一種拍攝方法及終端與流程
2023-10-09 12:44:24 4
本發明涉及拍攝技術領域,尤其涉及一種拍攝方法及其終端。
背景技術:
隨著拍照技術的快速發展,用戶喜歡利用拍照來記錄自己、家人、朋友及同事開心的時刻,在拍照的過程中,用戶都希望清晰地拍出自己眼睛,這樣拍出的圖像能夠突出重點,並能體現圖像中的人物的精神面貌。但在實踐中發現,現有的拍照設備不能對人眼進行準確的對焦,拍出的人物圖像的人眼區域的清晰度不高。
技術實現要素:
本發明實施例提供一種拍攝方法及其終端,可快速且準確的對人眼進行對焦,以提高所拍攝的目標圖像的人眼區域的清晰度。
本發明實施例提供了一種拍攝方法,包括:
獲取當前圖像並對所述當前圖像進行處理以得到當前對焦位置,所述當前對焦位置為人眼位置;
根據所述當前對焦位置對進行對焦;
接收拍攝指令以獲取目標圖像。
本發明實施例還提供了一種終端,包括:
獲取單元,用於獲取當前圖像;
處理單元,用於對所述獲取單元獲取的當前圖像進行處理以得到當前對焦位置,所述當前對焦位置為人眼位置;
對焦單元,用於根據所述出處理單元得到的當前對焦位置對進行對焦;
所述獲取單元還用於接收拍攝指令以獲取目標圖像。
本發明實施例中,終端通過獲取當前圖像並對該當前圖像進行處理以得到當前對焦位置,並根據該當前對焦位置進行對焦,根據拍攝指令獲取目標圖像。由於當前對焦位置為人眼位置,因此可以快速且準確的對人眼進行對焦,從而提高了所拍攝的目標圖像的人眼區域的清晰度。
附圖說明
為了更清楚地說明本發明實施例技術方案,下面將對實施例描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖是本發明的一些實施例,對於本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1是本發明一實施例提供的一種拍攝方法的流程示意圖;
圖2是本發明另一實施例提供的一種拍攝方法的流程示意圖;
圖3是本發明一實施例提供的一種特徵模版的示意圖;
圖4是本發明一實施例提供的一種子窗口的結構示意圖;
圖5是本發明另一實施例提供的一種子窗口的結構示意圖;
圖6是本發明另一實施例提供的一種強分類器的結構示意圖;
圖7是目標人臉圖像的示意圖;
圖8是經顯著性處理後的區域圖像示意圖;
圖9是本發明一實施例提供的一種終端的結構示意圖;
圖10是本發明另一實施例提供的一種終端的結構示意;
圖11是本發明再一實施例提供的一種終端的結構示意。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述。
應當理解,當在本說明書和所附權利要求書中使用時,術語「包括」和「包含」指示所描述特徵、整體、步驟、操作、元素和/或組件的存在,但並不排除一個或多個其它特徵、整體、步驟、操作、元素、組件和/或其集合的存在或添加。
還應當理解,在此本發明說明書中所使用的術語僅僅是出於描述特定實施例的目的而並不意在限制本發明。如在本發明說明書和所附權利要求書中所使用的那樣,除非上下文清楚地指明其它情況,否則單數形式的「一」、「一個」及「該」意在包括複數形式。
還應當進一步理解,在本發明說明書和所附權利要求書中使用的術語「和/或」是指相關聯列出的項中的一個或多個的任何組合以及所有可能組合,並且包括這些組合。
如在本說明書和所附權利要求書中所使用的那樣,術語「如果」可以依據上下文被解釋為「當...時」或「一旦」或「響應於確定」或「響應於檢測到」。類似地,短語「如果確定」或「如果檢測到[所描述條件或事件]」可以依據上下文被解釋為意指「一旦確定」或「響應於確定」或「一旦檢測到[所描述條件或事件]」或「響應於檢測到[所描述條件或事件]」。
具體實現中,本發明實施例中描述的終端包括但不限於諸如具有觸摸敏感表面(例如,觸控螢幕顯示器和/或觸摸板)的行動電話、膝上型計算機或平板計算機之類的其它可攜式設備。還應當理解的是,在某些實施例中,所述設備並非可攜式通信設備,而是具有觸摸敏感表面(例如,觸控螢幕顯示器和/或觸摸板)的臺式計算機。
