基於決策樹和SVM混合模型的中文句型分類方法與流程
2023-06-10 11:54:56 2
本發明涉及一種文本分類,特別涉及一種基於決策樹和svm(支持向量機)混合模型的中文句型分類方法。
背景技術:
現今時代網際網路發展迅速,信息急劇膨脹,充斥著人們的生活。微博、微信、論壇等信息發布和社交網絡平臺,在各個方面滲透著人們的生活,已然成為人們獲取信息、交流互動、發表觀點的平臺。網際網路上的中文文本信息傳播量大、類型多樣、更新快,隨著情報加工的深入,對文本數據精確判斷的要求也越來越高。在分析中文句子時,不同句型即使使用類似的關鍵詞,表達的含義仍有很大差別,特別是在情感判斷中,更需要精準判斷關鍵詞的作用。因此,通過精準的句法分析對這些中文文本進行句型判別成為一個熱門的研究話題。上述問題是一個文本多分類問題,即判斷句子是屬於疑問句、否定句,還是屬於其他類別。問題看似簡單,實際上卻存在許多難點。第一,中文的語法靈活多變,句法複雜多樣;句子中不僅包含了多種句法成分,而且不同句法成分的搭配生成了各種各樣的語義,導致句子難以統一歸納分析。第二,句子中的某些詞語對句子類型起到了關鍵作用,但這些關鍵詞在不同語境下有不同語義,發揮著不同的作用,造成了一詞多義的難題;第三,來自微博、論壇等社交網絡平臺的中文文本,絕大部分都是口語化的句子;這些句子有的缺少完整的句法成分,有的存在明顯的語法錯誤,有的甚至不符合口語化的使用規律,導致難以按照正確的語法規則來分析,極大地增加了挑戰性。
當前常用的分類算法主要有:
決策樹:決策樹是用於分類和預測的主要技術之一,決策樹學習是以實例為基礎的歸納學習算法,它著眼於從一組無次序、無規則的實例中推理出以決策樹表示的分類規則。構造決策樹的目的是找出屬性和類別間的關係,用它來預測將來未知類別的記錄的類別。它採用自頂向下的遞歸方式,在決策樹的內部節點進行屬性的比較,並根據不同屬性值判斷從該節點向下的分支,在決策樹的葉節點得到結論。主要的決策樹算法有id3、c4.5(c5.0)、cart、public、sliq和sprint算法等。它們在選擇測試屬性採用的技術、生成的決策樹的結構、剪枝的方法以及時刻,能否處理大數據集等方面都有各自的不同之處。
貝葉斯算法:貝葉斯(bayes)分類算法是一類利用概率統計知識進行分類的算法,如樸素貝葉斯(naivebayes)算法。這些算法主要利用bayes定理來預測一個未知類別的樣本屬於各個類別的可能性,選擇其中可能性最大的一個類別作為該樣本的最終類別。由於貝葉斯定理的成立本身需要一個很強的條件獨立性假設前提,而此假設在實際情況中經常是不成立的,因而其分類準確性就會下降。為此就出現了許多降低獨立性假設的貝葉斯分類算法,如tan(treeaugmentednaivebayes)算法,它是在貝葉斯網絡結構的基礎上增加屬性對之間的關聯來實現的。
k-近鄰算法:k-近鄰(knn,k-nearestneighbors)算法是一種基於實例的分類方法。該方法就是找出與未知樣本x距離最近的k個訓練樣本,看這k個樣本中多數屬於哪一類,就把x歸為那一類。k-近鄰方法是一種懶惰學習方法,它存放樣本,直到需要分類時才進行分類,如果樣本集比較複雜,可能會導致很大的計算開銷,因此無法應用到實時性很強的場合。
支持向量機:支持向量機(svm,supportvectormachine)是vapnik根據統計學習理論提出的一種新的學習方法,它的最大特點是根據結構風險最小化準則,以最大化分類間隔構造最優分類超平面來提高學習機的泛化能力,較好地解決了非線性、高維數、局部極小點等問題。對於分類問題,svm算法根據區域中的樣本計算該區域的決策曲面,由此確定該區域中未知樣本的類別。
技術實現要素:
本發明的目的在於克服現有技術的缺點與不足,提供一種基於決策樹和svm混合模型的中文句型分類方法,該方法將首先通過特殊陳述句決策樹、疑問句決策樹和否定句決策樹對句子進行句型判定,在未判定出結果的情況下,再採用svm分類器進行判定,本發明方法以決策樹算法為核心,以svm算法為輔助,可以很好地解決傳統決策樹模型無法判斷的特殊點,提升句型分類的準確率。
本發明的目的通過下述技術方案實現:一種基於決策樹和svm混合模型的中文句型分類方法,其特徵在於,步驟如下:
s1、獲取到多個訓練樣本,並且人工標註出各個訓練樣本的句型,得到訓練樣本集;訓練樣本集中包括特殊陳述句句型、疑問句句型和否定句句型的訓練樣本;
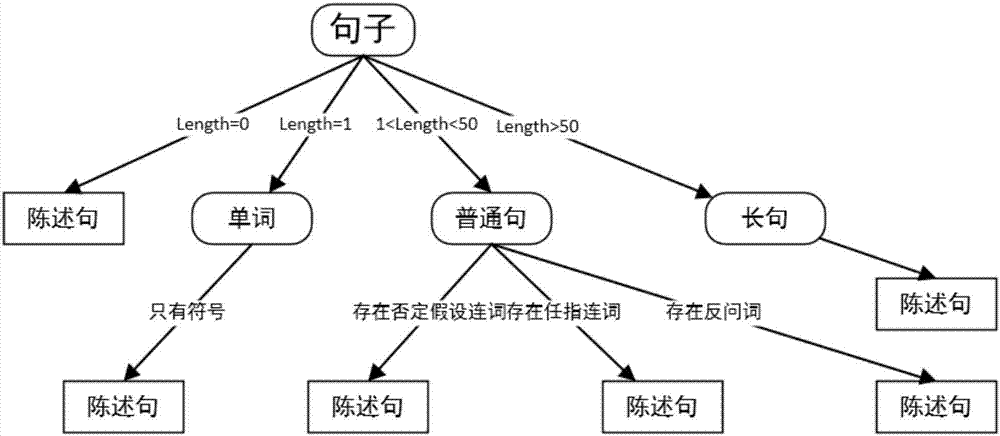
s2、構建特殊陳述句決策樹,首先根據已知的中文語法規則以及訓練樣本集中各類特殊陳述句訓練樣本所具備的特徵獲取到特殊陳述句的判定規則,根據上述判定規則構建得到特殊陳述句決策樹;其中根據特殊陳述句句型具備的特徵將其分為非正常句、任指型陳述句、否定假設句和反問句,具體如下:將句子為空、句子只有一個符號或句子長度超過一定值句子定義為非正常句;將句中包括任指連詞的句子定義為任指型陳述句;將句中包括否定假設詞的句子定義為否定假設句;將句中包括反問詞的句子定義為反問句;
構建疑問句決策樹,首先根據已知的中文語法規則以及訓練樣本集中各類疑問句訓練樣本所具備的特徵獲取到疑問句的判定規則,根據上述判定規則構建得到疑問句決策樹;其中根據疑問句句型所具備的特徵將其分為是非疑問句、選擇疑問句、正反疑問句和特殊疑問句;
構建否定句決策樹,首先提取訓練集中否定句訓練樣本謂語中心語及狀語,通過上述提取的謂語中心語及狀語獲取到否定句訓練樣本所具備的以下特徵:否定詞、狀語、謂語否定詞數量、狀語否定詞數量、狀語否定詞修飾謂語否定詞;然後根據已知的中文語法規則以及訓練樣本集中否定句訓練樣本所具備的特徵獲取到否定句的判定規則,最後根據否定句的判定規則和否定句訓練樣本所具備的特徵訓練得到否定句決策樹;
s3、構建svm分類器,具體步驟如下:
s31、將訓練樣本集中的各個訓練樣本首先分別輸入至步驟s2中構建得到的特殊陳述句決策樹、疑問句決策樹和否定句決策樹中,獲取到上述三個決策樹均不能判定出結果的訓練樣本;
