一種基於k均值樣本預選的支持向量機主動學習方法與流程
2023-12-04 15:07:51 3
本發明屬於機器學習中的主動學習
技術領域:
,尤其涉及一種基於k均值樣本預選的支持向量機主動學習方法。
背景技術:
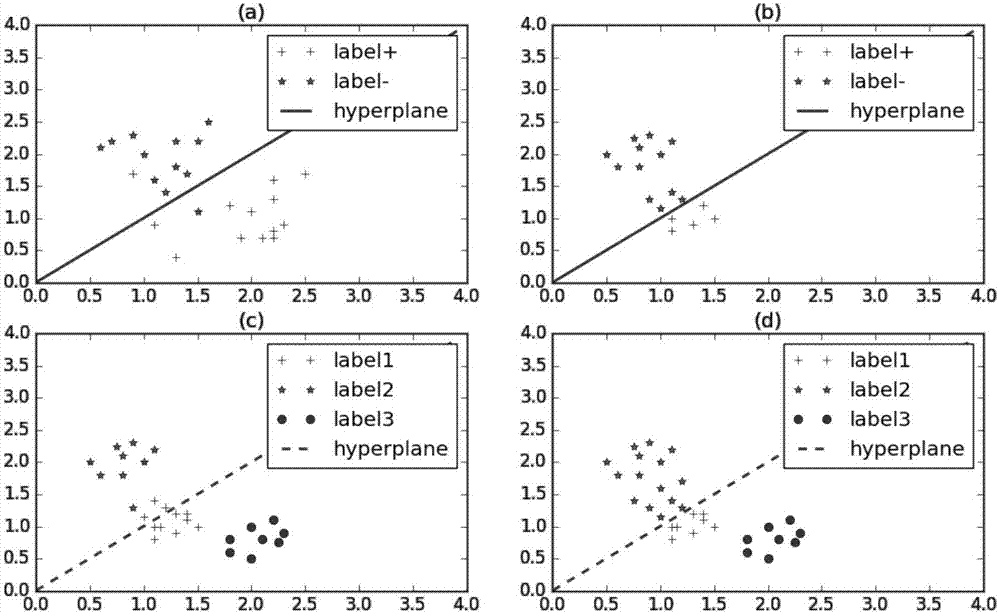
:在很多複雜的監督學習任務中,標記實例的獲得是困難的、耗時的;比如在語音識別中,獲得對語音表達的正確標註需要花費經驗豐富的語言學家大量的時間和精力;對於詞級的標註所耗費的時間通常是音頻時長的10倍,而音素標註的時間耗費是音頻時長的400倍;在信息提取中,好的信息提取系統必須依賴具有標籤的文本和詳細的相關說明,這也需要耗費大量的時間,並要求領域專家參與以保證信息的準確;此外,諸如郵件的分類和過濾、計算機輔助醫學影像分析等領域,標記實例都是昂貴的、不易獲取的。因此,如何通過對大量未標記數據進行利用來提升學習性能這一理論上重要、現實中能夠發揮效用的問題,受到了機器學習界的高度重視;主動學習和半監督學習是利用未標記實例提升學習性能的兩個重要方法,其中,主動學習也被稱作「查詢學習」(querylearning),作為機器學習的一個分支領域,其重要思想是:如果本發明允許學習算法去選擇它所學習的數據,變得更為「富有好奇心」,那麼算法將會需要更少的訓練並且表現得更好;主動學習的幾個常用方法有:整合成員信息查詢(membershipquerysynthesis)、基於流的選擇抽樣(stream-basedselectivesampling)、基於池的抽樣(pool-basedsampling)等;半監督學習作為機器學習的另一分支,它讓學習器自動地對大量未標記數據進行利用,輔助少量標記數據進行學習。在概念上兩者也存在許多共性的地方值得思考。舉例半監督學習中的自訓練方法(self-training),它首先利用少量的標記實例進行學習,然後將最有把握的未標記實例及其預測標記加入學習器進行迭代;而主動學習中的不確定性抽樣方法(uncertaintysampling),提出選擇學習器最沒把握的未標記實例進行標記查詢。由此可見,主動學習和半監督學習分別著重問題的兩個方面,前者探索未標記實例的未知信息,而後者著重已知的方面。正因為如此,許多學者自然地提出了將主動學習與半監督學習相結合的方法。現有利用未標記實例提高分類器學習性能的方法主要有兩種,其具體缺點如下:(1)主動學習實例選取的缺點主動學習的思想為:如何選擇需要的數據,主動學習並沒有給出完善的解決方案。多數時候,只能應用主動學習的思想而並沒有解決特定問題的具體辦法,需要做到「具體問題,具體分析」。這一方面使得相關技術人員在考慮採用主動學習的思想時,因為得不到規範具體的執行步驟、佐證而畏首畏尾,導致項目設計周期長、效率低。另一方面,主動學習基於經驗的決策方式使得相關決策缺乏完善的理論支持,可信度較低,而為了提升決策可信度,僱傭足夠多的領域專家又會導致決策成本的大幅提高。(2)半監督svm方法的缺點,半監督svm(s3vm)是支持向量機在半監督學習上的推廣,在不考慮未標記樣本時,支持向量機試圖找到最大間隔劃分超平面,而在考慮未標記樣本後,s3vm試圖找到能將兩類樣本分開的,且穿過數據低密度區域的劃分超平面。s3vm方法的問題是計算複雜,具有較多的待定參數,使得該方法的複雜度很高且難以使用,在如今日益增長的數據規模下,算法複雜度高的算法無法應對龐大的數據量及特殊應用所要求的響應速度,具體表現在:半監督svm算法難以遷移到大數據量的應用問題上;對於實時處理、要求響應時間的應用上也難以應用這類複雜度高的算法等。因此,需要更為高效的優化求解策略;同時,傳統的s3vm具有未標記實例降低分類準確率的風險。綜上所述,現有技術存在的問題是:現有利用未標記實例提高分類器學習性能的方法存在只能應用主動學習的思想而並沒有解決特定問題的具體辦法,需要做到「具體問題,具體分析」;算法計算複雜度高,導致算法難以應用在時效性需求較高的應用上。