一種語音信息處理方法及系統與流程
2024-01-27 07:38:15 4
本發明涉及語音識別技術領域,尤指一種語音信息處理方法及系統。
背景技術:
隨著通信技術的蓬勃發展,語音識別的應用越來越廣泛,各種網絡通信工具如微信、騰訊qq等通信工具逐步成為大眾交流溝通的主要工具之一。其中,語音消息的操作簡易性、便捷性廣受用戶喜愛。在目前的手機、電腦等智能終端中,可以通過通信工具提供語音輸入、輸出功能。
現有技術中,目前的語音識別的識別方案對於識別開始時間長短沒有做出考慮,識別較短時用戶的等待時間將較長,較長時用戶的語音識別不僅等待時間更加漫長而且識別不完整,嚴重影響用戶的使用需求。而且現有技術是語音錄製結束後,然後將錄音結果發送至語音識別模塊進行語音識別,錄音時間加上識別時間,造成了不必要的等待時間,浪費時間,影響用戶的使用體驗。
技術實現要素:
本發明的目的是提供一種語音信息處理方法及系統,實現語音錄製過程中進行語音識別,減少用戶等待語音錄製完成後。
本發明提供的技術方案如下:
一種語音信息處理方法,包括步驟:s100在用戶錄音過程中周期性採集並識別用戶的語音信息,得到語音識別片段;s200處理所述語音識別片段,得到語音識別結果。
本發明實現語音錄製過程中進行語音識別,減少用戶需要在語音錄製完成後,才能夠進行語音識別並輸出語音結果的等待時間,在不影響正常識別結果的同時縮短錄音時延,提高用戶使用體驗。
進一步的,所述步驟s100包括步驟:s110在用戶錄音過程中,根據所預設採集規則採集用戶的語音信息,獲得當前語音片段;s120根據語音識別庫識別所述當前語音片段,得到語音識別片段;s130獲取下一語音片段並執行步驟s110-130,直至用戶結束錄音;其中,所述預設採集規則為根據時間間隔相等的採集方式。
進一步的,s110還包括步驟:s111判斷所述當前語音片段是否為空白語音片段;若是,執行步驟s112;否則,執行步驟s120;s112刪除所述當前語音片段,並執行步驟s130。
進一步的,所述步驟s200包括步驟:s210按照採集的時間順序,將所述語音識別片段進行排序整合,得到所述語音識別結果。
進一步的,所述步驟s200還包括步驟:s220根據採集的時間順序,輸出所述語音識別片段,得到所述語音識別結果。
本發明還提供一種語音信息處理系統,包括:控制模塊和處理模塊;所述處理模塊與所述控制模塊通信連接;所述控制模塊,在用戶錄音過程中周期性採集並識別用戶的語音信息,得到語音識別片段;所述處理模塊,處理所述控制模塊識別得到的所述語音識別片段,得到語音識別結果。
進一步的,所述控制模塊包括:採集子模塊和識別子模塊;所述採集子模塊與所述識別子模塊通信連接;所述採集子模塊,在用戶錄音過程中,根據預設採集規則採集用戶的語音信息,獲得當前語音片段,發送所述當前語音片段至所述識別子模塊;所述識別子模塊,接收所述採集子模塊發送的所述當前語音片段,根據語音識別庫識別所述當前語音片段,得到語音識別片段;所述採集子模塊還獲取並發送下一語音片段至所述識別子模塊,直至用戶結束錄音;所述識別子模塊還接收所述採集子模塊發送的所述下一語音片段,根據語音識別庫識別所述下一語音片段,得到語音識別片段,直至用戶結束錄音;其中,所述預設採集規則為根據時間間隔相等的採集方式。
進一步的,所述控制模塊還包括:判斷子模塊和刪除子模塊,所述判斷子模塊分別與所述採集子模塊、所述刪除子模塊和所述識別子模塊通信連接;所述判斷子模塊,判斷所述當前語音片段是否為空白語音片段;若是,發送判斷所述當前語音片段為空白語音片段的結果至所述刪除子模塊;否則,發送判斷所述當前語音片段不為空白語音片段的結果至所述識別子模塊;所述刪除子模塊,接收所述判斷子模塊發送的判斷結果,刪除所述當前語音片段。
