一種快速查找投注組合的方法與流程
2023-05-30 08:50:11 2
本發明涉及競猜投注管理技術領域,特別涉及一種快速查找投注組合的方法。
背景技術:
在競猜投注過程中,當需要在現有投注組合中查找出當前投注組合是否已經存在,現有技術採用平衡二叉樹原理進行搜索,即需要從根節點搜索到葉節點,若以現有投注組合為152萬的話,採用以下計算式便很容易得出平均需要進行20次比較的結果。計算式為log21520000=20,才能在現有投注組合中找到當前投注組合。
而由於平衡二叉樹的數學特性,其左右兩個子樹的高度差的絕對值不超過1,當不符合上述條件時,便需要進行數據平衡,而在數據平衡時則需要大量的數據移動。由此,一來耽誤查找效率,二來由於增加了運算量以及存儲地址,也就無形中增加了成本。
技術實現要素:
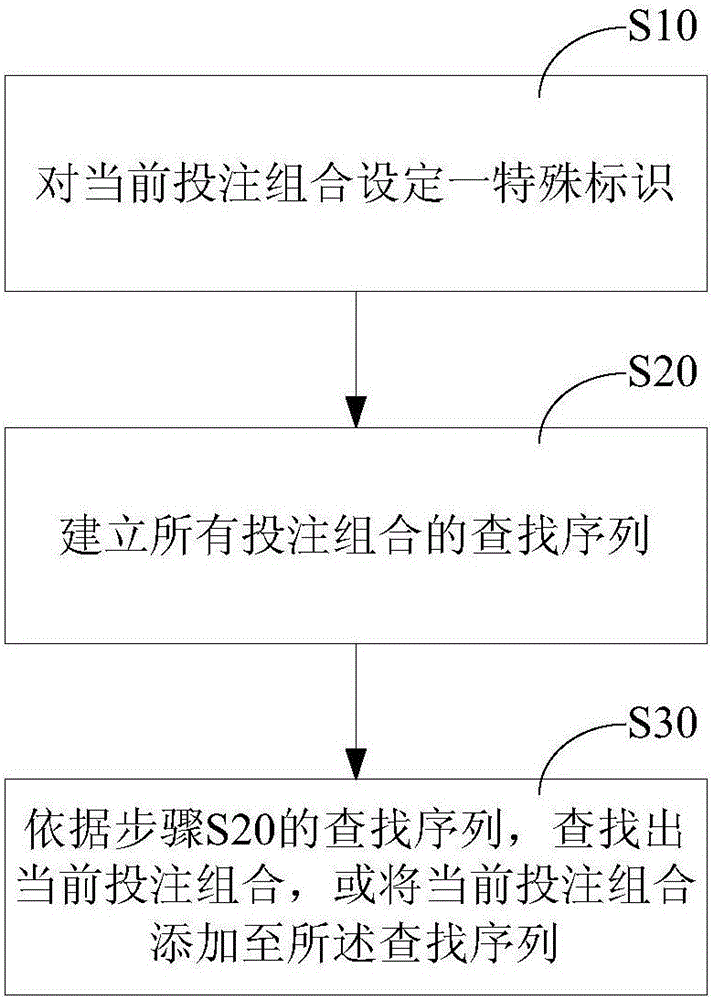
有鑑於此,本發明的主要目的在於,提供一種快速查找投注組合的方法,包括步驟:
A1、逐一確定現有各投注組合的串關數以及獎池;
A2、對於各投注組合,將其獎池依據其串關數進行累加,計算得出現有各投注組合的標識;
A3、將所述所有現有各投注組合的標識進行排列,分別針對各標識,逐一列出計算出該標識的所有投注組合的鍊表,以組成查找序列;
B、將本次所選獎池依據本次所選串關數進行累加,計算當前投注組合的標識;
C、依據所述當前投注組合的標識,在步驟A3所建立的查找序列中查找出當前投注組合。
由上,將當前投注組合以串關數和獎池為計算依據進行標識,將相同計算結果的不同投注組合進行排序,從而可以在數量巨大的投注組合中快速查找出當前投注組合。
可選的,步驟A2包括:
預先設定一組彼此不相同的質數primeq;
計算得出現有各投注組合的標識包括:式中hash_value_p表示當前投注組合的標識;m_pool_idq表示當前投注組合中各獎池的序號,1≤q≤e;e表示當前投注組合的串關數,primeq表示質數的序號。
由上,採用不同質數與獎池乘積,再結合串關數,可以儘量多的區分出不同的投注組合,以分別進行標識,從而可以在數量巨大的投注組合中快速查找出當前投注組合。
可選的,當所述q取值為1時,對應的質數prime1=1。
由上,噹噹前投注組合為單關時,在計算過程中不需要考慮質數因素,從而可以在一定程度上降低運算量,從而進一步提高查找速度。
可選的,所述獎池和所述各投注組合的標識分別按一定數值取模。
可選的,所述獎池按1024取模,所述各投注組合的標識按1000000取模。
由上,通過取模的方式限定計算數量,雖然在一定程度上降低了查找速度,但是取模後可以降低存儲成本,以百萬投注組合為例,一個投注組合的存儲地址佔用8位元組,總共僅需佔用8M存儲空間。
可選的,噹噹前投注組合併不在步驟A3所建立的查找序列時,依據當前投注組合的標識,將當前投注組合添加於該標識的查找序列。
可選的,步驟C後包括,查找出當前投注組合後,利用計數器對統計數據進行累加更新。
附圖說明
圖1為本發明的流程圖。
具體實施方式
本發明所述一種實時快速查找投注組合的方法,在現有已銷售的所有投注組合中快速查找出當前所銷售的投注組合。
在投注競彩領域中,包含獎池以及投注組合等概念,所述獎池表示任意包含兩個以上投注選項的投註標的,如一場A球隊對陣B球隊比賽,競猜其比賽結果(勝、平、負),另一場為C球隊對陣D球隊的比賽,競猜其比賽結果,那麼上述兩場比賽分別為兩個獎池。各獎池用一個唯一整型數值pool_id進行標識,pool_id按在系統中生成的時間順序以步長1遞增。
