文本糾錯方法、裝置及終端與流程
2023-05-30 01:59:11 2
本發明涉及自然語言處理領域,尤其涉及一種文本糾錯方法、裝置及終端。
背景技術:
文本糾錯是自然語言處理中的難題之一。中文文本錯誤主要有替換錯誤、多字錯誤和缺字錯誤。隨著各種拼音輸入法的廣泛使用,文本數據中廣泛存在音似詞替換錯誤,例如,「託運行李」被誤寫為「拖運行李」。錯詞的存在通常直接導致分詞錯誤,而分詞錯誤又使得文本的語義混亂,給文本處理帶來困難。
現有技術中,對於音似詞替換錯誤,需要進行查錯和糾錯處理。通常是基於混淆集進行查錯和糾錯,而混淆集的建立需要花費大量時間和人工進行維護,成本高且使用不便。
技術實現要素:
本發明解決的技術問題是如何提高對於文本中音似詞糾錯的簡便有效性。
為解決上述技術問題,本發明實施例提供一種文本糾錯方法,文本糾錯方法包括:
對待糾錯語料進行分詞,以得到單字串和詞串;對所述單字串中的至少一部分進行合併,以得到多個錯詞候選詞;將拼音相同的錯詞候選詞和詞串劃分至同一錯詞候選類;在每一錯詞候選類中,根據每一錯詞候選詞和每一詞串的成詞概率選取推薦詞,以用於文本糾錯。
可選的,所述對所述單字串中的至少一部分進行合併,以得到所述多個錯詞候選詞包括:如果相鄰兩個單字串的成詞概率均小於第一閾值,則將所述相鄰兩個單字串合併,以作為錯詞候選詞;和/或,如果所述單字串與相鄰詞串的成詞概率均小於所述第一閾值,則將所述單字串與所述相鄰詞串合併,以作為所述錯詞候選詞。
可選的,所述在每一錯詞候選類中,根據每一錯詞候選詞的成詞概率選取推薦詞包括:計算每一錯詞候選類中所有詞語兩兩之間的語義距離;如果兩個詞語之間的語義距離小於第二閾值,則將所述兩個詞語加入同一錯詞候選集,直至遍歷完所述所有詞語,以得到至少一個錯詞候選集;在每一錯詞候選集中,分別根據所述每一錯詞候選詞和/或所述每一詞串的成詞概率選取所述推薦詞。
可選的,所述如果兩個詞語之間的語義距離小於第二閾值,則將所述兩個詞語加入同一錯詞候選集,直至遍歷完所述所有詞語,以得到至少一個錯詞候選集之後還包括:如果遍歷完所述每一錯詞候選類中所述所有詞語後僅剩餘單個詞語,則剔除所述單個詞語。
可選的,所述對所述單字串中的至少一部分進行合併,以得到多個錯詞候選詞之後還包括:將所述多個錯詞候選詞和所述詞串轉化為對應的語義向量,以用於計算所述每一錯詞候選類中所述所有詞語兩兩之間的語義距離。
可選的,所述在每一錯詞候選集中,分別根據每一錯詞候選詞和/或所述每一詞串的成詞概率選取推薦詞包括:在所述至少一個錯詞候選集中,分別選取成詞概率最大的詞語作為所述推薦詞。
可選的,在進行文本糾錯之後還包括:獲取文本糾錯的準確率;當所述準確率小於預設值時,調整所述第一閾值和/或所述第二閾值,重新進行文本糾錯,直至所述準確率大於或等於所述預設值。
可選的,採用以下方式進行文本糾錯:利用所述推薦詞替換對應的所述錯詞候選集中所述推薦詞之外的其他詞。
可選的,對所述待糾錯語料進行分詞之前還包括:對所述待糾錯語料進行預處理,以得到格式統一的所述待糾錯語料。
可選的,所述對所述待糾錯語料進行預處理之後還包括:找出所述待糾錯語料中的新詞,並加入分詞詞典,對所述待糾錯語料進行分詞是基於所述分詞詞典完成的。
為解決上述技術問題,本發明實施例還公開了一種文本糾錯裝置,文本糾錯裝置包括:
分詞單元,適於對待糾錯語料進行分詞,以得到單字串和詞串;合併單元,適於對所述單字串中的至少一部分進行合併,以得到多個錯詞候選詞;錯詞候選類劃分單元,適於將拼音相同的錯詞候選詞和詞串劃分至同一錯詞候選類;推薦詞選取單元,適於在每一錯詞候選類中,根據每一錯詞候選詞和每一詞串的成詞概率選取推薦詞;糾錯處理單元,用於根據所述推薦詞進行文本糾錯。
可選的,所述合併單元在相鄰兩個單字串的成詞概率均小於第一閾值時,將所述相鄰兩個單字串合併,以作為錯詞候選詞;和/或,在所述單字串與相鄰詞串的成詞概率均小於所述第一閾值時,將所述單字串與所述相鄰詞串合併,以作為所述錯詞候選詞。