在接下來的討論中,描述了包括顯示器和觸摸敏感表面的終端。然而,應當理解的是,終端可以包括諸如物理鍵盤、滑鼠和/或控制杆的一個或多個其它物理用戶接口設備。
終端支持各種應用程式,例如以下中的一個或多個:繪圖應用程式、演示應用程式、文字處理應用程式、網站創建應用程式、盤刻錄應用程式、電子表格應用程式、遊戲應用程式、電話應用程式、視頻會議應用程式、電子郵件應用程式、即時消息收發應用程式、鍛鍊支持應用程式、照片管理應用程式、數位相機應用程式、數字攝影機應用程式、web瀏覽應用程式、數位音樂播放器應用程式和/或數字視頻播放器應用程式。
可以在終端上執行的各種應用程式可以使用諸如觸摸敏感表面的至少一個公共物理用戶接口設備。可以在應用程式之間和/或相應應用程式內調整和/或改變觸摸敏感表面的一個或多個功能以及終端上顯示的相應信息。這樣,終端的公共物理架構(例如,觸摸敏感表面)可以支持具有對用戶而言直觀且透明的用戶界面的各種應用程式。
請參考圖1,是本發明一實施例提供的拍攝方法的流程示意圖,如圖所示,該方法可以包括以下步驟:
S101、終端獲取當前圖像並對該當前圖像進行處理以得到當前對焦位置,該當前對焦位置為人眼位置。
需要說明的是,用戶可以通過觸控或者語音的方式向終端發送開啟拍照應用的指令,終端在接收到用戶發送的開啟拍照應用指令的時,可以開啟拍照應用以獲取當前圖像,可以對該當前圖像進行處理以得到當前對焦位置,該當前對焦位置為人眼位置。具體的,終端可以對該當前圖像進行灰度處理以得到灰度圖像,並可以對灰度圖像進行人臉檢測,若檢測到人臉圖像,則可以對人臉圖像進行顯著性檢測以獲得人眼位置;若沒有檢測到人臉圖像,則終端可以直接將當前圖像作為目標圖像,可以不執行以下步驟。
其中,當前圖像是指終端接收到開啟拍照應用的指令時拍攝的,該當前圖像以緩存的形式存儲在終端中,可用於獲取人眼位置,以便終端可以根據該人眼位置拍出清晰的目標圖像,在拍完目標圖像後,終端可以將該當前圖像刪除。另外,上述當前對焦位置可以是多個,也可以是一個,當前對焦位置的數量由當前圖像中的人物個數決定,也就是說一個人物對應一個當前對焦位置。上述終端可以是智慧型手機、照相機、平板電腦,智能可穿戴設備等具有拍照功能的設備,本發明實施例不做限定。
作為一種可選的實施方式,上述對該當前圖像進行處理以得到當前對焦位置,可以包括以下步驟S1011、S1012和S1013。
S1011、終端對該當前圖像進行灰度處理以獲得灰度圖像。
需要說明的是,終端可以根據當前圖像的格式做出相應的灰度處理以獲得灰度圖像,例如,若終端獲取的當前圖像是YUV格式,可以通過提取Y通道的圖像以獲得灰度圖像;若終端獲取的當前圖像是RGB格式,可以通過提取G通道的圖像以得到灰度圖像。以上兩種獲取當前圖像的灰度圖像的方法僅是示意性的,本發明實施例對此不做限制。
S1012、終端對該灰度圖像進行人臉檢測以檢測出目標人臉圖像。
需要說明的是,終端可以採用人臉檢測方法對該灰度圖像進行人臉檢測以檢測出目標人臉圖像,以便進一步獲取人眼位置,具體的,人臉檢測方法可以包括基於學習的人臉檢測方法或基於特徵的人臉檢測方法等。基於學習的人臉檢測方法可以包括基於Adaboost的方法、基於貝葉斯準則的方法、基於人工神經網絡的方法(Artificial Neural Network,ANN)或支持向量機的方法(Support Vector Machine,SVM)等。基於特徵的人臉檢測方法包括底層特徵分析方法、組群特徵方法或變形模板方法等,其中,底層特徵分析方法又包括基於膚色的人臉檢測方法。
其中,上述的目標人臉圖像中,可以包括多個人物的人臉,也可以只有一個人物的人臉。
舉例來說,終端可以將灰度圖像劃分為若干個小方格,每個小方格為一個像素點,提取該灰度圖像的各個像素點的顏色信息,將各個像素點的顏色信息與人臉顏色信息資料庫進行對比,若該像素點的顏色信息與人臉顏色信息資料庫匹配,則該像素點屬於人臉,將該灰度圖像中屬於人臉的像素點進行聚類以得到目標人臉圖像。
S1013、終端對該目標人臉圖像進行顯著性檢測以獲得該當前對焦位置。