s32、針對步驟s31獲取到的這些訓練樣本,根據第一疑問詞詞典和否定詞詞典,識別出每個訓練樣本中的疑問詞、及其前置詞性和後置詞性,其中疑問詞前置詞性和後置詞性分別指的是疑問詞相鄰前面詞的詞性和相鄰後面詞的詞性;識別出每個訓練樣本中的否定詞、及其前置詞性和後置詞性,其中否定前置詞性和後置詞性分別指的是否定詞相鄰前面詞的詞性和相鄰後面詞的詞性;識別出每個訓練樣本中的疑問詞和否定詞的相對位置,識別出每個訓練樣本中否定詞的個數;所述第一疑問詞詞典包括疑問代詞和副詞;
s33、根據步驟s31獲取到的這些訓練樣本的人工標註的句型,採用數據統計法統計出訓練樣本中出現某個疑問詞時句子成為疑問句的概率,出現某個疑問詞和某種前置詞性搭配時句子為疑問句的概率;出現某個疑問詞和某種後置詞性搭配時句子為疑問句的概率;然後將出現某個疑問詞和某種前置詞性搭配時句子為疑問句的概率除以出現某個疑問詞時句子成為疑問句的概率得到出現某個疑問詞和某種前置詞性搭配時句子為疑問句的條件概率;將出現某個疑問詞和某種後置詞性搭配時句子為疑問句的概率除以出現某個疑問詞時句子成為疑問句的概率得到出現某個疑問詞和某種後置詞性搭配時句子為疑問句的條件概率;
s34、根據步驟s31獲取到的這些訓練樣本的人工標註的句型,採用數據統計法統計出訓練樣本中出現某個否定詞時句子成為否定句的概率,出現某個否定詞和某種前置詞性搭配時句子為否定句的概率;出現某個否定詞和某種後置詞性搭配時句子為否定句的概率;然後將出現某個否定詞和某種前置詞性搭配時句子為否定句的概率除以出現某個否定詞時句子成為否定句的概率得到出現某個否定詞和某種前置詞性搭配時句子為否定句的條件概率;將出現某個否定詞和某種後置詞性搭配時句子為否定句的概率除以出現某個否定詞時句子成為否定句的概率得到出現某個否定詞和某種後置詞性搭配時句子為否定句的條件概率;
s35、根據步驟s31獲取到的這些訓練樣本的人工標註的句型,採用數據統計法統計出訓練樣本中出現某個疑問詞在前而某個否定詞在後時句子分別成為疑問句和否定句的概率,出現某個否定詞在前而某個疑問詞在後時句子分別成為疑問句和否定句的概率;
s36、針對於步驟s31獲取到的三個決策樹均不能判定出結果的訓練樣本,通過以下步驟提取出這些訓練樣本中每個訓練樣本的特徵,具體如下:
s361、當訓練樣本中識別出疑問詞時,分別獲取到該疑問詞的前置詞性和後置詞性,然後通過步驟s33獲取到出現該疑問詞和該前置詞性時句子成為疑問句的概率,作為訓練樣本第一特徵值;同時通過步驟s33獲取到出現該疑問詞和該後置詞性時句子成為疑問句的概率,作為訓練樣的第二特徵值;當訓練樣本未出現疑問詞時,則訓練樣本的第一特徵值和訓練樣本的第二特徵值分別為零;
s362、當訓練樣本中識別出否定詞時,統計否定詞的個數,將否定詞的個數作為訓練樣本的第三特徵值;同時分別獲取到該否定詞的前置詞性和後置詞性,然後通過步驟s34獲取到出現該否定詞和該前置詞性時句子成為否定句的概率,作為訓練樣本的第四特徵值;同時通過步驟s34獲取到出現該否定詞和該後置詞性時句子成為否定句的概率,作為訓練樣本的第五特徵值;當訓練樣本未出現否定詞時,則訓練樣本對應的第四特徵值和第五特徵值分別為零;
s363、當訓練樣本中同時識別出疑問詞和否定詞時,獲取該疑問詞和該否定詞的相對位置,將該相對位置作為訓練樣本的第六特徵值;訓練樣本中若該疑問詞在前而該否定詞在後,則通過步驟s35獲取到出現該疑問詞在前而該否定詞在後時句子分別成為疑問句和否定句的概率,且分別作為訓練樣本的第七特徵值和第八特徵值;訓練樣本中若該否定詞在前而該疑問詞在後,則通過步驟s35獲取到出現該否定詞在前而該疑問詞在後時句子分別成為疑問句和否定句的概率,且分別作為訓練樣本的第七特徵值和第八特徵值;
s37、將步驟s36中獲取到的訓練樣本的第一特徵值、第二特徵值、第三特徵值、第四特徵值、第五特徵值、第六特徵值、第七特徵值和第八特徵值分別作為輸入對svm進行訓練,得到svm分類器;
s4、當獲取到測試文本數據時,首先進行數據預處理得到測試樣本,然後將測試樣本輸入至步驟s2構建得到的特殊陳述句決策樹中,通過特殊陳述句決策樹判斷測試樣本句型,若特殊陳述句決策樹未能判定出測試樣本,那麼進行步驟s5的處理;
s5、首先根據第二疑問詞詞典和否定詞詞典判斷測試樣本中是否有疑問詞和否定詞,若測試樣本中只有疑問詞而沒有否定詞,則將測試樣本作為候選疑問句,進入步驟s6;若測試樣本只有否定詞而沒有疑問詞,則將測試樣本作為候選否定句,進入步驟s7;若測試樣本中既有否定詞又有疑問詞,則進入步驟s8;其中第二疑問詞詞典為第一疑問詞詞典基礎上加上疑問語氣詞後得到的詞典;
s6、將測試樣本輸入至步驟s2構建的疑問句決策樹,通過疑問句決策樹對測試樣本的句型進行判定,輸出測試樣樣本的句型判定結果,若疑問句決策樹未能輸出測試樣本的句型判定結果,則將測試樣本進行步驟s8的處理;
s7、提取出測試樣本的謂語以及修飾該謂語的狀語,並且輸入至步驟s2中構建的否定句決策樹,否定句決策樹根據測試樣本的謂語以及修飾該謂語的狀語對測試樣本的句型進行判定,輸出判定結果,若否定句決策樹未能輸出測試樣本的判定結果,則將測試樣本進行步驟s8的處理;
s8、通過第一疑問詞詞典和否定詞詞典分別識別出測試樣本中的疑問詞和否定詞,然後通過以下步驟提取出測試樣本的特徵;
s81、當測試樣本中有疑問詞時,分別獲取到該疑問詞的前置詞性和後置詞性,然後通過步驟s33獲取到出現該疑問詞和該前置詞性時句子成為疑問句的概率,作為測試樣本第一特徵值;同時通過步驟s33獲取到出現該疑問詞和該後置詞性時句子成為疑問句的概率,作為測試樣本的第二特徵值;當測試樣本未出現疑問詞時,則測試樣本的第一特徵值和第二特徵值分別為零;
