數據分析方法與裝置與流程
2023-06-11 06:16:01 5
本發明涉及無線通信領域,特別是一種數據分析方法與裝置。
背景技術:
隨著網際網路技術的飛速發展,大數據已經成為不可逆轉的時代潮流。隨著數據存儲設備成本的不斷降低,以及數據採集方式和渠道的多樣化,越來越多的公司和組織構建了自己的資料庫,用於存儲海量的用戶數據。然而,數據的快速積累帶來了信息超載的問題,企業和用戶真正感興趣的信息被湮沒在大量紛繁複雜的數據當中,有用的信息難以被有效的挖掘。數據挖掘技術則被認為是當前解決信息超載問題的有效工具之一。通過對海量數據的分析和挖掘,可以從中獲取大量有價值的信息,使大數據更好的為用戶服務。
目前,序列模式挖掘做為一種對數據分析的方式,已經逐漸被廣泛應用。序列模式挖掘目的在於尋找海量資料庫中頻繁出現的序列模式。現有的技術需求中,需要對大量的網絡傳輸數據報文進行分類,以標記各個傳輸數據流對應的網絡協議。而採用同一協議傳輸的數據,其在數據的特定位置會出現相同的特徵值。當前對於特定位置和特徵值的尋找主要依靠人工專家判定的方式,這樣會花費大量的人力物力。
技術實現要素:
有鑑於此,本發明提出了一種數據分析方法與裝置,用以避免人工對網絡傳輸數據進行分類所花費的大量的人力物力。
本發明一個方面提供一種數據分析方法。該方法包括:根據各原始序列獲取第一序列組,所述第一序列組中包括第一長度的各個第一匹配特徵以及各所述第一匹配特徵在相應待確定序列中的第一位置,所述第一特徵匹配特徵對應的支持度大於或等於第一預設支持度,所述待確定序列為在所述第一位置具有所述第一特徵匹配特徵的原始序列(S1),所述原始序列是採用預設協議的多個序列,所述原始序列包含多個匹配特徵, 各匹配特徵對應的支持度為所述匹配特徵在所述多個原始序列的同一位置出現的次數;
根據所述第一序列組獲取第二序列組,所述第二序列組中包括第二長度的各個第二匹配特徵以及所述第二匹配特徵在相應所述待確定序列中的第二位置,所述第二匹配特徵是通過組合所述第一匹配特徵獲取的,且所述第二匹配特徵對應的支持度大於或等於第二預設支持度(S2);
根據第二序列組從所述待確定序列中獲取包含所述第二匹配特徵的各第三序列,並依次從各所述第三序列中去除相應的第二匹配特徵以及第二匹配特徵之前的各匹配特徵,形成第四序列,將所述原始序列更新為第四序列,返回重複執行前述步驟,直至執行次數達到預設次數(S3);
根據所獲取的各所述第一序列組和各所述第二序列組獲取投影資料庫(S4);和
根據所述投影資料庫獲取所述預設協議的協議特徵(S5)。
如上所述的數據分析方法,可選地,所述根據所述第一序列組獲取第二序列組包括:根據所述第一序列組中的各第一匹配特徵獲取第二匹配特徵,各所述第二匹配特徵包括多個第一匹配特徵的組合;和根據所述第二匹配特徵值和所述第二位置確定第二序列組。
如上所述的數據分析方法,可選地,所述依次從各所述第三序列中去除相應的第二匹配特徵以及第二匹配特徵之前的各匹配特徵,進一步包括:步驟a:獲取未遍歷的一個第三序列;步驟b:遍歷步驟a中獲取的第三序列,若獲取到所述第二匹配特徵,則去除所獲取的第二匹配特徵以及所獲取的第二匹配特徵之前的各匹配特徵,並繼續遍歷操作,直至完成遍歷所述步驟a中獲取的第三序列的操作;步驟c:將所述步驟b中的第三序列中未去除的各匹配特徵組成的序列作為第四序列,返回執行步驟a。
