機械學習裝置及方法、機器人控制裝置、機器人系統與流程
2023-06-18 17:06:21 2
本發明涉及一種學習人的行為模式的機械學習裝置、機器人控制裝置、機器人系統及機械學習方法。
背景技術:
在現有技術中,為了確保人的安全,採用了如下的安全對策:在機器人驅動的期間,人不進入機器人的作業區域。例如,在機器人的周邊設置安全柵,在機器人的驅動期間,禁止人進入到安全柵的內部。近年來,已知人與機器人協作來進行作業的機器人系統。在該機器人系統中,在機器人的周邊不設置安全柵的狀態下,機器人和人可以同時進行一個作業。
在日本特開2015-123505號公報中公開了與人進行協作作業的工業機器人。該機器人具備被底部支持的可動部、由剛性比可動部低的材質形成且覆蓋可動部的周圍的保護部件、設於可動部且檢測經由保護部件輸入的外力的檢測器。
按照預先生成的動作程序驅動一般的工業機器人。或者,以通過由示教編程器等預先示教的示教點的方式驅動機器人。即,沿著預先決定的軌道驅動機器人。
在人與機器人協作來進行作業的機器人系統中,也可以預先設定機器人的軌道,沿著所生成的軌道驅動機器人。然而,在人與機器人協作來進行作業的情況下,有時作業方法並不一般。例如,在製造產品的工廠等,有時將工件從初始位置搬運至目標位置。為了搬運工件,有時人與機器人協作來抬起工件,搬運至目標位置。機器人可以抬起搬運物並進行搬運。在該情況下,抬起工件的方向和速度等,存在多個選項。
依存於針對工件的機器人的控制方法,人的負擔度變化。例如,即使在進行同一作業的情況下,人的疲憊程度也變化,負擔度還根據離人的距離或速度而變化。因此,優選適當地設定機器人的控制方法。然而,存在多個機器人的控制方法。此外,有時人的行為模式因作業內容而不同。因此,存在難以根據作業內容設定最佳的機器人的控制方法的問題。
技術實現要素:
根據本發明的第1實施方式,提供一種在人與機器人協作來進行作業的機器人的機械學習裝置,其中,具備:狀態觀測部,其在上述人與上述機器人協作地進行作業的期間,觀測表示上述機器人的狀態的狀態變量;判定數據取得部,其取得與上述人的負擔度以及作業效率中的至少一方相關的判定數據;以及學習部,其根據上述狀態變量以及上述判定數據,學習用於設定上述機器人的行為的訓練數據集。
優選地,上述狀態變量包括上述機器人的位置、姿勢、速度以及加速度中的至少一個。優選地,上述判定數據包括上述機器人感知的負荷的大小或方向、上述機器人的周圍感知的負荷的大小或方向、上述機器人的周圍的負擔度以及上述機器人的移動時間中的至少一個。
上述訓練數據集包括對上述機器人的每個狀態以及上述機器人的每個行為設定的表示上述機器人的行為的價值的行為價值變量,上述學習部包括:回報計算部,其根據上述判定數據以及上述狀態變量設定回報;以及函數更新部,其根據上述回報以及上述狀態變量,更新上述行為價值變量。優選地,上述機器人的加速度的絕對值越小,上述回報計算部設定越大的回報,上述機器人的移動時間越短,上述回報計算部設定越大的回報。
上述訓練數據集包括對上述機器人的每個狀態以及上述機器人的每個行為設定的上述機器人的學習模型,上述學習部包括:誤差計算部,其根據上述判定數據、上述狀態變量以及所輸入的教師數據,計算上述學習模型的誤差;以及學習模型變更部,其根據上述誤差以及上述狀態變量,更新上述學習模型。優選地,該機械學習裝置還具備:人判別部,其判別與上述機器人協作地進行作業的人,對每個人生成上述訓練數據集,上述學習部學習所判別出的人的上述訓練數據集,或者,上述機械學習裝置具備神經網絡。優選地,上述機器人為工業機器人、場地機器人或服務機器人。
根據本發明的第2實施方式,提供一種機器人控制裝置,其包括上述機械學習裝置和行為控制部,其控制上述機器人的行為,上述機械學習裝置包括:意圖決定部,其根據上述訓練數據集設定上述機器人的行為,上述行為控制部根據來自上述意圖決定部的指令控制上述機器人的行為。