s82、當測試樣本中有否定詞時,統計否定詞的個數,將否定詞的個數作為測試樣本的第三特徵值;同時分別獲取到該否定詞的前置詞性和後置詞性,然後通過步驟s34獲取到出現該否定詞和該前置詞性時句子成為否定句的概率,作為測試的第四特徵值;同時通過步驟s34獲取到出現該否定詞和該後置詞性時句子成為否定句的概率,作為測試樣本的第五特徵值;當測試樣本未出現否定詞時,則測試樣本的第四特徵值和第五特徵值分別為零;
s83、當測試樣本中同時有疑問詞和否定詞時,獲取該疑問詞和該否定詞的相對位置,將該相對位置作為測試樣本的第六特徵值;測試樣本中若該疑問詞在前而該否定詞在後,則通過步驟s35獲取到出現該疑問詞在前而該否定詞在後時句子分別成為疑問句和否定句的概率,且分別作為測試樣本的第七特徵值和第八特徵值;測試樣本中若該否定詞在前而該疑問詞在後,則通過步驟s35獲取到出現該否定詞在前而該疑問詞在後時句子分別成為疑問句和否定句的概率,且分別作為測試樣本的第七特徵值和第八特徵值;
s9、將測試樣本的第一特徵值、第二特徵值、第三特徵值、第四特徵值、第五特徵值、第六特徵值、第七特徵值和第八特徵值分別輸入至步驟s364訓練好的svm分類器中,通過svm分類器的輸出獲取到測試樣本的句型判定結果。
優選的,所述步驟s2中在構建特殊陳述句決策樹時,當根據已知的中文語法規則以及訓練樣本集中疑問句訓練樣本所具備的特徵獲取到疑問句的判定規則時,將訓練樣本集中符合上述判定規則的特殊陳述句訓練本輸入至上述判定規則進行驗證,若驗證的準確率達到設定閾值,則將對應的判斷規則加入到決策樹中,從而獲取到特殊陳述句決策樹。
優選的,所述步驟s2中在構建疑問句決策樹時,將訓練樣本集中符合上述判定規則的疑問句訓練樣本輸入至上述判定規則進行驗證,若驗證的準確率達到設定閾值,則將對應的判斷規則加入到決策樹中,從而獲取到疑問句決策樹。
優選的,所述步驟s2中在構建否定句決策樹時,根據否定句的判定規則和否定句訓練樣本所具備的特徵,並且採用id3算法訓練得到否定句決策樹。
更進一步的,所述通過id3算法訓練後,否定句決策樹從上至下每一層的特徵分別為:判定是否存在否定詞、判定是否存在狀語、判定謂語否定詞數量、判定狀語否定詞數量、判定狀語否定詞是否修飾謂語否定詞。
優選的,其特徵在於,所述第二疑問詞詞典為第一疑問詞詞典的基礎上加入疑問語氣詞「嗎、呢、吧、咩、捏、咯、?、?」後得到;
所述步驟s2中,將句中包含正反疑問詞且正反疑問詞不在句尾的句子定義為正反疑問句;將句中出現空格、正反疑問詞在空格前且空格後只有一個詞的句子也作為正反疑問句;所述步驟s2中根據已知的中文語法規則以及訓練樣本集中正反疑問句訓練樣本所具備的上述特徵獲取到正反疑問句的判定規則;
所述步驟s2中,將句中包含選擇疑問詞「是」和「還是」、「是」在「還是」前面、「是」前面沒有疑問詞並且「是」和「還是」之間沒有空格的句子定義為選擇疑問句,所述步驟s2中根據已知的中文語法規則以及訓練樣本集中選擇疑問句訓練樣本所具備的上述特徵獲取到選擇疑問句的判定規則;
所述步驟s2中,將句中包含疑問語氣詞且疑問語氣詞位置滿足一定條件的句子定義為是非疑問句,其中疑問語氣詞分為強疑問語氣詞和弱疑問語氣詞,所述強疑問語氣詞包括「嗎」和「麼」,所述弱疑問詞包括「吧」和「啊」;將句中包含強疑問語氣詞且強疑問語氣詞在句末或者強疑問語氣詞後面只有標點符號的句子定義為是非疑問句,將句中包含強疑問語氣詞、強疑問語氣詞未在句末且強疑問語氣詞後面詞的個數小於3的句子定義為是非疑問句;將句中包含弱疑問語氣詞且弱疑問語氣詞在句末或者弱疑問語氣詞後面跟著問號的句子定義為是非疑問句;所述步驟s2中根據已知的中文語法規則以及訓練樣本集中是非疑問句訓練樣本所具備的上述特徵獲取到是非疑問句的判定規則;
所述步驟s2中,將句中包含不含歧義的疑問代詞或疑問副詞且句尾出現疑問語氣詞的句子定義為特殊疑問句,其中句尾出現的疑問語氣詞不為「嗎」和「吧」;所述步驟s2中根據已知的中文語法規則以及訓練樣本集中特殊疑問句訓練樣本所具備的上述特徵獲取到特殊疑問句的判定規則;
根據上述獲取到的正反疑問句的判定規則、選擇疑問句的判定規則、是非疑問句的判定規則和特殊疑問句的判定規則獲取到疑問句決策樹。
優選的,其特徵在於,還包括構建非否定詞詞典,所述非否定詞詞典中存儲帶否定字眼而不屬於否定詞的非否定詞,所述步驟s5中當根據否定詞詞典判斷出測試樣本中有否定詞時,則再根據非否定詞詞典判斷是否為帶否定字眼而不屬於否定詞的非否定詞,若是,則判定測試樣本沒有否定詞,若否,則將判定測試樣本有否定詞。
優選的,其特徵在於,所述步驟s4中,數據預處理的過程具體如下:
s41、以漢語標點符號中的句號、感嘆號、問號和逗號以及英文標點符號中的感嘆號、問號和逗號作為斷句的分隔符對測試文本數據進行斷句,得到測試樣本,並且保留漢語標點符號中的問號和英文標點符號中的問號;
s42、對斷句後的獲取到的測試樣本進行去幹擾處理;
s43、利用分詞工具對測試樣本進行分詞和詞性標註,得到分詞和詞性標註後的測試樣本。
優選的,所述步驟s7中根據測試樣本的謂語以及修飾該謂語的狀語獲取到測試樣本以下特徵:是否有否定詞、是否有狀語、謂語否定詞數量、狀語否定詞數量、是否存在狀語否定詞修飾謂語否定詞;所述否定句決策樹根據測試樣本上述特徵通過規則對測試樣本進行判定:
s71、若測試樣本只有謂語,沒有狀語,則如果謂語包含有否定詞且謂語否定詞的數量個數不為2,則將測試樣本判定為否定句;
s72、若測試樣本既有謂語,也有狀語,但謂語不包含否定詞,則如果狀語存在否定詞,且狀語否定詞個數不為2,則將測試樣本判定為否定句;
s73、若測試樣本既有謂語,也有狀語,但狀語不包含否定詞,則如果謂語包含有否定詞,且謂語否定詞個數不為2,則將測試樣本判定為否定句;
s74、若測試樣本既有謂語,也有狀語,且狀語和謂語都有否定詞,但狀語否定詞並不是修飾謂語否定詞,則將測試樣本判定為否定句。
優選的,所述步驟s2中通過依存句法分析提取出訓練集中否定句訓練樣本謂語中心語及狀語;所述步驟s7中通過依存句法分析提取出測試樣本的謂語以及修飾該謂語的狀語。
