基於卷積神經網絡的視頻編碼後置濾波方法與流程
2023-06-01 22:54:26 2
本發明涉及計算機視覺和視頻編碼領域,具體涉及一種基於卷積神經網絡的視頻編碼後置濾波方法。
背景技術:
隨著科技的發展和各種視頻顯示設備的豐富,視頻已經日益成為人們生活中不可缺少的部分,在各個領域發揮著十分重要的作用。過去的幾十年來見證了視頻解析度與顯示設備屏幕的巨大發展,而超高解析度的視頻會產生龐大的數據量,這會對網絡帶寬產生極大的負擔。因此,需要高效的視頻編碼和傳輸技術來保證用戶觀看視頻的體驗,同時儘可能地降低視頻的數據量,為網絡帶寬減負。鑑於此,研究人員在幾十年來不斷研究高效的視頻編碼方法。視頻編碼技術,主要是通過移除視頻中的冗餘信息來減少視頻的數據量以達到有效地儲存和傳輸大量視頻數據,其旨在儘量保持原視頻質量的前提下,以更低的碼率壓縮視頻。
然而,當前的視頻編碼標準主要都是基於塊的混合視頻編碼技術,在這種編碼框架下,基於塊的幀內/幀間預測、轉換以及粗量化都會導致視頻質量的下降,尤其是在低碼率的情況下。因此,減少視頻編碼中的失真成為當前視頻編碼領域的研究熱點之一。雖然,在當前視頻編碼標準中也採取了一些算法來減少塊效應和提高主觀質量,但是其效果還不夠理想,處理後的視頻仍存在明顯的塊效應和邊緣模糊,細節丟失仍比較嚴重。
技術實現要素:
本發明的主要目的在於利用卷積神經網絡對非線性變換的強擬合能力,提出一種基於卷積神經網絡的視頻編碼後置濾波方法,該方法建立起有損視頻幀到無損視頻幀的映射,從而近似得到視頻編碼中失真過程的逆變換,來達到減少失真的目的。
本發明為達上述目的所提供的技術方案如下:
一種基於卷積神經網絡的視頻編碼後置濾波方法,包括卷積神經網絡模型的訓練步驟以及後置濾波處理步驟,其中:
所述訓練步驟包括s1至s4:
s1、設置視頻壓縮的量化參數為20至51,對原始視頻進行編碼壓縮,得到壓縮視頻;
s2、對所述壓縮視頻和所述原始視頻進行幀的提取,得到多個幀對,每個所述幀對包含一壓縮視頻幀和一原始視頻幀;
s3、將步驟s2提取的幀對按照幀類型和量化參數的不同劃分為多個組;
s4、搭建卷積神經網絡框架並初始化網絡參數,使用步驟s3劃分的組分別對神經網絡進行訓練,得到對應於不同量化參數和幀類型的多個神經網絡模型;
所述後置濾波處理步驟包括s5和s6:
s5、將步驟s4得到的多個神經網絡模型嵌入至視頻編碼器的後置濾波環節;
s6、對待處理的原始視頻執行步驟s1和s2得到待處理幀對,並依據待處理幀對的量化參數和幀類型選擇對應的神經網絡模型進行濾波處理。
量化參數和幀類型的不同導致它們的失真性質也不同,本發明在訓練和實際處理過程中都是提取原始視頻和壓縮視頻組成的幀對,以此建立起有損視頻幀和無損視頻幀的映射;並通過訓練出針對不同量化參數和幀類型的神經網絡模型嵌入到編碼器中後置濾波環節進行濾波處理,充分考慮量化參數和幀類型對失真程度的影響,採用本發明的方法先判別幀的量化參數和幀類型,再選擇量化參數和幀類型都與之對應的神經網絡模型來進行濾波,從而可以有效抑制失真。
附圖說明
圖1是本發明提供的基於卷積神經網絡的視頻編碼後置濾波方法的流程圖;
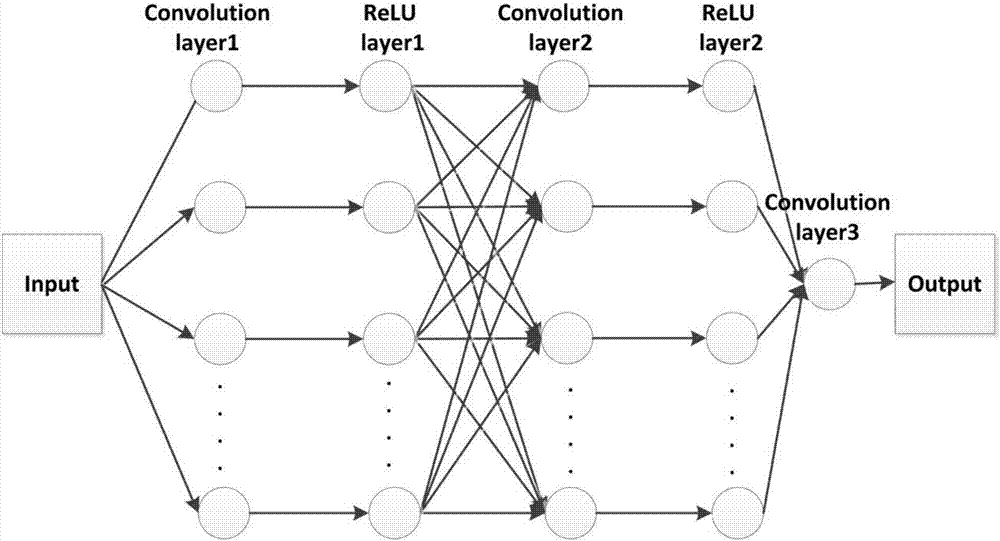
圖2是卷積神經網絡框架圖;
圖3是卷積神經網絡的訓練過程示意圖。
具體實施方式
