用於卷積神經網絡計算的處理器的製作方法
2023-09-16 08:30:50 4
本發明涉及卷積神經網絡計算領域,特別涉及一種用於卷積神經網絡計算的處理器。
背景技術:
卷積神經網絡(Convolutional Neural Network,以下簡稱CNN)近年來成為圖像識別領域的研究熱點。經過訓練後的CNN模型,可以用於圖像分類、物體識別與顯著性檢測等諸多領域。
CNN主要由三部分組成:卷積層、降採樣層以及全連接層。通過改變不同層的數目、相互間的級聯方式以及層內的配置,可以獲得不同的網絡結構。
現有的大部分CNN的實現主要是基於通用處理器CPU實現的。在CNN網絡結構中,層內計算是獨立不相關的,而層間結構可以理解為是一個流水線結構。通用處理器CPU由於其自身特點無法充分地挖掘CNN內部的並行性,在進行CNN計算時,會增加CNN的計算規模,提升CNN計算的複雜度。
由此,需要一種能夠對卷積神經網絡計算過程進行優化的處理器。
技術實現要素:
本發明主要解決的技術問題是提供一種用於卷積神經網絡計算的處理器,其可以實現CNN的層內計算並行化,從而能夠實現對卷積神經網絡計算過程的優化。
根據本發明的一個方面,提供了一種用於卷積神經網絡計算的處理器,其基於N個輸入通道的輸入數據分別計算M個輸出通道的輸出數據,其中N和M是大於或等於2的自然數,該處理器包括:m個計算單元,每個計算單元用於針對其所對應的對應輸出通道,基於N個輸入通道的輸入數據和分別分配給對應輸出通道的權重組,計算對應輸出通道的輸出數據,其中m是大於或等於2的自然數,其中,m個計算單元同步地接收N個輸入通道的輸入數據,並且同步地進行計算。
優選地,每個計算單元可以包括:n個卷積計算模塊,分別同步接收其所對應的輸入通道的輸入數據,並對其進行卷積計算,其中n是大於或等於2的自然數。
優選地,n和m的值可以是根據計算單元的計算資源和外部存儲的輸入輸出帶寬設定的,以使得數據輸入速度基本上等於數據被使用的速度,數據輸出速度基本上等於數據產生速度。
優選地,每個卷積計算模塊可以包括:輸入端,用於接收其所對應的輸入通道的輸入數據;輸入緩存,用於緩存輸入數據;卷積器,用於使用針對該計算單元所對應的對應輸出通道和該卷積計算模塊所對應的輸入通道的權重矩陣,對輸入數據進行循環卷積計算,其中,在卷積器的一個計算周期內,卷積器從輸入緩存中讀取對應於權重矩陣的元素數的一批輸入數據,並進行卷積計算,輸出計算結果。
優選地,每個計算單元還可以包括:輸出端,用於輸出計算單元的最終計算結果;加法模塊,設置在n個卷積計算模塊和輸出端之間,用於將n個卷積計算模塊針對N個輸入通道的輸入數據進行卷積計算的相應計算結果相加。
優選地,加法模塊可以包括:加法樹,用於將n個卷積計算模塊同步計算得到的相應計算結果相加。
優選地,加法模塊還可以包括:中間結果緩存,設置在加法樹和輸出端之間,用於在n個卷積計算模塊完成對N個輸入通道的所有卷積計算以前,緩存中間計算結果。
