加標籤的嗜肝DNA病毒e抗原及其在篩選抗病毒物質中的用途的製作方法
2023-04-30 11:33:56 8
本發明涉及篩選抗嗜肝DNA病毒物質的方法和用途,其中物質是B型肝炎e抗原(HBeAg)的抑制劑,所述抑制劑在本發明中所述的細胞系中優勢地為共價閉合環狀(ccc)DNA依賴性並且可能充當cccDNA的替代標記,其中對所述替代標記篩選抑制嗜肝DNA病毒(如B型肝炎病毒(HBV))ccc DNA的能力。所述方法和用途利用包含核酸序列的細胞,所述核酸序列編碼加標籤的嗜肝DNA病毒e抗原,如B型肝炎病毒e抗原(HBeAg)。另外,本發明提供了編碼加標籤的嗜肝DNA病毒e抗原的核酸序列和因此編碼的蛋白質。還提供用於篩選方法中的試劑盒。
慢性B型肝炎目前是重大公共衛生負擔,全球侵襲大約35000萬個體並且在美國侵襲至少120萬個體。這些患者具有升高的肝硬化、肝細胞癌(HCC)和其他嚴重臨床後遺症風險(1,2,12,14)。每年,全球存在約1百萬例因HBV相關肝病所致的死亡。因此,全球健康優先事項是治癒慢性HBV感染並阻止其可怕結果。
B型肝炎病毒(HBV)是屬於嗜肝DNA病毒科(Hepadnaviridae)的非細胞病變性、嗜肝DNA病毒。嗜肝DNA病毒是可以在人類和動物中造成肝感染的有包膜雙鏈病毒科。嗜肝DNA病毒共有相似的基因組結構。它們具有部分為雙鏈環狀DNA的小基因組。基因組由兩條DNA鏈組成,一條鏈具有負義方向,另一條鏈具有正義方向。複製涉及稱作前基因組RNA的RNA中間體逆轉錄(15,19)。編碼三個主要可讀框(ORF)並且病毒具有五種已知的mRNA(18,19)。
一旦感染,則病毒基因組鬆弛型環狀(rc)DNA運輸入細胞核並轉化成附加體性共價閉合環狀(ccc)DNA,其充當病毒全部mRNA的轉錄模板,尤其是3.5-3.6kb編碼作為HBeAg前體的前核心蛋白的前核心蛋白mRNA;3.5kb編碼核心蛋白和病毒聚合酶的前基因組(pg)RNA;2.4kb/2.1kb編碼病毒包膜蛋白(大抗原(L)、中等抗原(M)和小(S)抗原)的表面mRNA;和0.7kb編碼X蛋白的X mRNA(18,19)。通過移除前核心蛋白N端信號肽和C末端精氨酸豐富序列的兩個蛋白酶解性事件產生HBeAg(Wang(1991)J Virol 65(9),5080(10,21)。在轉錄和核輸出後,胞質病毒pgRNA隨HBV聚合酶和衣殼蛋白一起裝配以形成核衣殼,其內部聚合酶催化的逆轉錄產生負鏈DNA,後者隨後拷貝成正鏈DNA以形成後代rcDNA基因組。新合成的成熟核衣殼將用病毒包膜蛋白包裝並移出作為病毒粒粒子,或返回胞核以通過胞內cccDNA擴增途徑放大cccDNA儲備(19)。因此,慢性B型肝炎分子基礎是病毒cccDNA在感染的肝細胞的胞核中持續存在。
不存在確定的慢性B型肝炎治癒。目前批准的HBV治療藥物是幹擾素-α(IFN-α)和5種核苷(酸)類似物(拉米夫定、阿德福韋、恩替卡韋、替比夫定和替諾福韋)。Xu(2010)J Virol(84)9332-9340公開了用小鼠幹擾素治療小鼠肝細胞。在48周標準治療後IFN-α僅在少量患者組中實現持久的病毒學反應,並且存在明顯的不良作用(9)。五種核苷(酸)類似物(NA)均充當病毒聚合酶抑制劑,但是幾乎未治癒HBV感染(6),並且耐藥性的出現大幅度限制其長期效力(16,24)。現在熟知,當前療法的主要局限是無法消除事先存在的cccDNA池和/或阻止cccDNA從痕量水平的野生型或耐藥性病毒形成。因此,對於開發直接靶cccDNA形成和維持的新治療藥存在未滿足的迫切需求。
Cai(2013)Methods in Mol Biol 1030(151-161)公開了從細胞培養物檢出HBV ccc(共價閉合環狀)DNA的DNA印跡測定法。然而,迄今,抗cccDNA物質的篩選已經因缺少有效體外HBV感染模型受限,並且以高通量至中等通量模式測量cccDNA的實用方案不可得。備選地,可以在組成型或條件性複製HBV基因組的穩定轉染的HBV細胞培養物(如HepG2.2.15細胞和HepAD38細胞所代表)中通過胞內擴增途徑實現cccDNA形成(7,11,20)。
但是,通過DNA印跡雜交或實時PCR測定法從HBV細胞系直接檢出cccDNA將經不住篩選檢驗,原因分別在於靈敏度問題和特異性問題。在另一方面,HepG2.2.15細胞中不存在合適的cccDNA替代標記,因為絕大部分病毒產物衍生自整合的病毒轉基因,其無法與cccDNA的貢獻區分。先前已經報告,分泌型HBeAg的產生在HepAD38細胞中優勢地為cccDNA依賴性斌並且可能充當cccDNA的替代標記(11,23)。最近,Cai等人將改進形式的唯一依賴cccDNA產生HBeAg的細胞系(命名為HepDE19細胞(7))應用成篩選cccDNA抑制劑的96孔模式測定法並且鑑定到抑制cccDNA形成的兩種小分子化合物(3)。這種工作因此提供了以下的堅實「概念驗證」展示:可以通過化學分子直接靶向cccDNA生物合成,並且可以從高通量篩選計劃鑑定cccDNA抑制劑。然而,現存HepDE19測定體系的某些缺點令篩選較大文庫不切實際。例如,目前用於HBeAg的傳統ELISA測定法需要多重操作,因胺基酸序列同源性而與病毒核心蛋白顯示出某種程度的交叉反應,並且不適於較大模式基於細胞的測定法。
因此,作為本發明基礎的技術問題是提供手段和方法以可靠篩選嗜肝DNA病毒cccDNA的抑制劑。
這個技術問題通過提供在權利要求書中表徵的實施方案加以解決。
因此,本發明涉及一種用於評估候選分子抑制嗜肝DNA病毒ccc(共價閉合環狀)DNA的能力的方法,包括步驟
(a)使包含核酸分子的細胞與所述候選分子接觸,所述核酸分子包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列;
(b)評估加標籤的嗜肝DNA病毒e抗原的水平;並且
(c)當加標籤的嗜肝DNA病毒e抗原的水平與對照相比降低時選擇候選分子。
這些方法總體上適用於與B型肝炎病毒(HBV)共有相似基因構造和複製策略的其他哺乳動物及鳥類嗜肝DNA病毒,如代表性土撥鼠肝炎病毒(WHV)和鴨B型肝炎病毒(DHBV)。本文中就B型肝炎病毒提供的解釋和實驗因此同樣地適用於其他嗜肝DNA病毒。然而,本文中提供的教導內容在優選的實施方案中涉及「B型肝炎病毒」/HBV。術語「嗜肝DNA病毒」、「B型肝炎病毒」、「鴨B型肝炎病毒」、「土撥鼠肝炎病毒(WHV)」是本領域熟知的並且因此用於本文中。縮寫「HBV」、「DHBV」或「WHV」在本文中分別與完整術語「B型肝炎病毒」、「鴨B型肝炎病毒」和「土撥鼠肝炎病毒」互換使用。
本文優選的嗜肝DNA病毒優選地是B型肝炎病毒(HBV)。B型肝炎病毒(HBV)是屬於嗜肝DNA病毒科(Hepadnaviridae)的非細胞病變性、嗜肝DNA病毒,即,HBV是一種嗜肝DNA病毒。HBV基因組的示例性核酸序列在SEQ ID NO:27、28、29、30、31、32、33或34中顯示。
本文優選的嗜肝DNA病毒e抗原是B型肝炎病毒e抗原(HBeAg)。術語「B型肝炎病毒e抗原」和「HBeAg」在本文中互換地使用。HBeAg的示例性核酸序列和胺基酸序列分別在SEQ ID NO:16和18中顯示。如本文所用,「嗜肝DNA病毒e抗原」(並且同樣地「B型肝炎病毒e抗原」)主要指蛋白質/多肽,例如具有如SEQ ID NO:18中所顯示的胺基酸序列的蛋白質/多肽。
一旦感染,可以如下產生HBeAg:一旦感染,HBV病毒基因組鬆弛型環狀(rc)DNA運輸入細胞核並轉化成附加體性cccDNA,其充當病毒全部mRNA的轉錄模板,包括3.5-3.6kb編碼作為HBeAg前體的前核心蛋白的前核心蛋白mRNA。術語「ccc DNA」和「共價閉合環狀DNA」在本文中互換地使用。
HBV前核心蛋白的示例性核酸序列和胺基酸序列分別在SEQ IDNO:15和17中顯示。HBV前核心蛋白具有一個N末端19胺基酸信號肽、一個10-胺基酸接頭、一個中央胺基酸段和一個C末端34胺基酸精氨酸豐富結構域。
HBV核心蛋白的示例性核酸序列和胺基酸序列分別在SEQ ID NO:23和24中顯示。核心蛋白對應於前核心蛋白(參見SEQ ID NO:17),在於它包含前核心蛋白的C末端精氨酸豐富序列;然而,核心蛋白不包含前核心蛋白的N端信號肽和10胺基酸接頭序列。
通過移除前核心蛋白N端信號肽和C末端精氨酸豐富序列的兩個蛋白酶解性事件產生HBeAg(Wang(1991)J Virol 65(9),5080(21)。因此,B型肝炎病毒e抗原(HBeAg)對應於前核心蛋白(參見SEQ ID NO:17),在於它包含前核心蛋白的N末端10-aa接頭肽;然而,HBeAg不包含前核心蛋白的C末端精氨酸豐富序列。
慢性B型肝炎分子基礎是病毒cccDNA在感染的肝細胞的胞核中持續存在。
術語「共價閉合環狀DNA」和「cccDNA」在本文中互換地使用。術語「共價閉合環狀DNA」/「cccDNA」是本領域熟知的並且因此用於本文中。通常,如本文所用的「共價閉合環狀DNA」/「cccDNA」指充當嗜肝DNA病毒mRNA的可靠附加體性轉錄模板的DNA。
B型肝炎病毒e抗原(HBeAg)是接受的HBV嗜肝DNA病毒cccDNA替代標記,所述替代標記轉而反映慢性嗜肝DNA病毒感染。然而,使用HBeAg的基於細胞的已知測定法具有缺點,如與病毒核心蛋白交叉反應。
為了改善cccDNA報導分子檢測法的特異性和靈敏度,本文中建立了這樣的細胞系,它們支持具有標籤(如N末端嵌入的血凝素(HA)表位標籤)的重組HBeAg的cccDNA依賴性產生。另外,開發了檢測加(HA-)標籤的HBeAg的化學發光ELISA(CLIA)和AlphaLISA測定法。該測定體是適應於高通量篩選模式和完全自動化。
本文提供的方法利用建立的標籤(如可以替代HA標籤使用或除HA標籤之外使用的HA標籤、或His標籤、Flag標籤、c-myc標籤、V5標籤或C9標籤)的用途。這些標籤可以用於純化和檢測加標籤的嗜肝DNA病毒e抗原。通過使用與標籤特異性結合的抗體(例如通過ELISA測定法,如化學發光-ELISA(CLIA)和AlphaLISA),可以可靠地及快速地評估加標籤的嗜肝DNA病毒e抗原的水平並且可以避免與核心蛋白的交叉反應。
本文提供的方法利用包含核酸分子的細胞,所述核酸分子包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列。該核酸分子可以包含編碼嗜肝DNA病毒前核心蛋白的序列或甚至嗜肝DNA病毒基因組以反映嗜肝DNA病毒的cccDNA形成並且令其成為可能。本領域已知,HBV基因組具有顯示重疊ORF和多個順式元件的高度緊湊型基因構造。因此,認為基因插入/缺失或序列替換將很可能影響病毒DNA複製(13,22)。(Liu等人,J Virol.2004;78(2):642-9)(Wang等人.PLoS One.2013 2;8(4):e60306)。先前的工作已經通過GFP替換HBV序列,如在大多數情況下pol/包膜蛋白編碼區,以產生重組HBV基因組,但是需要病毒蛋白的反式互補以支持病毒複製和病毒粒裝配(17)(Protzer等人,PNAS(1999),96:10818-23)。另外,這種報告的重組HBV基因組僅可以產生第一輪cccDNA合成,如果用來感染容許性細胞,則cccDNA的胞內擴增被阻斷,原因是缺陷型病毒DNA複製。
嗜肝DNA病毒pgRNA、優選地HBV pgRNA中的5』莖-環結構(ε)是病毒複製的必需順式元件。它充當pgRNA包裝信號和DNA引發位點。ε與前核心蛋白ORF的5』部分重疊並含有衣殼(核心)蛋白ORF的起始密碼子。為了在不改變HBV基因組編碼的ε結構的完整性的情況下,在前核心蛋白ORF中的N端信號肽序列下遊插入編碼標籤的核酸序列,將一個三胺基酸接頭序列(GTG GAC ATC)在(HA-)標籤5'末端引入其中,以替代如HBV基因組編碼的ε的底部處右臂的原始病毒序列(ATGGAC ATC)。因而,維持如HBV基因組編碼的ε的鹼基配對並且將核心蛋白ORF的起始密碼子移動到HBV基因組編碼的ε下遊的位置。此外,原始GGC序列安置在HA標籤序列和核心蛋白AUG之間,以保持核心蛋白起始密碼子的可靠Kozak基序(圖1)。圖1顯示HBV基因組的編碼ε結構的部分,其中根據本發明插入編碼標籤的核酸序列。
本文中構思了以上修飾對HBV pgRNA依賴性核心蛋白表達和pgRNA衣殼化造成最小影響,因為保留了ε和核心蛋白表達盒,不過核心蛋白的翻譯起始位點在pgRNA模板中進一步向下遊移動39-nt。實際上,重組HBV基因組支持幾乎野生型水平的病毒DNA複製,並且一旦前核心蛋白ORF在cccDNA分子中重構,則成功產生加HA標籤的HBeAg。
插入編碼標籤的寡聚物的確不影響病毒DNA應用,從而本文提供的方法允許產生cccDNA並且因此允許通過確定替代標記「加標籤的嗜肝DNA病毒e抗原」的量,評估物質/候選分子抑制cccDNA形成的能力。本文提供的手段和方法主要可用於篩選及鑑定可以在與嗜肝DNA病毒相關的慢性病如(慢性)肝炎和尤其慢性B型肝炎感染的療法中使用的候選分子。
將編碼標籤(如HA標籤)的核酸序列插入嗜肝DNA病毒(如HBV)前核心蛋白ORF中導致嗜肝DNA病毒(如HBV)可用於改善抗原檢測特異性的加標籤的嗜肝DNA病毒e抗原(如HBeAg)的cccDNA依賴性產生。在支持本發明時,本文中證實,(HA-)標籤插入不影響前核心蛋白的表達及其後續翻譯後加工(N端信號肽切割和C末端結構域切割)和成熟的HBeAg分泌(圖2)。更重要地,本文中顯示,嗜肝DNA病毒(如HBV)基因組中的這種修飾不妨礙病毒pgRNA衣殼化和逆轉錄,這是通過胞內擴增途徑形成cccDNA的前提(圖4、圖6-8、圖12)。
本發明涉及篩選藥理學物質及評估其對抗嗜肝DNA病毒的活性。特別地,本發明描述了設計和構建用於誘導型表達HBV cccDNA依賴性表位(例如加人流感血凝素(HA)標籤的HBV e抗原(HBeAg)的重組B型肝炎病毒(HBV)基因組和新細胞系。可以定量地測量分泌入培養液的加標籤的HBeAg,例如通過化學發光酶免疫測定法(CLIA)和/或AlphaLISA。本發明提供基於細胞的有效HBV報導分子系統以篩選化合物的抗嗜肝DNA病毒活性,尤其抑制cccDNA形成、維持和/或其轉錄活性的那些化合物。
本發明進一步由圖10說明。這裡,顯示3TC處理消除了HepBHAe13細胞中的HA-HBeAg信號,不過這是一種其中3TC阻斷病毒DNA複製並且因此無cccDNA合成的極端情況。另外,作為原理的證據,在HepBHAe13細胞中檢驗了兩種cccDNA形成抑制劑(CCC-0975和CCC-0346)。兩種化合物均劑量依賴地降低HA-HBeAg水平;參見圖11。
例如,以下非限制性抗嗜肝DNA病毒測定法可以根據本發明進行:
1.使用HepBHAe細胞系篩選調節cccDNA穩定性和/或轉錄活性的化合物/候選分子。
根據本發明,體外測定方法可以用來篩選/評價化合物/候選分子調節胞核中cccDNA穩定性或轉錄活性的效力。化合物/候選分子因而改變培養上清液中加標籤的嗜肝DNA病毒e抗原(如HA-HBeAg)的水平。為了進行該測定法,細胞可以首先在含有四環素的培養板中接種,並且在細胞達到匯合後,培養基將更換為無四環素的培養基以誘導嗜肝DNA病毒(如HBV)DNA複製和cccDNA形成,這在正常情況下耗時6-8天。此後,可以再添加四環素以關閉病毒DNA從整合型HBV基因組從頭複製,同時添加3TC(或其他HBV聚合酶抑制劑)以阻斷cccDNA的胞內擴增途徑。在相同的時間,可以將測試化合物加入培養基持續某個時間段。培養基隨後可以用於加標籤的嗜肝DNA病毒e抗原(如HA-HBeAg)的ELISA測量。來自不含有測試化合物的孔的培養基可以用作對照。降低培養基中加標籤的嗜肝DNA病毒e抗原(如HA-HBeAg)水平的有效化合物可以具有促進cccDNA翻轉(turnover)或沉默cccDNA轉錄的活性。短語「有效的或有效地」可以在本文中用來顯示,化合物在某個檢驗濃度足以阻止並且優選地減少本發明基於細胞的測定體系中加標籤的嗜肝DNA病毒e抗原(如HA-HBeAg)的產生至少50%、最優選至少90%。通過qPCR或雜交直接測量cccDNA和前核心蛋白mRNA的穩態水平可以用來區分測試化合物/候選化合物/候選分子是否分別減少cccDNA穩定性或轉錄。
2.使用HepBHAe細胞系篩選抑制嗜肝DNA病毒(如HBV)cccDNA形成的化合物/候選分子。
根據本發明的另一個方面,體外測定方法可以用來評價抑制cccDNA形成的化合物/候選分子。簡而言之,細胞可以接種在培養孔中並且四環素可以在細胞單層變得匯合的當日省略。同時,可以添加測試化合物並且可以在處理結束時通過ELISA測量培養基中加標籤的嗜肝DNA病毒e抗原(如HA-HBeAg)(大約6天)。導致加標籤的嗜肝DNA病毒e抗原(如HA-HBeAg)減少的任何化合物表示它可以有效地阻斷cccDNA的形成。作為這種體外測定方法的擴展方面,值得指出的是,在這種測定法中減少加標籤的嗜肝DNA病毒e抗原(如HA-HBeAg)還可以顯示化合物具有抑制嗜肝DNA病毒(如HBV)DNA複製的潛力。可以通過DNA印跡和/或qPCR直接測量病毒核心蛋白DNA,研究這種可能性。從上文描述的測定法浮現的「命中」還可以包括影響cccDNA穩定性和/或轉錄的化合物。在誘導時間段期間,早期產生的cccDNA的穩定性和/或轉錄活性可以被檢驗性化合物靶向。
3.HepHA-HBe細胞系起到反篩選系統的作用。
理論上,來自前述測定法的化合物「命中」可以直接抑制加HA標籤的前核心蛋白翻譯、或翻譯後加工、或加標籤的嗜肝DNA病毒e抗原(如HA-HBeAg)分泌。為了排除這類非cccDNA抑制劑,「命中」可以在HepHA-HBe細胞中反篩選,所述HepHA-HBe細胞使用轉基因作為模板產生加標籤的嗜肝DNA病毒e抗原(如加HA標籤的HBeAg)。在另一方面,HepHA-HBe細胞還可能用來篩選HBeAg抑制劑。
術語「抑制共價閉合環狀DNA」及其語法形式可以指抑制共價閉合環狀DNA的穩定性(即指降低的共價閉合環狀DNA穩定性)、指抑制共價閉合環狀DNA的轉錄活性(即指使用共價閉合環狀DNA作為轉錄模板的嗜肝DNA病毒mRNA轉錄減少)或指抑制共價閉合環狀DNA的形成(即無或更少cccDNA形成)。
術語「抑制共價閉合環狀DNA」的這些示例性解釋和定義不是互斥的。例如,抑制的共價閉合環狀DNA形成可以導致使用共價閉合環狀DNA作為轉錄模板的嗜肝DNA病毒mRNA轉錄減少/與之相關(即抑制共價閉合環狀DNA的轉錄活性)。抑制的共價閉合環狀DNA穩定性可以導致使用共價閉合環狀DNA作為轉錄模板的嗜肝DNA病毒mRNA轉錄減少/與之相關。
加標籤的嗜肝DNA病毒e抗原可以在本文中作為嗜肝DNA病毒cccDNA的任何這類抑制作用的替代標記使用。
根據上文,本文提供的方法可以用於評估候選分子抑制嗜肝DNA病毒cccDNA形成的能力。在這種情況下,細胞可以在cccDNA已經形成之前與候選分子接觸。
本文提供的方法可以用於評估候選分子降低嗜肝DNA病毒cccDNA的穩定性(例如cccDNA的量或數目)的能力。這裡,細胞可以在cccDNA已經形成之後與候選分子接觸。
本文提供的方法可以用於評估候選分子降低嗜肝DNA病毒cccDNA轉錄(活性)的能力。這裡,細胞可以在cccDNA已經形成之後與候選分子接觸。
根據本發明待評估其水平的加標籤的嗜肝DNA病毒e抗原可以含有一個或多個標籤。如本文中顯示,可以通過使用僅一個標籤,例如通過使用與該標籤特異性結合的抗體,實現對加標籤的嗜肝DNA病毒e抗原的可靠評估。因此,本文中構思和優選加標籤的嗜肝DNA病毒e抗原僅含有一個標籤。
以下涉及一種或多種在本文待用的標籤。
如本文所用的術語「標籤」指可用作標誌物的任何化學結構。主要地,術語「標籤」指「蛋白質標籤」。術語「標籤」和「蛋白質標籤」是本領域已知的;尤其參見Fritze CE,Anderson TR.「Epitope tagging:general method for tracking recombinant proteins」.Methods Enzymol.2000;327:3-16;Brizzard B,Chubet R.Epitope tagging of recombinant proteins.Curr Protoc Neurosci.2001年5月;第5章:第5.8單元;和/或Terpe K.Overview of tag protein fusions:from molecular and biochemical fundamentals to commercial systems.Appl Microbiol Biotechnol.2003Jan;60(5):523-33。
一般,本文待用的標籤是與嗜肝DNA病毒e抗原融合的蛋白質標籤。例如,編碼標籤的核酸可以與編碼嗜肝DNA病毒e抗原的核酸融合,從而表達包含標籤和嗜肝DNA病毒e抗原的融合蛋白。標籤可以融合於編碼嗜肝DNA病毒e抗原的核酸的5'末端、插入編碼嗜肝DNA病毒e抗原的核酸內部和/或融合於編碼嗜肝DNA病毒e抗原的核酸的3'末端。因此,所產生的融合蛋白可以在N末端、內部(即在嗜肝DNA病毒e抗原內部/作為內部表位)、和/或在C末端包含標籤。如本文中顯示,內部表位標籤可以用於可靠評估加標籤的嗜肝DNA病毒e抗原的水平並且因此是優選的。
各種標籤是本領域已知的並且可以根據本發明使用。通常,本文待用的標籤具有約1-3kDa、優選地約1kDa的低分子量。示例性非限制的低分子量標籤是HA標籤、His標籤、Flag標籤、c-myc標籤、V5標籤或C9標籤。本文中優選使用HA標籤。本文待用的Flag標籤可以是1×Flag標籤或3×Flag標籤。
低分子量以標籤長度(即組成標籤的胺基酸殘基數)反映。例如,可以在本文中使用His標籤(6個胺基酸)、HA標籤(9個胺基酸)、FLAG-標籤(8個胺基酸)、或3XFLAG標籤(22個胺基酸)。這些示例性標籤支持接近野生型水平的HBV DNA複製並且因此可用於實施本發明。
因此,本文待用的標籤可以由6至22個胺基酸,例如6個胺基酸、7個胺基酸、8個胺基酸、9個胺基酸、10個胺基酸、11個胺基酸、12個胺基酸、13個胺基酸、14個胺基酸、15個胺基酸、16個胺基酸、17個胺基酸、18個胺基酸、19個胺基酸、20個胺基酸、21個胺基酸、或22個胺基酸組成。
編碼本文待用標籤的示例性核酸序列是如SEQ ID NO:1中所示的編碼HA標籤的核酸序列、如SEQ ID NO:2中所示的編碼His標籤的核酸序列、如SEQ ID NO:4中所示的編碼c-myc標籤的核酸序列、如SEQ ID NO:5中所示的編碼V5標籤的核酸序列、或如SEQ ID NO:6中所示的編碼C9標籤的核酸序列。本文中優選使用由SEQ ID NO:1編碼或如SEQ ID NO:8中所示胺基酸序列組成的HA標籤。
編碼本文待用的Flag標籤的示例性核酸序列是如SEQ ID NO:3中所顯示的編碼1×Flag標籤的核酸序列或如SEQ ID NO:7中所顯示的編碼3×Flag標籤的核酸序列。
本文待用的標籤的示例性胺基酸序列是如SEQ ID NO:8中所示的HA標籤的胺基酸序列、如SEQ ID NO:9中所示的His標籤的胺基酸序列、如SEQ ID NO:11中所示的c-myc標籤的胺基酸序列、如SEQ ID NO:12中所示的V5標籤的胺基酸序列或如SEQ ID NO:13中所示的C9標籤的胺基酸序列。
本文待用的Flag標籤的示例性胺基酸序列是如SEQ ID NO:10中所顯示的1×Flag標籤的胺基酸序列或如SEQ ID NO:14中所顯示的3×Flag標籤的胺基酸序列。
本文中主要構思使用多種表位標籤,如血凝素(HA)標籤、His標籤、Flag標籤、c-myc標籤、V5標籤和/或C9標籤。表位標籤是因為可以在許多不同物種中可靠產生高親和力抗體而選擇的短肽序列。這些標籤經常衍生自病毒基因,這解釋了它們的高度免疫反應性。這些標籤特別可用於蛋白質印跡法、免疫螢光法、免疫組織化學、免疫親和色譜及免疫沉澱實驗。它們還用於抗體純化。這類表位標籤特別有用,因為可以根據本發明使用與這些標籤特異性結合的已知和市售抗體。
將親和標籤附加至蛋白質,從而使用親和技術,可以從粗製生物學來源中純化所述蛋白質。這些包括殼多糖結合蛋白(CBP)、麥芽糖結合蛋白(MBP)和穀胱甘肽-S-轉移酶(GST)。聚(His)標籤是一種廣泛使用的蛋白質標籤;它與金屬基質結合。
色譜標籤用來改變蛋白質的色譜特性以提供跨越特定分離技術的不同分離度。經常,這些標籤由聚陰離子胺基酸組成,如FLAG-標籤。
基本上可以在本文中使用任何標籤。如包含於本文待用的核酸分子中的編碼標籤的核酸應當能夠支持嗜肝DNA病毒DNA複製、cccDNA形成和cccDNA依賴性加標籤的嗜肝DNA病毒抗原e產生和分泌。可以使用本文中提供的測定法例如實驗中所提供的測定法,容易地驗證這種能力。例如,已經在本文中展示,HA標籤插入導致在穩定細胞系中野生型水平的HBV DNA複製和從cccDNA產生加HA標籤的HBeAg。可以對其他標籤容易證實和檢驗這些能力。例如,插入His標籤和Flag標籤的確在瞬時轉染測定法中不影響病毒DNA複製。
其他標籤可以在不背離本發明精神的情況下使用。
例如,報導蛋白可以用作本文中的標籤,如螢光素酶(例如螢火蟲螢光素酶、海腎螢光素酶、長腹水蚤(Gaussia)螢光素酶、等)、綠色螢光蛋白(GFP)等。這些報導蛋白允許容易評估加標籤的嗜肝DNA病毒的水平,例如通過視檢、螢光測量等。螢光標籤用來給出蛋白質的視覺讀出結果。GFP和其變體是最常使用的螢光標籤。
可以在本發明篩選方法中使用的示例性報導蛋白尤其是螢光素酶、(綠色/紅色)螢光蛋白及其變體、EGFP(增強型綠色螢光蛋白)、RFP(紅色螢光蛋白,如DsRed或DsRed2)、CFP(青色螢光蛋白)、BFP(藍綠色螢光蛋白)、YFP(黃色螢光蛋白)、β-半乳糖苷酶或氯黴素乙醯轉移酶。
螢光素酶是熟知的報導分子;參見,例如,Jeffrey(1987)Mol.Cell.Biol.7(2),725-737。本領域技術人員可以容易地從相應的資料庫和標準教材/綜述推斷出在本發明的上下文中待使用的其他螢光素酶核酸序列和胺基酸序列。
報導蛋白可以通過引起可檢測信號的信號強度變化,允許檢測/評估抑制cccDNA的候選分子。所述可檢測信號可以是螢光共振能量轉移(FRET)信號、螢光偏振(FP)信號或閃爍臨近(SP)信號。可檢測信號可以與如上文定義的報導蛋白相關。例如,GFP可以衍生自維多利亞多管發光水母(Aequorea victoria)(US5,491,084)。編碼維多利亞多管發光水母GFP的質粒從ATCC登錄號87451可獲得。這種GFP的其他突變形式,包括但不限於pRSGFP、EGFP、RFP/DsRed、DSRed2、和EYFP、BFP、YFP連同其他,尤其從Clontech Laboratories,Inc.(Palo Alto,California)可商業獲得。
可以監測包含核酸分子的培養的細胞/組織,所述核酸分子包含編碼與報導基因(如螢光素酶、GFP等)融合的嗜肝DNA病毒e抗原的核酸序列,用於報導基因轉錄隨培養基中測試化合物/候選分子濃度變化的證據。報導基因的轉錄水平隨測試化合物濃度變化而變動顯示了測試化合物/候選分子抑制cccDNA的能力。
