GPU任務調度方法及系統與流程
2023-12-07 07:26:41 4
本發明涉及處理器技術領域,特別是涉及gpu技術領域,具體為一種gpu任務調度方法及系統。
背景技術:
隨著網際網路用戶的快速增長,數據量的急劇膨脹,數據中心對計算的需求也在迅猛上漲。諸如深度學習在線預測、視頻轉碼以及圖片壓縮解壓縮等各類新型應用的出現對計算的需求已遠遠超出了傳統cpu處理器的能力所及。gpu等有別於cpu的新型處理器的出現為數據中心帶來了巨大的體系結構變革。
傳統的高性能計算集群通過mpi等方式作為主要通信方式,利用隊列系統讓每個任務獨佔式地享用集群中的資源。相對於高性能計算集群中的獨佔式訪問,數據中心需要同時為多個用戶提供服務。因此為了提高數據中心的利用率,用戶往往需要共享數據中心中的計算資源。另外,在實際環境中,不同的用戶會有不同的應用請求服務,且不同的服務請求到達的時間也各不相同,在此情況下,如何有效地解決資源的競爭和共享成為了提高數據中心資源的利用率的關鍵。動態任務調度就是最常見的共享計算資源的解決方案。
對於多任務共享cpu以及cpu的任務調度,研究人員已經進行了大量的研究。而對於gpu,由於其產生之初便是為了高性能計算的獨佔式服務而設計的,因此其原本的硬體架構並不支持多任務共享gpu。gpukernel是一段在gpu上執行的代碼。當調用gpu計算時,需要從cpu端將kernel和對應的輸入參數傳遞到gpu上。kernel可以並發執行,目前,用戶可通過定義可並行的kernelstream來實現kernel的並發執行。stream可理解為一堆異步的操作,同一stream中的操作有嚴格的執行順序,而不同stream之間則沒有該限制。利用不同stream異步執行的特性,就可以通過協調不同stream來提高資源的利用率。從軟體角度來看,不同stream中的不同操作可以並行執行,但在硬體角度卻不一定如此。kernel並行的程度依賴於pcie接口的帶寬以及kernel在每個streamingmultiprocessor(sm)中可獲得的資源,在資源不足的情況下,stream仍然需要等待其他的stream完成執行才能開始執行。因此,多任務共享gpu需要打破現有gpu硬體框架的限制。意識到該問題,學術界和工業界均開始重視起gpu的硬體級共享以及搶佔支持。
cpu上的搶佔式多任務是通過上下文切換實現的,上下文切換引入的額外的延遲和吞吐量損失對於cpu來說是完全可以接收的。而對於gpu來說,由於gpu架構以及相關特性與cpu存在較大的差異,在gpu上實現搶佔式多任務將會引入相對cpu上大得多的額外開銷。僅對於一個sm來說,上下文切換可能會涉及到近256kb大小的寄存器以及48kb的共享內存的內容切換。而目前gpu的性能在很大程度上受到內存帶寬的限制,由於內存請求引入的延遲過大,即使gpu的多線程計算能力也無法完全掩蓋內存延遲所帶來的影響。考慮到內存請求對gpu性能的整體影響,在設計調度算法時也不能忽視調度算法所引起的額外的內存請求。
現有技術中,一種方式是chimera通過將不同的sm劃分給不同的kernel實現多kernel共享一個gpu。另外,chimera針對不同的應用場景提出了以下三種不同的搶佔策略:
1.contextswitching:即通過把一個sm上的正在運行的threadblock(tb)的上下文保存到內存裡,並發射一個新的kernel來搶佔當前sm。
2.draining:暫停發射新的kernel,直到一個正在運行的kernel的所有tb運行結束。
3.flushing:對於具有「冪等性」(idempotent)kernel,即使強制結束當前正在運行的tb,重新啟動後也不會對kernel最後的結果產生影響,因此在上下文切換時可直接將其tb強行中止,且不需要保存任何上下文信息。
三種策略各有優劣,其中contextswitching所引入的額外開銷對於延遲和吞吐量的影響居於另外兩個策略之間;draining對吞吐量的影響最小,但對延遲的影響最大;flushing對延遲幾乎沒有影響,但若是搶佔發生在tb即將運行結束時,則會對吞吐量造成很大的影響。
當有一個新的kernel到達時,chimera會根據三種策略所引入的開銷以及當前正在運行的kernel的狀態,選擇將被搶佔的sm,以及其上運行的tb被搶佔的方式,從而達到以一個較小的開銷實現搶佔的效果。
chimera中採取的三種策略均存在比較嚴重的缺點,如果是通過內存進行切換,就會產生大量的內存訪問,對性能產生影響。如果等待tb結束,則會導致不可預期的搶佔延遲。而「冪等性」則對kernel本身有比較大的要求。