需要說明的是,由於人眼具有嚴格的對稱性、眼球形狀的特殊性,左右兩眼睛的距離具有相對固定性等特點,終端可以對目標人臉圖像進行顯著性檢測以獲得該當前的對焦位置即人眼位置。
具體地,終端先對目標人臉圖像進行離散餘弦變換及負離散餘弦變換以得到區域圖像,再對比目標人臉圖像及區域圖像並結合先驗知識得到當前對焦位置。需要說明的是,通過顯著性檢測以獲得人眼位置的方法具有很強的時效性,可以優化達到毫秒級。
結合步驟S1011、S1012、S1013來看,終端可以對該當前圖像進行灰度處理以獲得灰度圖像,對該灰度圖像進行人臉檢測以檢測出目標人臉圖像,對該目標人臉圖像進行顯著性檢測以獲得該當前對焦位置。
S102、終端根據該當前對焦位置進行對焦。
需要說明的是,終端在獲取該當前對焦位置後,可以自動根據該當前對焦位置來調節物距和相距進行對焦,以便拍出清晰的人眼。
S103、終端接收拍攝指令以獲取該目標圖像。
需要說明的是,終端接收到用戶通過語音、觸控操作等方式發送的拍攝指令時,可以拍攝目標圖像。其中,目標圖像是指終端接收到拍攝指令時,根據當前對焦位置對人眼進行定焦而拍出的圖像,終端可以將該目標圖像存儲在圖片庫中,即該目標圖像是用戶想要的圖像。
終端通過獲取當前圖像並對該當前圖像進行處理以得到當前對焦位置,並根據該當前對焦位置進行對焦,根據拍攝指令獲取目標圖像。由於當前對焦位置為人眼位置,因此可以快速且準確的對人眼進行對焦,從而提高了所拍攝的目標圖像的人眼區域的清晰度。
參見圖2,是本發明另一實施例提供的一種拍攝方法的流程示意圖,如圖所示,該方法可以包括以下步驟:
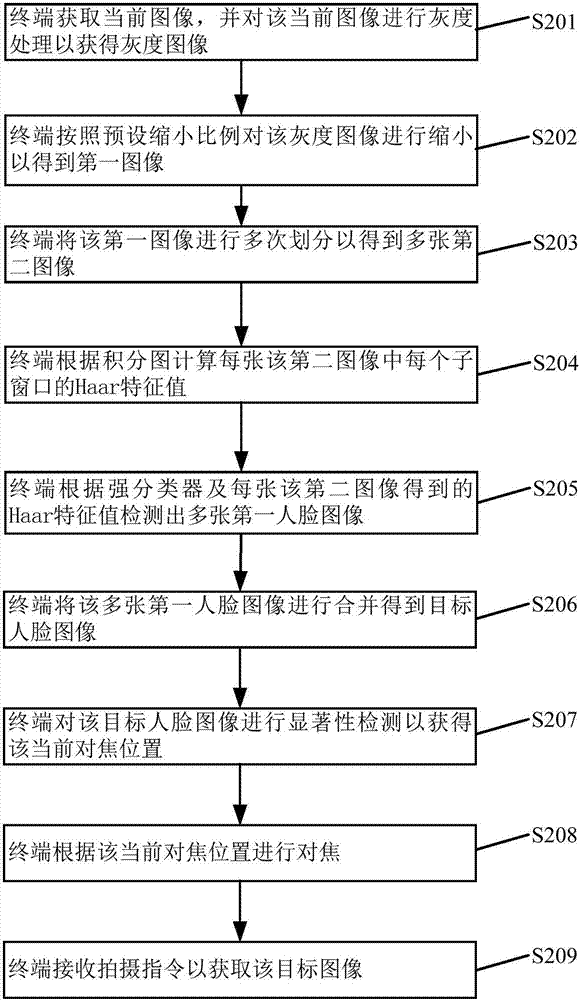
S201、終端獲取當前圖像,並對該當前圖像進行灰度處理以獲得灰度圖像。
終端可根據用戶發送的開啟拍照應用指令以獲取當前圖像,之後根據當前圖像的格式做出相應的灰度處理以獲得灰度圖像。例如,若終端獲取的當前圖像是YUV格式,可以通過提取Y通道的圖像以獲得灰度圖像;若終端獲取的當前圖像是RGB格式,可以通過提取G通道的圖像以得到灰度圖像。以上兩種獲取當前圖像的灰度圖像的方法僅是示意性的,本發明實施例對此不做限制。
S202、終端按照預設縮小比例對該灰度圖像進行縮小以得到第一圖像。
需要說明的是,終端可以按照預設縮小比例對該灰度圖像進行縮小以得到第一圖像,以便提高檢測目標人臉圖像的效率。例如,終端處理一張1300萬像素的圖像,需要20ms,如果將該1300萬像素的圖像縮小10倍,相應的處理時間也會縮小。其中,預設放大比例可以根據終端處理圖像的性能決定。
S203、終端將該第一圖像進行多次劃分以得到多張第二圖像,每張該第二圖像包括多個子窗口。
需要說明的是,終端可以將該第一圖像進行多次劃分以得到多張第二圖像,每張該第二圖像包括多個子窗口,其中每次劃分的子窗口的個數越多,計算得出的Haar特徵值也越多,檢測到的人臉圖像更加準確,但是每次劃分的子窗口越多,計算Haar特徵值的時間也會相應增加,另外,子窗口的最大數量不能超過強分類器檢測的最大子窗口數量,所以劃分的子窗口的數量可以根據檢測人臉圖像的準確性、計算Haar特徵值的時間、強分類器子窗口的數量等因素綜合考慮。其中,Haar特徵值可以通過圖像的子窗口的像素值計算得出,並用於描述圖像的灰度變化。
舉例來說,終端初次可以將第一圖像劃分為20*20個子窗口,然後可以按照等比例擴大劃分子窗口的數量,如按照3倍的比例擴大劃分子窗口的數量,即可以將該第一圖像劃分為60*60個子窗口、180*180個子窗口或540*540個子窗口等。
S204、終端根據積分圖計算每張該第二圖像中每個子窗口的Haar特徵值。
需要說明的是,由於人臉圖像中人眼比臉頰顏色要深,鼻梁兩側比鼻梁顏色要深,嘴巴比周圍顏色要深等特徵,所以可以採用Haar特徵值描述第二圖像的灰度變化情況。由於計算Haar特徵值需要已知每個子窗口的像素值,每個子窗口的像素值可以根據子窗口的端點處的積分圖計算出,所以可以根據積分圖計算每張第二圖像的Haar特徵值。
作為一種可選的實施方式,上述根據積分圖計算每個子窗口的Haar特徵值,可以包括:根據該積分圖計算該每個子窗口對應的像素值;根據該每個子窗口的像素值計算該每個子窗口的Haar特徵值。