根據本發明的第3實施方式,提供一種機器人系統,其包括上述的機器人控制裝置、輔助人的作業的機器人、安裝在上述機器人上的末端執行器。上述機器人包括:力檢測器,其輸出與來自上述人的力對應的信號;以及狀態檢測器,其檢測機器人的位置以及姿勢,上述判定數據取得部根據上述力檢測器的輸出取得上述判定數據,上述狀態觀測部根據上述狀態檢測器的輸出取得上述狀態變量。上述狀態檢測器可以包括人感傳感器、壓力傳感器、電動機的轉矩傳感器以及接觸傳感器中的至少一個。該機器人系統具備:多個機器人;多個機器人控制裝置;以及相互連接多個上述機器人控制裝置的通信線,多個上述機器人控制裝置中的各個機器人控制裝置個別地學習進行控制的機器人的上述訓練數據集,經由通信線發送所學習的信息來共享信息。
根據本發明的第4實施方式,提供一種人與機器人協作來進行作業的機器人的機械學習方法,其中,包括如下步驟:在上述人與上述機器人協作來進行作業的期間,觀測表示上述機器人的狀態的狀態變量的步驟;取得與上述人的負擔度以及作業效率中的至少一方相關的判定數據的步驟;以及根據上述狀態變量以及上述判定數據,學習用於設定上述機器人的行為的訓練數據集的步驟。
附圖說明
通過參照以下的附圖,更明確地理解本發明。
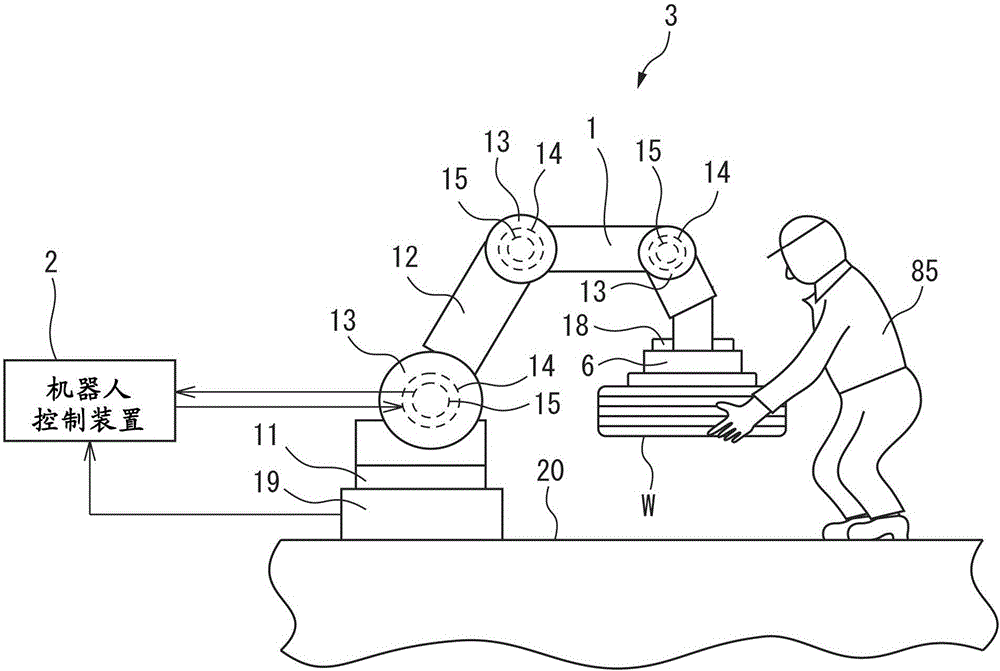
圖1是概要性地表示實施方式中的機器人和人進行協作作業的情況的圖。
圖2是表示實施方式中的一例的機器人系統的框圖。
圖3是示意性地表示神經元的模型的圖。
圖4是示意性地表示組合圖3所示的神經元而構成的三層的神經網絡的圖。
圖5是說明搬運工件的路徑的概要圖。
圖6是說明機器人前端點的移動點的圖。
圖7是說明機器人前端點的移動點的放大圖。
圖8是表示實施方式中的其他例子的機器人系統的框圖。
圖9是表示圖2所示的機器人系統的變形例的框圖。
具體實施方式
以下,參照附圖對實施方式中的機械學習裝置、機器人控制裝置、機器人系統以及機械學習方法進行說明。然而,應當理解本發明並不限定於附圖或以下說明的實施方式。
在機器人系統中,人和機器人協作地進行預先決定的作業。在本實施方式中,示出了人和機器人協作來搬運工件的例子並進行說明。
圖1表示本實施方式中的機器人系統的概要圖。圖2表示本實施方式中的一例的機器人系統的框圖。參照圖1和圖2,機器人系統3具備輔助工件W的搬運的機器人1和控制機器人1的機器人控制裝置2。本實施方式的機器人1是包含臂部12和多個關節部13的多關節機器人。機器人系統3具備安裝在機器人1上的作為末端執行器的手部6。手部6具有把持或釋放工件W的功能。末端執行器並不限定於手部,可以使用與作業內容對應的末端執行器。
機器人1包括驅動各個關節部13的臂部驅動裝置44。臂部驅動裝置44包括配置於關節部13的內部的臂部驅動電動機14。臂部驅動電動機14進行驅動,從而可以使臂部12通過關節部13彎曲成所希望的角度。此外,本實施方式的機器人1形成為整個臂部12可圍繞向鉛垂方向延伸的旋轉軸進行旋轉。臂部驅動電動機14包括使臂部12旋轉的電動機。
機器人1具備打開或關閉手部6的手部驅動裝置45。本實施方式的手部驅動裝置45包括驅動手部6的手部驅動缸18、用於向手部驅動缸18提供壓縮空氣的空氣泵以及電磁閥。
機器人1具備支持臂部12的底座部11。本實施方式中的機器人1具備用於檢測向底座部11作用的力的力檢測器19。向底座部11作用的力相當於作用於機器人1的力。力檢測器19輸出與來自人的力對應的信號。本實施方式的力檢測器19被固定在地面20。
作為力檢測器19,可以採用可檢測作用於機器人1的力的大小以及力的方向的任意的檢測器。本實施方式的力檢測器19包括與底座部11連接的金屬基材和安裝於基材表面的應變傳感器。並且,力檢測器19可以根據由應變傳感器檢測出的變形量,計算出作用於機器人1的力。
本實施方式的機器人1包括用於檢測機器人的位置以及姿勢的狀態檢測器。狀態檢測器檢測出機器人前端點的位置以及機器人1的姿勢。本實施方式的狀態檢測器包括安裝於各臂部驅動電動機14的旋轉角檢測器15。旋轉角檢測器15檢測出臂部驅動電動機14驅動時的旋轉角。可以根據各臂部驅動電動機14的旋轉角,檢測出機器人1的位置、姿勢、速度以及加速度。