優選地,在N>n的情況下,N個輸入通道可以被分為多組輸入通道,每組最多n個輸入通道,將多組輸入通道分批次輸入到每個計算單元,n個卷積計算模塊在完成針對一組輸入通道的計算之後,開始輸入下一組輸入通道的輸入數據,加法模塊還可以包括:第一加法單元,用於將加法樹的輸出結果與中間計算結果緩存中針對先前一組或多組輸入通道進行計算得到的相應中間計算結果相加,並且在完成針對所有輸入通道的輸入數據的計算以前,將相加的結果保存在中間結果緩存中,而在完成對所有輸入通道的輸入數據的計算之後,輸出相加的結果。
優選地,該處理器還可以包括:第二加法單元,用於將加法模塊的輸出結果與偏置值相加,偏置值是針對該計算單元所對應的對應輸出通道設置的。
優選地,該處理器還可以包括:第一移位器,用於對預設偏置值進行移位以得到偏置值,以使偏置值的小數點與加法模塊的輸出結果的小數點位置對齊,其中,第二加法單元將加法模塊的輸出結果與移位得到的偏置值相加。
優選地,該處理器還可以包括:多路選擇單元,用於從其多個輸入埠的輸入中選擇一個輸出,其中,第二加法單元的輸出連接到多路選擇單元的一個輸入埠。
優選地,該處理器還可以包括:非線性單元,用於對第二加法單元的輸出結果進行非線性運算,並且非線性單元的輸出連接到多路選擇單元的一個輸入埠。
優選地,該處理器還可以包括:池化單元,用於對非線性單元的輸出結果進行池化操作,並且池化單元的輸出連接到多路選擇單元的一個輸入埠。
優選地,該處理器還可以包括:第二移位器,設置在多路選擇單元和輸出端之間,用於對多路選擇單元的輸出結果進行移位,以便對多路選擇單元的輸出結果進行適當的截斷,從而確保輸出端的輸出結果的位寬和輸入通道的輸入數據一致。
綜上,本發明的處理器包括多個可以並行計算的計算單元,不同的計算單元可以獨立且同步地負責計算不同的輸出通道的輸出數據。由此,本發明的處理器在用於卷積神經網絡計算時,可以實現並行化計算,從而可以大大縮短完成整個卷積神經網絡計算所需的時間。
附圖說明
通過結合附圖對本公開示例性實施方式進行更詳細的描述,本公開的上述以及其它目的、特徵和優勢將變得更加明顯,其中,在本公開示例性實施方式中,相同的參考標號通常代表相同部件。
圖1示出了根據本發明一實施例的用於卷積神經網絡計算的處理器的結構的示意性方框圖。
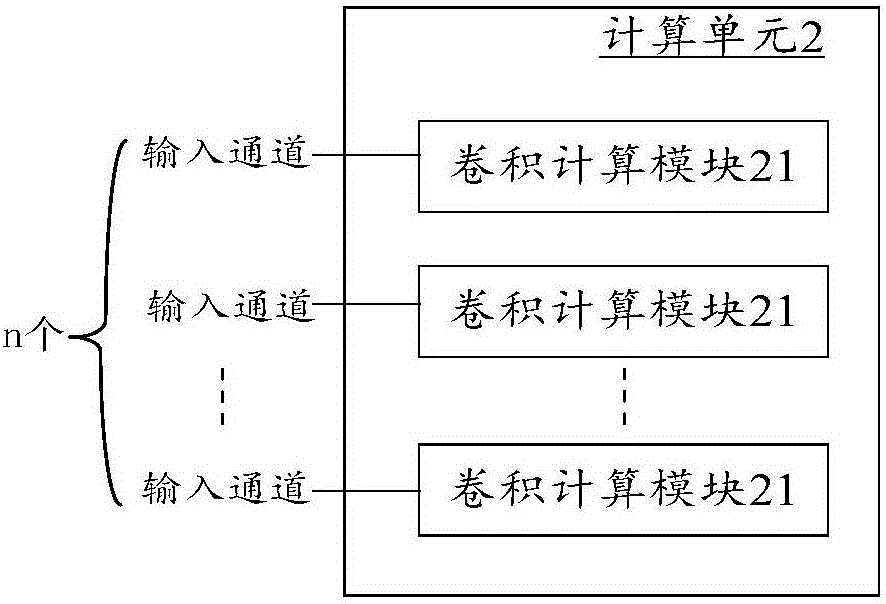
圖2示出了根據本發明一實施例的計算單元的結構的示意性方框圖。
圖3示出了根據本發明一實施例的卷積計算模塊可以具有的具體結構的示意性方框圖。
圖4示出了根據本發明另一實施例的計算單元的結構的示意性方框圖。
圖5示出了根據本發明另一實施例的計算單元的結構的示意性方框圖。
具體實施方式
下面將參照附圖更詳細地描述本公開的優選實施方式。雖然附圖中顯示了本公開的優選實施方式,然而應該理解,可以以各種形式實現本公開而不應被這裡闡述的實施方式所限制。相反,提供這些實施方式是為了使本公開更加透徹和完整,並且能夠將本公開的範圍完整地傳達給本領域的技術人員。
如前所述,基於CNN網絡結構的層內計算獨立不相關的特點,本發明提出了一種能夠實現CNN的並行化計算的處理器。
圖1示出了根據本發明一實施例的用於卷積神經網絡計算的處理器的結構的示意性方框圖。
在卷積神經網絡的一層計算中,往往需要對多個輸入通道的輸入數據進行計算,得到多個輸出通道的輸出數據,作為下一層計算的輸入數據或作為計算結果。
