一種圖像數據集的稀疏表示的加速方法以及裝置與流程
2023-06-06 21:23:27 3
本發明涉及數據處理領域,尤其涉及一種圖像數據集的稀疏表示的加速方法以及裝置。
背景技術:
圖像數據集的稀疏表示包括自學習方法,自學習方法不需任何預定的形式獲取超完備字典,自學習方法的基本假設是:複雜的非相干特性的結構可以直接從數據提取,而不是使用一個數學表達描述。例如,給定一組圖像向量,K-SVD(全稱:K-Singular Value Decomposition;中文:K-奇異值分解)方法能在嚴格的稀疏約束下尋找導致在該組中每個成員表示最好的字典。非參數貝葉斯字典學習使用一個截斷的β-伯努利過程來學習相匹配的圖像塊的字典。
在當前大數據的時代,圖像數據集的大小已經呈爆炸式的增長,而自學習的方法不能有效的處理非常大的數據集,因為每次學習迭代都需要訪問整個數據集,處理速度較慢。
因此,現有技術中存在對圖像數據集的稀疏表示的處理速度較慢的技術問題。
技術實現要素:
本發明實施例通過提供一種圖像數據集的稀疏表示的加速方法以及裝置,用以解決現有技術中存在的對圖像數據集的稀疏表示的處理速度較慢的技術問題。
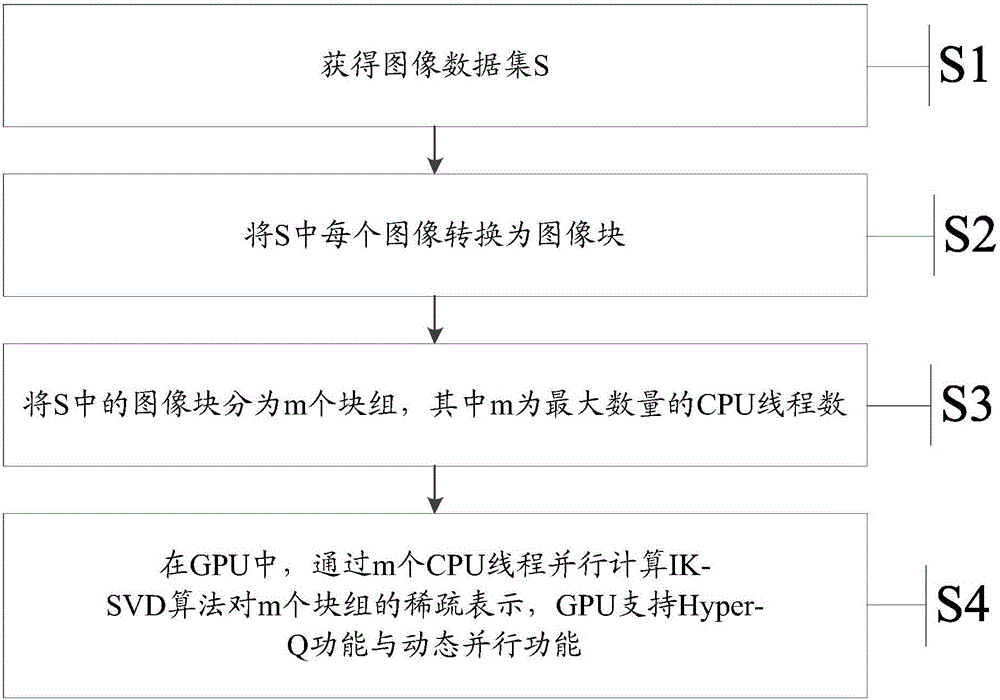
本發明實施例提供了一種圖像數據集的稀疏表示的加速方法,所述方法包括:
獲得圖像數據集S,S={Yi|1≤i≤s^Yi∈Rn×N};
將S中每個圖像轉換為圖像塊;
將S中的圖像塊分為m個塊組,其中m為最大數量的CPU線程數;
在GPU中,通過m個CPU線程並行計算IK-SVD算法對所述m個塊組的稀疏表示,所述GPU支持Hyper-Q功能與動態並行功能。
可選地,所述將S中每個圖像轉換為圖像塊,具體為:
針對S中任一圖像Y∈S,將Y分為Pi個塊,
可選地,所述通過m個CPU線程並行計算IK-SVD算法對所述m個塊組的稀疏表示,具體包括:
所述m個線程對m個塊組並行執行:將局部數據傳送到GPU存儲器;計算稀疏係數;從GPU輸出結果。
可選地,所述計算稀疏係數,具體包括:
通過IK-SVD算法訓練對塊組中的第一個圖像塊獲得超完備字典D1;
根據塊組中的剩餘圖像塊對所述超完備字典D1進行更新,其中,在每一次更新時通過GPU計算遞歸Cholesky分解中的矩陣運算,直到收斂。
可選地,所述在每一次更新時通過GPU計算遞歸Cholesky分解中的矩陣運算,包括:
通過和選取所述新的原子;以及
通過GPU計算遞歸Cholesky分解中矩陣的左上角矩陣Ln-1更新;以及
通過GPU計算所述矩陣中子矩陣A和子矩陣B的順序更新。
本發明實施例第二方面還提供一種圖像數據集的稀疏表示的加速裝置,其特徵在於,所述裝置包括:
獲得單元,用於獲得圖像數據集S,S={Yi|1≤i≤s^Yi∈Rn×N};
轉換單元,用於將S中每個圖像轉換為圖像塊;
分組單元,用於將S中的圖像塊分為m個塊組,其中m為最大數量的CPU線程數;
計算單元,用於在GPU中,通過m個CPU線程並行計算IK-SVD算法對所述m個塊組的稀疏表示,所述GPU支持Hyper-Q功能與動態並行功能。
可選地,所述轉換單元具體用於針對S中任一圖像Y∈S,將Y分為Pi個塊,
可選地,所述計算單元具體用於所述m個線程對m個塊組並行執行:將局部數據傳送到GPU存儲器;計算稀疏係數;從GPU輸出結果。
可選地,所述計算單元具體用於通過IK-SVD算法訓練對塊組中的第一個圖像塊獲得超完備字典D1,並根據塊組中的剩餘圖像塊對所述超完備字典D1進行更新,其中,在每一次更新時通過GPU計算遞歸Cholesky分解中的矩陣運算,直到收斂。
可選地,所述計算單元具體用於通過和選取所述新的原子,以及通過GPU計算遞歸Cholesky分解中矩陣的左上角矩陣Ln-1更新,以及通過GPU計算所述矩陣中子矩陣A和子矩陣B的順序更新。