需要說明的是,灰度圖像中的任意一點的積分圖是指從圖像的左上角到這點所構成的矩形區域內所有點的像素值值之和,同理對於具有多個子窗口第二圖像中,每個子窗口端點處的積分圖為該端點到該圖像左上角所包含的所有子窗口的像素值之和。所以在計算出各個子窗口端點處的積分圖的情況下,可以根據積分圖計算各個子窗口的像素值,並可以根據每個子窗口的像素值計算各子窗口的Haar特徵值。
進一步,在計算Haar特徵值時,首先需要選擇合適的特徵模版,特徵模版是由兩個或多個的矩形組合而成,特徵模板內有黑色和白色兩種矩形,其中常見的特徵模版如圖3所示。其中每種特徵模版僅對應一種特徵,但每種特徵可以對應多種特徵模版,常見的特徵有邊緣特徵、線性特徵、點特徵、對角特徵,然後將特徵模版按照預設規則放置在灰度圖像對應的子窗口中,計算該特徵模版放置區域對應的Haar特徵值,該Haar特徵值由特徵模版中白色矩形區域的像素和減去黑色矩形區域的像素和計算得出。其中,預設規則包括設置特徵模版的大小、特徵模版在子窗口中放置的位置,預設規則根據灰度圖像劃分的子窗口的數量決定。
其中,在選定特徵模版的情況下,由於特徵模版的大小不同,且在每張第二圖像的的子窗口中放置的位置不同,所以對於一個特徵模版,每張第二圖像中對應有多個Haar特徵,同時可以選擇多個特徵模版來計算每張第二圖像的Haar特徵,另外,該每張第二圖像的劃分的子窗口的數量不一樣,所以每張第二圖像的Haar特徵值的數量不一樣。
舉例來說,終端可以將灰度圖像縮小1000倍,並將該縮小後的灰度圖像劃分為20*20個子窗口,根據積分圖計算各個子窗口的像素值,其步驟包括:
1、計算各個子窗口端點處的積分圖,這裡以計算如圖4中的子窗口D的端點(i,j)處的積分圖為例,端點(i,j)的積分圖為該點到灰度圖像左上角所包括的各子窗口的像素之和,可表示為:
Integral(i,j)=子窗口D的像素值+子窗口C的像素值+子窗口B的像素值+子窗口A的像素值;
因為Integral(i-1,j-1)=子窗口A的像素值;
Integral(i-1,j)=子窗口A的像素值+子窗口C的像素值;
Integral(i,j-1)=子窗口B的像素值+子窗口A的像素值;
所以,Integral(i,j)進一步可以表示為:
Integral(i,j)=Integral(i,j-1)+Integral(i-1,j)-Integral(i-1,j-1)+子窗口D的像素值;
其中,Integral(,)表示某點的積分圖,進過觀察發現(i,j)點的積分圖可以通過(i,j-1)點的積分圖Integral(i,j-1)加上第j列的像素和ColumnSum(j)獲得,即(i,j)點的積分圖可以表示為:
Integral(i,j)=Integral(i,j-1)+ColumnSum(j);
其中,ColumnSum(0)=0,Integral(0,j)=0,所以對於20*20的子窗口,灰度圖像上所有子窗口端點處的積分圖可以通過19+19+2*19*19=760次迭代求得。
2、根據各子窗口端點處的積分圖計算各個子窗口的像素值,這裡以計算子窗口D的像素值為例,由步驟1可知子窗口D的像素值可以由端點(i,j)、(i,j-1),(i-1,j)及(i-1,j-1)處的積分圖計算得出,即子窗口D的像素值可表示為:
子窗口D的像素值=Integral(i,j)+Integral(i-1,j-1)-Integral(i-1,j)-Integral(i,j-1);
根據上式可知,只要已知各個子窗口端點處的積分圖,就可以計算出各個子窗口的像素值。
進一步,在獲得各個子窗口的像素值以後,可以根據各個窗口的像素值計算Haar特徵值,其中選擇不同的特徵模版,放置的位置不同,且特徵模版的尺寸不同,對應的Haar特徵值不同,選擇圖4中的以邊緣特徵對應的特徵模板為例,如圖5所示,該特徵模版對應區域的Haar特徵值可以由子窗口A的像素值減去子窗口B的像素值。
S205、終端根據強分類器及每張該第二圖像得到的Haar特徵值檢測出多張第一人臉圖像。