如上所述的數據分析方法,可選地,所述根據所獲取的各所述第一序列組和各所述第二序列組獲取投影資料庫包括:將獲取到的第一匹配特徵和第二匹配特徵與最新生成的長度最長的整合匹配特徵組合生成新的整合匹配特徵,初始的整合匹配特徵是初次獲取的各第二匹配特徵分別與第二次獲取的第一匹配特徵和第二匹配特徵組合生成的;和根據各第一序列組、各第二序列組和各整合匹配特徵獲取所述投影資料庫。
如上所述的數據分析方法,可選地,在所述根據所獲取的各所述第一序列組和各所述第二序列組獲取獲取所述預設協議的協議特徵之後,還包括:獲取待分析序列;和將所述待分析序列與所述協議特徵進行匹配,若兩者匹配,則確定所述待分析序列是所述預設協議進行傳輸的。
如上所述的數據分析方法,可選地,所述第一長度為1,所述第二長度為2。
如上所述的數據分析方法,可選地,直至執行根據各所述原始序列獲取長度為1的第一序列組的步驟的次數達到預設次數包括:直至不能獲取到第二序列組。
本發明另一個方面提供一種數據分析裝置,包括:
第一獲取模塊,用於根據各原始序列獲取第一序列組,所述第一序列組中包括第一長度的各個第一匹配特徵以及各所述第一匹配特徵在相應待確定序列中的第一位置,所述第一特徵匹配特徵對應的支持度大於或等於第一預設支持度,所述待確定序列為在所述第一位置具有所述第一特徵匹配特徵的原始序列,所述原始序列是採用預設協議的多個序列,所述原始序列包含多個匹配特徵,各匹配特徵對應的支持度為所述匹配特徵在所述多個原始序列的同一位置出現的次數;
第二獲取模塊,用於根據所述第一序列組獲取第二序列組,所述第二序列組中包括第二長度的各個第二匹配特徵以及所述第二匹配特徵在相應所述待確定序列中的第二位置,所述第二匹配特徵是通過組合所述第一匹配特徵獲取的,且所述第二匹配特徵對應的支持度大於或等於第二預設支持度;
去除模塊,用於根據第二序列組從所述待確定序列中獲取包含所述第二匹配特徵的各第三序列,並依次從各所述第三序列中去除相應的第二匹配特徵以及第二匹配特徵之前的各匹配特徵,形成第四序列,將所述原始序列更新為第四序列,觸發所述第一獲取模塊,直至觸發所述第一獲取模塊達到預設次數;
第三獲取模塊,用於根據所獲取的各所述第一序列組和各所述第二序列組獲取投影資料庫;
第四獲取模塊,用於根據所述投影資料庫獲取所述預設協議的協議特徵。
如上所述的數據分析裝置,可選地,所述第一獲取模塊具體用於:
根據所述第一序列組中的各第一匹配特徵獲取第二匹配特徵,各所述第二匹配特徵包括多個第一匹配特徵的組合;
根據所述第二匹配特徵值和所述第二位置確定第二序列組。
如上所述的數據分析裝置,可選地,所述去除模塊具體用於執行下述步驟:
步驟a:獲取未遍歷的一個第三序列;
步驟b:遍歷步驟a中獲取的第三序列,若獲取到所述第二匹配特徵,則去除所獲取的第二匹配特徵以及所獲取的第二匹配特徵之前的各匹配特徵,並繼續遍歷操作,直至完成遍歷所述步驟a中獲取的第三序列的操作;
步驟c:將所述步驟b中的第三序列中未去除的各匹配特徵組成的序列作為第四序 列,返回執行步驟a。
如上所述的數據分析裝置,可選地,所述第三獲取模塊具體用於:
將獲取到的第一匹配特徵和第二匹配特徵與最新生成的長度最長的整合匹配特徵組合生成新的整合匹配特徵,初始的整合匹配特徵是初次獲取的各第二匹配特徵分別與第二次獲取的第一匹配特徵和第二匹配特徵組合生成的;