本發明相對於現有技術具有如下的優點及效果:
(1)本發明中文句型分類方法首先獲取到訓練樣本,並且對訓練樣本的句型進行人工標註,得到訓練樣本集;然後根據訓練樣本集中各類句型的訓練樣本構建得到特殊陳述句決策樹、疑問句決策樹和否定句決策樹,並且將訓練樣本集中的各訓練樣本分別輸入至特殊陳述句決策樹、疑問句決策樹和否定句決策樹進行句型判定;最後提取出特殊陳述句決策樹、疑問句決策樹和否定句決策樹均不能判定的訓練樣本,針對這些訓練樣本提取相關特徵值,將這些訓練樣本的相關特徵值輸入至svm中對svm進行訓練,最終得到svm分類器。當獲取到測試樣本後,首先通過特殊陳述句決策樹進行句型判定,在特殊陳述句決策樹未判定出結果的情況下,首先根據第二疑問詞詞典和否定詞詞典判斷測試樣本中是否有疑問詞和否定詞,在只有疑問詞的情況下,將測試樣本作為候選疑問句輸入至疑問句決策樹進行判定;在只有否定詞的情況下,將測試樣本作為候選否定句輸入至否定句決策樹進行判定;將疑問句決策樹和否定句決策樹均未能判定出結果的測試樣本以及既有疑問詞又有否定詞的測試樣本輸入至svm分類器進行分類;可見,本發明將特殊陳述句決策樹、疑問句決策樹、否定句決策樹和svm分類器相結合,既可以比較準確地判斷出大部分正常的句子,又可以相對高效地處理一部分難以歸納總結的句子。本發明方法以決策樹算法為核心,以svm算法為輔助,可以很好地解決傳統決策樹模型無法判斷的特殊點,提升句型分類的準確率。
(2)本發明在構建svm分類器時,首先根據第一疑問詞典和否定詞典提取出特殊陳述句決策樹、疑問句決策樹和否定句決策樹均不能判定出結果的訓練樣本中的疑問詞和否定詞關鍵詞,然後統計出訓練樣本集中出現某個疑問詞和某種前置詞性搭配時句子為疑問句的條件概率、出現某個疑問詞和某種後置詞性搭配時句子為疑問句的條件概率、出現某個否定詞和某種前置詞性搭配時句子為否定句的條件概率、出現某個否定詞和某種後置詞性搭配時句子為否定句的條件概率、出現某個疑問詞在前而某個否定詞在後時句子分別成為疑問句和否定句的概率、出現某個否定詞在前而某個疑問詞在後時句子分別成為疑問句和否定句的概率;然後針對於特殊陳述句決策樹、疑問句決策樹和否定句決策樹均不能判定出結果的每個訓練樣本以及需要進行句型分類的測試樣本,首先識別出疑問詞及其前置詞性和後置詞性、否定詞及其前置詞性和後置詞性,將出現該疑問詞和該前置詞性時句子成為疑問句的概率作為樣本第一特徵值;將出現該疑問詞和該後置詞性時句子成為疑問句的概率作為樣本的第二特徵值;將出現的否定詞個數作為樣本的第三特徵值;將出現該否定詞和該前置詞性時句子成為否定句的概率作為樣本的第四特徵值;將出現該否定詞和該後置詞性時句子成為否定句的概率作為樣本的第五特徵值;將該疑問詞和該否定詞的相對位置作為樣本的第六特徵值;將出現該疑問詞在前而該否定詞在後時句子分別成為疑問句和否定句的概率分別作為樣本的第七特徵值和第八特徵值;或者將出現該否定詞在前而該疑問詞在後時句子分別成為疑問句和否定句的概率作為樣本的第七特徵值和第八特徵值;在訓練階段,將訓練樣本對應的上述第一特徵值至第八特徵值作為輸入對svm進行訓練,得到svm分類器;在測試階段,針對不能通過特殊陳述句決策樹、疑問句決策樹和否定句決策樹判定出結果的測試樣本,提取對應的上述第一特徵值至第八特徵值輸入svm分類器,通過svm分類器對測試樣本進行分類,得到最終的分類結果。本發明svm分類器將疑問詞及其前置詞性和後置詞性、否定詞及其前置詞性和後置詞性以及疑問詞及其前後否定詞作為關鍵特徵實現對句型的分類,較好地解決疑問詞和否定詞多義性的問題,進一步提高了句型分類的準確率。
(3)本發明方法中還構建有非否定詞詞典,其中非否定詞詞典用於存儲帶否定字眼而不屬於否定詞的非否定詞,當根據否定詞詞典判斷出測試樣本中有否定詞時,本發明方法中再根據非否定詞詞典判斷是否只是為帶否定字眼而不屬於否定詞的非否定詞,在不是的情況下,才將判定測試樣本判定為有否定詞。進一步提高了否定句分類的準確率。
(4)本發明方法通過依存句法分析提取出否定句訓練樣本中的謂語中心語及狀語,然後通過提取的謂語中心語及狀語獲取到否定句訓練樣本所具備的以下特徵:否定詞、狀語、謂語否定詞數量、狀語否定詞數量、狀語否定詞修飾謂語否定詞;通過上述否定句訓練樣本所具備的上述特徵以及否定句判斷規則訓練得到否定句決策樹;同時本發明通過依存句法分析提取出候選否定句測試樣本中的謂語中心語及狀語,否定句決策樹根據測試樣本中的謂語中心語及狀語對否定句進行判定,能夠較好地處理否定句判斷的問題,進一步提高否定句分類的準確率。
附圖說明
圖1是本發明中文句型分類方法流程圖。
圖2是本發明特殊陳述句決策樹模型圖。
圖3是本發明疑問句決策樹的決策流程圖。
圖4是本發明否定句決策樹模型圖。
具體實施方式
下面結合實施例及附圖對本發明作進一步詳細的描述,但本發明的實施方式不限於此。
實施例
本實施例公開了一種基於決策樹和svm混合模型的中文句型分類方法,如圖1所示,步驟如下:
s1、獲取到多個訓練樣本,並且人工標註出各個訓練樣本的句型,得到訓練樣本集;訓練樣本集中包括特殊陳述句句型、疑問句句型和否定句句型的訓練樣本;
s2、構建特殊陳述句決策樹,首先根據已知的中文語法規則以及訓練樣本集中各類特殊陳述句訓練樣本所具備的特徵獲取到特殊陳述句的判定規則,根據上述判定規則構建得到特殊陳述句決策樹;在本實施例中將訓練樣本集中符合上述判定規則的特殊陳述句訓練本輸入至上述判定規則進行驗證,若驗證的準確率達到設定閾值70%,則將對應的判斷規則加入到決策樹中,從而獲取到特殊陳述句決策樹。
在本實施例中根據特殊陳述句句型具備的特徵將其分為非正常句、任指型陳述句、否定假設句和反問句;具體如下:
在本實施例中將句子為空、句子只有一個符號或句子長度超過一定值句子定義為非正常句;