投注組合表示多個獎池進行串關投注。本實施例中,最少為1個獎池,例如僅競猜一場比賽,該類投注組合為單關;最多為8個獎池,例如同時競猜8場比賽,該類投注組合為8串1。
如圖1所示為本發明的流程圖,包括以下步驟:
S10:依據當前的投注組合,計算出代表其標識hash_value。
一般來說,競彩預售期約1周,同時在售獎池數約為1000個。基於此,對在售的獎池按1024取模,得出m_pool_idn,作為各個獎池的序號分配給各個獎池,n表示當前獎池的序號,n取值為1~1024。
上述分配方式可以儘可能的保證每一個序號代表唯一獎池,降低同一序號代表多個獎池的可能性,從而在後期計算時可以提高查找速度,具體原理將在後文詳述。不難理解,當投注選項更多時,以足球比賽為例,假如增加競猜比分、總進球數、角球數甚至紅黃牌數等等獎池時,還可對獎池按2048、4096等取模。
獲取當前的投注組合各個獎池的序號,即獲取各個獎池的m_pool_idn,由於本實施例中的投注組合最多為8串1,基於此,預先設置8個彼此不同的質數,分別命名為prime1、prime2、……、prime8。實際使用中,還可依據串關數的增加,對應增加質數的數量,即prime1、prime2、……、primem,m表述質數的序號。
依據當前投注組合的串關數,計算得出當前投注組合的標識hash_value_p。
假如當前投注組合僅為單關,則hash_value_p=m_pool_id1*prime1;
假如當前投注組合為2串1,則hash_value_p=m_pool_id1*prime1+m_pool_id2*prime2;
依上述規律類推,當前投注組合為8串1時,則hash_value_p=m_pool_id1*prime1+m_pool_id2*prime2+……+m_pool_id8*prime8。
上述公式可以總結為:式中m_pool_idq表示當前投注組合中各獎池的序號(1≤q≤e),e表示當前投注組合串關數的最大值,也可以理解為串關數,primeq表示質數的序號。依據公式原理不難理解,q實質為串關數。
較佳的,還可對上述公式進行優化,當q取值為1時,對應的質數prime1=1。由於在單關時,僅包含一個獎池,故無需設置質數,由此可以較少運算量。由上述公式可以看出,設置多個彼此不同的質數的目的在於,可以降低所計算出的hash_value_p數值相同的可能性。使同一hash_value_p對應更少的投注組合。
對所計算出的hash_value_p按100萬取模,得出hash_value。這樣做的目的在於,使計算結果儘可能的對應至不同的投注組合,從而提高查找當前投注組合的速度。不難理解,當獎池的數量增多以後,hash_value_p可以按千萬乃至億取模。
S20:建立所有已有投注組合的查找序列。
如下表1所示,針對已有的hash_value,按100萬取模,並建立查找序列,分別將hash_value記為序號0~999999,並將不同的hash_value存儲於不同的地址,地址分別表示為地址1~地址999999,即表1中的縱向列表。
下面以hash_value值序號為1為例進行說明,從表1給出的例子可見,hash_value值序號為1時,其投注組合鍊表中共包括4組「投注組合KEY」,分別表示為①、②、③、④,即表1中序號為1所對應的橫向列表。其中,「投注組合KEY」表示現存共有4種投注組合計算出來的hash_value值相同,包括各投注組合的串關數(單關、2串1、3串1、……、8串1)、各關的獎池以及計數器;「NEXT_LINK」表示序號為1的序列中下一節點(投注組合KEY)的地址。
表1
