基於商品評論文檔集的概念層次創建方法與流程
2023-10-04 03:58:24 6
本發明涉及語義挖掘領域,尤其涉及基於商品評論文檔集的概念層次創建方法。
背景技術:
隨著社交網絡和電子商務的迅速發展,網絡和信息系統中產生了大量評論數據。面對龐大的數據集,人們一般難以快速找到其感興趣的內容,如電子商務系統用戶往往需要閱讀某一產品大量的用戶評論,才能對其某項性能做出相對準確的評價。由於概念層次能提供數據之間的內在相關性,所以其能大幅提高人們分析數據集的效率,發掘其內在價值,在信息檢索、文本分類、自動問答等領域有著廣闊的應用空間。概念層次是一個分類表,以等級方式對概念進行分類,是本體的一種特殊形式,其僅包含子類關係。構建針對特定文檔集的概念分類通常包含3個步驟:1)提取出對於該文檔集來說是最具代表性和相關性的概念;2)在確認這些概念後,發掘出這些概念之間的語義關係;3)通過概念之間的語義關係將其有效的組織起來。一般獲得文檔集關鍵概念和語義關係之後需要通過恰當的方法去生成最終的層次結構。在語義關係比較明顯的情況下,可以採用推理的方法去生成最終結構,但此類方法對於文本本身數量和質量要求較高,在評論數據中無法滿足。而其他情況下,則一般採取根據語義距離進行層次聚類的方法。公開號為1669029A的專利文獻公開了一種可自一文件集合中自動搜尋概念並自動生成一概念層次結構的方法、系統及電腦程式。該方法包括:自文件集合中抽取特徵字符;利用統計方法計算特徵字符間的相似度;提煉特徵字符的分布頻率以使上述相似度計算趨於精確;對特徵字符進行語義排歧以解決意義分歧的問題;以經提煉的分布頻率及語義排歧後的特徵字符為基礎,重新計算特徵字符的相似度。經再次計算所得的相似度可反映各特徵字符間的實際相似程度,藉此,可將相關的特徵字符進行聚類形成不同的概念,所得概念排列為一個概念層次結構。該概念層次結構可自動對某一待檢索的特定概念產生詢問並返回與該概念相關的文件。層次聚類是一種常用的數據聚類方法,其根據一定標準對數據進行層次分解。基本層次聚類方法一般以二叉樹的形式輸出最終結果,但這樣的知識表達方式對於很多應用場景來說顯得不恰當。例如在電視機評論數據中有液晶電視、等離子電視和OLED電視三個概念,較符合人類認知的概念分類應該將這三個概念合併到同一個節點下,但通過基本層次聚類算法無法實現。
技術實現要素:
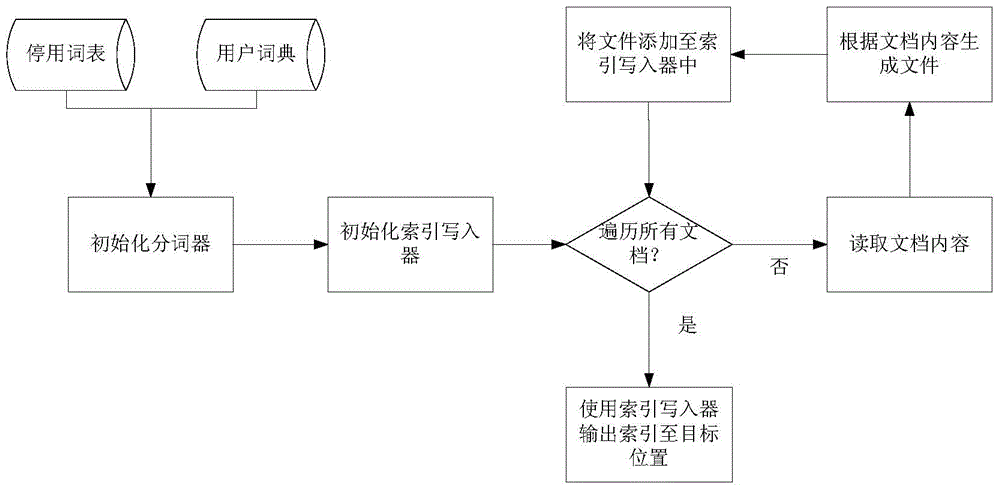
為了能夠對數據實現符合人類認知的聚類,本發明提出了一種基於商品評論文檔集的概念層次創建方法。一種基於商品評論文檔集的概念層次創建方法,包括如下步驟:步驟1,對初始的文檔集進行預處理,得到文檔矩陣以及關鍵詞表;步驟2,根據文檔矩陣以及關鍵詞表建立主題模型,並將每個主題下相關度最高的k個名詞作為關鍵概念;步驟3,對關鍵概念進行語義關係提取,得到關鍵概念的距離矩陣;步驟4,根據距離矩陣進行多路凝聚聚類,得到概念層次。k的取值由用戶根據需要來確定,一般取值範圍在10-15。在概念層次生成時,使用多路凝聚層次聚類組織概念節點,從而構建多叉樹形式的概念分類。