根據各第一序列組、各第二序列組和各整合匹配特徵獲取所述投影資料庫。
如上所述的數據分析裝置,可選地,還包括:
匹配模塊,用於獲取待分析序列,並將所述待分析序列與所述協議特徵進行匹配,若兩者匹配,則確定所述待分析序列是所述預設協議進行傳輸的。
如上所述的數據分析裝置,可選地,所述第一長度為1,所述第二長度為2。
如上所述的數據分析裝置,可選地,所述去除模塊用於直至觸發所述第一獲取模塊達到預設次數時,具體包括:
直至不能獲取到第二序列組。
從上述方案中可以看出,由於本發明在獲取各匹配特徵時記錄了位置這一屬性,可以排除掉未在同一位置出現次數超過門限值的匹配特徵,因此建立投影特徵庫的運算過程較簡單,所耗費的時間較短,進而能夠較快的對數據進行分析。
附圖說明
下面將通過參照附圖詳細描述本發明的優選實施例,使本領域的普通技術人員更清楚本發明的上述及其它特徵和優點,附圖中:
圖1為根據本發明一實施例的數據分析方法的流程示意圖。
圖2為根據本發明另一實施例的數據分析方法的流程示意圖。
圖3為根據本發明再一實施例的數據分析裝置的結構示意圖;
圖4為根據本發明又一實施例的數據分析裝置的結構示意圖。
具體實施方式
為使本發明的目的、技術方案和優點更加清楚,以下舉實施例對本發明進一步詳細說明。
實施例一
本實施例提供一種數據分析方法,用於對網絡中傳輸的數據進行分析。本實施例的執行主體是數據分析裝置。如圖1所示,為根據本實施例的數據分析方法的流程示意圖。
步驟101,根據各原始序列獲取的第一序列組,第一序列組中包括各第一長度的各個第一匹配特徵以及各第一匹配特徵在相應待確定序列中的第一位置,第一特徵匹配特徵對應的支持度大於或等於第一預設支持度,待確定序列為在第一位置具有第一特徵匹配特徵的原始序列,原始序列是採用預設協議的多個序列,原始序列包含多個匹配特徵,各匹配特徵對應的支持度為匹配特徵在多個原始序列的同一位置出現的次數。
獲取採用預設協議的多個初始的原始序列,原始序列包含多個匹配特徵,各匹配特徵對應的支持度為匹配特徵在不同原始序列的同一位置出現的次數。
本實施例中,數據分析裝置先獲取網絡中採用已知的某一種協議進行傳輸的數據,由於數據都是以多個長度為1位元組的二進位數據進行傳輸,這些長度為1位元組的二進位數據即為匹配特徵,每匹配特徵在原始序列中的位置,可以採用編號來表示。例如,原始序列依次包括的長度為1的各匹配特徵分別是00、01、06、75,則00的位置為1,01的位置為2,06的位置為3,75的位置為4,長度為2的各匹配特徵為0001、0106和0675,其中,0001的位置為1,0106的位置為2,0675的位置為3。長度為2或者更長的各匹配特徵的位置,是按照第一個字節的位置進行定位的。一個報文所對應的數據可以為一個原始序列。本實施例中將根據報文攜帶的數據獲取的數列作為原始序列,即需要進行分析的序列。
支持度即在不同原始序列中同一位置出現的次數。對於支持度的計算,舉例來說,例如,某一匹配特徵在不同序列中的位置5出現了30次,則該匹配特徵對應的支持度為30,或者某一匹配特徵在不同序列中的位置1出現了5次,則該匹配特徵對應的支持度為5。
第一序列組中的各匹配特徵的長度為第一長度。該第一長度可以根據實際需要進行設定,例如1。
該步驟可以包括:
根據第一序列組中的各第一匹配特徵獲取第二匹配特徵,各第二匹配特徵包括多個第一匹配特徵的組合;
