翻譯輔助方法、翻譯輔助裝置、翻譯裝置以及翻譯輔助程序與流程
2023-05-30 03:34:31 1
本發明涉及對使用短語表的機器翻譯進行輔助的技術。
背景技術:
作為機器翻譯的一種,存在統計機器翻譯。例如,專利文獻1公開了以包括通過預先構建的短語表對輸入文中的句子進行模糊匹配的步驟作為特徵的基於短語的統計機器翻譯方法。
現有技術文獻
專利文獻1:日本特開2010-61645號公報
技術實現要素:
發明要解決的技術問題
然而,對於上述專利文獻1的技術,希望對翻譯精度有進一步的改善。
用於解決問題的技術方案
為了解決上述問題,本發明的一個技術方案涉及的翻譯輔助方法是對機器翻譯進行輔助的方法,所述機器翻譯使用短語表將第1語言的原文翻譯成第2語言的翻譯文,所述短語表保存有作為所述第1語言的短語與所述第2語言的短語的對的短語對,所述翻譯輔助方法包括如下的存儲步驟:存儲組合信息,所述組合信息是針對成為所述翻譯文的候選的多個翻譯候選文的各翻譯候選文,確定所述短語表所保存的所述短語對中為了生成所述翻譯候選文而使用的所述短語對的組合的信息。
發明的效果
根據上述技術方案,能夠實現進一步的改善。
附圖說明
圖1是說明適用於本發明涉及的一個方式的統計機器翻譯系統的框圖。
圖2是說明短語表的具體例子的說明圖。
圖3是說明原文和三個翻譯候選文的說明圖。
圖4是本實施方式涉及的翻譯系統的功能框圖。
圖5是說明本實施方式涉及的翻譯系統的工作的流程圖。
圖6是說明被分解成詞素的原文的一例的說明圖。
圖7是說明由機器翻譯部生成的數據構造的一例的說明圖。
圖8是說明翻譯結果信息的一例的說明圖。
圖9是說明五個翻譯候選文各自的詞素分析的結果的說明圖。
圖10是說明詞素的評價結果的說明圖。
圖11是說明由評價部搜索出的短語對的組合的說明圖。
圖12是說明短語對的評價結果的說明圖。
標號的說明
1:統計機器翻譯系統;2:對譯語料庫;3:單語言語料庫;4:翻譯模型;5:語言模型;6:解碼器;7:短語表;10:翻譯系統;11:用戶終端;12:伺服器(翻譯輔助裝置的一例);13:原文輸入部;14:機器翻譯部;15:翻譯候選文輸出部;16:選擇部;17:翻譯模型;18:翻譯信息存儲部;19:評價部;20:評分調整部;21:語言處理部;22:再次翻譯部;23:翻譯結果比較部;24:評分再調整決定部;25:權重設定部;30:數據構造;31:路徑;40:翻譯結果信息;50、50a~50h:詞素。
具體實施方式
以下說明的實施方式表示本發明的一個具體例子。以下的實施方式中表示的數值、構成要素、步驟、步驟的順序等為一例,並非旨在限定本發明。另外,對於以下的實施方式中的構成要素中的沒有記載在表示最上位概念的獨立權利要求中的構成要素,將作為任意的構成要素進行說明。
(得到本發明的見解)
圖1是說明適用於本發明涉及的一個方式的統計機器翻譯系統1的框圖。統計機器翻譯系統1具備對譯語料庫2、單語言語料庫3、翻譯模型4、語言模型5以及解碼器6。對譯語料庫2按領域、按語言對而分別準備。領域例如是旅行領域、醫療領域。語言對例如是日語與英語的對、日語與中文的對。
統計機器翻譯系統1事先學習對譯語料庫2來生成翻譯模型4,並且學習單語言語料庫3來生成語言模型5。解碼器6針對輸入文(原文),從翻譯模型4與語言模型5的組合中搜索概率成為最大的翻譯候選文,將其作為輸出文(翻譯文)。通過使用了維特比(viterbi)和/或集束(beam)搜索的最大似然估計,搜索翻譯候選文。
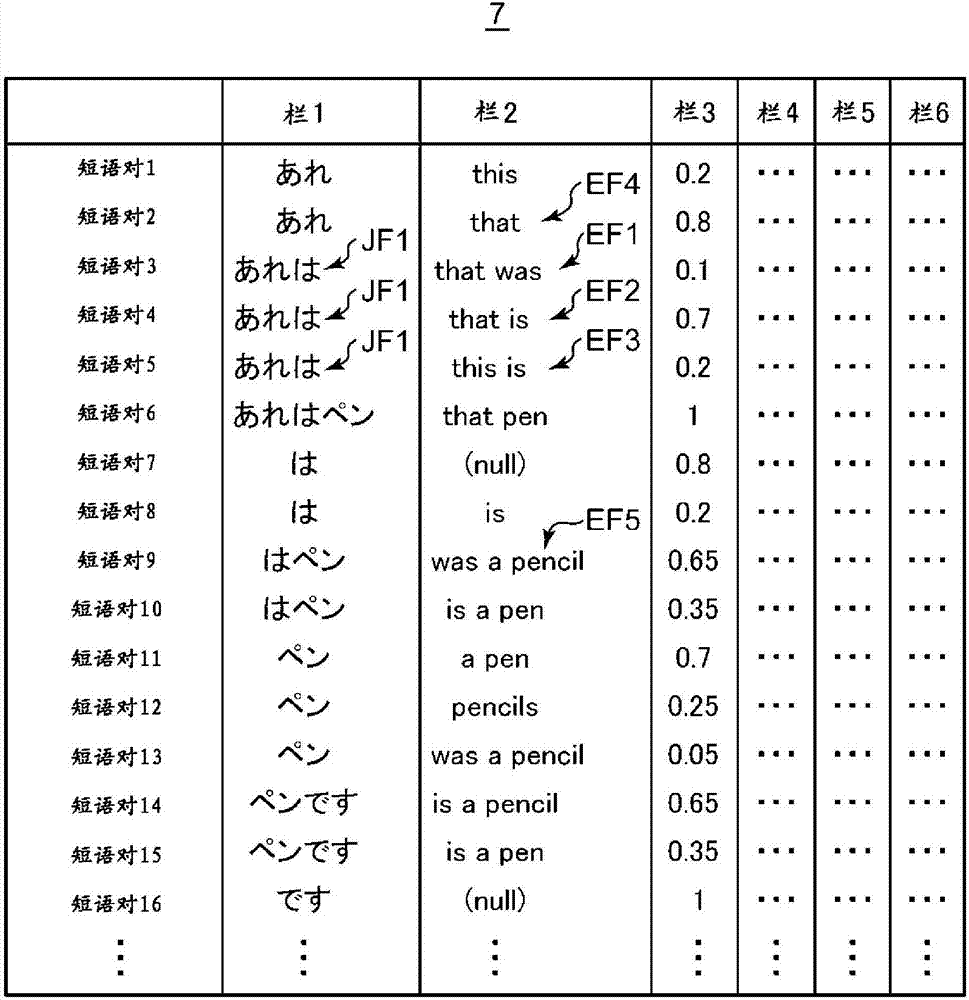
翻譯模型4通過短語表來管理。在短語表中,保存有短語對,並且與各短語對關聯地保存有各短語對的評分。短語對是第1語言的短語與第2語言的短語的對。評分是與短語對的出現概率有關的信息。設為第1語言是日語、第2語言是英語來說明該情況下的短語表的具體例子。圖2是對其進行說明的說明圖。在短語表7中,在欄1中示出日語短語,在欄2中示出英語短語,在欄3中示出短語的英日翻譯概率,在欄4中示出單詞的英日翻譯概率之積,在欄5中示出短語的日英翻譯概率,在欄6中示出單詞的日英翻譯概率之積。欄3~欄6中示出的值分別被稱為評分。位於同一行的日語短語和英語短語是短語對。在圖2中,示出了短語對1~16。
