一種基於視覺上自監督學習與模仿的繩索操縱方法與流程
2023-09-09 23:55:05 7
本發明涉及機器人手臂操作領域,尤其是涉及了一種基於視覺上自監督學習與模仿的繩索操縱方法。
背景技術:
在機器人領域,操控易變形物體一直是一個具有挑戰性的問題,例如繩索、衣服、布條等。但同時,這些活動對人類來講意義重大,在許多具有高度危險的場合可以代替人力勞動,使人類避免受到傷害,如高樓外牆的構建與清洗、具有重大汙染地區的管道清理、航天航空中的機械處理等,都具有非常大的潛在開發空間,另外,在遠洋深海中,繩索的操控更具有重要性,例如油井的探勘、輪船的拖拉、漁場圍捕網的豎立,結冰面的海底工具牽引等,不僅在實體應用上,而且在經濟上也是高新科技發展的重要動力。
繩索等易變形物體的機械操作始終未能有突破性進展,一方面由於物質材料的軟化性質及易變形狀性質,既難以在視覺上對變形程度、形變方向角度等進行預測,也不能從材料密度中估算出每次形變的結果,因此,對一千條繩子作及其細微變化的力學操作,也可能得到一千種截然不同的形變結果,另一方面由於機械製備的強度問題,無法掌握易形變材料在不同力的強度之下作出的反應,因此很難完備地完成一種易變形材料的輕操控。
本發明提出了一種基於深度卷積網絡學習的新框架。改造機器人機械系統平臺,允許其進行拾、取操作,然後將真實世界人手操控的圖像與機器人自己操控的圖像進行對比,輸入到深度神經學習網絡中進行配對訓練,生成逆向模型,來進行下一步的動作預測,在重複訓練過程中提高預測準度,從而使得該配置符合人手要求。本發明可以處理繩索等軟性材料物體的操縱,提供一個深度神經學習網絡來生成逆向動態模型,同時提高了機器人操控繩索的準確度。
技術實現要素:
針對解決在易形變材料中機器人操控的問題,本發明的目的在於提供一種基於視覺上自監督學習與模仿的繩索操縱方法,提出了一種基於深度卷積網絡學習的新框架。
為解決上述問題,本發明提供一種基於視覺上自監督學習與模仿的繩索操縱方法,其主要內容包括:
(一)繩索操縱機械系統構造;
(二)指數線性單元深度卷積學習網絡;
(三)繩索拾放模塊;
(四)繩索拾放仿真。
其中,所述的繩索操縱機械系統構造,改造具有視覺攝入系統、軟體處理單元、單機械手臂和實驗平臺的機器人機械系統;
(1)視覺攝入系統具有攝像設備及儲存設備,可以對視覺範圍內的物體進行攝影儲存;
(2)軟體處理單元具有計算單元、數據處理單元,主要對圖像進行變換及搭建深度卷積學習網絡;
(3)單機械手臂具有旋轉功能,末端是由平行的夾子組成的抓手,可以開啟跟閉合;
(4)實驗平臺是置於機械手臂下的平板,繩索的一端固定於平板上。
進一步地,所述的指數線性單元深度卷積學習網絡,包括網絡結構、學習過程和有效數據收集。
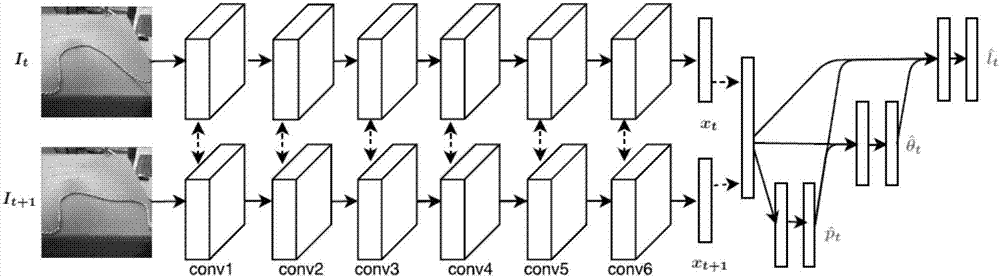
進一步地,所述的網絡結構,對當前視圖及下一視圖中的繩索,分別利用兩組原始設置相同的卷積網絡進行學習,具體網絡設置為:c96-c256-c384-c384-c256-c200,每一層緊接著指數線性函數;
其中,上述連結符號「-」表示相繼連接網絡的層,「c」表示卷積層,數字表示該網絡層的神經元數;
兩張視圖經過這兩組卷積網絡後得到兩部分輸出(xt,xt+1),t是指當前視圖,分別具有200個特徵,合併兩部分特徵再輸入到最後一個部分全連接網絡f200-f200,得到關於繩索的動作預測特徵。
進一步地,所述的學習過程,為了進行網絡訓練,動作預測問題轉變為動作空間的分類問題,具體地將其表達為(pt,θt,lt),pt是拾取動作地點,範圍為20×20的網格,θt是拾取動作方向,分為36個範圍,lt是拾取動作長度,分為10個等級;
訓練過程是將以上三個參數獨立地進行分類,即:
p(pt,θt,lt)=p(pt)p(θt|pt)p(lt|θt,pt)(1)
神經網絡首先對拾取地點進行一個預測分布,得到超過400個的可能拾取地點,然後某一地點被選取為拾取地點;接著,根據特徵(xt,xt+1)和公式(1),利用一位有效編碼推出θt;進一步地,再一次利用一位有效編碼推出狀態lt;
具體地,按照著名神經網絡alexnet在imagenet中訓練得到的權值對神經網絡前五層賦值,在前面5000次迭代中將學習率調整為0,剩餘迭代則學習率調整為0.004,總共利用60000對圖像進行網絡訓練,2500張圖像進行參數調整。
進一步地,所述的有效數據採集,為了使得數據收集有益於配置,在手動選擇隨機配置時,先實時收集一套含有50張連續動作的圖像,然後利用一個已經經過30000張圖像訓練的模型進行圖像的收集,將這兩個不同的圖像庫作為特徵對(xt,xt+1)的訓練圖像。
進一步地,所述的繩索拾放模塊,按照以下次序進行機械手臂的動作:
(1)由公式(1)得到拾取動作地點和釋放動作地點;
(2)在拾取地點使用夾子抓住繩索一點;
(3)旋轉手臂,使夾子垂直上升5釐米;
(4)移動手臂到釋放動作地點垂直高度5釐米處;
(5)鬆開夾子,釋放繩索;
其中,旋轉角度的範圍是(0,2π),移動距離是(1,15cm)。
進一步地,所述的繩索拾放仿真,包括逆向動態模型和仿真人手拾放動作兩部分。
進一步地,所述的逆向動態模型,給定當前動作圖像it和下一動作圖像it+1,用ut表示預測的動作,則可定義為:
ut=f(it,it+1)(2)
其中,f表示動作預測函數,這個逆向動態模型表達動作預測與當前及下一動作都密切相關。
進一步地,所述的人手拾放動作仿真,在逆向動態模型的幫助下,機器人系統可以使得繩索逐漸變形,成為想要的形狀,每個階段的形狀會作為圖像的序列輸入到機器人系統中,用v={i′t|t∈(1…t)}表示,其中i′t表示終極動作圖像;
具體地,i1表示初始圖像,i′t表示終極圖像,則(i1,i2′)會被輸入到逆向動態模型並預測動作,從而產生真實世界圖像i2,再將(i2,i3′)輸入到逆向動態模型,得到下一個真實預測動作,產生下一個真實世界圖像,一直重複此套動作直到t次,則完成一次人手拾放動作的仿真。
附圖說明
圖1是本發明一種基於視覺上自監督學習與模仿的繩索操縱方法的系統流程圖。
圖2是本發明一種基於視覺上自監督學習與模仿的繩索操縱方法的深度學習卷積網絡示意圖。
圖3是本發明一種基於視覺上自監督學習與模仿的繩索操縱方法的實驗結果圖。
具體實施方式
需要說明的是,在不衝突的情況下,本申請中的實施例及實施例中的特徵可以相互結合,下面結合附圖和具體實施例對本發明作進一步詳細說明。
圖1是本發明一種基於視覺上自監督學習與模仿的繩索操縱方法的系統流程圖。主要包括繩索操縱機械系統構造、指數線性單元深度卷積學習網絡、繩索拾放模塊、繩索拾放仿真。
其中,繩索操縱機械系統構造,改造具有視覺攝入系統、軟體處理單元、單機械手臂和實驗平臺的機器人機械系統;
(1)視覺攝入系統具有攝像設備及儲存設備,可以對視覺範圍內的物體進行攝影儲存;
(2)軟體處理單元具有計算單元、數據處理單元,主要對圖像進行變換及搭建深度卷積學習網絡;
(3)單機械手臂具有旋轉功能,末端是由平行的夾子組成的抓手,可以開啟跟閉合;
(4)實驗平臺是置於機械手臂下的平板,繩索的一端固定於平板上。
指數線性單元深度卷積學習網絡,包括網絡結構、學習過程和有效數據收集。
網絡結構,對當前視圖及下一視圖中的繩索,分別利用兩組原始設置相同的卷積網絡進行學習,具體網絡設置為:c96-c256-c384-c384-c256-c200,每一層緊接著指數線性函數;