根據第二匹配特徵值和第二位置確定第二序列組。
步驟102,根據第一序列組獲取的第二序列組,第二序列組中包括各第二長度的各個第二匹配特徵以及第二匹配特徵在相應待確定序列中的第二位置,第二匹配特徵是通過組合第一匹配特徵獲取的且第二匹配特徵對應的支持度大於或等於第二預設支持度。
本實施例的第二匹配特徵可以包括任意幾個第一匹配特徵的組合,需指出的是,多個第一長度的第一匹配特徵組合後的長度為第二長度,例如,兩個長度為1的第一匹配特徵組合成長度為2的第二匹配特徵。多個第一匹配特徵的組合順序並不限定。第二匹配特徵對應的支持度大於或等於第二預設支持度表示的是,即該第二匹配特徵在不同待確定序列中同一位置出現的次數大於或等於第二預設支持度。
步驟103,根據第二序列組從待確定序列中獲取包含第二匹配特徵的各第三序列,並依次從各第三序列中去除相應的第二匹配特徵以及第二匹配特徵之前的各匹配特徵,形成第四序列,將原始序列更新為第四序列,返回重複執行前述步驟,直至重複次數達到預設次數。
若獲取到第二匹配特徵,則可以遍歷待確定序列,並根據第二序列組從待確定序列中獲取包含第二匹配特徵的待確定序列作為第三序列,即,第三序列中的第二匹配特徵的位置是記錄在第二序列組中的位置。將第三序列的第二匹配特徵以及第二匹配特徵之前的各匹配特徵去掉之後,獲取相應的第四序列。將第四序列作為新的原始序列,並重複步驟101至步驟103,直至不能再獲取到相應的第二序列組。
具體地:步驟a:獲取未遍歷的一個第三序列;
步驟b:遍歷步驟a中獲取的第三序列,若獲取到第二匹配特徵,則去除所獲取的第二匹配特徵以及所獲取的第二匹配特徵之前的各匹配特徵,並繼續遍歷操作,直至完成遍歷步驟a中獲取的第三序列的操作;
步驟c:將步驟b中的第三序列中未去除的各匹配特徵組成的序列作為第四序列,返回執行步驟a。
可選地,對於上述步驟a至步驟c,直至所有的第三序列均被遍歷完成,當然,也可以根據實際需要遍歷預設個數的第三序列,以減少遍歷時間,進而減少分析數據的時間。
本實施例的直至執行根據各原始序列獲取長度為1的第一序列組的步驟的次數達到預設次數包括:
直至不能獲取到第二序列組。
需指出的是,這裡不能獲取到第二序列組至少包含以下情況:
第一種情況:無法獲取到第一序列組。即最新的原始序列中不包括所對應的支持度 大於或等於第一預設支持度的第一匹配特徵,由於不能獲取到第一序列組,相應地也不能獲取到第二序列組。
第二種情況:無法獲取到第二序列組。即第二序列組中沒有對應的支持度大於或等於第二預設支持度的第二匹配特徵。
步驟104,根據所獲取的各第一序列組和各第二序列組獲取投影資料庫。
在重複執行步驟101-步驟103的過程中,能夠獲取多個第一序列組和第二序列組,根據各第一序列組和第二序列組獲取預設協議的協議特徵。
該步驟的具體實現方式有很多種,例如,投影資料庫中包括全部的第一序列組和第二序列組;或者
將第一序列組和第二序列組中的各匹配特徵進行整合,進而投影資料庫中的各匹配特徵還包括根據第一序列組和第二序列組進行整合的匹配特徵,具體地:該步驟可以包括:
將獲取到的第一匹配特徵和第二匹配特徵與最新生成的長度最長的整合匹配特徵組合生成新的整合匹配特徵,初始的整合匹配特徵是初次獲取的各第一匹配特徵、第二匹配特徵分別與第二次獲取的第一匹配特徵和第二匹配特徵組合生成的;