報導蛋白通常大於上文所述的低分子量標籤,如表位標籤。歸因於例如包含編碼螢光素酶的核酸序列的核酸分子與編碼更小(表位)標籤(如HA標籤)的核酸序列相比插入更長,下遊病毒核心蛋白和pol從重組前基因組RNA中的表達可能減少,從而可能需要核心蛋白/pol的反式互補物以恢復病毒複製。例如,在這種情況下尤其可以根據本發明使用組成型表達嗜肝DNA病毒核心蛋白和嗜肝DNA病毒聚合酶(核心蛋白/pol)的細胞/細胞系。
本文中構思了使用含有兩個或更多個標籤的加標籤的嗜肝DNA病毒e抗原。使用兩個或更多個標籤可以允許甚至更可靠和因此有利地評估加標籤的嗜肝DNA病毒e抗原。例如,如果兩個或更多個標籤是不同的標籤(例如一個標籤是HA標籤,第二個標籤是His標籤),則可以使用與兩個標籤均特異性結合的抗體。這種測定法可以因此使用例如兩個表位抗體例如用於ELISA檢測,以進一步增加分析特異性。
本文中發現,插入一個22胺基酸的3×FLAG標籤插入物支持有效的HBV複製。因此,認為也可以在本文中使用例如串聯嵌合表位標籤,如HA-接頭-FLAG。
根據上文,當使用兩個或更多個標籤(例如兩個或更多個不同標籤)時,一個標籤可以由6至22個胺基酸組成。本文中特別地構思,本文待用的標籤的總長度(即兩個或更多個標籤的胺基酸殘基總和)不超過最大約22個胺基酸,因為下遊病毒核心蛋白和pol從重組前基因組RNA中的表達可能降低,如上文報導蛋白(如螢光素酶)的上下文中所述。如果這種下遊病毒核心蛋白和pol表達減少出現,例如當兩個或更多個標籤的總長度超過約22個胺基酸時,可能需要核心蛋白/pol的反式互補物以恢復病毒複製。例如,在這種情況下尤其可以根據本發明使用組成型表達嗜肝DNA病毒核心蛋白和嗜肝DNA病毒聚合酶(核心蛋白/pol)的細胞/細胞系。
如同編碼僅一個標籤的核酸、編碼兩個或更多個標籤的核酸可以融合於編碼嗜肝DNA病毒e抗原的核酸的5'末端、插入編碼嗜肝DNA病毒e抗原的核酸內部和/或融合於編碼嗜肝DNA病毒e抗原的核酸的3'末端。標籤可以由標籤分隔:如果使用兩個標籤,則標籤-接頭標籤,如果使用三個標籤,則標籤-接頭-標籤-接頭-標籤等。
因此,所產生的融合蛋白可以在N末端、內部(即在嗜肝DNA病毒e抗原內部/作為內部表位)、和/或在C末端包含兩個或更多個標籤。如本文中顯示,內部表位標籤可以用於可靠評估加標籤的嗜肝DNA病毒e抗原的水平並且因此是優選的。本文中構思了使用例如在N末端具有一個標籤和例如具有第二內部標籤和/或例如在C末端具有第三標籤的所得融合蛋白。在不背離本發明精神的情況下,其他組合容易地顯見和涵蓋的。
兩個或更多個標籤可以是以下兩者或更多者:血凝素(HA)標籤、His標籤、Flag標籤、c-myc標籤、V5標籤和/或C9標籤。Flag標籤可以是1×Flag標籤或3×Flag標籤。
在下文,更詳細地描述根據本發明待使用的核酸分子。
核酸分子可以包含編碼嗜肝DNA病毒前核心蛋白(如HBV前核心蛋白)的核酸序列。編碼嗜肝DNA病毒前核心蛋白的示例性核酸序列在SEQ ID NO:15中顯示並且嗜肝DNA病毒前核心蛋白的示例性胺基酸序列在SEQ ID NO:17中顯示。
核酸分子可以包含如上文限定和解釋的編碼一個或多個標籤的核酸序列。編碼一個或多個標籤的序列可以在編碼嗜肝DNA病毒前核心蛋白的N端信號肽和接頭的核酸序列的3'下遊(插入)。
相對於B型肝炎病毒,N端信號肽和接頭構成例如SEQ ID NO:17中所示的前核心蛋白的N末端29個胺基酸。因此,編碼一個或多個標籤的核酸序列可以在編碼B型肝炎病毒前核心蛋白N端29個胺基酸的核酸序列的3'下遊(插入)。換而言之,編碼一個或多個標籤的核酸序列可以在構成從編碼HBV前核心蛋白的核酸(編碼HBV前核心蛋白的核酸例如在SEQ ID NO:15中顯示)的5'末端起87個核酸殘基的核酸序列的3』下遊(插入)。在蛋白質水平,一個或多個標籤可以在與B型肝炎病毒前核心蛋白(前核心蛋白的胺基酸例如在SEQ ID NO:17中顯示)的位置29相對應的胺基酸殘基的C末端插入。
相對於HBeAg,接頭構成例如SEQ ID NO:18中所示的HBeAg的N末端10個胺基酸。就HBeAg而言,編碼一個或多個標籤的核酸序列可以在編碼HBeAg N端10個胺基酸的核酸序列的3'下遊(插入)。換而言之,編碼一個或多個標籤的核酸序列可以在構成從編碼HBV HBeAg的核酸(編碼HBeAg的核酸例如在SEQ ID NO:16中顯示)的5'末端起30個核酸殘基的核酸序列的3』下遊(插入)。在蛋白質水平,一個或多個標籤可以在與HBeAg(HBeAg的胺基酸例如在SEQ ID NO:18中顯示)的位置10相對應的胺基酸殘基的C末端插入。
更精確地,編碼一個或多個標籤的核酸序列可以在與編碼HBV前核心蛋白的核酸序列(編碼HBV前核心蛋白的核酸序列例如在SEQ ID NO:15中顯示)的位置87和88相對應的核苷酸之間(插入)。這些位置在嗜肝DNA病毒的pgRNA的ε結構中或如嗜肝DNA病毒基因組編碼的ε中界定了接頭的編碼性序列和編碼嗜肝DNA病毒核心蛋白的核酸序列的ORF起始密碼子。相對於HBV,位置87是編碼接頭的序列的最末3』核苷酸並且位置88是編碼核心蛋白的序列的第一個核苷酸。
在蛋白質水平,一個或多個標籤可以在與B型肝炎病毒前核心蛋白(前核心蛋白的胺基酸例如在SEQ ID NO:17中顯示)的位置29和30相對應的胺基酸殘基之間插入。
同樣地,編碼一個或多個標籤的核酸序列可以在與編碼HBeAg的核酸序列(編碼HBeAg的核酸序列例如在SEQ ID NO:16中顯示)的位置30和31相對應的核苷酸之間(插入)。在蛋白質水平,一個或多個標籤可以在與HBeAg(HBeAg的胺基酸例如在SEQ ID NO:18中顯示)的位置10和11相對應的胺基酸殘基之間插入。
編碼一個或多個標籤的核酸可以在編碼嗜肝DNA病毒核心蛋白(如HBV核心蛋白)的核酸的5』上遊(插入)。編碼HBV核心蛋白的示例性核酸在SEQ ID NO:23中顯示。HBV核心蛋白的示例性胺基酸序列在SEQ ID NO:24中顯示。
編碼一個或多個標籤的核酸序列的上文限定的插入位點也可以由嗜肝DNA病毒基因組中核苷酸的位置限定。相對於HBV基因組,根據上文,包含編碼一個或多個標籤的序列的核酸分子可以插入與HBV基因組的位置C1902和位置A1903相對應的核苷酸之間。這些位置可以根據例如Galibert,F.等人(1979),Nature 281:646-650中所述的命名法確定。
顯而易見,如本文中使用的核苷酸(位置)「C1902」和「A1903」分別指前核心蛋白區域編碼性序列的最末核苷酸和核心蛋白AUG的第一個核苷酸。它們在不同HBV基因型(A-H)序列(還如本文中提供及在SEQ IDNO:27-34中顯示)之間保守。因此,本文待用的HBV基因組的示例性非限制核酸序列在SEQ ID NO:27、28、29、30、31、32、33或34中顯示。然而,核苷酸「C」,而非核心AUG中的「A」,或它們的位置可以在序列上不同於一些罕見(臨床)分離株。這類序列也包含於本發明中。
根據本發明,編碼一個或多個標籤的核酸序列可以插入除HBV基因組之外的嗜肝DNA病毒基因組的位置C1902和位置A1903相對應的核苷酸之間。可以容易地確定嗜肝DNA病毒基因組中這些相應的位置(即嗜肝DNA病毒基因組中與HBV基因組的位置C1902和位置A1903對應的位置)。換而言之,編碼一個或多個標籤的核酸序列可以在嗜肝DNA病毒pgRNA的、優選地HBV pgRNA的ε結構或嗜肝DNA病毒基因組(優選地,HBV基因組)編碼的ε和編碼嗜肝DNA病毒核心蛋白的核酸序列的ORF起始密碼子之間插入。
例如,如果核酸分子包含編碼嗜肝DNA病毒前核心蛋白的核酸序列,則編碼一個或多個標籤的序列可以在編碼嗜肝DNA病毒前核心蛋白的N端信號肽和接頭的核酸序列的3'下遊(插入)。可以以容易地確定編碼嗜肝DNA病毒前核心蛋白的N端信號肽和接頭的核酸序列。該序列始於(並因此包含)編碼嗜肝DNA病毒前核心蛋白的核酸序列的ORF起始密碼子並止於編碼嗜肝DNA病毒核心蛋白的核酸序列的ORF起始密碼子之前(即排除核心蛋白的編碼性序列)。在蛋白質水平,一個或多個標籤可以在與接頭(N端信號肽後的接頭)C末端最末胺基酸相對應的胺基酸殘基的C末端插入。
因此,編碼一個或多個標籤的核酸序列可以在編碼嗜肝DNA病毒e抗原的N端胺基酸的核酸序列的3'下遊(插入)。這些N端胺基酸構成嗜肝DNA病毒前核心蛋白中的「接頭」。在蛋白質水平,一個或多個標籤可以在接頭的最末C端胺基酸殘基的C末端插入。
更精確地,編碼一個或多個標籤的核酸序列可以在與編碼HBV前核心蛋白的核酸序列(編碼HBV前核心蛋白的核酸序列例如在SEQ ID NO:15中顯示)的位置87和88相對應的核苷酸之間(插入)。在蛋白質水平,一個或多個標籤可以在與B型肝炎病毒前核心蛋白(前核心蛋白的胺基酸例如在SEQ ID NO:17中顯示)的位置29和30相對應的胺基酸殘基之間插入。這些位置在嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構中或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構中界定了接頭的編碼性序列和編碼嗜肝DNA病毒核心蛋白的核酸序列的ORF起始密碼子。相對於HBV,位置87是編碼接頭的序列的最末3』核苷酸並且位置88是編碼核心蛋白的序列的第一個核苷酸。可以容易確定嗜肝DNA病毒HBV前核心蛋白中的相應位置(即嗜肝DNA病毒基因組中與編碼HBV前核心蛋白的核酸序列的位置87和88對應的位置)。
同樣地,編碼一個或多個標籤的核酸序列可以在編碼嗜肝DNA病毒前核心蛋白的N端信號肽和接頭的核酸序列和編碼嗜肝DNA病毒核心蛋白的核酸序列之間(插入)。
例如,該核酸序列可以在與編碼HBeAg的核酸序列(編碼HBeAg的核酸序列例如在SEQ ID NO:16中顯示)的位置30和31相對應的核苷酸之間(插入)。在蛋白質水平,一個或多個標籤可以在與HBeAg(HBeAg的胺基酸例如在SEQ ID NO:18中顯示)的位置10和11相對應的胺基酸殘基之間插入。這些位置界定了前核心蛋白中嗜肝DNA病毒N末端接頭的編碼性序列(或嗜肝DNA病毒e抗原中嗜肝DNA病毒N末端接頭的編碼性序列)和編碼嗜肝DNA病毒核心蛋白的核酸序列的ORF起始密碼子。相對於HBV,位置30是編碼HBeAg的核酸序列中編碼接頭的序列的最末3』核苷酸。位置31是編碼核心蛋白的序列的第一個核苷酸。可以容易確定編碼嗜肝DNA病毒e抗原的核酸序列中的相應位置(即嗜肝DNA病毒e抗原中與編碼HBeAg的核酸序列的位置30和31對應的位置)。
編碼一個或多個標籤的核酸可以在編碼嗜肝DNA病毒核心蛋白、優選地HBV核心蛋白的核酸的5』上遊(插入)。編碼HBV核心蛋白的示例性核酸在SEQ ID NO:23中顯示。HBV核心蛋白的示例性胺基酸序列在SEQ ID NO:24中顯示。換而言之,編碼一個或多個標籤的核酸序列可以在嗜肝DNA病毒pgRNA的、優選地HBV pgRNA的ε結構或如嗜肝DNA病毒基因組(優選地,HBV基因組)編碼的ε結構和編碼嗜肝DNA病毒核心蛋白、優選地HBV核心蛋白的核酸序列的ORF起始密碼子之間插入。
如上文提到,本文中待使用/提供的核酸分子可以包含編碼一個或多個標籤的序列,其中所述序列插入嗜肝DNA病毒pgRNA、優選地HBVpgRNA的ε結構,或插入如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構。圖1中顯示HBV基因組編碼的示例性ε結構。相對於HBV,如HBV基因組編碼的ε結構始於(並且包括)HBV基因組的位置T1849並止於(並且包括)其位置A1909。HBV基因組編碼的ε結構的示例性核酸序列在SEQ ID NO:25中顯示。
如上文所述,包含編碼一個或多個標籤的序列的核酸分子可以插入嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖中。如HBV基因組編碼的ε結構的示例性下部莖在SEQ ID NO:1中顯示。例如,編碼一個或多個標籤的核酸序列可以插入與編碼HBV前核心蛋白的核酸序列(編碼HBV前核心蛋白的核酸序列例如在SEQ ID NO:15中顯示)的位置87和88相對應的核苷酸之間、或與編碼HBeAg的核酸序列(編碼HBeAg的核酸序列例如在SEQ ID NO:16中顯示)的位置30和31相對應的核苷酸之間或與HBV基因組的位置C1902和位置A1903相對應的核苷酸之間。全部這些位置均在嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖中或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖中。
本文中構思和優選,核酸分子在編碼一個或多個標籤的序列的5』包含能夠與嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖形成鹼基對的序列。認為本文中相對於B型肝炎病毒/加標籤的B型肝炎病毒e抗原描述和提供的實驗和教導內容總體上適用於嗜肝DNA病毒/加標籤的嗜肝DNA病毒e抗原。對於每種具體的嗜肝DNA病毒、優選地HBV,對用於HBV的插入序列的唯一修飾可以涉及修飾編碼(表位)標籤的核酸序列的5』側翼序列以維持嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε、或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε的鹼基配對。基於本發明的教導內容,本領域技術人員能容易地設計並製備編碼標籤的核酸序列的5』的核酸序列以維持與嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的鹼基配對。特別地就鴨B型肝炎病毒(DHBV)而言,由於其核心蛋白ORF的起始密碼子位於ε的下遊,因此甚至不需要引入編碼(表位)標籤的核酸序列的5』側翼序列以維持DHBV的ε的鹼基配對。
如圖1中所示,核酸序列插入與HBV基因組的位置C1902和A1903相對應的核苷酸之間,其中所述核酸序列含有9個核苷酸的5』-側翼區(即編碼一個或多個標籤的核酸序列的5』),所述5』側翼區與嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖(例如與對應於HBV基因組位置T1849至T1855的核苷酸)形成鹼基對。
本發明的一個重要和優選方面是,如本文定義和/或如上文所述待插入的編碼一個或多個標籤的核酸序列還包含這樣的核酸序列,其能夠與嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構形成鹼基對,尤其與嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖形成鹼基對。通過使用能夠與ε結構形成鹼基對的核酸序列,目的在於保留嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構。轉而,認為ε結構對複製、產生cccDNA和表達/產生(加標籤的)嗜肝DNA病毒e抗原、優選地HBVe抗原重要。
優選地,能夠與嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖形成鹼基對的序列能夠與優選地對應於位置T1849至A1854或任選地對應於HBV基因組位置T1849至T1855的核苷酸形成鹼基對。一般,pgRNA中的鹼基對形成在匹配的核糖核苷酸如A-U、G-C和搖擺鹼基對G-U之間發生。如果維持ε結構,則複製、產生cccDNA和/或表達/產生(加標籤的)嗜肝DNA病毒e抗原在本文中待使用/提供的核酸分子中不受阻礙。
應當指出,ε結構的左臂是編碼嗜肝DNA病毒e抗原(如HBeAg)信號肽的核酸序列的組成部分並且因此應當是保持不變。如所述那樣在ε的右臂處設計的插入不應當改變下部莖的鹼基配對。在圖1中顯示的例舉插入中,唯一核苷酸變化與A1903G相關(即在HBV基因組位置1903處A替換為G)。在位置1903處的點突變從嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε移出核心蛋白ORF、因而允許維持ε結構和在核心蛋白AUG前方插入標籤。核心蛋白從前核心蛋白ORF的起始密碼子後轉錄的前基因組RNA翻譯,從而標籤將不併入核心蛋白。
能夠與嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構(的下部莖)或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構(的下部莖)、嗜肝DNA病毒基因組的ε結構(的下部莖)形成鹼基對的表位標籤5』側翼序列由至多3、6或9個核苷酸、一般9個核苷酸組成。
能夠與嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖形成鹼基對的示例性序列由SEQ ID NO:26中所示的序列組成。能夠與嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖形成鹼基對的示例性序列編碼如SEQ ID NO:40中所示的多肽。
本文中待使用/提供的核酸分子還可以在編碼一個或多個標籤的序列的3』包含編碼接頭的核酸序列。接頭可以由一個或多個胺基酸殘基組成。優選地,接頭僅由一個胺基酸殘基如甘氨酸殘基組成。
例如,編碼接頭的核酸序列由序列GGC組成;或核酸序列編碼甘氨酸殘基。GGC從核心蛋白ORF的AUG前方的原始3個核苷酸拷貝而來、所述3個核苷酸與AUG一起裝配成用於最佳翻譯起始的常見Kozak基序。因此,可以使用/插入的接頭優選地並適當地選擇,從而保持核心蛋白起始密碼子的可靠Kozak基序。
例如,包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子可以包含如SEQ ID NO:41中所示的核酸序列。例如,包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子可以包含編碼如SEQ ID NO:42中所示的胺基酸序列的核酸序列。如SEQ ID NO:41中所示的示例性核酸序列由能夠與ε結構(的下部莖)形成鹼基對的核酸序列(GTGGACATC;尤其核苷酸GTGGACAT與對應於HBV基因組位置T1849至T1855的核苷酸形成鹼基對)、編碼HA標籤的核酸序列和編碼甘氨酸殘基作為接頭的核酸序列(後一種核酸序列主要用來保持核心蛋白起始密碼子的可靠Kozak基序)組成。
本文中構思了一個或多個標籤符合可讀框地融合入嗜肝DNA病毒e抗原、優選地B型肝炎病毒e抗原(HBeAg)。同樣地,本文中構思了,編碼一個或多個標籤的核酸序列(連同能夠與ε結構(的下部莖)形成鹼基對的潛在5』側翼核酸序列和/或連同保持核心蛋白起始密碼子的可靠Kozak基序或編碼接頭的潛在3』核酸序列)符合可讀框地融合於編碼嗜肝DNA病毒e抗原、優選地B型肝炎病毒e抗原(HBeAg)的核酸序列。
本發明中待使用和提供的核酸分子可以包含嗜肝DNA病毒基因組、優選地B型肝炎病毒(HBV)基因組。例如,HBV基因組是HBV基因型A、B、C、D、E、F、G或H的基因組。本文待用的HBV基因組的示例性非限制核酸序列在SEQ ID NO:27、28、29、30、31、32、33或34中顯示。HBV基因組可以是HBV基因型D的基因組,尤其HBV亞基因型ayw的基因組(如SEQ ID NO:27中所示的HBV基因組)。
根據本發明,僅允許(大量)表達/產生(加標籤的)嗜肝DNA病毒e抗原的那些核酸分子,如嗜肝DNA病毒基因組才會使用。例如,已知不允許大量表達/產生嗜肝DNA病毒e抗原的一些臨床HBV變體。在一些臨床HBV變體中,HBeAg陰性歸因於基礎核心啟動子(BCP)雙突變(基因型D中A1764T/G1766A)或前核心蛋白(pC)突變(基因型D中G1898A)。在BCP突變通過下調前核心蛋白mRNA轉錄減少HBeAg的同時,pC突變引入過早終止密碼子以阻礙前核心蛋白翻譯。這類嗜肝DNA病毒變體較不適用於本文提供的方法。
在本發明的一個優選實施方案中,加標籤的HBeAg包含如SEQ ID NO:22中所示的胺基酸序列或由其組成。編碼加標籤的HBeAg的相應核酸序列在SEQ ID NO:20中顯示。這些序列在本發明的背景下特別有用,但是僅為優選實施方案的例子。
編碼加HA標籤的前核心蛋白(即加標籤的HBeAg的前體)的核酸序列在SEQ ID NO:19中顯示。因為這種核酸序列編碼加標籤的HBeAg的前體,它可以視為編碼加標籤的HBeAg的核酸序列。相應的胺基酸序列在SEQ ID NO:21中顯示。
下文更詳細地涉及產生加標籤的嗜肝DNA病毒e抗原及其評估候選分子抑制嗜肝DNA病毒cccDNA的能力的用途。
文中待使用/提供的核酸可以轉錄成前基因組(pg)嗜肝DNA病毒RNA、尤其前基因組(pg)HBV RNA。
本文中構思了所述核酸可以設計成阻止加標籤的嗜肝DNA病毒e抗原的翻譯。例如,核酸不含有在編碼加標籤的嗜肝DNA病毒e抗原的核酸5』上遊的起始密碼子ATG。相對於HBV,編碼前核心蛋白的核酸的起始密碼子可以缺失或突變。例如,這種(待缺失/突變的)起始密碼子可以對應在(並包括)HBV基因組位置1816至(並包括)位置1818處的核苷酸;參見例如圖1。
避免翻譯加標籤的嗜肝DNA病毒e抗原可能是有利的,目的是避免其在測定法開始時產生/表達。本發明的目的是使用加標籤的嗜肝DNA病毒e抗原作為cccDNA的替代標記。如果加標籤的嗜肝DNA病毒e抗原在全部時間均產生,則其表達/產生並必然地與產生cccDNA相關。如圖5中所示,起始密碼子可以在cccDNA形成時/之後在測定法的後期恢復,從而加標籤的嗜肝DNA病毒e抗原的表達/產生(即水平)真實反映嗜肝DNA病毒cccDNA的產生/水平。因此,為了甚至更可靠地評估候選分子抑制cccDNA的能力,以下情況是有利:在測定法開始時抑制加標籤的嗜肝DNA病毒e抗原的產生/表達,例如通過移除編碼該抗原的相應核酸的起始密碼子/使其突變,以及允許稍後產生/表達加標籤的嗜肝DNA病毒e抗原以反映嗜肝DNA病毒cccDNA的產生/水平。
例如,在如上文限定和描述的編碼加標籤的嗜肝DNA病毒e抗原的核酸5』上遊的起始密碼子ATG可以由核酸TG替換。因此,本文中待使用和提供的核酸分子可以例如通過點突變修飾,以阻止加標籤的嗜肝DNA病毒e抗原的翻譯。
根據本發明待使用的方法的步驟(a)還可以包含步驟(aa),所述驟(aa)包括在以下條件培養包含核酸分子的細胞,所述核酸分子包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列,所述條件允許
(i)合成嗜肝DNA病毒前基因組(pg)RNA;
(ii)逆轉錄所述合成的pgRNA成為負鏈DNA;
(iii)合成第二正鏈DNA,從而所述負鏈DNA和所述正鏈DNA形成雙鏈鬆弛型環狀DNA;
(iv)從所述鬆弛型環狀雙鏈DNA形成cccDNA;
(v)恢復允許翻譯加標籤的嗜肝DNA病毒e抗原的條件;
(vi)轉錄編碼加標籤的嗜肝DNA病毒e抗原的mRNA;
(vii)翻譯加標籤的嗜肝DNA病毒e抗原;
恢復允許翻譯加標籤的嗜肝DNA病毒e抗原的條件可以涉及或是恢復如上文定義和解釋的起始密碼子。
包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子可以包含於載體、尤其表達載體中。
載體可以例如包含如SEQ ID NO:35中所顯示的序列。
包含編碼加標籤的嗜肝DNA病毒e抗原、優選地B型肝炎病毒e抗原(HBeAg)的核酸序列的核酸分子可以在誘導型啟動子的控制下。本文待用的示例性非限制誘導型啟動子是四環素誘導型啟動子、強力黴素誘導型啟動子、抗生素誘導型啟動子、銅誘導型啟動子、醇誘導型啟動子、類固醇誘導型啟動子、或除草劑誘導型啟動子。在本文提供的實驗中使用的四環素誘導型啟動子(從例如Clontech可商業獲得)以tet-off方式工作。認為以tet-on方式工作的四環素誘導型啟動子可以同樣地在本文中使用。tet-on/off系統例如從Clontech和Invitrogen可獲得或者在質粒或病毒(逆轉錄病毒、腺病毒)主鏈中。除了四環素/強力黴素誘導型啟動子外,如上文所述的例如響應於抗生素、銅、醇、類固醇、或除草劑連同其他化合物的其他誘導型啟動子也是合適的。例如,誘導型啟動子是CMV啟動子。誘導型啟動子可以是tet-EF-1α啟動子。
另外,可以將一個或多個終止密碼子引入一種或多種嗜肝DNA病毒包膜蛋白的編碼區,如一種或多種嗜肝DNA病毒包膜蛋白是一種或多種HBV包膜蛋白。一種或多種嗜肝DNA病毒(HBV)包膜蛋白可以是表面大蛋白(L)、表面中等蛋白(M)和表面小蛋白(S)的一者或多者。在一個實施方案中,HBV包膜蛋白是表面小蛋白(S)。一種或多種HBV包膜蛋白的示例性編碼區在SEQ ID NO:36(L)、SEQ ID NO:37(M)和/或SEQ ID NO:38(S)中顯示。在HBV中,可以將SEQ ID NO:38(S)的HBV核苷酸217至222(TTGTTG)突變成例如TAGTAG以阻止包膜蛋白的表達。
如果cccDNA的替代標記即加標籤的嗜肝DNA病毒e抗原的(表達)水平與對照相比降低,則確定候選分子能夠抑制嗜肝DNA病毒cccDNA。
應當理解加標籤的嗜肝DNA病毒e抗原的評估(表達)水平與對照比較,如加標籤的嗜肝DNA病毒e抗原的評估(表達)水平的標準或參比值。可以在尚未與候選分子接觸的如本文定義的細胞、組織或非人類動物中評估對照(標準/參比值)。備選地,可以在上述接觸步驟之前在如本文定義的細胞、組織或非人類動物中評估對照(標準/參比值)。與候選分子接觸時加標籤的嗜肝DNA病毒e抗原的(表達)水平下降也可以是與常規使用的參比化合物(如已知不能抑制cccDNA的化合物)誘導的加標籤的嗜肝DNA病毒e抗原的(表達)水平下降比較。技術人員容易地處於確定/評估加標籤的嗜肝DNA病毒e抗原的(表達)水平是否降低的地位。
反之和在不背離本發明精神的情況下,可以使用陽性對照,例如,參比化合物,如已知能夠抑制cccDNA的化合物。如果與這種(陽性)對照相比,cccDNA的替代標記即加標籤的嗜肝DNA病毒e抗原的(表達)水平等同或甚至增加,則確定候選分子能夠抑制嗜肝DNA病毒cccDNA。
根據本發明,尤其本文所述的篩選或確定方法,細胞、組織或非人類動物將與包含核酸分子的候選分子接觸,其中所述核酸分子包含編碼如本文定義的加標籤的嗜肝DNA病毒e抗原的核酸序列。
例如,所述細胞、組織或非人類動物可以能夠表達如本文定義的加標籤的嗜肝DNA病毒e抗原。如本文中解釋,可以因此通過測量編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的這類基因產物的表達水平、尤其蛋白質表達水平,檢測候選分子抑制/拮抗cccDNA的能力。(與對照(標準或參比值)相比的)(較)低(蛋白質)表達水平指示了候選分子充當抑制劑/拮抗劑的能力。
歸因於降低的轉錄物/表達水平,翻譯的基因產物(即蛋白質水平)的水平也將降低。上述加標籤的嗜肝DNA病毒e抗原蛋白的(蛋白質)水平一般與加標籤的嗜肝DNA病毒e抗原蛋白相關的可檢測信號的信號強度相關。示例性加標籤的嗜肝DNA病毒e抗原蛋白包含可以包含如上文所述的報導分子(例如螢光素酶、(綠色/紅色)螢光蛋白及其變體、EGFP(增強型綠色螢光蛋白)等)。
