一種基於遊客移動信令數據的景區實時動態客流量統計方法與流程
2023-06-20 08:29:06 1
本發明屬於通信技術領域,特別是移動網際網路及計算機通信領域,涉及一種基於遊客移動信令數據的景區實時動態客流量統計方法。
背景技術:
近年來,以雲計算、物聯網、移動通信等為代表的新一代信息技術取得了重大突破,開始廣泛應用於各行各業。物聯網技術突破了網際網路的「線上」局限,把虛擬世界與現實世界聯成一體;移動通信技術實現了實時數據在系統之間、遠程設備之間的無線連接,為無處不在的全程服務提供了條件;雲計算解決了網際網路發展所帶來的巨量數據存儲與處理問題。這些技術的普及和應用,為旅遊信息化的發展提供了有力支撐,將人類社會帶入了一個以「pb」(1024tb)為單位的新階段,大數據時代應運而生。大數據不僅更新了旅遊信息化所需的技術,更從觀念和思維上革新了人類的認識,實現思維、商業、管理上的變革。
隨著中國經濟的發展,人們收入的增長以及對生活品質的追求,旅遊業在國內發展得很快,得到了國家的大力支持,旅遊業進入爆發性的增長階段,成為新的支柱產業。旅遊已經成為人們生活方式的重要組成部分,但與此同時引發了一些景區管理的安全隱患,景區超流量接待遊客已不是罕見現象。2015年跨年夜上海發生的踩踏事件,暴露出了我國在大量遊客管理方面能力的匱乏。事後國家旅遊局對景區安全管理更加嚴格,尤其是在景區客流量控制上。因此,無論是從國家還是旅遊局層面來講,景區需要一套針對景區遊客的安全監控方案。
傳統的景區動態客流量統計方法在實時性方面體現的比較差,統計景區客流量是通過從傳統的資料庫中分析提取。而傳統資料庫具有效率不夠高、可讀性不高、數據時間性不足等缺點,導致分析傳統資料庫中的海量遊客信令數據會造成查詢速度特別慢、統計速度特別慢等缺點。所以傳統資料庫不適合用於存儲分析海量數據,不利於應對短時間內因遊客劇增導致擁堵、踩踏等引發的安全事故。
flume是一個分布式、可靠、和高可用的海量日誌聚合的系統,支持在日誌系統中定製各類數據發送方,用於收集數據;同時,flume提供對數據進行簡單處理,並寫到各種數據接受方(可定製)的能力。
kafka是一種高吞吐量的分布式發布訂閱消息系統,它可以處理消費者規模的網站中的所有動作流數據。kafka可實時記錄從數據採集工具flume中收集的數據,並作為消息緩衝組件為上遊實時計算框架提供可靠數據支撐。
