基於筆跡坐標序列的手寫識別方法與流程
2023-05-24 08:52:46 2
本發明涉及手寫識別領域,尤其涉及一種針對手寫輸入筆跡的時間序列的手寫識別方法。
背景技術:
手寫識別(Hand Writing Recognition)是指在手寫設備上對手寫的有序軌跡進行識別,轉化為有效的文字信息的過程。隨著行動裝置,智能設備的普及,手寫輸入作為人機互動最有效的手段之一,正被越來越大規模的使用。
目前,手寫輸入識別算法類似於手勢識別算法。它針對手寫設備的輸入進行採樣,將手寫軌跡轉換為有序向量集合,然後過濾噪聲,對有序向量集合進行分類。對於英文等字母,由於單個字符較為簡單,識別率較高。而對於漢字等筆跡較為複雜的字符,通過向量集合進行分類的錯誤率仍然較高。另外,K聚類分析,貝葉斯分類,卷積神經網絡等識別算法也在手寫識別領域大規模運用,它們都通過提取手寫文字的結構特徵信息進行文字識別。
然而現有的通過結構特徵信息進行文字識別的算法,會忽略手寫過程中筆跡坐標序列的時間特性,而缺失的時間特性中實際包含有大量的手寫識別特徵。
本發明針對手寫過程中的筆跡坐標的時間序列進行分析,提取出用戶手寫筆跡的時間信息,識別結果貼合用戶手寫速度習慣,提高識別率。本發明採用的方法可以在手寫過程中進行識別,記錄用戶筆跡書寫時間上的特徵,具有反饋學習能力,經過大量訓練後可以形成專屬於個人手寫習慣的識別模型。在實際運用中可以先行採集大量手寫筆跡序列的數據,使得識別更具普適性,識別率更高。
技術實現要素:
發明目的:本發明的目的在於針對現有技術無法充分利用手寫過程中的時間特徵,無法在手寫過程中進行文字識別的不足,提供一種對手寫輸入筆跡坐標的時間序列進行識別的方法。
技術方案:本發明提供了一種對手寫輸入的筆跡坐標序列進行識別的方法。本方法先對手寫輸入設備進行初始化,然後通過產品生產過程中的監督訓練階段完對手寫筆跡的監督訓練,最後在實際使用階段完成對用戶手寫筆跡的識別。
第1步,初始化。根據待識別文字範圍選擇相應的文字編碼方式,根據手寫輸入設備的解析度設置筆跡坐標範圍,並設定手寫輸入設備輸入區域的左下角為原點,手寫輸入設備輸入坐標的區域為從原點向右延伸X個像素、從原點向上延伸Y個像素的矩形區域,同時設定手寫輸入設備的採樣頻率;
文字編碼方式:在使用本方法的設備設計之初就需要根據實際產品需要識別的文字類型決定文字編碼方式。例如,針對英文識別的產品,在設計的時候就已經定下來採用ASCII(American Standard Code for Information Interchange,美國標準信息交換代碼)編碼,對於漢字可以採用GB2312編碼形式,也可以根據實際需要自定義編碼方式。編碼採用二進位格式,對在需要識別範圍內所有文字進行編碼,每個文字擁有一個唯一與之對應的編碼。後面,由遞歸神經網絡對歸一化的筆跡坐標序列進行訓練,得到識別後的文字編碼結果。
採樣時,手寫輸入設備按照設置的採樣頻率採集手寫設備接觸位置的坐標,將所採集到的坐標按照時間順序排列為筆跡坐標的原始時間序列。
第2步,監督訓練過程。監督訓練過程中,產品設計人員預先給出真實的輸入字符,再手寫輸入對應的筆跡,通過比較手寫輸入設備計算出的手寫輸入的文字編碼值和實際輸入文字的編碼之間的編碼間誤差來調整計算參數,在對大量的字符進行監督訓練後,得到識別模型。