對初始的文檔集進行預處理的步驟如下:步驟1-1,從初始的文檔集提取具有評論數據的內容;步驟1-2,對所提取內容進行去停用詞和索引處理;步驟1-3,根據索引中詞的出現頻率對內容進行過濾,並生成相應的文檔矩陣和關鍵詞表。某些情況下,一些常見詞在文檔和用戶需求進行匹配時價值並不大,需要徹底從詞彙表中去除,這類詞稱為停用詞。常用的生成停用詞表的方法就是將詞項按照在文檔集中出現的頻率從高到低排列,然後手工選擇那些語義內容與文檔主題關係不大的高頻詞作為停用詞。停用詞表中的每個詞將在索引過程中被忽略。使用停用詞表可以大大減小系統所需要存儲的倒排記錄表的數目。採用分詞器進行索引處理。步驟2中,主題模型的建立方法為:步驟2-1,從文檔矩陣中得到主題-詞矩陣;步驟2-2,由關鍵詞表得到關鍵名詞鍊表,主題-詞矩陣及關鍵名詞鍊表構成主題模型。其中,關鍵概念來自於關鍵名詞鍊表。主題模型通過詞項在文檔集的共現信息抽取出語義相關的主題集合,並能夠將詞項空間中的文檔變換到主題空間,得到文檔在低維空間中的表達。步驟2-1中,得到主題-詞矩陣的步驟如下:步驟2-11,讀取文檔矩陣,並通過預設的參數得到初始的主題模型,並從初始的主題模型得到抽樣的文檔集,其中預設的參數為文檔-主題分布的分布參數以及主題-詞分布的分布參數;步驟2-12,根據抽樣的文檔集與文檔矩陣的分布差異來對主題模型進行調整;步驟2-13,將步驟2-12重複8000至12000次,從所得的主題模型得到主題-詞分布矩陣,將每個主題下的詞按出現概率大小進行排序,從而得到主題-詞矩陣。其中利用初始的主題模型進行調整過程為:根據文檔-主題分布抽樣生成文檔-主題矩陣。根據所得的文檔-主題矩陣以及主題-詞分布抽樣生成文檔-詞分布抽樣生成文檔-詞分布。計算目前參數設置下初始文檔集出現的概率。從初始主題模型中得到抽樣的文檔集,將抽樣的文檔集與初始的文檔集進行對比,根據兩者之間的差異對預設參數進行調整。在步驟2-13中,將每個主題下的詞按出現概率大小進行排序時,出現概率越大,次序越靠前。步驟2-2中,得到關鍵名詞鍊表的步驟如下:步驟2-21,讀取關鍵詞表,並建立一個初始的關鍵名詞鍊表,由關鍵詞表向該關鍵名詞鍊表輸入所有關鍵詞,並去除重複的關鍵詞;步驟2-22,對於每個關鍵詞,判定所述關鍵詞在各個句子中的詞性,統計各個詞性出現的概率,選擇出現概率最大的詞性作為該詞在整個文檔集中的詞性;步驟2-23,將所有名詞詞性的關鍵詞作為關鍵概念儲存於關鍵名詞鍊表中。其中,在步驟2-22中,利用索引閱讀器找到含有該關鍵詞的句子,採用分詞器分析該關鍵詞在各個句子中的詞性並進行統計。步驟3中,語義關係提取的步驟如下:步驟3-1,將全部關鍵概念組成一個關鍵概念集合;步驟3-2,遍歷各個句子,若包含關鍵概念,則將其寫入一個文件中;步驟3-3,對所有關鍵概念進行語義消歧;步驟3-4,對於語義消歧後的每一個關鍵概念,統計其所有語義ID在初始的文檔集出現次數,將出現次數最多的語義作為其在初始的文檔集中的語義;步驟3-5,根據步驟3-4中所得到的語義計算詞典語義距離;步驟3-6,根據所有關鍵概念對在初始文檔中出現的相關性計算其統計語義距離;步驟3-7,將詞典語義距離和統計語義距離進行結合得到語義距離,所有關鍵概念兩兩之間的語義距離所形成的矩陣作為最終的語義距離矩陣。