,觀察圖像在不同尺度空間中的特性,確立高斯卷積核為尺度空間內核唯一合理的線性核,
在一個圖像的尺度空間為:
l(x,y,σ)=g(x,y,σ)*i(x,y);
其中,l(x,y,σ)表示一個圖像的尺度空間,x和y表示圖像像素位置的橫坐標和縱坐標,σ為尺度參數,g(x,y,σ)表示一個變化尺度的高斯函數,i(x,y)表示原圖像,m,n表示高斯模板的維度,通過對尺度參數的改變,觀察圖像特性。
圖像關鍵點的確立方法為:
利用高斯差分函數:
d(x,y,σ)=(g(x,y,kσ)-g(x,y,σ))*i(x,y)=l(x,y,kσ)-l(x,y,σ);
其中,d(x,y,σ)表示高斯差分函數,是通過對兩個相鄰高斯函數(g(x,y,kσ),g(x,y,σ))進行相減與i(x,y)表示的原圖像相乘得到的,k表示常量,並取得該函數的極值點,從而初步測得關鍵點。l(x,y,kσ),l(x,y,σ)表示兩個相鄰的尺度空間。
下面結合實施例對本發明的應用原理作進一步描述。
1、多目標跟蹤技術:
多目標跟蹤技術是智能視頻監控系統的核心技術,其分析涉及到傳計算機圖像處理、模式識別、人工智慧及自動控制等諸多相關領域的知識,而智能視頻監控能夠現實複雜場景中對運動目標的識別和跟蹤,檢測場景事件和判斷危險事件的發生,因此,應加大對多目標跟蹤技術的研究工作,提高視頻監控系統的智能化水平,改善監控系統的精準度,為社會的經濟發展和社會治安貢獻一份力量。
在現實複雜場景中,針對視頻監控圖像中的運動目標,本發明應用光流法和幀差法這兩種運動目標檢測技術對運動目標進行識別和跟蹤。
2、多目標跟蹤的實現:
(1)針對不同狀態採用不同的跟蹤方法:
具體實踐中,要分析多目標的運動狀態,對不同狀態實行不同的跟蹤方法,才能有效提高跟蹤的性能。卡爾曼濾波與矩形跟蹤法是常見的跟蹤方法。卡爾曼濾波通過建立目標的運動模型和運動軌跡,判斷目標的下一位置,根據位置特徵進行跟蹤,這種方法的準確度隨著模型的準確度而變化。矩形跟蹤運用運動時獲得的矩形特徵完成對目標的跟蹤。它適用於簡單的情況下判斷目標的產生和消失,但無法進行深入的分析,也就不能進行穩定跟蹤。
(2)卡爾曼濾波法與矩形跟蹤法結合:
因為多目標圖像在空間領域和時間領域都變化的特性不同,以往用於單視角的卡爾曼濾波法和矩形跟蹤法都不能滿足多目標同時處於運動場景時的跟蹤,如果充分利用兩種方法的優點,將它們有效結合,分離目標位置、面積等特徵,通過構建特徵識別矩陣分析目標運動狀態,再對不同狀態實施相應的跟蹤辦法。
(3)構建新的特徵辨識矩陣:
多目標跟蹤一直是智能監控的難點,首先,因為在多個目標都存在運動時,目標之間相互產生幹擾,嚴重影響區域檢測的精度;其次,在時間上它們相互關聯,多目標間有可能有對應的因果關係,大大增加複雜度;再次,多個目標在同一時刻運動時,必須採用和運動狀態相對應的提取處理辦法。所以,多目標跟蹤不僅和運動分離精度有關係,也和目標特徵選擇、狀態分析緊密相連。
要實現對目標各種運動狀態的實時監測,包括新目標出現時、目標保留在場景內但沒有與其他目標相互幹擾、目標出現分裂現象、目標出現融合現象以及目標突然消失等情況,構建特徵辨識矩陣,充分利用目標的特徵與目前目標所處的區域特點構建新矩陣,利用矩形跟蹤法判別目標是否產生、是否消失,注意分析目標特徵,預判目標狀態空間,判斷目標的運動狀態。
判斷目標所處狀態,將目標分為新目標、目標的融合與目標的消失,當新目標出現時,立刻構建新目標的信息;當目標出現分裂時,分析產生分裂的原因,跟蹤分裂;當不同目標出現相互融合時,對融合後的目標進行融合處理;當跟蹤的目標消失時,首先判斷是否真消失,如果真消失,再刪除原有的數據信息等。
