網際網路醫療黃牛風險控制的實現方法與流程
2023-10-11 09:58:49 2
本發明是一種網際網路醫療黃牛風險控制,特別涉及一種網際網路醫療黃牛風險控制的實現方法。
背景技術:
黃牛黨俗稱「票販子」,活躍在各個行業。如商城,其利用商城返利,贈券,購物卡,代金券,代購積分等牟取利益,嚴重影響商城正常促銷效益;如火車票,其利用節假期間火車票的供不應求囤積然後高價賣出,嚴重影響正常購票出現需要。
醫療掛號領域,因為更加複雜的掛號渠道,極度不平衡的醫療需求,導致部分大醫院及專家號源供不應求,為黃牛黨的活躍存在創造了條件。特別是越來越多的號源從線下渠道放到線上,為我們提供更便捷的掛號服務之外也為黃牛的蔓延提供了更加適宜的條件。這些線上黃牛往往通過破解軟體,批量註冊等待手段大量收集號源然後賣給急需就醫用戶從中謀取暴利。
由於醫療掛號領域的特殊性,專業性的要求,並且目前因為網際網路醫療還處在初始探索階段,暫時還沒有比較完善的醫療掛號風控系統解決方案,所以實現網際網路醫療掛號領域黃牛風控系統實施方案,為用戶能夠及時便利掛號就診有很大的意義。
醫療掛號領域的黃牛主要特點:
第一,職業化,因為醫療資源的緊缺及醫療需求往往比較急迫,從而產生巨大利益吸引黃牛党進入。
第二,分工明確,從軟體破解,手機校驗,掛號,賣出等一系列流程分工明確。
第三,科技手段,藉助網絡技術手段使得黃牛隱藏在正常用戶中。
醫療掛號領域黃牛風控現狀:上去·
第一,通過簡單的限制用戶掛號次數,提高掛號門檻。
第二,基於這些簡單措施一定程度上增加黃牛掛號的難度,但隨著黃牛手段越來越多,團夥分工合作,使用現代化網絡技術,使得這些簡單措施很難起到有效作用。
第三,職業化黃牛反應迅速,經常使得新增加的預防措施很短時間被破解,並作出針對性反擊。
技術實現要素:
本發明主要是解決現有技術中存在的不足,對現有黃牛橫行的現象得到一種抑制,提升看病現狀的一種網際網路醫療黃牛風險控制的實現方法。
本發明的上述技術問題主要是通過下述技術方案得以解決的:
一種網際網路醫療黃牛風險控制的實現方法,按以下步驟進行:
第一步,獲取原始數據:
原始數據包括用戶在ios及安卓系統,web端及h5頁面的登錄,註冊,掛號,查詢排班,諮詢問診等行為數據,ip庫信息,非正常用戶手機號碼庫;
行為數據主要由應用端打點日誌,應用數據主要包含用戶信息,用戶業務信息,用戶設備信息;用戶信息包括用戶登錄名,一般是用戶手機號,郵箱,以及用戶唯一標識,此為系統內部唯一識別碼;此用戶信息作為風險評估的主要維度,識別黃牛攔截的主要對象;
用戶業務數據包括行為標識如登錄,註冊,查詢排班,掛號,針對不同行為事件,有不同業務數據,如查詢排班事件的排班信息,下單掛號事件訂單信息醫院科室等信息;用戶設備信息包括用戶設備唯一標識,用戶ip,用戶所用瀏覽器信息,用戶設備信息作為風險評估的重要維度,根據設備及ip等識別大量註冊帳號等行為;用戶行為數據主要由用戶操作時,應用系統獲取到的用戶基本信息,因此具有數據邏輯性強,規範化,標準化,覆蓋面廣,可信度高相關特點,是非常重要的數據;
ip庫信息主要通過購買專業ip庫獲得,包含ip對應經緯度及地域信息,基站,idc機房ip;此部分信息作為用戶行為數據的輔助數據,作為定位用戶地理位置,定位用戶地域變動,用戶是否使用代理,用戶ip是否為省統一出口ip相關信息;ip庫數據可以更準確的把握用戶網絡坐標,數據為商業化數據,具有準確,規範,標準,數據變更及時相關特點,可信度較高,是非常重要的輔助數據;