根據各第一序列組、各第二序列組和各整合匹配特徵獲取投影資料庫。
每次生成的整合匹配特徵可能有多個,獲取其中長度最長的整合匹配特徵用於再次生成整合匹配特徵時。
將各第一匹配特徵和第二匹配特徵進行組合生成各整合匹配特徵,並根據各第一序列組、各第二序列組和各整合匹配特徵獲取投影資料庫。整合匹配特徵可包括多個第一匹配特徵、第二匹配特徵的組合。需指出的是,該整合匹配特徵可以包括按照順序依次組合的最新生成的長度最長的整合匹配特徵和最新獲取到的第一匹配特徵、以及最新生成的長度最長的整合匹配特徵和最新獲取到的第二匹配特徵,例如,初次獲取的第一匹配特徵包括06、08和10,第二匹配特徵包括0610,第二次獲取的第一匹配特徵為01,第二次獲取的第二匹配特徵為23ef,則整合匹配包括061001和0610323ef。
需指出的是,整合匹配特徵的位置時按照第一個字節的位置確定的。
步驟105,根據投影資料庫獲取預設協議的協議特徵。
投影資料庫中包括多個匹配特徵,從中選擇出一個或多個匹配特徵作為預設協議的協議特徵。例如,可以通過人工選擇出其中一個作為協議特徵,或者從中選擇出符合預定長度的匹配特徵作為協議特徵,具體可以根據實際需要設定,在此不再贅述。
可選地,在步驟105之後,本實施例中還包括:
將待分析序列與協議特徵進行匹配,若兩者匹配,則確定待分析序列是預設協議進行傳輸的。
本實施例中的第一長度為可以1,相應地第二長度可以為2,採用這樣的組合可以獲取長度較完整的投影資料庫。
根據本實施例的數據分析方法,由於在獲取各匹配特徵時記錄了位置這一屬性,可以排除掉未在同一位置出現次數超過門限值的匹配特徵,因此建立投影特徵庫的運算過程較簡單,所耗費的時間較短,進而能夠較快的對數據進行分析。
實施例二
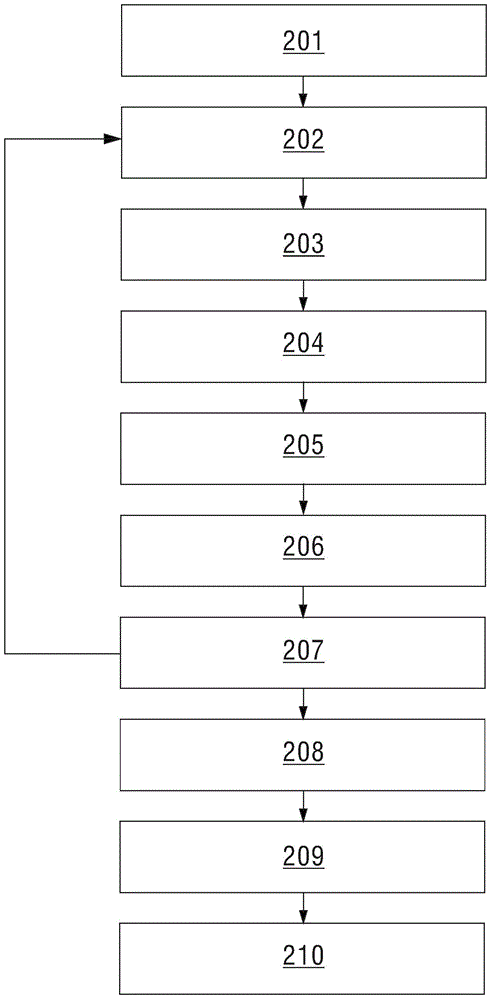
本實施例對實施例一的數據分析方法做進一步補充說明。如圖2所示,為根據本實施例的數據分析方法的流程示意圖。本實施例以第一長度為1,第二長度為2為例進行說明。
步驟201,獲取採用預設協議的多個初始的原始序列。
本實施例中,可以採用I={i1,i2,i3,…,in}來表示包括各原始序列的原始序列組,其中,in表示各原始序列,n為正整數。本實施例的各原始序列是均採用同一個已知協議進行傳輸的。
舉例來說,根據數據所獲取到的多個原始序列為:
原始序列1:{00 E7 89 7E 00 a1 E7 a1}
原始序列2:{a1 7E E7 00 E7 we 81 82}
原始序列3:{00 E7 E7 81 82 a1 08 00}
原始序列4:{00 E7 22 81 82 a1 63 22}
需指出的是,各原始序列的長度可以相等,也可以不相等,長度可以是任何長度,本實施例僅示出長度為8的且長度相等的四個原始序列,即各原始序列中包括8個長度為1的匹配特徵。
步驟202,遍歷原始序列,並獲取在不同的原始序列中出現次數大於或等於最小預設閾值的待確定第一匹配特徵,待確定第一匹配特徵的長度為1。
首先,從原始序列中挑選出在不同原始序列中出現次數大於或等於最小預設閾值的待確定第一匹配特徵。需指出的是,同一匹配特徵在同一原始序列中出現多次,也僅記為在該原始序列中出現一次。
步驟203,從待確定第一匹配特徵中選取在不同序列中同一位置出現的次數大於或等於第一預設支持度的第一匹配特徵,第一序列組中包括第一長度的各個第一匹配特徵,該同一位置即第一匹配特徵對應的第一位置。