其中,上述連結符號「-」表示相繼連接網絡的層,「c」表示卷積層,數字表示該網絡層的神經元數;
兩張視圖經過這兩組卷積網絡後得到兩部分輸出(xt,xt+1),t是指當前視圖,分別具有200個特徵,合併兩部分特徵再輸入到最後一個部分全連接網絡f200-f200,得到關於繩索的動作預測特徵。
學習過程,為了進行網絡訓練,動作預測問題轉變為動作空間的分類問題,具體地將其表達為(pt,θt,lt),pt是拾取動作地點,範圍為20×20的網格,θt是拾取動作方向,分為36個範圍,lt是拾取動作長度,分為10個等級;
訓練過程是將以上三個參數獨立地進行分類,即:
p(pt,θt,lt)=p(pt)p(θt|pt)p(lt|θt,pt)(1)
神經網絡首先對拾取地點進行一個預測分布,得到超過400個的可能拾取地點,然後某一地點被選取為拾取地點;接著,根據特徵(xt,xt+1)和公式(1),利用一位有效編碼推出θt;進一步地,再一次利用一位有效編碼推出狀態lt;
具體地,按照著名神經網絡alexnet在imagenet中訓練得到的權值對神經網絡前五層賦值,在前面5000次迭代中將學習率調整為0,剩餘迭代則學習率調整為0.004,總共利用60000對圖像進行網絡訓練,2500張圖像進行參數調整。
有效數據採集,為了使得數據收集有益於配置,在手動選擇隨機配置時,先實時收集一套含有50張連續動作的圖像,然後利用一個已經經過30000張圖像訓練的模型進行圖像的收集,將這兩個不同的圖像庫作為特徵對(xt,xt+1)的訓練圖像。
繩索拾放模塊,按照以下次序進行機械手臂的動作:
(1)由公式(1)得到拾取動作地點和釋放動作地點;
(2)在拾取地點使用夾子抓住繩索一點;
(3)旋轉手臂,使夾子垂直上升5釐米;
(4)移動手臂到釋放動作地點垂直高度5釐米處;
(5)鬆開夾子,釋放繩索;
其中,旋轉角度的範圍是(0,2π),移動距離是(1,15cm)。
繩索拾放仿真,包括逆向動態模型和仿真人手拾放動作兩部分。
逆向動態模型,給定當前動作圖像it和下一動作圖像it+1,用ut表示預測的動作,則可定義為:
ut=f(it,it+1)(2)
其中,f表示動作預測函數,這個逆向動態模型表達動作預測與當前及下一動作都密切相關。
人手拾放動作仿真,在逆向動態模型的幫助下,機器人系統可以使得繩索逐漸變形,成為想要的形狀,每個階段的形狀會作為圖像的序列輸入到機器人系統中,用v={i′t|t∈(1…t)}表示,其中i′t表示終極動作圖像;
具體地,i1表示初始圖像,i′t表示終極圖像,則(i1,i2′)會被輸入到逆向動態模型並預測動作,從而產生真實世界圖像i2,再將(i2,i3′)輸入到逆向動態模型,得到下一個真實預測動作,產生下一個真實世界圖像,一直重複此套動作直到t次,則完成一次人手拾放動作的仿真。
圖2是本發明一種基於視覺上自監督學習與模仿的繩索操縱方法的深度學習卷積網絡示意圖。如圖所示,第一行第二行的卷積網絡設置是一樣的,左端輸入的圖像分別是現動作及下一動作的真實世界圖像,由此可推出關於拾取地點、方向和角度的參數值(右端)。
圖3是本發明一種基於視覺上自監督學習與模仿的繩索操縱方法的實驗結果圖。如圖所示,可以觀察到,在人手和機器人操控學習中,機器人能通過學習圖像的特徵,很好地預判到繩索的運動方向,從而進行拾放功能,將其操縱地跟人手一樣。
對於本領域技術人員,本發明不限制於上述實施例的細節,在不背離本發明的精神和範圍的情況下,能夠以其他具體形式實現本發明。此外,本領域的技術人員可以對本發明進行各種改動和變型而不脫離本發明的精神和範圍,這些改進和變型也應視為本發明的保護範圍。因此,所附權利要求意欲解釋為包括優選實施例以及落入本發明範圍的所有變更和修改。