這三種策略的綜合結果是能夠在搶佔發生時,如何根據當前運行環境的狀態,儘量減少搶佔過程所引入的開銷,而對於任務動態到達的場景,chimera沒有提出相對應的調度策略,無法實現全局的吞吐量優化。
現有技術中,還有一種方式是simultaneousmultikernel通過在每個sm增加搶佔機制,實現部分上下文切換(partialcontextswitching)從而能夠對正在運行的kernel進行部分資源的搶佔,使得多個kernel可以共享一個sm的資源。對於多個kernel之間的資源分配,該研究採取的是主導資源公平算法(drf),drf是一種通用的多資源的max-minfairness分配策略。drf的主題思想是在多用戶環境下一個用戶的資源分配應該由用戶的主導份額的資源決定,主導份額的資源指的是在所有已經分配給用戶的多種資源中,佔據最大份額的一種資源。在gpu中總共有四種資源:寄存器、共享內存、線程以及tb。
simultaneousmultikernel提供了讓不同kernel共享gpu的硬體機制,但沒有對共享gpu的kernel進行進一步限制。在數據中心的應用場景下,simultaneousmultikerne研究表明,不同的kernel具有不同的資源利用率。有些kernel幾乎不使用scratchpad內存,而是頻繁的訪問l1緩存。而另一些kernel則正相反。這導致了gpu整體資源利用率的低下。雖然simultaneousmultikernel在硬體上允許kernel之間利用互補的資源,但其並沒有給出調度動態到來的任務使其資源互補的算法。因此,在數據中心的應用場景下,simultaneousmultikernel無法徹底解決資源利用率的問題。
技術實現要素:
鑑於以上所述現有技術的缺點,本發明的目的在於提供一種gpu任務調度方法及系統,用於解決現有技術中gpu任務調度存在的影響內存性能,延遲高以及資源利用率低的問題。
為實現上述目的及他相關目的,本發明在一方面提供一種gpu任務調度系統,所述任務調度系統包括:應用分析模塊,用於接收用戶的應用程式請求,分析應用程式,根據所述應用程式的類型和輸入數據集的大小分析獲取所述應用程式的各個kernel的指令數;動態任務調度模塊,包括:動態檢測單元,用於動態檢測、接收用戶的應用程式請求並將接收的用戶的應用程式請求發送至所述應用分析模塊;數量查詢單元,用於從運行時系統查詢當前運行的kernel數量;處理單元,用於判斷當前運行的kernel數量是否達到預設的上限值,若否,則從被搶佔的kernel以及新到達的kernel中挑選與當前運的kernel組合形成kernel組合優先級最高的kernel並將挑選的kernel發射至運行時系統,若是,則繼續判斷被搶佔的kernel和新到達的kernel中是否存在與當前運行kernel進行組合得到更高優先級的kernel組合,若否,則保持當前運行的kernel狀態,若是,則繼續判斷搶佔程序後的gpu性能提升是否大於搶佔過程所佔用的gpu開銷,若是,則進行搶佔,若否,則保持當前運行的kernel狀態。
於本發明的一實施例中,被搶佔的kernel的優先級高於新到達的kernel的優先級,使得gpu性能越好的kernel組合的優先級越高。
於本發明的一實施例中,通過預設的歸一化ipc衡量gpu性能,歸一化ipc的計算公式為:
其中,norm_ipc表示為歸一化ipc,ipcshare表示為kernel與其他kernel共享gpu時gpu表現出的ipc,ipcalone表示為kernel獨佔gpu時gpu表現出的ipc。
於本發明的一實施例中,搶佔程序後的gpu性能提升根據搶佔前歸一化ipc和搶佔後歸一化ipc的對比獲取,其中:搶佔前歸一化ipc為:
搶佔後歸一化ipc為:
preempt_cycle=(0.09526×miss_rate+0.01633)×(reg+smem)×tb;
其中,normalized_ipci表示為第i個kernel的指令數,running1表示為正在運行的第一個kernel,running2表示正在運行的第二個kernel,rest_cycle表示為正在運行的兩個kernel還能一起運行的時鐘周期數,rest_instrunning1表示為正在運行的第一個kernel剩餘的指令數,ipcrunning1表示為正在運行的第一個kernel所表現出的ipc,rest_instrunning2表示為正在運行的第二個kernel剩餘的指令數,ipcrunning2表示為正在運行的第二個kernel所表現出的ipc,norm_ipci表示為第i個kernel所表現出的歸一化ipc,preempt_cycle表示為搶佔過程所持續的時鐘周期數,miss_rate表示為未被搶佔的kernel發生高速緩存缺失的頻率,reg表示為被搶佔的kernel中每個線程塊佔用寄存器的字節數,smem表示為被搶佔的kernel中每個線程塊佔用共享內存的字節數,tb表示為被搶佔的kernel中線程塊的數量。
