優化分段清除技術的製作方法
2023-12-02 02:24:56 4
本公開涉及存儲系統,並且更具體地涉及群集的一個或多個存儲系統中的優化分段清除。
背景技術:
存儲系統通常包括可以根據需要向其錄入信息以及從其獲得信息的一個或多個存儲設備,諸如體現為存儲陣列的快快閃記憶體儲設備的固態驅動器(SSD)。存儲系統可以實現高層級模塊(諸如文件系統)以在邏輯上將存儲在陣列的存儲設備上的信息組織為存儲容器,諸如文件或邏輯單元(LUN)。每個存儲容器可以被實現為一組數據結構,諸如為存儲容器存儲數據的數據塊以及描述存儲容器中的數據的元數據塊。例如,元數據可以描述(例如,標識)數據在設備上的存儲位置。另外,元數據可以包含對數據的存儲位置的引用的拷貝(即,多對一),由此在數據的位置改變時需要對引用的每個拷貝進行更新。這顯著有助於寫入放大以及系統複雜度(即,跟蹤將要更新的引用)。
某些類型的SSD(尤其是具有NAND快閃部件的那些SSD)可以包括或者可以不包括內部控制器(即,對於SSD的用戶不可訪問),該內部控制器在以頁面粒度(例如,8Kbyte)的那些部件之間將有效數據從舊的位置移動到新的位置,繼而僅移動到先前擦除的頁面。此後,頁面被存儲的舊的位置被釋放,即,頁面被標記用於刪除(或無效)。通常,頁面以32或更多頁面的塊(即,256KB或更多)被排他地擦除。將有效數據從舊的位置移動到新的位置(即,垃圾收集)有助於系統中的寫入放大。因此,期望儘可能不頻繁地移動有效數據,以便不放大數據被寫入的次數,即,減少寫入放大。
技術實現要素:
本文所述各實施例涉及優化分段清除技術,該優化分段清除技術被配置為有效清除耦合至群集的一個或多個節點的存儲陣列的一個或多個選定部分或分段。在一個或多個節點上執行的存儲輸入/輸出(I/O)棧的文件系統的盤區存儲層在存儲陣列的固態驅動(SSD)上提供數據和元數據的順序存儲。數據(和元數據)可以被組織為由節點提供服務的一個或多個主機可見LUN的任意數目的可變長度盤區。元數據可以包括從LUN的主機可見邏輯塊地址範圍(即,偏移範圍)到盤區鍵值的映射,以及盤區鍵值到盤區在SSD上存儲的位置的映射。盤區鍵值到盤區的位置的映射示例性為組織為哈希表的條目的盤區元數據以及一個或多個節點的存儲器(內核)中存儲的其他元數據數據結構。盤區的位置示例性包括包含最近版本盤區的分段的分段標識符(ID)以及包含該盤區的分段塊的偏移(即,分段偏移)。
在一個實施例中,盤區存儲層保持計數結構(例如,指示分段空閒空間量的空閒分段圖)以及具有關於試探法和策略的信息的其他數據結構,其由分段清除過程示例性用於確定將要清除的分段(即,舊分段)的分段ID。分段清除處理可以使用分段ID掃描內核哈希表和元數據數據結構的條目以找到與分段ID的匹配。注意,條目的盤區元數據(例如,位置)包括對最近版本盤區的引用;因此,舊分段中需要被重定位的任意有效盤區可以被標識並且被拷貝到新分段。
在一個實施例中,分段清除技術的自下而上法被配置為讀取將要清除的分段(即,「舊」分段)的所有塊以定位分段的SSD上存儲的盤區並且檢查盤區元數據以確定盤區是否有效。SSD上存儲的每個盤區是自描述的;即,盤區包括包含描述該盤區的信息(例如,盤區鍵值)的報頭。盤區存儲層的分段清除過程使用每個盤區的盤區鍵值來找到內核哈希表和元數據數據結構的盤區元數據條目,以確定包含最近版本盤區的分段的分段ID。如果條目的分段ID(和其他位置信息)匹配舊分段的分段ID(和其他位置信息),則由盤區鍵值引用的盤區被確定為有效(即,最近版本)並且由分段清除過程拷貝(重定位)到正被寫入的分段(即,「新」分段)。如果條目的分段ID不匹配舊分段的分段ID,則由盤區鍵值引用的盤區不是最近版本(即,被確定為無效)並且可以被複寫。
在一個實施例中,優化分段清除技術的自上而下法排除對舊分段的塊進行讀取來定位盤區,相反檢查內核盤區元數據以確定舊分段的有效盤區。分段清除技術的此方法考慮到舊分段可能曾經具有相對滿的有效盤區,但在清除之前,那些盤區中的某些盤區可能已經被邏輯複寫(即,相同LBA範圍),從而將複寫盤區留作分段上的過期數據。因此,邏輯複寫盤區(即,無效盤區)不需要被拷貝(重定位)。
在一個實施例中,分段清除技術的混合方法被配置為進一步減少舊分段塊的讀取,尤其是共享盤區的壓縮塊。混合方法可以執行合併全條帶讀取操作,尤其是在從丟失或不可訪問SSD中重建丟失塊(數據/元數據)的情況。為此,混合方法使用自上而下法確定舊分段的分段ID,掃描內核哈希表和元數據表的條目以找到與分段ID的匹配,並且標識舊分段中需要被重定位到新分段的有效盤區。重定位列表可以例如由分段清除過程創建,該重定位列表標識舊分段中需要被讀取(和重定位)的有效盤區的塊以及需要在可訪問SSD上被讀取以滿足丟失SSD的丟失塊的重建的任意塊。分段清除過程繼而可以根據將要重定位盤區的塊所需的讀取操作通過SSD位置對塊(盤區)進行排序,繼而i)將一個或多個鄰近位置組合成單個更大讀取操作;以及ii)將任意冗餘位置引用合併到塊,例如重定位在SSD上共享共同塊的兩個有效盤區所需的兩個讀取操作可以被合併到共同塊的一個讀取操作。在對列表排序和合併之後,減少數目的讀取操作可以被確定以重定位塊並且優化分段清除。
優勢在於,自下而上法可以在舊分段(即,將要清除)的SSD具有相對滿(即,超過容量閾值)的有效盤區(塊)時被採用,以利用全條帶讀取操作來減少針對存儲I/O棧的讀取路徑的SSD訪問。相反,在i)SSD不可訪問(即,丟失或故障)時;以及ii)分段的SSD相對空(即,針對有效盤區低於容量閾值)時可以採用自上而下法,因為該自上而下法僅需要讀取舊分段中塊的一部分以訪問那些有效盤區,與讀取分段的所有塊相反。混合方法可以被用於擴展自上而下法以僅包括針對塊重定位和重建所需的全條帶讀取操作,同時還避免自下而上法的任何不必要的讀取操作。注意,在執行全條帶讀取操作之後,混合方法可以使用例如從掃描哈希表獲得的分段偏移從條帶中直接檢索任意有效盤區。
附圖說明
通過參考下面結合附圖所做出的描述,可以更好地理解本文實施例中的上述優點和其他優點,在這些附圖中,相同的附圖標記表示相同的或功能上相似的元件,在附圖中:
圖1是相互連接為群集的多個節點的框圖;
圖2是節點的框圖;
圖3是節點的存儲輸入/輸出(I/O)棧的框圖;
圖4示出了輸入/輸出(I/O)棧的寫入路徑;
圖5示出了輸入/輸出(I/O)棧的讀取路徑;
圖6示出了通過存儲I/O棧的分層文件系統的分段清除;
圖7示出了由分層文件系統執行的RAID條帶;
圖8示出了優化分段清除技術的自下而上法和盤區位置元數據;以及
圖9a示出了優化分段清除技術的自上而下法;以及
圖9b示出了在存儲設備故障期間優化分段清除技術的方法。
具體實施方式
存儲群集