另外,作為狀態檢測器,除了旋轉角檢測器15外,例如可以使用攝像機、人感傳感器、壓力傳感器、電動機的轉矩傳感器以及接觸傳感器等。即,作為狀態觀測部51觀測的狀態變量,除了旋轉角檢測器15的輸出外,也可以是從攝像機、人感傳感器、壓力傳感器、電動機的轉矩傳感器以及接觸傳感器等得到的數據(狀態量)。當然,這些攝像機、人感傳感器、壓力傳感器、電動機的轉矩傳感器以及接觸傳感器等例如可以直接設於機器人1(手部6)的預定位置,或者也可以安裝在機器人1周邊的恰當的位置。
根據機器人控制裝置2的動作指令驅動機器人1。機器人控制裝置2包括運算處理裝置,該運算處理裝置具有經由總線相互連接的CPU(Central Processing Unit,中央處理單元)、RAM(Random Access Memory,隨機存取存儲器)以及ROM(Read Only Memory,只讀存儲器)等。機器人控制裝置2包括存儲各種信息的存儲部59。機器人控制裝置2包括控制臂部驅動裝置44以及手部驅動裝置45的行為控制部43。根據來自行為控制部43的動作指令,臂部驅動裝置44以及手部驅動裝置45進行驅動。
本實施方式的機器人控制裝置2包括推定從機器人1的外側向機器人1施加的外力的外力計算部46。通過力檢測器19檢測出的力包括因機器人1的質量以及機器人的動作產生的內力、從機器人1的外側向機器人1施加的外力。
在沒有從機器人1的外側施加力的狀態下,外力計算部46計算出在機器人1動作時因自重而作用於機器人1的內力。可以根據通過旋轉角檢測器15的輸出而檢測出的機器人的位置、姿勢以及機器人的質量等,計算出內力。機器人1的質量等可以預先存儲在存儲部59中。外力計算部46從由力檢測器19檢測出的力減去內力來計算出外力。外力相當於人85向工件施加的力。
機器人控制裝置2包括輸入部41以及顯示部42。顯示部42形成為可顯示與機器人1的運轉相關的信息。作為顯示部42,可以示例液晶顯示裝置。輸入部41形成為人可向機器人控制裝置2輸入所希望的指令。作為輸入部41,可以示例鍵盤等。
圖5是說明在本實施方式的機器人系統中,搬運工件的路徑的概要圖。參照圖1和圖5,在本實施方式中,進行將配置於地面20的工件W搬運到作業臺81的上表面的作業。例如,工件W為重量較大的工件。若人85想要搬運這樣的工件,則非常疲憊或難以搬運。本實施方式的工件W為汽車輪胎。
在搬運工件W的情況下,如箭頭91~93所示,存在多條搬運工件W的路徑。此外,存在人85需要較大力的區間,或較小的力就足夠的區間等。此外,即使工件W的位置相同,也存在機器人1的各種姿勢。
參照圖2,本實施方式的機器人控制裝置2具備機械學習裝置5,該機械學習裝置5學習人的行為模式,學習機器人的控制方法以便對人進行適當的輔助。本實施方式的機械學習裝置5在機器人1驅動的期間中的預先決定的移動點,選擇判斷為最佳的機器人1的行為。即,機械學習裝置5發送在判斷為最佳的驅動模式下驅動機器人1的指令。
機械學習裝置5具備狀態觀測部51,該狀態觀測部51在人85和機器人1協作進行作業的期間,取得表示機器人1的狀態的狀態變量。本實施方式的狀態變量為機器人1的位置、姿勢、速度以及加速度。例如,可以將機器人前端點的位置、速度、加速度用作狀態變量。可以根據旋轉角檢測器15的輸出檢測出機器人1的位置、姿勢、速度以及加速度。向狀態觀測部51輸入旋轉角檢測器15的輸出信號。
作為狀態變量,並不限於該形態,可以使用表示機器人的狀態的任意的變量。例如,狀態觀測部51可以取得機器人1的位置、姿勢、速度、加速度中的至少一個變量。
機械學習裝置5具備取得與人85的負擔相關的判定數據的判定數據取得部52。本實施方式的判定數據包括搬運工件W時人85施加的力的大小以及人85施加的力的方向。此外,本實施方式的判定數據包括移動工件W時的移動時間。
本實施方式的判定數據取得部52根據力檢測器19的輸出取得判定數據。通過外力計算部46計算出的外力的大小相當於人85的力的大小。通過外力計算部46計算出的外力的方向相當於人85向工件W施加的力的方向。判定數據取得部52從外力計算部46接收人的力的大小以及人的力的方向。