本發明的發明人注意到,在針對一個輸出通道的計算過程中,需要用到多個(一般是全部)輸入通道的輸入數據。但是針對任何一個輸出通道的計算過程與針對其它任何輸出通道的計算過程是不相關的。因此,本發明提出,採用多個硬體來分別同步執行針對多個輸出通道的計算,從而實現針對多個輸出通道的並行化計算,提高計算效率。
本發明的處理器可以基於N個輸入通道的輸入數據分別計算M個輸出通道的輸出數據,其中N和M是大於或等於2的自然數。這裡,在圖像處理的場景下,對於第一層計算而言,輸入通道可以是例如RGB的三幀像素值,此時輸入通道可以是3個。輸出通道的數量可以根據要計算的卷積神經網絡的網絡結構得到,其中,每個輸出通道可以對應於一個權重組,每個權重組可以包括N個權重,例如這裡的權重可以用Wij表示,其中,i為輸入通道的編號,i=1、2、3……N,j為輸出通道的編號,j=1、2、3……M。權重Wij可以是預先設定的。
參見圖1,本發明實施例的處理器1包括m個計算單元2,其中,m是大於或等於2的自然數。
在一個循環周期內,一個計算單元2獨立地針對一個輸出通道進行計算。
每個計算單元2針對其所對應的對應輸出通道,基於N個輸入通道的輸入數據和分別分配給該計算單元2所對應的對應輸出通道的權重組,計算對應輸出通道的輸出數據,m個計算單元2可以同步地接收N個輸入通道的輸入數據,並且同步地進行計算。
其中,處理器1所包含的計算單元的個數m可以小於或等於輸出通道的個數M。此時,可以同時針對全部輸出通道進行並行計算。
而在m<M的情況下,可以分批進行同步計算。即,在m個計算單元完成對應的對應輸出通道的計算後,可以接下來為下一批尚未進行計算的輸出通道進行計算。
也就是說,在處理器1所包含的計算單元2的個數小於輸出通道的個數時,每個計算單元2可以具有多個對應的對應輸出通道,在每個計算單元2計算完一個對應輸出通道的輸出數據後,就可以繼續計算其所對應的其它對應輸出通道的輸出數據。
不同的計算單元2可以共享相同的輸入通道的輸入數據,以計算不同的輸入通道的輸出數據,這樣,可以減少讀取數據的次數。
綜上,本發明的處理器1包括多個可以並行計算的計算單元2,不同的計算單元2可以獨立且同步地負責計算不同的輸出通道的輸出數據。由此,本發明的處理器1在用於卷積神經網絡計算時,可以實現並行化計算,從而可以大大縮短完成整個卷積神經網絡計算所需的時間。
其中,處理器1所包含的計算單元2的個數m可以根據計算單元2的計算資源和外部存儲的輸入輸出帶寬設定,以使得數據輸入速度基本上等於數據被使用的速度,數據輸出速度基本上等於數據產生速度。由此,可以在不浪費計算資源的情況下,外部存儲的輸入輸出帶寬的利用效率最大化。
至此,結合圖1就本發明的處理器的基本構成做了詳細說明。下面就本發明的處理器中的每個計算單元2可以具有的具體結構做進一步說明。
圖2示出了根據本發明一實施例的計算單元2的結構的示意性方框圖。
對於卷積神經網絡計算的每一層計算而言,卷積計算的計算量往往是非常繁重的。
本發明的發明人注意到,在針對一個輸出通道的計算中,可以針對不同輸入通道的輸入數據分別進行卷積計算。因此,本發明提出,在針對一個輸出通道進行計算的一個計算單元中,設置多個卷積計算模塊,分別對多個輸入通道的數據進行卷積計算,從而實現針對多個輸入通道的並行化計算,進一步提高計算效率。