技術實現要素:針對現有技術存在的問題,本發明提供了一種基於k均值樣本預選的支持向量機主動學習方法。本發明是這樣實現的,一種基於k均值樣本預選的支持向量機主動學習方法,所述基於k均值樣本預選的支持向量機主動學習方法包括以下步驟:步驟一,利用k均值聚類算法進行樣本預選,基於距離選擇出少部分靠近聚類中心、較為密集、「重要」的樣本來代替整個樣本集進行常規支持向量機的訓練;步驟二,依據數據預選的結果,在未標記實例集中對重要樣本集l*中的每個實例進行查詢,將查詢得到的類標返回;得到未標記實例集中的部分「重要」實例並獲取標記,來代替全部未標記實例;步驟三,利用樣本預選結果,重要樣本集l*作為支持向量機主動學習的訓練集,結合傳統的svm方法進行模型訓練,得到最終的學習模型。進一步,所述k均值聚類算法包括:給定樣本集d={x1,x2,;;;,xm},「k均值」算法針對聚類所得簇劃分c={c1,c2,;;;,ck}最小化平方誤差:其中,x是簇ci的均值向量;生成的聚類個數k=2。進一步,所述學習模型驗證的方法包括:算法1;activesvm;輸入:樣本集u、groundtrue輸出:最佳分類超平面(ω,b)得到當前p下的l*利用l*訓練支持向量機模型m*本發明的另一目的在於提供一種所述基於k均值樣本預選的支持向量機主動學習方法的基於k均值樣本預選的支持向量機主動學習系統,所述基於k均值樣本預選的支持向量機主動學習系統包括:樣本預選模塊,用於利用k均值聚類算法進行樣本預選,基於距離選擇出少部分靠近聚類中心、較為密集、「重要」的樣本來代替整個樣本集進行常規支持向量機的訓練;標記查詢模塊,用於依據數據預選的結果,在未標記實例集中對重要樣本集l*中的每個實例進行查詢,將查詢得到的類標返回;svm模型生成模塊,用於利用樣本預選結果,重要樣本集l*作為支持向量機主動學習的訓練集,結合傳統的svm方法進行模型訓練,得到最終的學習模型。本發明的另一目的在於提供一種利用所述基於k均值樣本預選的支持向量機主動學習方法的基於距離聚類的樣本預選方法,所述基於距離聚類的樣本預選方法利用基於距離的聚類算法獲得整合成員變量的主動學習方法所需的假設空間,得到重要樣本集進行類標查詢、svm模型生成。本發明的另一目的在於提供一種利用所述基於k均值樣本預選的支持向量機主動學習方法的基於密度聚類的樣本預選方法,所述基於密度聚類的樣本預選方法鄰近區域的密度、對象或數據點的數目超過某個閾值,繼續聚類;對給定類中的每個數據點,在一個給定範圍的區域內必須至少包含某個數目的點。本發明的另一目的在於提供一種利用所述基於k均值樣本預選的支持向量機主動學習方法的基於網格聚類的樣本預選方法,所述基於網格聚類的樣本預選方法把對象空間量化為有限數目的單元,形成一個網格結構;所有的聚類操作都在這個網格結構上進行。本發明的另一目的在於提供一種利用所述基於k均值樣本預選的支持向量機主動學習方法的基於約束聚類的樣本預選方法,所述基於約束聚類的樣本預選方法對個體對象的約束或對聚類參數的約束,均來自相關領域的經驗知識;結合特定實例及特定領域,定製出適合特定問題的聚類方法進行樣本預選。本發明的優點及積極效果為:解決傳統分類問題,保證算法精確度及效率的基礎上,降低分類器對於標記實例的需求,從而降低成本。屬於機器學習中的主動學習領域,利用k均值聚類算法進行樣本預選,選擇出少部分較為「重要」的樣本來代替整個樣本集進行常規支持向量機(supportvectormachine)的訓練。在很多複雜的監督學習任務中,標記實例的獲得是困難的、耗時的。與傳統的svm方法相比,本發明在保證分類正確率的前提下,降低了分類器對於標記實例的需求,降低了解決分類問題的成本;與半監督svm方法相比,本發明具有較強的抗噪能力,並且擁有更好的分類穩定性與精確度;與傳統的主動學習方法相比,本發明提出了一種適用範圍廣的實例選取範式。傳統的主動學習方法對如何選擇需要的數據,並沒有給出完善的解決方案。