可選的,所述推薦詞選取單元包括:語義距離計算子單元,適於計算每一錯詞候選類中所有詞語兩兩之間的語義距離;錯詞候選集獲取子單元,適於在兩個詞語之間的語義距離小於第二閾值時,將所述兩個詞語加入同一錯詞候選集,直至遍歷完所述所有詞語,以得到至少一個錯詞候選集;選擇子單元,適於在每一錯詞候選集中,分別根據每一錯詞候選詞和/或所述每一詞串的成詞概率選取所述推薦詞。
可選的,所述文本糾錯裝置還包括:剔除子單元,適於在遍歷完所述每一錯詞候選類所述所有詞語後僅剩餘單個詞語時,剔除所述單個詞語。
可選的,所述文本糾錯裝置還包括:語義向量獲取單元,適於將所述多個錯詞候選詞和所述詞串轉化為對應的語義向量,以用於所述語義距離計算子單元計算所述每一錯詞候選類中所有詞語兩兩之間的語義距離。
可選的,所述選擇子單元在所述至少一個錯詞候選集中,分別選取成詞概率最大的詞語作為所述推薦詞。
可選的,所述文本糾錯裝置還包括:準確率獲取單元,適於獲取文本糾錯的準確率;調整單元,適於在所述準確率小於預設值時,調整所述第一閾值和/或所述第二閾值時,重新進行文本糾錯,直至所述準確率大於或等於所述預設值。
可選的,所述文本糾錯裝置還包括:預處理單元,適於對所述待糾錯語料進行預處理,以得到格式統一的所述待糾錯語料。
可選的,所述文本糾錯裝置還包括:新詞發現單元,適於找出所述待糾錯語料中的新詞,並加入分詞詞典,所述分詞單元對所述待糾錯語料進行分詞是基於所述分詞詞典完成的。
可選的,所述糾錯處理單元採用以下方式進行文本糾錯:利用所述推薦詞替換對應的所述錯詞候選集中所述推薦詞之外的其他詞。
為解決上述技術問題,本發明實施例還公開了一種終端,所述終端包括所述文本糾錯裝置。
與現有技術相比,本發明實施例的技術方案具有以下有益效果:
本發明技術方案首先對待糾錯語料進行分詞,以得到單字串和詞串;然後對所述單字串中的至少一部分進行合併,以得到多個錯詞候選詞;再將拼音相同的錯詞候選詞和詞串劃分至同一錯詞候選類;最後在每一錯詞候選類中,根據每一錯詞候選詞和每一詞串的成詞概率選取推薦詞,以用於文本糾錯。在文本出現音似詞替換錯誤的情況下,由於錯誤的音似詞在分詞時會被分為多個字,因此本發明技術方案對分詞得到的單字串的至少一部分進行了合併,得到多個錯詞候選詞,以便於與拼音相同的詞串建立錯詞候選類,基於成詞概率在錯詞候選類中選取推薦詞,該推薦詞為錯誤音似詞的正確詞,從而完成文本糾錯;進而可以簡便且有效地自動找出錯詞並給出糾錯建議,同時避免了建立混淆集以及花費大量時間和人工進行維護的問題,提高了文本糾錯的效率。
進一步,計算每一錯詞候選類中所有詞語兩兩之間的語義距離;如果兩個詞語之間的語義距離小於第二閾值,則將所述兩個詞語加入同一錯詞候選集,直至遍歷完所述所有詞語,以得到至少一個錯詞候選集;在每一錯詞候選集中,分別根據所述每一錯詞候選詞和/或所述每一詞串的成詞概率選取所述推薦詞。本發明技術方案在錯詞候選類的基礎上根據語義距離建立錯詞候選集,使得語義相近的詞語可以處於同一集合中;然後在錯詞候選集中根據成詞概率選取推薦詞,在語義相近的集合中選取成詞概率最大的詞語作為推薦詞,進一步提高了文本糾錯的準確率。
附圖說明
圖1是本發明實施例一種文本糾錯方法的流程圖;
圖2是本發明實施例另一種文本糾錯方法的流程圖;
圖3是本發明實施例一種文本糾錯裝置的結構示意圖;
圖4是本發明實施例另一種文本糾錯裝置的結構示意圖。
具體實施方式
如背景技術中所述,現有技術對於音似詞替換錯誤,需要進行查錯和糾錯處理。通常是基於混淆集進行查錯和糾錯,而混淆集的建立需要花費大量時間和人工進行維護,成本高且使用不便。
在文本出現音似詞替換錯誤的情況下,由於錯誤的音似詞在分詞時會被分為多個字,因此本發明技術方案對分詞得到的單字串的至少一部分進行了合併,得到多個錯詞候選詞,以便於與拼音相同的詞串建立錯詞候選類,基於成詞概率在錯詞候選類中選取推薦詞,該推薦詞為錯誤音似詞的正確詞,從而完成文本糾錯;進而可以簡便且有效地自動找出錯詞並給出糾錯建議,成本低,同時避免了建立混淆集以及花費大量時間和人工進行維護的問題,提高了文本糾錯的效率。
為使本發明的上述目的、特徵和優點能夠更為明顯易懂,下面結合附圖對本發明的具體實施例做詳細的說明。
圖1是本發明實施例一種文本糾錯方法的流程圖。