監督訓練過程按照步驟201-205依次進行;
步驟201,選定待訓練字符,然後通過手寫輸入設備進行輸入,並對輸入的筆跡按照採樣頻率進行採樣,採樣後得到待訓練字符的筆跡坐標序列;
步驟202,對筆跡坐標序列進行歸一化處理,歸一化處理後將歸一化的筆跡坐標序列輸入至遞歸神經網絡進行訓練;
步驟203,遞歸神經網絡根據筆跡坐標序列的順序對其中的坐標進行遞歸計算,並將計算結果與待訓練字符的編碼值比較,根據損失函數計算出編碼間誤差;
步驟204,將編碼間誤差反饋回遞歸神經網絡中,通過梯度下降函數調節下一個坐標進行遞歸計算時的計算參數,並根據步驟203繼續對下一個坐標進行遞歸計算,直至筆跡坐標序列中的最後一個坐標完成遞歸計算,即通過訓練到對應的待訓練字符的編碼值,本次訓練結束;
步驟205,依次重複步驟201至步驟204,直至完成所選文字編碼方式中字符的監督訓練。考慮到中文文字庫很大,而常用字僅幾千個,一般,僅完成常用漢字的訓練即可滿足日常文字識別的需要。
第3步,實際使用階段。實際使用階段中,不會預先知道真實的輸入字符,而是由用戶判斷識別結果是否正確。若識別錯誤,則先保存本次識別錯誤的筆跡,再通知使用者重新輸入待識別字符,重新進行文字識別;若識別結果正確,則查詢之前是否存儲了識別錯誤的筆跡,若存儲了識別錯誤的筆跡則通過比較手寫輸入設備計算出的手寫輸入的文字編碼值和正確的識別結果所對應的文字的編碼值之間的編碼間誤差來調整計算參數,重新進行訓練;若沒有存儲識別錯誤的筆跡則進清空之前存儲的筆跡坐標序列,輸出本次識別結果。在用戶的使用過程中,根據識別錯誤的筆跡更新識別模型。因為,識別錯誤的筆跡更符合用戶手寫習慣而本次沒識別成功,在獲得正確識別結果後如果用識別錯誤的筆跡調整識別模型,就可以使識別模型更加符合用戶的手寫習慣,從而提高識別的準確性。
實際使用階段具體按照如下步驟進行文字識別:
步驟301,對手寫輸入設備輸入的待識別字符的筆跡按照採樣頻率進行採樣,採樣後得到待訓練字符的筆跡坐標序列;
考慮到手寫輸入時筆跡的停頓,優選在對手寫輸入設備輸入的待識別字符的筆跡進行採樣時設置採樣閾值。若超過採樣閾值而沒有檢測到筆跡輸入則認為本次輸入結束,停止對筆跡坐標進行採樣。
步驟302,對筆跡坐標序列進行歸一化處理,歸一化處理後將歸一化的筆跡坐標序列輸入至遞歸神經網絡進行訓練;
步驟303,遞歸神經網絡根據對筆跡坐標序列的順序對其中的每一個坐標進行遞歸計算,直至完成筆跡坐標序列中的最後一個坐標的遞歸計算,最後一個坐標進行遞歸計算的結果即本次識別得到的待識別字符的字符編碼;
步驟304,顯示本次識別得到的字符編碼所對應的字符,對比本次識別得到的字符編碼所對應的字符與實際輸入的待識別字符,若不同,則表示本次識別結果錯誤,先保存本次識別錯誤的筆跡坐標序列,再重新輸入待識別字符,回到步驟301重新進行文字識別;若相同,則查詢之前是否存儲了識別錯誤的筆跡坐標序列,若存儲了識別錯誤的筆跡坐標序列,則依次進行步驟305至步驟306的計算,若沒有存儲識別錯誤的筆跡坐標序列,則進入步驟307;