在本實施例中將句中包括任指連詞的句子定義為任指型陳述句,本實施例中任指連詞包括「無論」、「不論」和「不管」,當句中出現任指連詞「無論」、「不論」時,則定義句子為任指型陳述句,當句中出現任指連詞「不管」且任指連詞「不管」在句首時,則定義句子為任指型陳述句;例如「無論他怎麼做」、「無論他去上學了沒有」、「不管他去上學了沒有」均為任指型陳述句,而「我不管他了」,此處的「不管」做否定謂語,在本實施例中不被定義為任指型陳述句。
在本實施例中將句中包括否定假設詞的句子定義為否定假設句;本實施例中否定假設詞包括「即使」、「儘管」、「哪怕」、「就算」和「縱使」,比如「即使他不是中國人」、「就算他沒完成作業」均屬於否定假設句。
在本實施例中將句中包括反問詞的句子定義為反問句。本實施例中反問詞包括「還敢」、「何曾」、「何來」、「何止」、「難道」、「難不成」、「豈不是」和「怎能」。
如圖2所示,即為本實施例構建得到的特殊陳述句決策樹。
構建疑問句決策樹,首先根據已知的中文語法規則以及訓練樣本集中各類疑問句訓練樣本所具備的特徵獲取到疑問句的判定規則,根據上述判定規則構建得到疑問句決策樹;本實施例中將訓練樣本集中符合上述判定規則的疑問句訓練樣本輸入至上述判定規則進行驗證,若驗證的準確率達到設定閾值70%,則將對應的判斷規則加入到決策樹中,從而獲取到疑問句決策樹。
其中根據疑問句句型所具備的特徵將其分為是非疑問句、選擇疑問句、正反疑問句和特殊疑問句;具體如下:
在本實施例中將句中包含正反疑問詞且正反疑問詞不在句尾的句子定義為正反疑問句;如句子:「今天是個好天氣有木有!」、「他是個好人好不好。」,由於上述兩個句子中正反疑問詞在句尾,因此不為正反疑問句;另外本實施例中將句中出現空格、正反疑問詞在空格前且空格後只有一個詞的句子也作為正反疑問句,如「你愛不愛他不愛。」這個句子為正反疑問句。因此本實施例中根據已知的中文語法規則以及訓練樣本集中正反疑問句訓練樣本所具備的上述特徵獲取到正反疑問句的判定規則;
在本實施例中將句中包含選擇疑問詞「是」和「還是」、「是」在「還是」前面、「是」前面沒有疑問詞並且「是」和「還是」之間沒有空格的句子定義為選擇疑問句,其中最後一個條件「是」和「還是」之間沒有空格針對的問題是使用空格當分隔符時,使得空格前後為兩個獨立的句子。如「今天是個好天氣我們還是去學校吧。」空格前後是兩個句子,因此「是」和「還是」有空格時,將不認為是選擇疑問句;本實施例中根據已知的中文語法規則以及訓練樣本集中選擇疑問句訓練樣本所具備的上述特徵獲取到選擇疑問句的判定規則;
在本實施例中將句中包含疑問語氣詞且疑問語氣詞位置滿足一定條件的句子定義為是非疑問句,其中疑問語氣詞分為強疑問語氣詞和弱疑問語氣詞,所述強疑問語氣詞包括「嗎」和「麼」,所述弱疑問詞包括「吧」和「啊」;將句中包含強疑問語氣詞且強疑問語氣詞在句末或者強疑問語氣詞後面只有標點符號的句子定義為是非疑問句;將句中包含強疑問語氣詞、強疑問語氣詞未在句末且強疑問語氣詞後面詞的個數小於3的句子定義為是非疑問句,例如在句末加表情的句子,此時表情個數小於3,所以也被認為是非疑問句;將句中包含弱疑問語氣詞且弱疑問語氣詞在句末或者弱疑問語氣詞後面跟著問號的句子定義為是非疑問句;本實施例中根據已知的中文語法規則以及訓練樣本集中是非疑問句訓練樣本所具備的上述特徵獲取到是非疑問句的判定規則;
本實施例中將句中包含不含歧義的疑問代詞或疑問副詞且句尾出現疑問語氣詞的句子定義為特殊疑問句,其中句尾出現的疑問語氣詞不為「嗎」和「吧」;本實施例中根據已知的中文語法規則以及訓練樣本集中特殊疑問句訓練樣本所具備的上述特徵獲取到特殊疑問句的判定規則。
構建否定句決策樹,首先通過依存句法分析提取出訓練集中否定句訓練樣本謂語中心語及狀語,通過上述提取的謂語中心語及狀語獲取到否定句訓練樣本所具備的以下特徵:否定詞、狀語、謂語否定詞數量、狀語否定詞數量、狀語否定詞修飾謂語否定詞;然後根據已知的中文語法規則以及訓練樣本集中否定句訓練樣本所具備的特徵獲取到否定句的判定規則,最後根據否定句的判定規則和否定句訓練樣本所具備的特徵,採用id3算法訓練得到否定句決策樹;本實施例中通過id3算法訓練後,否定句決策樹從上至下每一層的特徵分別為:判定是否存在否定詞、判定是否存在狀語、判定謂語否定詞數量、判定狀語否定詞數量、判定狀語否定詞是否修飾謂語否定詞,如圖4所示即為本實施例構建得到的否定句決策樹模型。
s3、構建svm分類器,具體步驟如下:
s31、將訓練樣本集中的各個訓練樣本首先分別輸入至步驟s2中構建得到的特殊陳述句決策樹、疑問句決策樹和否定句決策樹中,獲取到上述三個決策樹均不能判定出結果的訓練樣本;
s32、針對步驟s31獲取到的三個決策樹均不能判定出結果的訓練樣本,根據第一疑問詞詞典和否定詞詞典,識別出每個訓練樣本中的疑問詞、及其前置詞性和後置詞性,其中疑問詞前置詞性和後置詞性分別指的是疑問詞相鄰前面詞的詞性和相鄰後面詞的詞性;識別出步驟s31獲取到的這些訓練樣本中的每個訓練樣本中的否定詞、及其前置詞性和後置詞性,其中否定前置詞性和後置詞性分別指的是否定詞相鄰前面詞的詞性和相鄰後面詞的詞性;識別出每個訓練樣本中的疑問詞和否定詞的相對位置,識別出每個訓練樣本中否定詞的個數;本實施例中第一疑問詞詞典包括中文和英文的疑問代詞和副詞;本實施例中第一疑問詞詞典包括如下疑問代詞和副詞:how、how、what、what、when、when、where、where、which、which、who、who、whom、whom、whose、whose、why、why、到底、多會兒、多會兒、多久、多少、多咱、反倒、幹嗎、幹嘛、幹什麼、幹嗎、幹嘛、幹什麼、何、何來、何來、何時、何時、何為、何為、何用、何在、幾時、幾時、究竟、可好、毛線、毛線、莫非、哪、哪兒、哪兒、哪個、哪個、哪會兒、哪會兒、哪款、哪裡、哪裡、哪些、哪種、哪種、難道、難怪、難道、難怪、豈、豈、如何、啥、啥時候、啥時候、什麼、什麼、神馬、神馬、孰是孰非、誰、誰、為何、為毛、為啥、為什麼、為何、為毛、為啥、為什麼、要不、有何、有木有、怎、怎的、怎地、怎會、怎會、怎麼、怎麼辦、怎麼回事、怎麼弄、怎麼樣、怎麼著、怎麼做、怎麼、怎麼辦、怎麼回事、怎麼弄、怎麼樣、怎麼著、怎麼做、怎樣、怎樣、知否、腫麼、腫麼。