因為使用評分中的短語的英日翻譯概率(欄3)對實施方式進行說明,所以短語的英日翻譯概率(欄3)示出了值,而單詞的英日翻譯概率之積(欄4)、短語的日英翻譯概率(欄5)、單詞的日英翻譯概率之積(欄6)省略了值。
具體進行說明,對於短語的英日翻譯概率(欄3),例如日語短語jf1(意味著「あれは」的日語)被翻譯成英語短語ef1的概率是0.1,被翻譯成英語短語ef2的概率是0.7,被翻譯成英語短語ef3的概率成為0.2。將這些概率相加得到的值成為1。
考慮如下的方案:統計機器翻譯系統1向用戶提示在對原文進行翻譯時所生成的多個翻譯候選文,使用戶從多個翻譯候選文中選擇最佳的翻譯候選文,基於該最佳的翻譯候選文進行學習。具體進行說明,圖3是說明原文os和三個翻譯候選文ts1、ts2、ts3之間的關係的說明圖。作為對原文os(意味著「あれは、ペンです」的日語)的翻譯候選文,設為生成了翻譯候選文ts1、ts2、ts3。
在用戶選擇了翻譯候選文ts2時,統計機器翻譯系統1在翻譯候選文ts1中,將句節(日語「文節」)c1學習為差句節,將句節c2學習為好句節,在翻譯候選文ts3中,將句節c3學習為差句節,將句節c4學習為好句節,將句節c5學習為差句節。
如果將上述學習的結果反映於短語表7的評分,則統計機器翻譯系統1的翻譯精度會提高。
但是,在統計機器翻譯系統1對原文進行了翻譯的情況下,會產生多個構成翻譯候選文(例如,翻譯候選文ts1)的短語對的組合。例如存在短語對1、8、11、16的組合和短語對1、7、15的組合。因此,僅根據翻譯候選文,並不知道通過哪個短語對的組合生成了該翻譯候選文,因此無法將學習的結果反映於短語表7的評分。
因此,為了使得能夠確定通過哪個短語對的組合生成了翻譯候選文,研究了以下的改善措施。
翻譯輔助方法的一個技術方案是對機器翻譯進行輔助的方法,所述機器翻譯使用短語表將第1語言的原文翻譯成第2語言的翻譯文,所述短語表保存有作為所述第1語言的短語與所述第2語言的短語的對的短語對,所述翻譯輔助方法包括如下的存儲步驟:存儲組合信息,所述組合信息是針對成為所述翻譯文的候選的多個翻譯候選文的各翻譯候選文,確定所述短語表所保存的所述短語對中為了生成所述翻譯候選文而使用的所述短語對的組合的信息。
在翻譯輔助方法的一個技術方案中,針對成為翻譯文的候選的多個翻譯候選文的各翻譯候選文,存儲組合信息,該組合信息是確定短語表所保存的短語對中為了生成翻譯候選文而使用的短語對的組合的信息。由此,根據翻譯輔助方法的一個技術方案,能夠確定為了生成翻譯候選文而使用的短語對的組合。
在上述構成中,在所述存儲步驟中,將與為了生成多個所述翻譯候選文的各翻譯候選文而使用的所述短語對的組合有關的數據構造、以及在所述數據構造中能夠獲得為了生成多個所述翻譯候選文的各翻譯候選文而使用的所述短語對的組合的路徑作為所述組合信息進行存儲。
該構成是組合信息的一例。
在上述構成中,在所述短語表中,與所述短語表所保存的所述短語對分別關聯地保存有作為與所述短語對的出現概率有關的信息的評分,所述翻譯輔助方法還包括:選擇步驟,使用戶從多個所述翻譯候選文中選擇最佳的所述翻譯候選文;確定步驟,使用通過所述存儲步驟存儲的所述組合信息來確定為了生成在所述選擇步驟中未被選擇的所述翻譯候選文而使用的所述短語對的組合;以及評價步驟,針對構成通過所述確定步驟確定出的所述組合的各個所述短語對,進行用於調整所述評分的評價。
在該構成中,對為了生成在選擇步驟中未被選擇的翻譯候選文而使用的各短語對進行用於調整評分的評價,來作為用於調整評分的前提。
在上述構成中,在所述評價步驟中,針對構成通過所述確定步驟確定出的所述組合的各個所述短語對,通過與所述選擇步驟選擇出的所述翻譯候選文所包含的要素進行比較,由此使用預定的基準,對應該提高所述評分的所述短語對進行應該提高所述評分的評價,對應該降低所述評分的所述短語對進行應該降低所述評分的評價。
該構成是評價步驟的一個方式。在翻譯候選文例如通過詞素分析進行了分解時,詞素成為要素。另外,在翻譯候選文例如通過句法分析進行了分解時,主語、謂語、補語、賓語等成為要素。作為進行應該提高評分的評價的情況下的基準以及進行應該降低評分的評價的情況下的基準,可考慮各種基準。考慮這些基準對本領域技術人員來說是容易的,因此設為預定的基準。在實施方式中,作為預定的基準,例示了後面說明的(1)~(7)的基準。