因此,細胞/組織/非人類動物與候選分子接觸時報導分子信號下降將顯示候選分子的確是cccDNA抑制劑/拮抗劑並且因此能夠抑制cccDNA。從測試的候選分子選出降低如上文定義的加標籤的嗜肝DNA病毒e抗原的水平的候選分子,其中優選地選擇強烈降低加標籤的嗜肝DNA病毒e抗原的水平的那些分子(例如以報導分子信號下降反映)。
在本發明的上下文(尤其,本文所公開的篩選/鑑定方法)中構思,還可以接觸細胞提取物(例如包含核酸分子的細胞提取物,所述核酸分子包含編碼如本文中描述和定義的加標籤的嗜肝DNA病毒e抗原的核酸序列)。例如,這些細胞提取物可以從本文待用、尤其待接觸候選分子的(轉基因/基因工程化)細胞、組織和/或非人類動物獲得。
使用這類細胞提取物是特別有利的,因為它允許在體外評估候選分子的活性。利用這類(細胞)提取物的評估/篩選方法可以例如用於預篩選候選分子,其中,在這種預篩選中選出的分子隨後接受後續篩選,例如在本文所公開的基於細胞的方法、尤其在(轉基因)細胞、組織和/或非人類動物與候選分子接觸的方法中接受後續篩選。在這種情況下,因此優選已經在上文和下文所述的體外預篩選方法中選出候選分子。
因此,如本文所用的術語「細胞」涵蓋(轉基因/基因工程化)細胞、(轉基因/基因工程化)組織和/或(轉基因/基因工程化)非人類動物並且還涵蓋從中衍生的細胞提取物。
應當理解常規地在高通量篩選中,同時篩選許多(經常數千種)候選分子。因此,在(第一)次篩選中,選出降低加標籤的嗜肝DNA病毒e抗原的水平的候選分子。
也可以通過添加含有所述候選分子或多種候選分子(即各種不同候選分子)的(生物)樣品或組合物至待分析的細胞(包含核酸分子的細胞/組織/非人類動物,所述核酸分子包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列),實現本發明篩選方法的步驟(a),即「接觸步驟」。
通常,候選分子或包含/含有候選分子的組合物可以例如添加至包含核酸分子的(轉染的)細胞、組織或非人類動物,所述核酸分子包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列。如本文定義和公開、術語「包含了包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子」暗示使用報導分子。還可以在本文中使用包含啟動子和/或增強子區域的報導分子構建體。
在本發明中、尤其在篩選/鑑定方法的上下文中待使用或提供的細胞、組織和/或非人類動物可以用包含編碼本文公開的加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子穩定或瞬時染。
能夠抑制cccDNA(如反映為加標籤的嗜肝DNA病毒e抗原的水平降低)的化合物/分子預計作為本文公開的藥物背景下的物質有益並且用於醫學目的,尤其用於治療與嗜肝DNA病毒相關的疾病、尤其與嗜肝DNA病毒相關的慢性病,如慢性肝炎和尤其慢性B型肝炎。
可以作為嗜肝DNA病毒cccDNA的特異性「拮抗劑」或「抑制劑」發揮作用的候選分子/化合物可以是小結合分子如小分子(有機)化合物。
在藥物發現背景下,術語「小分子」是本領域已知的並且指具有小於2,500道爾頓、優選地小於1,000道爾頓、更優選地50和350道爾頓之間分子量的醫用化合物。(小)結合分子包含天然化合物以及合成性化合物。術語「化合物」(或同樣地「分子」)在本發明的背景下包括單一物質或多種物質。所述化合物/分子可以例如包含於樣品(例如來自植物、動物或微生物的細胞提取物)中。另外,所述化合物可以是本領域已知的,但是迄今未知能夠(不利)影響嗜肝DNA病毒cccDNA。可以將多種化合物例如在體外添加至樣品、添加至培養基或注入細胞。
候選物質還可以包含與蛋白質結構性相互作用必需的官能團、尤其氫鍵,並且一般包含至少胺、羰基、羥基或羧基,優選地至少兩種功能性化學基團。候選物質經常包含經一個或多個上述官能團取代的碳環結構或雜環結構和/或芳族或多芳族結構。
示例類別的候選物質可以包括雜環、肽、糖、類固醇等。可以修飾化合物以提高效力、穩定性、藥物相容性等。物質的結構性鑑定可以用來鑑定、產生或篩選額外的物質。例如,在鑑定到肽物質的情況下,可以將它們按多種方式修飾以增強其穩定性,如使用非天然胺基酸,如D-胺基酸、尤其L-丙氨酸,通過使氨基末端或羧基末端官能化,例如對於氨基,醯化或烷基化、並且對於羧基,酯化或酸化等,進行修飾。其他穩定方法可以包括囊化,例如,在脂質體中囊化等。
如上文提到,候選物質還存在其他生物分子中,所述其他生物分子包括胺基酸、脂肪酸、嘌呤、嘧啶、核酸和衍生物、其結構類似物或組合。候選物質從多種來源獲得,所述來源包括合成或天然化合物文庫。例如,多種手段可用於隨機和定向合成多種有機化合物和生物分子,所述手段包括表達隨機化的寡核苷酸和寡肽。可選地,處於細菌提取物、真菌提取物、植物提取物和動物提取物形式的天然化合物文庫是可獲得的或容易地產生。額外地,通過常規的化學、物理和生物化學手段容易修飾天然或合成產生的文庫和化合物,並且它們可以用來產生組合文庫。已知的藥理學物質可以經歷定向或隨機化學修飾,如醯化、烷基化、酯化、酸化等,以便產生結構類似物。
本發明中還構思,可以評估化合物/分子抑制cccDNA的能力,所述化合物/分子尤其包括肽、蛋白質、核酸(包括cDNA表達文庫)、小分子有機化合物、配體、PNA等。所述化合物也可以是功能性衍生物或類似物。
用於製備化學衍生物和類似物的方法是本領域技術人員熟知的並且在例如Beilstein,"Handbook of Organic Chemistry",Springer Edition New York或在"Organic Synthesis",Wiley,New York中描述。另外,可以根據本發明檢驗所述衍生物和類似物的作用,即它們對cccDNA的拮抗作用。
另外,可以使用適宜的cccDNA拮抗劑或抑制劑的肽模擬物和/或計算機輔助設計。本領域中描述了用於計算機輔助設計例如蛋白質和肽的適宜計算機系統述,例如,在Berry(1994)Biochem.Soc.Trans.22:1033-1036;Wodak(1987),Ann.N.Y.Acad.Sci.501:1-13;Pabo(1986),Biochemistry 25:5987-5991中描述。從上述計算機分析獲得的結果可以與本發明的方法組合用於例如優化已知的化合物、物質或分子。也可以通過連續化學修飾法合成肽模似物組合文庫並(例如,根據本文所述的方法)檢驗所產生的化合物,鑑定適宜的化合物。現有技術中描述了用於生成和使用肽模似物組合文庫的方法,例如在Ostresh(1996)Methods in Enzymology 267:220-234和Dorner(1996)Bioorg.Med.Chem.4:709-715中描述。另外,cccDNA拮抗劑的三維和/或結晶學結構可以用於設計cccDNA的(肽模擬物)拮抗劑(Rose(1996)Biochemistry35:12933-12944;Rutenber(1996)Bioorg.Med.Chem.4:1545-1558)。
尤其可以通過用包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子轉染適宜的宿主並使所述宿主與候選分子接觸,鑑定/評估能夠抑制cccDNA的候選分子。
本文待用的細胞/宿主優選地是真核細胞、尤其是肝細胞來源的真核細胞。真核細胞優選地是肝瘤細胞或肝細胞。真核細胞也可以衍生自肝瘤細胞或肝細胞。本文待用的優選細胞是真核細胞HepG2(ATCC#HB-8065)。HepG2細胞已知支持功能性HBV cccDNA形成和轉錄。本文中構思使用其他細胞,如肝細胞衍生的細胞(例如Huh7)。也可以根據本發明使用非肝細胞/宿主,前提是它們支持嗜肝DNA病毒cccDNA形成(或在更廣意義下,嗜肝DNA病毒DNA複製)。例如,如果將病毒前基因組RNA引入細胞或通過外源啟動子從DNA模板轉錄,則可以修飾這種非肝細胞/宿主以支持嗜肝DNA病毒cccDNA形成(或嗜肝DNA病毒DNA複製)。如果在這類非肝細胞中反式補足肝特異性轉錄因子,則cccDNA轉錄可以進行。本發明的核酸分子或包含前者的載體可以穩定整合在細胞的基因組中。
根據本發明待使用的核酸分子(即包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子)或包含前者的載體優選地基本上由DNA組成。
上文就「細胞」方面給出的解釋還適用於並涵蓋包含或衍生自這些細胞的組織/非人類動物。本文待用的細胞可以包含於樣品(例如,生物學樣品、醫學樣品或病理學樣品)中。例如,構思了使用包含細胞、組織或細胞培養物的流體。這種流體可以是體液或還可以是分泌物並也可以是培養物樣品。體液可以包括但不限於血清、血漿、尿、唾液、滑液、脊液、腦脊液、淚、糞便等。
同樣地,候選分子可以包含於(生物)樣品或組合物中。(多種)候選分子經常接受第一次篩選。在第一次篩選中測試呈陽性的樣品/組合物可以接受後續篩選,以驗證此前結果並選出最強力的抑制劑/拮抗劑。依賴於多個篩選和選擇輪次,可以選出顯示明顯的如本文定義和公開的抑制/拮抗cccDNA的能力的那些候選分子。例如,含有多種候選分子的批次(即組合物/樣品)將復篩並且無候選分子抑制活性或候選分子抑制活性不足的批次在不復篩的情況下棄去。
例如,如果檢驗具有有多種候選分子的(生物)樣品或組合物並且一個(生物)樣品或組合物檢驗呈陽性,則隨後可能在第二次篩選中篩選、優選地在純化後篩選(生物)樣品或組合物的各個分子。也可以是在後續篩選中篩選第一次篩選的(生物)樣品或組合物的亞組。篩選具有此前篩選輪次中檢驗過的那些候選分子亞組的組合物將因此縮小潛在強力cccDNA抑制劑的範圍。這可以促進並加速篩選過程,尤其當篩選眾多分子時。因此,與第一次(和後續)篩選中檢驗每種和每個單個候選分子(這當然也還是可能的)相比,篩選輪次的循環次數減少。因此,取決於候選分子的複雜性或數目,本文所述的篩選方法的步驟可以進行幾次直至待篩選的(生物)樣品或組合物包含有限的數目、優選地僅一種物質,所述物質指示所篩選的分子降低加標籤的嗜肝DNA病毒e抗原水平的能力。
本文中構思使用允許在單個細胞水平或某組織的單個細胞水平(例如在亞細胞水平)解析例如螢光的光學測量技術。這些技術可以涉及螢光,例如共聚焦顯微術、數字圖像記錄,如CCD照相機和合適的圖像分析軟體。例如,通過執行對照在測量標準響應後實驗實施步驟(b)。例如,在第一次篩選中在不接觸候選分子情況下確定包含加標籤的嗜肝DNA病毒e抗原的細胞、組織或非人類動物中加標籤的嗜肝DNA病毒e抗原的水平。在第二次篩選中,在接觸候選分子後,測量/評估加標籤的嗜肝DNA病毒e抗原的水平。水平的差異顯示檢驗的候選分子是否的確為cccDNA的拮抗劑/抑制劑。
可以通過本文中所述的任何方法、尤其蛋白質測量/檢測/評估技術測量例如基因產物的水平(尤其加標籤的嗜肝DNA病毒e抗原的蛋白質水平),定量加標籤的嗜肝DNA病毒e抗原的水平。
例如,可以通過利用免疫凝集、免疫沉澱法(例如免疫擴散、免疫電泳、免疫固定)、蛋白質印跡技術(例如(原位)免疫組織化學、(原位)免疫細胞化學、親和色譜、酶免疫測定法)等在蛋白質水平確定表達。可以通過物理方法例如光度法確定溶液中已純化多肽的量。定量混合物中特定多肽的方法依賴於(例如抗體的)特異性結合作用。利用抗體特異性的特異性檢測和定量方法包含例如免疫組織化學(原位)。例如,可以通過酶聯免疫吸附測定法(ELISA)確定細胞、組織或非人類動物中加標籤的嗜肝DNA病毒e抗原蛋白水平的濃度/量。
本文中構思了根據步驟(b)評估加標籤的嗜肝DNA病毒e抗原的水平可以通過ELISA、CLIA或AlphaLISA進行。
本文提供的方法利用建立的標籤(如可以替代HA標籤使用或除HA標籤之外使用的HA標籤、或His標籤、Flag標籤、c-myc標籤、V5標籤或C9標籤)的用途。這些標籤可以用於純化和檢測加標籤的嗜肝DNA病毒e抗原。通過使用與標籤特異性結合的抗體(例如通過ELISA測定法,如化學發光-ELISA(CLIA)和AlphaLISA),可以可靠地及快速地評估加標籤的嗜肝DNA病毒e抗原的水平並且可以避免與核心蛋白的交叉反應。
根據本文所提供方法的步驟(b)評估加標籤的嗜肝DNA病毒e抗原的水平可以包括使用特異性識別所述嗜肝DNA病毒e抗原的抗體、優選地B型肝炎病毒e抗原(如,但不限於抗HBe:克隆29,批號20110305,Autobio Diagnostics)的抗體和特異性識別一個或多個標籤的一種或多種抗體(如,但不限於抗HA:目錄號A01244-100,Genscript)。
以下抗體特異性識別B型肝炎病毒e抗原並且可以根據本發明使用:
Imai等人,Demonstration of two distinct antigenic determinants on hepatitis B e antigen by monoclonal antibodies.J Immunol.1982Jan;128(1):69-72。
Ferns和Tedder.Monoclonal antibodies to hepatitis B antigen(HBeAg)derived from hepatitis B core antigen(HBcAg):their use in characterization and detection of HBeAg.J Gen Virol.1984May;65(Pt5):899-908。
Mondelli等人,Differential distribution of hepatitis B core and E antigens in hepatocytes:analysis by monoclonal antibodies.Hepatology.1986 6(2):199-204。
Stuckmann和Mushahwar.Re-examination and further characterization of a monoclonal antibody to hepatitis B e antigen(anti-HBe).J Virol Methods.1986Jul;13(4):351-62。
Korec等人,Monoclonal antibodies against hepatitis B e antigen:production,characterization,and use for diagnosis.J Virol Methods.1990May;28(2):165-9。
Usuda等人,A monoclonal antibody against a hepatitis B e antigen epitope borne by six amino acids encoded by the precore region.J Virol Methods.1997Nov;68(2):207-15。
Sogut等人,Monoclonal antibodies specific for hepatitis B e antigen and hepatitis B core antigen.Hybridoma(Larchmt).2011Oct;30(5):475-9。
備選地,可以進行蛋白質印跡分析或免疫組織化學染色。蛋白質印跡法組合了通過電泳法分離蛋白質混合物和用抗體特異性檢測。電泳可以是多維的如2D電泳。通常,多肽在2D電泳中依照其表觀分子量沿一個維度分離並且依照其等電點沿另一個方向分離。
技術人員能夠通過利用檢測信號強度和待確定的例如多肽/蛋白質的量之間的相關性、優選地線性相關性,確定上文所述的多肽/蛋白質、尤其基因產物的量。因此,加標籤的嗜肝DNA病毒e抗原的水平可以基於加標籤的嗜肝DNA病毒e抗原的蛋白質水平定量。技術人員是知曉待用於確定樣品中加標籤的嗜肝DNA病毒e抗原蛋白表達產物水平的量/濃度的標準方法或可以從標準教材(例如Sambrook,2001)推導出相應方法。
如果加標籤的嗜肝DNA病毒e抗原(或相應報導分子信號)的水平強烈地降低、優選地很低或不可檢出,則選出候選分子。例如,與(對照)標準值相比,加標籤的嗜肝DNA病毒e抗原(或相應報導分子信號)的水平可以降低至少50%、60%、70%、80%、更優選地至少90%。
用於轉染細胞或組織的方法是本領域已知的。因此,磷酸鈣處理或電穿孔法可以用於轉染細胞或組織以表達所述報導分子構建體(參見Sambrook(2001),見上述引文)。另外,表達所述報導分子構建體的核酸分子可以重構入脂質體以遞送至靶細胞。作為又一種備選,可以使用基因工程病毒載體轉導細胞以表達特定報導分子構建體。
在另一個實施方案中,包含用於檢測cccDNA抑制作用的所述報導分子構建體的非人類動物是轉基因非人類動物。所描述的篩選分析法中待使用的非人類生物可以選自秀麗隱杆線蟲(C.elegans)、酵母、果蠅、斑馬魚、豚鼠、大鼠和小鼠。產生這種轉基因動物處於技術人員的技能範圍內。相應的技術尤其在「Current Protocols in Neuroscience」(2001),John Wiley&Sons,第3.16章中描述。
因此,本發明還涉及一種用於產生非人類轉基因動物的方法,所述方法包括步驟:將包含編碼如本文中公開的加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子引入ES-細胞或生殖細胞中。本文提供和描述的非人類轉基因動物特別可用於上文所述的篩選方法和藥理學試驗中。本文所述的非人類轉基因動物可以用於藥物篩選分析法中以及用於其中追蹤、選擇和/或分離治療嗜肝DNA病毒相關疾病的cccDNA拮抗劑/抑制劑的科學研究和醫學研究中。
在本發明背景、尤其篩選/鑑定方法下待使用的轉基因/基因工程細胞、組織和/或非人類動物包含本文描述和定義的包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子。
本發明涉及使用細胞、組織或非人類動物篩選和/或驗證疑似作為嗜肝DNA病毒cccDNA的抑制劑的化合物。
如本文所用的術語「轉基因非人類動物」、「轉基因細胞」或「轉基因組織」,指不是人類的包含相應野生型動物、組織或細胞的不同遺傳物質的非人類動物、組織或細胞。術語「遺傳物質」在這種背景下可以是任何種類的核酸分子或其類似物,例如如本文定義的核酸分子或其類似物。術語「不同」意指與野生型動物或動物細胞的基因組相比附加或較少的遺傳物質。待用於產生轉基因細胞/動物的不同表達系統的概述例如參見Methods in Enzymology 153(1987),385-516、Bitter等人(Methods in Enzymology 153(1987),516-544)和Sawers等人(Applied Microbiology and Biotechnology 46(1996),1-9)、Billman-Jacobe(Current Opinion in Biotechnology 7(1996),500-4)、Hockney(Trends in Biotechnology 12(1994),456-463)、Griffiths等人,(Methods in Molecular Biology 75(1997),427-440)。
本發明涉及如上文定義的核酸分子,即包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子。上文給出的解釋和定義在已作必要修正的情況下適用於此處。嗜肝DNA病毒e抗原優選地是B型肝炎病毒e抗原(HBeAg)。
加標籤的嗜肝DNA病毒e抗原可以含有僅一個標籤。標籤可以由6至22個胺基酸組成。常見的和本文中優選的(表位)標籤由8、9、10或11個胺基酸組成。6xHis是可以在本文中使用的最小表位標籤。可能的是,少於6個胺基酸的插入可以與毗鄰的HBeAg胺基酸一起裝配成新表位,從而這種插入還產生加標籤的嗜肝DNA病毒。標籤可以是血凝素(HA)標籤、His標籤、Flag標籤、c-myc標籤、V5標籤或C9標籤。Flag標籤可以是1×Flag標籤或3×Flag標籤。
加標籤的嗜肝DNA病毒e抗原可以含有兩個或更多個標籤。兩個或更多個標籤優選地是不同的標籤。所述兩個或更多個標籤的整個長度可以是約12個至約31個胺基酸。例如,兩個或更多個標籤的整個長度可以是12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或31個胺基酸。兩個或更多個標籤可以是以下兩者或更多者:HA標籤、His標籤、Flag標籤、c-myc標籤、V5標籤和/或C9標籤。Flag標籤可以是1×Flag標籤或3×Flag標籤。
編碼標籤的示例性核酸序列是如SEQ ID NO:1中所示的編碼HA標籤的核酸序列、如SEQ ID NO:2中所示的編碼His標籤的核酸序列;如SEQ ID NO:4中所示的編碼c-myc標籤的核酸序列、如SEQ ID NO:5中所示的編碼V5標籤的核酸序列、和/或如SEQ ID NO:6中所示的編碼C9標籤的核酸序列。
編碼Flag標籤的示例性核酸序列是如SEQ ID NO:3中所顯示的編碼1×Flag標籤的核酸序列或如SEQ ID NO:7中所顯示的編碼3×Flag標籤的核酸序列。
標籤的示例性胺基酸序列是如SEQ ID NO:8中所示的HA標籤的胺基酸序列、如SEQ ID NO:9中所示的His標籤的胺基酸序列、如SEQ ID NO:11中所示的c-myc標籤的胺基酸序列、如SEQ ID NO:12中所示的V5標籤的胺基酸序列和/或如SEQ ID NO:13中所示的C9標籤的胺基酸序列。
Flag標籤的示例性胺基酸序列是如SEQ ID NO:10中所顯示的1×Flag標籤的胺基酸序列或如SEQ ID NO:14中所顯示的3×Flag標籤的胺基酸序列。
編碼HBeAg的示例性核酸序列在SEQ ID NO:16中顯示。HBeAg的示例性胺基酸序列在SEQ ID NO:18中顯示。
核酸分子可以包含編碼嗜肝DNA病毒前核心蛋白的核酸序列。編碼嗜肝DNA病毒前核心蛋白的示例性核酸序列在SEQ ID NO:15中顯示。嗜肝DNA病毒前核心蛋白的示例性胺基酸序列在SEQ ID NO:17中顯示。
核酸分子可以包含編碼一個或多個標籤的核酸序列,其中所述序列在編碼嗜肝DNA病毒前核心蛋白的N端信號肽和接頭的核酸序列的3'下遊(插入)。
編碼一個或多個標籤的核酸序列可以在編碼B型肝炎病毒前核心蛋白N端29個胺基酸的核酸序列的3'下遊(插入)。
核酸分子可以包含嗜肝DNA病毒基因組。優選地,嗜肝DNA病毒基因組是B型肝炎病毒(HBV)基因組。HBV基因組可以是HBV基因型A、B、C、D、E、F、G或H的基因組。HBV基因組可以是HBV基因型D的基因組。優選地,HBV基因組是HBV基因型D亞基因型ayw的基因組。
編碼一個或多個標籤的核酸可以在編碼嗜肝DNA病毒核心蛋白、優選地HBV核心蛋白的核酸的5』上遊(插入)。編碼HBV核心蛋白的示例性核酸序列在SEQ ID NO:23中顯示。核心蛋白可以是HBV核心蛋白。HBV核心蛋白的示例性胺基酸序列在SEQ ID NO:24中顯示。
包含編碼一個或多個標籤的序列的核酸分子可以插入如本文定義的嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構中。如HBV基因組編碼的ε結構的示例性核酸序列在SEQ ID NO:25中顯示。包含編碼一個或多個標籤的序列的核酸分子可以插入嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖中。
將包含編碼一個或多個標籤的序列的核酸分子插入與HBV基因組的位置C1902和A1903相對應的核苷酸之間。
核酸分子可以在編碼一個或多個標籤的序列的5』包含能夠與嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖形成鹼基對的序列。優選地,能夠與嗜肝DNA病毒基因組、優選地HBV(編碼)的ε結構的下部莖形成鹼基對的序列主要能夠與優選地對應於位置T1849至A1854或任選地對應於HBV基因組位置T1849至T1855的核苷酸形成鹼基對。能夠與嗜肝DNA病毒基因組的ε結構的下部莖形成鹼基對的序列可以由(至多)9個核苷酸組成。
能夠與嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖形成鹼基對的示例性序列由SEQ ID NO:26中所示的序列組成。能夠與嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖形成鹼基對的示例性序列編碼如SEQ ID NO:40中所示的多肽。
核酸分子可以在編碼一個或多個標籤的序列的3』包含編碼接頭的序列。接頭可以由一個或多個胺基酸殘基組成。優選地,接頭僅由一個胺基酸殘基如甘氨酸殘基組成。編碼接頭的序列可以由序列GGC組成。編碼接頭的序列可以編碼甘氨酸殘基。編碼序列可以用於並適當地經選擇以保持核心蛋白起始密碼子的可靠Kozak基序。
核酸分子可以包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列,所述核酸序列包含如SEQ ID NO:41中所示的核酸序列。核酸分子可以包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列,所述核酸序列包含編碼如SEQ ID NO:42中所示的胺基酸序列的核酸序列。
一個或多個標籤優選符合可讀框地融合於嗜肝DNA病毒e抗原(或融合入嗜肝DNA病毒e前核心蛋白)、優選地B型肝炎病毒e抗原(HBeAg)(或融合入B型肝炎病毒前核心蛋白)中。
編碼加標籤的HBeAg的示例性核酸序列在SEQ ID NO:20中顯示。加標籤的HBeAg的優選胺基酸序列在SEQ ID NO:22中顯示。
編碼加標籤的B型肝炎病毒前核心蛋白的示例性核酸序在SEQ ID NO:19中顯示。加標籤的B型肝炎病毒前核心蛋白的示例性胺基酸序列在SEQ ID NO:21中顯示。
HBV基因組的示例性核酸序列在SEQ ID NO:27、28、29、30、31、32、33或34中顯示。
核酸可以轉錄成前基因組(pg)嗜肝DNA病毒RNA。嗜肝DNA病毒RNA優選地是HBV RNA。
包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子可以包含於載體如表達載體中。優選地,嗜肝DNA病毒e抗原是B型肝炎病毒e抗原(HBeAg)。
核酸通常允許加標籤的嗜肝DNA病毒e抗原、優選地B型肝炎病毒e抗原(HBeAg)的翻譯。核酸可以包含於包含如SEQ ID NO:39中所顯示的序列的載體中。
在某些實施方案中,核酸設計成阻止加標籤的嗜肝DNA病毒e抗原的翻譯。例如,核酸不含有在編碼加標籤的嗜肝DNA病毒e抗原的核酸5』上遊的起始密碼子ATG。例如,在編碼加標籤的嗜肝DNA病毒e抗原的核酸5』上遊的起始密碼子ATG可以由核酸TG替換。可以通過點突變修飾核酸以阻止加標籤的嗜肝DNA病毒e抗原的翻譯。載體可以包含如SEQ ID NO:35中所顯示的序列。