於本發明的一實施例中,搶佔過程所佔用的gpu開銷通過搶佔過程中歸一化ipc衡量,所述搶佔過程中歸一化ipc為:
norm_ipcrunning1×decay_rate×preempt_cycle;
其中,norm_ipcrunning1表示為未被搶佔kernel所表現出的歸一化ipc,decay_rate表示為未被搶佔的kernel由於搶佔過程而導致的ipc衰減率,preempt_cycle表示為搶佔過程所持續的時鐘周期數,kernel∈memory_intensive表示為未被搶佔的kernel屬於內存密集型kernel,kernel∈compute_intensive表示為未被搶佔的kernel屬於計算密集型kernel。
實現上述目的,本發明在另外一方面還提供一種晶片,所述晶片為異構多核硬體結構,所述晶片內裝設有如上所述的gpu任務調度系統。
實現上述目的,本發明在另外一方面還提供一種gpu任務調度方法,所述任務調度方法包括:動態檢測並接收用戶的應用程式請求,分析應用程式,根據所述應用程式的類型和輸入數據集的大小分析獲取所述應用程式的各個kernel的指令數;從運行時系統查詢當前運行的kernel數量,並判斷當前運行的kernel數量是否達到預設的上限值,若否,則從被搶佔的kernel以及新到達的kernel中挑選與當前運的kernel組合形成kernel組合優先級最高的kernel並將挑選的kernel發射至運行時系統,若是,則繼續判斷被搶佔的kernel和新到達的kernel中是否存在與當前運行kernel進行組合得到更高優先級的kernel組合,若否,則保持當前運行的kernel狀態,若是,則繼續判斷搶佔程序後的gpu性能提升是否大於搶佔過程所佔用的gpu開銷,若是,則進行搶佔,若否,則保持當前運行的kernel狀態。
於本發明的一實施例中,被搶佔的kernel的優先級高於新到達的kernel的優先級,使得gpu性能越好的kernel組合的優先級越高。
於本發明的一實施例中,通過預設的歸一化ipc衡量gpu性能,歸一化ipc的計算公式為:
其中,norm_ipc表示為歸一化ipc,ipcshare表示為kernel與其他kernel共享gpu時gpu表現出的ipc,ipcalone表示為kernel獨佔gpu時gpu表現出的ipc。
於本發明的一實施例中,搶佔程序後的gpu性能提升根據搶佔前歸一化ipc和搶佔後歸一化ipc的對比獲取,其中:
搶佔前歸一化ipc為:
搶佔後歸一化ipc為:
preempt_cycle=(0.09526×miss_rate+0.01633)×(reg+smem)×tb;
其中,normalized_ipci表示為第i個kernel的指令數,running1表示為正在運行的第一個kernel,running2表示正在運行的第二個kernel,rest_cycle表示為正在運行的兩個kernel還能一起運行的時鐘周期數,rest_instrunning1表示為正在運行的第一個kernel剩餘的指令數,ipcrunning1表示為正在運行的第一個kernel所表現出的ipc,rest_instrunning2表示為正在運行的第二個kernel剩餘的指令數,ipcrunning2表示為正在運行的第二個kernel所表現出的ipc,norm_ipci表示為第i個kernel所表現出的歸一化ipc,preempt_cycle表示為搶佔過程所持續的時鐘周期數,miss_rate表示為未被搶佔的kernel發生高速緩存缺失的頻率,reg表示為被搶佔的kernel中每個線程塊佔用寄存器的字節數,smem表示為被搶佔的kernel中每個線程塊佔用共享內存的字節數,tb表示為被搶佔的kernel中線程塊的數量。
於本發明的一實施例中,搶佔過程所佔用的gpu開銷通過搶佔過程中歸一化ipc衡量,所述搶佔過程中歸一化ipc為:
norm_ipcrunning1×decay_rate×preempt_cycle;
其中,norm_ipcrunning1表示為未被搶佔kernel所表現出的歸一化ipc,decay_rate表示為未被搶佔的kernel由於搶佔過程而導致的ipc衰減率,preempt_cycle表示為搶佔過程所持續的時鐘周期數,kernel∈memory_intensive表示為未被搶佔的kernel屬於內存密集型kernel,kernel∈compute_intensive表示為未被搶佔的kernel屬於計算密集型kernel。