下面結合附圖和具體的實施方式對本發明作進一步說明。
本發明利用卷積神經網絡強大的非線性擬合能力,結合視頻編碼的特性,充分分析視頻編碼壓縮過程中造成失真的原因,提出了基於卷積神經網絡且相關於量化參數和幀類型的視頻編碼後置濾波方法,建立有損視頻幀和無損視頻幀之間的映射,訓練得到不同量化參數(簡稱qp)以及不同幀類型下的卷積神經網絡模型,用於在編碼器的後置濾波環節針對不同量化參數和幀類型的幀進行濾波處理,可以有效抑制失真。
在混合視頻編碼框架中,幀類型主要有i幀、p幀和b幀,其中:
i幀採用的是幀內預測模式,又稱之為幀內編碼幀(intrapicture),i幀通常是每一個畫面組(gop)的起始幀,它不依賴於前後幀的信息,因此在播放中可以作為隨機播放的切入點。對於幀內預測模式,在解碼端,是基於解碼出的相鄰的左邊的塊和上邊的塊,使用算法來進行當前塊的預測,而後再加上殘差數據來重建圖像的原始信息,該殘差數據由解碼值和預測值相減而得;在編碼端,需要使用相同的幀內預測,因為預測值與原始圖像數據較相似,所以要傳輸的剩餘數據的能量是非常低的,從而能夠實現碼流的壓縮。
p幀和b幀採用幀間預測模式,p幀即前向預測幀(predictive-frame),參考前面的i幀或者b幀來去除時間上的冗餘信息,實現高效壓縮。b幀即雙向預測內插編碼幀,又稱(bi-directionalinterpolatedpredictionframe),其需要參考前後的視頻幀,利用兩邊的幀與b幀的相似性去除冗餘信息。幀間預測主要是基於相鄰幀之間較高的相似度,利用已知幀的信息來重建當前幀,通常使用的方法是通過運動估計和補償的方式來進行幀間預測。尋找最匹配的宏塊的方法即運動估計法,該方法是針對當前宏塊,先在前一幀尋找最相似的宏塊(即匹配塊),對它們求差,產生很多零值,進行與幀內相似的編碼流程就能節省可觀的比特數。
在混合視頻編碼框架中,不同幀類型的視頻幀,其編碼方法是不一樣的,正因如此,不同幀類型的視頻幀其失真性質也不同。由於i幀是相對獨立的,因此其失真的原因主要為量化過程和dct變換(離散餘弦變換)過程,量化過程本質上是將多數值映射到少數值的過程,相對地,反量化過程即通過少數值來恢復多數值的過程,其恢復不可避免會存在數據誤差,因此視頻幀會出現一些由量化損失造成的高頻噪聲。產生p幀和b幀的主要方式是通過幀間預測的方式,這兩種幀預測的源泉都是來自於i幀,因此i幀本身具有的失真性質也會傳播給p幀和b幀;另外,運動估計和補償的過程中,也存在導致失真的因素。比如,在幀間預測的運動補償環節,當前幀的相鄰兩個塊的預測塊有可能並非來自於同一參考幀的相鄰兩個塊的預測,有可能是自於不同幀中的兩個塊的預測。也就是說,相鄰塊參考的那兩個塊的邊緣本身便不具備連續性,這也將導致一定的塊效應現象,從而造成失真。
視頻編碼的基本原理就是利用視頻序列所具有的相關性來壓縮冗餘信息,實現視頻序列的高效傳輸。其中視頻序列所具有的相關性主要分為空間和時間相關性,空間上的相關性主要體現在同一視頻幀相鄰像素點之間存在著相關性,時間上的相關性主要體現在時間上相鄰的幀具有較高的相似度。因此,在混合視頻編碼框架中,每一視頻幀的產生方式,不是幀內預測的結果,就是幀間預測的結果。不同類型的幀其產生機制也不相同,意味著在基於卷積神經網絡的視頻編碼質量增強算法中需要將幀類型也考慮進來,以取得更好的效果。