包含編碼加標籤的嗜肝DNA病毒e抗原、優選地B型肝炎病毒e抗原(HBeAg)的核酸序列的核酸分子可以在誘導型啟動子的控制下。
誘導型啟動子可以是四環素誘導型啟動子、強力黴素誘導型啟動子、抗生素誘導型啟動子、銅誘導型啟動子、醇誘導型啟動子、類固醇誘導型啟動子或除草劑誘導型啟動子。
誘導型啟動子可以優選地是CMV啟動子。誘導型啟動子可以是tet-EF-1α啟動子。
另外,可以將一個或多個終止密碼子引入一種或多種嗜肝DNA病毒包膜蛋白的、優選地一種或多種HBV包膜蛋白的編碼區。
一種或多種HBV包膜蛋白可以如下一者或多者:L、M和/或S。HBV包膜蛋白可以是S。
一種或多種HBV包膜蛋白的示例性編碼區(或編碼所述包膜蛋白的示例性核酸序列)在SEQ ID NO:36(L)、37(M)或38(S)中顯示。SEQ ID NO:38(S)的HBV核苷酸217至222(TTGTTG)可以突變成TAGTAG以阻止包膜蛋白的表達。
本發明涉及如上文定義和提供的核酸分子編碼的蛋白質。
該蛋白質包含加標籤的嗜肝DNA病毒e抗原、優選地加標籤的B型肝炎病毒e抗原(HBeAg)。
B型肝炎病毒e抗原(HBeAg)可以包含如SEQ ID NO:18中所示的胺基酸序列。優選地,加標籤的嗜肝DNA病毒e抗原僅含有一個標籤。
標籤可以由6至22個胺基酸組成。標籤可以是血凝素(HA)標籤、His標籤、Flag標籤、c-myc標籤、V5標籤或C9標籤。Flag標籤可以是1×Flag標籤或3×Flag標籤。
加標籤的嗜肝DNA病毒e抗原可以含有兩個或更多個標籤。優選地,兩個或更多個標籤是不同的標籤。所述兩個或更多個標籤的整個長度是約14個至約31個胺基酸。兩個或更多個標籤可以是以下兩者或更多者:HA標籤、His標籤、Flag標籤、c-myc標籤、V5標籤和/或C9標籤。Flag標籤可以是1×Flag標籤或3×Flag標籤。
編碼標籤的示例性核酸序列是如SEQ ID NO:1中所示的編碼HA標籤的核酸序列、如SEQ ID NO:2中所示的編碼His標籤的核酸序列;如SEQ ID NO:4中所示的編碼c-myc標籤的核酸序列、如SEQ ID NO:5中所示的編碼V5標籤的核酸序列、和/或如SEQ ID NO:6中所示的編碼C9標籤的核酸序列。
編碼Flag標籤的示例性核酸序列是如SEQ ID NO:3中所顯示的編碼1×Flag標籤的核酸序列或如SEQ ID NO:7中所顯示的編碼3×Flag標籤的核酸序列。
標籤的示例性胺基酸序列是如SEQ ID NO:8中所示的HA標籤的胺基酸序列、如SEQ ID NO:9中所示的His標籤的胺基酸序列、如SEQ ID NO:11中所示的c-myc標籤的胺基酸序列、如SEQ ID NO:12中所示的V5標籤的胺基酸序列和/或如SEQ ID NO:13中所示的C9標籤的胺基酸序列。
Flag標籤的示例性胺基酸序列是如SEQ ID NO:10中所顯示的1×Flag標籤的胺基酸序列或如SEQ ID NO:14中所顯示的3×Flag標籤的胺基酸序列。
蛋白質可以包含嗜肝DNA病毒前核心蛋白。編碼嗜肝DNA病毒前核心蛋白的示例性核酸序列在SEQ ID NO:15中顯示。嗜肝DNA病毒前核心蛋白的示例性胺基酸序列在SEQ ID NO:17中顯示。
該蛋白質可以包含一個或多個標籤的胺基酸序列,其中所述序列在嗜肝DNA病毒前核心蛋白的信號肽和接頭的胺基酸序列的C末端。該蛋白質可以在B型肝炎病毒前核心蛋白N端29個胺基酸的胺基酸序列的C末端包含一個或多個標籤的胺基酸序列。
該蛋白質可以包含一個或多個標籤的胺基酸序列,其中所述序列在嗜肝DNA病毒核心蛋白的胺基酸序列的N末端、優選地HBV核心蛋白的胺基酸序列的N末端。編碼HBV核心蛋白的示例性核酸在SEQ ID NO:23中顯示。HBV核心蛋白的示例性胺基酸序列在SEQ ID NO:24中顯示。
一個或多個標籤的胺基酸序列可以插入由嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構編碼的胺基酸序列中。如HBV基因組編碼的ε結構的示例性核酸序列在SEQ ID NO:25中顯示。一個或多個標籤的胺基酸序列可以插入由嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖編碼的胺基酸序列;優選插入由嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖編碼的胺基酸序列。
可以將一個或多個標籤的胺基酸序列插入與HBV前核心蛋白(如SEQ ID NO:17中所顯示的一種)的位置G29和位置M30相對應的胺基酸殘基之間。
該蛋白質還可以在一個或多個標籤的胺基酸序列的N末端包含(至多)3個胺基酸的胺基酸序列,其中所述至多3個胺基酸的胺基酸序列由能夠與嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖形成鹼基對的核酸序列編碼。能夠與嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖形成鹼基對的核酸序列主要能夠與優選地對應於位置T1849至T1855或任選地對應於HBV基因組位置T1849至T1855的核苷酸形成鹼基對。能夠與嗜肝DNA病毒pgRNA、優選地HBV pgRNA的ε結構的下部莖或如嗜肝DNA病毒基因組、優選地HBV基因組編碼的ε結構的下部莖形成鹼基對的示例性核酸序列由SEQ ID NO:26中所示的序列組成。(至多)3個胺基酸的示例性胺基酸序列在SEQ ID NO:40中顯示。
該蛋白質還可以在一個或多個標籤的胺基酸序列的C末端包含接頭。接頭可以由一個或多個胺基酸殘基組成。優選地,接頭僅由一個胺基酸殘基如甘氨酸殘基組成。
加標籤的嗜肝DNA病毒e抗原的胺基酸序列可以包含如SEQ ID NO:41中所顯示的核酸序列編碼的胺基酸序列。其中加標籤的嗜肝DNA病毒e抗原的胺基酸序列可以包含如SEQ ID NO:42中所顯示的胺基酸序列。
一個或多個標籤優選符合可讀框地融合入嗜肝DNA病毒e抗原、優選地B型肝炎病毒e抗原(HBeAg)。
編碼加標籤的HBeAg的示例性核酸序列在SEQ ID NO:20中顯示。優選地,加標籤的HBeAg具有如SEQ ID NO:22中所示的胺基酸序列。
編碼加標籤的HBV前核心蛋白的示例性核酸序列在SEQ ID NO:19中顯示。加標籤的HBV前核心蛋白的示例性胺基酸序列在SEQ ID NO:21中顯示。
本發明涉及包含如本文定義和提供的核酸分子的宿主細胞和/或涉及包含如本文定義和提供的蛋白質的宿主細胞。宿主細胞可以是真核細胞。真核細胞可以是肝細胞來源的。真核細胞可以是肝瘤細胞或可以衍生自肝瘤細胞。在一個優選實施方案中,真核細胞是HepG2(ATCC#HB-8065)。
本發明涉及用於產生如上文定義的蛋白質的方法,所述方法包括在允許蛋白質表達的條件下培養如上文定義的宿主並且從培養物回收產生的蛋白質。
本發明涉及用於本發明方法中的試劑盒。同樣地,本發明涉及篩選疑似能夠抑制嗜肝DNA病毒共價閉合環狀DNA的候選分子的試劑盒的用途。本文相對於評估候選分子抑制嗜肝DNA病毒cccDNA的能力的方法所提供的解釋在已作必要修正的情況下適用於此處。
試劑盒可以包含特異性識別如本文定義的嗜肝DNA病毒抗原e的抗體和特異性識別如本文定義的一個或多個標籤的一種或多種抗體。
本發明(在本發明背景下待製備)的試劑盒或本發明的方法和用途還可以包括或配有使用手冊。例如,所述使用手冊可以指導技術人員(如何)評估候選分子抑制cccDNA的能力和/或如何評估本發明加標籤的嗜肝DNA病毒e抗原的水平。特別地,所述使用手冊可以包含使用或應用本文提供的方法或用途的指導。
本發明(在本發明背景下待製備)的試劑盒還可以包含適於實施本發明方法和用途/本發明方法和用途所要求的物質/化學品和/或設備。例如,這類物質/化學品和/或設備是用於穩定和/或儲存化合物的溶劑、稀釋劑和/或緩衝液,所述化合物是特異性確定如本文定義的所述加標籤的嗜肝DNA病毒e抗原(蛋白質(表達))水平所需的。
本發明涉及如本文定義和提供的核酸分子、如本文定義和提供的蛋白質和/或如本文定義和提供的宿主細胞用於篩選疑似能夠抑制嗜肝DNA病毒共價閉合環狀DNA的候選分子的用途。本文相對於評估候選分子抑制嗜肝DNA病毒cccDNA的能力的方法所提供的解釋在已作必要修正的情況下適用於此處。
如本文所用,術語「包含」和「包括」或其語法變體將視為規定所述的特徵、整數、步驟或組分,但是不排除增加一個或多個附加特徵、整數、步驟、組分或其群組。這個術語涵蓋術語「由……組成」和「基本上由……組成」。因此,術語「包含」/「包括」/」具有」意指任何其他組分(或同樣意指任何其他特徵、整數、步驟等)可以存在。
術語「由……組成」意指無其他組分(或同樣意指無其他特徵、整數、步驟等)可以存在。
在本文中使用時,術語「基本上由……組成」或其語法變體將視為規定所述的特徵、整數、步驟或組分,但是不排除增加一個或多個附加特徵、整數、步驟、組分或其群組,但條件是上述附加特徵、整數、步驟、組分或其群組不實質地改變要求保護的組合物、裝置或方法的基本特徵和新特徵。
因此,術語「基本上由……組成」意指特定其他組分(或同樣地特定其他特徵、整數、步驟等)可以存在,即這些不實質地影響組合物、裝置或方法的必需特徵。換而言之,術語「基本上由……組成」(其可以在本文中與術語「基本上包含」互換使用)允許除強制性組分(或同樣地強制性特徵、整數、步驟等)之外的其他組分在組合物、裝置或方法中存在,前提是裝置或方法的必需特徵並未實質地受其他組分的存在影響。
術語「方法」指用於實現給出任務的方式、手段、技術和程序,包括但不限於化學、生物學和生物物理技術人員已知或從已知方式、手段、技術和程序容易開發的那些方式、手段、技術和程序。
如本文所用,術語「分離」指已經從其體內位置取出的組合物。優選地,本發明的分離的組合物或化合物基本上不含在其體內位置存在的其他物質(例如,其他蛋白質或其他化合物)(即純化或半純化的組合物或化合物)。
如本文所用術語「約」指±10%。
本發明參考以下非限制性圖和實施例進一步描述。
除非另外說明,否則既定的重組基因技術方法如通過引用方式完整併入本文的例如Sambrook,Russell"Molecular Cloning,A Laboratory Manual",Cold Spring Harbor Laboratory,N.Y.(2001)中所述那樣使用。
以下實施例說明本發明:
這些圖顯示:
圖1.HA標籤序列插入HBV前核心蛋白ORF中。
描述了HBV前核心蛋白(基因型D,亞型ayw,nt 1816-2454)的ORF,5』部分(nt 1816-1941)以核苷酸序列顯示。在nt 1941和前核心蛋白ORF的終止密碼子之間的序列省略。加框表示前核心蛋白ORF的起始密碼子、同向重複序列1(DR1)和核心蛋白ORF的符合可讀框的起始密碼子。在質粒pTREHBV-HAe中突變前核心蛋白ORF的5'末端起始密碼子。可靠的pgRNA轉錄啟動位點(nt 1820)以箭頭標記。HBV核苷酸位置依據Galibert命名法確定(5)。以預測的內部結構(下部莖、凸起、上部莖、環)說明充當HBV pgRNA中後續DNA複製的必需順式元件的關鍵莖-環結構(ε,ε)。為了將符合可讀框地融合的HA標籤序列在不改變ε的鹼基配對情況下置入前核心蛋白ORF,將含有HA標籤的DNA序列(gtggacatcTACCCATACGACGTTCCAGATTACGCTggc;SEQ ID NO:41)符合可讀框地插入與核心蛋白ORF的起始密碼子毗鄰的上遊位置(參見插入物框)。這個序列修飾導致HA標籤加接頭序列符合可讀框地融合入前核心蛋白,並且核心蛋白的完整ORF在ε的下遊維持。
圖2.加HA標籤的HBeAg的表達和分泌
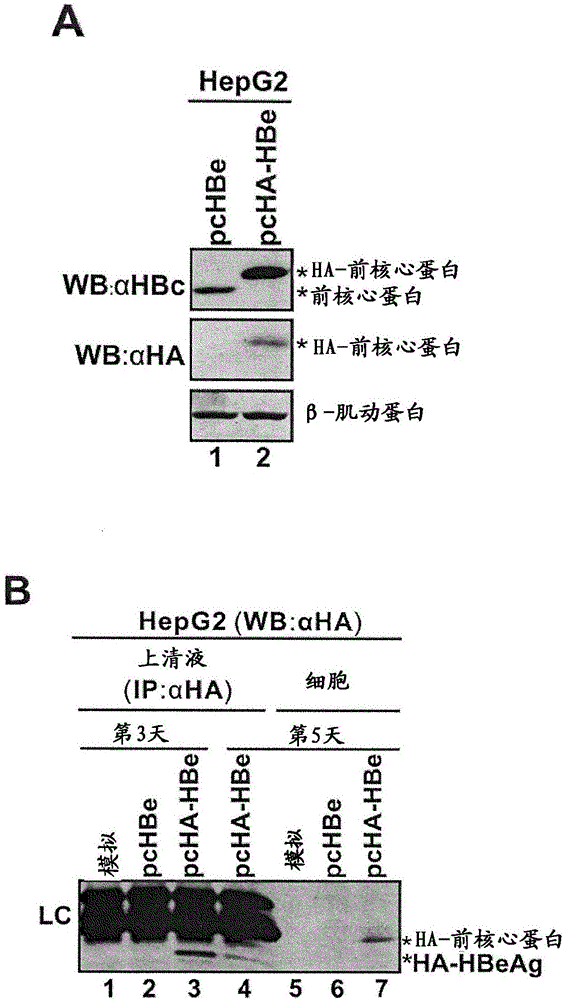
(A)野生型和加HA標籤的前核心蛋白的胞內表達。將HepG2細胞用質粒pcHBe或pcHA-HBe轉染,5天後,通過使用抗HBc(頂部小圖)和抗HA(中部小圖)抗體,令全細胞裂解物接受蛋白質印跡分析。β-肌動蛋白充當內參對照。標記野生型前核心蛋白和加HA標籤的前核心蛋白(HA-前核心蛋白)。
(B)檢測培養液中加HA標籤的HBeAg。將HepG2細胞模擬轉染或用質粒pcHBe或pcHA-HBe轉染,在指示的時間點收集上清液樣品並且在轉染後第5天收穫細胞。使用抗HA抗體,對上清液樣品進行免疫沉澱(IP)並且通過蛋白質印跡法採用針對HA的抗體檢測加HA標籤的HBeAg(HA-HBeAg)。顯示抗體的輕鏈(LC)。通過HA蛋白質印跡法揭示HA-前核心蛋白的胞內表達。
圖3.HA-HBeAg在HepHA-HBe細胞系中的分泌。
將建立的加HA標籤的HBeAg穩定表達細胞系,尤其HepHA-HBe4和HepHA-HBe47細胞,在匯合條件下接種在膠原蛋白塗覆的12孔板中。接種細胞的當日設為第0天,並且每隔1天補充培養基。在指示的時間點收集上清液樣品並且通過如「材料和方法」中所述的AlphaLISA分析法檢測HA-HBeAg。在直方圖中AlphaLISA信號(相對光單位)(Y-軸)對應於時間點(X-軸)作圖
圖4.HA-重組HBV基因組在瞬時染的細胞中的複製。
將HepG2細胞用pTREHBVDES或pTREHBV-HAe和質粒pTet-off共轉染。轉染後5天收穫細胞,並且分別通過RNA印跡法、蛋白質印跡法和DNA印跡雜交法分析基於質粒的HBV RNA、核心蛋白、衣殼化pgRNA的產生和病毒DNA複製。pgRNA:前基因組RNA;sRNA:表面RNA;RC:鬆弛型環狀DNA;SS:單鏈DNA。
圖5.HepBHAe穩定細胞系中HBV cccDNA依賴性加HA標籤的HBeAg表達的合理設計的示意圖。
在pTREHBV-HAe和pTet-off穩定轉染的細胞中,轉基因含有tet-CMV啟動子控制下的1.1倍超長HBV基因組。前核心蛋白的起始密碼子(ATG)在HBV DNA的5'末端突變,第二起始密碼子在3』多餘處未改變。將含有HA標籤的片段(以灰色顯示)如材料和方法中所述插入前核心蛋白ORF。轉基因還在表面小蛋白(S)ORF中含有兩個串聯終止密碼子以阻止病毒包膜蛋白表達。(B)一旦移除Tet,則pgRNA轉錄並且產生核心蛋白和聚合酶,導致pgRNA包裝和(C)pgRNA逆轉錄成rcDNA。DNA修復機制將(D)rcDNA轉化成(E)環狀cccDNA模板,其中HA-前核心蛋白ORF得到恢復,產生HA-前核心蛋白mRNA、及(F)用於從頭病毒複製的pgRNA。(G)HA-前核心蛋白從HA-前核心蛋白mRNA翻譯並加工成可以通過ELISA檢測到的分泌型HA-HBeAg。preC、C、pol、L、M、S和X分別代表前核心蛋白、核心蛋白、聚合酶、表面大抗原、中等抗原和小抗原和X蛋白的ORF起始密碼子。DR代表同向重複序列。CTD代表C末端結構域。
圖6.HepBHAe13細胞中病毒DNA複製、cccDNA積累和加HA標籤的HBeAg生產的動力學。
將HepBHAe13細胞在四環素存在下接種於6孔板中。當細胞單層變得匯合時,從培養基移除四環素並且每隔1天更換培養基。在指示的時間點收穫細胞樣品和上清液樣品。提取並通過DNA印跡雜交法分析胞內核心蛋白DNA(上半小圖)和cccDNA(底部小圖)。DP-rc代表去蛋白化(無蛋白質)的RC DNA。通過如上文所述的HA IP-蛋白質印跡法檢測分泌型加HA標籤的HBeAg。
圖7.支持HA-重組HBV DNA複製的額外誘導型HepBHAe細胞系。
將HepDES19細胞和新建立的克隆編號不同的HepBHAe細胞按相同的密度在四環素存在下接種於6孔板中。當細胞達到匯合時,將一組細胞在四環素存在下培養,並且將另一組細胞在四環素不存在下培養。6天後,收穫細胞並通過DNA印跡分析病毒核心蛋白DNA。
圖8.HepBHAe細胞系中cccDNA的真實性。
通過Hirt提取法提取HepDES19細胞和所示的HepBHAe細胞中產生的cccDNA並對其進行凝膠電泳和DNA印跡雜交(泳道1、5、8、11、14)。為了進一步驗證HBV cccDNA的真實性,將Hirt DNA樣品在裝載凝膠前加熱到85℃持續5分鐘,一種使DP-rcDNA變性成SS DNA,同時cccDNA保持非變性並且其電泳遷移率保持不變的條件(泳道2、6、9、12、15)。將熱變性的DNA樣品進一步用EcoRI消化,在所述條件下cccDNA線性化成基因組長度的雙鏈DNA(泳道3、7、10、13、16)。
圖9.AlphaLISA檢測HepBHAe細胞系中的HA-HBeAg。
將HepBHAe細胞在四環素存在下接種於平板中。當細胞變得匯合時,從培養基移除四環素並且每隔1天更換培養基。在指示的時間點收穫上清液樣品並對其進行AlphaLISA以檢測HA-HBeAg。AlphaLISA讀數(相對光單位,RLU)表述為每秒的計數(CPS)。
圖10.HBV複製抑制劑(3TC)阻斷HepBHAe13細胞中的HA-HBeAg表達。
將HepBHAe13細胞在6孔板中在四環素存在下培養直至匯合。一組細胞在四環素存在下持續維持。第二組細胞隨後轉換成無四環素的培養基。第三組細胞隨後在含有10μM 3TC的無四環素培養基中培養。每隔1天補充培養基,並且對指示的時間點上收穫的上清液樣品進行化學發光免疫測定(CLIA)以檢測加HA標籤的HBeAg。
圖11.HBV cccDNA形成抑制劑降低HepBHAe13細胞中的HA-HBeAg水平。將細胞接種於96孔板中並且當細胞變得匯合時,從培養基移除四環素以誘導病毒複製。同時,將細胞不處理或用化合物在所示的濃度處理,在處理組和未處理組中將DMSO濃度歸一化為0.5%。每4天重複處理。在處理後第12天,對培養液進行HA-HBeAg CLIA並且將讀數作為百分數(均值±SD)相對於對照作圖。
圖12.額外的HepBHAe細胞克隆中病毒RNA轉錄、DNA複製和cccDNA積累的動力學。
將所示的HepBHAe細胞在四環素存在下接種於6孔板中。當細胞單層變得匯合時,從培養基移除四環素並且每隔1天更換培養基。細胞在指示的時間點收穫。提取總病毒RNA(上半小圖)、胞質核心蛋白DNA(中部小圖)並分別通過RNA印跡和DNA印跡雜交分析。將提取的cccDNA在85℃熱變性5分鐘並且隨後用EcoR I線性化,隨後進行DNA印跡分析(底部小圖)。
圖13.HA-HBeAg在額外的HepBHAe細胞克隆中的cccDNA依賴性表達。
選出的HepBHAe細胞在96孔板中在四環素存在下培養直至匯合。一組細胞在四環素存在下持續維持。第二組細胞隨後轉換成無四環素的培養基。第三組細胞隨後在含有10μM 3TC的無四環素培養基中培養。每隔1天補充培養基,並且在處理後第9天收穫的上清液樣品進行化學發光免疫測定法(CLIA)以檢測加HA標籤的HBeAg。
實施例說明本發明。
實施例1:誘導型表達B型肝炎病毒共價閉合環狀DNA依賴性加表位標籤的e抗原的培養細胞系及其篩選抗病毒物質的用途
材料和方法
質粒
為了構建含有敲除其起始密碼子的融合人流感血凝素(HA)的前核心蛋白可讀框的四環素誘導型HBV複製載體,將通過Genscript Inc化學合成下述DNA片段,所述DNA片段含有CMV-IE啟動子TATA框基序和下遊HBV片段(基因型D,亞型ayw,nt 1805-2335),同時缺失nt 1816(A)及在前核心蛋白ORF中插入HA標籤序列。在這個DNA片段內部,SacI限制性酶位點在5'末端存在並且真實BspEI限制性位點在3'末端存在。通過將合成的DNA片段插入質粒pTREHBVDES中的SacI/BspEI限制性位點,構建載體pTREHBV-HAe。pTREHBV-HAe的完整序列在SEQ ID NO:35顯示。
為了產生融合HA的前核心蛋白表達載體,通過使用引物5』-ATTGGATCCACCATGCAACTTTTTCACCTCTGC-3』和5』-ACAGTAGTTTCCGGAAGTGTTGATAGGATAGGGG-3』從pTREHBV-HAe擴增含有HBV nt 1816-2335連同HA序列插入物的PCR片段。將該PCR片段用BamHI和BspEI限制性酶處理並插入前核心蛋白表達載體(pcHBe)中的相同限制性位點以產生質粒pcHA-HBe。pcHA-HBe的完整序列在SEQ ID NO:39顯示。
細胞培養物
支持HBV複製的肝母細胞瘤細胞系HepG2細胞(HB-8065TM)從ATCC獲得。先前已經描述了誘導型表達HBV DNA和cccDNA的HepG2衍生的HepDES19細胞系(7)。將細胞系在補充有10%胎牛血清、100U/ml青黴素和100μg/ml鏈黴素的Dulbecco改良Eagle培養基(DMEM)-F12培養基(Cellgro)中維持。
為了建立HepBHAe細胞系,將HepG2細胞用表達Tet應答性轉錄激活物的質粒pTet-off(Clontech)和其中修飾的HBV pgRNA的轉錄受CMV-IE啟動子連同四環素應答元件控制的質粒pTREHBV-HAe轉染。在1μg/ml四環素存在下用500μg/ml G418選擇轉染的HepG2細胞。挑取G418耐藥性集落並擴充成細胞系。通過在無四環素的培養基中培養細胞誘導HBV複製,並且通過DNA印跡雜交測定病毒DNA複製中間體的水平。選擇HBV高水平複製的細胞系並命名為具有不同克隆編號的HepBHAe。
通過用pcHA-HBe質粒轉染HepG2細胞產生加HA標籤的HBeAg穩定表達細胞系HepHA-HBe,用500μg/ml G418選擇集落並且通過抗HA蛋白質印跡分析法鑑定陽性集落。
按照與HepG2相同的方式培養HepBHAe穩定細胞系和HepHA-HBe穩定細胞系,除了添加500μg/ml的G418。對於HepBHAe細胞,在維持期間按1μg/ml常規添加四環素以抑制HBV pgRNA轉錄。
細胞轉染
將細胞(約1.0×106個)接種在膠原蛋白塗覆的35mm直徑培養皿的無抗生素DMEM/F12培養基中。在溫育過夜後,通過遵循製造商的說明,每個孔用總計4μg質粒以脂質轉染胺2000(Life Technologies)轉染。在指示的時間點收穫轉染的細胞樣品或上清液樣品。
病毒核酸分析
通過遵循製造商的操作方案,用TRIzol試劑(Life Technologies)提取細胞總RNA。將衣殼化的病毒pgRNA如下純化:在250μl含有10mMTris-HCl(pH8.0)、1mM EDTA、1%NP-40和50mM NaCl裂解緩衝液中在37℃充分裂解來自一個12孔平板的細胞10分鐘,並通過離心移除胞核。將樣品與6U微球菌核酸酶和15μl 100mM CaCl2在37℃溫育15分鐘以消化游離的核酸。根據製造商的操作方案,通過添加750μlTRIzol LS試劑(Invitrogen)提取衣殼化的病毒pgRNA。將RNA樣品通過1.5%含有2.2M甲醛的瓊脂糖凝膠電泳並轉移到20×SSC緩衝液(1×SSC是0.15M NaCl加0.015M檸檬酸鈉)中的Hybond-XL膜(GEHealthcare)上。
將胞質病毒核心蛋白DNA如下提取:在0.5ml含有10mMTris-HCl,pH 8.0、10mM EDTA、1%NP40和2%蔗糖的裂解緩衝液中在37℃裂解來自一個35mm直徑培養皿的細胞10分鐘。通過離心移除細胞殘片和胞核,並且將上清液在37℃與3μl 1M Mg(OAc)2和5μl 10mg/mlDNA酶I(Calbiochem)溫育30分鐘。上清液隨後與15μl 0.5M EDTA和130μl含有1.5M NaCl的35%聚乙二醇(PEG)8000混合以沉澱核衣殼。在冰上溫育1小時後,將病毒核衣殼通過在4℃按10,000轉/分鐘離心5分鐘沉澱,隨後在37℃在400μl含有0.5mg/ml鏈黴蛋白酶(Calbiochem)、0.5%十二烷基硫酸鈉(SDS)、100mM NaCl、25mMTris-HCl(pH 7.4)和10mM EDTA的消化緩衝液中消化1小時。消化混合物苯酚提取,並且DNA用乙醇沉澱並溶解於TE(10mM Tris-HCl、pH 8.0、1mM EDTA)緩衝液中。來自每塊平板的三分之一核心蛋白DNA樣品由電泳法分離進入1.2%瓊脂糖凝膠。凝膠隨後在含有0.2N HCl的緩衝液中進行脫嘌呤,在含有0.5M NaOH和1.5M NaCl的溶液中變性,並在含有1M Tris-HCl(pH 7.4)和1.5M NaCl的緩衝液內中和。DNA隨後印跡到20×SSC緩衝液中的Hybond-XL膜上。
通過使用改良的Hirt提取程序實施無蛋白質的病毒DNA(cccDNA和無蛋白質的rcDNA)的提取(4,8)。簡而言之,在3ml 10mM Tris-HCl(pH 7.5)、10mM EDTA和0.7%SDS中裂解來自一個35mm直徑培養皿的細胞。在室溫溫育30分鐘後,將裂解物轉移至15ml管中,並且這個步驟後是添加0.8ml 5M NaCl及在4℃溫育過夜。裂解物隨後通過在4℃按10,000轉/分鐘離心30分鐘澄清並用苯酚提取2次及用酚:氯仿:異戊醇(25:24:1)提取一次。將DNA在室溫在乙醇中沉澱過夜並溶解於TE緩衝液中。隨後將三分之一的無蛋白質的DNA樣品在1.2%瓊脂糖凝膠中分離並轉移到Hybond-XL膜上。
為了檢測HBV RNA和DNA,用[α-32P]UTP(800Ci/mmol;PerkinElmer)標記的正鏈或負鏈特異性全長HBV Riboprobe探測膜。雜交在5ml EKONO雜交緩衝液(Genotech)中實施,在65℃預雜交1小時並在65℃雜交過夜,隨後在65℃於0.1×SSC和0.1%SDS中洗滌1小時。將膜對磷光成像儀屏曝光,並通過Typhoon FLA-7000系統(GEHealthcare)檢測雜交信號。
蛋白質印跡分析
將35mm培養皿中的細胞用PBS緩衝液洗滌1次並在500μl 1×Laemmli緩衝液中裂解。將總計50μl細胞裂解物在SDS-12%聚丙烯醯胺凝膠上分離並轉移到聚偏二氟乙烯膜膜(Millipore)上。將膜用蛋白質印跡Breeze封閉緩衝液(Life Technologies)封閉並用針對HBcAg(aa170-183)、HA標籤(Sigma-Aldrich,克隆M2)、β-肌動蛋白(Sigma-Aldrich)的抗體探測。通過IRDye第二抗體揭示結合的抗體。將免疫印跡信號用Li-COR Odyssey系統可視化和定量。
免疫沉澱
在0.5ml含有10mM Tris-HCl,pH 8.0、10mM EDTA、1%NP40、2%蔗糖和1×蛋白酶抑制劑混合物(G-biosciences)的裂解緩衝液中裂解來自一個35mm直徑培養皿的細胞。在離心以除去細胞殘片後,將澄清的細胞裂解物與50μl Ezview Red抗HA(Sigma-Aldrich)在4℃溫育過夜伴以溫和轉動。來自一個35mm直徑培養皿的0.5ml培養基樣品(總計1ml)直接進行免疫沉澱。將珠在4℃用TBS緩衝液(0.15M NaCl、0.05M Tris-HCl[pH 7.4])洗滌3次。沉澱的珠用Laemmli緩衝液進行蛋白質樣品製備。使用針對HA標籤的抗體(Sigma-Aldrich)通過蛋白質印跡法檢測免疫沉澱的加HA標籤的蛋白質。
檢測加HA標籤的HBeAg的ELISA