其中,一個關鍵概念的語義ID為該關鍵概念所表達的語義在語義詞典中的唯一標識。其中,兩個關鍵概念之間的詞典語義距離表示為:其中,n為正實數,用於調整帶深度的詞典語義距離,d是兩個關鍵概念的公共祖先概念在語義詞典中的深度,BSD(c1,c2,T)是兩個關鍵概念在語義詞典中的最短距離。兩個關鍵概念之間的統計語義距離表示為:其中和為關鍵概念c1和c2所對應的上下文向量,和為對應的上下文向量的模。步驟3-3中,對各個關鍵概念的語義消歧方法如下:步驟a),讀取該關鍵概念在同義詞詞林的所有語義ID;步驟b),根據語義ID在同義詞詞林中的頂級分類進行過濾;步驟c),獲取所有語義ID的同義詞集;步驟d),統計各個同義詞在初始的文檔集中出現的次數,選擇出現次數最多的語義ID作為該關鍵概念的語義ID。由於同一詞語可能存在一詞多義的情況,因此通過語義消歧方法確定該詞語在文檔集中的語義。步驟3-7中,將關鍵概念的詞典語義距離和統計語義距離進行結合的公式為:其中c1和c2為關鍵概念,T為語義詞典中包含c1和c2的概念樹,SSD(c1,c2,T)為歸一化後的詞典語義距離,CD(c1,c2)為歸一化後的統計語義距離。其中,歸一化後的詞典語義距離SDD(c1,c2,T)表達式為:Dmax是基本詞典語義距離的可能最大值,其中基本語義距離為兩個概念節點在概念樹上的最短距離BSD(c1,c2,T),詞典語義距離在此基礎上考慮其他因素。歸一化後的統計語義距離CD(c1,c2)表達式為:CD(c1,c2)=1-CS(c1,c2)。步驟4中,多路凝聚聚類的方法為:步驟4-1,輸入所有的關鍵概念的語義距離矩陣,每個關鍵概念作為一個概念節點;步驟4-2,從語義距離矩陣中選取語義距離最小的兩個概念節點,將兩個概念節點合併成新的概念節點;步驟4-3,從關鍵概念集合中刪除掉已合併的概念節點,加入合併後的概念節點,並且更新語義距離矩陣;步驟4-4,重複步驟4-2至4-3直到所有概念節點都已合併到同一個概念節點下,得到最終概念層次;步驟4-5,以XML形式輸出最終的概念層次。與傳統層次聚類算法不同的是,多路凝聚層次聚類算法在合併兩個聚類時有三種不同的合併操作,而傳統層次聚類只有一種。額外的合併操作使得輸出多叉樹成為可能。本發明針對使用基本層次聚類算法只能輸出二叉樹的問題,提出了一種自動的基於商品評論文檔集的概念層次構建方法,在概念層次生成時使用多路凝聚層次聚類來組織概念節點,從而構建多叉樹形式的概念層次。本發明的優點包括:(1)在提取語義關係時結合了語義詞典中的信息和商品評論文檔集中的統計特徵,計算出的語義關係更加健壯和真實;(2)使用多路凝聚聚類算法生成最終的概念層次,突破了傳統凝聚聚類只能生成二叉樹的限制;(3)一種完全自動化的構建方法,在概念層次構建過程中無需任何人工幹預。