需要說明的是,在計算出每張第二圖像中各個子窗口的Haar特徵值後,終端可以根據強分類器及每張該第二圖像得到的Haar特徵值檢測出多張第一人臉圖像,也就是說根據一張第二圖像的Haar特徵值及強分類器可以檢測出一張第一人臉圖像。具體的,強分類器可以由若干個弱分類器組成,將每張第二圖像的子窗口的Haar特徵值輸入到強分類器中,逐級通過各個弱分類器,相當於弱分類器判斷Haar特徵值是否滿足對應的預設人臉特徵條件,若滿足,則允許該Haar特徵值通過,若不滿足,則不允許該Haar特徵值通過。如果有一級未通過,則該Haar特徵值對應的子窗口將被拒絕,並分類為非人臉,每一級都能夠通過,則對該Haar特徵值進一步處理以找出該Haar特徵值對應的子窗口,並將該Haar特徵值對應的子窗口分類為人臉,對每張第二圖像中分類為人臉的子窗口進行合併,以得到每張第二圖像對應的第一人臉圖像(例如,將子窗口數量為20*20的第二圖像中檢測出的人臉子窗口進行合併得到一張對應的第一人臉圖像)。本實施例中所描述的根據強分類器及每張該第二圖像得到的Haar特徵值檢測出多張第一人臉圖像的方法的步驟比較簡單,從而降低人臉圖像檢測的複雜度,且該強分類器可以是由多個弱分類器組成,所以提高了人臉檢測的準確率。
舉例來說,如圖6所示,若該強分類器是由3個級聯的弱分類器組成,將子窗口數量為24*24的第二圖像的各個子窗口的Haar特徵值依次輸入到3個弱分類器中,每個弱分類器判斷該Haar特徵值是否滿足對應的預設人臉特徵條件,若滿足,則允許該Haar特徵值通過,若不滿足,則不允許該Haar特徵值通過。如果有一級未通過,則該Haar特徵值對應的子窗口將被拒絕,並分類為非人臉,每一級都能夠通過,則對該Haar特徵值進一步處理以找出該Haar特徵值對應的子窗口,並將該Haar特徵值對應的子窗口分類為人臉,將子窗口數量為24*24的第二圖像中分類為人臉的子窗口進行合併,以得子窗口數量為24*24的第二圖像對應的第一人臉圖像。同理可以根據以上步驟計算子窗口數量為36*36的第二圖像對應的第一人臉圖。
進一步地,在檢測出多張人臉圖像之前,還需要獲取強分類器。具體的,獲取強分類器的詳細描述如下:
1、選定訓練樣本T={(x1,y1),(x2,y2)…(xi,yi)…(xN,yN)},並將該訓練樣本存儲於指定位置,如樣本資料庫中。其中xi表示第i個樣本,yi=0時表示其為負樣本(非人臉),yi=1時表示其為正樣本(人臉)。N為訓練樣本數量。
2、初始化訓練樣本的權值分布D1,即給每個訓練樣本設置相同的權值,可以表示為:
D1=(w11,w12…w1i…w1N),w1i=1/N,i=1,2…N
3、設置迭代次數T,用t=1,2,...,T表示第多少次迭代。
4、歸一化權值:
其中,Dt(i)為第t次循環中第i個樣本的權值,qt(i)為第t次循環中第i個樣本的歸一化權值。
5、對訓練樣本進行學習以得到多個弱分類器,並計算每一弱分類器在訓練樣本上的分類誤差率:使用具有權值分布Dt的訓練樣本學習得到弱分類器h(xi,fi,pi,θi),計算弱分類器的分類錯誤率εt:
其中,一個弱分類器h(xi,fi,pi,θi)是由特徵fi,閾值θi,以及偏置位置pi組成:
另外,xi為一個訓練樣本,特徵fi與弱分類器hi(xi,fi,pi,θi)具有一一對應的關係,偏置位pi的作用是控制不等式的方向,使得不等式符號都是小於等於號,訓練一個弱分類器的就是找到最優閾值值θi的過程。
6、從5中確定的弱分類器中,找出一個具有最小的分類錯誤率εt(i)的弱分類器ht。
7、根據分類誤差率計算弱分類器的係數βt:
βt=εt/(1-εt)
其中,該係數表示每一弱分類器在強分類器中所佔的權值,當xi被正確地分類時,ei的值取0,當被xi錯誤地分類時,ei的值取1。並跟該係數對所有訓練樣本的權值進行更新:
8、所有訓練樣本的權值更新後,循環執行步驟4到7,直到迭代T次後,結束迭代,得到強分類器H(x):
其中,αt=log(1/βt)。
S206、終端將該多張第一人臉圖像進行合併得到所述目標人臉圖像。