圖1是多個節點200的框圖,這些節點相互連接為群集100並且被配置成提供與存儲設備上信息的組織相關的存儲服務。節點200可以通過群集互連結構110相互連接,並且包括多個功能部件,這些功能部件協作以提供群集100的分布式存儲架構,該分布式存儲架構可以被部署到存儲區域網絡(SAN)中。如本文所描述的,每個節點200的各部件包括硬體和軟體功能,該硬體和軟體功能使得該節點能夠通過計算機網絡130連接到一個或多個主機120、以及通過存儲互連140連接到存儲設備的一個或多個存儲陣列150,從而按照分布式存儲架構提供存儲服務。
每個主機120可以被體現為通用計算機,該通用計算機被配置成按照信息遞送的客戶端/伺服器模型與任意節點200交互。即,客戶端(主機)可以請求節點的服務,並且節點可以通過經由網絡130交換分組的方式返回主機所請求的服務的結果。當主機訪問節點上的形式為存儲容器(諸如文件和目錄)的信息時,該主機可以發出包括基於文件的訪問協議(諸如,傳輸控制協議/網際網路協議(TCP/IP)上的網絡文件系統(NFS)協議)的分組。然而,在一種實施例中,當主機120訪問形式為存儲容器(諸如邏輯單元(LUN))的信息時,該主機120示例性地發出包括基於塊的訪問協議(諸如,在TCP上封裝的小型計算機系統接口(SCSI)協議(iSCSI)和在FC上封裝的SCSI)的分組。注意,任意節點200可以為針對群集100上所存儲的存儲容器的請求提供服務。
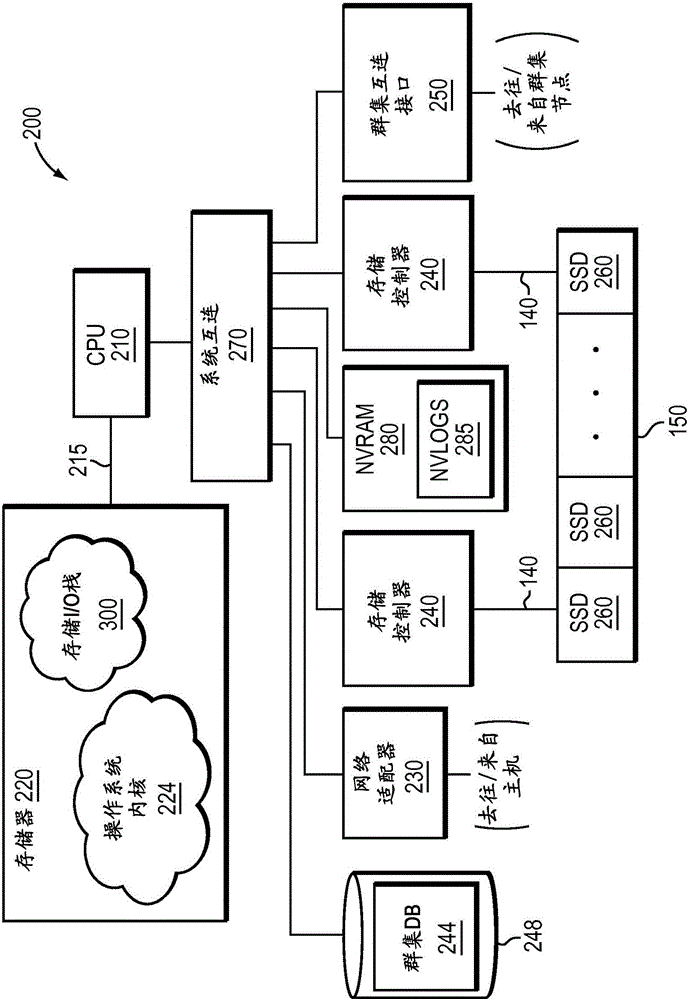
圖2是節點200的框圖,該節點200被示例性地體現為存儲系統,該存儲系統具有經由存儲總線215耦接至存儲器220的一個或多個中央處理單元(CPU)210。CPU 210還經由系統互連270耦接至網絡適配器230、存儲控制器240、群集互連接口250和非易失性隨機訪問存儲器(NVRAM 280)。網絡適配器230可以包括被適配成通過計算機網絡130將節點200耦接至主機120的一個或多個埠,計算機網絡130可以包括點對點鏈路、廣域網、通過公共網絡(網際網路)或區域網實現的虛擬專用網絡。因此,網絡適配器230包括需要將節點連接至網絡130的機械的、電氣的和信令電路,該網絡130示例性地體現了乙太網或光纖通道(FC)網絡。
存儲器220可以包括CPU 210可尋址的存儲器位置,該存儲器位置用於存儲軟體程序以及與本文所描述的實施例相關聯的數據結構。CPU 210則可以包括處理元件和/或邏輯電路,該處理元件和/或邏輯電路被配置成執行軟體程序(諸如,存儲輸入/輸出(I/O)棧300)以及操作數據結構。示例性地,存儲輸入/輸出(I/O)棧300可以被實現為一組用戶模式進程,該用戶模式進程可以被分解為多個線程。作業系統內核224在功能上尤其是通過調用受節點(尤其是存儲器I/O棧300)所實現的存儲服務支持的操作來組織節點,作業系統內核224的一部分通常保留在存儲器220(內核)並且由處理元件(即,CPU 210)執行。合適的作業系統內核224可以包括通用作業系統(諸如,作業系統的系列或Microsoft系列),或者具有可配置功能的作業系統(諸如,微內核和嵌入式內核)。然而,在本文中的一種實施例中,作業系統內核示例性地為作業系統。本領域技術人員應當理解,包括各種計算機可讀介質的其他處理和存儲器裝置也可以用於存儲並執行與本文的實施例有關的程序指令。
每個存儲控制器240與節點200上執行的存儲I/O棧300協作以獲取主機120所請求的信息。該信息被優選地存儲在存儲設備(諸如,固態磁碟(SSD)260)上,該SSD被示例性地體現為存儲陣列150的快閃記憶體存儲設備。在一種實施例中,儘管本領域技術人員理解其他非易失性、固態電子設備(例如,基於存儲類的存儲器組件的驅動器)可以有利地結合本文所描述的實施例使用,但是快閃記憶體存儲設備也可以是基於NAND的快閃記憶體組件(例如,單層單元(SLC)快閃記憶體、多層單元(MLC)快閃記憶體或三層單元(TLC)快閃記憶體)。因此,存儲設備可以是或可以不是面向塊的(即,作為塊進行訪問)。存儲控制器240包括一個或多個具有I/O接口電路的埠,該I/O接口電路通過存儲互連140耦接至SSD 260,存儲互連140示例性地體現為串行連接SCSI(SAS)拓撲結構。備選地,可以使用其他的點對點I/O互連裝置,諸如,常規串行ATA(SATA)拓撲結構或PCI拓撲結構。系統互連270還可以將節點200耦接至本地服務存儲設備248(諸如,SSD),本地服務存儲設備248被配置成將群集相關的配置信息本地存儲為例如群集資料庫(DB)244,群集資料庫(DB)244可以被複製到群集100中的其他節點200。
群集互連接口250可以包括一個或多個埠,這些埠被適配成將節點200耦接至群集100的其他節點。在一種實施例中,可以使用乙太網作為群集協議和互連結構介質,但是本領域技術人員應當理解,本文所描述的實施例中可以使用其他類型的協議和互連(諸如,無線帶寬)。NVRAM 280可以包括能夠根據節點的故障和群集環境來維護數據的後備電池或其他內建的最後狀態保持能力(例如,非易失性半導體存儲器,諸如,存儲類存儲器)。示例性地,NVRAM 280的一部分可以被配置為一個或多個非易失性日誌(NVLog 285),這些非易失性日誌被配置成臨時地記錄(「記入(log)」)I/O接收自主機120的請求(諸如寫入請求)。
存儲I/O棧
圖3是存儲I/O棧300的框圖,該存儲I/O棧300可以有利地結合本文所描述的一個或更多個實施例使用。存儲I/O棧300包括多個軟體模塊或層,這些軟體模塊或層與節點200的其他功能組件協作以提供群集100的分布式存儲架構。在一種實施例中,分布式存儲架構表示單個存儲容器的抽象化,即,所有關於整個群集100的節點200的存儲陣列150被組織為一個大存儲池。換句話說,該架構整合(consolidate)整個群集(通過群集範圍鍵值可檢索的)的存儲(即,陣列150的SSD 260)以實現LUN的存儲。隨後,可以通過將節點200添加至群集100來縮放(scale)存儲容量和性能。
示例性地,存儲I/O棧300包括管理層310、協議層320、持久層330、卷層340、盤區存儲層350、獨立磁碟冗餘陣列(RAID)層360、存儲層365,以及與消息傳送內核370互連的NVRAM(用於存儲NVLog)層。該消息收發內核370可以提供基於消息(或基於事件)的調度模型(例如,異步調度),基於消息(或基於事件)的調度模型採用消息作為上述層之間交換(即,傳遞)的基本的工作單元。消息收發內核提供了一些合適的消息傳遞機制來在存儲I/O棧300的上述層之間傳送信息,這些消息傳遞機制可以包括:例如,針對節點內通信:i)在線程池上執行的消息傳送;ii)通過存儲I/O棧作為一種操作進行的在單線程上執行的消息傳送;iii)使用進程間通信(IRC)機制的消息傳送,以及例如,針對節點間通信:根據功能傳送實現方式使用遠程過程調用(PRC)機制的消息傳送。備選地,I/O棧可以使用基於線程或基於棧的執行模型來實現。在一種或多種實施例中,消息傳送內核370對來自作業系統內核224的處理資源進行分配以執行消息傳送。每個存儲I/O棧層可以被實現為執行一個或多個線程(例如,在內核或用戶空間中)的一個或多個實例(即,進程),這些實例對上述層之間傳遞的消息進行處理使得消息能夠針對上述層的阻斷或非阻斷操作提供同步化。