在上述構成中,還包括如下的評分調整步驟:進行第1處理和第2處理中的至少一方的處理,所述第1處理是將與被作出應該提高所述評分的評價的所述短語對關聯的所述評分進行提高的處理,所述第2處理是將與被作出應該降低所述評分的評價的所述短語對關聯的所述評分進行降低的處理。
根據該構成,基於評價步驟中的評價,對為了生成在選擇步驟中未被選擇的翻譯候選文而使用的短語對的評分進行調整,因此能夠使機器翻譯的翻譯精度提高。設為進行使評分提高的第1處理和使評分降低的第2處理中的至少一方的處理,是因為:無論進行兩方的處理還是進行單方的處理,機器翻譯的精度都會提高。
在上述構成中,還包括如下的第1設定步驟:在所述評分調整步驟進行所述第1處理的情況下,根據被進行所述第1處理的所述短語對的所述評分和所述第1語言與被進行所述第1處理的所述短語對的所述第1語言相同的其他短語對的所述評分之間的偏差,設定在所述第1處理中使用的第1預定值,在所述評分調整步驟中,使用通過所述第1設定步驟設定的所述第1預定值來進行所述第1處理。
根據該構成,能夠根據被進行第1處理的短語對的評分和第1語言與該短語對的第1語言相同的其他短語對的評分之間的偏差,改變在第1處理中使用的第1預定值。因此,與在第1處理中使用的第1預定值是固定值的技術方案相比,能夠使翻譯精度提高。
對第1預定值的設定進行詳細說明。在第1設定步驟中,在被進行第1處理的短語對的評分和第1語言與該短語對的第1語言相同的其他短語對的評分之間的偏差比較大時,設定第1預定值以使得被進行第1處理的短語對的評分變化較大,在該偏差比較小時,設定第1預定值以使得被進行第1處理的短語對的評分變化較小。也可以反過來。即,在第1設定步驟中,在被進行第1處理的短語對的評分和第1語言與該短語對的第1語言相同的其他短語對的評分之間的偏差比較大時,設定第1預定值以使得被進行第1處理的短語對的評分變化較小,在該偏差比較小時,設定第1預定值以使得被進行第1處理的短語對的評分變化較大。
在上述構成中,還包括如下的第2設定步驟:在所述評分調整步驟進行所述第2處理的情況下,根據被進行所述第2處理的所述短語對的所述評分和所述第1語言與被進行所述第2處理的所述短語對的所述第1語言相同的其他短語對的所述評分之間的偏差,設定在所述第2處理中使用的第2預定值,在所述評分調整步驟中,使用通過所述第2設定步驟設定的所述第2預定值來進行所述第2處理。
根據該構成,能夠根據被進行第2處理的短語對的評分和第1語言與該短語對的第1語言相同的其他短語對的評分之間的偏差,改變在第2處理中使用的第2預定值。因此,與在第2處理中使用的第2預定值是固定值的技術方案相比,能夠使翻譯精度提高。
對第2預定值的設定進行詳細說明。在第2設定步驟中,在被進行第2處理的短語對的評分和第1語言與該短語對的第1語言相同的其他短語對的評分之間的偏差比較大時,設定第2預定值以使得被進行第2處理的短語對的評分變化較大,在該偏差比較小時,設定第2預定值以使得被進行第2處理的短語對的評分變化比較小。也可以反過來。即,在第2設定步驟中,在被進行第2處理的短語對的評分和第1語言與該短語對的第1語言相同的其他短語對的評分之間的偏差比較大時,設定第2預定值以使得被進行第2處理的短語對的評分變化較小,在該偏差比較小時,設定第2預定值以使得被進行第2處理的短語對的評分變化較大。
在上述構成中,在所述存儲步驟中,針對多個所述翻譯候選文的各翻譯候選文,存儲與基於所述評分而算出的翻譯結果有關的數值信息,所述翻譯輔助方法還包括:再次翻譯步驟,使用所述評分調整步驟後的所述短語表對所述原文進行再次翻譯,由此再次生成成為所述翻譯文的候選的多個所述翻譯候選文,針對再次生成的多個所述翻譯候選文的各翻譯候選文,生成基於所述評分調整步驟後的所述短語表的所述評分而算出的所述數值信息;比較步驟,對通過所述存儲步驟存儲的所述數值信息和通過所述再次翻譯步驟生成的所述數值信息進行比較,判定是否滿足預先確定的基準;以及再次執行步驟,在判定為滿足所述預先確定的基準時,再次執行所述評分調整步驟。
與翻譯結果有關的數值信息例如是n-best排序。滿足預先確定的基準的情況例如是對通過存儲步驟存儲的n-best排序和通過再次翻譯步驟生成的n-best排序進行比較而排序沒有變化的情況。根據該構成,對通過存儲步驟存儲的數值信息和通過再次翻譯步驟生成的數值信息進行比較,在判定為滿足預先確定的基準時,再次執行評分調整步驟。因此,能夠使翻譯精度提高。