如上所述,本發明的一種gpu任務調度方法及系統,具有以下有益效果:
1、本發明提供了一個高性能的gpu搶佔式任務調度系統,其基於硬體式搶佔機制和高性能任務調度算法,可以在無需升級硬體設備的情況下,應對應用請求動態到達的情況,有效降低延遲,提高資源利用率,提高gpu的性能。
2、本發明的成果可以用於構建具有商業意義的、基於cpu和異構計算晶片gpu的異構數據中心,面向用戶提供程序動態任務調度服務。
3、本發明簡單實用,具有良好的市場前景和廣泛的適用性。
附圖說明
圖1顯示為本發明的一種gpu任務調度方法的流程示意圖。
圖2顯示為本發明的一種gpu任務調度系統的原理框圖。
圖3顯示為本發明與現有的軟體層的關係架構圖。
圖4顯示為本發明的gpu任務調度方法及系統的實施過程示意圖。
元件標號說明
100gpu任務調度系統
110應用分析模塊
120動態任務調度模塊
121動態檢測單元
122數量查詢單元
123處理單元
s101~s108步驟
具體實施方式
以下通過特定的具體實例說明本發明的實施方式,本領域技術人員可由本說明書所揭露的內容輕易地了解本發明的其他優點與功效。本發明還可以通過另外不同的具體實施方式加以實施或應用,本說明書中的各項細節也可以基於不同觀點與應用,在沒有背離本發明的精神下進行各種修飾或改變。
本實施例的目的在於提供一種gpu任務調度方法及系統,用於解決現有技術中gpu任務調度存在的影響內存性能,延遲高以及資源利用率低的問題。以下將詳細闡述本發明的一種gpu任務調度方法及系統的原理及實施方式,使本領域技術人員不需要創造性勞動即可理解本發明的一種gpu任務調度方法及系統。
具體地,本實施例旨在實現一個高性能的gpu搶佔式任務調度,其基於硬體搶佔機制和高性能任務調度算法,分別完成基於gpu的多任務共享以及搶佔和在任務動態到達的情況下動態調度的工作。便於開發人員在無需關心硬體系統以及調度細節的前提下獲得高吞吐和低延遲。
以下對本實施例的gpu任務調度方法及系統進行詳細說明。
如圖1所示,本實施例提供一種gpu任務調度方法,所述任務調度方法包括:
步驟s101,動態檢測並接收用戶的應用程式請求,分析應用程式,根據所述應用程式的類型和輸入數據集的大小分析獲取所述應用程式的各個kernel的指令數。
步驟s102,從運行時系統查詢當前運行的kernel數量。
步驟s103,判斷當前運行的kernel數量是否達到預設的上限值,若否,則執行步驟s104,若是,則執行步驟s105。
步驟s104,從被搶佔的kernel以及新到達的kernel中挑選與當前運的kernel組合形成kernel組合優先級最高的kernel並將挑選的kernel發射至運行時系統。
步驟s105,繼續判斷被搶佔的kernel和新到達的kernel中是否存在與當前運行kernel進行組合得到更高優先級的kernel組合,若否,則執行步驟s106,若是,則執行步驟s107。
步驟s106,保持當前運行的kernel狀態。
步驟s107,繼續判斷搶佔程序後的gpu性能提升是否大於搶佔過程所佔用的gpu開銷,若是,則執行步驟s108,進行搶佔,若否,則返回步驟s106保持當前運行的kernel狀態。
以下對本實施例的gpu任務調度方法進行詳細說明。
根據kernel在運行過程中對不同類型資源的需求程度不同,可將kernel分為內存密集型和計算密集型兩種類型。計算密集型的kernel對計算資源的需求較大,而內存密集型的kernel在運行過程中對內存的訪問表現的比較頻繁。由於兩種類型的kernel對資源的需求表現為互補,因此當兩者共享gpu時,可最大程度的提高資源的利用率,且在最大程度上避免發生資源爭搶。另外,由於gpu的性能在很大程度上被內存帶寬所限制,內存密集型的kernel共享gpu時所表現出的性能結果要差於計算密集型的kernel共享gpu時的性能結果。根據不同組合的kernel所表現出的性能結果,將性能表現更好的kernel組合賦予更高的優先級。該優先級便作為調度過程中進行發射kernel以及實施搶佔的重要依據。另外,出於對延遲的考慮,已經被搶佔的kernel在優先級上要高於新到達的kernel,即在組合優先級相等的情況下,優先會將已經被搶佔過的kernel發射上去。
所以於本實施例中,被搶佔的kernel的優先級高於新到達的kernel的優先級,使得gpu性能越好的kernel組合的優先級越高。
當需要發生搶佔時,除了考慮優先級的影響,還要考慮搶佔過程所引入的額外開銷。於本實施例中,通過預設的歸一化ipc(instructionpercycle,每周期執行指令數)衡量gpu性能,歸一化ipc的計算公式為:
其中,norm_ipc表示為歸一化ipc,ipcshare表示為kernel與其他kernel共享gpu時gpu表現出的ipc,ipcalone表示為kernel獨佔gpu時gpu表現出的ipc。
為了實現吞吐量的最大化,則要儘可能保持各時刻運行分kernel的歸一化ipc之和最大。若被搶佔的kernel或者新到達的kernel與正在運行的kernel能到組合出比當前運行的kernel組合更高優先級的組合,則進一步考慮是否進行搶佔。判斷是否搶佔的邏輯取決於搶佔前和搶佔後的歸一化ipc的對比,即搶佔程序後的gpu性能提升根據搶佔前歸一化ipc和搶佔後歸一化ipc的對比獲取。搶佔前的歸一化ipc取決於當前正在運行的kernel,動態調度模塊可通過向運行時系統層發出請求獲取當前正在運行的kernel的狀態,其中包括各個kernel已經運行的指令數和實際運行的ipc,結合程序分析模塊分析出的各個kernel的總指令數,則可以預測出搶佔前歸一化ipc為:
搶佔後歸一化ipc為:
preempt_cycle=(0.09526×miss_rate+0.01633)×(reg+smem)×tb;
其中,normalized_ipci表示為第i個kernel的指令數,running1表示為正在運行的第一個kernel,running2表示正在運行的第二個kernel,rest_cycle表示為正在運行的兩個kernel還能一起運行的時鐘周期數,rest_instrunning1表示為正在運行的第一個kernel剩餘的指令數,ipcrunning1表示為正在運行的第一個kernel所表現出的ipc,rest_instrunning2表示為正在運行的第二個kernel剩餘的指令數,ipcrunning2表示為正在運行的第二個kernel所表現出的ipc,norm_ipci表示為第i個kernel所表現出的歸一化ipc,preempt_cycle表示為搶佔過程所持續的時鐘周期數,miss_rate表示為未被搶佔的kernel發生高速緩存缺失的頻率,reg表示為被搶佔的kernel中每個線程塊佔用寄存器的字節數,smem表示為被搶佔的kernel中每個線程塊佔用共享內存的字節數,tb表示為被搶佔的kernel中線程塊的數量。
於本實施例中,搶佔過程所佔用的gpu開銷通過搶佔過程中歸一化ipc衡量,所述搶佔過程中歸一化ipc為:
norm_ipcrunning1×decay_rate×preempt_cycle;
其中,norm_ipcrunning1表示為未被搶佔kernel所表現出的歸一化ipc,decay_rate表示為未被搶佔的kernel由於搶佔過程而導致的ipc衰減率,preempt_cycle表示為搶佔過程所持續的時鐘周期數。
搶佔後的歸一化ipc由兩個階段組成,一部分是搶佔過程中的ipc表現,另一部分是搶佔完成後的ipc表現。搶佔發生時,未被搶佔的kernel仍在繼續運行,而被搶佔的kernel需要先將相關的上下文保存到內存中,這其中涉及到大量的內存訪問操作。根據實際測試情況可知,當未被搶佔的kernel屬於內存密集型類型的kernel時,其ipc會減小到原來的83%~97%不等,而計算密集型的kernel基本不受影響,因此根據kernel的類型,decay_rate定義如下:
kernel∈memory_intensive表示為未被搶佔的kernel屬於內存密集型kernel,kernel∈compute_intensive表示為未被搶佔的kernel屬於計算密集型kernel
搶佔過程所佔用的時鐘周期數(cycle)受到兩個因素的影響:第一個因素為被換出的kernel的上下文的大小,其中包括該kernel所佔用的tb,以及每個tb所佔用的寄存器數量和共享內存的大小,這些數量決定了保存完整上下文所需要執行的內存訪問操作的數量,通過統計測試結果可知,搶佔過程所持續的cycle數與所要保存的字節數成正相關,且可通過線性模型對兩者的關係進行擬合;另一個因素是未被換出的kernel執行內存訪問操作的頻繁程度,由於搶佔過程中涉及到較多的內存操作,若未被搶佔的kernel也涉及到較多的內存操作,會更加拖慢搶佔過程,可通過l2cachemiss的頻率來衡量kernel涉及內存操作的頻率,研究過程中發現,搶佔過程cycle數和上下文切換字節數的線性模型的斜率與正在運行的kernel的cachemiss頻率成正相關,且成線性關係。因此搶佔過程的cycle數可大致擬合以下關係式:
preempt_cycle=(0.09526×miss_rate+0.01633)×(reg+smem)×tb。