參見圖2,計算單元2可以包括n個卷積計算模塊21。每個卷積計算模塊21可以同步接收其所對應的輸入通道的輸入數據,並可以對接收到的輸入數據進行卷積計算,其中n是大於或等於2的自然數。
由此,不同輸入通道的輸入數據可以交由計算單元2中相應的卷積計算模塊21分別同步進行卷積計算。
其中,不同的計算單元2所包含的卷積計算模塊21的個數可以相同,也可以不同。作為優選方案,不同的計算單元2可以包含相同個數量的卷積計算模塊21,這樣,每個計算單元2的計算能力基本相同,可以更好地實現不同的計算單元2之間的同步計算。
另外,每個計算單元2所包含的卷積計算模塊21的個數可以小於或等於輸入通道的個數。在每個計算單元2所包含卷積計算模塊21的個數小於輸出通道的個數時,每個卷積計算模塊21可以具有多個對應的輸入通道,即每個卷積計算模塊21可以分別先後接收多個輸入通道的輸入數據,並對其先後進行卷積計算。
具體來說,在每個卷積計算模塊21計算完一個其對應的輸入通道的輸入數據的卷積後,就可以繼續計算其所對應的其它輸入通道的輸入數據的卷積。
另外,每個計算單元2所包含的卷積計算模塊21的個數n,可以根據計算單元2的計算資源和外部存儲的輸入輸出帶寬設定,以使得數據輸入速度基本上等於數據被使用的速度,數據輸出速度基本上等於數據產生速度。由此,可以在不浪費計算資源的情況下,外部存儲的輸入輸出帶寬的利用效率最大化。
這裡,可以根據計算單元2的計算資源和外部存儲的輸入輸出帶寬,綜合設定計算單元2的個數m以及每個計算單元2可以具有的卷積計算模塊21的個數n。
作為示例,這裡給出一種確定計算單元輸入輸出通道個數的方法。
以現場可編程門陣列(FPGA)平臺為例,通常而言,乘法單元由片上的數位訊號處理(DSP)模塊搭建,因此DSP模塊的數量約束了乘法單元的數量。以最大吞吐率為要求的話則乘法器的數量應至少等於DSP模塊的數量。因此,
輸入通道個數×輸出通道個數×卷積核大小=FPGA平臺的DSP模塊數量。
實際上,由於FPGA本身的資源也可以構建乘法器,因此乘法器的數量可以略微大於DSP模塊的數量。
選定了總的並行度之後,需要確定輸入通道個數和輸出通道個數。為了保證計算單元最高效地被利用,需要使數據輸入的速度和數據被使用的速度儘可能相同。
假設每一個輸入通道對應的(在計算單元外的)緩存大小相同為B,則一組數據的輸入時間約為:
B×輸入通道個數/輸入帶寬。
卷積核因為數據較少(對應於權重矩陣)可以基本忽略。
數據計算的時間為:
B×數據復用的次數。
由於中間結果緩存的存在,因此有可能用一組輸入數據計算多組中間結果同時緩存。
在已知上述公式中的其他參數的情況下,可以根據輸入時間基本上等於輸出時間的原則來確定輸入通道的個數,進而確定輸出通道的個數。
圖3示出了根據本發明一實施例的卷積計算模塊21可以具有的具體結構的示意性方框圖。
參見圖3,卷積計算模塊21可以包括輸入端211、輸入緩存212以及卷積器213。
其中,輸入端211可以接收其所對應的輸入通道的輸入數據。