翻譯輔助裝置的一個技術方案是是對機器翻譯進行輔助的裝置,所述機器翻譯使用短語表將第1語言的原文翻譯成第2語言的翻譯文,所述短語表保存有作為所述第1語言的短語與所述第2語言的短語的對的短語對,所述翻譯輔助裝置具備存儲部,所述存儲部存儲組合信息,所述組合信息是針對成為所述翻譯文的候選的多個翻譯候選文的各翻譯候選文,確定所述短語表所保存的所述短語對中為了生成所述翻譯候選文而使用的所述短語對的組合的信息。
翻譯輔助裝置的一個技術方案具有與翻譯輔助方法的一個技術方案同樣的作用效果。
翻譯裝置的一個技術方案具備:短語表,其保存有作為第1語言的短語與第2語言的短語的對的短語對;機器翻譯部,其使用所述短語表,為了從所述第1語言的原文生成所述第2語言的翻譯文,生成成為所述翻譯文的候選的多個翻譯候選文;以及存儲部,其存儲組合信息,所述組合信息是針對所述機器翻譯部生成的多個翻譯候選文的各翻譯候選文,確定所述短語表所保存的所述短語對中為了生成所述翻譯候選文而使用的所述短語對的組合的信息。
翻譯裝置的一個技術方案具有與翻譯輔助方法的一個技術方案同樣的作用效果。
翻譯輔助程序的一個技術方案是對機器翻譯進行輔助的程序,所述機器翻譯使用短語表將第1語言的原文翻譯成第2語言的翻譯文,所述短語表保存有作為所述第1語言的短語與所述第2語言的短語的對的短語對,所述翻譯輔助程序使計算機執行如下的存儲步驟:存儲組合信息,所述組合信息是針對成為所述翻譯文的候選的多個翻譯候選文的各翻譯候選文,確定所述短語表所保存的所述短語對中為了生成所述翻譯候選文而使用的所述短語對的組合的信息。
翻譯輔助程序的一個技術方案具有與翻譯輔助方法的一個技術方案同樣的作用效果。
(實施方式)
以下,基於附圖對本發明的實施方式進行詳細說明。以第1語言是日語、第2語言是英語的組合進行說明,但第1語言與第2語言的組合併不限定於此。圖4是本實施方式涉及的翻譯系統10的功能框圖。翻譯系統10使用統計機器翻譯進行翻譯。翻譯系統10由用戶終端11和伺服器12構成。翻譯系統10具備原文輸入部13、機器翻譯部14、翻譯候選文輸出部15、選擇部16、翻譯模型17、翻譯信息存儲部18、評價部19、評分調整部20、語言處理部21、再次翻譯部22、翻譯結果比較部23、評分再調整決定部24以及權重設定部25來作為功能塊。
原文輸入部13、機器翻譯部14、翻譯候選文輸出部15以及選擇部16被設置於用戶終端11。用戶終端11例如是臺式個人計算機、筆記本式個人計算機、智慧型手機、平板終端。
翻譯模型17、翻譯信息存儲部18、評價部19、評分調整部20、語言處理部21、再次翻譯部22、翻譯結果比較部23、評分再調整決定部24以及權重設定部25被設置於伺服器12。伺服器12能夠與用戶終端11進行通信,是翻譯輔助裝置的一例。此外,也可以是這些功能塊的一部分(例如,翻譯模型17)被設置於用戶終端11的技術方案。另外,也可以是構成翻譯系統10的全部功能塊被設置於用戶終端11的技術方案。在後者的技術方案中,不需要伺服器12,僅通過用戶終端11就行,因此成為包含翻譯輔助裝置的翻譯裝置。
對設置於用戶終端11的功能塊進行說明。通過用戶向原文輸入部13輸入原文。在以文字的方式輸入原文的情況下,例如鍵盤、觸摸面板成為原文輸入部13。在以聲音的方式輸入原文的情況下,麥克風以及對從麥克風輸入的聲音進行識別的聲音識別裝置成為原文輸入部13。
機器翻譯部14針對輸入到原文輸入部13的第1語言的原文,生成成為第2語言的翻譯文的候選的多個翻譯候選文。多個翻譯候選文通過圖1中說明的統計機器翻譯來生成。機器翻譯部14是圖1所示的解碼器6,通過cpu(centralprocessingunit,中央處理單元)、ram(randomaccessmemory,隨機存取存儲器)以及rom(readonlymemory,只讀存儲器)等硬體和用於執行機器翻譯的各種軟體等來實現。
翻譯候選文輸出部15將由機器翻譯部14生成的多個翻譯候選文進行輸出。在以文字的方式輸出翻譯候選文的情況下,顯示器成為翻譯候選文輸出部15。在以聲音的方式輸出翻譯候選文的情況下,揚聲器成為翻譯候選文輸出部15。
用戶使用選擇部16,從自翻譯候選文輸出部15輸出的多個翻譯候選文中選擇最佳的翻譯候選文。例如,鍵盤、觸摸面板成為選擇部16。在以聲音的方式選擇最佳的翻譯候選文的情況下,麥克風以及對從麥克風輸入的聲音進行識別的聲音識別裝置成為選擇部16。