對於化學發光酶免疫測定法(CLIA)檢測加HA標籤的HBeAg,將鏈黴親和素塗布的高靈敏平板(黑色,目錄號:15525,Thermo Scientific)用PBST(PBS外加0.05%Tween20)洗滌3次,並且隨後在室溫與50μl抗HA-生物素(目錄號:A00203,Genscript;PBS中5μg/ml)溫育30分鐘,隨後用200μlPBST洗滌3次。在移除洗滌緩衝液後,將50μl培養上清液樣品添加於ELISA孔中並在室溫溫育30分鐘,隨後用200μlPBST洗滌3次。隨後,將50μl辣根過氧化物酶(HRP綴合的抗HBe抗體(來自HBeAg CLIA試劑盒,目錄號:CL0312-2,Autobio Diagnostics)添加於孔中並在室溫溫育30分鐘。用200μlPBST洗滌5次後,添加來自CLIA試劑盒的25μl每種底物A和B並且將平板溫和地振搖10秒。在光度計上讀取平板。
對於AlphaLISA檢測加HA標籤的HBeAg,將抗HA-生物素(目錄號:A00203,Genscript)在1×分析緩衝液(25mM HEPES、0.1M NaCl、0.1%BSA,pH 7.4)中稀釋至2μg/ml並分配5μl至Proxiplate-384HS(目錄號:6008279,Perkin Elmer)的每個孔中。隨後將5μl培養液樣品添加於各孔中並溫和地混合,隨後在室溫溫育30分鐘。隨後、添加5μl 0.2μg/ml抗HBe(克隆29,批號20110305,Autobio Diagnostics)並溫和地混合,隨後在室溫溫育30分鐘。隨後,將分析溶液與5μl稀釋的抗小鼠IgG AlphaLISA接納體珠(目錄號:AL105C,Perkin Elmer)(125μg/ml)混合併在室溫溫育30分鐘,隨後在室溫與5μl AlphaScreen鏈黴親和素供體珠(目錄號:6760002S,Perkin Elmer)(125μg/ml)溫育1小時。在溫育後,在Envision2104多標記讀數儀(Perkin Elmer)上讀取平板。
結果
本文提供兩種類型的分別從轉基因和HBV cccDNA表達加HA標籤的HBeAg(HA-HBeAg)的新細胞系及通過化學發光免疫測定法和AlphaLISA測定法檢測重組HBeAg的方法。細胞系和測定法適於高通量篩選減少HBV cccDNA水平和/或沉默cccDNA轉錄的化合物。
緊湊的HBV DNA基因組小尺寸和重疊基因組構造在轉染的細胞中不影響病毒DNA複製和後續cccDNA形成的情況下限制了報導基因的插入。
前核心蛋白/HBeAg可以在HepDE19細胞中工程化成cccDNA依賴性(3)。本領域已知,HBV基因組具有顯示重疊ORF和多個順式元件的高度緊湊型基因構造。因此,認為基因插入/缺失或序列替換將很可能影響病毒DNA複製。先前的工作已經通過GFP替換HBV序列,如在大多數情況下的包膜蛋白編碼區,以產生重組HBV基因組,但是需要病毒蛋白的反式互補以支持病毒複製和病毒粒裝配(Protzer等人,PNAS(1999),96:10818-23)。另外,那些報告的重組HBV基因組如果用來感染容許性細胞則僅可以產生第一輪cccDNA合成,cccDNA的胞內擴增被阻斷,原因是缺陷型病毒DNA複製。
即便有以上的現有技術知識,在本文中嘗試以下情況並且其是合理的:在前核心蛋白可讀框(ORF)中符合可讀框地融合外源短表位標籤可以由HBV基因組耐受並且從cccDNA模板表達,因此一對標籤特異性抗體和HBeAg抗體將顯著地改善ELISA檢測的特異性。
為了構建具有人流感血凝素(HA)融合的前核心蛋白可讀框的四環素誘導型HBV複製載體,將含有HA標籤的DNA序列(gtggacatcTACCCATACGACGTTCCAGATTACGCTggc;SED ID NO.:41)插入與HBV表達載體pTREHBVDES中核心蛋白ORF的起始密碼子毗鄰的符合可讀框的上遊位置,其中HBV pgRNA表達以Tet-off方式受四環素(tet)調節的CMV-IE啟動子控制。HA標籤(大寫)的側翼序列(小寫)設計成維持HBV基因組莖環結構(ε)的鹼基配對和核心蛋白ORF起始密碼子的Kozak基序(圖1)。獲得的重組質粒命名為pTREHBV-HAe(SEQ ID NO:35)。除了HA標籤插入外,質粒pTREHBV-HAe還在前核心蛋白ORF的5'末端起始密碼子中含有點缺失(ATG至TG),藉此阻止前核心蛋白從質粒模板中的HBV基因組表達。此外,將兩個串聯終止密碼子引入小(S)包膜蛋白氨基端的編碼區中(217TTGTTG222 to 217TAGTAG222;突變加下劃線)以阻斷HBV感染性粒子的產生。
為了檢驗加表位標籤的HBV前核心蛋白表達和HBeAg分泌的可行性,如上文所述,將含有HA標籤的DNA序列插入前核心蛋白表達質粒pcHBe中的相同病毒DNA位置,並且構建體命名為pcHA-HBe(SEQID NO:39)。pcHA-HBe在HepG2細胞中的轉染導致加HA標籤的前核心蛋白的胞內表達和加HA標籤的HBeAg的胞外積累(圖2),因此證實HA標籤插入前核心蛋白不影響前核心蛋白表達、翻譯後加工和HBeAg分泌。也已經建立用於檢測加HA標籤的HBeAg(HA-HBeAg)的化學發光ELISA和AlphaLISA,如材料和方法章節中所述。
根據上文,通過將pcHA-HBe穩定轉染入HepG2細胞,建立以組成型方式表達加HA標籤的HBeAg的細胞系。通過AlphaLISA測定法選出高水平表達加HA標籤的HBeAg的兩個克隆,並且將它們分別命名為HepHA-HBe4和HepHA-HBe47(圖3)。
在瞬時轉染測定法中,重組HBV質粒pTREHBV-HAe能夠複製HBV DNA到與pTREHBVDES所實現水平可比較的水平(圖4),提示HA標籤插入由HBV基因組複製耐受。隨後,將pTREHBV-HAe隨pTET-off(Clontech)一起穩定共轉染入HepG2細胞以產生四環素誘導型HBV細胞系。理論上,在這種細胞系中,一旦誘導,前核心蛋白和其衍生物HBeAg將不從轉基因產生,原因在於前核心蛋白ORF起始密碼子沉默。轉錄的pgRNA將表達病毒核心蛋白和聚合酶並啟動逆轉錄以產生rcDNA,從而通過胞內擴增途徑導致cccDNA形成。前核心蛋白不完整ORF在pgRNA的3』多餘處的起始密碼子將拷貝入病毒DNA序列,並且加HA標籤的前核心蛋白的完整ORF將在rcDNA轉變成cccDNA期間重構。因此,HA-前核心蛋白mRNA僅可以從cccDNA轉錄,產生核內cccDNA的分泌型加HA標籤的HBeAg替代標記(圖5)。
我們已經獲得5個以四環素依賴性方式支持高水平HBV DNA複製的細胞系(HepBHAe1、HepBHAe13、HepBHAe34、HepBHAe45、HepBHAe82)(圖6和圖7)。
在代表性株系HepBHAe13細胞中,當撤除四環素時觀察到病毒產物(包括複製型DNA中間體和cccDNA)合成和積累的時間依賴性動力學。在HepBHAe13細胞的培養液中,移除四環素後第6天還通過蛋白質印跡法檢測到加HA標籤的HBeAg,並且此後抗原水平逐漸增加。加HA標籤的HBeAg(HA-HBeAg)的水平與病毒核心蛋白DNA和cccDNA的胞內水平成正比(圖6)。已經通過熱變性和進一步限制性酶消化證實從HepBHAe細胞系產生的cccDNA的真實性(圖8)。因此,已經建立了支持前核心蛋白中插入含有HA標籤的重組HBV的DNA複製和cccDNA形成的誘導型細胞系。
在16天時間過程研究中,來自培養的HepBHAe細胞的上清液樣品上的AlphaLISA測定法展示加HA標籤的HBeAg的水平增加(圖9)。選擇HepHBAe13細胞以進一步驗證。細胞在三種條件下培養:1)在四環素存在下以抑制轉基因表達;2)在四環素不存在下以誘導病毒DNA複製;3)在四環素不存在下但是給予3TC處理以阻斷病毒DNA複製及後續cccDNA形成。化學發光免疫測定法(CLIA)顯示,作為cccDNA建立和基因表達的結果,培養基中加HA標籤的HBeAg信號在撤除四環素後的第6天出現並且此後逐漸增加。如預測,在四環素存在下或在3TC處理(tet-)下的任何時間點在培養液中均未檢出HA-HBeAg(圖10)。另外,兩種先前鑑定的cccDNA形成抑制劑,具體為CCC-0975和CCC-0346(3)、顯示劑量依賴地抑制HA-HBeAg從HepBHAe13細胞產生(圖11)。因此,HepBHAe13細胞中加HA標籤的HBeAg的產生是cccDNA依賴的。
此外,對其他HepBHAe細胞系(包括HepBHAe1、HepBHAe45和HepBHAe82)的時間過程研究展示了撤除四環素時HBVmRNA、胞質核心蛋白DNA和核cccDNA的時間依賴性積累(圖12)。如圖13中所示,在這些三個額外的HepBHAe細胞系中驗證了cccDNA依賴的加HA標籤的HBeAg產生。
總之,本文中已經建立了新的誘導性型細胞系,所述細胞系以HBVcccDNA依賴方式表達加HA標籤的HBeAg,後者可以在用本文所述的HA-HBeAg檢測方法篩選抗病毒化合物中充當HBV cccDNA的替代標記。
本發明參考以下核苷酸序列和胺基酸序列。
本文中提供的序列在NCBI資料庫中可獲得並且可以在ncbi.nlm.nih.gov/sites/entrez?db=gene從全球資訊網取回;這些序列還涉及注釋的和修飾的序列。本發明還提供其中使用本文所提供之簡潔序列的同源序列和變體的技術和方法。優選地,這類「變體」是遺傳變體。
SEQ ID NO:1:
編碼血凝素(HA)標籤的核苷酸序列
TACCCATACGACGTTCCAGATTACGCT
SEQ ID NO:2:
編碼His標籤的核苷酸序列
CATCATCATCATCATCAC
SEQ ID NO:3:
編碼Flag標籤的核苷酸序列
GACTACAAGCACGACGACGACAAG
SEQ ID NO:4:
編碼c-myc標籤的核苷酸序列
ATG GCA TCA ATG CAG AAG CTG ATC TCA GAG GAG GAC CTG
SEQ ID NO:5:
編碼V5標籤的核苷酸序列
GGT AAG CCT ATC CCT AAC CCT CTC CTC GGT CTC GAT TCT ACG
SEQ ID NO:6:
編碼C9標籤的核苷酸序列
ACTGAAACATCTCAAGTAGCTCCAGCT
SEQ ID NO:7∶
編碼3×Flag標籤的核苷酸序列
GACTACAAAGACCACGACGGTGACTACAAAGACCACGACATCGACTACAAGGACGACGACGACAAG
SEQ ID NO:8:
HA標籤的胺基酸序列
YPYDVPDYA
SEQ ID NO:9:
His標籤的胺基酸序列
HHHHHH
SEQ ID NO:10:
Flag標籤的胺基酸序列
DYKDDDDK
SEQ ID NO:11:
c-myc標籤的胺基酸序列
EQKLISEEDL
SEQ ID NO:12:
V5標籤的胺基酸序列
GKPIPNPLLGLDST
SEQ ID NO:13:
C9標籤的胺基酸序列
TETSQVAPA
SEQ ID NO:14:
3×Flag標籤的胺基酸序列
DYKDHDGDYKDHDIDYKDDDDK
SEQ ID NO:15:
編碼B型肝炎病毒前核心蛋白的核苷酸序列
前核心蛋白ORF序列:
ATGCAACTTTTTCACCTCTGCCTAATCATCTCTTGTTCATGTCCTACTGTTCAAGCCTCCAAGCTGTGCCTTGGGTGGCTTTGGGGCATGGACATCGACCCTTATAAAGAATTTGGAGCTACTGTGGAGTTACTCTCGTTTTTGCCTTCTGACTTCTTTCCTTCAGTACGAGATCTTCTAGATACCGCCTCAGCTCTGTATCGGGAAGCCTTAGAGTCTCCTGAGCATTGTTCACCTCACCATACTGCACTCAGGCAAGCAATTCTTTGCTGGGGGGAACTAATGACTCTAGCTACCTGGGTGGGTGTTAATTTGGAAGATCCAGCATCTAGAGACCTAGTAGTCAGTTATGTCAACACTAATATGGGCCTAAAGTTCAGGCAACTCTTGTGGTTTCACATTTCTTGTCTCACTTTTGGAAGAGAAACCGTTATAGAGTATTTGGTGTCTTTCGGAGTGTGGATTCGCACTCCTCCAGCTTATAGACCACCAAATGCCCCTATCCTATCAACACTTCCGGAAACTACTGTTGTTAGACGACGAGGCAGGTCCCCTAGAAGAAGAACTCCCTCGCCTCGCAGACGAAGGTCTCAATCGCCGCGTCGCAGAAGATCTCAATCTCGGGAACCTCAATGTTAG
SEQ ID NO:16:
編碼B型肝炎病毒e抗原(HBeAg)的核苷酸序列
HBeAg DNA序列:
TCCAAGCTGTGCCTTGGGTGGCTTTGGGGCATGGACATCGACCCTTATAAAGAATTTGGAGCTACTGTGGAGTTACTCTCGTTTTTGCCTTCTGACTTCTTTCCTTCAGTACGAGATCTTCTAGATACCGCCTCAGCTCTGTATCGGGAAGCCTTAGAGTCTCCTGAGCATTGTTCACCTCACCATACTGCACTCAGGCAAGCAATTCTTTGCTGGGGGGAACTAATGACTCTAGCTACCTGGGTGGGTGTTAATTTGGAAGATCCAGCATCTAGAGACCTAGTAGTCAGTTATGTCAACACTAATATGGGCCTAAAGTTCAGGCAACTCTTGTGGTTTCACATTTCTTGTCTCACTTTTGGAAGAGAAACCGTTATAGAGTATTTGGTGTCTTTCGGAGTGTGGATTCGCACTCCTCCAGCTTATAGACCACCAAATGCCCCTATCCTATCAACACTTCCGGAAACTACTGTTGTT
SEQ ID NO:17:
B型肝炎病毒前核心蛋白的胺基酸序列
前核心蛋白的胺基酸序列:
MQLFHLCLIISCSCPTVQASKLCLGWLWGMDIDPYKEFGATVELLSFLPSDFFPSVRDLLDTASALYREALESPEHCSPHHTALRQAILCWGELMTLATWVGVNLEDPASRDLVVSYVNTNMGLKFRQLLWFHISCLTFGRETVIEYLVSFGVWIRTPPAYRPPNAPILSTLPETTVVRRRGRSPRRRTPSPRRRRSQSPRRRRSQSREPQC
SEQ ID NO:18:
B型肝炎病毒e抗原(HBeAg)的胺基酸序列
HBeAg胺基酸序列(從前核心蛋白除去N端信號肽(19aa)和C末端精氨酸豐富結構域(34aa)):
SKLCLGWLWGMDIDPYKEFGATVELLSFLPSDFFPSVRDLLDTASALYREALESPEHCSPHHTALRQAILCWGELMTLATWVGVNLEDPASRDLVVSYVNTNMGLKFRQLLWFHISCLTFGRETVIEYLVSFGVWIRTPPAYRPPNAPILSTLPETTVV
SEQ ID NO:19:
編碼加HA標籤B型肝炎病毒前核心蛋白的核苷酸序列。
加HA標籤的前核心蛋白DNA序列:
ATGCAACTTTTTCACCTCTGCCTAATCATCTCTTGTTCATGTCCTACTGTTCAAGCCTCCAAGCTGTGCCTTGGGTGGCTTTGGGGCGTGGACATCTACCCATACCACGTTCCAGATTACGCTGGCATGGACATCGACCCTTATAAAGAATTTGGAGCTACTGTGGAGTTACTCTCGTTTTTGCCTTCTGACTTCTTTCCTTCAGTACGAGATCTTCTAGATACCGCCTCAGCTCTGTATCGGGAAGCCTTAGAGTCTCCTGAGCATTGTTCACCTCACCATACTGCACTCAGGCAAGCAATTCTTTGCTGGGGGGAACTAATGACTCTAGCTACCTGGGTGGGTGTTAATTTGGAAGATCCAGCATCTAGAGACCTAGTAGTCAGTTATGTCAACACTAATATGGGCCTAAAGTTCAGGCAACTCTTGTGGTTTCACATTTCTTGTCTCACTTTTGGAAGAGAAACCGTTATAGAGTATTTGGTGTCTTTCGGAGTGTGGATTCGCACTCCTCCAGCTTATAGACCACCAAATGCCCCTATCCTATCAACACTTCCGGAAACTACTGTTGTTAGACGACGAGGCAGGTCCCCTAGAAGAAGAACTCCCTCGCCTCGCAGACGAAGGTCTCAATCGCCGCGTCGCAGAAGATCTCAATCTCGGGAACCTCAATGTTAG
SEQ ID NO:20:
編碼加HA標籤的B型肝炎病毒e抗原(HBeAg)的核苷酸序列
加HA標籤的HBeAg DNA序列:
TCCAAGCTGTGCCTTGGGTGGCTTTGGGGCGTGGACATCTACCCATACGACGTTCCAGATTACGCTGGCATGGACATCGACCCTTATAAAGAATTTGGAGCTACTGTGGAGTTACTCTCGTTTTTGCCTTCTGACTTCTTTCCTTCAGTACGAGATCTTCTAGATACCGCCTCAGCTCTGTATCGGGAAGCCTTAGAGTCTCCTGAGCATTGTTCACCTCACCATACTGCACTCAGGCAAGCAATTCTTTGCTGGGGGGAACTAATGACTCTAGCTACCTGGGTGGGTGTTAATTTGGAAGATCCAGCATCTAGAGACCTAGTAGTCAGTTATGTCAACACTAATATGGGCCTAAAGTTCAGGCAACTCTTGTGGTTTCACATTTCTTGTCTCACTTTTGGAAGAGAAACCGTTATAGAGTATTTGGTGTCTTTCGGAGTGTGGATTCGCACTCCTCCAGCTTATAGACCACCAAATGCCCCTATCCTATCAACACTTCCGGAAACTACTGTTGTT
SEQ ID NO:21:
加HA標籤的B型肝炎病毒前核心蛋白的胺基酸序列。HA標籤加下劃線。
加HA標籤的前核心蛋白的胺基酸序列:
MQLFHLCLIISCSCPTVQASKLCLGWLWGVDIYPYDVPDYAGMDlDPYKEFGATVELLSFLPSDFFPSVRDLLDTASALYREALESPEHCSPHHTALRQAILCWGELMTLATWVGVNLEDPASRDLVVSYVNTNMGLKFRQLLWFHISCLTFGRETVIEYLVSFGVWIRTPPAYRPPNAPILSTLPETTVVRRRGRSPRRRTPSPRRRRSQSPRRRRSQSREPQC
SEQ ID NO:22:
加HA標籤的B型肝炎病毒e抗原(HBeAg)的胺基酸序列。HA標籤加下劃線。
加HA標籤的HBeAg胺基酸序列:
SKLCLGWLWGVDIYPYDVPDYAGMDIDPYKEFGATVELLSFLPSDFFPSVRDLLDTASALYREALESPEHCSPHHTALRQAILCWGELMTLATWVGVNLEDPASRDLVVSYVNTNMGLKFRQLLWFHISCLTFGRETVIEYLVSFGVWIRTPPAYRPPNAPILSTLPETTVV
SEQ ID NO:23:
編碼HBV核心蛋白的核苷酸序列ATGGACATCGACCCTTATAAAGAATTTGGAGCTACTGTGGAGTTACTCTCGTTTTTGCCTTCTGACTTCTTTCCTTCAGTACGAGATCTTCTAGATACCGCCTCAGCTCTGTATCGGGAAGCCTTAGAGTCTCCTGAGCATTGTTCACCTCACCATACTGCACTCAGGCAAGCAATTCTTTGCTGGGGGGAACTAATGACTCTAGCTACCTGGGTGGGTGTTAATTTGGAAGATCCAGCATCTAGAGACCTAGTAGTCAGTTATGTCAACACTAATATGGGCCTAAAGTTCAGGCAACTCTTGTGGTTTCACATTTCTTGTCTCACTTTTGGAAGAGAAACCGTTATAGAGTATTTGGTGTCTTTCGGAGTGTGGATTCGCACTCCTCCAGCTTATAGACCACCAAATGCCCCTATCCTATCAACACTTCCGGAAACTACTGTTGTTAGACGACGAGGCAGGTCCCCTAGAAGAAGAACTCCCTCGCCTCGCAGACGAAGGTCTCAATCGCCGCGTCGCAGAAGATCTCAATCTCGGGAACCTCAATGTTAG
SEQ ID NO:24:
HBV核心蛋白的胺基酸序列
MDIDPYKEFGATVELLSFLPSDFFPSVRDLLDTASALYREALESPEHCSPHHTALRQAILCWGELMTLATWVGVNLEDPASRDLVVSYVNTNMGLKFRQLLWFHISCLTFGRETVIEYLVSFGVWIRTPPAYRPPNAPILSTLPETTVVRRRGRSPRRRTPSPRRRRSQSPRRRRSQSREPQC
SEQ ID NO:25:
如HBV基因組編碼的ε結構的核苷酸序列
TGTTCATGTCCTACTGTTCAAGCCTCCAAGCTGTGCCTTGGGTGGCTTTGGGGCATGGACA
SEQ ID NO:26:
能夠與嗜肝DNA病毒基因組的ε結構的下部莖形成鹼基對的核苷酸序列
GTGGACATC
SEQ ID NO:27:
HBV基因組的核苷酸序列,HBV基因型D,亞型ayw。Genbank登錄號U95551(C1902和A1903為粗體。前核心蛋白的ORF加下劃線)AATTCCACAACCTTTCACCAAACTCTGCAAGATCCCAGAGTGAGAGGCCTGTATTTCCCTGCTGGTGGCTCCAGTTCAGGAGCAGTAAACCCTGTTCCGACTACTGCCTCTCCCTTATCGTCAATCTTCTCGAGGATTGGGGACCCTGCGCTGAACATGGAGAACATCACATCAGGATTCCTAGGACCCCTTCTCGTGTTACAGGCGGGGTTTTTCTTGTTGACAAGAATCCTCACAATACCGCAAAGTCTAGACTCGTGGTGGACTTCTCTCAATTTTCTAGGGGGAACTACCGTGTGTCTTGGCCAAAATTCGCAGTCCCCAACCTCCAATCACTCACCAACCTCCTGTCCTCCAACTTGTCCTGGTTATCGCTGGATGTGTCTGCGGCGTTTTATCATCTTCCTCTTCATCCTGCTGCTATGCCTCATCTTCTTGTTGGTTCTTCTGGACTATCAAGGTATGTTGCCCGTTTGTCCTCTAATTCCAGGATCCTCAACCACCAGCACGGGACCATGCCGAACCTGCATGACTACTGCTCAAGGAACCTCTATGTATCCCTCCTGTTGCTGTACCAAACCTTCGGACGGAAATTGCACCTGTATTCCCATCCCATCATCCTGGGCTTTCGGAAAATTCCTATGGGAGTGGGCCTCAGCCCGTTTCTCCTGGCTCAGTTTACTAGTGCCATTTGTTCAGTGGTTCGTAGGGCTTTCCCCCACTGTTTGGCTTTCAGTTATATGGATGATGTGGTATTGGGGGCCAAGTCTGTACAGCATCTTGAGTCCCTTTTTACCGCTGTTACCAATTTTCTTTTGTCTTTGGGTATACATTTAAACCCTAACAAAACAAAGAGATGGGGTTACTCTCTGAATTTTATGGGTTATGTCATTGGAAGTTATGGGTCCTTGCCACAAGAACACATCATACAAAAAATCAAAGAATGTTTTAGAAAACTTCCTATTAACAGGCCTATTGATTGGAAAGTATGTCAACGAATTGTGGGTCTTTTGGGTTTTGCTGCCCCATTTACACAATGTGGTTATCCTGCGTTAATGCCCTTGTATGCATGTATTCAATCTAAGCAGGCTTTCACTTTCTCGCCAACTTACAAGGCCTTTCTGTGTAAACAATACCTGAACCTTTACCCCGTTGCCCGGCAACGGCCAGGTCTGTGCCAAGTGTTTGCTGACGCAACCCCCACTGGCTGGGGCTTGGTCATGGGCCATCAGCGCGTGCGTGGAACCTTTTCGGCTCCTCTGCCGATCCATACTGCGGAACTCCTAGCCGCTTGTTTTGCTCGCAGCAGGTCTGGAGCAAACATTATCGGGACTGATAACTCTGTTGTCCTCTCCCGCAAATATACATCGTATCCATGGCTGCTAGGCTGTGCTGCCAACTGGATCCTGCGCGGGACGTCCTTTGTTTACGTCCCGTCGGCGCTGAATCCTGCGGACGACCCTTCTCGGGGTCGCTTGGGACTCTCTCGTCCCCTTCTCCGTCTGCCGTTCCGACCGACCACGGGGCGCACCTCTCTTTACGCGGACTCCCCGTCTGTGCCTTCTCATCTGCCGGACCGTGTGCACTTCGCTTCACCTCTGCACGTCGCATGGAGACCACCGTGAACGCCCACCGAATGTTGCCCAAGGTCTTACATAAGAGGACTCTTGGACTCTCTGCAATGTCAACGACCGACCTTGAGGCATACTTCAAAGACTGTTTGTTTAAAGACTGGGAGGAGTTGGGGGAGGAGATTAGATTAAAGGTCTTTGTACTAGGAGGCTGTAGGCATAAATTGGTCTGCGCACCAGCACCATGCAACTTTTTCACCTCTGCCTAATCATCTCTTGTTCATGTCCTACTGTTCAAGCCTCCAAGCTGTGCCTTGGGTGGCTTTGGGGCATGGACATCGACCCTTATAAAGAATTTGGAGCTACTGTGGAGTTACTCTCGTTTTTGCCTTCTGACTTCTTTCCTTCAGTACGAGATCTTCTAGATACCGCCTCAGCTCTGTATCGGGAAGCCTTAGAGTCTCCTGAGCATTGTTCACCTCACCATACTGCACTCAGGCAAGCAATTCTTTGCTGGGGGGAACTAATGACTCTAGCTACCTGGGTGGGTGTTAATTTGGAAGATCCAGCATCTAGAGACCTAGTAGTCAGTTATGTCAACACTAATATGGGCCTAAAGTTCAGGCAACTCTTGTGGTTTCACATTTCTTGTCTCACTTTTGGAAGAGAAACCGTTATAGAGTATTTGGTGTCTTTCGGAGTGTGGATTCGCACTCCTCCAGCTTATAGACCACCAAATGCCCCTATCCTATCAACACTTCCGGAAACTACTGTTGTTAGACGACGAGGCAGGTCCCCTAGAAGAAGAACTCCCTCGCCTCGCAGACGAAGGTCTCAATCGCCGCGTCGCAGAAGATCTCAATCTCGGGAACCTCAATGTTAGTATTCCTTGGACTCATAAGGTGGGGAACTTTACTGGTCTTTATTCTTCTACTGTACCTGTCTTTAATCCTCATTGGAAAACACCATCTTTTCCTAATATACATTTACACCAAGACATTATCAAAAAATGTGAACAGTTTGTAGGCCCACTTACAGTTAATGAGAAAAGAAGATTGCAATTGATTATGCCTGCTAGGTTTTATCCAAAGGTTACCAAATATTTACCATTGGATAAGGGTATTAAACCTTATTATCCAGAACATCTAGTTAATCATTACTTCCAAACTAGACACTATTTACACACTCTATGGAAGGCGGGTATATTATATAAGAGAGAAACAACACATAGCGCCTCATTTTGTGGGTCACCATATTCTTGGGAACAAGATCTACAGCATGGGGCAGAATCTTTCCACCAGCAATCCTCTGGGATTCTTTCCCGACCACCAGTTGGATCCAGCCTTCAGAGCAAACACAGCAAATCCAGATTGGGACTTCAATCCCAACAAGGACACCTGGCCAGACGCCAACAAGGTAGGAGCTGGAGCATTCGGGCTGGGTTTCACCCCACCGCACGGAGGCCTTTTGGGGTGGAGCCCTCAGGCTCAGGGCATACTACAAACTTTGCCAGCAAATCCGCCTCCTGCCTCCACCAATCGCCAGACAGGAAGGCAGCCTACCCCGCTGTCTCCACCTTTGAGAAACACTCATCCTCAGGCCATGCAGTGG