本發明實施例中提供的一個或多個技術方案,至少具有如下技術效果或優點:
由於採用了將圖像數據集S中每個圖像轉換為圖像塊,並將S中的圖像塊分為m個塊組,最後在GPU中通過m個CPU線程並行技術IK-SVD算法對m個塊組的稀疏表示的技術方案,其中m個CPU線程在GPU中計算m個塊組的稀疏表示時各不影響,同時IK-SVD算法需要多次執行稀疏編碼,所以在GPU中通過m個線程並行計算IK-SVD算法對m個塊組的稀疏表示時的計算速度能夠得到大大提高,解決了現有技術中存在的對圖像數據集的稀疏表示的處理速度較慢的技術問題。
附圖說明
圖1為本發明實施例提供的圖像數據集的稀疏表示的加速方法的流程圖;
圖2為本發明實施例提供的圖像數據集的稀疏表示的加速方法的過程示意圖;
圖3為本發明實施例提供的BRC格式矩陣的表示示意圖;
圖4為本發明實施例提供的圖像數據集的稀疏表示的加速裝置的模塊圖。
具體實施方式
本發明實施例通過提供一種圖像數據集的稀疏表示的加速方法以及裝置,用以解決現有技術中存在的對圖像數據集的稀疏表示的處理速度較慢的技術問題。
本發明實施例中的技術方案解決上述技術問題,總體思路如下:
本發明實施例提供一種圖像數據集的稀疏表示的加速方法,方法包括:
首先,獲得圖像數據集S,S={Yi|1≤i≤s^Yi∈Rn×N};
接著,將S中每個圖像轉換為圖像塊;
然後,將S中的圖像塊分為m個塊組,其中m為最大數量的CPU線程數;
最後,在GPU中,通過m個CPU線程並行計算IK-SVD算法對m個塊組的稀疏表示,GPU支持Hyper-Q功能與動態並行功能。Hyper-Q技術允許多個CPU內核與同一個單一GPU同時開展工作,從而大大提高了GPU的利用率,大幅降低了CPU的空閒時間,而動態並行功能使得GPU線程可以自動刷新新線程,減少了CPU控制GPU刷新線程的時間,從而簡化了並行操作。
可以看出,由於採用了將圖像數據集S中每個圖像轉換為圖像塊,並將S中的圖像塊分為m個塊組,最後在GPU中通過m個CPU線程並行技術IK-SVD算法對m個塊組的稀疏表示的技術方案,其中m個CPU線程在GPU中計算m個塊組的稀疏表示時各不影響,同時IK-SVD算法需要多次執行稀疏編碼,所以在GPU中通過m個線程並行計算IK-SVD算法對m個塊組的稀疏表示時的計算速度能夠得到大大提高,解決了現有技術中存在的對圖像數據集的稀疏表示的處理速度較慢的技術問題。
為了更好的理解上述技術方案,下面將結合說明書附圖以及具體的實施方式對上述技術方案進行詳細的說明。
請參考圖1,圖1為本發明實施例提供的圖像數據集的稀疏表示的加速方法的流程圖,如圖1所示,該方法包括:
S1:獲得圖像數據集S,S={Yi|1≤i≤s^Yi∈Rn×N};在本實施例中,圖像數據集S可以為大規模圖像數據集,例如,在本實施例中,S內可以包括10000張圖片;
S2:將S中每個圖像轉換為圖像塊;
S3:將S中的圖像塊分為m個塊組,其中m為最大數量的CPU線程數;
S4:在GPU中,通過m個CPU線程並行計算IK-SVD算法對m個塊組的稀疏表示,GPU支持Hyper-Q功能與動態並行功能。
請繼續參考圖2,圖2為本發明實施例提供的圖像數據集的稀疏表示的加速方法的過程圖。
請同時參考圖1和圖2,在本實施例中,將S中每個圖像轉換為圖像塊,具體為:針對S中任一圖像Y∈S,將Y分為Pi個塊,
在具體實施過程中,可以根據S中的圖像大小,將每個圖像分為合適數目的圖像塊,例如在S中圖像中最小圖片的大小為1Mb的情況下,可以將S中每張圖片按照100kb/塊的大小進行分塊,當然,此處的100kb/塊僅僅是一個舉例,通過本實施例的介紹,本領域所屬的技術人員能夠根據實際情況,選擇其他合適的數值來對圖像進行分塊,以滿足實際情況的需要,在此就不再贅述了。