3、提出一種新型的多視角的監控跟蹤方法:
針對運動目標的陰影檢測、多目標跟蹤、克服遮擋目標的方法以及多視角下監控目標的相互傳遞。首先,對運動目標的陰影光照和顏色特徵進行分析探討,改進原有的檢測辦法;其次,探討研究先利用目標的特點,辨別運動狀態,再處理不同跟蹤裡的不同狀態達到跟蹤多目標;再次,構建符合目標顏色的模型,運用顏色的特點克服對目標的遮擋。最後,分析多視角的監控系統應用需求,設計智能監控框架,分析一種新型的多視角的監控跟蹤辦法,實現不同視角的信息傳遞。
4、圖像增強與匹配技術:
(1)採用稀疏冗餘模型算法進行圖像增強:
由於自然圖像會在小波基下呈現出一種「近零元素係數很多,而非零元素係數很少」的特點,這種特點為變換係數向量的「稀疏性」。正是由於這種特性的存在,可以對其進行係數冗餘模型的建立。
首先,假定原圖像收到了加性高斯噪聲的汙染,則汙染後的圖像可稱之為退化圖像,而圖像恢復的過程其實就是退化圖像的逆過程。假定圖像的退化模型(加性高斯噪聲)為:
g=hu+v;
g表示含噪圖像,hu表示原圖像,v表示噪聲;
則圖像的恢復模型可表示為:
表示恢復圖像,g表示含噪圖像,hu表示原圖像;但由於噪聲的幹擾,並不能得到合適且唯一的解,要想使其獲得一個良好穩定的值,一個經典的解決方法就是對恢復模型施加一個正則性約束;則恢復模型即變為變分模型:
表示恢復圖像,g表示含噪圖像,hu表示原圖像,r(u)即為正則項,該項是與圖像的本身性質有關,利用稀疏冗餘字典模型來描述r(u),λ表示約束參數。
整個恢復增強算法可以總結為如圖2流程圖:
(2)利用sift算法進行特徵提取匹配
通過上述的流程,得到了一個較好的恢復圖像,下面針對該恢復圖像進行匹配,由於在視頻拍攝過程中,往往會由於方向、角度等問題產生一定量的形變,針對這個問題,採用微分不變量,即基於局部考慮的特徵提取算法(sift匹配算法),該算法注重局部細節,能夠很好的對抗位置移動,朝向改變甚至是噪聲。
sift算法簡易流程圖如圖1。
5、圖像在不同尺度空間中的特性:
尺度空間的建立需要靠高斯模糊來實現,通過尺度參數不同的變化,觀察圖像在不同尺度空間中的特性。尺度空間內核的確立就成了關鍵問題,而實驗證明,高斯卷積核是尺度空間內核唯一合理的線性核。
在一個圖像的尺度空間
l(x,y,σ)=g(x,y,σ)*i(x,y);
其中,l(x,y,σ)表示一個圖像的尺度空間,x和y表示圖像像素位置的橫坐標和縱坐標,σ為尺度參數,g(x,y,σ)表示一個變化尺度的高斯函數,i(x,y)表示原圖像,m,n表示高斯模板的維度,通過對尺度參數的改變,觀察圖像特性。
6、圖像關鍵點的確立
利用高斯差分函數:
d(x,y,σ)=(g(x,y,kσ)-g(x,y,σ))*i(x,y)=l(x,y,kσ)-l(x,y,σ);
其中,d(x,y,σ)表示高斯差分函數,是通過對兩個相鄰高斯函數(g(x,y,kσ),g(x,y,σ))進行相減與i(x,y)表示的原圖像相乘得到的,k表示常量,並取得該函數的極值點,從而初步測得關鍵點。l(x,y,kσ),l(x,y,σ)表示兩個相鄰的尺度空間。
7、驗證了圖像特徵點的提取及匹配
sift算法的關鍵問題在於尺度空間的建立,關鍵點位置方向的確立和關鍵點描述子的確立。當這些問題得到解決後,就可以通過實驗來驗證圖像特徵點的提取及匹配情況,
8、結論
本發明建立了視頻模糊圖像中多目標跟蹤算法相關的技術方法,提出了模糊圖像中目標物的特徵點的提取及匹配算法並進行了一定的實驗分析。
以上所述僅為本發明的較佳實施例而已,並不用以限制本發明,凡在本發明的精神和原則之內所作的任何修改、等同替換和改進等,均應包含在本發明的保護範圍之內。