舉例來說,對於原始序列1中的匹配特徵00,即使該匹配特徵00在原始序列1中出現兩次,針對原始序列1記錄該匹配特徵00對應的出現次數也僅為1,同時記錄該匹配特徵00在原始序列1中的位置1和7;遍歷原始序列2,也有匹配特徵00,則匹配特徵00對應的次數加1,變為2,同時記錄該匹配特徵00在原始序列2中的位置4,遍歷原始序列3,即使匹配特徵00出現兩次,也僅記錄1次,即該匹配特徵00對應的次數加1,變為3,同時記錄該匹配特徵00在原始序列1中的位置1和8;遍歷原始序列4,也有匹配特徵00,則匹配特徵00對應的次數加1,變為4,同時記錄該匹配特徵00在原始序列4中的位置1。
其它各匹配特徵依次類推,獲取各匹配特徵在不同原始序列中出現的次數。
對於上述原始序列,假設最小預設閾值為2,獲取在不同序列中出現的次數大於或等於該預設閾值的匹配特徵作為待確定第一匹配特徵,本實施例中,從上述四個原始序列中確定出的待確定第一匹配特徵包括:00、a1、E7、7E、81和82。
第一序列組可以採用以下公式表示:
Q1={,,…,},其中Q1代表第一序列組,Ep代表第一匹配特徵,Tp代表第一匹配特徵在序列中出現的位置。其中p≤n且p為正整數。
假設,第一預設支持度為3,則上述原始序列中的第一匹配特徵為00、E7和a1。
包含對應的支持度大於或等於第一預設支持度的各第一匹配特徵的待確定序列為原始序列1、原始序列3和原始序列4。第一序列組Q1={,,}。
實施例一中的步驟102可以包括本實施例的步驟201和202。
步驟204,根據第一序列組中各第一匹配特徵獲取待確定第二匹配特徵。
其中,第二匹配特徵的長度為2,由兩個第一匹配特徵進行組合而成。各待確定第二匹配特徵包括多個第一匹配特徵的組合。根據原始序列1、原始序列2、原始序列3和原始序列4,第一匹配特徵為00、E7和a1,則待確定第二匹配特徵包括0000、00E7、00a1、E700、E7E7、E7a1、a100、a1E7以及a1a1。
遍歷待確定序列,即原始序列1、原始序列3和原始序列4,獲取對應的支持度大於或等於第二預設支持度的第二匹配特徵。
步驟205,根據第二匹配特徵值和第二位置確定第二序列組。
第二序列組Q2={P1,P2,…,Pr},其中Pr代表第二匹配特徵,即Pr={<Tt,>},其中1≤t≤r,Ei∈O1,Ej∈O1。
假設,本實施例中的第二預設支持度為2,則可以獲取到最終的第二匹配特徵為00E7,第二序列組Q2為{}。
步驟206,根據第二序列組從待確定序列中獲取包含第二匹配特徵的各第三序列。
根據第二序列組Q2為{},第三序列為原始序列1、原始序列3和原始序列4。
步驟207,依次從各第三序列中去除相應的第二匹配特徵以及第二匹配特徵之前的各匹配特徵,根據去除第二匹配特徵後的各第三序列獲取第四序列,將原始序列更新為第四序列,返回執行步驟202,直至未獲取到第二序列組。
該步驟包括以下步驟:
步驟a:獲取未遍歷的一個第三序列;
步驟b:遍歷步驟a中獲取的第三序列,若獲取到第二匹配特徵,則去除所獲取的第二匹配特徵以及所獲取的第二匹配特徵之前的各匹配特徵,並繼續遍歷操作,直至完成遍歷步驟a中獲取的第三序列的操作;
步驟c:將步驟b中的第三序列中未去除的各匹配特徵組成的序列作為第四序列,返回執行步驟a。