在一種實施例中,協議層320可以根據預定義的協議(諸如iSCSI和FCP)通過交換被配置為I/O請求的離散幀或分組的方式經由網絡130與主機120通信。I/O請求(例如,讀取或寫入請求)可以針對LUN,並且可以包括I/O參數(諸如,尤其是LUN標識符(ID)、LUN的邏輯塊地址(LBA)、長度(即,數據量),以及寫數據(在寫入請求的情況下)。協議層320接收I/O請求並且將I/O請求轉發給持久層330,該持久層330將該請求記錄到持久回寫高速緩存380中並且經由協議層320向主機120返回確認通知,該持久回寫高速緩存380示例性地體現為日誌;例如,在一些隨機訪問替換策略,而不只是串行方式的情況下,日誌的內容可以進行隨機替換。在一種實施例中,僅記錄了修改LUN的I/O請求(例如,寫入請求)。注意,可以將I/O請求記錄到接收I/O請求的節點處,或者,在備選實施例中,可以根據功能傳送實現方式將I/O請求記錄在其他節點處。
示例性地,專用日誌可以通過存儲I/O棧300的各個層維護。例如,專用日誌335可以通過持久層330維護以內部等效地記錄I/O請求的I/O參數(即,存儲I/O棧、參數(例如,卷ID、偏移量和長度))。在寫入請求的情況下,持久層330還可以與NVRAM 280協作以實現回寫高速緩存380,該回寫高速緩存380被配置成存儲與寫入請求相關聯的寫數據。在一種實施例中,回寫高速緩存可以被構造為日誌。注意,關於寫入請求的寫數據可以被物理地存儲在高速緩存380中使得日誌335包括對相關聯的寫數據的引用。本領域技術人員應當理解,可以使用數據結構的其他變型來存儲或維護NVRAM中的寫數據,包括使用沒有日誌的數據結構。在一種實施例中,還可以將回寫高速緩存的副本維護在存儲器220中以促進對存儲控制器的直接存儲器訪問。在其他實施例中,可以按照維護數據被存儲在高速緩存與群集之間的相關性的協議在主機120處或接收節點處執行高速緩存。
在一種實施例中,管理層310可以將LUN分成多個卷,每個卷可以被分區成多個區域(例如,根據不相交塊地址範圍進行分配),每個區域具有一個或多個分段,這些分段作為多個帶被存儲在陣列150上。因此,節點200中分布的多個卷可以為單個LUN提供服務,即,LUN內的每個卷為LUN內的、不同的LBA範圍(即,偏移量範圍和長度,以下稱為偏移量範圍)或一組範圍提供服務。因此,該協議層320可以實施卷映射技術來對I/O請求所針對的卷(即,為I/O請求的參數所指示的偏移量範圍提供服務的卷)進行識別。示例性地,群集資料庫244可以被配置成針對多個卷中的每個卷維護一個或多個關聯(例如,鍵值對),例如,LUN ID與卷之間的關聯以及卷與用於管理該卷的節點的節點ID之間的關聯。管理層310還可以與資料庫244協作以創建(或刪除)與LUN相關聯的一個或多個卷(例如,在資料庫244中創建卷ID/LUN鍵值對)。通過使用LUN ID和LBA(或LBA範圍),卷映射技術可以提供卷ID(例如,使用群集資料庫244中的適當關聯)以及將LBA(或LBA範圍)轉化成卷內的偏移量和長度,該卷ID用於識別卷和為該卷提供服務的節點,該卷是所述請求的目的地。具體地,卷ID用於確定卷層實例,該卷層實例管理與LBA或LBA範圍相關聯的卷元數據。如前所述,協議層320可以將I/O請求(即,卷ID,偏移量和長度)傳遞至持久層330,持久層330基於卷ID可以使用功能傳送(例如,節點間)實現方式將I/O請求轉發至群集中的節點上執行的合適的卷層實例。
在一種實施例中,卷層340可以通過以下方式管理卷元數據,例如:維護主機可見容器的狀態(諸如,LUN的範圍),以及對與管理層310協作的LUN執行數據管理功能(諸如,創建快照和克隆)。卷元數據被示例性地體現為LUN地址(即,偏移量)到持久性盤區鍵值的內核映射,持久性盤區鍵值是群集範圍內的存儲容器的盤區鍵值空間內的、與盤區的SSD存儲位置相關聯的唯一的群集範圍內的ID。也就是說,盤區鍵值可以用於檢索位於SSD存儲位置處的盤區中、與該盤區鍵值相關聯的數據。備選地,群集中可以具有多個存儲容器,其中每個容器具有其自身的盤區鍵值空間,例如,在該盤區鍵值空間中管理層310將盤區分布在存儲容器中。盤區是可變長度的數據塊,該數據塊提供位於SSD上的存儲單元並且不需要與任何特定邊界對齊,即,可以是字節對齊。因此,為了維持這樣的對齊,盤區可以是來自多個寫入請求的寫數據的聚集體。示例性地,卷層340可以將所轉發的請求(例如,表徵該請求的信息或參數)以及卷元數據的變化記錄到卷層340所維護的專用日誌345中。隨後,可以按照核查點(例如,同步)操作將卷層日誌345的內容寫入存儲陣列150,所述核查點操作將內核元數據存儲到陣列150上。也就是說,核查點操作(核查點)確保內核所處理的元數據的一致狀態被提交(即,存儲)至存儲陣列150;而日誌條目的引退通過例如在核查點操作之前引退累積的日誌條目的方式來確保卷層日誌345中所累積的條目與提交到存儲陣列150的元數據核查點同步。在一個或多個實施例中,核查點和日誌條目的引退可以是數據驅動的、周期的、或以上二者。
在一種實施例中,盤區存儲層350負責將盤區存儲到SSD 260上(即,在存儲陣列150上),並且(例如,響應於所轉發的寫入請求)將盤區鍵值提供給卷層340。盤區存儲層350還負責(例如,響應於所轉發的讀取請求)使用盤區鍵值檢索數據(例如,現有的盤區)。盤區存儲層350可以負責在對盤區進行存儲之前對該盤區進行解重複和壓縮。盤區存儲層350可以對盤區鍵值到SSD存儲位置(即,陣列150的SSD 260上的偏移量)的內核映射(例如,體現為哈希表)進行維護。盤區存儲層350還可以對條目的專用日誌355進行維護,所述條目累積所請求的「放入」和「刪除」操作(即,從其他層向盤區存儲層350發出的針對盤區的寫入請求和刪除請求),而這些操作會改變內核映射(即,哈希表條目)。隨後,可以根據「模糊」核查點390(即,記錄在一個或多個日誌文件中的具有增量變化的核查點)將內核映射和盤區存儲層日誌355的內容寫入存儲陣列150,其中將所選擇的內核映射(少於總量的內核映射)按照不同的時間間隔(例如,通過大量內核映射的變化驅動、通過日誌355的大小閾值驅動的或定期地驅動)提交到陣列150。注意,一旦所有的已經提交的內核映射包括日誌355中的所累積的條目所記錄的變化時,則可以將這些條目引退。