對設置於伺服器12的功能塊進行說明。這些功能塊通過cpu、ram以及rom等硬體和用於執行機器翻譯的各種軟體等來實現。
翻譯模型17對應於圖1所示的翻譯模型4,通過圖2所示那樣的短語表7來管理。機器翻譯部14使用翻譯模型17進行統計機器翻譯。此外,在實際的統計機器翻譯中,除了翻譯模型17之外還需要圖1所示的語言模型5,但在本實施方式中,為了簡化翻譯系統10的說明,省略了語言模型5。
翻譯信息存儲部18存儲翻譯信息。在翻譯信息中包含翻譯結果信息以及組合信息。翻譯結果信息是被輸入到原文輸入部13的原文、機器翻譯部14生成的多個翻譯候選文等。組合信息是針對多個翻譯候選文的各翻譯候選文,確定在短語表7所保存的短語對中為了生成翻譯候選文而使用的短語對的組合的信息。關於翻譯結果信息以及組合信息,將在後面進行詳細說明。
評分調整部20基於由選擇部16選擇出的翻譯候選文(即,由用戶判斷出的最佳的翻譯候選文),對管理翻譯模型17的短語表7的評分進行調整。
關於其餘的功能塊,在下面說明的翻譯系統10的工作中進行它們的說明。
主要參照圖4以及圖5來說明本實施方式涉及的翻譯系統10的工作。圖5是說明該工作的流程圖。
用戶向原文輸入部13輸入原文(步驟s1)。作為原文,以圖3的原文os為例來說明。
機器翻譯部14對輸入到原文輸入部13的原文進行統計機器翻譯(步驟s2)。詳細地進行說明,通過預定的方法對通過步驟s1輸入到原文輸入部13的原文進行分解。作為預定的方法,存在詞素分析、句法分析等。在此,以詞素分析為例來說明。
通過機器翻譯部14對原文進行詞素分析,原文被分解成圖6所示的4個詞素50。機器翻譯部14使用這4個詞素50以及管理翻譯模型17的圖2所示那樣的短語表7,生成能夠獲得成為原文的翻譯文的候選的全部翻譯候選文的、圖7所示的數據構造30。圖7是說明由機器翻譯部14生成的數據構造30的一例的說明圖。
數據構造30具有樹構造。節點是短語對。這裡的短語對是在圖2所示的短語表7所保存的短語對中為了生成翻譯候選文而使用的短語對。對於短語對,分別示出了日語短語、英語短語、評分。評分是圖2的欄3中示出的值。
在數據構造30中,作為為了生成翻譯候選文而使用的短語對的組合,示出了組合1~10。例如,組合1是將短語對1、7、11、16按該順序排列而得到的組合。組合1的翻譯候選文成為圖8所示的翻譯候選文ts4。
機器翻譯部14對由數據構造30示出的全部組合的各組合,計算累計概率,決定n-best排序。
機器翻譯部14基於以上構成,生成翻譯結果信息。圖8是說明翻譯結果信息40的一例的說明圖。翻譯結果信息40是對原文以及各個組合示出累計概率、n-best排序以及翻譯候選文的信息。
累計概率是將為了生成翻譯候選文而使用的各個短語對的評分(圖2的欄3中示出的英日翻譯概率)相乘而得到的值。例如,在組合1的情況下,參照圖7以及圖8,0.112(=0.2×0.8×0.7×1)成為累計概率。
n-best排序表示從具有最大的累計概率的組合到具有第n大的累計概率的組合為止的排序。在此,n-best排序的n以5來說明,但並不限定於此。機器翻譯部14按累計概率從高到低的順序,確定第1順位到第5順位的排序。在此,組合7是第1順位,組合9是第2順位,組合10是第3順位,組合2是第4順位,組合5是第5順位。
在本實施方式中,將n-best排序以及累計概率作為與翻譯結果有關的數值信息進行說明。此外,也可以僅將n-best排序作為與翻譯結果有關的數值信息。
機器翻譯部14使翻譯信息存儲於翻譯信息存儲部18(步驟s3)。翻譯信息由組合信息和圖8所示的翻譯結果信息40構成。組合信息是指圖7所示的數據構造30以及路徑31。路徑31是指在數據構造30中能夠獲得n-best排序的第1順位~第n順位(在此為第5順位)的各個組合的路徑(在此,為組合2的路徑31、組合5的路徑31、組合7的路徑31、組合9的路徑31、組合10的路徑31)。在翻譯結果信息40中包含與上述的翻譯結果有關的數值信息(累計概率、n-best排序)。
翻譯候選文輸出部15針對n-best排序的第1順位到第n順位(在此為第5順位)的各個組合,輸出翻譯候選文(步驟s4)。在此,圖8所示的翻譯候選文ts5、翻譯候選文ts6、翻譯候選文ts7、翻譯候選文ts8、翻譯候選文ts9被輸出。在翻譯候選文輸出部15例如是用戶終端11的顯示器的情況下,在該顯示器上顯示這些翻譯候選文。