機器人控制裝置2具備測定作業時間的移動時間測定部47。本實施方式的移動時間測定部47計算出在後述的移動點之間移動時的移動時間。本實施方式的移動時間測定部47根據行為控制部43的指令計算出移動時間。將通過移動時間測定部47測定出的移動時間發送給判定數據取得部52。
作為判定數據,並不限於上述形態,可以採用與人的負擔度以及作業效率中的至少一方相關的任意數據。例如,作為判定數據,除了機器人感知的負荷的大小及其方向、周圍的人或物所感知的負荷的大小及其方向、周圍的人或物的負擔度以及移動時間等外,還可以利用來自攝像機、人感傳感器、壓力傳感器等的信息。另外,在本說明書中,人除了實際與機器人協作來進行處理(作業)的作業者外,例如還包括如下的各種人:不直接操作機器人,但在機器人周邊觀察處理的人,或者偶爾通過機器人附近的人。
本實施方式的機械學習裝置5具備學習部54,該學習部54根據狀態變量和判定數據學習用於設定機器人的行為的訓練數據集。學習部54從狀態觀測部51取得狀態變量。此外,學習部54從判定數據取得部52取得判定數據。訓練數據集是根據狀態變量和判定數據決定的行為的價值信息的集合。機械學習裝置5可以通過比較與訓練數據集的狀態以及行為相關的值來設定機器人的驅動方法。另外,本實施方式的應用並不限定於工業機器人,例如,當然也可以應用於場地機器人、服務機器人。
在此,對機械學習裝置進行說明。機械學習裝置具有如下的功能:通過解析從輸入到裝置的數據集合中提取其中的有用的規則、知識表現、判斷基準等,輸出該判斷結果,並且進行知識的學習(機械學習)。機械學習方法有多種,例如大致分為「有教師學習」、「無教師學習」以及「強化學習」。而且,實現這些方法時,還有學習特徵量其本身的提取的、稱為「深層學習(Deep Learning)」的方法。
另外,圖2所示的機械學習裝置5應用了「強化學習」,此外,參照圖9後述的機械學習裝置7應用了「有教師學習」。這些機械學習(機械學習裝置5、7)也可以使用通用的計算機或處理器,但若例如應用GPGPU(General-Purpose computing on Graphics Processing Units,通用計算圖形處理單元)、大規模PC群集等,則能夠進行更高速處理。
首先,有教師學習是如下方法:通過向機械學習裝置大量提供教師數據即某輸入和結果(標籤)的數據的組,學習這些數據集中的特徵,通過歸納獲得根據輸入推定結果的模型(學習模型)即其關係性。例如,能夠通過後述的神經網絡等算法來實現。
此外,無教師學習是如下方法:通過向學習裝置僅大量提供輸入數據,學習輸入數據如何分布,即使不提供對應的教師輸出數據,也能夠通過對輸入數據進行壓縮、分類、整形等的裝置進行學習。例如,能夠在相似者之間對這些數據集中的特徵進行聚類。使用該結果設置某基準,並進行使之最佳化的輸出分配,由此能夠實現輸出的預測。
另外,作為無教師學習與有教師學習的中間的問題設定,有稱為半有教師學習的學習,這例如對應於如下的情況:存在僅部分輸入和輸出的數據組,除此以外為僅輸入的數據。在本實施方式中,在無教師學習中利用即使不使機器人實際移動也能夠取得的數據(圖像數據、模擬數據等),由此能夠有效地進行學習。
接著,對強化學習進行說明。首先,作為強化學習的問題設定,按如下方式進行思考。
·機器人觀測環境狀態,決定行為。
·環境按照某種規則變化,並且,有時自身的行為也會對環境產生變化。
·每次實施行為時,返回回報信號。
·想要最大化的是將來的(折扣)回報的合計。
·從完全不知道或不完全知道行為引起的結果的狀態起開始學習。即,機器人實際行為後,可以初次將該結果作為數據而得到。換句話說,需要一邊試錯一邊探索最佳行為。
·也可以將進行了事先學習(上述的有教師學習、逆強化學習的方法)的狀態設為初始狀態,從較佳的開始地點開始學習以便模擬人的動作。
在此,強化學習是指如下的方法:除了判定和分類外,通過學習行為,根據行為對環境產生的相互作用來學習恰當的行為,即學習進行用於使將來得到的回報最大化的學習的方法。以下,作為例子,在Q學習的情況下繼續說明,但並不限定於Q學習。