在一種實施例中,RAID層360可以將存儲陣列150內的SSD 260組織為一個或多個RAID組(例如,SSD集合),該一個或多個RAID組通過在每個RAID組的給定數量的SSD 260上寫入具有冗餘信息(即,關於分條數據的適當的奇偶校驗信息)的數據「條帶」來提高陣列上的盤區存儲的可靠性和完整性。RAID層360還可以例如根據多個連續範圍的寫操作來存儲多個條帶(例如,具有足夠深度的條帶),從而減少了SSD內可能發生的作為上述操作的結果的數據再定位(即,內部快閃記憶體塊管理)。在一種實施例中,存儲層365實現存儲I/O驅動器,該存儲I/O驅動器(諸如,Linux虛擬功能的I/O(VFIO)驅動器)可以通過與作業系統內核224共同操作來直接地與硬體(例如,存儲控制器和群集接口)通信。
寫入路徑
圖4示出了存儲I/O棧300的用於處理I/O請求(例如,SCSI寫入請求410)的I/O(例如,寫入)路徑400。該寫入請求410可以由主機120發出並且針對群集100的存儲陣列150上所存儲的LUN。示例性地,協議層320接收該寫入請求並通過對該請求的欄位(例如,LUN ID、LBA和長度(在413處示出))以及寫數據414進行解碼420(例如,解析和提取)來對該寫入請求進行處理。協議層320還可以使用針對卷映射技術430(如上所述)解碼420的結果422以將寫入請求中的LUN ID和LBA範圍(即,相當於偏移量和長度)轉化為群集100中適當的卷層實例(即,卷ID(卷445)),該適當的卷層實例負責針對LBA範圍來管理卷元數據。在一種備選實施例中,持久層330可以實現上述卷映射技術430。然後,協議層將結果432(例如,卷ID、偏移量、長度(以及寫數據)傳遞給持久層330,持久層330將請求記錄到持久層日誌335中並且將確認信息經由協議層320返回至主機120。持久層330可以將來自一個或多個寫入請求的寫數據414聚集並組織到新盤區610中,並且根據盤區哈希技術450對該新盤區執行哈希計算(即,哈希函數)以生成哈希值472。
然後,持久層330可以將具有所聚集的寫數據的寫入請求(包括,例如卷ID、偏移量和長度)作為參數434傳遞至適當的卷層實例。在一種實施例中,(由持久層接收的)參數434的消息傳遞可以經由功能傳送機制(例如,PRC)重定向至其他節點以用於節點間通信。備選地,參數434的消息傳遞可以經由IPC機制(例如,消息線程)進行以用於節點內通信。
在一種或更多種實施例中,桶(bucket)映射技術476被提供來將哈希值472轉化為適當的盤區存儲層的實例(即,盤區存儲實例470),該適當的盤區存儲層負責存儲新盤區610。注意,桶映射技術可以在存儲I/O棧的位於盤區存儲層上方的任意層中執行。例如,在一種實施例中,桶映射技術可以在持久層330、卷層340、或管理群集範圍內的信息的層(諸如,群集層(未示出))中執行。因此,持久層330、卷層340或群集層可以包括CPU 210執行的計算機可執行指令,以進行用於執行本文所描述的桶映射技術476的操作。然後,持久層330可以將哈希值472和新盤區610傳遞至適當的卷層實例,並且通過盤區存儲放入操作將哈希值472和新盤區610傳遞至適當的盤區存儲實例。盤區哈希技術450可以體現近似一致的哈希函數,以確保任意待寫入的盤區可以具有近似相同的機會進入任意盤區存儲實例470,即,基於可用資源將哈希桶分布到群集100的盤區存儲實例中。因此,桶映射技術476在群集的節點200上提供負載均衡的寫入操作(以及,出於對稱性,讀取操作),同時平衡了群集中的SSD 260的快閃記憶體磨損。
響應於放入操作,盤區存儲實例可以對哈希值472進行處理以執行盤區元數據選擇技術460:(i)從盤區存儲實例470內的一組哈希表(示例性地,內核)中選擇適當的哈希表480(例如,哈希表480a),以及(ii)從哈希值472中提取哈希表索引462以索引所選擇的哈希表,並且針對盤區查找具有盤區鍵值475的表條目,該盤區鍵值475用於識別SSD 260上的存儲位置490。因此,盤區存儲層350包括計算機可執行指令,CPU 210執行這些計算機可執行指令以進行用於實現本文所描述的盤區元數據選擇技術460的操作。如果找到具有匹配盤區鍵值的表條目,則使用盤區鍵值475所映射的SSD位置490來從SSD中檢索出現有的盤區(未示出)。然後,將現有的盤區與新盤區610進行比較以確定它們的數據是否相同。如果數據是相同的,則新盤區610本來存儲在SSD 260上並且存在解重複機會(表示為解重複452)從而沒有必要寫入數據的另一副本。因此,表條目中對於現有盤區的引用計數增大,並且現有盤區的盤區鍵值475被傳遞至適當的卷層實例用於存儲在密集樹元數據結構444(例如,密集樹444a)的條目(表示為卷元數據條目446)中,使得盤區鍵值475與卷445的偏移量範圍440(例如,偏移量範圍440a)相關聯。
然而,如果現有盤區的數據與新盤區610的數據不同,則會發生衝突並且確定性算法被調用來按照需要連續地生成許多映射至同一桶的新候選盤區鍵值(未示出)以提供解重複452或產生尚未在盤區存儲實例中存儲的盤區鍵值。注意,另一哈希表(例如,哈希表480n)可以根據盤區元數據選擇技術460來通過所述新候選盤區鍵值來選出。在不存在解重複機會的情況下(即,尚未存儲該盤區),根據壓縮技術454對新盤區610進行壓縮並且將新盤區610傳遞至RAID層360,RAID層360對新盤區610進行處理用於存儲在SSD 260上的、RAID組466的一個或多個條帶710內。盤區存儲實例可以與RAID層360協作以識別存儲分段650(即,存儲陣列150的一部分)以及SSD 260上、用於存儲新盤區610的分段650內的位置。示例性地,所識別的存儲分段是具有較大的連續空閒空間的分段,該空閒空間具有例如在SSD 260上用於存儲盤區610的位置490。
在一種實施例中,RAID層360繼而跨RAID組466寫入條帶710,示例性地為一個或多個全條帶寫入(full stripe write)458。該RAID層360可以寫入一系列足夠深度的條帶710,以減少在基於快閃記憶體的SSD 260(即,快閃記憶體塊管理)中可能出現的數據重定位。然後,盤區存儲實例(i)將新盤區610的SSD位置490加載到所選擇的哈希表480n(即,根據新的候選盤區鍵值進行選擇的哈希表);(ii)將新盤區鍵值(表示為盤區鍵值475)傳遞至適當的卷層實例用於將該新盤區鍵值存儲到由卷層實例所管理的密集樹444的條目(還表示卷元數據條目446)內;以及(iii)將所選擇的哈希表的盤區元數據的變化記錄到盤區存儲層日誌355中。示例性地,卷層實例選擇跨越卷445的偏移量範圍440a的密集樹444a,偏移量範圍440a包括寫入請求的偏移量範圍。如前所述,卷445(例如,卷的偏移量空間)被分區為多個區域(例如,根據不相交的偏移量範圍進行分配的多個區域);在一種實施例中,每個區域由密集樹444表示。然後,卷層實例將卷元數據條目446插入到密集樹444a中並且將與卷元數據條目相對應的變化記錄到卷層日誌345中。因此,在I/O(寫入)請求被充分地存儲在群集的SSD 260上。