附圖說明圖1為本發明一個實施例的方法流程圖;圖2為對文檔內容進行去停用詞和索引處理的流程圖;圖3為文檔集矩陣和關鍵詞表生成過程;圖4為主題-詞提取流程圖;圖5為名詞提取流程圖;圖6為語義消歧流程圖;圖7a為多路凝聚前的示意圖;圖7b至7d為多路凝聚聚類3種情況的示意圖;圖8為關鍵詞表的一個示例圖;圖9為文檔矩陣的一個示例圖。具體實施方式現結合附圖和實施例對本發明進行詳細的解釋,本發明方法的流程圖如圖1所示。該方法分為對商品評論文檔集進行預處理、主題模型建模、語義關係提取和多路凝聚聚類四個階段。步驟1,數據預處理階段的主要步驟包括:1)從網頁形式的原始商品評論文檔集中提取出商品評論數據的內容;原始商品評論文檔集中可能存在很多無意義的信息,比如各種tag或者一些界面元素,這些在進行概念提取時都是不需要的,因此需要根據特定的模式把評論內容從原始信息中提取出來,以減小概念提取時的計算量和主題模型的可解釋性。2)對商品評論數據的內容進行去停用詞和索引等處理;處理過程如圖2所示,系統首先根據輸入讀取停用詞和用戶字典中的詞,接著初始化一個分詞器,該分詞器支持停用詞過濾和用戶字典功能。然後根據文件夾地址讀取文檔集內容,對於每一篇文檔的內容生成倒排索引,最後將索引保存到輸入的索引保存位置中。3)根據在索引中出現的頻率對評論中的詞進行過濾,並且生成相應的關鍵詞表和文檔矩陣;處理過程如圖3所示,用戶輸入包括:索引文件夾地址、關鍵詞出現頻率的上限和下限,以及輸出的文件夾,輸出則為詞表文件和文檔矩陣文件。處理過程:首先根據索引文件夾地址讀取索引的文檔內容;接著生成一個與文檔數目長度相同的鍊表a,初始化詞語ID為0(即a(0)),然後開始遍歷索引中的每一個詞語。索引方式為:對於每一個詞語,首先統計其在整個文檔集中出現的次數,如果超過關鍵詞的次數限制,就對下一個詞語進行索引;否則,在關鍵詞表中寫入:ID、詞語和以及詞語出現的次數,接著在文檔集中遍歷其所有位置,如果出現在文檔1中,則在關鍵詞表的a(1)中添加一個ID,遍歷完所有位置後ID+1,進入下一個詞語的索引。遍歷完所有詞語之後,將所得的文檔矩陣寫入到輸出文件夾內的文檔矩陣文件(即目標位置)中。生成的關鍵詞表如圖8所示。輸出的關鍵詞表的格式為每一行分為3個部分,中間用空格隔開,第一個部分是詞語,第二個部分是詞語所對應的詞語ID,第三個部分是相應詞語出現的總次數。文檔矩陣如圖9所示,文檔矩陣中每一行代表一個文檔,每個文檔由一串詞語的ID組成,詞語之間用空格隔開,每行第一個元素表示文檔所包含不重複的詞語ID數,後面各個部分由詞語ID和詞語ID的出現次數組成,不同詞語ID之間用「:」符號隔開。在得到文檔矩陣和關鍵詞表之後進入步驟2。步驟2,根據文檔矩陣建立主題模型。主題模型建模階段包括主題-詞提取和名詞提取兩個子階段。