請同時參考圖1和圖2,在本實施例中,通過m個CPU線程並行計算IK-SVD算法對m個塊組的稀疏表示,具體包括:m個線程對m個塊組並行執行:將局部數據傳送到GPU存儲器;計算稀疏係數;從GPU輸出結果。
在具體實施過程中,如圖2所示,在GPU中,m個CPU線程執行對應的m個塊組的計算稀疏係數的任務,並且由於各個m個CPU線程在GPU中計算m個塊組的稀疏表示時各不影響,同時IK-SVD算法需要多次執行稀疏編碼,所以在GPU中通過m個線程並行計算IK-SVD算法對m個塊組的稀疏表示時的計算速度能夠得到大大提高,解決了現有技術中存在的對圖像數據集的稀疏表示的處理速度較慢的技術問題。
在具體實施過程中,計算稀疏係數,具體包括:
通過IK-SVD算法訓練對塊組中的第一個圖像塊獲得超完備字典D1;
根據塊組中的剩餘圖像塊對超完備字典D1進行更新,其中,在每一次更新時通過GPU計算遞歸Cholesky分解中的矩陣運算,直到收斂。
在具體實施過程中,在每一次更新時通過GPU計算遞歸Cholesky分解中的矩陣運算,包括:
通過和選取新的原子;以及
通過GPU計算遞歸Cholesky分解中矩陣的左上角矩陣Ln-1更新;以及
通過GPU計算矩陣中子矩陣A和子矩陣B的順序更新。
在具體實施過程中,通過GPU計算遞歸Cholesky分解中矩陣的左上角矩陣Ln-1更新,具體為:
通過GPU計算Ln-1←K(Solve{Ln-1=KDKT}in parallel)。
在具體實施過程中,通過GPU計算矩陣中子矩陣A和子矩陣B的順序更新,包括:
通過GPU計算A←Temp(Temp=AK-T in parallel)和B←TempTempT in parallel。
在具體實施過程中,在IK-SVD方法中存在大量的矩陣矩陣相乘(SpMM)和矩陣向量相乘(SpMV)。基於GPU的Batch-OMP算法也主要依賴於矩陣運算。由於Coordinate(COO)、Compressed Sparse Row(CSR)、ELLPACK(ELL)和hybrid(HYB)格式的矩陣稀疏格式存在線程發散、冗餘計算、數據傳輸、缺乏適應性等問題。
本發明採用一種自適應的稀疏矩陣格式——blocked row-column(BRC)。給定矩陣M:其基於BRC格式的表示方法如圖3所示。B1為相鄰行分塊,其值設置成一個warp的大小(例如32),塊較長的行將會導致負載不平衡,然後對其進行列分塊。每一個block具有相同的大小B1×T,具體可以通過以下兩個公式進行限制:其中C為一個常量,μ是每一行非零個數的平均值,σ為標準差,MaxNZ為最大非零個數的行。
通過上述部分可以看出,由於採用了將圖像數據集S中每個圖像轉換為圖像塊,並將S中的圖像塊分為m個塊組,最後在GPU中通過m個CPU線程並行技術IK-SVD算法對m個塊組的稀疏表示的技術方案,其中m個CPU線程在GPU中計算m個塊組的稀疏表示時各不影響,同時IK-SVD算法需要多次執行稀疏編碼,所以在GPU中通過m個線程並行計算IK-SVD算法對m個塊組的稀疏表示時的計算速度能夠得到大大提高,解決了現有技術中存在的對圖像數據集的稀疏表示的處理速度較慢的技術問題。
基於同一發明構思,本發明實施例第二方面還提供一種圖像數據集的稀疏表示的加速裝置,請參考圖2,圖2為本發明實施例提供的圖像數據集的稀疏表示的加速裝置的示意圖,如圖2所示,該裝置包括:
獲得單元401,用於獲得圖像數據集S,S={Yi|1≤i≤s^Yi∈Rn×N};
轉換單元402,用於將S中每個圖像轉換為圖像塊;
分組單元403,用於將S中的圖像塊分為m個塊組,其中m為最大數量的CPU線程數;
計算單元404,用於在GPU中,通過m個CPU線程並行計算IK-SVD算法對m個塊組的稀疏表示,GPU支持Hyper-Q功能與動態並行功能。