讀取路徑
圖5示出了用於處理I/O請求(例如,SCSI讀取請求510)的存儲I/O棧300的I/O(例如,讀取)路徑500。該讀取請求510可以由主機120發出並且在群集100的節點200的協議層320處接收。示例性地,協議層320通過對該請求的欄位(例如,LUN ID、LBA和長度(在513處示出))進行解碼420(例如,解析和提取)來對該讀取請求進行處理,並且針對卷映射技術430使用所解碼的結果522(例如,LUN ID、偏移量和長度)。也就是說,協議層320可以實現卷映射技術430(上面描述的)以將讀取請求中的LUN ID和LBA的範圍(相當於偏移量和長度)轉化為群集100中的適當的卷層實例(即,卷ID(卷445)),該適當的卷層實例負責針對LBA(即偏移量)範圍來管理卷元數據。協議層然後將結果532傳遞到持久層330,持久層330可以搜索寫入高速緩存380來根據其所高速緩存的數據確定是否可以為一些讀取請求或全部讀取請求提供服務。如果根據所高速緩存的數據不能對整個請求提供服務,則持久層330可以按照功能傳送機制(例如,用於節點間通信的RPC)或IPC機制(例如,用於節點內通信的消息線程)將請求的剩餘部分(包括,卷ID、偏移量和長度)作為參數534傳遞到適當的卷層實例。
卷層實例可以對該讀取請求進行處理以訪問與卷445的區域(例如,偏移量範圍440a)相關聯的密集樹元數據結構444(例如,密集樹444a),卷445的區域包括所請求的偏移量範圍(由參數534指定的)。卷層實例可以進一步地對讀取請求進行處理,以搜索(查找)密集樹444a的一個或多個卷的元數據條目446從而獲得所請求的偏移量範圍內的、與一個或多個盤區610(或盤區的各部分)相關聯的一個或多個盤區鍵值475。在一種實施例中,每個密樹444可以被體現為多級搜索結構,該搜索結構能夠在每一級處重疊偏移量範圍條目。該多級密集樹可以針對同一偏移量具有卷元數據條目446,在這種情況下,較高的級別具有較新的條目並且用來為讀取請求提供服務。密集樹444的頂級示例性地保留在內核中並且頁面高速緩存448可以被用來訪問樹的較低級。如果頂級中不存在所請求的範圍或者其一部分,則可以訪問與下一較低樹級別(未示出)處的索引條目相關聯的元數據頁面。然後,對下一級處的元數據頁面(例如,在頁面高速緩存448中)進行搜索以找到任意重疊的條目。然後,迭代地執行該過程,直到發現一個級的一個或多個卷元數據條目446為止,以確保能夠找到對於整個所請求的讀取範圍的盤區鍵值475。如果整個或部分所請求的讀取範圍不存在元數據條目,則未缺失部分被零填充。
一旦找到,則卷層340對每個盤區鍵值475進行處理以實現例如桶映射技術476,從而將該盤區鍵值轉化為負責存儲所請求的盤區610的適當的盤區存儲實例470。需要注意的是,在一種實施例中,每個盤區鍵值475可以基本上等同於與盤區610相關聯的哈希值472(即,針對盤區進行寫入請求期間所計算的哈希值),使得桶映射技術476和盤區元數據選擇技術460可以用於寫入路徑操作和讀取路徑操作二者。還需要注意的是,可以根據哈希值472推導出盤區鍵值475。然後,該卷層340可以將盤區鍵值475(即,來自先前的針對盤區的寫入請求的哈希值)傳遞(經由盤區存儲獲取操作)至適當的盤區存儲實例470,該盤區存儲實例470實現盤區鍵值至SSD的映射以確定盤區在SSD 226上的位置。
響應於該獲取操作,盤區存儲實例可以對盤區鍵值475(即,哈希值472)進行處理以執行元數據選擇技術460:(i)從盤區存儲實例470內的一組哈希表中選擇適當的哈希表480(例如,哈希表480a),以及(ii)從盤區鍵值475(哈希值472)中提取哈希表索引462以索引到所選擇的哈希表,並且針對盤區610查找具有匹配盤區鍵值475的表條目,該匹配盤區鍵值475用於標識SSD 260上的存儲位置490。也就是說,映射到盤區鍵值475的SSD位置490可以用於從SSD 260(例如,SSD 260b)中檢索現有的盤區(表示為範圍610)。然後,盤區存儲實例與RAID層360協作以訪問在SSD 260b上的盤區並且根據讀取請求來檢索數據內容。示例性地,RAID層360可以根據盤區讀取操作468對盤區進行讀取並且將盤區610傳遞至盤區存儲實例。然後,盤區存儲實例可以根據解壓縮技術456對盤區610進行解壓,然而應本領域技術人員應當理解可以在存儲I/O棧300的任一層來執行解壓。盤區610可以被存儲在存儲器220的緩衝器(未示出)中,並且對該緩衝區的引用可以通過存儲I/O棧的各層被傳回。然後,持久層可以將盤區加載到讀取式高速緩存580(或其他分級機制),並且可以針對讀取請求510的LBA範圍從讀取式高速緩存580中提取適當的讀數據512。此後,協議層320可以創建SCSI讀取響應514(包括讀數據512)並且將該讀取響應返回至主機120。
分層文件系統
本文所述實施例示例性採用了存儲I/O棧的分層文件系統。該分層文件系統包括文件系統的快閃記憶體優選、日誌結構層(即,盤區存儲層),該快閃記憶體優選、日誌結構層被配置為提供群集的SSD 260上的數據和元數據的連續存儲(即,日誌結構布局)。數據可以被組織為由節點提供服務的一個或多個主機可見LUN的任意數目的可變長度盤區。元數據可以包括從LUN的主機可見邏輯塊地址範圍(即,偏移範圍)到盤區鍵值的映射,以及盤區鍵值到盤區在SSD上存儲的位置的映射。示例性地,分層文件系統的卷層與盤區存儲層協作以提供間接層,該間接層通過盤區存儲層促進SSD上盤區的高效日誌結構布局。
在一個實施例中,文件系統的日誌結構層的功能(諸如寫入分配和快閃記憶體設備(即,SSD)管理)由盤區存儲層350執行並管理。寫入分配可以包括收集可變長度盤區,以形成可以被寫入以跨一個或多個RAID組的SSD釋放分段的全條帶。即,文件系統的日誌結構層將盤區寫到最初空閒(即,乾淨)分段作為全條帶,而不是部分條帶。快閃記憶體設備管理可以包括分段清除以創建經由RAID組間接映射到SSD的這種空閒分段。因此,部分RAID條帶寫入被避免,這產生減少的RAID相關寫入放大。