進一步的,所述處理模塊包括:排序子模塊;所述排序子模塊與所述控制模塊通信連接;所述排序子模塊,按照採集的時間順序,將所述語音識別片段進行排序整合,得到所述語音識別結果。
進一步的,所述處理模塊還包括:輸出子模塊,所述輸出子模塊與所述控制模塊通信連接;所述輸出子模塊,根據採集的時間順序,輸出所述語音識別片段,得到所述語音識別結果
通過本發明提供的一種語音信息處理方法及系統,能夠帶來以下至少一種有益效果:
1、本發明在錄音的過程中,採集錄音獲得的語音片段進行語音識別,相比傳統語音識別方式,處理語音識別結果更快,減少用戶等待語音錄入和語音識別的時間。
2、本發明根據fifo隊列(fifo是firstinputfirstoutput的縮寫,先入先出隊列,這是一種傳統的按序執行方法,先進入的指令先完成並引退,跟著才執行第二條指令。是一種先進先出的數據緩存器)進行獲取語音信息,並通過fifo隊列進行語音識別,對於較長時間的錄音過程不僅可以有效地減少語音錄音和語音識別的等待時間,也可以做出完整的語音識別。
3、本發明實現語音錄製過程中進行語音識別,解決用戶需要在語音錄製完成後,才能夠進行語音識別的問題。
4、本發明在不影響正常識別結果的同時縮短錄音時延,提高用戶使用體驗。
5、本發明能夠刪除無效語音片段,幫助用戶更加快速地進行語音識別。
附圖說明
下面將以明確易懂的方式,結合附圖說明優選實施方式,對一種語音信息處理方法及系統的上述特性、技術特徵、優點及其實現方式予以進一步說明。
圖1是本發明一種語音信息處理方法的一個實施例的流程圖;
圖2是本發明一種語音信息處理方法的另一個實施例的流程圖;
圖3是本發明一種語音信息處理方法的另一個實施例的流程圖;
圖4是本發明一種語音信息處理方法的另一個實施例的流程圖;
圖5是本發明一種語音信息處理系統的一個實施例的結構示意圖;
圖6是本發明一種語音信息處理系統的另一個實施例的結構示意圖;
圖7是本發明一種語音信息處理系統的另一個實施例的結構示意圖;
圖8是本發明一種語音信息處理系統的另一個實施例的結構示意圖;
圖9是本發明一種語音信息處理方法的一個實例的流程圖。
具體實施方式
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對照附圖說明本發明的具體實施方式。顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對於本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖,並獲得其他的實施方式。
為使圖面簡潔,各圖中只示意性地表示出了與本發明相關的部分,它們並不代表其作為產品的實際結構。另外,以使圖面簡潔便於理解,在有些圖中具有相同結構或功能的部件,僅示意性地繪示了其中的一個,或僅標出了其中的一個。在本文中,「一個」不僅表示「僅此一個」,也可以表示「多於一個」的情形。
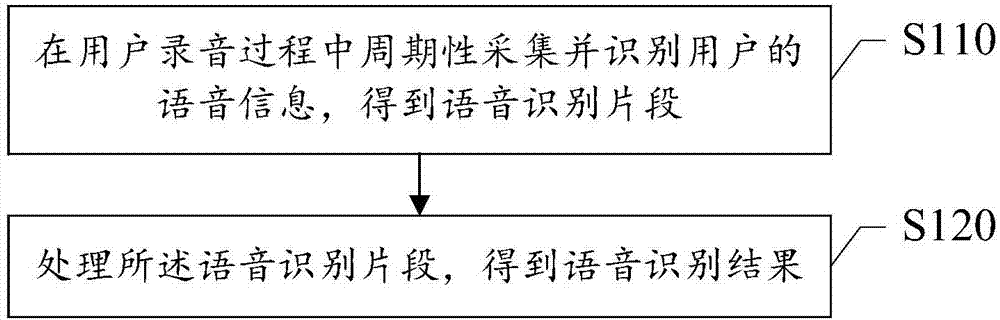
參考圖1所示,本發明提供一種語音信息處理方法的一個實施例,包括:
s110在用戶錄音過程中周期性採集並識別用戶的語音信息,得到語音識別片段;
s120處理所述語音識別片段,得到語音識別結果。