非正常手機號碼庫是一類在其他平臺被標記的有不正常行為的號碼,或者出現在一些自動識別驗證碼的手機號;此部分數據作為用戶黃牛風險評估的一個輔助策略,主要通過網絡爬蟲,商業合作,公共接口相關方法獲得;數據相對準確,可以有效降低黃牛生存空間,可以在黃牛未進入醫療平臺之前作為預防手段,提前檢測出潛在風險用戶;
第二步,實時規則引擎:
包括以下步驟:
第2a步,實時數據接入:實時數據為用戶行為數據,由應用層將數據發送到分布式消息系統kafka中,風控實時系統消費得實時數據流;
第2b步,數據完善補充:對實時流數據補充ip地域信息,對部分敏感數據加密,對查詢排班及下單等行為根據排班號或訂單號從業務系統查詢訂單詳細信息,如醫院名稱,專業名稱,科室;
第2c步,導入規則計算規則風險:規則是風控系統風險評估的核心,可以動態更新;規則分為評分規則和攔截規則,評分規則參與風險評分,攔截規則參與風險攔截;評分規則是一系列定義用戶某方面行為限制的規定,如我們認為用戶在一小時內連續查詢排班的次數可以反映出正常用戶和非正常用戶,那麼我們可以把這一約束形成一評分規則;評分規則主要依據線性風險模型設計,主要核心依據為某一行為頻次約束,此外是某一行為特徵標籤約束;
線性風險計算模型:
其中分為五個風險等級,無風險(0)、輕微風險(0,20)、一般風險(20,50)、較大風險(50,80)、高危風險(80,100);風險最高為100,規則定義時需要確定五個參數(a0、a1、a2、a3、a100),分別規定了五個風險等級的頻次閾值;通過此模型可以實現人工完全可控,所有規則可解釋,可規範;
攔截規則是一系列滿足一定頻次條件或特徵即加入黑名單庫的行為限制方面的規定;如用戶在一個小時內出現在5個地區以上,加入黑名單庫的用戶或設備將被拒絕繼續訪問系統排班查詢,掛號,問診相關行為;
第2d步,規則風險聚合,事件風險計算:對於上一步中此次事件所觸發的所有規則及其風險,每觸發一種規則則意味著此事件增加一種風險點,意味著此事件風險增加;
事件風險計算公式:score=max(s)(1-q(s))+∑rinrs(s(r)q(s(r))),
其中max(s)為事件觸發規則中風險最大的分值,q(s)為風險累加權重因子,s(r)為事件觸發規則風險分值;
另外事件風險分值計算遵循風險等級原則及最大風險分值原則,即風控系統中最大風險分值為100;
第2e步,數據入庫:落地數據為經過處理的原始數據,規則風險明細數據,事件風險數據,觸發攔截黑名單數據;其中觸發攔截規則的事件,則其對應的用戶及設備加入黑名單庫,以此為依據攔截異常行為用戶;規則風險明細數據及事件風險數據集成到原始數據中存儲;
第三步,用戶風險計算引擎:
具體的戶風險計算引擎流程,包括以下步驟:
第3a步,用戶當天風險點採集:用戶當天風險點,是指該用戶當天所有行為事件中觸發風險評分規則的統計;風險點以規則為基礎,統計當天所觸發的所有規則,以每種規則對應的最大評分風險分值為此規則該用戶的當天風險分值,從而得到該用戶當天所有風險點;
第3b步,計算用戶當天風險:
用戶當天風險計算依據最大風險原則,規則權重模型,風險累計模型計算;
規則權重,是指每種評分規則對此用戶維度影響度,如過規則完全反映用戶風險大小則權重為1,如果規則和用戶風險無關則權重為0,因為規則定義會考慮用戶,設備,ip多方面因素,所以可能部分規則並不反映用戶風險情況;除此之外,因為規則定義可能偏向某種業務,而對其他業務的參考價值較低;權重為我們手工配置,以此調節此風險分值算法的準確度,計算公式:
ns=s(r)w(r)
其中s為風險分值,w為規則權重,ns為此規則對用戶有效風險分值;