代替依賴於SSD中的垃圾收集,存儲I/O棧可以在盤區存儲層中實現分段清除(即,垃圾收集),以繞開SSD中快閃記憶體轉換層(FTL)功能(包括垃圾收集)的性能影響。換言之,存儲I/O棧允許文件系統的日誌結構層使用分段清除操作為數據布局引擎,以有效代替SSD的FTL功能的實質部分。盤區存儲層因此可以按照分段清除(即,垃圾收集)來處理隨機寫入請求以預測其FTL功能內的快閃記憶體行為。因此,針對存儲I/O棧的寫入放大的日誌結構等效源可以在盤區存儲層合併和管理。另外,文件系統的日誌結構層可以被部分採用以改進存儲陣列的快閃記憶體設備的寫入性能。
注意,SSD的日誌結構布局通過順序寫入盤區以清除分段來實現。因此,由盤區存儲層採用的日誌結構布局(即,順序存儲)固有地支持可變長度盤區,由此允許SSD上的存儲之前盤區的不嚴格壓縮並且不具有來自SSD的明確塊級(即,SSD塊)元數據支持,諸如支持512位元組數據和8位元組元數據(例如,對於包含壓縮數據的末端的另一塊的指針)的520位元組扇區。通常,消費者級別SSD支持為2的冪(例如,512位元組)的扇區,而更昂貴的企業級別SSD可以支持增強大小的扇區(例如,520位元組)。因此,盤區存儲層可以利用較低成本的消費者級別SSD進行操作,同時利用其相伴的無約束壓縮來支持可變長度盤區。
分段清除
圖6示出了通過分層文件系統的分段清除。在一個實施例中,分層文件系統的盤區存儲層350可以將盤區寫到空或空閒區域或「分段」。在再次重寫入該分段之前,盤區存儲層350可以按照分段清除將段進行清除,如圖所示該分段清除可以被體現為分段清除過程。該分段清除過程可以從舊分段650a讀取所有有效盤區610並且將那些有效盤區(即,未被刪除或複寫612的盤區)寫到一個或多個新分段650b-c,由此釋放(即,「清除」)舊分段650a。新盤區繼而可以被順序寫到舊(現在乾淨)分段。分層文件系統可以保持特定量的保留空間(即,空閒分段)以支持分段清除的高效表現。例如,分層文件系統可以如圖所示保持等同於近似7%存儲容量的空閒分段的保留空間。新盤區的順序寫入可以表現為全條帶寫入458,使得對存儲的單個寫入操作跨越RAID組466中的所有SSD。寫數據可以被累積直到最小深度的條帶寫入操作可以被執行。
示例性地,分段清除可以被執行以釋放間接映射到SSD的一個或多個選定分段。如本文所使用的,SSD可以包括多個分段塊620,其中每個塊的大小示例為近似2GB。分段可以包括來自RAID組466中多個SSD的每個SSD的分段塊620a-c。因此,針對具有24個SSD的RAID組,其中22個SSD的等效存儲空間存儲數據(數據SSD)並且2個SSD的等效存儲空間存儲奇偶校驗(奇偶校驗SSD),每個分段可以包括44GB的數據和4GB的奇偶校驗。RAID層可以進一步按照一個或多個RAID實現方式(例如,RAID1、RAID 4、RAID 5和/或RAID 6)來配置RAID組,由此在例如一個或多個SSD故障的情況下提供對SSD的保護。注意,每個分段可以與不同的RAID組相關聯,並且因此可以具有不同的RAID配置,即,每個RAID組可以按照不同的RAID實現方式進行配置。為了釋放或清除選定的分段,分段中包含有效數據的盤區被移動到不同的乾淨分段並且選定的分段(現在乾淨)被釋放用於後續重用。分段清除合併分散的空閒空間以改進寫入有效性,例如,通過減少RAID相關的放大率來改進對條帶的寫入有效性以及通過減少FTL的性能影響來改進對基礎快閃記憶體塊的寫入有效性。一旦分段被清除並指定釋放,數據就可以被順序寫到該分段。由盤區存儲層為寫入分配保持的計數結構(例如,指示分段空閒空間的量的空閒分段映射)可以由分段清除過程採用。注意,選擇乾淨分段以從正被清除的分段接收數據(即,寫入)可以基於該乾淨分段中剩餘的空閒空間的量和/或該乾淨分段被使用的最後時間。還應當注意,來自正被清除的分段的數據的不同部分可以被移動至不同「目標」分段。即,多個相關乾淨分段650b、650c可以從正被清除的分段650a接收數據的不同部分。
示例性地,分段清除可能造成存儲陣列(SSD)中的某種程度的寫入放大。然而,文件系統可以通過向SSD順序寫入盤區作為日誌設備來減少這種寫入放大。例如,假設SSD具有近似2MB的擦除塊大小,通過向空閒分段順序寫入至少2MB的數據(盤區),整個擦除塊可以被複寫並且SSD級的存儲殘片可以被消除(即,減少SSD中的垃圾收集)。然而,SSD通常跨多個快閃記憶體部件和跨多個通道(即,存儲控制器240)分條數據以便實現性能。因此,對空閒(即,乾淨)分段的相對大(例如,2GB)寫入粒度可能對避免SSD級寫入放大(即,覆蓋內部SSD分條)而言是必要的。
具體地,因為SSD中的擦除塊邊界可能是未知的,所以寫入粒度應當足夠大,以便針對大的連續範圍上的盤區的一系列寫入可以複寫SSD上先前寫入的盤區並且有效地覆蓋SSD中的垃圾收集。換言之,這種垃圾收集可以被搶佔,因為新數據在與先前數據相同的範圍上被寫入,使得該新數據完全複寫先前寫入的數據。此方法還避免了新寫入數據消耗保留的空間容量。因此,存儲I/O棧的日誌結構特徵(即,文件系統的日誌結構層)的優勢在於僅利用SSD中最小量的保留空間來減少SSD的寫入放大的能力。該日誌結構特徵將保留空間的快閃記憶體設備管理從SSD有效地「移動」到盤區存儲層,該盤區存儲層使用該保留空間來管理寫入放大。因此,僅存在寫入放大的一個源(即,盤區存儲層)而不是具有寫入放大的兩個源(即,盤區存儲層和SSD FTL,兩者進行相乘)。
寫入分配
在一個實施例中,每個分段可以有多個RAID條帶。每次分段被分配(即,在清除分段之後),該分段內各SSD的塊可以包括一系列RAID條帶。各塊可以位於SSD內的相同或不同偏移。盤區存儲層可以出於清除的目的順序讀取塊並且將所有有效數據重定位到另一分段。此後,經清除的分組的塊620可以被釋放並且可以提出如何構成使用該塊的下一分段的決策。例如,如果SSD從RAID組被移除,則容量的一部分(即,一組塊620)可以從下一分段中省略(即,RAID條帶配置中的改變),以便從多個塊620中構成較窄的一個塊的RAID組,即,使得RAID寬度少一個塊寬度。因此,通過使用分段清除,每次新分段被分配,構成分段的塊620的RAID組就可以被有效創建,即,當新分段被分配時,RAID組就從可用SSD動態創建。通常不需要在新分段中包括存儲陣列150中的所有SSD 260。備選地,來自新引入的SSD的塊620可以被添加至在新分段650被分配時創建的RAID組。