假設,獲取的第三序列為原始序列1,首先獲取到位置為1的第二匹配特徵00E7,去除位置為1的第二匹配特徵00E7,接下來,獲取到位置為4的第二匹配特徵00E7,去除該位置為4的第二匹配特徵00E7,原始序列1遍歷完畢。根據原始序列1未獲取到第四序列。
接下來,獲取的第三序列為原始序列3,首先獲取到位置為1的第二匹配特徵00E7,去除位置為1的第二匹配特徵00E7,接下來,未遍歷到第二匹配特徵,則根據原始序列3獲取到的第四序列1為:{E7 81 82 a1 08 00}。
接下來,獲取的第三序列為原始序列4,首先獲取到位置為1的第二匹配特徵00E7,去除位置為1的第二匹配特徵00E7,接下來,未遍歷到第二匹配特徵,則根據原始序列4獲取到的第四序列2為:{22 81 82 a1 63 22}。
需注意的是,各第四序列中的各匹配特徵的位置發生改變,第四序列1為:{E7, 81,82,a1,08,00}中的匹配特徵E7,在初始的原始序列中的位置為3,在第四序列中的位置為1。
接著,由於第四序列僅為2個,一定獲取不到對應的支持度大於或等於第一預設支持度的第一匹配特徵,接著,繼續執行步驟208。
步驟208,根據獲取的各第一序列組和各第二序列組獲取投影資料庫。
該步驟包括:將獲取到的第一匹配特徵和第二匹配特徵與最新生成的長度最長的整合匹配特徵組合生成新的整合匹配特徵,初始的整合匹配特徵是初次獲取的各第二匹配特徵分別與第二次獲取的第一匹配特徵和第二匹配特徵組合生成的;
根據各第一序列組、各第二序列組和各整合匹配特徵獲取投影資料庫。
步驟209,根據投影資料庫中確定出預設協議的協議特徵。
如何確定該協議特徵可以根據實際需要設定,例如採用人工根據經驗選擇的方式,在此不再贅述。
步驟210,獲取待分析序列,並將待分析序列與協議特徵進行匹配,若兩者匹配,則確定待分析序列是預設協議進行傳輸的。
獲取某一待分析序列,根據預先獲取的協議特徵進行匹配,若在該待分析序列中在與協議特徵相應的位置匹配到該協議特徵時,則說明該待分析序列就是採用該預設協議進行分析的。各協議特徵以及對應的位置均可以記錄在協議特徵庫中。例如,協議特徵庫中有,其中,協議特徵為00E7,1表示該匹配特徵00E7在序列中的位置。本實施例獲取到的特徵資料庫中包括該,則表示該特徵資料庫採用的是第一協議。
根據檢測,本實施例的數據分析方法最終的分析數據如表1所示:
表1
該表1中的偏移表示匹配特徵的位置,長度即為協議的序列的長度。從表1中可以看出,本實施例的數據分析方法錯判率為不超過4%,誤判率不超過3%,可靠率非常高。這表明本實施例的數據分析方法的結果非常準確。本實施例的誤判率為將某一協議錯誤的判斷成另外一協議的概率,漏判率為遺漏了某組數據沒有判斷出來。
根據本實施例,獲取投影特徵庫的過程計算比較簡單,耗費時間短,因此能夠很快的對數據進行分析,進而能夠較快地得到結論。
實施例三
本實施例提供一種數據分析裝置,用於執行上述實施例中的數據分析方法。本實施例的數據分析裝置可以是任一終端,例如手機、電腦、伺服器等。
如圖3所示,為根據本實施例的數據分析裝置的結構示意圖。本實施例的數據分析裝置包括:第一獲取模塊301、第二獲取模塊302、去除模塊303、第三獲取模塊304和分析模塊305。