搶佔過程中歸一化ipc定義為:norm_ipcrunning1×decay_rate×preempt_cycle。
搶佔後的ipc無法精確得知,可通過歷史數據獲取一個經驗值,搶佔後的歸一化ipc定義為:
根據搶佔前歸一化ipc和搶佔後歸一化ipc的對比獲取搶佔程序後的gpu性能提升,即
和
兩者相減。具體地,計算搶佔前歸一化ipc和搶佔後歸一化ipc的差值,獲取搶佔程序後的gpu性能提升。
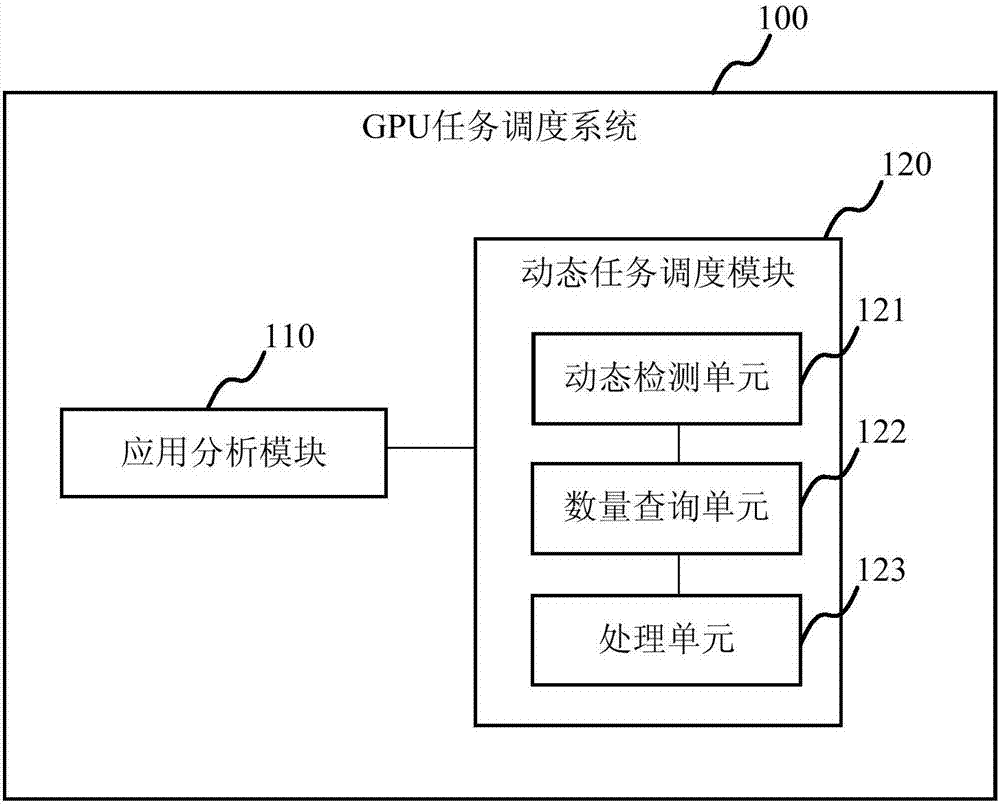
為實現上述gpu任務調度方法,本實施例提供一種gpu任務調度系統100,如圖2所示,所述gpu任務調度系統100包括:應用分析模塊110和動態任務調度模塊120。以下對本實施例中的任務用分析模塊和動態任務調度模塊120進行詳細說明。
如圖3所示,本實施例中gpu任務調度系統100的軟體架構分為三層:應用層、調度層和運行時系統層。其中,應用層主要由用戶應用所組成,用戶遵循一般的gpu編程規則,編寫能在gpu上運行的kernel程序,即可在本發明所提供的軟體架構中運行。所述gpu任務調度系統100運行於調度層,即調度層運行應用分析模塊110和動態任務調度模塊120。運行時系統層是系統的主要組成部分之一,在用戶可執行程序運行時,運行時系統通過調度層的調度結果調度任務或者對正在運行的程序進行搶佔。運行時系統層通過在每個sm增加搶佔機制,實現了部分上下文切換,從而能夠對正在運行的kernel進行部分資源的搶佔,使得多個kernel可以共享一個sm的資源。當運行時系統層接收到調度層發射的新的kernel,運行時系統層優先使用各sm中未被佔用的資源為新kernel分配tb,當資源不足時,需要搶佔部分正在運行的kernel的資源。被換出的tb的上下文被保存到內存中,換出過程結束後,新的kernel的tb被換入,整個上下文切換過程中正在運行的kernel的tb不會被打斷。需要進行搶佔時,被換出的kernel的tb會被全部換出,其上下文同樣被保存到內存中。
其中,1、用戶與應用層的交互包括:a)用戶根據gpu編程規範編寫用戶應用程式;b)
經過本地調試後,確保程序正確。
2、用戶與調度層的交互包括:a)用戶向調度層提交應用請求;b)應用分析模塊110接收用戶請求。
3、用戶與運行時系統層的交互包括:a)運行時系統層向用戶返回運行結果。
4、調度層之間的交互包括:a)應用分析模塊110向動態任務調度模塊120轉移用戶請求;b)應用分析模塊110向動態任務調度模塊120發送應用分析結果。
5、調度層與運行時系統層的交互包括:a)調度層向運行時系統層發送發射應用請求;b)
調度層向運行時系統層發送搶佔請求;c)運行時系統層向調度層發送運行kernel狀態。
具體地,於本實施中,所述應用分析模塊110負責接收用戶的應用請求並分析用戶應用程式,通過機器學習算法,根據所輸入的應用程式類型以及輸入數據集的大小,分析出應用程式的指令數,其輸出信息將作為動態任務調度模塊120的重要參考信息。具體地,所述應用分析模塊110用於接收用戶的應用程式請求,分析應用程式,根據所述應用程式的類型和輸入數據集的大小分析獲取所述應用程式的各個kernel的指令數。
所述動態任務調度模塊120與所述應用分析模塊110是一個有機整體,但各司其職。所述動態任務調度模塊120接收來自用戶和應用分析程序的輸入信息,並根據綜合信息做出調度判斷。所述動態任務調度模塊120的第一個功能是接收用戶的請求。由於用戶的請求是動態到達,因此需要周期性地檢查是否有新的用戶請求到達,新到達的用戶程序需要首先經過應用分析程序的分析,新的應用和其相關的分析結果將一起被發送到所述動態任務調度模塊120;所述動態任務調度模塊120的第二個功能是根據當前正在運行的程序狀態以及新到達的應用的特徵,判斷是否向底層發射新的任務或者對正在運行的程序進行搶佔。
具體地,所述動態任務調度模塊120包括:動態檢測單元121,數量查詢單元122以及處理單元123。所述動態檢測單元121用於動態檢測、接收用戶的應用程式請求並將接收的用戶的應用程式請求發送至所述應用分析模塊110。所述數量查詢單元122用於從運行時系統查詢當前運行的kernel數量。
所述處理單元123用於判斷當前運行的kernel數量是否達到預設的上限值,若否,則從被搶佔的kernel以及新到達的kernel中挑選與當前運的kernel組合形成kernel組合優先級最高的kernel並將挑選的kernel發射至運行時系統,若是,則繼續判斷被搶佔的kernel和新到達的kernel中是否存在與當前運行kernel進行組合得到更高優先級的kernel組合,若否,則保持當前運行的kernel狀態,若是,則繼續判斷搶佔程序後的gpu性能提升是否大於搶佔過程所佔用的gpu開銷,若是,則進行搶佔,若否,則保持當前運行的kernel狀態。