SEQ ID NO:28:
HBV基因組的核苷酸序列,HBV基因型A(Genbank登錄號AP007263)
AATTCCACTGCCTTCCACCAAGCTCTGCAGGATCCCAGAGTCAGGGGTCTGTATTTTCCTGCTGGTGGCTCCAGTTCAGGAACAGTAAACCCTGCTCCGAATATTGCCTCTCACATCTCGTCAATCTCCGCGAGGACTGGGGACCCTGTGGCGAACATGGAGAACATCACATCAGGATTCCTAGGACCCCTGCTCGTGTTACAGGCGGGGTTTTTCTTGTTGACAAGAATCCTCACAATACCGCAGAGTCTAGACTCGTGGTGGACTTCTCTCAATTTTCTAGGGGGATCACCCGTGTGTCTTGGCCAAAATTCGCAGTCCCCAACCTCCAATCACTCACCAACCTCCTGTCCTCCAATTTGTCCTGGTTATCGCTGGATGTGTCTGCGGCGTTTTATCATATTCCTCTTCATCCTGCTGCTATGCCTCATCTTCTTATTGGTTCTTCTGGATTATCAAGGTATGTTGCCCGTTTGTCCTCTAATTCCAGGATCAACAACAACCAGTACGGGACCATGCAAAACCTGCACGACTCCTGCTCAAGGCAACTCTATGTTTCCCTCATGTTGCTGTACAAAACCTACGGATGGAAATTGCACCTGTATTCCCATCCCATCGTCCTGGGCTTTCGCAAAATACCTATGGGAGTGGGCCTCAGTCCGTTTCTCTTGGCTCAGTTTACTAGTGCCATTTGTTCAGTGGTTCGTAGGGCTTTCCCCCACTGTTTGGCTTTCAGCTATATGGATGATGTGGTATTGGGGGCCAAGTCTGTACAGCATCGTGAGTCCCTTTATACCGCTGTTACCAATTTTCTTTTGTCTCTGGGTATACATTTAAACCCTAACAAAACAAAAAGATGGGGTTATTCCCTAAACTTCATGGGTTACATAATTGGAAGTTGGGGAACTTTGCCACAGGATCATATTGTACAAAAGATCAAACACTGTTTTAGAAAACTTCCTGTTAACAGGCCTATTGATTGGAAAGTATGTCAAAGAATTGTGGGTCTTTTGGGCTTTGCTGCTCCATTTACACAATGTGGATATCCTGCCTTAATGCCTTTGTATGCATGTATACAAGCTAAACAGGCTTTCACTTTCTCGCCAACTTACAAGGCCTTTCTAAGTAAACAGTACATGAACCTTTACCCCGTTGCTCGGCAACGGCCTGGTCTGTGCCAAGTGTTTGCTGACGCAACCCCCACTGGCTGGGGCTTGGCCATAGGCCATCAGCGCATGCGTGGAACCTTTGTGGCTCCTCTGCCGATCCATACTGCGGAACTCCTAGCCGCTTGTTTTGCTCGCAGCCGGTCTGGAGCAAAGCTCATCGGAACTGACAATTCTGTCGTCCTCTCGCGGAAATATACATCGTTTCCATGGCTGCTAGGCTGTGCTGCCAACTGGATCCTTCGCGGAACGTCCTTTGTCTACGTCCCGTCGGCGCTGAATCCCGCGGACGACCCCTCTCGGGGCCGCTTGGGACTCTCTCGTCCCCTTCTCCGTCTGCCGTTCCAGCCGACCACGGGGCGCACCTCTCTTTACGCGGTCTCCCCGTCTGTGCCTTCTCATCTGCCGGTCCGTGTGCACTTCGCTTCACCTCTGCACGTTGCATGGAGACCACCGTGAACGCCCATCAGATCCTGCCCAAGGTCTTACATAAGAGGACTCTTGGACTCCCAGCAATGTCAACGACCGACCTTGAGGCCTACTTCAAAGACTGTGTGTTTAAGGACTGGGAGGAGCTGGGGGAGGAGATTAGGTTAAAGGTCTTTGTATTAGGAGGCTGTAGGCATAAATTGGTCTGCGCACCAGCACCATGCAACTTTTTCACCTCTGCCTAATCATCTCTTGTACATGTCCCACTGTTCAAGCCTCCAAGCTGTGCCTTGGGTGGCTTTGGGGCATGGACATTGACCCTTATAAAGAATTTGGAGCTACTGTGGAGTTACTCTCGTTTTTGCCTTCTGACTTCTTTCCTTCCGTCAGAGATCTCCTAGACACCGCCTCAGCTCTGTATCGAGAAGCCTTAGAGTCTCCTGAGCATTGCTCACCTCACCATACTGCACTCAGGCAAGCCATTCTCTGCTGGGGGGAATTGATGACTCTAGCTACCTGGGTGGGTAATAATTTGGAAGATCCAGCATCCAGGGATCTAGTAGTCAATTATGTTAATACTAACATGGGTTTAAAGATCAGGCAACTATTGTGGTTTCATATATCTTGCCTTACTTTTGGAAGAGAGACTGTACTTGAATATTTGGTCTCTTTCGGAGTGTGGATTCGCACTCCTCCAGCCTATAGACCACCAAATGCCCCTATCTTATCAACAATTCCGGAAACTACTGTTGTTAGACGACGGGACCGAGGCAGGTCCCCTAGAAGAAGAACTCCCTCGCCTCGCAGACGCAGATCTCAATCGCCGCGTCGCAGAAGATCTCAATCTCGGGAATCTCAATGTTAGTATTCCTTGGACTCATAAGGTGGGAAACTTTACGGGGCTTTATTCCTCTACAGTACCTATCTTTAATCCTGAATGGCAAACTCCTTCCTTTCCTAAGATTCATTTACAAGAGGACATTATTAATAGGTGTCAACAATTTGTGGGCCCTCTCACTGTAAATGAAAAGAGAAGATTGAAATTAATTATGCCTGCTAGATTCTATCCTACCCACACTAAATATTTGCCCTTAGACAAAGGAATTAAACCTTATTATCCAGATCAGGTAGTTAATCATTACTTCCAAACCAGACATTATTTACATACTCTTTGGAAGGCTGGTATTCTATATAAGAGGGAAACCACACGTAGCGCATCATTTTGCGGGTCACCATATTCTTGGGAACAAGAGCTACAGCATGGGAGGTTGGTCATCAAAACCTCGCAAAGGCATGGGGACGAATCTTTCTGTTCCCAACCCTCTGGGATTCTTTCCCGATCATCAGTTGGACCCTGCATTCGGAGCCAACTCAAACAATCCAGATTGGGACTTCAACCCCATCAAGGACCACTGGCCAACAGCCAACCAGGTAGGAGTGGGAGCATTCGGGCCAGGGCTCACCCCTCCACACGGCGGTATTTTGGGGGGGAGCCCTCAGGCTCAGGGCATATTGACCACAGTGTCAACAATTCCTCCTCCTGCCTCCACCAATCGGCAGTCAGGAAGGCAGCCTACTCCCATCTCTCCACCTCTAAGAGACAGTCATCCTCAGGCCATGCAGTGG
SEQ ID NO:29:
HBV基因組的核苷酸序列,HBV基因型B(Genbank登錄號AB602818)
AACTCCACCACTTTTCACCAAACTCTTCAAGATCCCAGAGTCCGGGCTCTGTACTTTCCTGCTGGTGGCTCCAGTTCAGGAACAGTAAGCCCTGCTCAGAATACTGTCTCTGCCATATCGTCAATCTTATCGAAGACTGGGGACCCTGTGCCGAACATGGAGAACATCGCATCAGGACTCCTAGGACCCCTGCTCGTGTTACAGGCGGGGTTTTTCTTGTTGACAAAAATCCTCACAATACCACAGAGTCTAGACTCGTGGTGGACTTCTCTCAATTTTCTAGGGGGAACACCCGTGTGTCTTGGCCAAAATTCGCAGTCCCAAATCTCCAGTCACTCACCAACCTGTTGTCCTCCAATTTGTCCTGGTTATCGCTGGATGTGTCTGCGGCGTTTTATCATCTTCCTCTGCATCCTGCTGCTATGCCTCATCTTCTTGTTGGTTCTTCTGGACTATCAAGGTATGTTGCCCGTTTGTCCTCTAATTCCAGGATCATCAACCACCAGCACGGGACCATGCAAGACCTGCACAACTCCTGCTCAAGGAACCTCTATGTTTCCCTCATGTTGCTGTACAAAACCTACGGATGGAAACTGCACCTGTATTCCCATCCCATCATCTTGGGCTTTCGCAAAATACCTATGGGAGTGGGCCTCAGTCCGTTTCTCTTGGCTCAGTTTACTAGTGCCATTTGTTCAGTGGTTCGTAGGGCTTTCCCCCACTGTCTGGCTTTCAGTTATATGGATGATGTGGTATTGGGGGCCAAGTCTGTACAACATCTTGAGTCCCTTTATGCCGCTGTTACCAATTTTCTTTTGTCTTTGGGTATACATTTAAACCCTCACAAAACAAAAAGATGGGGATATTCCCTTAACTTCATGGGATATGTAATTGGGAGTTGGGGCACATTGCCACAGGAACATATTGTACAAAAAATCAAACTATGTTTTAGGAAACTTCCTGTAAACAGGCCTATTGATTGGAAAGTATGTCAACGAATTGTGGGTCTTTTGGGGTTTGCTGCCCCTTTTACGCAATGTGGATATCCTGCTTTAATGCCTTTATATGCATGTATACAAGCAAAACAGGCTTTTACTTTCTCGCCAACTTACAAGGCCTTTCTAAGTAAACAGTATCTAGCCCTTTACCCCGTTGCTCGGCAACGGCCTGGTCTGTGCCAAGTGTTTGCTGACGCAACCCCCACTGGTTGGGGCTTGGCCATAGGCCATCAGCGCATGCGTGGAACCTTTGTGTCTCCTCTGCCGATCCATACTGCGGAACTCCTAGCCGCTTGTTTTGCTCGCAGCAGGTCTGGAGCGAAACTCATCGGGACTGACAATTCTGTCGTGCTCTCCCGCAAGTATACATCGTTTCCATGGCTGCTAGGCTGTGCTGCCAACTGGATCCTGCGCGGGACGTCCTTTGTTTACGTCCCGTCGGCGCTGAATCCCGCGGACGACCCCTCCCGGGGCCGCTTGGGGCTCTACCGCCCGCTTCTCCGTCTGCCGTACCGACCGACCACGGGGCGCACCTCTCTTTACGCGGACTCCCCGTCTGTGCCTTCTCGTCTGCCGGACCGTGTGCACTTCGCTTCACCTCTGCACGTCGCATGGAAACCACCGTGAACGCCCACCGGAACCTGCCCAAGGTCTTGCACAAGAGGACTCTTGGACTTTCAGCAATGTCAACGACCGACCTTGAGGCATACTTCAAAGACTGTGTGTTTCATGAGTGGGAGGAGCTGGGGGAGGAGATTAGGTTAAAGGTCTTTGTACTAGGAGGCTGTAGGCATAAATTGGTCTGTTCACCAGCACCATGCAACTTTTTCACCTCTGCCTAGTCATCTCTTGTTCATGTCCTACTGTTCAAGCCTCCAAGCTGTGCCTTGGGTGGCTTTGGGACATGGACATTGACCCTTATAAAGAATTTGGAGCTACTGTGGAGTTACTCTCTTTTTTGCCTTCTGACTTCTTTCCGTCGGTACGAGACCTCCTAGATACCGCTGCTGCTCTGTATCGGGAAGCCTTAGAATCTCCTGAACATTGCTCACCTCACCACACAGCACTCAGGCAAGCTATTCTGTGCTGGGGGGAATTAATGACTCTAGCTACCTGGGTGGGTAATAATTTAGAAGATCCAGCGTCCAGGGATCTAGTAGTCAATTATGTTAACACTAACATGGGCCTAAAGATCAGGCAATTATTGTGGTTTCACATTTCCTGTCTTACTTTTGGAAGAGAAACTGTTCTTGAATATTTGGTGTCTTTTGGAGTGTGGATTCGCACTCCTCCGGCCTACAGACCACCAAATGCCCCTATCTTATCAACACTTCCGGAAACTACTGTTGTTAGACGACGAGGCAGGTCCCCTAGAAGAAGAACTCCCTCGCCTCGCAGACGAAGGTCTCAATCACCGCGTCGCAGAAGATCTCAATCTCGGGAATCCCAATGTTAGTATTCCTTGGACTCATAAGGTGGGAAACTTTACGGGGCTCTATTCTTCTACAGTACCTGTCTTTAATCCTGAATGGCAAACTCCTTCTTTTCCAGACATTCATTTGCAGGAGGATATTGTTGATAGATGTAAGCAATTTGTGGGACCCCTTACAGTAAATGAAAACAGGAGACTAAAATTAATAATGCCTGCTAGATTTTATCCTAATGTTACCAAATATTTGCCCTTAGATAAAGGGATCAAACCTTATTATCCAGAGCATGTAGTTAATCATTACTTCCAGACAAGACATTATTTGCATACTCTTTGGAAGGCGGGTATCTTATATAAGAGAGAGTCAACACATAGCGCCTCATTTTGCGGGTCACCATATTCTTGGGAACAAGATCTACAGCATGGGAGGTTGGTCTTCCAAACCTCGAAAAGGCATGGGGACAAATCTTTCTGTCCCCAATCCCCTGGGATTCTTCCCCGATCATCAGTTGGACCCTGCATTCAAAGCCAACTCAGAAAATCCAGATTGGGACCTCAACCCACACAAGGACAACTGGCCGGACGCCCACAAGGTGGGAGTGGGAGCATTCGGGCCAGGGTTCACCCCTCCCCACGGGGGACTGTTGGGGTGGAGCCCTCAGGCTCAGGGCATACTTACATCTGTGCCAGCAGCTCCTCCTCCTGCCTCCACCAATCGGCAGTCAGGAAGGCAGCCTACTCCCTTATCTCCACCTCTAAGGGACACTCATCCTCAGGCCATGCAGTGG
SEQ ID NO:30:
HBV基因組的核苷酸序列,HBV基因型C(Genbank登錄號AB540584)
AACTCCACAACTTTCCACCAAGCTCTGCTAGATCCCAGAGTGAGGGGCCTATACTTTCCTGCTGGTGGCTCCAGTTCCGGAACAGTAAACCCTGTTCCGACTACTGCCTCTCCCATATCGTCAATCTTCACGAGGACTGGGGACCCTGTACCGAACATGGAGAACACAACATCAGGATTCCTAGGACCCCTGCTCGTGTTACAGGCGGGGTTTTTCTTGTTGACAAGAATCCTCACAATACCGCAGAGTCTAGACTCGTGGTGGACTTCTCTCAATTTTCTAGGGGGAGCACCCACGTGTCCTGGCCAAAATTCGCAGTCCCCAACCTCCAATCACTCACCAACCTCTTGTCCTCCAATTTGTCCTGGCTATCGCTGGATGTGTCTGCGGCGTTTTATCATATTCCTCTTCATCCTGCTGCTATGCCTCATCTTCTTGTTGGTTCTTCTGGACTATCAAGGTATGTTGCCCGTTTGTCCTCTACTTCCAGGAACATCAACTACAAGCACGGGACCATGCAAGACCTGCACGATTCCTGCTCAAGGAAMCTCTATGTTTCCCTCTTGTTGCTGTACAAAACCTTCGGACGGAAACTGCACTTGTATTCCCATCCCATCATCCTGGGCTTTCGCAAGATTCCTATGGGAGTGGGCCTCAGTCCGTTTCTCCTGGCTCAGTTTACTAGTGCCATTTGTTCAGTGGTTCGTAGGGCTTTCCCCCACTGTTTGGCTTTCAGCTATATGGATGATGTGGTATTGGGGGCCAAGTCTGTACAACATCTTGAGTCCCTTTTTACCTCTATTACCAATTTTCTTTTGTCTTTGGGTATACATTTGAACCCTAATAAAACCAAGCGTTGGGGCTACTCCCTTAACTTTATGGGATATGTAATTGGAAGTTGGGGTACTTTACCACAGGAACATATTGTTCTAAAAATCAAACAATGTTTTCGGAAACTGCCTGTAAATAGACCTATTGATTGGAAAGTATGTCAACGAATTGTGGGTCTTCTGGGCTTTGCTGCCCCTTTTACACAATGTGGGTATCCTGCCTTGATGCCTTTGTATGCATGTATACAAGCTAAGCAGGCTTTCACTTTCTCGCCAACTTATAAGGCCTTTCTGTGTAAACAATATCTGAACCTTTACCCCGTTGCTCGGCAACGGTCAGGTCTCTGCCAAGTATTTGCTGACGCAACCCCCACTGGATGGGGCTTGGCAATAGGCCATCAGCGCATGCGTGGAACCTTTGTGGCTCCTCTGCCGATCCATACTGCGGAACTCTTAGCAGCCTGCTTTGCTCGCAGCCGGTCTGGAGCRAATCTTATTGGAACCGACAACTCCGTTGTCCTCTCTCGGAAATACACCTCCTTTCCATGGCTGCTAGGGTGTGCTGCAAACTGGATCCTGCGCGGGACGTCCTTTGTCTACGTCCCGTCGGCGCTGAATCCAGCGGACGACCCGTCTCGGGGCCGTTTGGGACTCTACCGTCCCCTTCTTCGTCTGCCGTTCCGGCCGACCACGGGGCGCACCTCTCTTTACGCGGTCTCCCCGTCTGTGCCTTCTCATCTGCCGGACCGTGTGCACTTCGCTTCACCTCTGCACGTCGCATGGAGACCACCGTGAACGCCCACCAGGTCTTGCCCAAGGTCTTACATAAGAGGACTCTTGGACTCTCGGCAATGTCAACGACCGACCTTGAGGCATACTTCAAAGACTGTGTGTTTAAAGACTGGGAGGAGTTGGGGGAGGAGATTAGGTTAAAGGTCTTTGTACTAGGAGGCTGTAGGCATAAATTGGTCTGTTCACCAGCACCATGCAACTTTTTCACCTCTGCCTAATCATCTCATGTTCATGTCCTACTGTTCAAGCCTCCAAGCTGTGCCTTGGGTGGCTTTGGGGCATGGACATTGACCCGTATAAAGAATTTGGAGCTTCTGTGGAGTTACTCTCTTTTTTGCCTTCTGACTTCTTTCCTTCCATTCGAGATCTCCTCGACACCGCCTCTGCTCTGTATCGGGAGGCCTTAGAGTCTCCGGAACATTGTTCACCTCACCATACAGCACTCAGGCAAGCTATTCTGTGTTGGGGTGAGTTGATGAATCTGGCCACCTGGGTGGGAAGTAATTTGGAAGACCCAGCATCTAGGGAATTAGTAGTCAGTTATGTTAATGTTAATATGGGCCTAAAGATCAGACAACTATTGTGGTTTCACATTTCCTGTCTTACTTTTGGAAGAGAAACTGTTCTTGAGTATTTGGTGTCCTTTGGAGTGTGGATACGCACTCCTCCCGCTTACAGACCACCAAATGCCCCTATCTTATCAACACTTCCGGAAACTACTGTTGTTAGACGACGAGGCAGGTCCCCTAGAAGAAGAACTCCCTCGCCTCGCAGACGAAGGTCTCAATCGCCGCGTCGCAGAAGATCTCAATCTCGGGAATCTCAATGTTAGTATCCCTTGGACTCATAAGGTGGGAAATTTTACTGGGCTTTATTCTTCTACTGTACCTGTCTTCAATCCTGAGTGGCAAACTCCCTCCTTTCCTCACATTCATTTGCAGGAGGACATTATTAATAGATGTCAACAATATGTGGGCCCTCTTACAGTTAATGAAAAAAGGAGATTAAAATTAATTATGCCTGCCAGGTTTTATCCTAACCGTACCAAATATTTGCCCCTAGATAAAGGCATTAAACCTTATTATCCTGAATATACAGTTAATCATTACTTCCAAACCAGGCATTATTTACATACTCTGTGGAAGGCTGGCATTCTATATAAGAGAGAAACTACACGCAGCGCCTCATTTTGTGGGTCACCATATTCTTGGGAACAAGAGCTACAGCATGGGAGGTTGGTCCTCCAAACCTCGAAAGGGCATGGGGACGAATCTTTCTGTTCCCAATCCTCTGGGCTTCTTTCCCGATCACCAGTTGGACCCTGCATTCGGAGCCAACTCAAACAATCCGGATTGGGACTTCAATCCCAACAAGGATCACTGGCCAGCAGCAAACCAGGTAGGAGCGGGAGCCTTCGGGCCAGGGTTCACCCCACCGCACGGCGGTCTTTTGGGGTGGAGCCCTCAGGCTCAGGGCGTATTGACAACAGTGCCAGCAGCGCCTCCTCCTGCCTCCACCAATCGGCAGTCAGGCAGACAGCCTACTCCCATCTCTCCACCTCTAAGAGACAGTCATCCTCAGGCCATGCAGTGG
SEQ ID NO:31:
HBV基因組的核苷酸序列,HBV基因型E(Genbank登錄號AP007262)