在具體實施過程中,轉換單元402具體用於針對S中任一圖像Y∈S,將Y分為Pi個塊,
在具體實施過程中,計算單元404具體用於m個線程對m個塊組並行執行:將局部數據傳送到GPU存儲器;計算稀疏係數;從GPU輸出結果。
在具體實施過程中,計算單元404具體用於通過IK-SVD算法訓練對塊組中的第一個圖像塊獲得超完備字典D1,並根據塊組中的剩餘圖像塊對超完備字典D1進行更新,其中,在每一次更新時通過GPU計算遞歸Cholesky分解中的矩陣運算,直到收斂。
在具體實施過程中,計算單元404具體用於通過和選取新的原子,以及通過GPU計算遞歸Cholesky分解中矩陣的左上角矩陣Ln-1更新,以及通過GPU計算矩陣中子矩陣A和子矩陣B的順序更新。
在具體實施過程中,通過GPU計算矩陣中子矩陣A和子矩陣B的順序更新,包括:
通過GPU計算A←Temp(Temp=AK-T in parallel)和B←TempTempT in parallel。
本發明實施例中的加速裝置與前述部分介紹的加速方法是同一發明構思下的兩個方面,在前述部分中已經詳細地介紹了圖像數據集的稀疏表示的加速方法的具體過程,本領域所屬的技術人員能夠根據前述部分的描述清楚地了解加速裝置的結構以及處理過程,在此為了說明書的簡潔,就不再贅述了。
上述本發明實施例中的技術方案,至少具有如下的技術效果或優點:
由於採用了將圖像數據集S中每個圖像轉換為圖像塊,並將S中的圖像塊分為m個塊組,最後在GPU中通過m個CPU線程並行技術IK-SVD算法對m個塊組的稀疏表示的技術方案,其中m個CPU線程在GPU中計算m個塊組的稀疏表示時各不影響,同時IK-SVD算法需要多次執行稀疏編碼,所以在GPU中通過m個線程並行計算IK-SVD算法對m個塊組的稀疏表示時的計算速度能夠得到大大提高,解決了現有技術中存在的對圖像數據集的稀疏表示的處理速度較慢的技術問題。
本領域內的技術人員應明白,本發明的實施例可提供為方法、系統、或電腦程式產品。因此,本發明可採用完全硬體實施例、完全軟體實施例、或結合軟體和硬體方面的實施例的形式。而且,本發明可採用在一個或多個其中包含有計算機可用程序代碼的計算機可用存儲介質(包括但不限於磁碟存儲器、CD-ROM、光學存儲器等)上實施的電腦程式產品的形式。
本發明是參照根據本發明實施例的方法、設備(系統)、和電腦程式產品的流程圖和/或方框圖來描述的。應理解可由電腦程式指令實現流程圖和/或方框圖中的每一流程和/或方框、以及流程圖和/或方框圖中的流程和/或方框的結合。可提供這些電腦程式指令到通用計算機、專用計算機、嵌入式處理機或其他可編程數據處理設備的處理器以產生一個機器,使得通過計算機或其他可編程數據處理設備的處理器執行的指令產生用於實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能的裝置。
這些電腦程式指令也可存儲在能引導計算機或其他可編程數據處理設備以特定方式工作的計算機可讀存儲器中,使得存儲在該計算機可讀存儲器中的指令產生包括指令裝置的製造品,該指令裝置實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能。
這些電腦程式指令也可裝載到計算機或其他可編程數據處理設備上,使得在計算機或其他可編程設備上執行一系列操作步驟以產生計算機實現的處理,從而在計算機或其他可編程設備上執行的指令提供用於實現在流程圖一個流程或多個流程和/或方框圖一個方框或多個方框中指定的功能的步驟。
顯然,本領域的技術人員可以對本發明進行各種改動和變型而不脫離本發明的精神和範圍。這樣,倘若本發明的這些修改和變型屬於本發明權利要求及其等同技術的範圍之內,則本發明也意圖包含這些改動和變型在內。