圖7示出了由分層文件系統形成的RAID條帶。注意,寫入分配可以包括收集可變長度盤區以形成跨一個或多個RAID組的SSD的一個或多個條帶。在一個實施例中,RAID層360可以管理用於RAID組466的SSD 260a-n上盤區610的替換的拓撲信息和奇偶校驗計算。為此,RAID層可以與盤區存儲層協作以將盤區組織為RAID組內的條帶710。示例性地,盤區存儲層可以收集盤區610以形成可以被寫到空閒分段650a的一個或多個全條帶710,使得單個條帶寫入操作458可以跨越該RAID組中的所有SSD。盤區存儲層還可以與RAID層協作以將每個條帶710包裝為可變長度盤區610的全條帶。一旦條帶被完成,RAID層可以將盤區的全條帶710作為一組塊620d-f傳遞到存儲I/O棧的存儲層365,用於在SSD 260上存儲。通過向空閒分段寫入全條帶(即,數據和奇偶校驗),分層文件系統避免了奇偶校驗更新的成本並且跨SSD展開任意請求的讀取操作負載。注意,對SSD 260掛起寫入操作的盤區610可以被累加至塊620d,e,該塊作為一個或多個臨時近似寫入操作被寫到SSD(例如,2Gbyte),由此減少了SSD中FTL的性能影響。
在一個實施例中,盤區存儲可以被視為群集的存儲陣列150上存儲的全局盤區池,其中每個盤區可以被保持在盤區存儲實例的RAID組466內。假設一個或多個可變長度(即,小和/或大)盤區被寫入分段。盤區存儲層可以收集可變長度盤區以形成跨RAID組的SSD的一個或多個條帶。雖然每個條帶可以包括多個盤區610並且盤區610可以跨越不止一個條帶710a,b,每個盤區被完整地存儲在一個SSD上。在一個實施例中,條帶可以具有深度16KB並且盤區可以具有大小4KB,但是此後盤區可以被向下壓縮到1KB或2KB或者更小,從而允許可能超過條帶深度(即,塊620g深度)的更大盤區被包裝。因此,條帶可以僅構成盤區的一部分,條帶710的深度(即,構成該條帶的一組塊620d-f)可以獨立於被寫入任意一個SSD的盤區。因為盤區存儲層可以將盤區作為全條帶跨SSD的一個或多個空閒分段寫入,所以與條帶的處理信息相關聯的寫入放大可以被減少。
優化分段清除技術
本文所述各實施例涉及優化分段清除技術,該優化分段清除技術被配置為有效清除耦合至群集的一個或多個節點的存儲陣列的一個或多個選定部分或分段。注意,盤區存儲層350在存儲陣列150的SSD 260上提供數據和元數據的順序存儲。元數據可以包括盤區鍵值到SSD上存儲的盤區的位置的映射,該映射示例性為組織為內核哈希表480的條目的盤區元數據以及一個或多個節點的其他元數據數據結構。例如,58GB的盤區元數據可以被用於描述在10TB可用存儲上存儲的盤區的位置(例如,22個數據SSD和2個奇偶校驗SSD)。這種盤區元數據可以被組織為內核哈希表480,例如,布穀鳥(cuckoo)哈希表。另外,可能存在與沒有被哈希表描述的哈希表自身的元數據(例如,核查點)有關的盤區;這些盤區的位置可以由其他內核元數據數據結構(即,元數據表)的條目描述,並且記錄在SSD上。例如,哈希表的盤區元數據自身體現為頁面並且寫為SSD上的盤區(例如,作為核查點),而哈希表(即,盤區元數據)的變化也在盤區存儲層日誌355中累積並且被寫為SSD上的盤區。
圖8示出了優化分段清除技術的自下而上法和盤區位置元數據。示例性地,哈希表480的每個條目810和元數據表850的每個條目852描述了盤區鍵值到SSD上最近版本的對應盤區的位置490的映射。因此,表中描述的每個盤區是有效盤區(即,使用中)。注意,位置提供了足夠信息用於從SSD檢索(即,讀取)盤區。優化分段清除技術可以被配置為搜索哈希表480的條目810以及元數據表850的條目852以標識將要清除的一個或多個分段內盤區的位置,所述條目存儲了針對哈希表的核查點和日誌的盤區元數據。每個盤區的位置490示例性包括包含最近版本盤區的分段的分段標識符(ID)824。在一個實施例中,最近版本盤區的位置490可以特別包括(i)1位,用於標識包含該盤區的RAID組(即,RAID ID822),(ii)13位,用於標識包含該盤區的分段(即,分段ID824),(iii)5位,用於標識包含該盤區的RAID組內的數據SSD(即,盤ID 826),(iv)21位,用於標識包含該盤區(例如,盤區報頭的第一字節)的一塊分段的偏移(即,分段偏移828),以及(v)8位,標識由該盤區(即,盤區大小829)消耗的若干標準大小塊(例如,512位元組)。
在一個實施例中,盤區存儲層保持計數結構(例如,指示分段空閒空間量的空閒分段圖)以及具有關於試探法和策略的信息的其他數據結構,其由分段清除過程示例性用於確定將要清除的分段(即,舊分段)的分段ID。因此,基於策略(例如,超過空閒空間閾值諸如25%)選擇用於清除的分段並且根據分段清除技術進行清除,示例性為:(i)自下而上法,(ii)自上而下法,或(iii)混合法。示例性地,分段清除技術的選擇可以基於檢查與選定用於清除的分段相關聯的計數結構來確定。
在一個實施例中,分段清除技術的自下而上法被配置為讀取將要清除的分段650(即,「舊」分段)的所有塊以定位分段的SSD上存儲的盤區610並且檢查盤區元數據以確定盤區是否有效。示例性地,分段清除技術可以與RAID層360協作以在舊分段開始起並行進到其結束執行連續全條帶讀取操作。SSD上存儲的每個盤區是自描述的;即,盤區包括包含描述該盤區的信息(例如,由SSD上盤區消耗的盤區鍵值和長度(以字節)(未示出))的盤區報頭860。盤區存儲層的分段清除過程使用每個盤區的盤區鍵值來分別找到(例如,索引)內核哈希表480和元數據表850a-n中對應於針對每個盤區的盤區鍵值的盤區元數據條目810、852,以確定包含最近版本盤區610a的分段的分段ID。注意,盤區元數據選擇技術460可以用於快速找到(即,索引)對應於盤區的哈希表條目810a。如果條目810a中位置490a的分段ID 824a(例如,「1」)匹配舊分段650a的分段ID(例如,「1」),則由盤區鍵值475a引用的盤區被確定為有效(即,最近版本)並且被拷貝(重定位)到正被寫入的分段650b(即,「新」分段)。分段清除過程繼而可以更新哈希表(或元數據表)條目810a中的位置490a以參考盤區610a在新分段650b中的新位置。然而,如果條目的分段ID 824b(例如,「2」)不匹配舊分段650a的分段ID(例如,「1」)(或者不存在針對盤區鍵值的哈希表條目810),則由盤區鍵值475b引用的盤區不是最近版本(即,被確定為無效)並且可以被複寫。注意,匹配位置的任意其他部分(即,RAID ID 822、盤ID 826和分段偏移828)的失敗指示該盤區無效。因此,條目位置的各部分(即,RAID ID、盤ID和分段偏移)可以被匹配到與該盤區相關聯的對應信息,以確定該盤區是否有效。因此,自下而上法被配置為讀取舊分段650a上每個盤區610的盤區報頭860以確定該盤區是否有效(即,數據/元數據處於使用中),並且如果有效,則將該盤區重定位(拷貝)到新分段以保護有效數據/元數據同時合併由無效盤區612(例如,被刪除的盤區)佔用的空間。一旦所有有效數據/元數據被重定位,整個舊分段繼而可以被安全重用。