步驟305,遞歸神經網絡根據存儲的識別錯誤的筆跡坐標序列的順序對其中的坐標進行遞歸計算,並將計算結果與步驟304中正確的識別結果比較,根據損失函數計算出編碼間誤差;
步驟306,將編碼間誤差反饋回遞歸神經網絡中,通過梯度下降函數調節下一個坐標進行遞歸計算時的計算參數,並根據步驟305繼續對下一個坐標進行遞歸計算,直至存儲的筆跡坐標序列中的最後一個坐標完成遞歸計算,即得到待識別字符的編碼值,本次計算結束;
計算筆跡坐標序列中每個坐標,並計算每次輸出的編碼間誤差,然後根據編碼間誤差調整計算參數,再計算下一個坐標。在這個序列中所有坐標運算完成之後仍可能存在誤差,但是由於每次調整參數後這個誤差就會越來越小。訓練樣本足夠,這個誤差就會逐漸小甚至消失。大量數據進行梯度下降計算就可以將誤差減小到最低,逼近實際的編碼值。
步驟307,清空之前存儲的筆跡坐標序列,輸出本次識別結果。
本發明中通過遞歸神經網絡對筆跡坐標序列進行計算。遞歸神經網絡是一種常用的用來進行文字識別的計算方法。本發明優選使用LSTM模型,即Long-Short Term Memory,長短期記憶神經網絡對筆跡坐標序列進行計算。這是一種採用特殊隱式單元的遞歸神經網絡模型。
LSTM模型分為三層,即輸入層,隱藏層和輸出層;其中輸入層接收筆跡坐標序列中的坐標,隱藏層計算從輸入層傳遞給隱藏層的數據,保存計算結果並將計算結果傳遞給輸出層,輸出層每次輸出對應的筆跡坐標序列中一個坐標的計算結果。
LSTM模型是遞歸神經網絡模型中的一種,在LSTM模型中,本次隱藏層的計算結果會傳遞到下一次隱藏層的計算中去,即隱藏層本次計算結果依賴於輸入層本次傳遞的數據和隱藏層前幾次計算的結果。而普通的遞歸神經網絡中,隱藏層的計算結果受時間影響嚴重,即時間越久遠的計算結果對當前的計算影響越小。LSTM模型引入cell機制,可以長期的存儲隱藏層的計算結果,因此降低了之前的計算結果影響力下降的問題。
設輸入層輸入變量為it,隱藏層的輸入門參數為Wi和bi。輸入門用於確定保留於記憶細胞單元狀態中的信息。需要隱藏層上一步計算結果ht-1和當前輸入it決定。輸入門按照如下公式進行計算:
C『t為更新記憶細胞單元狀態的中間變量,更新記憶細胞單元狀態的運算公式為:
Ct=ft·Ct-1+It·C『t
隱藏層的記憶細胞單元參數為WC和bc,隱藏層的遺忘門參數為Wf和bf。
遺忘門用於確定記憶細胞單元狀態丟棄信息量。需要隱藏層上一步計算結果ht-1和當前輸入it決定。遺忘門按照如下公式進行計算:
隱藏層的輸出門參數為Wo和bo。輸出門用於確定隱藏層的輸出值。需要根據已經更新的記憶細胞單元狀態值按照如下公式進行計算:
ht=ot·Tanh(Ct)
計算後將隱藏層計算結果ht傳遞給輸出層;
輸出層的參數為Wh和bh,本次隱藏層計算結果ht和記憶細胞單元狀態Ct傳遞給下一次計算,輸出層輸出結果為Ht,Ht=f(Wh·ht+bh);f函數為映射函數,即將隱藏層參數與參數乘積映射至字符編碼。由於所選擇的字符編碼方式不同,映射函數也各不同。
其中下標t表示當前輸出,t-1表示前一次輸出,it,Wf,Wi,Wo,,bi,bo,Ct,WC均為向量形式。