AATTCCACAACATTCCACCAAGCTCTGCAGGATCCCAGAGTAAGAGGCCTGTATCTTCCTGCTGGTGGCTCCAGTTCCGGAACAGTGAACCCTGTTCCGACTACTGCCTCACTCATCTCGTCAATCTTCTCGAGGATTGGGGACCCTGCACCGAACATGGAAGGCATCACATCAGGATTCCTAGGACCCCTGCTCGTGTTACAGGCGGGGTTTTTCTTGTTGACAAAAATCCTCACAATACCGCAGAGTCTAGACTCGTGGTGGACTTCTCTCAATTTTCTAGGGGGAGCTCCCGTGTGTCTTGGCCAAAATTCGCAGTCCCCAATCTCCAATCACTCACCAACCTCTTGTCCTCCAATTTGTCCTGGCTATCGCTGGATGTGTCTGCGGCGTTTTATCATCTTCCTCTTCATCCTGCTGCTATGCCTCATCTTCTTGTTGGTTCTTCTGGACTATCAAGGTATGTTGCCCGTTTGTCCTCTAATTCCAGGATCATCAACCACCAGTACGGGACCCTGCCGAACCTGCACGACTCTTGCTCAAGGAACCTCTATGTTTCCCTCATGTTGTTGTTTAAAACCTTCGGACGGAAATTGCACTTGTATTCCCATCCCATCATCATGGGCTTTCGGAAAATTCCTATGGGAGTGGGCCTCAGCCCGTTTCTCCTGGCTCAGTTTACTAGTGCCATTTGTTCAGTGGTTCGCCGGGCTTTCCCCCACTGTCTGGCTTTCAGTTATATGGATGATGTGGTATTGGGGGCCAAGTCTGTACAACATCTTGAGTCCCTTTATACCTCTGTTACCAATTTTCTTTTGTCTTTGGGTATACATTTAAATCCCAACAAAACAAAAAGATGGGGATATTCCCTAAATTTCATGGGTTATGTAATTGGTAGTTGGGGGTCATTACCACAAGAACACATCAGACTGAAAATCAAAGACTGTTTTAGAAAGCTCCCTGTTAACAGGCCTATTGATTGGAAAGTATGTCAAAGAATTGTGGGTCTTTTGGGCTTTGCTGCCCCTTTTACACAATGTGGATATCCTGCTTTAATGCCTCTATATGCGTGTATTCAATCTAAGCAGGCTTTCACTTTCTCGCCAACTTACAAGGCCTTTCTGTGTAAACAATATATGAACCTTTACCCCGTTGCCCGGCAACGGCCAGGTCTGTGCCAAGTGTTTGCTGATGCAACCCCCACTGGCTGGGGCTTGGCCATAGGCCATCAGCGCATGCGTGGAACCTTTGTGGCTCCTCTGCCGATCCATACTGCGGAACTCCTAGCCGCTTGTTTTGCTCGCAGCAGGTCTGGAGCGAAACTCATAGGGACAGATAATTCTGTCGTTCTCTCCCGGAAATATACATCATTTCCATGGCTGCTAGGCTGTGCTGCCAACTGGATCCTGCGAGGGACGTCCTTTGTCTACGTCCCGTCAGCGCTGAATCCTGCGGACGACCCCTCTCGGGGCCGCTTGGGGGTCTATCGTCCCCTTCTCCGTCTGCCGTTCCGGCCGACCACGGGGCGCACCTCTCTTTACGCGGTCTCCCCGTCTGTGCCTTCTCATCTGCCGGACCGTGTGCACTTCGCTTCACCTCTGCACGTCGCATGGAGACCACCGTGAACGCCCACCAGATCTTGCCCAAGGTCTTACATAAGAGGACTCTTGGACTCTCTGCAATGTCAACGACCGACCTTGAGGCATACTTCAAAGACTGTTTGTTTAAAGACTGGGAGGAGTTGGGGGAGGAGACTAGATTAATGATCTTTGTACTAGGAGGCTGTAGGCATAAATTGGTCTGCGCACCAGCACCATGCAACTTTTTCACCTCTGCCTAATCATCTCTTGTTCATGTCCTACTGTTCAAGCCTCCAAGCTGTGCCTTGGGTGGCTTTGGGACATGGACATTGACCCTTATAAAGAATTTGGAGCTACTGTGGAGTTACTCTCGTTTTTGCCTTCTGACTTCTTTCCTTCAGTAAGAGATCTTCTAGATACCGCCTCTGCTCTGTATCGGGATGCCTTAGAATCTCCTGAGCATTGTTCACCTCACCATACTGCACTCAGGCAAGCCATTCTTTGCTGGGGAGAATTAATGACTCTAGCTACCTGGGTGGGTGTAAATTTGGAAGATCCAGCATCCAGGGACCTAGTAGTCAGTTATGTCAATACTAATATGGGCCTAAAGTTCAGGCAATTATTGTGGTTTCACATTTCTTGTCTCACTTTTGGAAGAGAAACCGTCATAGAGTATTTGGTGTCTTTTGGAGTGTGGATTCGCACTCCTCCAGCTTATAGACCACCAAATGCCCCTATCTTATCAACACTTCCGGAGAATACTGTTGTTAGACGAAGAGGCAGGTCCCCTAGAAGAAGAACTCCCTCGCCTCGCAGACGAAGATCTCAATCGCCGCGTCGCAGAAGATCTCAATCTCCAGCTTCCCAATGTTAGTATTCCTTGGACTCACAAGGTGGGAAATTTTACGGGGCTTTATTCTTCTACTATACCTGTCTTTAATCCTAACTGGAAAACTCCATCTTTTCCTGATATTCATTTGCACCAGGACATTATTAACAAATGTGAACAATTTGTAGGTCCTYTAACAGTAAATGAAAAACGAAGATTAAACTTAGTCATGCCTGCTAGATTTTTTCCCATCTCCACGAAATATTTGCCCCTAGAGAAAGGTATAAAACCTTATTATCCAGATAATGTAGTTAATCATTACTTCCAAACCAGACACTATTTACATACCCTATGGAAGGCGGGCATCTTATATAAAAGAGAAACTACCCGTAGCGCCTCATTTTGTGGGTCACCTTATTCTTGGGAACACGAGCTACATCATGGGGCTTTCTTGGACGGTCCCTCTCGAATGGGGGAAGAATCATTCCACCACCAATCCTCTGGGATTTTTTCCCGACCACCAGTTGGATCCAGCATTCAGAGCAAACACCAGAAATCCAGATTGGGACCACAATCCCAACAAAGACCACTGGACAGAAGCCAACAAGGTAGGAGTGGGAGCATTTGGGCCGGGGTTCACTCCCCCACACGGAGGCCTTTTGGGGTGGAGCCCTCAGGCTCAAGGCATGCTAAAAACATTGCCAGCAAATCCGCCTCCTGCCTCCACCAATCGGCAGTCAGGAAGGCAGCCTACCCCAATCACTCCACCTTTGAGAGACACTCATCCTCAGGCCATGCAGTGG
SEQ ID NO:32:
HBV基因組的核苷酸序列,HBV基因型F(Genbank登錄號HE974366)
AACTCAACCCAGTTCCATCAGGCTCTGTTGGATCCCAGGGTAAGGGCTCTGTATCTTCCTGCTGGTGGCTCCAGTTCAGGAACACAAAACCCTGCTCCGACTATTGCCTCTCTCACATCCTCAATCTTCTCGACGACTGGGGGCCCTGCTATGAACATGGACAACATTACATCAGGACTCCTAGGACCCCTGCTCGTGTTACAGGCGGTGTGTTTCTTGTTGACAAAAATCCTCACAATACCACAGAGTCTAGACTCGTGGTGGACTTCTCTCAATTTTCTAGGGGGACTACCCGGGTGTCCTGGCCAAAATTCGCAGTCCCCAACCTCCAATCACTTACCAACCTCCTGTCCTCCAACTTGTCCTGGCTATCGTTGGATGTGTCTGCGGCGTTTTATCATCTTCCTCTTCATCCTGCTGCTATGCCTCATCTTCTTGTTGGTTCTTCTGGACTACCAGGGTATGTTGCCCGTTTGTCCTCTACTTCCAGGATCCACGACCACCAGCACGGGACCCTGCAAAACCTGCACAACTCTTGCACAAGGAACCTCTATGTTTCCCTCCTGTTGCTGTTCAAAACCCTCGGACGGAAACTGCACTTGTATTCCCATCCCATCATCCTGGGCTTTAGGAAAATACCTATGGGAGTGGGCCTCAGCCCGTTTCTCATGGCTCAGTTTACTAGTGCAATTTGTTCAGTGGTGCGTAGGGCTTTCCCCCACTGTCTGGCTTTTAGTTATATTGATGATCTGGTATTGGGGGCCAAATCTGTGCAGCACCTTGAGTCCCTTTATACCGCTGTTACCAATTTTCTGTTATCTGTGGGTATCCATTTAAATACTTCTAAAACTAAGAGATGGGGTTACACCCTACATTTTATGGGTTATGTCATTGGTAGTTGGGGATCATTACCTCAAGATCATATTGTACACAAAATCAAAGAATGTTTTCGGAAACTGCCTGTAAATCGTCCAATTGATTGGAAAGTCTGTCAACGCATTGTGGGTCTTTTGGGCTTTGCTGCCCCTTTCACACAATGTGGTTATCCTGCTCTCATGCCTCTGTATGCTTGTATTACTGCTAAACAGGCTTTTGTTTTTTCGCCAACTTACAAGGCCTTTCTCTGTAAACAATACATGAACCTTTACCCCGTTGCCAGGCAACGGCCGGGCCTGTGCCAAGTGTTTGCTGACGCAACCCCCACTGGTTGGGGCTTGGCCATTGGCCATCAGCGCATGCGTGGAACCTTTGTGGCTCCTCTGCCGATCCATACTGCGGAACTCCTTGCAGCTTGTTTCGCTCGCAGCAGGTCTGGAGCGACTCTCATCGGCACGGACAACTCTGTTGTCCTCTCTAGGAAGTACACCTCCTTCCCATGGCTGCTCGGGTGTGCTGCAAACTGGATCCTGCGCGGGACGTCCTTTGTTTACGTCCCGTCGGCGCTGAATCCCGCGGACGACCCCTCCCGGGGCCGCTTGGGGCTGTACCGCCCTCTTCTCCGTCTGCCGTTCCAGCCGACAACGGGTCGCACCTCTCTTTACGCGGACTCCCCGTCTGTTCCTTCTCATCTGCCGGACCGTGTGCACTTCGCTTCACCTCTGCACGTCGCATGGAGACCACCGTGAACGCCCCTTGGAGTTTGCCAACAGTCTTACATAAGAGGACTCTTGGACTTTCAGGAGGGTCAATGACCCGGATTGCAGAATACATCAAAGACTGTGTATTTAAGGACTGGGAGGAGTTGGGGGAGGAGACTAGGTTAATGATCTTTGTACTAGGAGGCTGTAGGCATAAATTGGTCTGTTCACCAGCACCATGCAACTTTTTCACCTCTGCCTAATCATCTTTTGTTCATGTCCTACTGTTCAAGCCTCCAAGCTGTGCCTTGGGTGGCTTTGGGACATGGACATTGACCCTTATAAAGAATTTGGCGCTTCTGTGGAGTTACTCTCTTTTTTGCCTTCTGATTTCTTTCCATCGGTTCGGGACCTACTCGACACCGCTTCAGCCCTTTACCGGGATGCTTTAGAGTCACCTGAACATTGCACTCCCCATCACACTGCCCTCAGGCAAGTTATTTTGTGCTGGGGTGAGTTAATGACTTTGGCTTCCTGGGTGGGCAATAACTTGGAAGACCCTGCTGCCAGGGATTTAGTAGTTAACTATGTTAACACTAACATGGGCCTAAAAATTAGACAACTACTGTGGTTTCACATTTCCTGCCTTACTTTTGGAAGAGATATAGTTCTTGAGTATTTGGTGTCCTTTGGAGTGTGGATTCGCACTCCTCCTGCTTACAGACCACAAAATGCCCCTATCCTATCCACACTTCCGGAAACTACTGTTGTTAGACGACGAGGCAGGTCCCCTAGAAGAAGAACTCCCTCGCCTCGCAGACGAAGATCTCAATCGCCGCGTCGCCGAAGATCTCAATCTCCAGCTTCCCAATGTTAGTATTCCTTGGACTCATAAGGTGGGAAATTTTACGGGGCTTTACTCTTCTACTGTGCCTGCTTTTAATCCTGACTGGTTAACTCCTTCTTTTCCTAATATTCATTTACATCAAGACCTAATTTCTAAATGTGAACAATTTGTAGGCCCACTCACTAAAAATGAATTAAGGAGGTTAAAATTGGTTATGCCAGCTAGATTTTATCCTAAGGTTACCAAATATTTTCCTATGGAGAAAGGAATCAAGCCTTATTATCCTGAGCATGCAGTTAATCATTACTTTAAAACAAGACATTATTTGCATACTTTATGGAAGGCGGGAATTTTATATAAGAGAGAATCCACACGTAGCGCATCATTTTGTGGGTCACCATATTCCTGGGAACAAGAGCTACAGCATGGGAGCACCTCTCTCAACGACAAGAAGAGGCATGGGACAGAATCTTTCTGTGCCCAATCCTCTGGGATTCTTTCCAGACCATCAGCTGGATCCGCTATTCAAAGCAAATTCCAGCAGTCCCGACTGGGACTTCAACACAAACAAGGACAGTTGGCCAATGGCAAACAAGGTAGGAGTGGGAGCATACGGTCCAGGGTTCACACCCCCACACGGTGGCCTGCTGGGGTGGAGCCCTCAGGCACAAGGTATGTTAACAACCTTGCCAGCAGATCCGCCTCCTGCTTCCACCAATCGGCGGTCCGGGAGAAAGCCAACCCCAGTCTCTCCACCTCTAAGAGACACTCATCCACAGGCAATGCAGTGG
SEQ ID NO:33:
HBV基因組的核苷酸序列,HBV基因型G(Genbank登錄號AP007264)
AACTCTACAGCATTCCACCAAGCTCTACAAAATCCCAAAGTCAGGGGCCTGTATTTTCCTGCTGGTGGCTCCAGTTCAGGGATAGTGAACCCTGTTCCGACTATTGCCTCTCACATCTCGTCAATCTTCTCCAGGATTGGGGACCCTGCACCGAACATGGAGAACATCACATCAGGATTCCTAGGACCCCTGCTCGTGTTACAGGCGGGGTTTTTCTTGTTGACAAGAATCCTCACAATACCGCAGAGTCTAGACTCGTGGTGGACTTCTCTCAATTTTCTAGGGGGAGTGCCCGTGTGTCCTGGCCTAAATTCGCAGTCCCCAACCTCCAATCACTCACCAATCTCCTGTCCTCCAACTTGTCCTGGCTATCGCTGGATGTGTCTGCGGCGTTTTATCATATTCCTCTTCATCCTGCTGCTATGCCTCATCTTCTTGTTGGTTCTTCTGGACTATCAAGGTATGTTGCCCGTTTGTCCTCTGATTCCAGGATCCTCGACCACCAGTACGGGACCCTGCAAAACCTGCACGACTCCTGCTCAAGGCAACTCTATGTATCCCTCATGTTGCTGTACAAAACCTTCGGACGGAAATTGCACCTGTATTCCCATCCCATCATCTTGGGCTTTCGCAAAATACCTATGGGAGTGGGCCTCAGTCCGTTTCTCTTGGCTCAGTTTACTAGTGCCATTTGTTCAGTGGTTCGTAGGGCTTTCCCCCACTGTCTGGCTTTCAGCTATATGGATGATGTGGTATTGGGGGCCAAATCTGTACAACATCTTGAGTCCCTTTATACCGCTGTTACCAATTTTCTTTTGTCTTTGGGTATACATCTAAACCCTAACAAAACAAAAAGATGGGGTTATTCCTTAAATTTTATGGGATATGTAATTGGAAGTTGGGGTACTTTGCCACAAGAACACATCACACAGAAAATTAAGCAATGTTTTCGGAAACTCCCTGTTAACAGGCCAATTGATTGGAAAGTCTGTCAACGAATAACTGGTCTGTTGGGTTTCGCTGCTCCTTTTACCCAATGTGGTTACCCTGCCTTAATGCCTTTATATGCATGTATACAAGCTAAGCAGGCTTTTACTTTCTCGCCAACTTATAAGGCCTTTCTCTGTAAACAATACATGAACCTTTACCCCGTTGCTAGGCAACGGCCCGGTCTGTGCCAAGTGTTTGCTGACGCAACCCCCACTGGTTGGGGCTTGGCCATCGGCCATCAGCGCATGCGTGGAACCTTTGTGGCTCCTCTGCCGATCCATACTGCGGAACTCCTAGCTGCTTGTTTTGCTCGCAGCCGGTCTGGAGCAAAACTCATTGGGACTGACAATTCTGTCGTCCTTTCTCGGAAATATACATCCTTTCCATGGCTGCTAGGCTGTGCTGCCAACTGGATCCTTCGCGGGACGTCCTTTGTTTACGTCCCGTCAGCGCTGAATCCAGCGGACGACCCCTCCCGGGGCCGTTTGGGGCTCTGTCGCCCCCTTCTCCGTCTGCCGTTCCTGCCGACCACGGGGCGCACCTCTCTTTACGCGGTCTCCCCGTCTGTGCCTTCTCATCTGCCGGACCGTGTGCACTTCGCTTCACCTCTGCACGTTACATGGAAACCGCCATGAACACCTCTCATCATCTGCCAAGGCAGTTATATAAGAGGACTCTTGGACTGTTTGTTATGTCAACAACCGGGGTGGAGAAATACTTCAAGGACTGTGTTTTTGCTGAGTGGGAAGAATTAGGCAATGAGTCCAGGTTAATGACCTTTGTATTAGGAGGCTGTAGGCATAAATTGGTCTGCGCACCAGCACCATGTAACTTTTTCACCTCTGCCTAATCATCTCTTGTTCATGTCCTACTGTTCAAGCCTCCAAGCTGTGCCTTGGGTGGCTTTAGGGCATGGATAGAACAACTTTGCCATATGGCCTTTTTGGCTTAGACATTGACCCTTATAAAGAATTTGGAGCTACTGTGGAGTTGCTCTCGTTTTTGCCTTCTGACTTTTTCCCGTCTGTTCGTGATCTTCTCGACACCGCTTCAGCTTTGTACCGGGAATCCTTAGAGTCCTCTGATCATTGTTCGCCTCACCATACAGCACTCAGGCAAGCAATCCTGTGCTGGGGTGAGTTGATGACTCTAGCTACCTGGGTGGGTAATAATTTGGAAGATCCAGCATCCAGAGATTTGGTGGTCAATTATGTTAATACTAATATGGGTTTAAAAATCAGGCAACTATTGTGGTTTCACATTTCCTGTCTTACTTTTGGGAGAGAAACCGTTCTTGAGTATTTGGTGTCTTTTGGAGTGTGGATTCGCACTCCTCCTGCTTATAGACCACCAAATGCCCCTATCCTATCAACACTTCCGGAGACTACTGTTGTTAGACGAAGAGGCAGGTCCCCTCGAAGAAGAACTCCCTCGCCTCGCAGACGAAGATCTCAATCGCCGCGTCGCAGAAGATCTGCATCTCCAGCTTCCCAATGTTAGTATTCCTTGGACTCACAAGGTGGGAAACTTTACGGGGCTGTATTCTTCTACTATACCTGTCTTTAATCCTGATTGGCAAACTCCTTCTTTTCCAAATATCCATTTGCATCAAGACATTATAACTAAATGTGAACAATTTGTGGGCCCTCTCACAGTAAATGAGAAACGAAGATTAAAACTAGTTATGCCTGCCAGATTTTTCCCAAACTCTACTAAATATTTACCATTAGACAAAGGTATCAAACCGTATTATCCAGAAAATGTAGTTAATCATTACTTCCAGACCAGACATTATTTACATACCCTTTGGAAGGCGGGTATTCTATATAAGAGAGAAACGTCCCGTAGCGCTTCATTTTGTGGGTCACCATATACTTGGGAACAAGATCTACAGCATGGGGCTTTCTTGGACGGTCCCTCTCGAGTGGGGAAAGAACCTTTCCACCAGCAATCCTCTAGGATTCCTTCCCGATCACCAGTTGGACCCAGCATTCAGAGCAAATACCAACAATCCAGATTGGGACTTCAATCCCAAAAAGGACCCTTGGCCAGAGGCCAACAAAGTAGGAGTTGGAGCCTATGGACCCGGGTTCACCCCTCCACACGGAGGCCTTTTGGGGTGGAGCCCTCAGTCTCAGGGCACACTAACAACTTTGCCAGCAGATCCGCCTCCTGCCTCCACCAATCGTCAGTCAGGGAGGCAGCCTACTCCCATCTCTCCACCACTAAGAGACAGTCATCCTCAGGCCATGCAGTGG
SEQ ID NO:34:
HBV基因組的核苷酸序列,HBV基因型H(Genbank登錄號AB516393)
AACTCAACACAGTTCCACCAAGCACTGTTGGATTCGAGAGTAAGGGGTCTGTATTTTCCTGCTGGTGGCTCCAGTTCAGAAACACAGAACCCTGCTCCGACTATTGCCTCTCTCACATCATCAATCTTCTCGAAGACTGGGGACCCTGCTATGAACATGGAGAACATCACATCAGGACTCCTAGGACCCCTTCTCGTGTTACAGGCGGTGTGTTTCTTGTTGACAAAAATCCTCACAATACCACAGAGTCTAGACTCGTGGTGGACTTCTCTCAATTTTCTAGGGGTACCACCCGGGTGTCCTGGCCAAAATTCGCAGTCCCCAATCTCCAATCACTTACCAACCTCCTGTCCTCCAACTTGTCCTGGCTATCGTTGGATGTGTCTGCGGCGTTTTATCATCTTCCTCTTCATCCTGCTGCTATGCCTCATCTTCTTGTTGGTTCTTCTGGACTATCAAGGTATGTTGCCCGTGTGTCCTCTACTTCCAGGATCTACAACCACCAGCACGGGACCCTGCAAAACCTGCACCACTCTTGCTCAAGGAACCTCTATGTTTCCCTCCTGCTGCTGTACCAAACCTTCGGACGGAAATTGCACCTGTATTCCCATCCCATCATCTTGGGCTTTCGGAAAATACCTATGGGAGTGGGCCTCAGCCCGTTTCTCTTGGCTCAGTTTACTAGTGCAATTTGCTCAGTGGTGCGTAGGGCTTTCCCCCACTGTCTGGCTTTTAGTTATATGGATGATTTGGTATTGGGGGCCAAATCTGTGCAGCATCTTGAGTCCCTTTATACCGCTGTTACCAATTTTTTGTTATCTGTGGGCATCCATTTGAACACAGCTAAAACAAAATGGTGGGGTTATTCCTTACACTTTATGGGTTATATAATTGGGAGTTGGGGGACCTTGCCTCAGGAACATATTGTGCATAAAATCAAAGATTGCTTTCGCAAACTTCCCGTGAATAGACCCATTGATTGGAAGGTTTGTCAACGCATTGTGGGTCTTTTGGGCTTTGCAGCCCCTTTTACTCAATGTGGTTATCCTGCTCTCATGCCCTTGTATGCCTGTATTACCGCTAAGCAGGCTTTTGTTTTCTCGCCAACTTACAAGGCCTTTCTCTGTCAACAATACATGAACCTTTACCCCGTTGCTCGGCAACGGCCAGGCCTTTGCCAAGTGTTTGCTGACGCAACCCCCACTGGCTGGGGCTTGGCGATTGGCCATCAGCGCATGCGCGGAACCTTTGTGGCTCCTCTGCCGATCCATACTGCGGAACTCCTAGCAGCCTGTTTCGCTCGCAGCAGGTCTGGAGCGGACGTTATCGGCACTGACAACTCCGTTGTCCTTTCTCGGAAGTACACCTCCTTCCCATGGCTGCTAGGCTGTGCTGCCAACTGGATCCTGCGCGGGACGTCCTTTGTCTACGTCCCGTCGGCGCTGAATCCTGCGGACGACCCCTCTCGTGGTCGCTTGGGGCTCTGCCGCCCTCTTCTCCGCCTACCGTTCCGGCCGACGACGGGTCGCACCTCTCTTTACGCGGACTCCCCGCCTGTGCCTTCTCATCTGCCGGCCCGTGTGCACTTCGCTTCACCTCTGCACGTCGCATGGAGACCACCGTGAACGCCCCTTGGAACTTGCCAACAACCTTACATAAGAGGACTCTTGGACTTTCGCCCCGGTCAACGACCTGGATTGAGGAATACATCAAAGACTGTGTATTTAAGGACTGGGAGGAGTCGGGGGAGGAGTTGAGGTTAAAGGTCTTTGTATTAGGAGGCTGTAGGCATAAATTGGTCTGTTCACCAGCACCATGCAACTTTTTCACCTCTGCCTAATCATCTTTTGTTCATGTCCCACTGTTCAAGCCTCCAAGCTGTGCCTTGGGTGGCTTTGGGGCATGGACATTGACCCTTATAAAGAATTTGGAGCTTCTGTGGAGTTACTCTCATTTTTGCCTTCTGACTTCTTCCCGTCTGTCCGGGACCTACTCGACACCGCTTCAGCCCTCTACCGAGATGCCTTAGAATCACCCGAACATTGCACCCCCAACCACACTGCTCTCAGGCAAGCTATTTTGTGCTGGGGTGAGTTGATGACCTTGGCTTCCTGGGTGGGCAATAATTTAGAGGATCCTGCAGCAAGAGATCTAGTAGTTAATTATGTCAATACTAACATGGGTCTAAAAATTAGACAATTATTATGGTTTCACATTTCCTGCCTTACATTTGGAAGAGAAACTGTGCTTGAGTATTTGGTGTCTTTTGGAGTGTGGATCCGCACTCCACCTGCTTACAGACCACCAAATGCCCCTATCCTATCAACACTTCCGGAGACTACTGTTGTTAGACAACGAGGCAGGGCCCCTAGAAGAAGAACTCCCTCGCCTCGCAGACGAAGATCTCAATCACCGCGTCGCAGAAGATCTCAATCTCCAGCTTCCCAATGTTAGTATTCCTTGGACTCATAAGGTGGGAAACTTTACCGGTCTTTACTCCTCTACTGTACCTGTTTTCAATCCTGACTGGTTAACTCCTTCTTTTCCTGACATTCACTTGCATCAAGATCTGATACAAAAATGTGAACAATTTGTAGGCCCACTCACTACAAATGAAAGGAGACGATTGAAACTAATTATGCCAGCTAGGTTTTATCCCAAAGTTACTAAATACTTCCCTTTGGATAAAGGTATTAAGCCTTACTATCCAGAGAATGTGGTTAATCATTACTTTAAAACTAGACATTATTTACATACTTTGTGGAAGGCAGGAATTCTATATAAGAGAGAATCCACACATAGCGCCTCATTTTGTGGGTCACCATATTCCTGGGAACAAGAGCTACAGCATGGGAGCACCTCTCTCAACGGCGAGAAGGGGCATGGGACAGAATCTTTCTGTGCCCAATCCTCTGGGATTCTTTCCAGACCACCAGTTGGATVCACTATTCAGAGCAAATTCCAGCAGTCCCGATTGGGACTTCAACACAAACAAGGACAATTGGCCAATGGCAAACAAGGTAGGAGTGGGAGGCTTCGGTCCAGGGTTCACACCCCCACACGGTGGCCTTCTGGGGTGGAGCCCTCAGGCACAGGGCATTCTGACAACCTCGCCACCAGATCCACCTCCTGCTTCCACCAATCGGAGGTCAGGAAGAAAGCCAACCCCAGTCTCTCCACCTCTAAGGGACACACATCCACAGGCCATGCAGTGG