在進行主題詞提取的處理之前首先由用戶輸入:關鍵詞表地址、文檔矩陣地址、預定義的文檔主題數目和輸出結果的地址;接著進行處理,具體處理過程如圖4所示,主要步驟包括:步驟2-11,讀取文檔矩陣,並通過預設的參數得到初始的主題模型,並從初始的主題模型得到抽樣的文檔集,其中預設的參數為文檔-主題分布的分布參數以及主題-詞分布的分布參數;步驟2-12,根據抽樣的文檔集與文檔矩陣的分布差異來對主題模型進行調整;對於文檔矩陣中的每一篇文檔,對應的抽樣文檔生成過程如下:對於每篇文檔di中的每一個詞,從該詞對應的主題分布Θi抽樣出一個主題zk;對於每個主題zk,從其對應的詞語分布中抽樣出一個詞wij,重複上述步驟直到遍歷完文檔dj中的所有詞語。步驟2-13,根據新的模型重複步驟2-12,直到達到預設的次數,本發明實施例中設置為10000次;步驟2-14,輸出主題-詞矩陣。在得到主題-詞矩陣之後,進行名詞提取,得到關鍵名詞鍊表。提取名詞的處理過程如圖5所示,方法如下:首先由用戶輸入:關鍵詞文件地址、倒排索引文件夾地址以及輸出結果地址。輸出為一個只包含關鍵名詞的文件。處理過程如下:首先讀取所有的關鍵詞,並且去掉重複的詞;接著初始化索引閱讀器,然後對於每一個關鍵詞,根據索引找出包含該關鍵詞的句子,使用分詞器對句子進行分詞,找出該關鍵詞在句子中的詞性,統計各種詞性出現的概率,選擇出現概率最大的詞性作為該關鍵詞在整個文檔集中的詞性,並且將詞性為名詞的關鍵詞加入到一個鍊表(名詞鍊表)中,遍歷完所有的關鍵詞後得到的鍊表即為關鍵名詞鍊表,最後將關鍵名詞鍊表輸出到輸出結果地址中。其中關鍵名詞鍊表中的所有名詞均為關鍵概念。在得到關鍵名詞鍊表之後,進入步驟3,對關鍵概念進行語義關係提取。語義關係提取階段過程如圖6所示,主要步驟包括:步驟3-1,將所有的關鍵概念輸入到一個集合中;步驟3-2,遍歷所有的句子,對於每個句子而言,如果其包含關鍵概念,則將其寫入到一個文件中;步驟3-3,對所有的句子進行語義消歧;步驟3-4,對於每一個關鍵概念,統計其所有語義ID的出現次數,將出現次數最多的語義ID作為該關鍵概念在文檔集中的語義;步驟3-5,根據步驟3-4中所得到的語義ID計算詞典語義距離。為計算兩個關鍵概念之間的語義距離,需藉助語義詞典中的上位詞關係。通過這些關係,可能找到兩個被標記概念的公共祖先概念。對於兩個概念c1、c2,如果在語義詞典中可以找到其公共祖先概念c3,那麼兩個概念詞之間帶深度的語義距離表示為:c1和c2分別為兩個關鍵概念,T為在語義詞典中包含c1和c2的概念樹,n為一個正實數,用於調整帶深度的語義距離,d為兩個關鍵概念的公共祖先概念在語義詞典中的深度,BSD(c1,c2,T)是兩個關鍵概念在語義詞典中的最短距離。步驟3-6,根據所有關鍵概念對在商品評論文檔集中出現的相關性計算關鍵概念的統計語義距離;使用所有主題詞作為關鍵概念的上下文,用其與關鍵概念出現次數的相關性作為上下文向量的特徵,該特徵表示為:tfk(w1)是w1在文檔dk中的詞頻,tfavg(w1)是整個文檔集中tfk(w1)的平均值,tfstd(w1)是tfk(w1)所有值的標準差。假設c1和c2是兩個概念的上下文向量,那麼其統計語義的餘弦距離(即統計語義距離)表示為:步驟3-7,結合兩種語義距離的結果,作為最終的語義距離並輸出記錄所有關鍵概念語義距離的距離矩陣。為了結合兩種距離,首先將其進行歸一化:CD(c1,c2)=1-CS(c1,c2)Dmax是基本詞典語義距離的可能最大值。