需要說明的是,將該多張第一人臉圖像進行合併得到該目標人臉圖像,也就是說對不同子窗口數量的第二圖像得到的多張人臉圖像進行合併得到該目標人臉圖像。具體的,將不同的第一人臉圖像進行對比,若某兩張第一人臉圖像重疊面積大於預設閾值,則認為這兩張第一人臉圖像表示同一人臉,對這兩張第一人臉進行合併,即將這兩張第一人臉的位置和大小的平均值作為合併後得到的人臉位置和大小;如果某兩張第一人臉圖像重疊面積小於預設閾值,則認為該兩張第一人臉圖像表示兩個不同的人臉,將該兩張人臉圖像合併成一張圖像,該圖像具有兩個人臉區域,經過多次對比及合併操作可以得到目標人臉圖像。其中,該目標人臉圖像可以是一個人臉圖像也可以是多個人臉圖像。
S207、終端對該目標人臉圖像進行顯著性檢測以獲得該當前對焦位置。
具體地,終端先對目標人臉圖像進行離散餘弦變換及負離散餘弦變換以得到區域圖像,再對比目標人臉圖像及區域圖像並結合先驗知識得到當前對焦位置。需要說明的是,通過顯著性檢測以獲得人眼位置的方法具有很強的時效性,可以優化達到毫秒級。
進一步地,步驟S207具體包括:
(1)對如圖7所示的目標人臉圖像,採用公式(1)進行離散餘弦變換(Discrete Cosine Transformation,DCT):
其中,x,y,u,v=0,1,…,N-1。
進一步地,在公式(1)中,F(u,v)表示經DCT變換後的信號,f(x,y)表示原始信號,N表示原始信號的個數,c(u)、c(v)表示補償係數,其可以使得經DCT變換後的矩陣成為正交矩陣。
(2)採用公式(2)對步驟(1)中進行DCT變換後的圖像進行符號變換:
進一步地,公式(2)表示從公式(1)中所得到的值為1或0或-1。
(3)採用公式(3)對步驟(2)中進行符號變換後的圖像進行負離散餘弦變換(Inverse Discrete Cosine Transformation,IDCT)以得到如圖8所示的區域圖像:
其中,x,y,u,v=0,1,…,N-1.
進一步地,在公式(2)中,F(u,v)表示經DCT變換後的信號,f(x,y)表示原始信號,N表示原始信號的個數,c(u)、c(v)表示補償係數,其可以使得經DCT變換後的矩陣成為正交矩陣。
(4)對比如圖7所示的目標人臉圖像及如圖8所示的區域圖像並結合先驗知識得到當前對焦位置。
S208、終端根據該當前對焦位置進行對焦。
S209、終端接收拍攝指令以獲取該目標圖像。
本發明實施例中,終端通過按照預設縮小比例對灰度圖像進行縮小以得到第一圖像,提高了檢測人臉圖像的效率,另外,終端通過將該第一圖像進行多次劃分以得到多張第二圖像,每張該第二圖像包括多個子窗口,並根據積分圖計算每張該第二圖像中每個子窗口的Haar特徵值,根據強分類器及每張該第二圖像得到的Haar特徵值檢測出多張第一人臉圖像,降低了檢測人臉圖像的複雜度,並提高了人臉檢測的準確率。進一步,終端將該多張第一人臉圖像進行合併得到目標人臉圖像,通過採用顯著性檢測該目標人臉圖像以獲得該當前對焦位置,該對焦位置為人眼位置,提高了人眼位置檢測的時效性,更進一步,終端通過根據該當前對焦位置進行對焦,接收拍攝指令以獲取該目標圖像,可以快速且準確的對人眼進行對焦,從而提高了所拍攝的目標圖像的人眼區域的清晰度。
參見圖9,圖9是本發明實施例提供的一種終端的結構示意圖,本實施例中所描述的終端,包括:
獲取單元701,用於獲取當前圖像。
處理單元702,用於對所述獲取單元701獲取的當前圖像進行處理以得到當前對焦位置,所述當前對焦位置為人眼位置。
對焦單元703,用於根據所述處理單元702得到的當前對焦位置進行對焦。
所述獲取單元701,還用於接收拍攝指令以獲取目標圖像。
進一步地,該處理單元702具體用於:
對所述當前圖像進行灰度處理以獲得灰度圖像;
對所述灰度圖像進行人臉檢測以檢測出目標人臉圖像;
對所述人臉圖像進行顯著性檢測以獲得所述當前對焦位置。
本發明實施例中,終端通過獲取當前圖像並對該當前圖像進行處理以得到當前對焦位置,並根據該當前對焦位置進行對焦,根據拍攝指令獲取該目標圖像。由於當前對焦位置為人眼位置,因此可以快速且準確的對人眼進行對焦,從而提高了所拍攝的目標圖像的人眼區域的清晰度。
