基於在線識別組裝設備對象協議庫的數據採集方法與流程
2023-12-11 19:09:52 8
本發明涉及工業數據採集技術領域,特別涉及一種基於在線識別組裝設備對象協議庫的數據採集方法。
背景技術:
隨著中國製造2025、網際網路+以及工業4.0在全球的鋪開,智能化已勢不可擋,而工業數據的實時獲取對智能化發展的影響極為重大。因此,在這種智能化的大環境下,工業數據的實施獲取變得尤為重要,從環境監測到道路橋梁,從工廠生產到數據檢驗,都離不開工業數據的獲取,這些工業數據與工業物聯網的建設以及工業數據的採集是密不可分的。
由於工業數據的採集具有多樣化、複雜化的特點,不同的生產廠家生產出的生產設備、通訊接口以及通訊協議各不相同,在實際應用中具有較為嚴重的缺陷:一是,由於軟體系統以及設備通訊協議的不一致,在實際應用過程中,需要將分標準通訊協議轉換為標準通訊協議,這就造成了系統通訊連接以及數據交換的成本增大,而且從設備安裝實施到數據採集,整個過程複雜。二是,由於企業中一般存在不同領域的知識斷層,導致工業數據採集系統不能被充分的使用,存在嚴重的資源浪費現象。
技術實現要素:
本發明的目的在於提供一種基於在線識別組裝設備對象協議庫的數據採集方法,以解決現有的工業數據採集過程複雜的問題。
為實現以上目的,本發明採用的技術方案為:提供一種在線識別組裝設備對象協議放入數據採集方法,該方法包括:
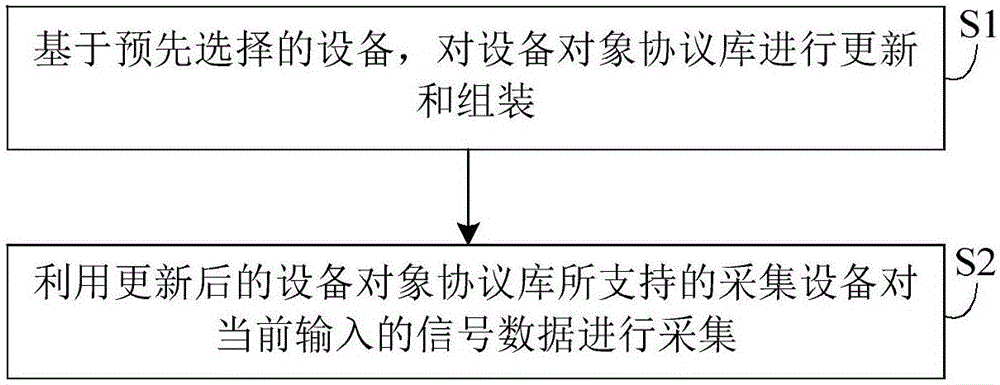
基於預先選擇的設備,對設備對象協議庫進行更新和組裝;
利用更新後的設備對象協議庫所支持的採集設備對當前輸入的信號數據進行採集。
與現有技術相比,本發明存在以下技術效果:通過對當前採集設備的身份進行識別,在採集設備的身份識別成功時,採集設備將獲取的設備對象協議庫更新到本地庫,並利用設備對象協議庫中所支持的採集設備對傳入的工業數據進行採集,減少了現場實施可配置的複雜度,大幅度的降低了行業用戶採集工業數據的成本。
附圖說明
圖1是本發明一實施例中的基於在線識別組裝設備對象協議庫的數據採集方法的流程示意圖;
圖2是本發明一實施例中的步驟S1的細分步驟的流程示意圖;
圖3是本發明一實施例中的步驟S2的細分步驟的流程示意圖;
圖4是本發明一實施例中的設備對象協議庫在線更新組裝的原理圖。
具體實施方式
下面結合圖1至圖4所示,對本發明做進一步詳細敘述。
如圖1所示,本實施例公開了一種基於在線識別設備對象協議庫的數據採集方法,該方法包括如下步驟S1至S2:
S1、基於預先選擇的設備,對設備對象協議庫進行更新和組裝;
S2、利用更新後的設備對象協議庫所支持的採集設備對當前輸入的信號數據進行採集。
具體地,本實施例實際上通過一種數據採集一體化程序對整個工業數據的採集過程進行控制,在實際應用中,通過獲取預先選擇設備的身份識別信息,並對設備的身份識別信息進行驗證,在驗證成功的情況下,該設備會獲取設備對象協議庫並更新到本地庫中,在對工業數據進行採集時。因此,只要是設備對象協議庫所支持的設備都可以對工業數據進行採集,整個採集過程的前提是該設備需要得到設備對象協議庫的在線支持。整個實施過程簡單,降低了設備配置的複雜性。
具體提,如圖2、圖4所示,步驟S1具體包括如下細分步驟S11至S12:
S11、基於預先選擇的設備,對設備對象協議庫進行在線更新;
S12、基於GCI模式,對更新後的設備對象協議庫進行組裝。
需要說明的是,本實施例中要求設備對象協議庫符合GCI模式(Generic Callable Interface,GCI)。
具體地,步驟S11具體包括如下步驟:
獲取預先選擇設備得對象編碼以及訪問協議編碼;
根據設備的對象編碼以及訪問協議編碼,基於預設的算法函數生成採集設備的身份識別碼;
通過設備對象協議庫對設備的身份識別碼進行校驗,並在校驗成功時提供設備獲取設備對象協議庫以更新到本地的權限。
具體地,對設備對象協議庫進行在線更新的過程進行說明如下:
首先獲取選擇設備的對象編碼DID以及訪問協議編碼PID,利用預設的算法函數f(DID,PID)生成該設備的身份證識別碼ID,然後利用設備對象協議庫對設備的身份證識別碼ID進行校驗,在校驗成功時,允許該合法的設備將設備對象協議庫更新到本地庫中。
具體地,步驟S12具體包括如下步驟:
利用GCI模式中的設備對象協議庫組件對類數組和算法組進行封裝以形成統一調用接口;
利用宿主對象回調統一調用接口以實現所述更新後的設備對象協議庫的組裝。
需要說明的是,GCI模式由類屬組、算法組、統一調度接口以及宿主對象四部分組成,由於本實施例中所說的設備對象協議庫的設計符合GCI模式,因此,本實施例利用GCI模式對設備對象協議庫進行在線組裝。
具體地,如圖3所示,步驟S2具體包括如下步驟S21至S23:
S21、對當前輸入的信號數據進行解碼;
S22、基於經驗值瞬間校正法對解碼後數據中的跳變量進行校正;
S23、通過所述預先選擇的設備對校正後的解碼數據進行採集。
需要說明的是,該處的跳變量是指與正常範圍值相比較後發現突變、異常情況的值。而當出現跳變量時需要對跳變量進行校正,以保證信息的完整性和可靠性。因為如果不對跳變量進行處理,直接進行採集,那麼該跳變值將會影響整個數據採集的正確性,如果將該跳變值忽略不進行採集,那麼會影響數據採集的完整性。因此,本實施例中對跳變量進行校正可以保證數據採集的完整性和可靠性。
具體地,步驟S21包括:
判斷輸入的攜帶有數據信號的數據包是否完整;
如果數據包完整,則對完整的數據包進行解碼處理;
如果數據包不完整,則對不完整的數據包進行修正處理。
需要說明的是,這裡的數據包不完整一般包括兩種情況:粘包和斷包。粘包是指兩個數據包粘在一起,斷包是指一個數據包被分成兩個數據包,如果對這兩種數據包進行解碼容易出現數據丟失現象,因此,需要對這兩種情況的數據包進行修正,以保證解碼後得到的數據時完整的。其中,針對粘包現象的修正過程是將兩個粘在一起的數據分離開來,針對斷包現象的修正過程是將同一個數據包斷開的兩部分或者多個部分合併在一起。
具體地,步驟S22具體包括如下步驟:
截取當前跳變量的跳變值以及跳變時間戳;
根據跳變時間戳獲取預定時間段的經驗值;
採用中值權法對經驗值進行處理,得到經驗值得權值;
根據經驗值得權值,基於加權均值法對當前的跳變量進行校正。
其中,對採用經驗值瞬間校正法對跳變量進行處理的具體過程說明如下:
當採集的信號數據出現跳變時,截取此時刻的跳變值Vt和時間戳T,將跳變值Vt與前述的正常範圍值相比較,如果跳變值Vt在該正常範圍內時,則不需要進行校正。如果不在該正常範圍內,則判斷該跳變值Vt需要進行校正。校正的過程如下:
(1)根據時間戳T獲取一組特定時間段的經驗值(T,T–n*To),To指的是向前時間偏移量,n指時間偏移量倍數,即Vn=V(T,T–n*To);
(2)採用中值法獲取加權值,即對經驗值Vn進行排序並獲取中值序號隊列(S1,…,Smid,…,Sn),即可通過算法βi∈(S1,…,Smid,Smid-1,…,Smid-n/2)獲取權值;
(3)採用加權均值法進行計算:Vf=∑(Vi*βi)/∑βi,其中Vi∈(V1,Vn);Vf是校正得到的結果值。
具體地,本實施例公開的方法在步驟S21之前,還包括:
對當前輸入的信號數據進行適配處理,以過濾掉不屬於所述選擇設備採集範疇的信號數據。
需要說明的是,本實施例中的當前輸入的數據進行適配處理,避免對不屬於該設備採集的數據進行採集,以避免浪費資源,降低設備的利用率。
具體地,本實施例中的步驟步驟S23包括:
獲取空閒的資料庫連結以及傳輸通道;
採集設備通過空閒的資料庫連結以及傳輸通道將解碼後的數據存入到本地資料庫和/或上傳至數據匯聚網關。
通過空閒的資料庫連結以及傳輸通道,避免通過忙碌的傳輸通道進行數據傳輸導致數據無法傳輸的現象。
以上顯示和描述了本發明的基本原理、主要特徵和本發明的優點。本行業的技術人員應該了解,本發明不受上述實施例的限制,上述實施例和說明書中描述的只是本發明的原理,在不脫離本發明精神和範圍的前提下本發明還會有各種變化和改進,這些變化和改進都落入要求保護的本發明的範圍內。本發明要求的保護範圍由所附的權利要求書及其等同物界定。