由於卷積計算中,需要對一些輸入數據重複利用。例如,在輸入數據為圖像數據的情況下,在針對對應於權重矩陣的多個像素(可以稱為一個「計算窗口」)的數據完成一次卷積計算之後,將計算窗口平移一個像素,進行下一次卷積計算。這種情況下,每個像素數據需要被重複利用多次。
輸入緩存212可以緩存輸入端211所接收的輸入數據,以便於卷積器213多次使用。
如上文所述,一個卷積計算模塊21可以用來先後計算多個輸入通道的輸入數據的卷積。因此,輸入端211也可以先後接收多個輸入通道的輸入數據,相應地,輸入緩存212也可以同時或先後緩存多個輸入通道的輸入數據。
圖3示出了為每一個卷積計算模塊21分別設置一個輸入緩存212,以緩存該卷積計算模塊21要進行計算處理的輸入通道的輸入數據的情況。應當明白,也可以在計算單元2中統一設置輸入緩存,其中緩存所有輸入通道的輸入數據。所有卷積計算模塊21都從該統一設置的輸入緩存中讀取各自所針對的輸入通道的輸入數據。
另外,輸入緩存212的容量可以被設置為緩存一個輸入通道的所有輸入數據。另一方面,輸入緩存212的容量也可以被設置為緩存一個輸入通道的部分輸入數據。當在後續的卷積計算中不再需要使用一個數據時,可以不再保留該數據。
卷積器213可以使用針對該計算單元(包含該卷積器213的卷積計算模塊21所對應的計算單元2)所對應的對應輸出通道和該卷積計算模塊(包含該卷積器213的卷積計算模塊21)所對應的輸入通道的權重矩陣,對輸入數據進行循環卷積計算。
這裡,卷積器213可以首先完成一個輸入通道的輸入數據的循環卷積計算,然後進行下一個輸入通道的輸入數據的循環卷積計算。
具體地說,在卷積器213的一個計算周期內,卷積器213可以從輸入緩存212中讀取對應於權重矩陣的元素數的一批輸入數據,並進行卷積計算,輸出計算結果。
這裡述及的計算周期是卷積器213計算對應於權重矩陣的元素數的輸入數據的卷積所需的時間。因此,卷積器213計算完成一個輸入通道的所有輸入數據的卷積需要多個計算周期。在一個計算周期結束後,卷積器213可以從輸入緩存中讀取對應於權重矩陣的元素數的下一批輸入數據,並進行卷積計算,輸出計算結果,直到把輸入緩存212中的所有輸入數據的卷積都計算完為止。
其中,在計算輸入數據卷積的過程中,可能存在一個或多個批次的輸入數據的個數與權重矩陣的元素數不對等(例如當涉及圖像數據的邊緣行或列時),此時可以添加相應個數(整行或陣列)的「0」或「1」,以使得計算可以正常進行。
圖4示出了根據本發明另一實施例的計算單元2的結構的示意性方框圖。
參見圖4,本發明實施例的計算單元2可以包括n個卷積計算模塊21、加法模塊22以及輸出模塊23。
其中,關於卷積計算模塊21可參見上文結合圖2、圖3的相關描述,這裡不再贅述。
輸出端23可以輸出計算單元2的最終計算結果。加法模塊22設置在n個卷積計算模塊21和輸出端23之間,可以將n個卷積計算模塊21針對N個輸入通道的輸入數據進行卷積計算的相應計算結果相加。
由此,將針對各個輸入通道獨立計算得到的數據整合起來。
參見圖4,加法模塊22可以可選地包括圖中虛線框所示的加法樹221,加法樹221可以將n個卷積計算模塊21同步計算得到的相應計算結果相加。