另外,在每組「投注組合KEY」中,還包括:「投注組合Data」(未圖示),表示各投注組合中各串關獎池的投注選項。例如A球隊對陣B球隊,競猜A球隊勝時,投注組合Data表示為3,A球隊平時表示為1,A球隊負時表示為0。
S30:依據步驟S20的查找序列,查找出當前投注組合,或將當前投注組合添加至所述查找序列。
將步驟10所計算的當前投注組合的hash_value值,在步驟20所建立的序列(表1)中縱向查找,以查找出該計算結果(hash_value值)是否已存在。例如步驟10所計算出當前投注組合的hash_value值序號為1,則進一步在在步驟20所建立的序列(表1)中找到hash_value值為1的投注組合鍊表,在其中查找是否已含有當前投注組合。
具體方法可包括:首先確定串關數。例如當前投注組合為2串1,則需查看hash_value值序號為1的投注組合鍊表中是否已有2串1的組合,若有,進一步確認在2串1的組合中是否與當前投注組合的獎池相同,若相同,則表示在hash_value值為1的鍊表中已有當前投注組合,在該投注組合的計數器中累加。
反之,噹噹前投注組合與表1中hash_value值序號為1的投注組合鍊表中現有的投注組合均不相同時(串關數、獎池數任一不相同即為與現有投注組合不同),將前投注組合作為「⑤投注組合KEY」,添加於hash_value值序號為1的投注組合鍊表中,並將計數器加1。
本發明根據投注組合數據的特點,計算出一個與全部投注組合大小相當,分布均勻的查找序列,利用hash_value作為投注組合數據鍊表的首地址,通過較少的數據比對便可迅速查找出當前投注組合,與現有技術需要在百萬級投注組合中通過逐一比較直至找到當前投注組合的技術方案相比,大大減少了比較次數,由其針對從巨大數據節點進行數據查找,提高了查找效率。
附表2是依據本發明所提供的方法,針對某一日銷售的所有投注組合(152萬個)進行查找的統計情況。
第一列「各hash_value對應投注組合鍊表的長度」表示計算出相同hash_value值的不同投注組合的數量,由表2可見,在100萬個hash_value值中,計算出相同hash_value值較多出現的是1~5種投注組合,計算出相同hash_value值最多為12種投注組合,且進出現一次。可見,採用本發明方法,在將各投注組合組建查詢列表時,排列較為分散,從而便於快速比較查詢。
第二列「出現次數」表示各hash_value對應投注組合鍊表的長度所出現的次數。
第三列「節點數」表示投注組合的數量,顯然,第三列為第一列與第二列的乘積。
第四列「在各hash_value下的平均比較次數」表示在已確認hash_value值後,從表1所示已有的查找序列中查找出當前投注組合所統計出的平均比較次數。
第五列「在各hash_value下的比較次數」表示在在已確認hash_value值後,從表1所示已有的查找序列中查找出當前投注組合的比較次數,即第五列為第三列與第四列的乘積。
第六列「平均比較次數」表示針對152萬個投注組合,找出當前投注組合所用的平均比較的次數。
從表中可見,在152萬個投注組合中找出當前投注組合平均僅需要不到2次比較即可,而極端情況下,最大比較次數僅為12。相比於現有技術少則20次的比較,提高查找速度至少達到10倍。
並且,本實施例中,建立如表1所示的投注組合的查找序列所佔存儲空間極小,以百萬投注組合為例,一個投注組合的存儲地址佔用8位元組,總共需佔用8M存儲空間。即便將投注組合以億計,總共需佔用800M存儲空間,在實現快速查找的前提下,可以節省存儲成本。
表2
以上所述僅為本發明的較佳實施例而已,並不用以限制本發明,凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。