Q學習是在某環境狀態s下學習用於選擇行為a的價值Q(s,a)的方法。換句話說,在某狀態s時,將價值Q(s,a)最高的行為a選擇為最佳行為即可。但是,最初,對於狀態s和行為a的組合,完全不知道價值Q(s,a)的正確值。因此,智能體(行為主體)在某狀態s下選擇各種行為a,針對此時的行為a提供回報。由此,智能體選擇更佳的行為,即學習正確的價值Q(s,a)。
並且,行為的結果,想要使將來得到的回報的合計最大化,因此以最終Q(s,a)=E[Σ(γt)rt]為目標。在此,E[]表示期待值,t為時刻,γ為後述的稱為折扣率的參數,rt為時刻t的回報,Σ為時刻t的合計。該式中的期待值是按照最佳的行為發生狀態變化時所取的值,不知道該值,因此一邊探索一邊學習。例如,可以通過下式(1)表示這樣的價值Q(s,a)的更新式。
在上述式(1)中,st表示時刻t的環境狀態,at表示時刻t的行為。通過行為at,狀態變化為st+1。rt+1表示根據該狀態變化得到的回報。此外,附有max的項為在狀態st+1下選擇此時獲知的Q值最高的行為a時的Q值乘上γ而得的項。在此,γ為0<γ≤1的參數,稱為折扣率。此外,α為學習係數,設為0<α≤1的範圍。
上述的式(1)表示如下方法:根據嘗試at的結果而返回的回報rt+1,更新狀態st下的行為at的評價值Q(st,at)。即,表示若基於回報rt+1和行為a的下個狀態下的最佳行為max a的評價值Q(st+1,max at+1)的合計大於狀態s下的行為a的評價值Q(st,at),則將Q(st,at)設為較大,相反,若小於狀態s下的行為a的評價值Q(st,at),則將Q(st,at)設為較小。換句話說,作為結果,使某狀態下的某行為的價值接近基於作為結果而立即返回的回報和該行為的下個狀態下的最佳行為的價值。
在此,Q(s,a)的計算機上的表現方法有:對於所有狀態行為對(s,a),將其值作為表而保持的方法;以及準備近似Q(s,a)的函數的方法。在後者的方法中,能夠通過概率梯度下降法等方法來調整近似函數的參數,由此實現上述式(1)。另外,作為近似函數,可以使用後述的神經網絡。
此外,作為有教師學習、無教師學習的學習模型,或者強化學習中的價值函數的近似算法,可以使用神經網絡。圖3是示意性地表示神經元的模型的圖,圖4是示意性地表示組合圖3所示的神經元而構成的三層神經網絡的圖。即,神經網絡例如由模仿圖3所示的神經元的模型的運算裝置以及存儲器等構成。
如圖3所示,神經元輸出針對多個輸入x(在圖3中,作為一例為輸入x1~輸入x3)的輸出(結果)y。對各輸入x(x1,x2,x3)乘以與該輸入x對應的權值w(w1,w2,w3)。由此,神經元輸出通過下式(2)表現的結果y。另外,輸入x、結果y以及權值w全部為向量。此外,在下式(2)中,θ為偏置,fk為激活函數。
參照圖4,說明組合圖3所示的神經元而構成的三層的神經網絡。如圖4所示,從神經網絡的左側輸入多個輸入x(在此,作為一例為輸入x1~輸入x3),從右側輸出結果y(在此,作為一例為結果y1~輸入y3)。具體地,輸入x1、x2、x3乘以對應的權值後輸入3個神經元N11~N13中的各個神經元。將這些對輸入乘以的權值統一表述為W1。
神經元N11~N13分別輸出z11~z13。在圖4中,這些z11~z13被統一表述為特徵向量Z1,可以視為提取出輸入向量的特徵量而得的向量。該特徵向量Z1為權值W1與權值W2之間的特徵向量。z11~z13乘以對應的權值後分別輸入2個神經元N21、N22中的各個神經元。將這些對特徵向量乘以的權值統一表述為W2。
神經元N21、N22分別輸出z21、z22。在圖4中,將這些z21、z22統一表述為特徵向量Z2。該特徵向量Z2為權值W2與權值W3之間的特徵向量。z21、z22乘以對應的權值後分別輸入到3個神經元N31~N33的各個神經元。將這些對特徵向量乘以的權值統一表述為W3。