由於卷積計算模塊是同步進行計算的,針對不同輸入通道的相應位置處(例如圖像上相同橫縱坐標處)的數據的卷積計算基本上是同步完成的。這樣,每當卷積計算模塊完成一次卷積計算(使用一次權重矩陣進行計算為一次卷積計算,例如,權重矩陣為3×3矩陣的情況下,卷積核的一次卷積計算需要9次乘法計算和8次加法計算),就可以將數據輸入到加法樹221。由此,可以對不同輸入通道的相應卷積結果進行加和計算。
另外,參見圖4,加法模塊22還可以可選地包括圖中虛線框所示的中間結果緩存222。中間結果緩存222設置在加法樹221和輸出端23之間,用於在n個卷積計算模塊21完成對N個輸入通道的所有卷積計算以前,緩存中間計算結果。中間結果緩存222可以對加法樹221的每次加和結果進行緩存,直到完成針對這一批輸入通道的輸入數據的卷積及加和計算。
另外,在n<N時,換言之,可以同時對所有輸入通道的輸入數據進行卷積計算的情況下,可以不設置或不使用中間結果緩存222,而將加法樹221的每次計算結果直接提供給後續計算部分。當然,也可以提供緩存,完成所有卷積計算之後再進行後續計算。
在N>n的情況下,N個輸入通道可以被分為多組輸入通道,每組可以包括最多n個輸入通道,可以將多組輸入通道分批次輸入到每個計算單元2。n個卷積計算模塊21在完成針對一組輸入通道的計算之後,開始輸入下一組輸入通道的輸入數據。
如圖4所示,加法模塊22還可以包括第一加法單元223。
第一加法單元223可以將加法樹221的輸出結果與中間計算結果緩存中針對先前一組或多組輸入通道進行計算得到的相應中間計算結果相加,並且在完成針對所有輸入通道的輸入數據的計算以前,將相加的結果保存在中間結果緩存222中,而在完成對所有輸入通道的輸入數據的計算之後,輸出相加的結果。
通過設置中間結果緩存222和第一加法單元223,在輸入通道數N大於計算單元2一次可並行操作的輸入通道數量m(卷積計算模塊21的數量)的情況下,可以將分批計算得到的數據整合起來。另外,還可以將需要較大存儲空間的中間計算結果通過累加的形式完成,減少了對所佔用的存儲空間,因此不必存入外部存儲。
圖5示出了根據本發明另一實施例的計算單元2的結構的示意性方框圖。
參見圖5,本發明實施例的計算單元2可以包括n個卷積計算模塊21、加法模塊22以及第二加法單元24。
其中,關於卷積計算模塊21和加法模塊22,可以參見上文相關描述,這裡不再贅述。
第二加法單元24可以將加法模塊22的輸出結果與偏置值相加,其中,偏置值是針對該計算單元所對應的對應輸出通道設置的。
參見圖5,本發明實施例的計算單元2還可以可選地包括第一移位器25。第一移位器25可以對預設偏置值進行移位以得到偏置值,得到的偏置值的小數點與加法模塊22的輸出結果的小數點位置對齊。這是由於採用char格式表示數值,而不是採用浮點格式表示數值,所以需要指定小數點在某兩位之間,因此需要通過移位來將小數點位置對齊。
其中,第二加法單元24可以將加法模塊22的輸出結果與移位得到的偏置值相加。
參見圖5,本發明實施例的計算單元2還可以可選地包括多路選擇單元26。多路選擇單元26用於從其多個輸入埠的輸入中選擇一個輸出,其中,如圖5所示,第二加法單元24的輸出可以直接連接到多路選擇單元26的一個輸入埠。