本實施例中否定詞詞典包括以下否定詞:別、別、並非、並非、不、不必、不曾、不成、不大、不得、不對、不對、不敢、不夠、不夠、不管用、不好、不合理、不會、不會、不見、不見、不堪、不可、不了、不利、不利於、不利於、不料、不能、不配、不然、不讓、不讓、不是、不說、不說、不同、不想、不要、不宜、不易、不用、不再、不足、吃不得、從不、從來不、從不、從來不、都木、都木有、非、覅、搞不懂、還沒、還沒、行不通、毫不、記不清、記不清、經不起、經不起、決不能、決不能、絕不、絕不能、絕不、絕不能、看錯、看錯、來不及、來不及、卵、沒、沒法、沒什麼、沒用、沒用過、沒有、沒、沒法、沒什麼、沒用、沒用過、沒有、木、木有、少於、少於、未必、未能、無、無度、無法、無可、無、無度、無法、無可、勿、也別、也別。
s33、根據步驟s31獲取到的這些訓練樣本的人工標註的句型,採用數據統計法統計出訓練樣本中出現某個疑問詞時句子成為疑問句的概率,出現某個疑問詞和某種前置詞性搭配時句子為疑問句的概率;出現某個疑問詞和某種後置詞性搭配時句子為疑問句的概率;然後將出現某個疑問詞和某種前置詞性搭配時句子為疑問句的概率除以出現某個疑問詞時句子成為疑問句的概率得到出現某個疑問詞和某種前置詞性搭配時句子為疑問句的條件概率;將出現某個疑問詞和某種後置詞性搭配時句子為疑問句的概率除以出現某個疑問詞時句子成為疑問句的概率得到出現某個疑問詞和某種後置詞性搭配時句子為疑問句的條件概率;
例如針對訓練樣本中識別出的某疑問詞a,某疑問詞a前一個詞的詞性b1,後一個詞的詞性b2;則
出現某個疑問詞和某種前置詞性搭配時句子為疑問句的條件概率為:
p(前置搭配屬於疑問句)=p(a,b1)/p(a);
出現某個疑問詞和某種後置詞性搭配時句子為疑問句的條件概率為:
p(後置搭配屬於疑問句)=p(a,b2)/p(a);
其中p(a,b1)為出現某個疑問詞a和某種前置詞性b1搭配時句子為疑問句的概率,p(a,b2)為出現某個疑問詞a和某種後置詞性b2搭配時句子為疑問句的概率,p(a)為出現某個疑問詞a時句子成為疑問句的概率。
s34、根據步驟s31獲取到的這些訓練樣本的人工標註的句型,採用數據統計法統計出訓練樣本中出現某個否定詞時句子成為否定句的概率,出現某個否定詞和某種前置詞性搭配時句子為否定句的概率;出現某個否定詞和某種後置詞性搭配時句子為否定句的概率;然後將出現某個否定詞和某種前置詞性搭配時句子為否定句的概率除以出現某個否定詞時句子成為否定句的概率得到出現某個否定詞和某種前置詞性搭配時句子為否定句的條件概率;將出現某個否定詞和某種後置詞性搭配時句子為否定句的概率除以出現某個否定詞時句子成為否定句的概率得到出現某個否定詞和某種後置詞性搭配時句子為否定句的條件概率;
s35、根據步驟s31獲取到的這些訓練樣本的人工標註的句型,採用數據統計法統計出訓練樣本中出現某個疑問詞在前而某個否定詞在後時句子分別成為疑問句和否定句的概率,出現某個否定詞在前而某個疑問詞在後時句子分別成為疑問句和否定句的概率;
例如針對訓練樣本中出現疑問詞a,否定詞b,且a在b之前。則本實施例方法統計出的訓練樣本中出現某個疑問詞在前而某個否定詞在後時句子分別成為疑問句和否定句的概率為:
py(a_b)=cy(a_b)/c(a_b);
pf(a_b)=cf(a_b)/c(a_b);
其中c(a_b)為步驟s31獲取到的訓練樣本中出現疑問詞a在前而否定詞b在後的次數;cy(a_b)表示出現疑問詞a在前而否定詞b在後的訓練樣本中為疑問句的個數,cf(a_b)表示出現疑問詞a在前而否定詞b在後的訓練樣本中為否定句的個數;py(a_b)表示出現某個疑問詞在前而某個否定詞在後時句子成為疑問句的概率;pf(a_b)表示出現某個疑問詞在前而某個否定詞在後時句子成為否定句的概率;
s36、針對於步驟s31獲取到的三個決策樹均不能判定出結果的訓練樣本,通過以下步驟提取出這些訓練樣本中每個訓練樣本的特徵,具體如下:
s361、當訓練樣本中識別出疑問詞時,分別獲取到該疑問詞的前置詞性和後置詞性,然後通過步驟s33獲取到出現該疑問詞和該前置詞性時句子成為疑問句的概率,作為訓練樣本第一特徵值;同時通過步驟s33獲取到出現該疑問詞和該後置詞性時句子成為疑問句的概率,作為訓練樣的第二特徵值;當訓練樣本未出現疑問詞時,則訓練樣本的第一特徵值和訓練樣本的第二特徵值分別為零;
s362、當訓練樣本中識別出否定詞時,統計否定詞的個數,將否定詞的個數作為訓練樣本的第三特徵值;同時分別獲取到該否定詞的前置詞性和後置詞性,然後通過步驟s34獲取到出現該否定詞和該前置詞性時句子成為否定句的概率,作為訓練樣本的第四特徵值;同時通過步驟s34獲取到出現該否定詞和該後置詞性時句子成為否定句的概率,作為訓練樣本的第五特徵值;當訓練樣本未出現否定詞時,則訓練樣本對應的第四特徵值和第五特徵值分別為零;
s363、當訓練樣本中同時識別出疑問詞和否定詞時,獲取該疑問詞和該否定詞的相對位置,將該相對位置作為訓練樣本的第六特徵值,在本實施例中,若疑問詞在否定詞前,則訓練樣本的第六特徵值為1,反之為-1;訓練樣本中若該疑問詞在前而該否定詞在後,則通過步驟s35獲取到出現該疑問詞在前而該否定詞在後時句子分別成為疑問句和否定句的概率,且分別作為訓練樣本的第七特徵值和第八特徵值;訓練樣本中若該否定詞在前而該疑問詞在後,則通過步驟s35獲取到出現該否定詞在前而該疑問詞在後時句子分別成為疑問句和否定句的概率,且分別作為訓練樣本的第七特徵值和第八特徵值;
s37、將步驟s36中獲取到的訓練樣本的第一特徵值、第二特徵值、第三特徵值、第四特徵值、第五特徵值、第六特徵值、第七特徵值和第八特徵值分別作為輸入對svm進行訓練,得到svm分類器;