風險累計模型,如同事件風險計算策略,用戶風險計算採用相同計算模型;計算公式:cs=max(ns)(1-q(ns))+∑rinrs(ns(r)q(ns(r)));
其中max(ns)為用戶觸發規則中風險最大的分值,q(ns)為風險累加權重因子,cs為當天用戶風險分值;
第3c步,歷史累計風險:
用戶風險按天計算,全量統計,即每天最終得到的風險即為當前用戶風險,此風險包含當天的所有風險因子及歷史所有風險因子累計結果,歷史風險將會隨時間衰減,衰減因子f,默認f=0.95,此衰減因子可根據需要確定;我們定義此衰減因子依據是以30天為一周期,30天前產生的用戶風險因素將會衰減到最低風險等級:輕微風險(0-20)計算公式是::hs=s*f;
其中s為前一天此用戶的最終風險分值,f為經過一天的衰減係數,hs為歷史風險在當前的有效風險分值;
第3d步,計算當前用戶風險:
用戶當前風險包含當天風險,歷史有效風險兩部分。依據風險累計模型,最大風險分值原則,計算公式:score=max(hs,cs)+min(hs,cs)*q;
其中q為風險累加權重因子,hs為此用戶經過衰減計算後的歷史風險在當天的風險表徵,cs為當天所有風險因子累計後的風險表徵,因此我們認為兩種風險分值同等程度代表此用戶風險狀況,取其中最大值,然後累加另一風險分值的累加風險,此計算公式是風險累計模型的簡化模型,是在只有兩種平等風險因子下的計算模型;
第3e步,數據落地:
用戶風險數據將作為實時風險決策中心的風險數據入庫,同時作為第二天的用戶歷史風險數據;
第四步,實時風險決策引擎:
實時風險分為攔截,驗證等級,身份驗證相關策略;攔截主要依據實時規則引擎中攔截規則生成的黑名單庫及用戶風險引擎中用戶風險分值,綜合評定出一部分具有較大風險的事件,向應用系統發出攔截信號,即拒絕用戶的查詢掛號相關操作;
驗證等級是針對一部分風險沒有達到攔截的程度,但仍然有一定風險,主要依據用戶風險分值按風險大小分等級給出相應難度的驗證碼,如增加語音及幹擾相關條件增大驗證難度;
身份驗證作為一種輔助策略,對熱門專家掛號及有一定風險用戶需要用戶完善用戶信息校驗身份;
從以上三個方面出發,封禁一批黃牛帳號設備及ip,增加一批疑似黃牛用戶的操作難度,同時通過身份信息完善綁定銀行卡相關手段達到風控的目的。
與現有醫療領域的黃牛預防的實現方法相比,本申請的醫療黃牛風控實現方法有以下優點:
數據源自用戶行為事件數據,可以直觀還原用戶行為軌跡;
根據用戶的歷史風險數據,綜合用戶多種行為數據,綜合多種預設規則計算,可以更準確確定用戶風險,抓到那些無法直接判斷的隱藏黃牛;
系統角度來說:動態添加風控攔截規則,更加便捷快速應對黃牛;風控策略與應用端隔離,減少對應用系統影響。
因此,本發明提供的一種網際網路醫療黃牛風險控制的實現方法,攔截規則科學,攔截效果出色。
附圖說明
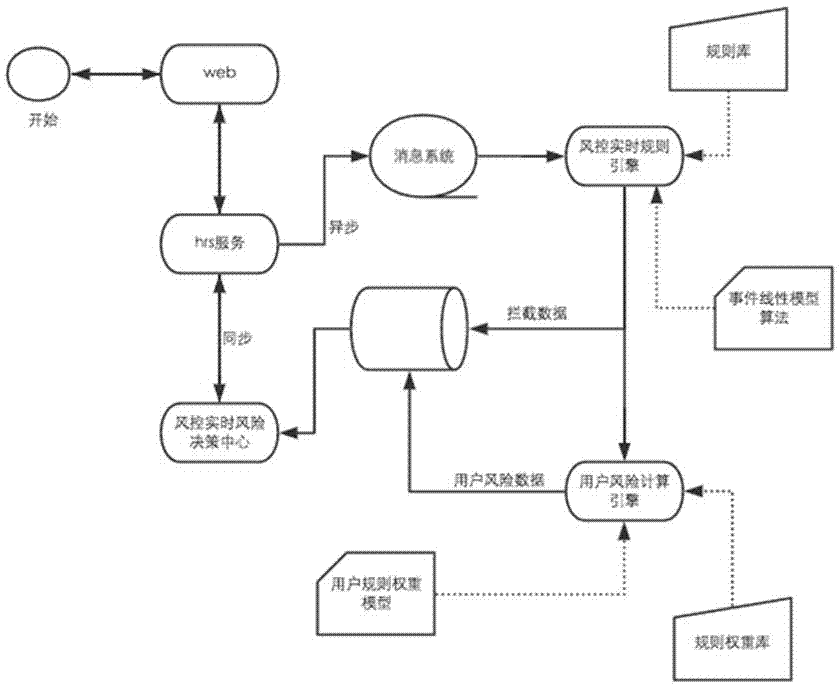
圖1是本發明的總流程概況圖;
圖2是本發明的流程圖;
圖3是本發明中實時規則引擎流程圖;
圖4是本發明中線性風險模型;
圖5是本發明中用戶風險計算引擎的流程圖。
具體實施方式
下面通過實施例,並結合附圖,對本發明的技術方案作進一步具體的說明。
實施例:如圖1、圖2、圖3、圖4和圖5所示,一種網際網路醫療黃牛風險控制的實現方法,其特徵在於按以下步驟進行:
第一步,獲取原始數據:
原始數據包括用戶在ios及安卓系統,web端及h5頁面的登錄,註冊,掛號,查詢排班,諮詢問診等行為數據,ip庫信息,非正常用戶手機號碼庫;