其中,第一獲取模塊301用於根據各原始序列獲取第一序列組,第一序列組中包括第一長度的各個第一匹配特徵以及各第一匹配特徵在相應待確定序列中的第一位置,第一特徵匹配特徵對應的支持度大於或等於第一預設支持度,待確定序列為在第一位置具有第一特徵匹配特徵的原始序列,原始序列是採用預設協議的多個序列,原始序列包含多個匹配特徵,各匹配特徵對應的支持度為匹配特徵在多個原始序列的同一位置出現的次數;第二獲取模塊302用於根據第一序列組獲取第二序列組,第二序列組中包括第二長度的各個第二匹配特徵以及第二匹配特徵在相應待確定序列中的第二位置,第二匹配特徵是通過組合第一匹配特徵獲取的,且第二匹配特徵對應的支持度大於或等於第二預設支持度;去除模塊303用於根據第二序列組從待確定序列中獲取包含第二匹配特徵的各第三序列,並依次從各第三序列中去除相應的第二匹配特徵以及第二匹配特徵之前的各匹配特徵,形成第四序列,將原始序列更新為第四序列,觸發第一獲取模塊301,直至觸發第一獲取模塊301達到預設次數;第三獲取模塊304用於根據所獲取的各第一序列組和各第二序列組獲取投影資料庫;第四獲取模塊305用於根據投影資料庫獲取預設協議的協議特徵。
本實施例的數據分析裝置的操作方法與實施例一一致,在此不再贅述。
根據本實施例的數據分析裝置,由於在獲取各匹配特徵時記錄了位置這一屬性,可以排除掉未在同一位置出現多次的匹配特徵,因此建立投影特徵庫的運算過程較簡單,所耗費的時間較短,進而能夠較快的對數據進行分析。
實施例四
本實施例對上述實施例的數據分析裝置做進一步補充說明。
如圖4所示,本實施例的數據分析裝置的第一獲取模塊301具體用於:
根據第一序列組中的各第一匹配特徵獲取第二匹配特徵,各第二匹配特徵包括多個第一匹配特徵的組合;
根據第二匹配特徵值和第二位置確定第二序列組。
可選地,本實施例的去除模塊303具體用於執行下述步驟:
步驟a:獲取未遍歷的一個第三序列;
步驟b:遍歷步驟a中獲取的第三序列,若獲取到第二匹配特徵,則去除所獲取的第二匹配特徵以及所獲取的第二匹配特徵之前的各匹配特徵,並繼續遍歷操作,直至完成遍歷步驟a中獲取的第三序列的操作;
步驟c:將步驟b中的第三序列中未去除的各匹配特徵組成的序列作為第四序列,返回執行步驟a。
可選地,本實施例的第三獲取模塊304具體用於:
將獲取到的第一匹配特徵和第二匹配特徵與最新生成的長度最長的整合匹配特徵組合生成新的整合匹配特徵,初始的整合匹配特徵是初次獲取的各第二匹配特徵分別與第二次獲取的第一匹配特徵和第二匹配特徵組合生成的;
根據各第一序列組、各第二序列組和各整合匹配特徵獲取投影資料庫。
可選地,如圖4所示,本實施例的數據分析裝置還包括匹配模塊401。該匹配模塊401用於獲取待分析序列,並將待分析序列與協議特徵進行匹配,若兩者匹配,則確定待分析序列是預設協議進行傳輸的。
可選地,本實施例的第一長度為1,第二長度為2。
可選地,本實施例的去除模塊303用於直至觸發第一獲取模塊301達到預設次數時,具體包括:
直至不能獲取到第二序列組。
本實施例的數據分析裝置的具體操作方式與上述實施例一致,在此不再贅述。
根據本實施例,獲取投影特徵庫的過程計算比較簡單,耗費時間短,因此能夠很快的對數據進行分析,進而能夠較快地得到結論。
以上僅為本發明的較佳實施例而已,並不用以限制本發明,凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。