圖1所示的文本糾錯方法可以包括以下步驟:
步驟S101:對待糾錯語料進行分詞,以得到單字串和詞串;
步驟S102:對所述單字串中的至少一部分進行合併,以得到多個錯詞候選詞;
步驟S103:將拼音相同的錯詞候選詞和詞串劃分至同一錯詞候選類;
步驟S104:在每一錯詞候選類中,根據每一錯詞候選詞和每一詞串的成詞概率選取推薦詞,以用於文本糾錯。
具體實施中,在步驟S101中,對待糾錯語料進行分詞,可以得到多個單字串和多個詞串。具體而言,待糾錯語料可以包括一個或多個文本。對待糾錯語料進行分詞可以基於分詞詞典來完成。
可以理解的是,分詞詞典可以是任意可實施的類型,本發明實施例對此不做限制。
具體實施中,考慮到在文本出現音似詞替換錯誤的情況,由於錯誤的音似詞在分詞時會被分為多個字(也就是單字串),因此在步驟S102中,對分詞得到的單字串的至少一部分進行了合併,以得到多個錯詞候選詞。也就是說,正確詞在步驟S101中的分詞操作中會被分為一個詞,而該正確詞的錯誤音似詞在步驟S101中的分詞操作中可能會被分為多個單字串,故在步驟S102中對多個單字串的至少一部分進行了合併。
具體實施中,在步驟S103中,將拼音相同的錯詞候選詞和詞串劃分至同一錯詞候選類。也就是說,同一錯詞候選類中的詞語拼音相同,以便後續步驟在拼音相同的詞語中確定出正確詞和錯誤音似詞。具體地,可以利用漢字轉拼音工具將錯詞候選詞和詞串轉換為對應的拼音。
具體實施中,在步驟S104中,在每一錯詞候選類中,根據每一錯詞候選詞和每一詞串的成詞概率選取推薦詞,以用於文本糾錯。也就是說,在步驟S103中確定的拼音相同的詞語(也就是每一錯詞候選類)中,根據上述成詞概率選取推薦詞(也就是正確詞),則該錯詞候選類中的其他詞為錯誤音似詞。具體而言,可以選取成詞概率最大的詞語作為所述推薦詞。
進一步而言,錯詞候選詞和詞串的成詞概率可以是預先獲取或計算得到的。
具體地,錯詞候選類中所有詞語的成詞概率可以預先根據漢語語言模型N-Gram計算得到。具體而言,可以採用bi-gram語言模型或Tri-Gram語言模型。採用bi-gram語言模型時,一個單字串的出現僅依賴於其前面出現的一個單字串。進一步而言,可以計算領域內分詞語料中每個單字串的成詞概率和詞語的概率,並利用bi-gram語言模型,對已知分詞語料中的所有單字串分別計算其與其他單字串的成詞概率,以得到錯詞候選類中所有詞語的成詞概率。
需要說明的是,計算詞語的成詞概率的方式可以採用其他任意可實施的算法或語言模型,本發明實施例對此不做限制。
本領域技術人員應當理解的是,也可以根據每一錯詞候選詞和每一詞串的共現概率選取推薦詞。詞語的成詞概率可以表示該詞語包括的單字之間成詞的概率;而詞語的共現概率可以表示該詞語包括的單字之間共同出現的概率,故可以根據成詞概率和/或共現概率在錯詞候選類中確定推薦詞。還可以根據其他任意可實施的概率在錯詞候選類中確定推薦詞,本發明實施例對此不做限制。
本發明實施例對分詞得到的單字串的至少一部分進行了合併,得到多個錯詞候選詞,以便於錯詞候選詞與拼音相同的詞串建立錯詞候選類,基於成詞概率在錯詞候選類中選取推薦詞,該推薦詞為錯誤音似詞的正確詞,從而完成文本糾錯;本實施例可以簡便且有效地自動找出錯詞並給出糾錯建議,成本低,同時避免了建立混淆集以及花費大量時間和人工進行維護的問題,提高了文本糾錯的效率。
具體實施中,步驟S102可以包括以下步驟:如果相鄰兩個單字串的成詞概率均小於第一閾值,則將所述相鄰兩個單字串合併,以作為錯詞候選詞;和/或,如果所述單字串與相鄰詞串的成詞概率均小於所述第一閾值,則將所述單字串與所述相鄰詞串合併,以作為所述錯詞候選詞。也就是說,在文本出現音似詞替換錯誤的情況下,由於錯誤的音似詞在分詞時會被分為多個字(也就是單字串)或單字串與詞串,因此在步驟S102中對分詞得到的單字串的至少一部分進行合併時,合併方式是將兩個單字串合併和/或將單字串與詞串合併。進一步而言,將成詞概率均小於第一閾值的相鄰兩個單字串進行合併;和/或,將成詞概率均小於所述第一閾值的單字串與相鄰詞串進行合併;也可以是將成詞概率小於第一閾值的單字串和在成詞語料中不存在的相鄰詞串進行合併。