在監督訓練過程中的步驟203和實際使用階段中的步驟305中所述的通過損失函數計算編碼間誤差的具體計算過程如下:將計算結果的編碼值對應至十進位數值Ht,將步驟203中待訓練字符的編碼值或者步驟305中正確的識別結果的編碼值對應至十進位數值則編碼間誤差θt可以通過損失函數計算,計算公式為
從而,在監督訓練過程步驟203隨後對應的步驟204和實際使用階段步驟305隨後對應的步驟306中,所述的將上面計算出的編碼間誤差反饋回遞歸神經網絡,再通過梯度下降函數調節下一個坐標進行遞歸計算時的計算參數,使遞歸神經網絡通過訓練器輸出的文字編碼值逼近真實輸入文字的編碼值。具體調整方式如下:
輸出層參數調整為:
其中,Wh′,bh′為更新後的輸出層參數,Wh,bh為當前輸出層參數;
隱藏層的輸出門參數調整為
其中,Wo′,bo′為更新後的隱藏層的輸出門參數,Wo,bo為當前隱藏層的輸出門參數;
隱藏層的輸入門參數調整為
其中,Wi′,bi′為更新後的隱藏層的輸入門參數,Wi,bi為當前輸入層的輸入門參數;
隱藏層的記憶細胞單元參數調整為
其中,Wc′,bc′為更新後的隱藏層的記憶細胞單元參數,Wc,bc為當前輸出層的記憶細胞單元參數;
隱藏層的遺忘門參數調整為
其中,Wf′,bf′為更新後的隱藏層的遺忘門參數,Wf,bf為當前隱藏層的遺忘門參數;
以上參數都是對編碼間誤差θt求偏導獲得的,其中α為梯度下降速度。α越大梯度下降越快。根據實際調整α,如果訓練的數據量很大,應使α儘可能的小以避免過擬合現象。
監督訓練過程中步驟202中以及實際使用階段中步驟302中對筆跡坐標序列進行歸一化處理的具體步驟如下:
設手寫輸入設備的左下角的頂點為原點,手寫輸入設備的輸入坐標範圍為從原點向右延伸X個像素,從原點向上延伸Y個像素的矩形區域。即手寫輸入設備的輸入坐標範圍為對角線從原點延伸到到(X,Y)這一點的矩形區域。
假定筆跡坐標的原始時間序列中的一個坐標點為(Xt,Yt),將坐標點(Xt,Yt)歸一化處理替換為(Xt』,Yt』),替換值計算公式為
將筆跡坐標的原始時間序列中的每一個坐標點都進行上述的歸一化處理,即得到歸一化的筆跡坐標序列。
神經網絡中,通常採用非線性激活函數用於計算信息的流通傳遞能力,這些非線性激活函數要求計算結果在[0,1]區間內,0代表完全沒有信息流通,1代表信息完全流通。LSTM模型通常採用sigmoid函數作為激活函數。我們假定使用Sig(m)代表對括號內表達式m做sigmoid函數計算。sigmoid函數的表達式為:
符號m僅代表表達式,實際使用中被替換真實表達式替換。
在遞歸神經網絡中重複神經網絡模塊通常採用tanh函數計算,簡單的遞歸神經網絡直接使用tanh函數作為隱藏層,tanh函數計算結果區間為[-1,+1]。我們假定使用Tanh(m)代表對括號內表達式m做tanh函數計算。tanh函數表達式為:
符號m僅代表表達式,實際使用中被替換真實表達式替換。
LSTM模型每次遞歸過程計算筆跡序列中一個坐標,筆跡序列中存在多少個坐標就遞歸多少次。對於一次遞歸過程,如圖3)輸入向量it與坐標的對應關係為:
筆跡坐標序列中的每一個坐標計算後都會對應一個輸出結果。最終識別結果則是所有筆跡時間序列中每個坐標的識別結果的累積。因此需要對序列中的每一個坐標都進行計算,通過記憶細胞單元狀態保存之前計算的累積值,直至序列中最後一個坐標計算完畢,則這個結果就包含了前面所有坐標計算的累計量和自身的坐標計算量。最後一個坐標的計算結果就是序列的輸出結果,即模型的識別結果。
有益效果
本發明在實際運用之前先行採集大量手寫筆跡序列的數據進行訓練,使得識別更具普適性,識別率更高。而同時,由於監督訓練訓練出的模型參數實際上是根據訓練人員的筆跡訓練的。用戶使用時可能由於手寫習慣的不同,導致部分筆跡識別不了。因而,用戶使用階段針中,本方法會對用戶的手寫習慣提取特徵,尤其考慮筆跡中的書寫速度與筆跡停頓的特徵,藉助遞歸神經網絡的反饋學習能力,將計算得到的文字編碼值和實際輸入文字的編碼的差值進行比較,並以編碼間誤差的形式返回至遞歸神經網絡訓練模型中,根據編碼間誤差調整模型各層的參數值,進行遞歸運算,經過大量訓練後可以形成適用於使用者個人手寫習慣的識別模型,不會忽略筆跡書寫中的停頓、書寫速度等時間信息。一旦模型符合用戶的特點,那麼對於用戶而言,識別精度就高了。
同時,相對於一般的筆跡向量識別方法,一般的筆跡向量識別方法通常將筆跡坐標統一成向量形式,實際輸入為向量的集合。統一過程中需要過濾無效的坐標點,將筆跡中轉折較大的坐標點保留,然後保留的坐標兩兩形成向量。過濾時可能丟棄有效的坐標,一些轉折不明顯或者手寫不明顯的筆畫被過濾丟棄。同時,有的向量方法只使用了時間信息中手寫筆跡順序的信息,而忽略了書寫時速度,停頓等時間信息。一般的筆跡向量識別方法無法形成適應使用者書寫習慣的書寫模型,因而識別精度無法達到本發明的標準。而本發明實施例處理的輸入為筆跡坐標的時間序列,與現有的針對筆跡向量的識別方法相比,不僅對輸入坐標的位置結構有很高的識別率,而且對於輸入過程的時間信息有很好的記錄能力,對信息的保留能力更高,因而識別率也更高。用戶長期使用本實施例,實際使用階段中,LSTM模型的記錄細胞單元會保留識別錯誤的用戶手寫筆跡的時間特徵和位置特徵,將前幾次未成功識別的序列重新輸入LSTM模型,採用梯度下降方法,調整模型參數。使用時間越長這些特徵就提取得越充分,識別時匹配輸入信息和記錄的特徵信息,可以針對用戶的手寫習慣與手寫速度調整到更高的準確度。
本發明可以通過改變手寫輸入設備的採樣頻率,改變筆跡坐標序列的數據量,以根據不同手寫速度來調整訓練模型計算速度。
本發明所採用的方法在手寫過程中即可記錄用戶書寫筆跡在時間上的特徵,如筆跡中的停頓等。由於遞歸神經網絡計算時針對的是一個一個的坐標點,因而在在手寫過程中就可以進行相應計算,在手寫過程中進行識別。因而識別效率更高。
而且本發明通過選擇性地改變LSTM模型中各層的參數數目,調整模型參數結構,在計算量和計算時間中取得平衡。具體而言,本方法中,隱藏層存在多個門,每個門都有參數。如果要求結果精確可以對每個參數都調整;如果追求速度,那麼可以固定部分參數不調整。從而獲得很高的靈活性。
附圖說明
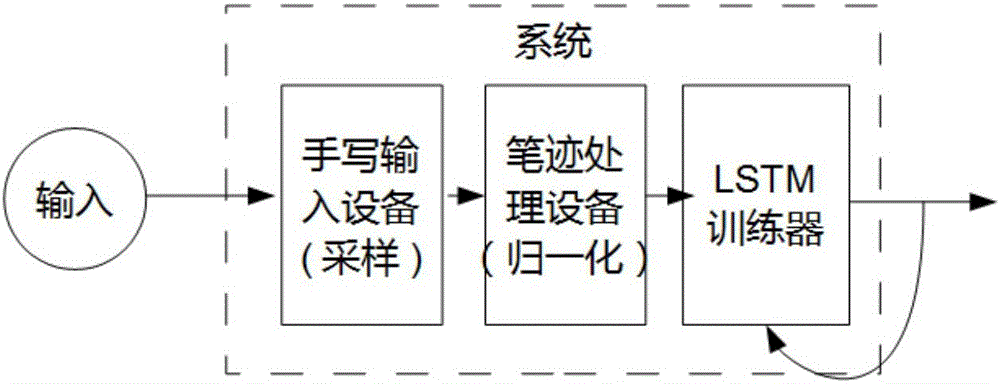
圖1為本發明實施例一的系統結構框圖;
圖2為本發明的手寫筆跡坐標採樣序列圖;
圖3為本發明的LSTM模型訓練原理示意圖;
圖4為本發明的LSTM模型各層結構示意圖;