s4、當獲取到測試文本數據時,首先進行數據預處理得到測試樣本,然後將測試樣本輸入至步驟s2構建得到的特殊陳述句決策樹中,如圖2所示,通過特殊陳述句決策樹判斷測試樣本句型,若特殊陳述句決策樹未能判定出測試樣本,那麼進行步驟s5的處理;其中圖2中length表示的是句子的長度;在本實施例中數據預處理的過程具體如下:
s41、以漢語標點符號中的句號、感嘆號、問號和逗號以及英文標點符號中的感嘆號、問號和逗號作為斷句的分隔符對測試文本數據進行斷句,得到測試樣本,並且保留漢語標點符號中的問號和英文標點符號中的問號;
s42、對斷句後的獲取到的測試樣本進行去幹擾處理;在本實施例中去除測試樣本中的以下幹擾:
(1)將測試樣本中出現的中括號【】及中括號【】裡面的內容進行刪除;
(2)將測試樣本中出現的【和?以及【和?之間的內容進行刪除,將測試樣本中的【和?以及【和?之間的內容進行刪除;
(3)將測試樣本中#以及#和#之間的內容進行刪除;
(4)將測試樣本中//@和:以及//@和之間的內容進行刪除,將測試樣本中的//@和:以及//@和:之間的內容進行刪除;
(5)將測試樣本中@和制表符及它們之間的內容進行刪除,將測試樣本中的@和空格符及它們之間的內容進行刪除;
(6)當測試樣本中僅有】而沒有【時,則將】及其之前的內容進行刪除;
(7)將測試樣本中尖括號《》及其中的內容進行刪除;
(8)將測試樣本中括號及其中的內容進行刪除:
(9)將測試樣本中的中文省略號「……」替換為逗號「,」;
(10)將測試樣本中的中文分號「;」和英文分號「;」替換為逗號「,」;
(11)將測試樣本中的雙引號「」及雙引號「」中的內容進行刪除;
(12)將測試文本中的網址進行刪除;
s43、利用分詞工具對測試樣本進行分詞和詞性標註,得到分詞和詞性標註後的測試樣本,即為數據預處理後的測試樣本。
s5、首先根據第二疑問詞詞典和否定詞詞典判斷測試樣本中是否有疑問詞和否定詞,若測試樣本中只有疑問詞而沒有否定詞,則將測試樣本作為候選疑問句,進入步驟s6;若測試樣本只有否定詞而沒有疑問詞,則將測試樣本作為候選否定句,進入步驟s7;若測試樣本中既有否定詞又有疑問詞,則進入步驟s8;其中第二疑問詞詞典為第一疑問詞詞典基礎上加上疑問語氣詞後得到的詞典;其中加上的疑問語氣詞包括中文疑問語氣詞「嗎、呢、吧、咩、捏、咯、?、?」。
s6、將測試樣本輸入至步驟s2構建的疑問句決策樹,通過疑問句決策樹對測試樣本的句型進行判定,輸出判定結果,若疑問句決策樹未能輸出測試樣本的判定結果,則將測試樣本進行步驟s8的處理;其中如圖3所示,本實施例中疑問句決策樹針對輸入的測試樣本首先判定是否為正反疑問句,當判定為不是正方疑問句的情況下判斷是否為選擇疑問句,當判定為不是選擇疑問句時再判定是否為是否非疑問句,當判定為不是是非疑問句時再判定是否為特殊疑問句,當判定為不是特殊疑問句時,即疑問句決策樹沒有輸出判定結果時,則將測試樣本進行步驟s8的處理。
s7、通過依存句法分析提取出測試樣本的謂語以及修飾該謂語的狀語,根據測試樣本的謂語以及修飾該謂語的狀語獲取到測試樣本以下特徵:否定詞、狀語、謂語否定詞數量、狀語否定詞數量、狀語否定詞修飾謂語否定詞;並且輸入至步驟s2中構建的否定句決策樹,如圖4所示,否定句決策樹根據測試樣本上述特徵對測試樣本的句型進行判定,輸出判定結果,若否定句決策樹未能輸出測試樣本的判定結果,則將測試樣本進行步驟s8的處理;
本步驟中否定句決策樹根據測試樣本上述特徵通過規則對測試樣本進行判定:
s71、若測試樣本只有謂語,沒有狀語,則如果謂語包含有否定詞且謂語否定詞的數量個數不為2,則將測試樣本判定為否定句;
s72、若測試樣本既有謂語,也有狀語,但謂語不包含否定詞,則如果狀語存在否定詞,且狀語否定詞個數不為2,則將測試樣本判定為否定句;
s73、若測試樣本既有謂語,也有狀語,但狀語不包含否定詞,則如果謂語包含有否定詞,且謂語否定詞個數不為2,則將測試樣本判定為否定句。
s74、若測試樣本既有謂語,也有狀語,且狀語和謂語都有否定詞,但狀語否定詞並不是修飾謂語否定詞,則將測試樣本判定為否定句。
其中圖4中neg_exist=1表示句中存在否定詞;adv_exist=0表示測試樣本只有謂語而沒有狀語;adv_exist=1表示測試樣本既有謂語也有狀語;neg_count表示謂語否定詞的個數,neg_count=0表示謂語否定詞的數量個數為0個,neg_count=1表示謂語否定詞的數量個數為1個,neg_count!=2表示謂語否定詞的數量個數不為2個,neg_count>=2表示謂語否定詞的數量個數大於等於2個;adv_neg_count表示狀語包含否定詞的個數,adv_neg_count=0表示狀語否定詞的個數為0;adv_neg_count!=2表示狀語否定詞的個數不為2個;adv_neg_count>=2表示狀語否定詞的個數大於等於2個。
s8、通過第一疑問詞詞典和否定詞詞典分別識別出測試樣本中的疑問詞和否定詞,然後通過以下步驟提取出測試樣本的特徵;
s81、當測試樣本中有疑問詞時,分別獲取到該疑問詞的前置詞性和後置詞性,然後通過步驟s33獲取到出現該疑問詞和該前置詞性時句子成為疑問句的概率,作為測試樣本第一特徵值;同時通過步驟s33獲取到出現該疑問詞和該後置詞性時句子成為疑問句的概率,作為測試樣本的第二特徵值;當測試樣本未出現疑問詞時,則測試樣本的第一特徵值和第二特徵值分別為零;
s82、當測試樣本中有否定詞時,統計否定詞的個數,將否定詞的個數作為測試樣本的第三特徵值;同時分別獲取到該否定詞的前置詞性和後置詞性,然後通過步驟s34獲取到出現該否定詞和該前置詞性時句子成為否定句的概率,作為測試的第四特徵值;同時通過步驟s34獲取到出現該否定詞和該後置詞性時句子成為否定句的概率,作為測試樣本的第五特徵值;當測試樣本未出現否定詞時,則測試樣本的第四特徵值和第五特徵值分別為零;