具體地,單字串和詞串的成詞概率可以預先根據分詞語料進行統計得到。也即,在分詞語料中統計單字串的數量和詞串的數量,並基於單字串的數量和詞串的數量以及總數量,來估計單字串和詞串的成詞概率。
需要說明的是,所述第一閾值可以根據實際的應用場景進行自定義配置和適應性的修改,本發明實施例對此不做限制。
優選的,文本糾錯方法還可以包括以下步驟:對所述待糾錯語料進行預處理,以得到格式統一的所述待糾錯語料。具體地,格式統一的待糾錯語料可以是文本格式,以便於步驟S101對格式統一的待糾錯語料進行分詞處理。進一步而言,預處理過程可以包括以下步驟:將待糾錯語料轉換為文本格式,以得到文本數據;對所述文本數據過濾預設詞,其中所述預設詞為以下一種或多種:髒詞、敏感詞和停用詞;將過濾後的所述文本數據按照標點進行劃分。更具體地,可以將過濾後的文本數據按指示句子結尾的標點,例如,「?」、「!」和「。」分割成行並保存。本實施例的預處理可以為後續步驟的操作提供便捷。
優選地,對所述待糾錯語料進行預處理之後還可以包括以下步驟:找出所述待糾錯語料中的新詞,並加入分詞詞典,對所述待糾錯語料進行分詞是基於所述分詞詞典完成的。本實施例通過找出新詞並加入分詞詞典,以避免利用分詞詞典分詞時將新詞進行分詞,進而避免將新詞作為錯誤音似詞,進一步提高了文本糾錯的準確率。具體而言,可以利用已有的新詞發現工具找出待糾錯語料的新詞候選詞,經人工過濾後加入分詞詞典。
本發明一優選實施例中,步驟S103可以包括以下步驟:計算每一錯詞候選類中所有詞語兩兩之間的語義距離;如果兩個詞語之間的語義距離小於第二閾值,則將所述兩個詞語加入同一錯詞候選集,直至遍歷完所述所有詞語,以得到至少一個錯詞候選集;在每一錯詞候選集中,分別根據所述每一錯詞候選詞和/或所述每一詞串的成詞概率選取所述推薦詞。也就是說,在錯詞候選類的基礎上根據語義距離建立錯詞候選集,使得語義相近的詞語可以處於同一集合中;然後在錯詞候選集中根據成詞概率選取推薦詞,在語義相近的集合中選取成詞概率最大的詞語作為推薦詞,進一步提高了文本糾錯的準確率。
可以理解的是,所述第二閾值可以根據實際的應用場景進行自定義配置和適應性的修改,本發明實施例對此不做限制。
具體而言,如果遍歷完所述每一錯詞候選類中所述所有詞語後僅剩餘單個詞語,則剔除所述單個詞語。也就是說,在每一錯詞候選類中建立至少一個錯詞候選集後,如果該錯詞候選類中剩餘單個詞語未能加入任一錯詞候選集,表示該單個詞語不存在同義的詞語,則不能夠採用音似詞糾錯的方式判定其是否為錯詞,故將該單個詞語剔除。
具體實施中,在得到多個錯詞候選詞之後還可以包括:將所述多個錯詞候選詞和所述詞串轉化為對應的語義向量,以用於計算所述每一錯詞候選類中所述所有詞語兩兩之間的語義距離。具體而言,可以將包括錯詞候選詞和詞串的分詞結果輸入word2vector模型,以得到各個詞的語義向量。更進一步地,由於錯誤音似詞和其對應的正確詞的上下文語境相同,因此可以利用word2vector模型將同音詞語按照語義進行聚類,例如,「記錄、紀錄、計錄」,同一錯詞候選集中的詞語為拼音相同且語義相似的詞語。
可以理解的是,得到語義向量的方式也可以是其他任意可實施的方式,本發明實施例對此不做限制。
具體實施中,在步驟S104中,在所述至少一個錯詞候選集中,分別選取成詞概率最大的詞語作為所述推薦詞。也就是說,當詞語的成詞概率最大時,表明該詞語包括的多個單字串之間成詞的概率大,相較於該錯詞候選集中的其他詞語,該詞語為正確詞的概率最大,故將其作為推薦詞。
例如,在錯詞候選集「記錄、紀錄、計錄」中,該錯詞候選集中的多個詞語具有共同的字「錄」,則比較該共同的字「錄」與其他各個字「記、紀、計」的成詞概率,其中,成詞概率最大的詞語為推薦詞,其他為錯詞;在錯詞候選集「澳洲、奧州」中,該錯詞候選集中的多個詞語不具有共同的字,則分別根據各個詞中第一個字和第二個字的成詞概率,也即「澳」和「洲」的成詞概率,以及「奧」和「州」的成詞概率,成詞概率大的詞語為推薦詞,其他為錯詞。