而本發明公布的基於聚類的樣本預選技術,利用整合成員變量的方法,為主動學習方法提供了一套基於聚類假設的解決方案範式;使得主動學習中的樣本類標查詢有據可依,且適用範圍廣。本發明公布的基於樣本預選的svm模型生成技術,在保證了svm模型分類精確度的基礎上,大大降低了分類器對類標的需求。實驗證明了本發明的可行性,其分類準確性高於同類svm方法,高精確性、穩定性,也是現有svm模型生成方法所不具備的。附圖說明圖1是本發明實施例提供的基於k均值樣本預選的支持向量機主動學習方法的流程示意圖。圖2是本發明實施例提供的人造數據集算法特點說明示意圖。圖3是本發明實施例提供的實驗對比情況(2)示意圖。具體實施方式為了使本發明的目的、技術方案及優點更加清楚明白,以下結合實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅僅用以解釋本發明,並不用於限定本發明。下面結合附圖對本發明的應用原理作詳細的描述。如圖1所示,本發明實施例提供的基於k均值樣本預選的支持向量機主動學習方法包括以下步驟:s101:未標記實例集;s102:採用k均值聚類和整合成員變量進行樣本預選;s103:標記查詢;s104:svm模型生成;s105:得到最終結果。本發明採用整合成員信息查詢的主動學習方法,提出了基於k均值樣本預選的支持向量機主動學習算法:即同一聚類中的樣本點可能具有同樣的類別標記,要求決策邊界所穿過的應當是數據點較為稀疏的區域。而在基於距離的聚類算法中,越是靠近聚類的中心,樣本越是相對密集,越是可能反映了該聚類的標記分布信息。由三個模塊組成,包括數據預選模塊、標記查詢模塊及svm模型生成模塊,技術流程如圖1所示。每一個模塊的具體描述如下:樣本預選模塊,利用k均值聚類算法進行樣本預選,基於距離選擇出少部分靠近聚類中心、較為密集、「重要」的樣本來代替整個樣本集進行常規支持向量機的訓練,這種方法剔除了部分噪聲點,在保證分類準確率的基礎上,能夠大量降低分類器對於標記實例的需求。k均值聚類算法給定樣本集d={x1,x2,;;;,xm},「k均值」(k-means)算法針對聚類所得簇劃分c={c1,c2,;;;,ck}最小化平方誤差:其中,x是簇ci的均值向量。可以看出,e越小時,簇內相似度越高。但求e的最小化是np難問題,不易解決。因此,k均值算法採用了貪心策略,通過不斷對均值向量x進行迭代更新,不斷優化近似的求解e的最小化。整合成員變量方法成員信息查詢是主動學習的使用場景之一。主動學習基於一個未知的集合l*進行查詢,l*不是基於某種自然分布,而是來自於一系列有限可計算的假設空間l1,l2,…,他們是樣本集u的子集;基於學習系統的外部環境,對未標記樣本x依據其是否在集合l*內部,決定是否進行查詢,如果x在集合l*內部,則查詢之,反之不查詢;而本發明中組成l*的假設空間,即是聚類假設中的「重要」樣本所組成的樣本空間;樣本預選基於一種聚類假設:即同一聚類中的樣本點可能具有同樣的類別標記;而在k均值聚類中,越是靠近聚類的中心,樣本越是相對密集,越是可能反映了該聚類的標記分布信息,本發明將這一部分樣本稱為「重要」樣本。這時,支持向量機的決策邊界所穿過的應當是數據點較為稀疏的區域。也正是這種聚類假設,整合成員變量查詢的主動學習方法提供了假設空間l(聚類所形成的簇),利用假設空間l,結合l中「重要」佔比p進行整合,即可在樣本集u中預選出l*,稱為「重要」樣本集;由於解決的是二分類問題,算法中令k均值的參數,生成的聚類個數k=2;l中「重要」佔比p並沒有固定的取值範圍,其取值原則是在svm模型生成時,在保證模型準確率的前提下,「重要」佔比p越低,模型的效果越好。(2)標記查詢模塊依據數據預選的結果,在未標記實例集中對重要樣本集l*中的每個實例進行查詢,將查詢得到的類標返回。這一部分旨在得到未標記實例集中的部分「重要」實例並獲取標記,來代替全部未標記實例。從而在保證分類器精度的基礎上,降低分類器對標記實例的需求。