在一個實施例中,優化分段清除技術的自上而下法排除對舊分段的塊進行讀取來定位盤區,相反檢查內核盤區元數據(即,哈希表和元數據表條目)以確定將要清除的舊分段的有效盤區。分段清除技術的此方法考慮到舊分段可能曾經具有相對滿的有效盤區,但在清除之前,那些盤區中的某些盤區可能已經被邏輯複寫(即,相同LBA範圍),從而將複寫盤區留作分段上的過期數據。因此,邏輯複寫盤區(即,無效盤區)不需要被拷貝(重定位)。因此,針對具有頻繁複寫數據的訪問模式的I/O工作負載,自上而下法可以是高效的,因為其僅讀取和重定位分段中塊的有效盤區。相反,自下而上法從舊分段讀取有效和無效盤區,然後驗證所讀取的盤區是否有效。
圖9a示出了優化分段清除技術的自上而下法。示例性地,分段清除過程掃描內核哈希表480和元數據表820的條目以找到匹配選定用於清除的分段的分段ID的相應條目810a,b和852。注意,條目的盤區元數據(例如,位置490)包括對最近版本盤區的引用;因此,舊分段650a中需要被重定位的任意有效盤區610a可以被標識並且被拷貝到新分段650b。換言之,無效(例如,被刪除)盤區612不被讀取,因為其不需要被重定位。分段清除過程繼而可以更新條目810a的位置490a以參考盤區610a在新分段650b中的新位置。與可以讀取分段中有效(即,使用中)和無效(例如,被刪除)盤區兩者,然後驗證所讀取盤區的有效性的自下而上法不同,自上而下法避免了從分段中讀取無效盤區。即,自下而上法由SSD上的盤區驅動,而自上而下法由與內核哈希表和元數據表中的條目相關聯的有效盤區驅動。通常,自下而上法針對相對滿(即,超過容量閾值)的分段更有效,而自上而下法針對相對空(即,低於容量閾值)的分段更有效。
圖9b示出了在存儲設備故障期間優化分段清除技術的方法。假設響應於RAID組的丟失(例如,故障、不可訪問或者其他原因不可用)SSD 260a,新SSD 260n+1被添加到RAID組並且不可訪問SSD的數據(例如,有效盤區610a和無效盤區612)被重建並且其有效性在存儲在新分段650c之前被驗證。使用自下而上法,RAID組的每個條帶710可以被讀取(經由全條帶讀取操作),並且丟失數據(例如,不可訪問SSD 260a上的有效盤區610a和無效盤區612)可以被重建並且在被寫到新分段650c上對應位置之前被驗證。使用自上而下法,內核哈希表和元數據表可以被掃描,以通過將要清除的分段(包括丟失SSD)的位置搜索有效盤區。此後,僅在掃描中找到的那些盤區(即,有效盤區610a)需要被重建;注意,不需要對丟失SSD上被複寫或刪除的數據(例如,無效盤區612)進行重建。注意,多個數據重建可以在丟失SSD上的多個盤區需要重定位時發生。
在一個實施例中,分段清除技術的混合方法被配置為進一步減少舊分段塊的讀取,尤其是共享盤區的壓縮塊,使得每個塊僅被讀取一次。如先前所述,盤區存儲層採用的日誌結構布局允許在SSD存儲之前盤區的非嚴格壓縮。例如,4KB盤區數據可以被壓縮到2KB盤區,使得SSD上不是全部4KB塊被消耗;相反,另外2KB盤區可以緊鄰(例如,同一4KB塊上)被壓縮的2KB盤區被包裝。但是,如果兩個盤區被單獨讀取,則SSD上的同一塊可能被讀取兩次,即,每個盤區使用分段清除的自上而下法或自下而上法一次。然而,混合方法被配置為避免這種冗餘,因為讀取塊兩次以從共享相同塊的不同盤區重定位信息增加了讀取放大率和寫入放大兩者。為此,混合方法可以被配置為執行合併全條帶讀取操作,尤其是在從丟失或不可訪問SSD中重建丟失塊(數據/元數據)的情況。
因此,混合方法使用自上而下法確定舊分段的分段ID,掃描內核哈希表和元數據表的條目以找到與分段ID的匹配,並且標識舊分段中需要被重定位到新分段的有效盤區。重定位列表可以例如由分段清除過程創建,該重定位列表標識舊分段中需要被讀取(和重定位)的有效盤區的塊以及需要在可訪問(丟失)SSD上被讀取以滿足丟失SSD的丟失塊的重建的任意塊。分段清除過程繼而可以根據將要重定位盤區的塊所需的讀取操作通過SSD位置(例如,通過存儲設備偏移的階梯排序)對塊(盤區)進行排序,繼而i)將一個或多個鄰近位置組合成單個更大讀取操作;以及ii)將任意冗餘位置引用合併到塊,例如重定位在SSD上共享共同塊的兩個有效盤區所需的兩個讀取操作可以被合併到共同塊的一個讀取操作。在對列表排序和合併之後,減少(理想是最小)數目的讀取操作可以被確定以重定位塊並且優化分段清除。
在一個實施例中,存在若干類型(例如,5類)的盤區,其中每類盤區指定內核表類型(即,哈希表或元數據表)來掃描以確定舊分段的盤區是否有效,即,舊分段是否存儲了最近版本的盤區。當將要清除的舊分段的盤區使用自下而上法被找到時,盤區的盤區報頭被讀取以確定盤區的類型,從而在那裡(即,哪種類型的表)查找描述該盤區的元數據(即,位置元數據)。相反,自上而下和混合方法掃描每個內核表。注意,當一次掃描不止一個分段時,內核表可以針對每個正被清除的分段逐條目進行掃描,以搜索所有正被清除的分段中的有效盤區。
優勢在於,自下而上法可以在舊分段(即,將要清除)的SSD具有相對滿(即,超過容量閾值)的有效盤區(塊)時被採用,以利用全條帶讀取操作來減少針對存儲I/O棧的讀取路徑的SSD訪問。注意,分段清除過程與RAID層協作來使用全條帶讀取操作示例性讀取整個舊分段,以將有效盤區從舊分段重定位到正被寫入的新分段。全條帶讀取操作的表現還排除對在重建數據時響應於RAID組的丟失SSD額外讀取操作的需求,例如,丟失SSD的丟失數據可以由RAID層每讀取操作使用一次XOR操作來構建,而不考慮正被讀取盤區的數目。
相反,在i)SSD不可訪問(即,丟失或故障)時;以及ii)分段的SSD相對空(即,針對有效盤區低於容量閾值)時可以採用自上而下法,因為該自上而下法僅需要讀取舊分段中塊的一部分以訪問那些有效盤區,與讀取分段的所有塊相反,由此減少了讀取和寫入放大。與自下而上法不同,自上而下法通常不執行全條帶讀取操作除非重建丟失SSD中的數據。混合方法可以被用於擴展自上而下法以僅包括針對塊重定位和重建所需的全條帶讀取操作,同時還避免自下而上法中實施的無效盤區的任何不必要的讀取操作以及針對自上而下法中實施的重建的冗餘讀取。注意,在執行全條帶讀取操作之後,混合方法可以使用例如從掃描哈希表獲得的分段偏移從條帶中直接檢索任意有效盤區。
前面的描述針對的是具體的實施例,然而,明顯的是,可以對所描述的實施例進行其他變型和修改,這些變型和修改獲得了所述實施例的部分或全部優點。例如,明確預期的是,本文所描述的組件和/或元件可以實施為在有形(非臨時性)的計算機可讀介質(例如,磁碟和/或CD)上進行編碼的軟體,該有形(非臨時性)的計算機可讀介質具有執行在計算機、硬體、固件或上述項的組合的程序指令。因此,本說明書僅意在舉例說明而並非意在對本文的實施例的範圍進行限制。因此,所附權利要求的目的在於覆蓋本文的實施例的真正主旨和範圍之內所有的這些變型和修改。