用戶使用選擇部16,從通過步驟s4輸出的五個翻譯候選文中選擇最佳的翻譯候選文來作為通過步驟s1輸入的原文的翻譯文(步驟s5)。在此,設為選擇了圖8所示的由組合9構成的翻譯候選文ts8。
語言處理部21對通過步驟s4輸出的五個翻譯候選文分別進行預定的分析,以多個要素對翻譯候選文進行分解(步驟s6)。作為預定的分析,存在詞素分析、句法分析等。在此,以詞素分析為例來說明。在詞素分析的情況下,要素成為詞素。圖9是說明五個翻譯候選文各自的詞素分析的結果的說明圖。例如,由組合7構成的翻譯候選文ts7被分解成詞素50a、詞素50b、詞素50c、詞素50d這4個詞素(要素)。
評價部19對通過步驟s6分解後的詞素分別進行評價(步驟s7)。詳細地進行說明,評價部19針對在步驟s5中未被選擇的翻譯候選文的詞素,將與通過步驟s5選擇出的翻譯候選文ts8的詞素50e、詞素50f、詞素50g、詞素50h相同的詞素評價為好詞素,將與通過步驟s5選擇出的翻譯候選文ts8的詞素50e、詞素50f、詞素50g、詞素50h不同的詞素評價為差詞素,將無法評價是好詞素還是差詞素的詞素評價為中性詞素。
圖10是說明詞素的評價結果的說明圖。好詞素由「○」表示,差詞素由「×」表示,中性詞素由「δ」表示。例如,由組合7構成的翻譯候選文ts7的詞素中的詞素50a被評價為好詞素,詞素50b被評價為差詞素,詞素50c被評價為好詞素,詞素50d被評價為差詞素。
評價部19針對在步驟s5中未被選擇的翻譯候選文,確定為了生成翻譯候選文而使用的短語對的組合(步驟s8)。在該確定中,使用通過步驟s3存儲的翻譯信息所包含的組合信息。如上所述,組合信息是圖7所示的數據構造30以及在數據構造30中能夠獲得n-best排序的第1順位到第5順位的各個組合的路徑31。
評價部19使用能夠獲得組合7的路徑31,對數據構造30進行搜索。由此,得到短語對2、9、16。評價部19使用能夠獲得組合10的路徑31,對數據構造30進行搜索。由此,得到短語對4、14。評價部19使用能夠獲得組合2的路徑31,對數據構造30進行搜索。由此,得到短語對2、7、11、16。評價部19使用能夠獲得組合5的路徑31,對數據構造30進行搜索。由此,得到短語對2、7、14。
圖11是說明由評價部19搜索出的短語對的組合的說明圖。組合7是短語對2、9、16的組合。組合10是短語對4、14的組合。組合2是短語對2、7、11、16的組合。組合5是短語對2、7、14的組合。
評價部19針對圖11所示的各個短語對,進行用於對評分(例如,短語對2的評分為0.8)進行調整的評價(步驟s9)。具體而言,如以下這樣來評價短語對。評價部19針對圖11所示的各個短語對(即,構成通過步驟s8確定出的組合的各個短語對),將其與通過步驟s5選擇出的翻譯候選文所包含的詞素(要素)進行比較,由此對應該提高評分的短語對進行應該提高評分的評價,對應該降低評分的短語對進行應該降低評分的評價。
在本實施方式中,將被作出了應該提高評分的評價的短語對設為好短語對,將被作出了應該降低評分的評價的短語對設為差短語對,將無法作出任何評價的短語對設為中性短語對。評價為好短語、差短語、中性短語的基準例如如以下所述。
(1)在短語對的英語短語僅由好詞素構成時,該短語對被評價為好短語對。
(2)在短語對的英語短語僅由差詞素構成時,該短語對被評價為差短語對。
(3)在短語對沒有英語短語時(例如,圖11所示的短語對16),該短語對被評價為中性短語對。
(4)在短語對的英語短語由好詞素和中性詞素構成時,該短語對被評價為好短語對。此外,也可以評價為中性短語對。
(5)在短語對的英語短語由差詞素和中性詞素構成時,該短語對被評價為差短語對。此外,也可以評價為中性短語對。
(6)在短語對的英語短語由好詞素和差詞素構成時、或者在短語對的英語短語由好詞素、差詞素和中性詞素構成時,該短語對被評價為差短語對。此外,也可以評價為好短語對。另外,在好詞素的數量比差詞素的數量多時,也可以評價為好短語對,在差詞素的數量比好詞素的數量多時,也可以評價為差短語對。
(7)在短語對的英語短語僅由中性詞素構成時,該短語對被評價為中性短語對。