具體地,錯詞候選集中所有詞語的成詞概率可以預先根據漢語語言模型N-Gram計算得到。具體而言,可以採用bi-gram語言模型或Tri-Gram語言模型。採用bi-gram語言模型時,一個單字串的出現僅依賴於其前面出現的一個單字串。進一步而言,可以計算領域內分詞語料中每個單字串的成詞概率和詞語的概率,並利用bi-gram語言模型,對已知分詞語料中的所有單字串分別計算其與其他單字串的成詞概率,以得到錯詞候選集中所有詞語的成詞概率。
需要說明的是,計算詞語的成詞概率的方式可以採用其他任意可實施的算法或語言模型,本發明實施例對此不做限制。
具體實施中,文本糾錯方法還可以包括以下步驟:獲取文本糾錯的準確率;當所述準確率小於預設值時,調整所述第一閾值和/或所述第二閾值,重新進行文本糾錯,直至所述準確率大於或等於所述預設值。經過準確率調整後的文本糾錯方法可以進一步提高文本糾錯的準確性和效率。
需要說明的是,所述預設值可以根據實際的應用場景進行自定義配置和適應性的修改,本發明實施例對此不做限制。
具體實施中,可以採用以下方式進行文本糾錯:利用所述推薦詞替換對應的所述錯詞候選集中所述推薦詞之外的其他詞。也即將錯詞候選集中的錯誤音似詞全部替換為正確詞,實現文本糾錯。
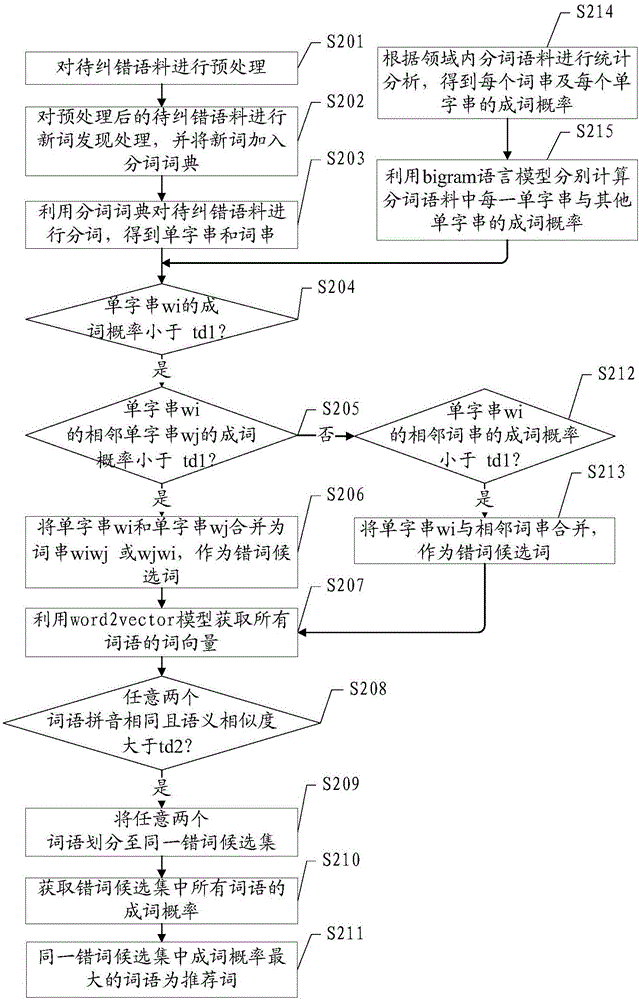
本發明一優選實施例中,文本糾錯方法可參照圖2,圖2是本發明實施例另一種文本糾錯方法的流程圖。
本領域技術人員應當理解的是,本實施例中單字串wi和相鄰單字串wj僅用於指代單字串,不構成對本發明實施例的限制。
圖2所示的文本糾錯方法可以包括以下步驟:
步驟S201:對待糾錯語料進行預處理;
步驟S202:對預處理後的待糾錯語料進行新詞發現處理,並將新詞加入分詞詞典;
步驟S203:利用分詞詞典對待糾錯語料進行分詞,得到單字串和詞串;
步驟S204:判斷單字串wi的成詞概率是否小於td1?如果是,則進入步驟S205;否則無操作;
步驟S205:判斷單字串wi的相鄰單字串wj的成詞概率是否小於td1,如果是,則進入步驟S206;否則進入步驟S212;
步驟S206:將單字串wi和單字串wj合併為詞串wiwj或wjwi,作為錯詞候選詞;
步驟S207:利用word2vector模型獲取所有詞語的詞向量;
步驟S208:判斷任意兩個詞語是否拼音相同且語義相似度大於td2,如果是,則進入步驟S209;否則無操作;
步驟S209:將任意兩個詞語劃分至同一錯詞候選集;
步驟S210:獲取錯詞候選集中所有詞語的成詞概率;
步驟S211:同一錯詞候選集中成詞概率最大的詞語為推薦詞;
步驟S212:判斷單字串wi的相鄰詞串的成詞概率是否小於td1,如果是,則進入步驟S213;否則無操作;
步驟S213:將單字串wi與相鄰詞串合併,作為錯詞候選詞;
步驟S214:根據領域內分詞語料進行統計分析,得到每個詞串及每個單字串的成詞概率;
步驟S215:利用bi-gram語言模型分別計算分詞語料中每一單字串與其他單字串的成詞概率。
具體實施中,在步驟S201中,對待糾錯語料進行預處理,可以得到格式統一的所述待糾錯語料。具體地,格式統一的待糾錯語料可以是文本格式,以便於後續步驟對格式統一的待糾錯語料進行分詞處理。進一步而言,步驟S201可以包括以下步驟:將待糾錯語料轉換為文本格式,以得到文本數據;對所述文本數據過濾預設詞,其中所述預設詞為以下一種或多種:髒詞、敏感詞和停用詞;將過濾後的所述文本數據按照標點進行劃分。更具體地,可以將過濾後的文本數據按指示句子結尾的標點,例如,「?」、「!」和「。」分割成行並保存。本實施例的預處理可以為後續步驟的操作提供便捷。
具體實施中,在步驟S202中,通過找出新詞並加入分詞詞典,可以避免在步驟S203中利用分詞詞典分詞時將新詞進行分詞,進而避免將新詞作為錯誤音似詞,進一步提高了文本糾錯的準確率。具體而言,可以利用已有的新詞發現工具找出待糾錯語料的新詞候選詞,經人工過濾後加入分詞詞典。