本發明實施例中,實現語音錄製過程中進行語音識別,減少用戶需要在語音錄製完成後,才能夠進行語音識別並輸出語音結果的等待時間,在不影響正常識別結果的同時縮短錄音時延,提高用戶使用體驗。
參考圖2所示,本發明提供一種語音信息處理方法的另一個實施例,包括:
s210在用戶錄音過程中,根據所預設採集規則採集用戶的語音信息,獲得當前語音片段;
s220根據語音識別庫識別所述當前語音片段,得到語音識別片段;
s230獲取下一語音片段並執行步驟s210-230,直至用戶結束錄音;
s240按照採集的時間順序,將所述語音識別片段進行排序整合,得到所述語音識別結果。
其中,所述預設採集規則為根據時間間隔相等的採集方式。
本發明實施例中,具體的語音識別庫的建立,現有技術有很多,在此不細細說明。在錄音的過程中,採集錄音獲得的語音片段進行語音識別,相比傳統語音識別方式,處理語音識別結果更快,減少用戶等待語音錄入和語音識別的時間。根據fifo隊列進行獲取語音信息,並通過fifo隊列進行語音識別,對於較短的錄音,語音識別模塊不需要等到達到語音識別時間開始後才能進行語音識別,避免增加不必要的等待時間,對於較長時間的錄音過程不僅可以有效地減少語音錄音和語音識別的等待時間,也可以做出完整的語音識別。用戶可以根據自己的喜好、需求來設置預設採集規則。避免造成了不必要的等待時間,節約時間提升用戶的使用體驗。根據fifo隊列進行獲取語音信息,並通過fifo隊列進行語音識別,對於較長時間的錄音過程不僅可以有效地減少語音錄音和語音識別的等待時間,也可以做出完整的語音識別。例如,用戶甲設置採集規則為在錄音過程中每1s進行截取語音信息,那麼用戶開始錄音後,根據用戶甲設置的採集規則採集得到第一個1s的語音片段y1,第二個1s的語音片段y2,……第n個1s的語音片段yn,那麼在採集得到該語音片段y1後,通過語音識別模塊進行語音識別,得到語音識別片段s1,得到該語音片段y2後,通過語音識別模塊進行語音識別,得到語音識別片段s2,依次類推,在錄音的過程中,一旦採集獲得相應的語音片段後就能立即進行語音識別得到與之對應的語音識別片段,將語音識別片段保存起來,按照獲取的時間先後順序進行先後順序排列,然後在錄音結束後幾乎是立刻得到完整的語音識別結果,提升語音識別的效率。
本發明實施例中的技術能夠應用在包括室內設備控制,語音對話機器人等方面,通過語音錄製過程中邊錄音邊進行語音識別的功能,解決用戶需要在語音錄製完成後,才能夠進行語音識別的問題,而且在不影響正常識別結果的同時縮短錄音時延,並且用戶的語音命令迅速地轉化為語音識別命令輸入至智能家居設備、智慧機器人,從而更加方便快捷地根據識別得到的語音識別命令控制智能家居設備、智慧機器人,而不需要用戶用手來操作,語音操作相比手動操作更加迅速,提高用戶使用體驗。這樣就避免了例如淘寶等購物平臺,由於語音識別的效率低下而導致用戶偏好於轉接人工服務,提高語音識別的使用率,減少語音服務的資源浪費,減少人工客戶的工作量,減少勞動成本。本發明實施例還能應用於語音檢索系統,例如百度語音搜索是一種全新的搜索模式,用戶可以使用語音說出搜索的意圖,例如說出「明天天氣如何」、「宮保雞丁的做法」等,用戶在說話的過程中,就能邊獲取用戶說話信息便進行語音識別,本發明實施例能立刻得到想要的結果,輸出文字版本的「明天天氣如何」、「宮保雞丁的做法」等語音搜索讓用戶免去打字的繁瑣,使搜索的整個過程更流暢、更便捷。
參考圖3所示,本發明提供一種語音信息處理方法的另一個實施例,包括:
s310在用戶錄音過程中,根據所預設採集規則採集用戶的語音信息,獲得當前語音片段;
s320根據語音識別庫識別所述當前語音片段,得到語音識別片段;
s330根據採集的時間順序,輸出所述語音識別片段,得到所述語音識別結果;
s340獲取下一語音片段並執行步驟s310-330,直至用戶結束錄音。
其中,所述預設採集規則為根據時間間隔相等的採集方式。
本發明實施例,在錄音的過程中,採集錄音獲得的語音片段進行語音識別,處理語音識別快,減少用戶等待時間。根據fifo隊列進行獲取語音信息,並通過fifo隊列進行語音識別,對於較長時間的錄音過程不僅可以有效地減少語音錄音和語音識別的等待時間,也可以做出完整的語音識別。例如一般的語音識別有效時間是30s,假如用戶乙一口氣說話錄音錄製了60s,由於錄製時間過長,不僅導致錄音等待時間過長,而且由於語音信息過長,導致語音識別模塊不能完整地識別出用戶乙的錄音內容。
本發明實施例還能夠應用與語音撥號、語音導航、聽寫數據錄入等領域。例如,聽寫數據錄入過程中,用戶邊說話語音識別模塊就立刻在錄入欄中輸出用戶說話的內容,具體的開始錄音後,根據用戶乙設置的採集規則採集得到第一個0.5s的語音片段x1,第二個0.5s的語音片段x2,……第n個0.5s的語音片段xn,那麼在採集得到該語音片段x1後,通過語音識別模塊進行語音識別,得到語音識別片段b1,依次類推。在錄音的過程中,一旦採集獲得相應的語音片段後就能立即進行語音識別得到與之對應的語音識別片段,根據採集的時間順序,輸出所述語音識別片段,得到所述語音識別結果。如果用戶乙發現錄入欄的文字部分有哪些與自己說話的內容不同的,還可以根據時間順序找出該錯誤識別的部分,進行重新識別。
參考圖4所示,本發明提供一種語音信息處理方法的另一個實施例,包括:
s410在用戶錄音過程中,根據所預設採集規則採集用戶的語音信息,獲得當前語音片段;
s420判斷所述當前語音片段是否為空白語音片段;若是,執行步驟s430;否則,執行步驟s440;
s430刪除所述當前語音片段,並執行步驟s450;
s440根據語音識別庫識別所述當前語音片段,得到語音識別片段;
s450獲取下一語音片段並執行步驟s410-s450,直至用戶結束錄音;
其中,所述預設採集規則為根據時間間隔相等的採集方式。
本發明實施例中,能夠刪除無效語音片段,幫助用戶更加快速地進行語音識別。在語音識別之前的預處理過程中,根據用戶的說話過程中聲波變化頻率和聲波變化波動等技術可以識別出用戶語音信息哪些部分為有效語音部分,哪些是無效語音部分,標記用戶空白語音的時間點,並去掉無效語音部分信息即空白語音片段。例如假設用戶丙根據2s的採集規則進行截取用戶語音信息,還假設用戶丙說話開始的時間點為14:30,用戶在14:33-14:36時間段沒有說話,即檢測到出現3s的靜音。那麼根據本發明實施例採集規則,14:33-14:35這個截取的語音片段是空白的語音片段,將這個語音片段進行標記,此時,可以認為該初始語音信息無效,語音識別模塊可以不對其進行語音識別
本實施例通過將語音識別技術可以減少按鍵輸入,增強與用戶的交互性;通過採用先進先出隊列,實現了多路話筒共用一個語音識別引擎,提高引擎利用率。
參考圖5所示,本發明提供一種語音信息處理系統1000的一個實施例,包括:控制模塊和處理模塊;所述處理模塊與所述控制模塊通信連接;
所述控制模塊,在用戶錄音過程中周期性採集並識別用戶的語音信息,得到語音識別片段;
所述處理模塊,處理所述控制模塊識別得到的所述語音識別片段,得到語音識別結果。