基於前述的原理,本發明具體實施方式提出了基於卷積神經網絡的視頻編碼後置濾波方法,該方法包括卷積神經網絡模型的訓練步驟以及後置濾波處理步驟,如圖1所示:
所述訓練步驟包括s1至s4:
s1、設置視頻壓縮的量化參數為20至51,對原始視頻進行編碼壓縮,得到壓縮視頻;
s2、對所述壓縮視頻和所述原始視頻進行幀的提取,得到多個幀對,每個所述幀對包含一壓縮視頻幀和一原始視頻幀;
s3、將步驟s2提取的幀對按照幀類型和量化參數的不同劃分為多個組;
s4、搭建卷積神經網絡框架並初始化網絡參數,使用步驟s3劃分的組分別對神經網絡進行訓練,得到對應於不同量化參數和幀類型的多個神經網絡模型;
所述後置濾波處理步驟包括s5和s6:
s5、將步驟s4得到的多個神經網絡模型嵌入至視頻編碼器的後置濾波環節;
s6、對待處理的原始視頻執行步驟s1和s2得到待處理幀對,並依據待處理幀對的量化參數和幀類型選擇對應的神經網絡模型進行濾波處理。
本發明的方法首先需要訓練神經網絡,再用訓練好的神經網絡模型進行濾波處理。下面以一種具體的實施例來說明本發明提供的上述基於卷積神經網絡的視頻編碼後置濾波方法。
選取用於訓練的原始視頻,進行編碼壓縮,壓縮時的量化參數qp設置為20至51(即連續的整數20、21、22、23、24、……、50、51),得到不同qp下的壓縮視頻。優選地,可以採用常用的jm10和/或hm12視頻編碼標準軟體對原始視頻進行編碼壓縮。對原始視頻和對應的壓縮視頻進行幀提取,得到很多個幀對,幀對可以表示為「原始視頻幀-壓縮視頻幀」,即每個幀對包含一原始視頻幀及一對應的壓縮視頻幀。將得到的所有幀對按照幀類型和量化參數qp的不同劃分為多個組,具體的劃分過程例如是:將所有幀對先按照qp的不同(32)進行劃分,再對每個qp下的幀對按照幀類型分為i幀、p幀和b幀,從而得到所述的多個組(在本例中,得到),每個組內的幀對具有相同的幀類型和量化參數qp。
待訓練的神經網絡的架構包括卷積層和relu層,在一種具體的實施例中,搭建的神經網絡的架構可參考圖2,包括3個卷積層(圖中的convolutionlayer1、convolutionlayer2、convolutionlayer3)和2個relu層(圖中的relulayer1和relulayer2),卷積層和relu層依次交替連接,例如,輸入層input之後連接卷積層1(convolutionlayer1),卷積層1的輸出連接relu層1(relulayer1),relu層1的輸出連接卷積層2(convolutionlayer2),卷積層2(convolutionlayer2)的輸出連接relu層2(relulayer2),relu層2的輸出連接卷積層3(convolutionlayer3),卷積層3的輸出連接輸出層output。需要說明,圖2所示的卷積神經網絡僅僅是示例性的,不構成對本發明的限制。對圖2所示的神經網絡中,設置卷積層1、2、3的濾波核大小(濾波核即卷積核)分別為9、1、5,神經元個數分別為64、32、1;relu層的神經元個數與和relu層連接的上一層卷積層的神經元個數保持一致。
接著,採用前述得到的多組幀對分別單獨地去訓練上述搭建好的例如圖2所示的神經網絡。首先,將每個組內的幀對依據解析度和場景來劃分訓練集、驗證集和測試集,例如將qp為20且幀類型為i幀的所有幀對劃分為訓練集、驗證集和測試集,將qp為20且幀類型為p幀的所有幀對劃分為訓練集、驗證集和測試集,其中,測試集內的幀對具有解析度和場景多樣的特點。其次,將所有的幀對按照一定的像素間距截取圖像塊,得到「原始幀圖像塊-壓縮幀圖像塊」的圖像塊對,作為訓練過程中神經網絡的輸入。