具體實施中,經步驟S203分詞得到單字串和詞串後,在步驟S204中,判斷單字串wi的成詞概率是否小於td1,如果是,則在步驟S205和步驟S206中,將單字串wi和成詞概率小於td1的相鄰單字串wj合併為詞串wiwj或wjwi;或者,在步驟S212和步驟S213中,將單字串wi和成詞概率小於td1的相鄰詞串進行合併;也可以是將單字串wi和在成詞語料中不存在的相鄰詞串進行合併,合併後的詞語都作為錯詞候選詞。也就是說,在文本出現音似詞替換錯誤的情況下,由於錯誤的音似詞在分詞時會被分為多個字(也就是單字串)或單字串與詞串,因此首先處理待糾錯語料分詞後出現的單字串,也就是對分詞得到的單字串的至少一部分進行合併,合併方式是將兩個單字串合併和/或將單字串與詞串合併,作為錯詞候選詞。
需要說明的是,td1的值可以根據實際的應用場景進行自定義配置和適應性的修改,本發明實施例對此不做。
具體實施中,在步驟S207中,所有詞語包括詞串和錯詞候選詞。具體地,可以將錯詞候選詞替換合併前的兩個相鄰單字串和/或將相鄰單字串與詞串,以便用於在步驟S207中計算錯詞候選詞的詞向量。更具體地,將步驟S206得到的分詞數據輸入word2vector模型,得到所有詞語的語義向量。
具體實施中,在步驟S208和步驟S209中,將拼音相同且語義相似度大於td2的詞語劃分至同一錯詞候選集。具體地,可以利用漢字轉拼音工具將錯詞候選詞和詞串轉換為對應的拼音,並將拼音相同的詞語作為同一錯詞候選類。然後,利用語義距離將每一錯詞候選類劃分為多個錯詞候選集,即分別依次計算每個錯詞候選類中的兩兩詞語之間的語義相似度(也即語義距離),如果語義相似度大於td2,則歸為同一錯詞候選集,剩餘的單個詞語捨棄掉(也即即沒有錯詞對)。也就是說,考慮到錯誤音似詞和其對應的正確詞的上下文語境相同,因此可以利用word2vector模型將同音詞語進行聚類,同一錯詞候選集中的詞語為同音同義詞語,例如,記錄、紀錄、計錄。
需要說明的是,td2的值可以根據實際的應用場景進行自定義配置和適應性的修改,本發明實施例對此不做。
具體實施中,在步驟S210和步驟S211中,獲取每一錯詞候選集中所有詞語的成詞概率,並選取每一錯詞候選集中成詞概率最大的詞語作為所述推薦詞。也就是說,當詞語的成詞概率最大時,表明該詞語包括的多個單字串之間成詞的概率大,相較於該錯詞候選集中的其他詞語,該詞語為正確詞的概率最大,故將其作為推薦詞。
例如,得到多個錯詞候選集:(記錄、紀錄、計錄)、(壓金、押金)、(奧州、澳洲)。錯詞候選集(記錄、紀錄、計錄)分別具有共同的字「錄」,獲取得到「錄」與其他三個字「計」、「紀」、「記」的成詞概率分別為p1、p2、p3,如果p3最大,則推薦詞為「記錄」,其他兩個詞語為錯詞。錯詞候選集(壓金、押金)依此類推。錯詞候選集(奧州、澳洲)不具有共同的字,獲取得到「奧」和「州」的成詞概率為p4、「澳」和「洲」的成詞概率為p5,如果p5>p4,則「澳洲」為推薦詞,「奧州」為錯詞。
具體地,在步驟S211之後,可以判斷推薦詞的正確性,如果推薦詞正確的話,則將推薦詞所在的錯詞候選集加入錯字對詞典,以便應用錯詞對詞典進行糾錯。
優選地,圖2所示的文本糾錯方法可以包括步驟S214和步驟S215。在步驟S214和步驟S215中,可以預先根據已標記的領域內分詞語料進行統計得到單字串和詞串的成詞概率。也即,在分詞語料中統計單字串的數量和詞串的數量,並基於單字串的數量和詞串的數量以及總數量,來估計單字串和詞串的成詞概率。然後,利用bi-gram語言模型,對現有已標記的領域內分詞語料中的所有單字串,分別計算每一單字串與其他單字串的成詞概率,以使在步驟S210中可以據此獲取每個錯詞候選詞的成詞概率。
優選地,在步驟S211之後,還可以獲取文本糾錯的準確率;當所述準確率小於預設值時,調整所述第一閾值和/或所述第二閾值,重新進行文本糾錯,直至所述準確率大於或等於所述預設值。
本發明實施例的具體實施方式和技術效果可參照圖1所示的文本糾錯方法的實施例,此處不再贅述。
在具體的應用場景中,待糾錯語料可以是用戶問題數據。在用戶問題數據中,同音詞替換錯誤普遍存在,故可以採用圖1或圖2所示的文本糾錯方法對用戶問題數據中的錯誤同音詞進行糾正。
圖3是本發明實施例一種文本糾錯裝置的結構示意圖。
圖3所示的文本糾錯裝置30可以包括:分詞單元301、合併單元302、錯詞候選類劃分單元303、推薦詞選取單元304和糾錯處理單元305。