spark是一個分布式的內存計算框架,其特點是能處理大規模數據,計算速度快。spark需要集成hadoop的分布式文件系統才能運作,它延續了hadoop的mapreduce計算模型,相比之下spark的計算過程保持在內存中,減少了硬碟讀寫,能夠將多個操作進行合併後計算,因此提升了計算速度。spark必須搭在hadoop集群上,它的數據來源是hdfs,本質上是yarn上的一個計算框架,像mapreduce一樣。spark核心部分分為rdd。sparksql、sparkstreaming、mllib、graphx、sparkr等核心組件解決了很多的大數據問題,其完美的框架日受歡迎。其相應的生態環境包括zepplin等可視化方面,正日益壯大。spark讀寫過程不像hadoop溢出寫入磁碟,都是基於內存,因此速度很快。另外dag作業調度系統的寬窄依賴讓spark速度提高。
本方法採用快速的海量數據處理框架和相應的分析算法實時監控景區內的客流情況,以便景區和當地人民政府能及時採取疏導、分流等措施,從而達到景區安全管理的目的。
技術實現要素:
有鑑於此,本發明的目的在於提供一種基於遊客移動信令數據的景區實時動態客流量統計方法,該方法針對傳統的景區動態客流量統計方法在實時性方面體現的比較差、海量數據不適合存儲在傳統資料庫中進行分析等問題,通過實時監控景區內的客流量,有助於應對短時間內景區遊客劇增情況,便於景區和當地政府及時採取疏導、分流等措施,從而達到景區安全管理的目的,同時更大程度地提升遊客對景區的體驗度。
為達到上述目的,本發明提供如下技術方案:
一種基於遊客移動信令數據的景區實時動態客流量統計方法,該方法包括以下步驟:
s1:lte-a空口監測儀實時採集景區內遊客的信令數據,並將數據保存至遠程文件中,以一分鐘的時間粒度保存一個信令數據文件;
s2:通過flume組件監測遠程文件是否有文件更新,若有更新,將文件逐條記錄收集;
s3:flume組件將更新的最新文件中的數據逐條發送至kafka數據緩衝組件中進行數據緩衝,直至更新後的最新文件中的數據全部發送完畢,將該數據流打包成批數據作為spark的數據輸入流;
s4:在spark分布式的內存計算框架中,通過比較前一分鐘和後一分鐘遊客所在基站的位置來實時統計景區內遊客總量;
s5:將每分鐘實時統計的客流量結果進行輸出並存儲,如存儲到mysql/oracle資料庫中。
進一步,在步驟s1中,所述lte-a空口監測儀採集景區內遊客的移動信令數據,包括imsi庫、信令發生的時間、所在的基站位置信息,並將移動信令數據以一分鐘的時間粒度保存一個信令數據文件。
進一步,該方法還包括以下步驟:s6:將存入到資料庫的實時結果輸出至應用展示層中,以可視化界面的形式方便用戶查看。
本發明的有益效果在於:
1)本發明將景區內遊客的海量實時移動信令數據存儲在遠程文件系統中,為數據預處理和數據分析處理模塊提供數據準備,把數據分析後的結果存儲到傳統的資料庫中,從而大大減輕了傳統資料庫直接存儲海量實時數據的壓力。
2)本發明基於hadoop平臺,在spark分布式內存計算框架中進行海量的數據運算分析,把在傳統資料庫中進行數據運算的壓力轉移到高效快速的spark分布式內存計算框架中,從而保證了景區內對遊客的實時監控。