圖5為本發明實例一的手寫字符『A』筆跡採樣示意圖;
具體實施方式
下面對本發明技術方案進行詳細說明,但是本發明的保護範圍不局限於所述實施例。
實施例1:
如圖1所示,本實施例的系統結構框圖分為手寫輸入採集,輸入數據坐標處理和訓練器三個部分。
具體給出系統的工作步驟如下:
步驟1)考慮需要處理的文字範圍,選擇相應的文字編碼方式。可以選擇使用已有廣泛使用的通用字符集,也可以針對所需識別的文字編寫特定的編碼集。編碼集預置於系統中,系統輸出將從編碼集中選取。不同的編碼方式會影響LSTM模型輸出層的映射函數,映射函數需要將隱藏層輸出結果映射為文字編碼,越複雜的文字編碼方式映射函數越複雜。本實例識別的是英文字符,因而採用ASCII編碼方式,映射函數直接原樣映射,隱藏層輸出結果與輸出層結果一致。
步驟2)根據手寫輸入設備的解析度獲得手寫觸點的坐標範圍。本實施例中手寫設備的解析度為640*480像素,輸入坐標範圍就是640*480。規定輸入設備左下角的頂點為原點,手寫輸入設備的輸入坐標範圍為從原點向右延伸640像素,從原點向上延伸480像素的矩形區域。即手寫輸入設備的輸入坐標範圍為對角線從原點延伸到到(640,480)這一點的矩形區域。這個矩形區域即可確定觸點坐標。
步驟3)設定手寫輸入設備的採樣頻率。採樣頻率和手寫輸入的速度,處理數據能力,採樣數據能力有關。應該儘可能選擇較高的採樣頻率以提高識別精度。然而,對於處理能力不高(如CPU計算量過小)的設備,採樣頻率過高,所採集的筆跡坐標序列中的坐標點也就越多,因而需要更長時間處理數據,識別的延時過長。這種情況下,應適當降低採樣頻率。而性能較差的手寫輸入設備,設備本身的採樣的能力不夠,採樣極限頻率過低,而實際採樣頻率不能超過設備本身的極限頻率,因而會對手寫筆跡的識別帶來不利影響。
若書寫者手寫速度很快則應採用高採樣頻率。否則採樣點過少,不易計算出文字編碼值。書寫者手寫速度很慢則應採用低採樣頻率,否則採樣點過多。實際產品可以根據產品面向的人群,在普通人手寫速度上,針對寫字較慢的老人或者特殊人群做調整。本實施例選擇100Hz的採樣頻率。
說明書中的監督訓練過程發生在手寫輸入設備的生產過程中。由於監督訓練過程中根據編碼間誤差調整遞歸計算中參數的過程與實際使用過程中的類似,此處,僅以監督訓練階段為例進行說明。
步驟4)輸入者在手寫輸入設備上書寫,如圖2所示,手寫輸入設備根據步驟3)預先設置的採樣頻率,對接觸點的軌跡進行採樣,得到採樣點的位置坐標。連續採樣得到的一系列筆跡坐標組合成筆跡坐標的原始時間序列。當設備在一定閾值時間仍然採集不到觸點,則認為本次手寫已經結束,之前的觸點坐標序列即為訓練和識別的筆跡序列。閾值時間應該避免過長或者過短,防止用戶等待時間過長或者用戶在書寫中有長時間手寫停頓的習慣。這裡選擇1秒作為閾值時間。
步驟5)將筆跡坐標的原始序列輸入至筆跡處理設備,根據步驟2)中獲得的輸入設備接觸點的坐標範圍(X,Y),把筆跡坐標的原始序列中的每一個坐標歸一化為一對小數值(Xt』,Yt』)。對於小數精度不高的系統,可以乘以相應的數值,將歸一化的坐標序列變為相對坐標序列。如圖5所示,輸入字符為A,採樣歸一化後得到歸一化的坐標序列。