其中,分詞單元301適於對待糾錯語料進行分詞,以得到單字串和詞串;合併單元302適於對所述單字串中的至少一部分進行合併,以得到多個錯詞候選詞;錯詞候選類劃分單元303適於將拼音相同的錯詞候選詞和詞串劃分至同一錯詞候選類;推薦詞選取單元304適於在每一錯詞候選類中,根據每一錯詞候選詞和每一詞串的成詞概率選取推薦詞;糾錯處理單元305用於根據所述推薦詞進行文本糾錯。
具體實施中,由於正確詞在分詞單元301中會被分為一個詞,而該正確詞的錯誤音似詞在分詞單元301中可能會被分為多個單字串,故合併單元302對多個單字串的至少一部分進行了合併。合併單元302在相鄰兩個單字串的成詞概率均小於第一閾值時,將所述相鄰兩個單字串合併,以作為錯詞候選詞;和/或,在所述單字串與相鄰詞串的成詞概率均小於所述第一閾值時,將所述單字串與所述相鄰詞串合併,以作為所述錯詞候選詞;也可以是將成詞概率小於第一閾值的單字串和在成詞語料中不存在的相鄰詞串進行合併。
具體實施中,錯詞候選類劃分單元303將拼音相同的錯詞候選詞和詞串劃分至同一錯詞候選類。也就是說,同一錯詞候選類中的詞語拼音相同,以便後續步驟在拼音相同的詞語中確定出正確詞和錯誤音似詞。具體地,可以利用漢字轉拼音工具將錯詞候選詞和詞串轉換為對應的拼音。
具體實施中,在每一錯詞候選類中,推薦詞選取單元304根據每一錯詞候選詞和每一詞串的成詞概率選取推薦詞,以用於文本糾錯。也就是說,錯詞候選類劃分單元303確定的拼音相同的詞語(也就是每一錯詞候選類)中,根據上述成詞概率選取推薦詞(也就是正確詞),則該錯詞候選類中的其他詞為錯誤音似詞。具體而言,可以選取成詞概率最大的詞語作為所述推薦詞。
進一步而言,錯詞候選詞和詞串的成詞概率可以是預先獲取得到的。
具體地,錯詞候選類中所有詞語的成詞概率可以預先根據漢語語言模型N-Gram計算得到。具體而言,可以採用bi-gram語言模型或Tri-Gram語言模型。採用bi-gram語言模型時,一個單字串的出現僅依賴於其前面出現的一個單字串。進一步而言,可以計算領域內分詞語料中每個單字串的成詞概率和詞語的概率,並利用bi-gram語言模型,對已知分詞語料中的所有單字串分別計算其與其他單字串的成詞概率,以得到錯詞候選類中所有詞語的成詞概率。
需要說明的是,計算詞語的成詞概率的方式可以採用其他任意可實施的算法或語言模型,本發明實施例對此不做限制。
具體實施中,糾錯處理單元305可以採用以下方式進行文本糾錯:利用所述推薦詞替換對應的所述錯詞候選集中所述推薦詞之外的其他詞。也即將錯詞候選集中的錯誤音似詞全部替換為正確詞,實現文本糾錯。
本領域技術人員應當理解的是,也可以根據每一錯詞候選詞和每一詞串的共現概率選取推薦詞。詞語的成詞概率可以表示該詞語包括的單字之間成詞的概率;而詞語的共現概率可以表示該詞語包括的單字之間共同出現的概率,故可以根據成詞概率和/或共現概率在錯詞候選類中確定推薦詞。還可以根據其他任意可實施的概率在錯詞候選類中確定推薦詞,本發明實施例對此不做限制。
本發明實施例對分詞得到的單字串的至少一部分進行了合併,得到多個錯詞候選詞,以便於錯詞候選詞與拼音相同的詞串建立錯詞候選類,基於成詞概率在錯詞候選類中選取推薦詞,該推薦詞為錯誤音似詞的正確詞,從而完成文本糾錯;本實施例可以簡便且有效地自動找出錯詞並給出糾錯建議,成本低,同時避免了建立混淆集以及花費大量時間和人工進行維護的問題,提高了文本糾錯的效率。
圖3所示的文本糾錯裝置30還可以包括:準確率獲取單元(圖未示)和調整單元(圖未示)。其中,準確率獲取單元適於獲取文本糾錯的準確率;調整單元適於在所述準確率小於預設值時,調整所述第一閾值和/或所述第二閾值時,重新進行文本糾錯,直至所述準確率大於或等於所述預設值。
需要說明的是,所述預設值可以根據實際的應用場景進行自定義配置和適應性的修改,本發明實施例對此不做限制。
本發明實施例的具體實施方式和技術效果可參照圖1和圖2所示的文本糾錯方法的實施例,此處不再贅述。
本發明一優選實施例中,文本糾錯裝置40的結構可參照圖4,圖4是本發明實施例另一種文本糾錯裝置的結構示意圖。