以組合7為例來具體說明。評價部19針對組合7,按照圖10所示的詞素的評價,對圖11所示的短語對2、9、16分別進行評價。短語對2的英語短語ef4僅由好詞素構成,因此被評價為好短語對。短語對9的英語短語ef5包含差詞素50b、50d,因此被評價為差短語對。短語對16沒有英語短語,因此被評價為中性短語對。
圖12是說明短語對的評價結果的說明圖。好短語對由「○」表示,差短語對由「×」表示,中性短語對由「δ」表示。
此外,也可以以與上述同樣的方式對為了生成通過步驟s5選擇出的翻譯候選文而使用的短語對分別進行評價。該情況下,全部短語對都被評價為好短語對。
作為對好短語對、差短語對、中性短語對的評分進行的處理,例如存在以下的處理。
評分調整部20對好短語對的評分乘以預定權重,使評分增大。此外,評分調整部20也可以對好短語對的評分加上預定值,使評分增大。
評分調整部20對差短語對的評分乘以預定權重,使評分減小。此外,評分調整部20也可以從差短語對的評分減去預定值,使評分減小。
評分調整部20維持中性短語對的評分。
評分調整部20以與同樣的方式使中性短語對的評分增大。
評分調整部20以與同樣的方式使中性短語對的評分減小。
評分調整部20在通過增大了好短語對的評分時,使包含與該短語對的日語短語相同的日語短語的短語對的評分減小,使將這些評分相加得到的值為1。具體進行說明,參照圖2,評分調整部20例如在使短語對2的評分成為了0.9時,使短語對1的評分成為0.1。
評分調整部20在通過減小了差短語對的評分時,使包含與該短語對的日語短語相同的日語短語的短語對的評分增大,使將這些評分相加得到的值為1。具體進行說明,參照圖2,評分調整部20例如在使短語對9的評分成為了0.55時,使短語對10的評分成為0.45。
評分調整部20單獨或組合使用~,對圖12所示的短語對分別調整評分(步驟s10)。這是一種翻譯模型17的學習。評分調整部20例如可以使用、以及來調整評分,也可以僅使用來調整評分,也可以僅使用來調整評分,也使用以及來調整評分,也可以使用以及來調整評分,也可以使用以及來調整評分。
以下,對使用了、以及的評分調整進行詳細說明。設為對好短語對的預定權重例如為1.2,對差短語對的預定權重例如為0.8。參照圖12,評分調整部20首先對構成組合7的短語對2、9、16的評分進行調整。
因為短語對2為好短語對,所以評分調整部20在圖2所示的短語表7中將短語對2的評分從0.8提高到0.96(=0.8×1.2)。因為短語對9為差短語對,所以評分調整部20在短語表7中將短語對9的評分從0.65降低到0.52(=0.65×0.8)。因為短語對16是中性短語對,所以評分調整部20在短語表7中將短語對16的評分維持為1。構成組合7的短語對2、9、16的評分調整後的累計概率成為0.4992(=0.96×0.52×1),變為比圖8所示的當初的累計概率(0.520)小。
此外,在評分調整後的累計概率仍然比構成用戶選擇出的翻譯候選文的短語對的累計概率大時,也可以再次進行步驟s10的處理。即,評分調整部20將構成組合7的短語對2、9、16的評分調整後的累計概率(0.4992)與構成通過步驟s5選擇出的翻譯候選文的短語對的評分的累計概率(即,圖8所示的構成組合9的短語對的評分的累計概率0.490)進行比較,在前者比後者大時,再次對構成組合7的短語對2、9、16進行步驟s10的處理。
評分調整部20針對其餘的組合(組合10、2、5),也以與組合7同樣的方式對評分進行調整。
在步驟s10之後,再次翻譯部22使用與步驟s2同樣的方法,對通過步驟s3存儲的翻譯信息所包含的原文(即,通過步驟s1輸入的原文)進行再次翻譯(步驟s11)。在再次翻譯中,使用評分調整後的短語表7。在該再次翻譯中,再次翻譯部22針對再次生成的多個翻譯候選文,生成再次翻譯結果信息(未圖示)。因為使用評分調整後的短語表7進行再次翻譯,所以再次翻譯結果信息有可能會與圖8所示的翻譯結果信息40不同的是與翻譯結果有關的數值信息(n-best排序、累計概率)。
此外,也可以是機器翻譯部14進行步驟s11的處理。該情況下,在翻譯系統10中不具備再次翻譯部22。