s83、當測試樣本中同時有疑問詞和否定詞時,獲取該疑問詞和該否定詞的相對位置,將該相對位置作為測試樣本的第六特徵值,在本實施例中,若疑問詞在否定詞前,則測試樣本的第六特徵值為1,反之為-1;測試樣本中若該疑問詞在前而該否定詞在後,則通過步驟s35獲取到出現該疑問詞在前而該否定詞在後時句子分別成為疑問句和否定句的概率,且分別作為測試樣本的第七特徵值和第八特徵值;測試樣本中若該否定詞在前而該疑問詞在後,則通過步驟s35獲取到出現該否定詞在前而該疑問詞在後時句子分別成為疑問句和否定句的概率,且分別作為測試樣本的第七特徵值和第八特徵值;
s9、將測試樣本的第一特徵值、第二特徵值、第三特徵值、第四特徵值、第五特徵值、第六特徵值、第七特徵值和第八特徵值分別輸入至步驟s364訓練好的svm分類器中,通過svm分類器的輸出獲取到測試樣本的句型判定結果。
本實施例中還包括構建非否定詞詞典的步驟,其中非否定詞詞典中存儲帶否定字眼而不屬於否定詞的非否定詞;本實施例中非否定詞詞典包括以下非否定詞:不變、不變、不錯、不錯、不但、不得不、不等、不過、不過、不介意、不僅、不僅、不久、不久前、不愧、不滿、不滿、不停、不吐不快、對不起、對不起、告別、告別、絕不、絕不、沒錯、沒關係、沒事、沒準、沒錯、沒關係、沒事、沒準、無所謂、無憂、無所謂、無憂、要不是、只不過、只不過。
本實施例上述步驟s5中當根據否定詞詞典判斷出測試樣本中有否定詞時,則再根據非否定詞詞典判斷是否為帶否定字眼而不屬於否定詞的非否定詞,若是,則判定測試樣本沒有否定詞,若否,則將判定測試樣本有否定詞。進而進行步驟s5之後的操作。通過本實施例中的非否定詞詞典帶將帶否定字眼而不屬於否定詞的非否定詞去掉,以避免將非否定詞誤認為是否定詞,進一步提到否定句分類的準確性。
在資訊理論中,信息熵(entropy)越小表示數據的混亂程度越低,數據純度越高。其中id3算法中採用信息增益(informationgain)來衡量節點分裂後的信息量損失。該算法的核心思想是選擇分裂後信息增益最大的特徵進行分裂。
設d為訓練元組集合,則採用以下公式計算d的信息熵:
上式中,m代表該元組集合總共被劃分到多少個類別,「句式判定」是每個元組的類別,因此m=2。p(i)代表的是第i個類別出現的概率。假設現在對屬性a進行分裂,則可以根據下面的公式求出a分裂後的信息熵:
在上述公式中,v代表屬性a的取值個數,比如a的取值有{a1,a2,a3,a4},則v=4。dj代表所有屬性a值等於aj的元組集合。|d|表示的是元組集合d的元組數量。該公式代表的含義是a分裂後的信息熵等於分裂後各個節點各自的信息熵之和。
信息增益即為上述兩者的差值:
gain(a)=entropy(d)-entropya(d)
本實施例上述步驟s2中否定句決策樹訓練所採用的id3算法就是在每次分裂前,使用信息增益計算還未使用特徵的信息增益,然後選擇出信息增益值最大的特徵作為分裂標準。重複這一過程直到決策樹訓練完畢。
本實施例上述方法首先獲取到訓練樣本,並且對訓練樣本的句型進行人工標註,得到訓練樣本集;然後根據訓練樣本集中各類句型的訓練樣本構建得到特殊陳述句決策樹、疑問句決策樹和否定句決策樹,並且將訓練樣本集中的各訓練樣本分別輸入至特殊陳述句決策樹、疑問句決策樹和否定句決策樹進行句型判定;最後提取出特殊陳述句決策樹、疑問句決策樹和否定句決策樹均不能判定的訓練樣本,針對這些訓練樣本,通過第一疑問詞詞典和否定詞詞典提取各訓練樣本中的疑問詞和否定詞,並且統計出以下情況:出現某個疑問詞和某種前置詞性搭配時句子為疑問句的條件概率、出現某個疑問詞和某種後置詞性搭配時句子為疑問句的條件概率、出現某個否定詞和某種前置詞性搭配時句子為否定句的條件概率、出現某個否定詞和某種後置詞性搭配時句子為否定句的條件概率、出現某個疑問詞在前而某個否定詞在後時句子分別成為疑問句和否定句的概率、出現某個否定詞在前而某個疑問詞在後時句子分別成為疑問句和否定句的概率;然後識別出每個訓練樣本中的疑問詞及其前置詞性和後置詞性、否定詞及其前置詞性和後置詞性,獲取到出現該疑問詞和該前置詞性時句子成為疑問句的概率,作為訓練樣本第一特徵值;獲取到出現該疑問詞和該後置詞性時句子成為疑問句的概率,作為訓練樣的第二特徵值;獲取到訓練樣本中否定詞的個數作為訓練樣本的第三特徵值;獲取到出現該否定詞和該前置詞性時句子成為否定句的概率,作為訓練樣本的第四特徵值;獲取到出現該否定詞和該後置詞性時句子成為否定句的概率,作為訓練樣本的第五特徵值;獲取該疑問詞和該否定詞的相對位置,將該相對位置作為訓練樣本的第六特徵值;獲取到出現該疑問詞在前而該否定詞在後時句子分別成為疑問句和否定句的概率,且分別作為訓練樣本的第七特徵值和第八特徵值;或者獲取到出現該否定詞在前而該疑問詞在後時句子分別成為訓練樣本的疑問句和否定句的概率,且分別作為訓練樣本的第七特徵值和第八特徵值;將訓練樣本的第一特徵值至第八特徵值分別作為輸入對svm進行訓練,得到svm分類器。當獲取到測試樣本後,首先通過特殊陳述句決策樹進行句型判定,在特殊陳述句決策樹未判定出結果的情況下,首先根據第二疑問詞詞典和否定詞詞典判斷測試樣本中是否有疑問詞和否定詞,在只有疑問詞的情況下,將測試樣本作為候選疑問句輸入至疑問句決策樹進行判定;在只有否定詞的情況下,將測試樣本作為候選否定句輸入至否定句決策樹進行判定;將疑問句決策樹和否定句決策樹均未能判定出結果的測試樣本以及既有疑問詞又有否定詞的測試樣本提取第一特徵值至第八特徵值後,通過svm分類器進行分類,得到分類結果;可見,本實施例方法將特殊陳述句決策樹、疑問句決策樹、否定句決策樹和svm分類器相結合既可以比較準確地判斷出大部分正常的句子,又可以相對高效地處理一部分難以歸納總結的句子。本發明方法以決策樹算法為核心,以svm算法為輔助,可以很好地解決傳統決策樹模型無法判斷的特殊點,提升句型分類的準確率。
上述實施例為本發明較佳的實施方式,但本發明的實施方式並不受上述實施例的限制,其他的任何未背離本發明的精神實質與原理下所作的改變、修飾、替代、組合、簡化,均應為等效的置換方式,都包含在本發明的保護範圍之內。