請參見圖10,圖10是本發明另一實施例提供一種移動終端的結構示意圖,如圖10所示,該移動終端可以包括:
獲取單元801,用於獲取當前圖像
處理單元802,用於對所述獲取單元801獲取的當前圖像進行處理以得到當前對焦位置,所述當前對焦位置為人眼位置;
對焦單元803,用於根據所述處理單元802得到的當前對焦位置進行對焦;
所述獲取單元801還用於接收拍攝指令以獲取目標圖像;
初始化單元804,用於初始化訓練樣本的權值分布;
學習單元805,用於對訓練樣本進行學習以得到多個弱分類器;
計算單元806,用於計算所述學習單元805得到的每一所述弱分類器在所述訓練樣本上的分類誤差率;
所述計算單元806,還用於根據所述分類誤差率計算所述弱分類器的係數,所述係數表示每一所述弱分類器在所述強分類器中所佔的權重;
更新單元807,用於根據所述計算單元806得到的係數更新所述訓練樣本中的權值分布並進行迭代計算,以得到所述強分類器,所述強分類器為每次迭代計算中加權分類誤差率最小的所述分類器。
進一步地,該處理單元802具體用於:
對所述當前圖像進行灰度處理以獲得灰度圖像;
對所述灰度圖像進行人臉檢測以檢測出目標人臉圖像;
對所述人臉圖像進行顯著性檢測以獲得所述當前對焦位置。
進一步地,該處理單元802具體用於:
按照預設縮小比例對所述灰度圖像進行縮小以得到第一圖像;
將所述第一圖像進行多次劃分以得到多張第二圖像,每張所述第二圖像包括多個子窗口;
根據積分圖計算每張所述第二圖像中每個子窗口的Haar特徵值;
根據強分類器及每張所述第二圖像得到的Haar特徵值檢測出多張第一人臉圖像;
將所述多張第一人臉圖像進行合併得到所述目標人臉圖像。
進一步地,根據積分圖計算每個子窗口的haar特徵值具體包括:
根據所述積分圖計算所述每個子窗口的像素值;
根據所述每個子窗口對應的像素值計算所述每個子窗口的Haar特徵值。
本發明實施例中,終端通過獲取當前圖像並對該當前圖像進行處理以得到當前對焦位置,並根據該當前對焦位置進行對焦,根據拍攝指令獲取該目標圖像。由於當前對焦位置為人眼位置,因此可以快速且準確的對人眼進行對焦,從而提高了所拍攝的目標圖像的人眼區域的清晰度。
需要說明的是,圖9及圖10所示終端的具體工作流程已在前述方法流程部分做了詳述,在此不再贅述。
另外,需要說明的是,圖像的Haar特徵值的計算過程與通過強分類器對人臉檢測的步驟可以在不同的終端上進行實現。
參見圖11,圖11是本發明再一實施例提供的一種終端的結構示意圖,本實施例中所描述的終端可以包括:一個或多個處理器903,一個或多個輸入接口901,一個或多個輸出接口902和存儲器904。處理器903、輸入接口901、輸出接口902和存儲器通過總線805連接。
輸入接口901可以包括觸控板、指紋採傳感器(用於採集人物的指紋信息和指紋的方向信息)、麥克風等,輸出接口902可以包括顯示器(LCD等)、揚聲器等。
處理器903可以是中央處理模塊(Central Processing Unit,CPU),該處理器還可以是其他通用處理器、數位訊號處理器(Digital Signal Processor,DSP)、專用集成電路(Application Specific Integrated Circuit,ASIC)、現成可編程門陣列(Field-Programmable Gate Array,FPGA)或者其他可編程邏輯器件、分立門或者電晶體邏輯器件、分立硬體組件等。通用處理器可以是微處理器或者該處理器也可以是任何常規的處理器等。
存儲器904可以是高速RAM存儲器,也可為非不穩定的存儲器(non-volatile memory),例如磁碟存儲器。存儲器904用於存儲一組程序代碼,輸入接口901、輸出接口902和處理器903可以調用存儲器904中存儲的程序代碼。
處理器903調用存儲器904中的代碼可以執行以下操作:
獲取當前圖像並對所述當前圖像進行處理以得到當前對焦位置,所述當前對焦位置為人眼位置;
根據所述當前對焦位置進行對焦;
接收拍攝指令以獲取目標圖像。