3)本發明可用於分析景區內精細化的客流特徵,通過重複利用kafka緩衝的批數據處理流,在spark中生成多個rdd變換,每個rdd變換用於一種客流特徵的分析,形成各自的業務邏輯。
附圖說明
為了使本發明的目的、技術方案和有益效果更加清楚,本發明提供如下附圖進行說明:
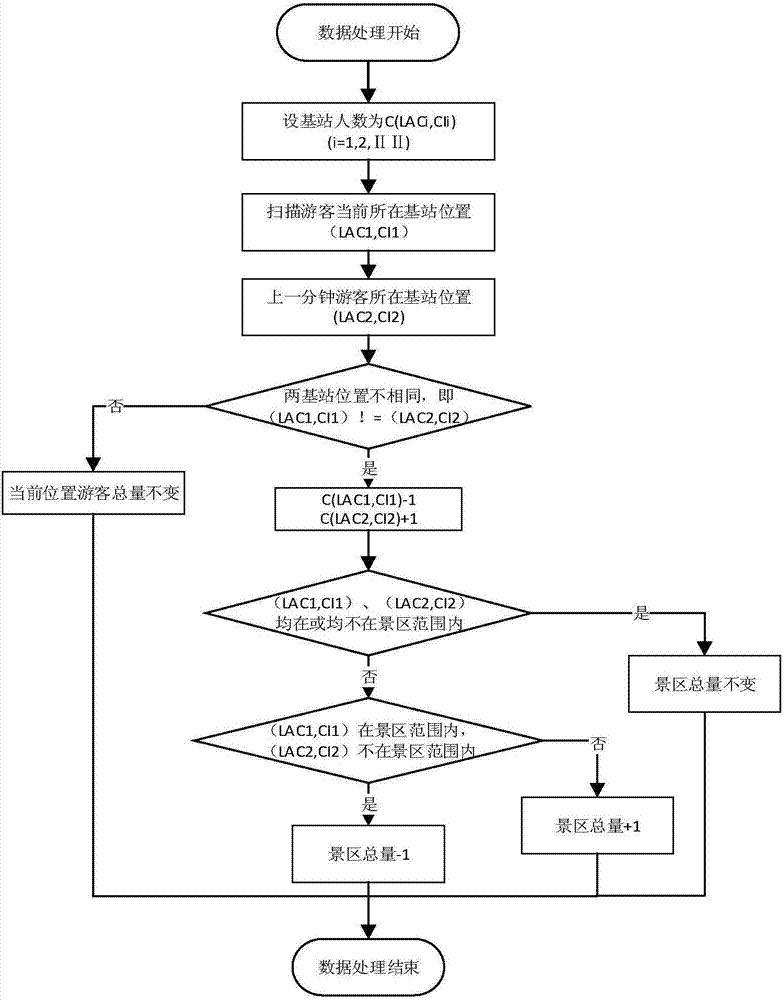
圖1為本發明中的數據預處理流程圖;
圖2為本發明中數據實時計算處理流程圖;
圖3為本發明中精細化的客流特徵分析流程框圖;
圖4為本發明中數據實時計算處理後數據表的設計。
具體實施方式
下面將結合附圖,對本發明的優選實施例進行詳細的描述。
圖1為本發明中的數據預處理流程圖,圖2為本發明中數據實時計算處理流程圖,如圖所示,本發明提供了一種基於遊客移動信令數據的景區實時動態客流量統計方法,該方法包括如下步驟:
步驟1:lte-a空口監測儀實時採集景區內遊客的信令數據imsi號和(lac,ci)(移動終端imsi表示遊客在景區的唯一標識,移動終端所在的基站位置(lac,ci)表示遊客所在的位置),並將數據保存至遠程的文件中,以一分鐘的時間粒度保存一個信令數據文件。
步驟2:通過flume組件監測遠程文件是否有文件更新,若有更新,將文件逐條記錄收集。
步驟3:flume組件將更新的最新文件中的數據逐條發送至kafka數據緩衝組件中進行數據緩衝,直至更新後的最新文件中的數據全部發送完畢,將該數據流打包成批數據作為spark的數據輸入流。
步驟4:在spark分布式的內存計算框架中,通過比較前一分鐘和後一分鐘遊客所在基站的位置來實時統計景區內遊客總量。當前景區遊客總量為各個基站下遊客總量之和。當遊客從景區內一個基站到另一個基站,景區總量不變;當遊客前後一分鐘都在該景區內的同一個基站範圍內,景區總量不變;當遊客從景區外的一個基站到景區內的一個基站,景區總量+1;當遊客從景區內的一個基站到景區外的一個基站,景區總量-1。
步驟5:將每分鐘實時統計的客流量結果進行輸出並存儲,如存儲到mysql/oracle資料庫中。資料庫中表的設計結構如圖4所示。
步驟6:將存入到資料庫的實時結果輸出至應用展示層中。
本發明可用於分析景區內精細化的客流特徵,通過重複利用kafka緩衝的批數據處理流,在spark中生成多個rdd變換,每個rdd變換用於一種客流特徵的分析,形成各自的業務邏輯。如圖3所示。
最後說明的是,以上優選實施例僅用以說明本發明的技術方案而非限制,儘管通過上述優選實施例已經對本發明進行了詳細的描述,但本領域技術人員應當理解,可以在形式上和細節上對其作出各種各樣的改變,而不偏離本發明權利要求書所限定的範圍。