歸一化之後,兩個關鍵概念的語義距離表示為:所有關鍵概念的語義距離組成關鍵概念。在得到關鍵概念的語義距離之後,進行步驟4,對關鍵概念進行多路凝聚聚類。多路凝聚聚類階段主要包含以下步驟:步驟4-1,輸入所有關鍵概念的距離矩陣;步驟4-2,選取語義距離最小的兩個關鍵概念,並根據其間各種指標的相似性選取合適的合併操作;與傳統的層次聚類算法不同的是,多路凝聚聚類算法在合併兩個聚類時有三種不同的合併操作,而傳統層次聚類只有一種。額外的合併操作使得輸出多叉樹成為可能。假設需合併的兩個聚類為聚類A和聚類B,如圖7a所示,則對應三種情況為:1)聚類A和聚類B變成一個新聚類C的子類,如圖7b所示。這種情況一般發生於兩個聚類之間的距離大於特定閾值時。該情況下的合併與傳統凝聚層次聚類中的情況一樣。2)聚類A和聚類B的子類變為一個新聚類C的子類,如圖7c。這種情況發生於兩個聚類之間的距離小於閾值並且其子類平均距離相似,這說明兩個聚類的語義接近且具有相近的密度。3)一個聚類變為另一個聚類的子類,如圖7d所示,圖中聚類B變為聚類A的子類。這種情況說明兩個聚類具有較小的距離但是兩者的語義密度並不相似。這種情況下則將較大密度的聚類作為另外一個聚類的子類。因為子類平均距離越小,說明子類之間的關係越緊密,密度越大,而在概念分類中,越往上子類之間的距離越大。在本發明中,每個聚類為一個概念節點。為計算聚類間的語義距離及其密度的相似性,需引入以下幾個概念:①平均節點距離。對於兩個概念c1和c2,其平均節點距離為:ci和cj是對應概念節點的葉節點,m和n分別為c1和c2概念下葉節點的數目,SDD(ci,cj)為葉節點ci和cj之間的語義距離。②子節點距離。對於一個概念節點c1,其子節點距離為:ci和cj是概念節點c1的直接子節點。③平均子節點距離。對於一個概念節點c1,其平均子節點距離為:擴展到兩個概念節點c1和c2的情況,則兩個概念節點的平均子節點距離為:m和n分別為概念節點c1和c2的直接子節點的數目。④節點距離差異。對於兩個概念節點c1、c2的節點距離差異為:DC(c1,c2)=NCDavg(c1,c2)-CCDavg(c1,c2)⑤節點密度差異。對於兩個概念節點c1、c2,則節點密度差異為:每一次迭代過程算法都會選取平均節點距離最小的兩個節點進行合併。假設這兩個節點為概念節點c1和c2,如果DC(c1,c2)>τ,那麼這兩個概念節點將會按照第一種情況進行合併。τ就是第一種情況裡的閾值,大於τ說明兩個聚類間的差距仍然過大。如果差距不大,則比較兩個概念節點的平均子節點概念距離。如果滿足DCD(c1,c2)<σ-1,則算法轉入第二種情況,否則轉入第三種情況。步驟4-3,從關鍵概念集合中刪除掉已合併的關鍵概念,加入合併後的概念節點,並且更新距離矩陣;步驟4-4,重複步驟4-2至4-3,直到所有概念節點都已合併到同一個概念節點下;步驟4-5,以XML形式輸出最終的概念層次。本發明方法使用多路凝聚聚類算法生成最終的概念層次,突破了傳統凝聚聚類只能生成二叉樹的限制。