以qp為20、類型為i幀的一組幀對為例來說明訓練神經網絡的過程,例如,對該組內的所有幀對中的幀按28個像素為間距來截取圖像塊,例如每個圖像塊的大小為33×33,在訓練過程中,所有的卷積層都不使用padding操作來避免邊界效應(因為使用padding相當於人工複製了邊界的像素點,從而擴大了圖像的大小,邊界處的信息就不準確了),為了計算輸出圖像塊和原始圖像塊之間的損失值,本發明將原始圖像塊也裁成跟輸出圖像塊的大小一致。接著,將截取的所有圖像塊隨機均分為多個批次,將一個批次的圖像塊依次輸入神經網絡,完成一個批次則為一次迭代,有多少個批次即進行多少次迭代,在迭代過程中利用隨機梯度下降法進行後向傳播,更新網絡參數,來不斷最小化損失函數。每迭代一定次數則採用驗證集來校正訓練出的網絡參數,以防止過擬合。
具體的訓練過程如圖3所示,卷積層的神經元對輸入的圖像塊的操作表示為其中n表示輸入圖像塊的數量,wi表示第i個卷積核,xi表示第i個輸入圖像塊,b表示偏置係數,*表示卷積操作,圖像塊用像素矩陣來表示;relu層的神經元對圖像塊的操作表示為m=max(n,0),其中n和m分別表示輸入圖像塊和輸出圖像塊的像素值。
待參數收斂時,完成訓練,得到qp為20、類型為i幀的該組幀對所對應的神經網絡模型,嵌入到編碼器後置濾波環節作為濾波用。同理地,qp為20、類型為p幀的一組幀對也採用上述方法來訓練神經網絡,得到對應於qp為20、類型為p幀的該組幀對的神經網絡模型;其它qp值下的幀對也採用同樣的方法來訓練神經網絡。
假設訓練過程中所採用的壓縮視頻有jm10和hm12兩種軟體,則兩種軟體壓縮得到的壓縮視頻應當分開進行處理,分開來訓練。從而,經過上述的訓練方法,則可以得到以下的多個神經網絡模型:
jm10標準軟體編碼下對應qp為20至51的32個不同的i幀模型,jm10標準軟體編碼下對應qp為20至51的32個不同的p幀模型,jm10標準軟體編碼下對應qp為20至51的32個不同的b幀模型,hm12標準軟體編碼下對應qp為20至51的32個不同的i幀模型,hm12標準軟體編碼下對應qp為20至51的32個不同的p幀模型,hm12標準軟體編碼下對應qp為20至51的32個不同的b幀模型。
在實際使用過程中,對待處理的原始視頻經編碼器進行編碼壓縮和幀對提取之後,對得到的幀對進行量化參數和幀類型的判斷,例如判斷得知當前待處理的幀對的qp為23、類型為b幀,則選擇屬於qp為23、類型為b幀的圖像塊訓練得到的神經網絡模型來進行後置濾波處理。在優選的實施例中,可將採用的編碼軟體也考慮進來,即在訓練時還根據編碼軟體的不同分別進行訓練(正如上一段所描述的),從而在實際使用時還考慮先分辨是何種編碼軟體壓縮編碼得到的,再考慮量化參數和幀類型來選擇對應的神經網絡模型進行濾波處理。
以上內容是結合具體的優選實施方式對本發明所作的進一步詳細說明,不能認定本發明的具體實施只局限於這些說明。對於本發明所屬技術領域的技術人員來說,在不脫離本發明構思的前提下,還可以做出若干等同替代或明顯變型,而且性能或用途相同,都應當視為屬於本發明的保護範圍。