步驟6)將步驟5)處理得到的歸一化的對坐標序列輸入LSTM訓練器中,LSTM訓練器輸出識別後的文字編碼。這裡使用的訓練器為LSTM(Long-Short Term Memory)模型。應說明的是,訓練器使用的模型包括但不限於LSTM模型,遞歸神經網絡均可以用於本方法對於手寫過程識別,只是LSTM識別性能更好。本實例中LSTM訓練器採用python深度學習theano庫編寫。
步驟7)將文字編碼值反饋回LSTM訓練器。在監督訓練中輸入者確定實際輸入文字,比較實際輸入文字的編碼值與LSTM訓練器輸出的識別後的文字編碼值,計算出編碼間誤差,將編碼間誤差反饋到LSTM訓練器中,訓練器通過梯度下降函數調整LSTM訓練器內部參數。本實施例經過多次訓練後,識別模型內部計算得到一個數值,如圖5所示的字符識別輸出為65(十進位),65的二進位值在ASCII碼中對應即為A。
本發明實施例的訓練模型為LSTM模型。LSTM模型相比其他遞歸神經網絡模型,引入了記憶細胞單元,解決了其他模型中後節點對前節點感知力下降的問題。其他模型中,從輸入的數據上來看,對本次結果影響最大的是本次輸入,接著是上次輸入,再次是上上次輸入。影響程度隨著距離愈遠而愈來愈小,最初的輸入幾乎對本次結果無影響。而LSTM模型中,在序列中坐標過多時,前面坐標的計算結果反饋至後面與後面坐標一併計算時,前面坐標計算結果的影響不會衰減。因而本發明所述的識別方法不至於忽略最初計算的筆跡坐標,而是考慮了本次輸入的筆跡坐標序列中的每一個坐標值,因而具有很高的識別精度。
而且本發明通過選擇性地改變LSTM模型中各層的參數數目,調整模型參數結構,在計算量和計算時間中取得平衡。具體而言,本方法中,隱藏層存在多個門,每個門都有參數。如果要求結果精確可以對每個參數都調整;如果追求速度,那麼可以固定部分參數不調整。從而獲得很高的靈活性。
一般的筆跡向量識別方法是將筆跡坐標統一成向量形式,實際輸入為向量的集合。統一過程中需要過濾無效的坐標點,將筆跡中轉折較大的坐標點保留,然後保留的坐標兩兩形成向量。過濾時可能丟棄有效的坐標,一些轉折不明顯或者手寫不明顯的筆畫被過濾丟棄。同時,有的向量方法只使用了時間信息中手寫筆跡順序的信息,而忽略了書寫時速度,停頓等時間信息。而本發明所記錄的這些時間信息可以針對用戶的手寫習慣提取特徵,提高識別率,而且使得識別模型更貼合於個人的書寫習慣。本發明實施例處理的輸入為筆跡坐標的時間序列,與現有的針對筆跡向量的識別方法相比,不僅對輸入坐標的位置結構有很高的識別率,而且對於輸入過程的時間信息有很好的記錄能力,對信息的保留能力更高,因而識別率也更高。監督訓練訓練出的模型參數實際上是根據訓練人員的筆跡訓練的。用戶使用時可能由於手寫方式,部分筆跡識別不了。在實際使用階段中,LSTM模型的記錄細胞單元會保留識別錯誤的用戶手寫筆跡的時間特徵和位置特徵,將前幾次未成功識別的序列重新輸入LSTM模型,採用梯度下降方法,調整模型參數。這種訓練使模型符合用戶的筆跡特點。一旦模型符合用戶的特點,那麼對於用戶而言,識別精度就高了。使用時間越長,用戶書寫的特徵就提取得越充分,識別時匹配輸入信息和記錄的特徵信息,可以針對用戶的手寫習慣與手寫速度調整到更高的準確度。