根據kernel在運行過程中對不同類型資源的需求程度不同,可將kernel分為內存密集型和計算密集型兩種類型。計算密集型的kernel對計算資源的需求較大,而內存密集型的kernel在運行過程中對內存的訪問表現的比較頻繁。由於兩種類型的kernel對資源的需求表現為互補,因此當兩者共享gpu時,可最大程度的提高資源的利用率,且在最大程度上避免發生資源爭搶。另外,由於gpu的性能在很大程度上被內存帶寬所限制,內存密集型的kernel共享gpu時所表現出的性能結果要差於計算密集型的kernel共享gpu時的性能結果。根據不同組合的kernel所表現出的性能結果,將性能表現更好的kernel組合賦予更高的優先級。該優先級便作為調度過程中進行發射kernel以及實施搶佔的重要依據。另外,出於對延遲的考慮,已經被搶佔的kernel在優先級上要高於新到達的kernel,即在組合優先級相等的情況下,優先會將已經被搶佔過的kernel發射上去。
所以於本實施例中,被搶佔的kernel的優先級高於新到達的kernel的優先級,使得gpu性能越好的kernel組合的優先級越高。
當需要發生搶佔時,除了考慮優先級的影響,還要考慮搶佔過程所引入的額外開銷。於本實施例中,通過預設的歸一化ipc衡量gpu性能,歸一化ipc的計算公式為:
其中,norm_ipc表示為歸一化ipc,ipcshare表示為kernel與其他kernel共享gpu時gpu表現出的ipc,ipcalone表示為kernel獨佔gpu時gpu表現出的ipc。
為了實現吞吐量的最大化,則要儘可能保持各時刻運行分kernel的歸一化ipc之和最大。若被搶佔的kernel或者新到達的kernel與正在運行的kernel能到組合出比當前運行的kernel組合更高優先級的組合,則進一步考慮是否進行搶佔。判斷是否搶佔的邏輯取決於搶佔前和搶佔後的歸一化ipc的對比,即搶佔程序後的gpu性能提升根據搶佔前歸一化ipc和搶佔後歸一化ipc的對比獲取。搶佔前的歸一化ipc取決於當前正在運行的kernel,動態調度模塊可通過向運行時系統層發出請求獲取當前正在運行的kernel的狀態,其中包括各個kernel已經運行的指令數和實際運行的ipc,結合程序分析模塊分析出的各個kernel的總指令數,則可以預測出搶佔前歸一化ipc為:
搶佔後歸一化ipc為:
preempt_cycle=(0.09526×miss_rate+0.01633)×(reg+smem)×tb;
其中,normalized_ipci表示為第i個kernel的指令數,running1表示為正在運行的第一個kernel,running2表示正在運行的第二個kernel,rest_cycle表示為正在運行的兩個kernel還能一起運行的時鐘周期數,rest_instrunning1表示為正在運行的第一個kernel剩餘的指令數,ipcrunning1表示為正在運行的第一個kernel所表現出的ipc,rest_instrunning2表示為正在運行的第二個kernel剩餘的指令數,ipcrunning2表示為正在運行的第二個kernel所表現出的ipc,norm_ipci表示為第i個kernel所表現出的歸一化ipc,preempt_cycle表示為搶佔過程所持續的時鐘周期數,miss_rate表示為未被搶佔的kernel發生高速緩存缺失的頻率,reg表示為被搶佔的kernel中每個線程塊佔用寄存器的字節數,smem表示為被搶佔的kernel中每個線程塊佔用共享內存的字節數,tb表示為被搶佔的kernel中線程塊的數量。
於本實施例中,搶佔過程所佔用的gpu開銷通過搶佔過程中歸一化ipc衡量,所述搶佔過程中歸一化ipc為:
norm_ipcrunning1×decay_rate×preempt_cycle;
其中,norm_ipcrunning1表示為未被搶佔kernel所表現出的歸一化ipc,decay_rate表示為未被搶佔的kernel由於搶佔過程而導致的ipc衰減率,preempt_cycle表示為搶佔過程所持續的時鐘周期數,kernel∈memory_intensive表示為未被搶佔的kernel屬於內存密集型kernel,kernel∈compute_intensive表示為未被搶佔的kernel屬於計算密集型kernel。