文本糾錯裝置40可以包括預處理單元401、新詞發現單元402、合併單元403、語義向量獲取單元404、錯詞候選類劃分單元405、推薦詞選取單元406、其中,推薦詞選取單元406可以包括語義距離計算子單元4061、錯詞候選集獲取子單元4062、選擇子單元4063和剔除子單元4064。
其中,預處理單元401適於對所述待糾錯語料進行預處理,以得到格式統一的所述待糾錯語料。
新詞發現單元402適於找出所述待糾錯語料中的新詞,並加入分詞詞典,所述分詞單元對所述待糾錯語料進行分詞是基於所述分詞詞典完成的。本實施例通過找出新詞並加入分詞詞典,以避免利用分詞詞典分詞時將新詞進行分詞,進而避免將新詞作為錯誤音似詞,進一步提高了文本糾錯的準確率。具體而言,可以利用已有的新詞發現工具找出待糾錯語料的新詞候選詞,經人工過濾後加入分詞詞典。
具體實施中,語義向量獲取單元404適於將所述多個錯詞候選詞和所述詞串轉化為對應的語義向量,以用於所述語義距離計算子單元4061計算所述每一錯詞候選類中所有詞語兩兩之間的語義距離。
具體實施中,推薦詞選取單元406可以在每一錯詞候選類中,根據每一錯詞候選詞和每一詞串的成詞概率選取推薦詞。具體而言,語義距離計算子單元4061適於計算每一錯詞候選類中所有詞語兩兩之間的語義距離;錯詞候選集獲取子單元4062適於在兩個詞語之間的語義距離小於第二閾值時,將所述兩個詞語加入同一錯詞候選集,直至遍歷完所述所有詞語,以得到至少一個錯詞候選集;選擇子單元4063適於在每一錯詞候選集中,分別根據每一錯詞候選詞和/或所述每一詞串的成詞概率選取所述推薦詞。選擇子單元4063在所述至少一個錯詞候選集中,分別選取成詞概率最大的詞語作為所述推薦詞。
也就是說,在錯詞候選類的基礎上根據語義距離建立錯詞候選集,使得語義相近的詞語可以處於同一集合中;然後在錯詞候選集中根據成詞概率選取推薦詞,在語義相近的集合中選取成詞概率最大的詞語作為推薦詞,進一步提高了文本糾錯的準確率。
本發明實施例在錯詞候選類的基礎上根據語義距離建立錯詞候選集,使得語義相近的詞語可以處於同一集合中;然後在錯詞候選集中根據成詞概率選取推薦詞,在語義相近的集合中選取成詞概率最大的詞語作為推薦詞,進一步提高了文本糾錯的準確率。
進一步地,推薦詞選取單元406可以包括剔除子單元4064,剔除子單元4064適於在遍歷完所述每一錯詞候選類所述所有詞語後僅剩餘單個詞語時,剔除所述單個詞語。
圖4所示的文本糾錯裝置40還可以包括:準確率獲取單元(圖未示)和調整單元(圖未示)。其中,準確率獲取單元適於獲取文本糾錯的準確率;調整單元適於在所述準確率小於預設值時,調整所述第一閾值和/或所述第二閾值時,重新進行文本糾錯,直至所述準確率大於或等於所述預設值。
需要說明的是,所述預設值可以根據實際的應用場景進行自定義配置和適應性的修改,本發明實施例對此不做限制。
本發明實施例對分詞得到的單字串的至少一部分進行了合併,得到多個錯詞候選詞,以便於錯詞候選詞與拼音相同的詞串建立錯詞候選類,基於成詞概率在錯詞候選類中選取推薦詞,該推薦詞為錯誤音似詞的正確詞,從而完成文本糾錯;本實施例可以簡便且有效地自動找出錯詞並給出糾錯建議,成本低,同時避免了建立混淆集以及花費大量時間和人工進行維護的問題,提高了文本糾錯的效率。
本發明實施例的具體實施方式和技術效果可參照圖1和圖2所示的文本糾錯方法的實施例,此處不再贅述。
本發明實施例還公開了一種終端,所述終端可以包括圖3所示的文本糾錯裝置30或圖4所示的文本糾錯裝置40。文本糾錯裝置30或文本糾錯裝置40可以內部集成於所述終端,也可以外部耦接於所述終端。所述終端可以是機器人、智慧型手機、平板設備等。
本領域普通技術人員可以理解上述實施例的各種方法中的全部或部分步驟是可以通過程序來指令相關的硬體來完成,該程序可以存儲於以計算機可讀存儲介質中,存儲介質可以包括:ROM、RAM、磁碟或光碟等。
雖然本發明披露如上,但本發明並非限定於此。任何本領域技術人員,在不脫離本發明的精神和範圍內,均可作各種更動與修改,因此本發明的保護範圍應當以權利要求所限定的範圍為準。