行為數據主要由應用端打點日誌,應用數據主要包含用戶信息,用戶業務信息,用戶設備信息;用戶信息包括用戶登錄名,一般是用戶手機號,郵箱,以及用戶唯一標識,此為系統內部唯一識別碼;此用戶信息作為風險評估的主要維度,識別黃牛攔截的主要對象;
用戶業務數據包括行為標識如登錄,註冊,查詢排班,掛號,針對不同行為事件,有不同業務數據,如查詢排班事件的排班信息,下單掛號事件訂單信息醫院科室等信息;用戶設備信息包括用戶設備唯一標識,用戶ip,用戶所用瀏覽器信息,用戶設備信息作為風險評估的重要維度,根據設備及ip等識別大量註冊帳號等行為;用戶行為數據主要由用戶操作時,應用系統獲取到的用戶基本信息,因此具有數據邏輯性強,規範化,標準化,覆蓋面廣,可信度高相關特點,是非常重要的數據;
ip庫信息主要通過購買專業ip庫獲得,包含ip對應經緯度及地域信息,基站,idc機房ip;此部分信息作為用戶行為數據的輔助數據,作為定位用戶地理位置,定位用戶地域變動,用戶是否使用代理,用戶ip是否為省統一出口ip相關信息;ip庫數據可以更準確的把握用戶網絡坐標,數據為商業化數據,具有準確,規範,標準,數據變更及時相關特點,可信度較高,是非常重要的輔助數據;
非正常手機號碼庫是一類在其他平臺被標記的有不正常行為的號碼,或者出現在一些自動識別驗證碼的手機號;此部分數據作為用戶黃牛風險評估的一個輔助策略,主要通過網絡爬蟲,商業合作,公共接口相關方法獲得;數據相對準確,可以有效降低黃牛生存空間,可以在黃牛未進入醫療平臺之前作為預防手段,提前檢測出潛在風險用戶;
第二步,實時規則引擎:
包括以下步驟:
第2a步,實時數據接入:實時數據為用戶行為數據,由應用層將數據發送到分布式消息系統kafka中,風控實時系統消費得實時數據流;
第2b步,數據完善補充:對實時流數據補充ip地域信息,對部分敏感數據加密,對查詢排班及下單等行為根據排班號或訂單號從業務系統查詢訂單詳細信息,如醫院名稱,專業名稱,科室;
第2c步,導入規則計算規則風險:規則是風控系統風險評估的核心,可以動態更新;規則分為評分規則和攔截規則,評分規則參與風險評分,攔截規則參與風險攔截;評分規則是一系列定義用戶某方面行為限制的規定,如我們認為用戶在一小時內連續查詢排班的次數可以反映出正常用戶和非正常用戶,那麼我們可以把這一約束形成一評分規則;評分規則主要依據線性風險模型設計,主要核心依據為某一行為頻次約束,此外是某一行為特徵標籤約束;
線性風險計算模型:
其中分為五個風險等級,無風險(0)、輕微風險(0,20)、一般風險(20,50)、較大風險(50,80)、高危風險(80,100);風險最高為100,規則定義時需要確定五個參數(a0、a1、a2、a3、a100),分別規定了五個風險等級的頻次閾值;通過此模型可以實現人工完全可控,所有規則可解釋,可規範;
攔截規則是一系列滿足一定頻次條件或特徵即加入黑名單庫的行為限制方面的規定;如用戶在一個小時內出現在5個地區以上,加入黑名單庫的用戶或設備將被拒絕繼續訪問系統排班查詢,掛號,問診相關行為;
第2d步,規則風險聚合,事件風險計算:對於上一步中此次事件所觸發的所有規則及其風險,每觸發一種規則則意味著此事件增加一種風險點,意味著此事件風險增加;
事件風險計算公式:score=max(s)(1-q(s))+∑rinrs(s(r)q(s(r))),
其中max(s)為事件觸發規則中風險最大的分值,q(s)為風險累加權重因子,s(r)為事件觸發規則風險分值;
另外事件風險分值計算遵循風險等級原則及最大風險分值原則,即風控系統中最大風險分值為100;