(3)svm模型生成模塊利用樣本預選結果,重要樣本集l*作為支持向量機主動學習的訓練集,結合傳統的svm方法進行模型訓練,得到最終的學習模型,該方法結束。為證實該方法的有效性,將生成模型採用如下算法進行驗證:算法1;activesvm;輸入:樣本集u、groundtrue輸出:最佳分類超平面(ω,b)圖2直觀的體現了本發明提出的算法具有以下特點:對於平衡樣本的二分類問題(如圖2a),基於k均值樣本預選的支持向量機主動學習方法能夠同軟間隔支持向量機算法一樣,忽略部分離群點,從而保證分類準確性。此時,用少量的「重要」數據即可代替整個樣本集;對於非平衡樣本的二分類問題,決策邊界可能穿過預選數據(如圖2b),算法依舊可以基於「重要」數據進行有效學習。此時,需要用較多的「重要」數據方可代替整個樣本集;對於平衡樣本集下的多分類問題(如圖2c),該方法並不穩定;此時,需要用較多的「重要」數據方可代替整個樣本集;非平衡樣本集下的多分類問題(如圖2d),由於生成的聚類不確定,因此算法的學習結果是不可預知的;在uci提供的多個基準數據集上,本發明的基於k均值樣本預選的支持向量機主動學習方法(ka-svm),與c-svc、s4vm進行了對比分析,並採用交叉驗證的方法驗證算法性能;表1和表2分別提供了實驗使用的數據集的特徵及算法的初始參數;表1instanceiristaeglasscount150151163dimension4514classification333instanceseedshearttrackscount210270164dimension7137classification332表2algorithmparameterka-svmk=2;p∈(0,1]c-svcnulls4vmkernel=′rbf′;cl=100;c2=0.1;表3實驗對比情況(1)顯示在絕大多數二分類及多分類數據集中,ka-svm比c-svc算法具有更好的分類準確率;在ka-svm算法中,減小p值會顯著的增加分類準確率的方差,使得算法變得不穩定。表3algorithmiristaeglasska-svm(p=0.6)0.855±0.0290.7800±0.0250.5172±0.045ka-svm(p=0.5)0.86±0.0210.8133±0.0220.5342±0.033ka-svm(p=0.4)0.8665±0.0380.7967±0.0190.5086±0.031ka-svm(p=0.3)0.8525±0.0170.8083±0.0310.4758±0.019c-svc0.8375±0.0290.8083±0.0130.5172±0.008algorithmseedshearttrackska-svm(p=0.6)0.8535±0.0170.6231±0.0230.6186±0.011ka-svm(p=0.5)0.8488±0.0220.5851±0.0260.6376±0.031ka-svm(p=0.4)0.8000±0.0190.6120±0.0330.6263±0.028ka-svm(p=0.3)0.6750±0.0160.6064±0.0250.5782±0.032c-svc0.8367±0.0210.6120±0.0110.6372±0.033圖3展示了ka-svm與s4vm分別在heart_scale和tracks兩個二分類數據集上隨著標記數據佔比變大時的分類準確率走勢,c-svc算法將全局樣本集u作為標記數據。實驗對比情況(2)顯示在解決二分類問題、標記數據佔比在50%以上時,ka-svm算法的分類準確率高於s4vm,而當標記數據佔比小於50%時,ka-svm的表現遜色於s4vm,這很可能是因為當標記數據佔比少時,聚類保留的信息大量減少而難以得到最優的分類超平面。以上所述僅為本發明的較佳實施例而已,並不用以限制本發明,凡在本發明的精神和原則之內所作的任何修改、等同替換和改進等,均應包含在本發明的保護範圍之內。當前第1頁12