翻譯結果比較部23對圖8所示的翻譯結果信息40所包含的n-best排序與上述再次翻譯結果信息所包含的n-best排序進行比較,判定n-best排序是否沒有變化(步驟s12)。n-best排序沒有變化的情況是滿足預先確定的基準的情況的一例。作為其替代,也可以將圖8所示的組合9的n-best排序(即,在步驟s5中由用戶選擇出的翻譯候選文的n-best排序)在再次翻譯結果信息所包含的n-best排序中不位於第1位的情況、或組合9的n-best排序在再次翻譯結果信息所包含的n-best排序中雖然位於第1位但n-best排序為第1位的累計概率和第2位的累計概率之差為預定值以下(即,差很小)的情況設為滿足預先確定的基準的情況。
翻譯結果比較部23在判定為n-best排序沒有變化時(步驟s12:是),評分再調整決定部24作出再次執行評分調整的決定(步驟s13),返回到步驟s10。
翻譯結果比較部23在判定為n-best排序發生變化時(步驟s12:否),翻譯系統10的工作結束。此外,在本實施方式中,執行了步驟s11~步驟s13,但也可以在步驟s10中結束翻譯系統10的工作。
如以上進行的說明,根據本實施方式涉及的翻譯系統10,針對機器翻譯部14生成的多個翻譯候選文的各翻譯候選文,能夠確定為了生成翻譯候選文而使用的短語對。因此,能夠基於用戶從多個翻譯候選文中選擇出的翻譯候選文,對為了生成其餘的翻譯候選文而使用的短語對的評分進行調整。
對在步驟s6中使用句法分析的情況進行簡單說明。語言處理部21對通過步驟s4輸出的五個翻譯候選文分別進行句法分析,以多個要素對翻譯候選文進行分解。在句法分析的情況下,例如,以樹構造來表現句法的情況下的各節點(為了簡單,例如設為主語s、謂語v、補語c、賓語o等)成為要素。例如,通過步驟s5選擇出的翻譯候選文ts8(組合9)被分解成「that=s」、「is=v」、「apen=c」。其他的翻譯候選文、例如組合7被分解成「that=s」、「was=v」、「apencil=c」。
在步驟s7中,對通過句法分析而得到的要素進行評價。以組合7為例來說明,評價部19將「that=s」評價為好要素、將「was=v」評價為差要素,將「apencil=c」評價為差要素。
評價部19以與詞素分析的情況同樣的方式,對圖11所示的短語對分別進行用於調整評分的評價(步驟s9)。以組合7為例來說明,評價部19將短語對2判定為好短語對,將短語對9評價為差短語對,將短語對16評價為中性短語對。
評分調整部20以與詞素分析的情況同樣的方式,對通過步驟s9進行了評價的短語對分別調整評分(步驟s10)。此時,評分調整部20對被評價為差短語對的短語對,使進行了比較的要素的種類不同的情況(例如,「apen=c」和「apencil=o」)下的評分與進行了比較的要素的種類相同的情況(例如,「apen=c」和「apencil=c」)下的評分相比更大地變化。由此,能夠提高對句法構造錯誤的學習效果。
對本實施方式的變形例進行說明。在本實施方式中,將在評分的調整(步驟s10)中使用的預定權重設為了固定值,而在變形例中,使預定權重為可變值。權重設定部25在提高好短語對(例如,圖2的短語對2)的評分的第1處理(上述)被進行的情況下,根據好短語對的評分、和日語(第1語言)與該短語對的日語相同的其他短語對(圖2的短語對1)的評分之間的偏差,設定在第1處理中使用的預定權重(第1預定值)。偏差例如是方差。並且,評分調整部20使用權重設定部25設定的預定權重,使好短語對的評分增大。
權重設定部25在上述偏差比較大時,設定預定權重以使得好短語對的評分變化較大,在上述偏差比較小時,設定預定權重以使得好短語對的評分變化較小。也可以反過來。即,權重設定部25在上述偏差比較大時,設定預定權重以使得好短語對的評分變化較小,在上述偏差比較小時,設定預定權重以使得好短語對的評分變化較大。
權重設定部25在降低差短語對(例如,圖2的短語對9)的評分的第2處理(上述)被進行的情況下,根據差短語對的評分和日語(第1語言)與該短語對的日語相同的其他短語對(圖2的短語對10)的評分之間的偏差,設定在第2處理中使用的預定權重(第2預定值)。偏差例如是方差。並且,評分調整部20使用所設定的預定權重,使差短語對的評分減小。
權重設定部25在上述偏差比較大時,設定預定權重以使得差短語對的評分變化較大,在上述偏差比較小時,設定預定權重以使得差短語對的評分變化較小。也可以反過來。即,權重設定部25在上述偏差比較大時,設定預定權重以使得差短語對的評分變化較小,在上述偏差比較小時,設定預定權重以使得差短語對的評分變化較大。
產業上的可利用性
本發明例如可以利用於統計機器翻譯。