搶佔後的歸一化ipc由兩個階段組成,一部分是搶佔過程中的ipc表現,另一部分是搶佔完成後的ipc表現。搶佔發生時,未被搶佔的kernel仍在繼續運行,而被搶佔的kernel需要先將相關的上下文保存到內存中,這其中涉及到大量的內存訪問操作。根據實際測試情況可知,當未被搶佔的kernel屬於內存密集型類型的kernel時,其ipc會減小到原來的83%~97%不等,而計算密集型的kernel基本不受影響,因此根據kernel的類型,decay_rate定義如下:
kernel∈memory_intensive表示為未被搶佔的kernel屬於內存密集型kernel,kernel∈compute_intensive表示為未被搶佔的kernel屬於計算密集型kernel。
搶佔過程所佔用的時鐘周期數受到兩個因素的影響:第一個因素為被換出的kernel的上下文的大小,其中包括該所佔用的tb,以及每個tb所佔用的寄存器數量和共享內存的大小,這些數量決定了保存完整上下文所需要執行的內存訪問操作的數量,通過統計測試結果可知,搶佔過程所持續的cycle數與所要保存的字節數成正相關,且可通過線性模型對兩者的關係進行擬合;另一個因素是未被換出的kernel執行內存訪問操作的頻繁程度,由於搶佔過程中涉及到較多的內存操作,若未被搶佔的kernel也涉及到較多的內存操作,會更加拖慢搶佔過程,可通過l2cachemiss的頻率來衡量kernel涉及內存操作的頻率,研究過程中發現,搶佔過程cycle數和上下文切換字節數的線性模型的斜率與正在運行的kernel的cachemiss頻率成正相關,且成線性關係。因此搶佔過程的cycle數可大致擬合以下關係式:
preempt_cycle=(0.09526×miss_rate+0.01633)×(reg+smem)×tb。
搶佔過程中歸一化ipc定義為:norm_ipcrunning1×decay_rate×preempt_cycle。
搶佔後的ipc無法精確得知,可通過歷史數據獲取一個經驗值,搶佔後的歸一化ipc定義為:
根據搶佔前歸一化ipc和搶佔後歸一化ipc的對比獲取搶佔程序後的gpu性能提升,即具體地,計算搶佔前歸一化ipc和搶佔後歸一化ipc的差值,獲取搶佔程序後的gpu性能提升。
此外,本實施例還提供一種晶片,所述晶片為異構多核硬體結構,所述晶片內裝設有如上所述的gpu任務調度系統1001。上述已經對所述gpu任務調度系統1001進行了詳細說明,在此不再贅述。
為使本領域技術人員進一步理解本實施例中的gpu任務調度系統100和方法,如圖4所示,以下以具體實例說明本實施例中gpu任務調度系統100和方法的實施過程。
於本實施例中,底層硬體是一個基於numa(nonuniformmemoryaccessarchitecture,非統一內存訪問)內存系統的異構多核架構。
1、用戶編寫應用程式:屬於應用層,用戶按照gpu編程規範,編寫能在gpu上運行的kernel程序。
2、用戶提交應用請求:用戶將應用提交給調度層。
3、應用分析模塊110分析應用:應用分析模塊110接收到用戶提交的請求,分析用戶提交的應用,判斷應用所屬的類型以及估計應用的指令數。
4、提交應交到動態任務調度模塊120:應用分析模塊110將應用以及相關的分析數據提交到動態任務調度模塊120。
5、查看當前運行kernel狀態:動態調度模塊向運行時系統層查詢當前運行的kernel數量。
6、若未達到運行數量上限,則從被搶佔的kernel以及新到達的knew中挑選與當前運行kernel組合優先級最高的kpreempted並進行發射。
7、若已達到運行數量上限,則判斷是否需要進行搶佔。判斷被搶佔的kernel以及新到達的knew中是否存在與當前運行kernel進行組合得到更高優先級的kernel。
8、若存在更優的組合,則判斷搶佔後的性能提升能否掩蓋搶佔的開銷。
9.、若能掩蓋,則進行搶佔。
綜上所述,本發明提供了一個高性能的gpu搶佔式任務調度系統,其基於硬體式搶佔機制和高性能任務調度算法,可以在無需升級硬體設備的情況下,應對應用請求動態到達的情況,有效降低延遲,提高資源利用率,提高gpu的性能;本發明的成果可以用於構建具有商業意義的、基於cpu和異構計算晶片gpu的異構數據中心,面向用戶提供程序動態任務調度服務;本發明簡單實用,具有良好的市場前景和廣泛的適用性。所以,本發明有效克服了現有技術中的種種缺點而具高度產業利用價值。
上述實施例僅例示性說明本發明的原理及功效,而非用於限制本發明。任何熟悉此技術的人士皆可在不違背本發明的精神及範疇下,對上述實施例進行修飾或改變。因此,舉凡所屬技術領域中具有通常知識者在未脫離本發明所揭示的精神與技術思想下所完成的一切等效修飾或改變,仍應由本發明的權利要求所涵蓋。