本發明實施例中,實現語音錄製過程中進行語音識別,減少用戶需要在語音錄製完成後,才能夠進行語音識別並輸出語音結果的等待時間,在不影響正常識別結果的同時縮短錄音時延,提高用戶使用體驗。
參考圖6所示,與上一個實施例相同的部分在此不再贅述。本發明提供一種語音信息處理系統1000的另一個實施例,包括:所述控制模塊包括:採集子模塊和識別子模塊;所述採集子模塊與所述識別子模塊通信連接;所述處理模塊包括:排序子模塊;所述排序子模塊與所述控制模塊通信連接;
所述採集子模塊,在用戶錄音過程中,根據預設採集規則採集用戶的語音信息,獲得當前語音片段,發送所述當前語音片段至所述識別子模塊;
所述識別子模塊,接收所述採集子模塊發送的所述當前語音片段,根據語音識別庫識別所述當前語音片段,得到語音識別片段;
所述採集子模塊還獲取並發送下一語音片段至所述識別子模塊,直至用戶結束錄音;
所述識別子模塊還接收所述採集子模塊發送的所述下一語音片段,根據語音識別庫識別所述下一語音片段,得到語音識別片段,直至用戶結束錄音;
所述排序子模塊,按照採集的時間順序,將所述語音識別片段進行排序整合,得到所述語音識別結果;
其中,所述預設採集規則為根據時間間隔相等的採集方式。
本發明實施例中,具體的語音識別庫的建立,現有技術有很多,在此不細細說明。在錄音的過程中,採集錄音獲得的語音片段進行語音識別,相比傳統語音識別方式,處理語音識別結果更快,減少用戶等待語音錄入和語音識別的時間。根據fifo隊列進行獲取語音信息,並通過fifo隊列進行語音識別,對於較長時間的錄音過程不僅可以有效地減少語音錄音和語音識別的等待時間,也可以做出完整的語音識別。用戶可以根據自己的喜好、需求來設置預設採集規則。避免造成了不必要的等待時間,節約時間提升用戶的使用體驗。根據fifo隊列進行獲取語音信息,並通過fifo隊列進行語音識別,對於較長時間的錄音過程不僅可以有效地減少語音錄音和語音識別的等待時間,也可以做出完整的語音識別。本發明實施例中的技術能夠應用在包括室內設備控制,語音對話機器人等方面,通過語音錄製過程中邊錄音邊進行語音識別的功能,解決用戶需要在語音錄製完成後,才能夠進行語音識別的問題,而且在不影響正常識別結果的同時縮短錄音時延,並且用戶的語音命令迅速地轉化為語音識別命令輸入至智能家居設備、智慧機器人,從而更加方便快捷地根據識別得到的語音識別命令控制智能家居設備、智慧機器人,而不需要用戶用手來操作,語音操作相比手動操作更加迅速,提高用戶使用體驗。具體例子見對應方法實施例。實現語音錄製過程中進行語音識別,減少用戶需要在語音錄製完成後,才能夠進行語音識別並輸出語音結果的等待時間,在不影響正常識別結果的同時縮短錄音時延,提高用戶使用體驗。
參考圖7所示,與上一個實施例相同的部分在此不再贅述。本發明提供一種語音信息處理系統1000的另一個實施例,包括:所述處理模塊還包括:輸出子模塊,所述輸出子模塊與所述控制模塊通信連接;
所述輸出子模塊,根據採集的時間順序,輸出所述語音識別片段,得到所述語音識別結果。
具體的,本實施例在錄音的過程中,一旦採集獲得相應的語音片段後就能立即進行語音識別得到與之對應的語音識別片段,根據採集的時間順序,輸出所述語音識別片段,得到所述語音識別結果。如果用戶乙發現錄入欄的文字部分有哪些與自己說話的內容不同的,由於採集時間是有規律的,可以根據採集的時間順序找到該語音片段重新進行識別,大大提升用戶使用體驗。實現語音錄製過程中進行語音識別,減少用戶需要在語音錄製完成後,才能夠進行語音識別並輸出語音結果的等待時間,在不影響正常識別結果的同時縮短錄音時延,提高用戶使用體驗。