作為一種可選的實施方式,處理器903調用存儲器904中的代碼還可以執行以下操作:
對所述當前圖像進行灰度處理以獲得灰度圖像;
對所述灰度圖像進行人臉檢測以檢測出目標人臉圖像;
對所述人臉圖像進行顯著性檢測以獲得所述當前對焦位置。
作為一種可選的實施方式,處理器903調用存儲器904中的代碼還可以執行以下操作:
按照預設縮小比例對所述灰度圖像進行縮小以得到第一圖像;
將所述第一圖像進行多次劃分以得到多張第二圖像,每張所述第二圖像包括多個子窗口;
根據積分圖計算每張所述第二圖像中每個子窗口的Haar特徵值;
根據強分類器及每張所述第二圖像得到的Haar特徵值檢測出多張第一人臉圖像;
將所述多張第一人臉圖像進行合併得到所述目標人臉圖像。
作為一種可選的實施方式,處理器903調用存儲器904中的代碼還可以執行以下操作:
根據所述積分圖計算所述每個子窗口的像素值;
根據所述每個子窗口對應的像素值計算所述每個子窗口的Haar特徵值。
作為一種可選的實施方式,處理器903調用存儲器904中的代碼還可以執行以下操作:
初始化訓練樣本的權值分布,所述訓練樣本包括人臉樣本和非人臉樣本;
對訓練樣本進行學習以得到多個弱分類器;
計算每一所述弱分類器在所述訓練樣本上的分類誤差率;
根據所述分類誤差率計算所述弱分類器的係數,所述係數表示每一所述弱分類器在所述強分類器中所佔的權重;
根據所述係數更新所述訓練樣本中的權值分布並進行迭代計算,以得到所述強分類器,所述強分類器為每次迭代計算中加權分類誤差率最小的所述分類器。
本發明實施例中,終端可以獲取當前圖像並對該當前圖像進行處理以得到當前對焦位置,該當前對焦位置為人眼位置;根據該當前對焦位置對目標圖像進行對焦;接收拍攝指令以獲取該目標圖像,可以快速且準確的對人眼進行對焦,從而提高了所拍攝圖像的清晰度。
具體實現中,本發明實施例中所描述的處理器903、輸入接口901、輸出接口902可執行本發明實施例提供的拍照方法的第一實施例和第二實施例中所描述的實現方式,也可執行本發明實施例所描述的終端的實現方式,在此不再贅述。
本領域普通技術人員可以意識到,結合本文中所公開的實施例描述的各示例的單元及算法步驟,能夠以電子硬體、計算機軟體或者二者的結合來實現,為了清楚地說明硬體和軟體的可互換性,在上述說明中已經按照功能一般性地描述了各示例的組成及步驟。這些功能究竟以硬體還是軟體方式來執行,取決於技術方案的特定應用和設計約束條件。專業技術人員可以對每個特定的應用來使用不同方法來實現所描述的功能,但是這種實現不應認為超出本發明的範圍。
此外,在本申請所提供的幾個實施例中,應該理解到,所揭露的、終端和方法,可以通過其它的方式實現。例如,以上所描述的裝置實施例僅僅是示意性的,例如,所述單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式,例如多個單元或組件可以結合或者可以集成到另一個系統,或一些特徵可以忽略,或不執行。另外,所顯示或討論的相互之間的耦合或直接耦合或通信連接可以是通過一些接口、裝置或單元的間接耦合或通信連接,也可以是電的,機械的或其它的形式連接。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位於一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本發明實施例方案的目的。
另外,在本發明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以是兩個或兩個以上單元集成在一個單元中。上述集成的單元既可以採用硬體的形式實現,也可以採用軟體功能單元的形式實現。
本發明實施例方法中的步驟可以根據實際需要進行順序調整、合併和刪減。本發明實施例終端中的單元可以根據實際需要進行合併、劃分和刪減。以上所述,僅為本發明的具體實施方式,但本發明的保護範圍並不局限於此,任何熟悉本技術領域的技術人員在本發明揭露的技術範圍內,可輕易想到各種等效的修改或替換,這些修改或替換都應涵蓋在本發明的保護範圍之內。因此,本發明的保護範圍應以權利要求的保護範圍為準。