最後,神經元N31~N33分別輸出結果y1~結果y3。神經網絡的動作中有學習模式和價值預測模式。例如,在學習模式中,使用學習數據集學習權值W,在預測模式中使用其參數判斷機器人的行為。另外,方便起見,寫成了預測,但也可以是檢測/分類/推論等多種任務。
在此,能夠進行在線學習和批學習,其中,在線學習為即時學習在預測模式下實際使機器人動作而得到的數據,並反映到下個行為;批學習是使用預先收集的數據群進行統一學習,以後一直用該參數進行檢測模式。或者,也可以進行其中間的、每當一定程度的數據積壓時插入學習模式。
此外,可以通過誤差反向傳播法(Back propagation)學習權值W1~W3。另外,誤差信息從右側進入並流向左側。誤差反向傳播法是如下的方法:針對各神經元,調整(學習)各個權值以使輸入了輸入x時的輸出y與真正的輸出y(教師)的差值變小。
這樣的神經網絡為三層以上,還可以進一步增加層(稱為深層學習)。此外,也可以自動地僅從教師數據獲得階段性地提取輸入的特徵並返回結果的運算裝置。因此,一實施方式的機械學習裝置5為了實施上述的Q學習(強化學習),如圖2所示,具備例如狀態觀測部51、學習部54以及意圖決定部58。但是,如上所述,應用於本發明的機械學習方法並不限定於Q學習。即,可以應用在機械學習裝置中能夠使用的方法即「有教師學習」、「無教師學習」、「半有教師學習」以及「強化學習(Q學習以外的強化學習)」等各種方法。
圖6是說明本實施方式的移動點的概要圖。在圖6中,為了簡化說明,示出了機器人前端點在二維平面上移動的例子。工件W從初始位置88被搬運至目標位置89。在機器人前端點有可能移動的區域中格子狀地設定了移動點P。移動點P成為機器人前端點通過的點。機器人前端點從與初始位置88對應的移動點P00移動至與目標位置89對應的移動點Pnm。
圖7表示說明機器人前端點的移動的概要圖。在本實施方式中,在各個移動點P預先決定了機器人前端點的移動方向。箭頭94~97所示的方向為機器人前端點的移動方向。當機器人前端點位於1個移動點P時,通過下個行為,機器人前端點移動到相鄰的其他移動點P。在圖7所示的例子中,當機器人前端點配置於移動點P11時,機器人前端點向移動點P12、P21、P10、P01中的某個點移動。
在本實施方式中,進行各種機械學習方法中的採用了上述的Q學習的強化學習。此外,本實施方式的訓練數據集包括多個行為價值變量Q。另外,如上所述,本實施方式可以應用「有教師學習」、「無教師學習」、「半有教師學習」以及「強化學習(包括Q學習)」等各種方法。
在本實施方式中,狀態st對應於機器人1的狀態變量。即,狀態st包括機器人1的位置、姿勢、速度以及加速度等。行為at關於機器人前端點的移動,例如相當於箭頭94~97所示的方向的移動。行為at例如包括與箭頭94~97所示的方向的移動相關的機器人1的位置、姿勢、速度以及加速度等。
本實施方式的學習部54在每次進行工件W的搬運時更新行為價值變量Q。學習部54包括設定回報的回報計算部55和更新行為價值變量Q的函數更新部56。回報計算部55根據判定數據取得部52取得的判定數據設定回報rt。此外,回報計算部55也可以根據由狀態觀測部51取得的狀態變量設定回報rt。
回報計算部55可以設定人的負擔(負擔度)越小,作業效率越高則越大的回報rt。例如,在工件W大幅度減速或大幅度加速的情況下,對人的負擔增大,作業效率變低。即,可以認為機器人1的加速度的絕對值(加速度的大小)越小,則人的負擔越小,作業效率越高。另外,若加速度的絕對值大,則機器人1急劇進行動作,因此可以判別為非優選的狀態。因此,回報計算部55可以設定機器人1的加速度的絕對值越小則越大的回報。此外,人施加的力的大小越小越好。因此,回報計算部55可以設定人施加的力的大小(向機器人施加的外力的大小)越小則越大的回報。
並且,將工件W從初始位置88搬運至目標位置89的作業時間越短,則人的負擔越小,作業效率越高。因此,回報計算部55設定移動點P之間的移動時間越短則越大的回報。此外,在圖5的形態下,若工件W向下移動,則搬運路徑變長。因此,在機器人前端點的位置向下側移動,或人施加的力的方向為下側的情況下,回報計算部55設定小的回報。在此,作為人的負擔度,不僅表示對人的負擔的程度,還包括基於各種原因的負荷,例如對人的意外的接觸或按壓等,並且,除了人,例如還可以包括對周圍的物品的負擔度。