參考圖8所示,本發明提供一種語音信息處理系統1000的另一個實施例,包括:所述控制模塊包括:採集子模塊、識別子模塊、判斷子模塊和刪除子模塊;所述判斷子模塊分別與所述採集子模塊、所述刪除子模塊和所述識別子模塊通信連接;
所述採集子模塊,在用戶錄音過程中,根據預設採集規則採集用戶的語音信息,獲得當前語音片段,發送所述當前語音片段至所述判斷子模塊;
所述判斷子模塊,判斷所述當前語音片段是否為空白語音片段;若是,發送判斷所述當前語音片段為空白語音片段的結果至所述刪除子模塊;否則,發送判斷所述當前語音片段不為空白語音片段的結果至所述識別子模塊;
所述刪除子模塊,接收所述判斷子模塊發送的判斷結果,刪除所述當前語音片段;
所述識別子模塊,接收所述採集子模塊發送的所述當前語音片段,根據語音識別庫識別所述當前語音片段,得到語音識別片段;
所述採集子模塊還獲取並發送下一語音片段至所述判斷子模塊,直至用戶結束錄音;
所述識別子模塊還接收所述採集子模塊發送的所述下一語音片段,根據語音識別庫識別所述下一語音片段,得到語音識別片段,直至用戶結束錄音。
本發明實施例中,能夠刪除無效語音片段,幫助用戶更加快速地進行語音識別。在語音識別之前的預處理過程中,根據用戶的說話過程中聲波變化頻率和聲波變化波動等技術可以識別出用戶語音信息哪些部分為有效語音部分,哪些是無效語音部分,並去掉無效語音部分信息即空白語音片段。實現語音錄製過程中進行語音識別,減少用戶需要在語音錄製完成後,才能夠進行語音識別並輸出語音結果的等待時間,在不影響正常識別結果的同時縮短錄音時延,提高用戶使用體驗。
參考圖9所示,本發明提供一種語音信息處理方法的一個實例,包括:
1、錄音開始。
2、錄音模塊保持錄音過程中,2s/次進行依次截取。
3、截取文件。
4、將錄音結果發送至語音識別模塊進行語音聽寫。
5、將語音聽寫結果放入fifo隊列中。
6、語義識別模塊不斷對隊列中的語句進行語義識別,語義分析,理解語句。
7、根據語義識別結果,發送相應指令或回答結果,從而完成整套語音識別。
本發明實施例中,2s/次進行截取並不是特例,可以根據用戶的喜好和需求進行設置截取的時間頻率。實現語音錄製過程中進行語音識別,減少用戶需要在語音錄製完成後,才能夠進行語音識別並輸出語音結果的等待時間,在不影響正常識別結果的同時縮短錄音時延,提高用戶使用體驗。通過採用fifo先進先出隊列,實現了多路話筒共用一個語音識別引擎,提高引擎利用率。減少對於較短的錄音,語音識別模塊不需要等到達到語音識別時間開始後才能進行語音識別,減少語音識別的等待時間,對於較長時間的錄音過程不僅可以有效地減少語音錄音和語音識別的等待時間,也可以做出完整的語音識別。本方案在錄音時間採用兩秒時間,每兩秒進行一次錄音,然後將錄音結果發送到語音識別模塊進行識別,識別結果後放入fifo隊列中,這樣連續錄音結果都在隊列中,然後在語義識別模塊對拼接語句進行識別,從而達到快速語音識別的效果。實現語音錄製過程中進行語音識別,減少用戶需要在語音錄製完成後,才能夠進行語音識別並輸出語音結果的等待時間,在不影響正常識別結果的同時縮短錄音時延,提高用戶使用體驗。
應當說明的是,上述實施例均可根據需要自由組合。以上所述僅是本發明的優選實施方式,應當指出,對於本技術領域的普通技術人員來說,在不脫離本發明原理的前提下,還可以做出若干改進和潤飾,這些改進和潤飾也應視為本發明的保護範圍。