參見圖5,本發明實施例的計算單元2還可以可選地包括非線性單元27。非線性單元27可以對第二加法單元24的輸出結果進行非線性運算,並且非線性單元27的輸出可以直接連接到多路選擇單元27的一個輸入埠。
參見圖5,本發明實施例的計算單元2還可以可選地包括池化(pooling)單元28。池化單元28用於對非線性單元27的輸出結果進行池化操作,並且池化單元28的輸出也可以連接到多路選擇單元26的一個輸入埠。
參見圖5,本發明實施例的計算單元2還可以可選地包括第二移位器29。第二移位器29可以設置在多路選擇單元26和輸出端23之間,用於對多路選擇單元26的輸出結果進行移位,以便對多路選擇單元26的輸出結果進行適當的截斷,從而確保輸出端23的輸出結果的位寬和輸入通道的輸入數據一致,以備下一層計算過程中使用。
如上所述,多路選擇單元26的多個輸入埠可以分別與第二加法單元24、非線性單元27以及池化單元28的輸出連接。根據實際情況,多路選擇單元26可以從多個輸入埠的輸入中選擇一個進行輸出。
綜上,本發明的用於卷積神經網絡計算的處理器同時在輸入通道、輸出通道以及卷積核層面都可以進行並行計算,可以提供較高的並行度,充分利用計算資源。並且通過改變輸入和輸出通道的並行度,可以形成各種規模的硬體設計,在電路面積和速度之間權衡。在給定計算系統和外部存儲的輸入輸出帶寬的情況下,可以選擇合適的輸入以及輸出通道並行度,使得輸入輸出帶寬的利用效率最大化,同時不浪費計算資源。
本發明的發明人在一款包含CPU和FPGA的片上系統平臺上搭建了一個神經網絡加速系統AEye,在這個系統上構建了一個人臉檢測應用,該算法以卷積神經網絡來標定人臉上的特徵點。其中,CPU平臺負責控制人臉檢測算法的主要流程,FPGA部分包括含一個由本發明作為控制器的卷積神經網絡加速器。該加速器負責算法中的卷積神經網絡的計算部分。
下表對比了採用本發明提出的用於卷積神經網絡計算的處理器和通用處理器在計算該任務中的神經網絡的性能。作為對比的CPU使用的是英偉達公司生產的Terga K1處理平臺的CPU。
可以看到,對比Terga K1平臺的CPU計算性能,本發明可以帶來明顯的速度提升。
本發明的發明人在另一款包含CPU和FPGA的片上系統平臺上同樣搭建了一個用於卷積神經網絡計算的處理器,本實施例的處理器採用了和前一實施例不同的設計參數。本實施例的處理器僅進行神經網絡加速計算,因此可以較為準確地估計實際運行中加速器和外部存儲之間的輸入輸出帶寬。該處理器的外部存儲為帶寬4.2GB/s的DDR3存儲器。根據FPGA平臺上的緩存資源以及計算資源,本實施例的處理器採用了2個計算單元,每個計算單元使用64個卷積計算模塊進行計算,可以在帶寬約束條件下最大化計算速度。
上文中已經參考附圖詳細描述了根據本發明的用於卷積神經網絡計算的處理器。
以上已經描述了本發明的各實施例,上述說明是示例性的,並非窮盡性的,並且也不限於所披露的各實施例。在不偏離所說明的各實施例的範圍和精神的情況下,對於本技術領域的普通技術人員來說許多修改和變更都是顯而易見的。本文中所用術語的選擇,旨在最好地解釋各實施例的原理、實際應用或對市場中的技術的改進,或者使本技術領域的其它普通技術人員能理解本文披露的各實施例。