此外,回報計算部55可以根據任意的人的行為設定回報。例如,在工件W與作業臺81碰撞的情況下,回報計算部55可以設定小的正的回報或負的回報。
在回報的設定中,例如人可以預先決定與力的大小等變量對應的回報的值,並存儲在存儲部59中。回報計算部55可以讀入存儲於存儲部59的回報來設定。或者,預先使存儲部59存儲人用於計算回報的計算式,回報計算部55根據計算式計算出回報。
接著,函數更新部56使用上述的式(1)或式(2)更新行為價值變量Q。即,根據實際的機器人的行為以及人施加的力,更新預先決定的移動點的機器人的行為的價值。
另外,人也可以預先設定各個移動點P的行為價值變量Q的初始值。另外,人也可以預先設定隨機的初始值。
機械學習裝置5包括根據訓練數據集設定機器人1的行為的意圖決定部58。本實施方式的意圖決定部58根據通過學習部54更新的行為價值變量Q設定機器人1的行為。例如,意圖決定部58可以選擇行為價值變量Q最大的行為。在本實施方式的強化學習中使用ε-greedy方法。在ε-greedy方法中,意圖決定部58以預先決定的概率ε設定隨機的行為。此外,意圖決定部58以概率(1-ε)設定行為價值變量Q最大的行為。即,意圖決定部58通過概率ε的比例選擇與被認為最佳的行為不同的行為。通過該方法,有時可以發現比判定為最佳的機器人的行為更好的機器人的行為。
將通過意圖決定部58設定的機器人1的行為指令發送給行為控制部43。行為控制部43根據來自意圖決定部58的指令控制機器人1和手部6。
這樣,本實施方式的機械學習方法包括如下的步驟:在人與機器人協作來作業的期間,取得表示機器人的狀態的狀態變量;以及取得與人的負擔度以及作業效率中的至少一方相關的判定數據。機械學習方法包括根據狀態變量和判定數據,學習用於決定機器人的行為的訓練數據集的步驟。
本實施方式的機械學習裝置以及機械學習方法重複進行工件W的搬運,由此可以根據人的行為模式學習機器人的控制方法。並且,能夠設定人的負擔較小、作業效率高、作業時間更短的最佳的機器人的控制方法。
另外,作為在機械學習裝置以及機械學習方法中進行的機械學習,並不限於上述方式,可以進行任意的機械學習。例如,機械學習裝置也可以通過深層學習使用神經網絡來多層化並設定最佳的行為。代替使用將多個行為以及多個狀態設為函數的行為價值變量表,也可以使用輸出給出預定狀態時的與各個行為對應的行為價值變量的神經網絡。
在上述的實施方式中,格子狀地配置了移動點,但並不限於該形態,也可以以任意形態設定移動點。此外,通過縮小移動點之間的間隔,能夠使機器人的動作變得流暢。在上述的實施方式中,在平面上設定了移動點,因此機器人的移動成為平面狀,但通過將移動點配置於三維空間,能夠使移動點三維地移動。
參照圖5,本實施方式的機械學習裝置5包括判別人的人判別部57。預先生成每個人的訓練數據集。存儲部59存儲每個人的訓練數據集。在本實施方式中,人85向輸入部41輸入每個人的編號。人判別部57根據所輸入的編號從存儲部59讀入與人對應的訓練數據集。然後,學習部54學習與人對應的訓練數據集。通過進行該控制,可以對每個人設定基於人的行為模式的機器人的控制方法。即,可以對每個人實施最佳的機器人的控制。例如,人有高個的人、矮個的人、腰腿強壯的人、臂力強的人等各種人。能夠與各個人對應地實現最佳的機器人的控制。
另外,作為判別人的控制,並不限於上述方式,可以採用任意的方法。例如,可以在機械學習裝置中配置編號讀取裝置。人持有記載了個別編號的牌。然後,編號讀取裝置讀取編號並將結果發送給人判別部。人判別部可以根據所讀取的編號來判別人。
圖8是表示本實施方式的其他機器人系統的框圖。在其他機器人系統(製造系統)4中進行分散學習。如圖8所示,其他機器人系統4具備多個機器人和多個機器人控制裝置。機器人系統4具備第1機器人1a和第2機器人1b。機器人系統4具備安裝於第1機器人1a的第1手部6a和安裝於第2機器人1b的第2手部6b。這樣,其他機器人系統4具備2個機器人1a、1b和2個手部6a、6b。