第2e步,數據入庫:落地數據為經過處理的原始數據,規則風險明細數據,事件風險數據,觸發攔截黑名單數據;其中觸發攔截規則的事件,則其對應的用戶及設備加入黑名單庫,以此為依據攔截異常行為用戶;規則風險明細數據及事件風險數據集成到原始數據中存儲;
第三步,用戶風險計算引擎:
具體的戶風險計算引擎流程,包括以下步驟:
第3a步,用戶當天風險點採集:用戶當天風險點,是指該用戶當天所有行為事件中觸發風險評分規則的統計;風險點以規則為基礎,統計當天所觸發的所有規則,以每種規則對應的最大評分風險分值為此規則該用戶的當天風險分值,從而得到該用戶當天所有風險點;
第3b步,計算用戶當天風險:
用戶當天風險計算依據最大風險原則,規則權重模型,風險累計模型計算;
規則權重,是指每種評分規則對此用戶維度影響度,如過規則完全反映用戶風險大小則權重為1,如果規則和用戶風險無關則權重為0,因為規則定義會考慮用戶,設備,ip多方面因素,所以可能部分規則並不反映用戶風險情況;除此之外,因為規則定義可能偏向某種業務,而對其他業務的參考價值較低;權重為我們手工配置,以此調節此風險分值算法的準確度,計算公式:
ns=s(r)w(r)
其中s為風險分值,w為規則權重,ns為此規則對用戶有效風險分值;
風險累計模型,如同事件風險計算策略,用戶風險計算採用相同計算模型;計算公式:cs=max(ns)(1-q(ns))+∑rinrs(ns(r)q(ns(r)));
其中max(ns)為用戶觸發規則中風險最大的分值,q(ns)為風險累加權重因子,cs為當天用戶風險分值;
第3c步,歷史累計風險:
用戶風險按天計算,全量統計,即每天最終得到的風險即為當前用戶風險,此風險包含當天的所有風險因子及歷史所有風險因子累計結果,歷史風險將會隨時間衰減,衰減因子f,默認f=0.95,此衰減因子可根據需要確定;我們定義此衰減因子依據是以30天為一周期,30天前產生的用戶風險因素將會衰減到最低風險等級:輕微風險(0-20)計算公式是::hs=s*f;
其中s為前一天此用戶的最終風險分值,f為經過一天的衰減係數,hs為歷史風險在當前的有效風險分值;
第3d步,計算當前用戶風險:
用戶當前風險包含當天風險,歷史有效風險兩部分。依據風險累計模型,最大風險分值原則,計算公式:score=max(hs,cs)+min(hs,cs)*q;
其中q為風險累加權重因子,hs為此用戶經過衰減計算後的歷史風險在當天的風險表徵,cs為當天所有風險因子累計後的風險表徵,因此我們認為兩種風險分值同等程度代表此用戶風險狀況,取其中最大值,然後累加另一風險分值的累加風險,此計算公式是風險累計模型的簡化模型,是在只有兩種平等風險因子下的計算模型;
第3e步,數據落地:
用戶風險數據將作為實時風險決策中心的風險數據入庫,同時作為第二天的用戶歷史風險數據;
第四步,實時風險決策引擎:
實時風險分為攔截,驗證等級,身份驗證相關策略;攔截主要依據實時規則引擎中攔截規則生成的黑名單庫及用戶風險引擎中用戶風險分值,綜合評定出一部分具有較大風險的事件,向應用系統發出攔截信號,即拒絕用戶的查詢掛號相關操作;
驗證等級是針對一部分風險沒有達到攔截的程度,但仍然有一定風險,主要依據用戶風險分值按風險大小分等級給出相應難度的驗證碼,如增加語音及幹擾相關條件增大驗證難度;
身份驗證作為一種輔助策略,對熱門專家掛號及有一定風險用戶需要用戶完善用戶信息校驗身份;
從以上三個方面出發,封禁一批黃牛帳號設備及ip,增加一批疑似黃牛用戶的操作難度,同時通過身份信息完善綁定銀行卡相關手段達到風控的目的。
對於本領域的技術人員來說,本申請可以有各種更改和變化。凡在本申請的精神和原則之內,所作的任何修改、等同、替換、改進等,均應包含在本申請的保護範圍之內。