機器人系統4具備控制第1機器人1a的第1機器人控制裝置2a和控制第2機器人1b的第2機器人控制裝置2b。第1機器人控制裝置2a的結構以及第2機器人控制裝置2b的結構與上述機器人控制裝置2的結構相同。多個機器人控制裝置2a、2b通過包含通信線21的通信裝置相互連接。通信裝置例如可以通過乙太網(註冊商標)實施通信。機器人控制裝置2a、2b形成為可以通過通信交換相互的信息。
在機器人系統4中,多個機器人1a、1b和人協作來進行作業。在圖8所示的例子中,通過2臺機器人輔助人的作業。第1機器人控制裝置2a個別地學習第1機器人1a的控制。此外,第2機器人控制裝置2b個別地學習第2機器人1b的控制。並且,可以經由通信線21相互發送通過各個機器人控制裝置學習的信息。
這樣,第1機器人控制裝置2a和第2機器人控制裝置2b可以共享通過各個機器人控制裝置2a、2b學習的信息。通過實施該控制,能夠共享用於學習的行為模式等,增加學習次數。該結果,能夠提高學習精度。
在上述實施方式中,示例了搬運工件W的協作作業,但作為協作作業,並不限於該方式,可以採用任意的協作作業。例如,可以示例機器人和人協作地將1個部件安裝到預定裝置的作業等。
圖9是圖2所示的機器人系統的變形例的框圖,表示應用了有教師學習的機器人系統3』。如圖9所示,機器人系統3』例如包括機器人1、手部6以及機器人控制裝置2』。機器人控制裝置2』包括機械學習裝置7、輸入部41、顯示部42、行為控制部43、外力計算部46以及移動時間測定部47。機械學習裝置7包括狀態觀測部71、判定數據取得部72、學習部74、人判別部77、意圖決定部78以及存儲部79。學習部74包括回報計算部55和函數更新部56。
即,從圖9與上述圖2的比較可知,在圖9所示的變形例的機器人系統3』的學習部74中,將圖2的學習部54中的回報計算部55和函數更新部56置換為誤差計算部75和學習模型變更部76。另外,實質上,其他結構與圖2所示的機械學習裝置5中的結構相同,因此省略其說明。從外部向誤差計算部75輸入教師數據,例如進行與通過到此為止的學習得到的數據的誤差變小的計算,通過學習模型變更部76更新學習模型(誤差模型)。即,誤差計算部75接受狀態觀測部71的輸出以及教師數據等,例如計算帶結果(標籤)的數據與安裝於學習部74的學習模型的輸出的誤差。在此,在向機器人控制裝置2』輸入的程序(機器人系統3』處理的動作)相同的情況下,教師數據可以保持使機器人系統3』進行處理的預定日的前日為止得到的帶結果(標籤)的數據,在該預定日向誤差計算部75提供帶結果(標籤)的數據。
或者,通過存儲卡或通信線路向該機器人系統3』的誤差計算部75提供通過在機器人系統3』的外部進行的模擬等得到的數據或其他機器人系統的帶結果(標籤)的數據作為教師數據。並且,例如通過內置於學習部74的閃速存儲器(Flash Memory)等非易失性存儲器保持帶結果(標籤)的數據,在學習部74中可以直接使用該非易失性存儲器所保持的帶結果(標籤)的數據。
以上,在考慮具備多個機器人系統3』(3)的製造系統(製造設備)的情況下,例如對每個機器人系統3』(3)設置機械學習裝置7(5),對每個機器人系統3』(3)設置的多個機械學習裝置7(5)例如可以經由通信介質相互共享或交換數據。此外,機械學習裝置7(5)例如也可以存在於雲伺服器上。
通過本發明,提供一種能夠學習人的行為模式,設定對人進行適當的輔助的機器人的控制方法的機械學習裝置、機器人控制裝置、機器人系統以及機械學習方法。
以上,對實施方式進行了說明,但在此記載的所有例子或條件是以幫助理解應用於發明和技術的發明概念為目的而進行的記載,所記載的例子或條件並不特別限制發明的範圍。此外,說明書的這樣的記載並不表示發明的優點和缺點。雖然詳細地記載了發明的實施方式,但應理解為在不脫離發明的主旨以及範圍的情況下能夠進行各種變更、置換、變形。