SEQ ID NO:35:
載體pTREHBV-HAe的核苷酸序列(5,980nt)
載體:pTRE2(Clontech)
nt 356-452:HBV nt 1805-1902,具有A1816缺失
nt 453-491:HA標籤插入,含側翼序列
nt 462-488:HA標籤序列
nt 492-3761:HBV nt 1903-3182/1-1990
SEQ ID NO:36:
編碼HBV包膜蛋白表面大蛋白(L)的核苷酸序列
ATGGGGCAGAATCTTTCCACCAGCAATCCTCTGGGATTCTTTCCCGACCACCAGTTGGATCCAGCCTTCAGAGCAAACACAGCAAATCCAGATTGGGACTTCAATCCCAACAAGGACACCTGGCCAGACGCCAACAAGGTAGGAGCTGGAGCATTCGGGCTGGGTTTCACCCCACCGCACGGAGGCCTTTTGGGGTGGAGCCCTCAGGCTCAGGGCATACTACAAACTTTGCCAGCAAATCCGCCTCCTGCCTCCACCAATCGCCAGACAGGAAGGCAGCCTACCCCGCTGTCTCCACCTTTGAGAAACACTCATCCTCAGGCCATGCAGTGGAATTCCACAACCTTTCACCAAACTCTGCAAGATCCCAGAGTGAGAGGCCTGTATTTCCCTGCTGGTGGCTCCAGTTCAGGAGCAGTAAACCCTGTTCCGACTACTGCCTCTCCCTTATCGTCAATCTTCTCGAGGATTGGGGACCCTGCGCTGAACATGGAGAACATCACATCAGGATTCCTAGGACCCCTTCTCGTGTTACAGGCGGGGTTTTTCTTGTTGACAAGAATCCTCACAATACCGCAAAGTCTAGACTCGTGGTGGACTTCTCTCAATTTTCTAGGGGGAACTACCGTGTGTCTTGGCCAAAATTCGCAGTCCCCAACCTCCAATCACTCACCAACCTCCTGTCCTCCAACTTGTCCTGGTTATCGCTGGATGTGTCTGCGGCGTTTTATCATCTTCCTCTTCATCCTGCTGCTATGCCTCATCTTCTTGTTGGTTCTTCTGGACTATCAAGGTATGTTGCCCGTTTGTCCTCTAATTCCAGGATCCTCAACCACCAGCACGGGACCATGCCGAACCTGCATGACTACTGCTCAAGGAACCTCTATGTATCCCTCCTGTTGCTGTACCAAACCTTCGGACGGAAATTGCACCTGTATTCCCATCCCATCATCCTGGGCTTTCGGAAAATTCCTATGGGAGTGGGCCTCAGCCCGTTTCTCCTGGCTCAGTTTACTAGTGCCATTTGTTCAGTGGTTCGTAGGGCTTTCCCCCACTGTTTGGCTTTCAGTTATATGGATGATGTGGTATTGGGGGCCAAGTCTGTACAGCATCTTGAGTCCCTTTTTACCGCTGTTACCAATTTTCTTTTGTCTTTGGGTATACATTTAA
SEQ ID NO:37:
編碼HBV包膜蛋白表面中等蛋白(M)的核苷酸序列
ATGCAGTGGAATTCCACAACCTTTCACCAAACTCTGCAAGATCCCAGAGTGAGAGGCCTGTATTTCCCTGCTGGTGGCTCCAGTTCAGGAGCAGTAAACCCTGTTCCGACTACTGCCTCTCCCTTATCGTCAATCTTCTCGAGGATTGGGGACCCTGCGCTGAACATGGAGAACATCACATCAGGATTCCTAGGACCCCTTCTCGTGTTACAGGCGGGGTTTTTCTTGTTGACAAGAATCCTCACAATACCGCAAAGTCTAGACTCGTGGTGGACTTCTCTCAATTTTCTAGGGGGAACTACCGTGTGTCTTGGCCAAAATTCGCAGTCCCCAACCTCCAATCACTCACCAACCTCCTGTCCTCCAACTTGTCCTGGTTATCGCTGGATGTGTCTGCGGCGTTTTATCATCTTCCTCTTCATCCTGCTGCTATGCCTCATCTTCTTGTTGGTTCTTCTGGACTATCAAGGTATGTTGCCCGTTTGTCCTCTAATTCCAGGATCCTCAACCACCAGCACGGGACCATGCCGAACCTGCATGACTACTGCTCAAGGAACCTCTATGTATCCCTCCTGTTGCTGTACCAAACCTTCGGACGGAAATTGCACCTGTATTCCCATCCCATCATCCTGGGCTTTCGGAAAATTCCTATGGGAGTGGGCCTCAGCCCGTTTCTCCTGGCTCAGTTTACTAGTGCCATTTGTTCAGTGGTTCGTAGGGCTTTCCCCCACTGTITGGCTTTCAGTTATATGGATGATGTGGTATTGGGGGCCAAGTCTGTACAGCATCTTGAGTCCCTTTTTACCGCTGTTACCAATTTTCTTTTGTCTTTGGGTATACATTTAA
SEQ ID NO:38:
編碼HBV包膜蛋白表面小蛋白(S)的核苷酸序列
ATGGAGAACATCACATCAGGATTCCTAGGACCCCTTCTCGTGTTACAGGCGGGGTTTTTCTTGTTGACAAGAATCCTCACAATACCGCAAAGTCTAGACTCGTGGTGGACTTCTCTCAATTTTCTAGGGGGAACTACCGTGTGTCTTGGCCAAAATTCGCAGTCCCCAACCTCCAATCACTCACCAACCTCCTGTCCTCCAACTTGTCCTGGTTATCGCTGGATGTGTCTGCGGCGTTTTATCATCTTCCTCTTCATCCTGCTGCTATGCCTCATCTTCTTGTTGGTTCTTCTGGACTATCAAGGTATGTTGCCCGTTTGTCCTCTAATTCCAGGATCCTCAACCACCAGCACGGGACCATGCCGAACCTGCATGACTACTGCTCAAGGAACCTCTATGTATCCCTCCTGTTGCTGTACCAAACCTTCGGACGGAAATTGCACCTGTATTCCCATCCCATCATCCTGGGCTTTCGGAAAATTCCTATGGGAGTGGGCCTCAGCCCGTTTCTCCTGGCTCAGTTTACTAGTGCCATTTGTTCAGTGGTTCGTAGGGCTTTCCCCCACTGTTTGGCTTTCAGTTATATGGATGATGTGGTATTGGGGGCCAAGTCTGTACAGCATCTTGAGTCCCTTTTTACCGCTGTTACCAATTTTCTTTTGTCTTTGGGTATACATTTAA
SEQ ID NO:39:
表達載體pcHA-HBe的核苷酸序列(6,682nt)
載體:pcDNA3.1/V5-His-TOPO(Invitrogen)
nt 929-1015:HBVnt 1816-1902
nt 1016-1054:插入
nt 1025-1051:HA標籤序列
nt 1055-21 12:HBV1903-2605/1573-1926
SEQ ID NO:40:
標籤N末端的胺基酸序列
VDI
SEQ ID NO:41:
包含5』和3』額外核苷酸的編碼HA標籤核苷酸序列。加下劃線的核苷酸顯示編碼HA標籤的序列。
GTGGACATCTACCCATACGACGTTCCAGATTACGCTGGC
SEQ ID NO:42:
包含N末端和C末端額外胺基酸的HA標籤的胺基酸序列。加下劃線的胺基酸殘基顯示HA標籤的序列。
VDIYPYDVPDYAG
如本文中討論的額外參考文獻
1.Arzumanyan,A.,H.M.Reis和M.A.Feitelson.2013.Pathogenic mechanisms in HBV-and HCV-associated hepatocellular carcinoma.Nature reviews.Cancer 13:123-135.
2.Block,T.M.,H.Guo和J.T.Guo.2007.Molecular virology of hepatitis B virus for clinicians.Clin Liver Dis 11:685-706,vii.
3.Cai,D.,C.Mills,W.Yu,R.Yan,C.E.Aldrich,J.R.Saputelli,W.S.Mason,X.Xu,J.T.Guo,T.M.Block,A.Cuconati和H.Guo.2012.Identification of disubstituted sulfonamide compounds as specific inhibitors of hepatitis B virus covalently closed circular DNA formation.Antimicrob Agents Chemother 56:4277-4288.
4.Cai,D.,H.Nie,R.Yan,J.T.Guo,T.M.Block和H.Guo.2013.A southern blot assay for detection of hepatitis B virus covalently closed circular DNA from cell cultures.Methods Mol Biol 1030:151-161.
5.Galibert,F.,E.Mandart,F.Fitoussi和P.Charnay.1979.Nucleotide sequence of the hepatitis B virus genome(subtype ayw)cloned in E.coli.Nature 281:646-650.
6.Gish,R.G.,A.S.Lok,T.T.Chang,R.A.de Man,A.Gadano,J.Sollano,K.H.Han,Y.C.Chao,S.D.Lee,M.Harris,J.Yang,R.Colonno和H.Brett-Smith.2007.Entecavir therapy for up to 96weeks in patients with HBeAg-positive chronic hepatitis B.Gastroenterology133:1437-1444.
7.Guo,H.,D.Jiang,T.Zhou,A.Cuconati,T.M.Block和J.T.Guo.2007.Characterization of the intracellular deproteinized relaxed circular DNA of hepatitis B virus:an intermediate of covalently closed circular DNA formation.J Virol 81:12472-12484.
8.Hirt,B.1967.Selective extraction of polyoma DNA from infected mouse cell cultures.J Mol Biol 26:365-369.
9.Hoofnagle,J.H.,E.Doo,T.J.Liang,R.Fleischer和A.S.Lok.2007.Management of hepatitis B:summary of a clinical research workshop.Hepatology 45:1056-1075.
10.Ito,K.,K.H.Kim,A.S.Lok和S.Tong.2009.Characterization of genotype-specific carboxyl-terminal cleavage sites of hepatitis B virus e antigen precursor and identification of furin as the candidate enzyme.J Virol 83:3507-3517.
11.Ladner,S.K.,M.J.Otto,C.S.Barker,K.Zaifert,G.H.Wang,J.T.Guo,C.Seeger和R.W.King.1997.Inducible expression of human hepatitis B virus(HBV)in stably transfected hepatoblastoma cells:a novel system for screening potential inhibitors of HBV replication.Antimicrob Agents Chemother 41:1715-1720.
12.Liang,T.J.2009.Hepatitis B:the virus and disease.Hepatology 49:S13-21.
13.Liu,N.,L.Ji,M.L.Maguire和D.D.Loeb.2004.cis-Acting sequences that contribute to the synthesis of relaxed-circular DNA of human hepatitis B virus.J Virol 78:642-649.
14.McMahon,B.J.2014.Chronic hepatitis B virus infection.The Medical clinics of North America 98:39-54.
15.Nassal,M.2008.Hepatitis B viruses:reverse transcription a different way.Virus Res 134:235-249.
16.Pawlotsky,J.M.,G.Dusheiko,A.Hatzakis,D.Lau,G.Lau,T.J.Liang,S.Locarnini,P.Martin,D.D.Richman和F.Zoulim.2008.Virologic monitoring of hepatitis B virus therapy in clinical trials and practice:recommendations for a standardized approach.Gastroenterology 134:405-415.
17.Protzer,U.,M.Nassal,P.W.Chiang,M.Kirschfink和H.Schaller.1999.Interferon gene transfer by a hepatitis B virus vector efficiently suppresses wild-type virus infection.Proc Natl Acad Sci U S A96:10818-10823.
18.Quasdorff,M.和U.Protzer.2010.Control of hepatitis B virus at the level of transcription.J Viral Hepat 17:527-536.
19.Seeger,C.和W.S.Mason.2000.Hepatitis B virus biology.Microbiol Mol Biol Rev 64:51-68.
20.Sells,M.A.,M.Chen和G.Acs.1987.Production of hepatitis B virus particles in hepG2cells transfected with cloned hepatitis B virus DNA.Proc.Natl.Acad.Sci.USA 84:1005-1009.
21.Wang,J.,A.S.Lee和J.H.Ou.1991.Proteolytic conversion of hepatitis B virus e antigen precursor to end product occurs in a postendoplasmic reticulum compartment.J Virol 65:5080-5083.
22.Wang,Z.,L.Wu,X.Cheng,S.Liu,B.Li,H.Li,F.Kang,J.Wang,H.Xia,C.Ping,M.Nassal和D.Sun.2013.Replication-competent infectious hepatitis B virus vectors carrying substantially sized transgenes by redesigned viral polymerase translation.PLoS One8:e60306.
23.Zhou,T.,H.Guo,J.T.Guo,A.Cuconati,A.Mehta和T.M.Block.2006.Hepatitis B virus e antigen production is dependent upon covalently closed circular(ccc)DNA in HepAD38cell cultures and may serve as a cccDNA surrogate in antiviral screening assays.Antiviral Res72:116-124.
24.Zoulim,F.和S.Locarnini.2009.Hepatitis B virus resistance to nucleos(t)ide analogues.Gastroenterology 137:1593-1608e1591-1592.
本文中提到的全部參考文獻通過引用的方式完整併入。現在已經充分描述了本發明,本領域技術人員將理解,可以在寬大和等同的條件、參數等範圍內實施本發明而不影響本發明或其任何實施方案的精神或範圍。
根據上文並且還如所附權利要求中所闡述,本發明尤其涉及以下項:
1.一種用於評估候選分子抑制嗜肝DNA病毒共價閉合環狀(ccc)DNA的能力的方法,包括步驟
(a)使包含核酸分子的細胞與所述候選分子接觸,所述核酸分子包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列;
(b)評估加標籤的嗜肝DNA病毒e抗原的水平;並且
(c)當加標籤的嗜肝DNA病毒e抗原的水平與對照相比降低時選擇候選分子。
2.項1的方法,其中所述嗜肝DNA病毒是B型肝炎病毒(HBV))並且其中所述嗜肝DNA病毒e抗原是B型肝炎病毒e抗原(HBeAg)。
3.項1或2的方法,其中所述加標籤的嗜肝DNA病毒e抗原僅含有一個標籤。
4.項3的方法,其中所述標籤由6至22個胺基酸組成。
5.項3或4的方法,其中所述標籤選自血凝素(HA)標籤、His標籤、Flag標籤、c-myc標籤、V5標籤和C9標籤。
6.項5的方法,其中所述Flag標籤是1×Flag標籤或3×Flag標籤。
7.項1或2的方法,其中所述加標籤的嗜肝DNA病毒e抗原含有兩個或更多個標籤。
8.項7的方法,其中所述兩個或更多個標籤是不同的標籤。
9.項7或8的方法,其中所述標籤由6至22個胺基酸組成。
10.根據項7至9中任一項的方法,其中所述兩個或更多個標籤是以下兩者或更多者:血凝素(HA)標籤、His標籤、Flag標籤、c-myc標籤、V5標籤和/或C9標籤。
11.項10的方法,其中所述Flag標籤是1×Flag標籤或3×Flag標籤。
12.項5或10的方法,
其中編碼HA標籤的核酸序列在SEQ ID NO:1中顯示;其中編碼His標籤的核酸序列在SEQ ID NO:2中顯示;其中編碼c-myc標籤的核酸序列在SEQ ID NO:4中顯示;其中編碼V5標籤的核酸序列在SEQ ID NO:5中顯示;和/或其中編碼C9標籤的核酸序列在SEQ ID NO:6中顯示。
13.項6或11的方法,其中編碼1×Flag標籤的核酸序列在SEQ ID NO:3中顯示;或其中編碼3×Flag標籤的核酸序列在SEQ ID NO:7中顯示。
14.項5或10的方法,
其中HA標籤的胺基酸序列在SEQ ID NO:8中顯示;
其中His標籤的胺基酸序列在SEQ ID NO:9中顯示;其中c-myc標籤的胺基酸序列在SEQ ID NO:11中顯示;
其中V5標籤的胺基酸序列在SEQ ID NO:12中顯示;和/或
其中C9標籤的胺基酸序列在SEQ ID NO:13中顯示。
15.項6或11的方法,
其中1×Flag標籤的胺基酸序列在SEQ ID NO:10中顯示;或
其中3×Flag標籤的胺基酸序列在SEQ ID NO:14中顯示。
16.根據項2至15中任一項的方法,其中編碼HBeAg的核酸序列在SEQ ID NO:16中顯示。
17.根據項2至15中任一項的方法,其中HBeAg的胺基酸序列在SEQ ID NO:18中顯示。
18.根據項1至17中任一項的方法,其中核酸分子包含編碼嗜肝DNA病毒前核心蛋白的核酸序列。
19.項18的方法,其中編碼嗜肝DNA病毒前核心蛋白的核酸序列在SEQ ID NO:15中顯示。
20.項18的方法,其中嗜肝DNA病毒前核心蛋白的胺基酸序列在SEQ ID NO:17中顯示。
21.根據項1至17中任一項的方法,其中核酸分子包含編碼一個或多個標籤的核酸序列,其中所述序列在編碼嗜肝DNA病毒前核心蛋白的N端信號肽和接頭的核酸序列的3'下遊。
22.項21的方法,其中所述編碼一個或多個標籤的核酸序列在編碼B型肝炎病毒前核心蛋白N端29個胺基酸的核酸序列的3'下遊。
23.根據項1至22中任一項的方法,其中核酸分子包含嗜肝DNA病毒基因組。
24.項23的方法,其中所述嗜肝DNA病毒基因組是B型肝炎病毒(HBV)基因組。
25.項24的方法,其中所述HBV基因組是HBV基因型A、B、C、D、E、F、G或H的基因組。
26.項24的方法,其中所述HBV基因組是HBV基因型D的基因組。
27.項26的方法,其中所述HBV基因型D的基因組是HBV亞基因型ayw的基因組。
28.根據項中任一項的方法1至27,其中編碼一個或多個標籤的核酸在編碼嗜肝DNA病毒核心蛋白的核酸的5』上遊。
29.項28的方法,其中嗜肝DNA病毒核心蛋白是HBV核心蛋白。
30.項29的方法,其中編碼HBV核心蛋白的核酸在SEQ ID NO:23中顯示。
31.項29的方法,其中HBV核心蛋白的胺基酸序列在SEQ ID NO:24中顯示。
32.根據項1至31中任一項的方法,其中將包含編碼一個或多個標籤的序列的核酸分子插入如嗜肝DNA病毒基因組編碼的ε結構。
33.項32的方法,其中嗜肝DNA病毒基因組是HBV基因組。
34.項33的方法,其中如HBV基因組編碼的ε結構的核酸序列在SEQ ID NO:25中顯示。
35.根據1至34項中任一項的方法,其中將包含編碼一個或多個標籤的序列的核酸分子插入如嗜肝DNA病毒基因組編碼的ε結構的下部莖。
36.項35的方法,其中嗜肝DNA病毒基因組是HBV基因組。
37.根據項1至36中任一項的方法,其中將包含編碼一個或多個標籤的序列的核酸分子插入與HBV基因組的位置C1902和位置A1903相對應的核苷酸之間。
38.根據項1至37中任一項的方法,其中核酸分子在編碼一個或多個標籤的序列的5』包含能夠與如嗜肝DNA病毒基因組編碼的ε結構的下部莖形成鹼基對的序列。
39.項38的方法,其中能夠與如嗜肝DNA病毒基因組編碼的ε結構的下部莖形成鹼基對的序列能夠與對應於HBV基因組位置T1849至A1854的核苷酸形成鹼基對。
40.項38或39的方法,其中能夠與如嗜肝DNA病毒基因組編碼的ε結構的下部莖形成鹼基對的序列由至多9個核苷酸組成。
41.項40的方法,其中能夠與如嗜肝DNA病毒基因組編碼的ε結構的下部莖形成鹼基對的序列由SEQ ID NO:26中所示的序列組成,或其中能夠與如嗜肝DNA病毒基因組編碼的ε結構的下部莖形成鹼基對的序列編碼如SEQ ID NO:40中所顯示的多肽。
42.根據項1至41中任一項的方法,其中核酸分子在編碼一個或多個標籤的序列的3』包含編碼接頭的序列。
43.項42的方法,其中所述接頭由一個或多個胺基酸殘基組成。
44.項42的方法,其中所述接頭僅由一個胺基酸殘基組成。
45.項44的方法,其中所述胺基酸是甘氨酸殘基。
46.根據項42至44中任一項的方法,其中所述編碼接頭的序列由序列GGC組成;或其中所述序列編碼甘氨酸殘基。
47.根據項1至46中任一項的方法,其中包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子包含如SEQ ID NO:41中所示的核酸序列,或
其中包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子包含編碼如SEQ ID NO:42中所示的胺基酸序列的核酸序列。
48.根據項1至47中任一項的方法,其中所述一個或多個標籤符合可讀框地融合入嗜肝DNA病毒e抗原。
49.項48的方法,其中嗜肝DNA病毒e抗原是B型肝炎病毒e抗原(HBeAg)。
50.根據項2至49中任一項的方法,其中編碼加標籤的HBeAg的核酸序列在SEQ ID NO:20中顯示。
51.根據項2至50中任一項的方法,其中加標籤的HBeAg的胺基酸序列在SEQ ID NO:22中顯示。
52.根據項2至51中任一項的方法,其中編碼加標籤的HBV前核心蛋白的核酸序列在SEQ ID NO:19中顯示。
53.根據項2至52中任一項的方法,其中加標籤的HBV前核心蛋白的胺基酸序列在SEQ ID NO:21中顯示。
54.根據項24至53中任一項的方法,其中HBV基因組的核酸序列在SEQ ID NO:27、28、29、30、31、32、33或34的任一項中顯示。
55.根據項中任一項的方法23至54,其中核酸轉錄成前基因組(pg)嗜肝DNA病毒RNA、尤其前基因組(pg)HBV RNA。
56.根據項1至55中任一項的方法,其中所述核酸阻止加標籤的嗜肝DNA病毒e抗原的翻譯。
57.項56的方法,其中所述核酸不含有在編碼加標籤的嗜肝DNA病毒e抗原的核酸5』上遊的起始密碼子ATG。
58.項56或57的方法,其中在編碼加標籤的嗜肝DNA病毒e抗原的核酸5』上遊的起始密碼子ATG已經由核酸TG替換。
59.根據項56至58中任一項的方法,其中所述核酸已經通過點突變被修飾以阻止加標籤的嗜肝DNA病毒e抗原的翻譯。
60.根據項1至59中任一項的方法,其中包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子包含於載體中。
61.項60的方法,其中載體包含如SEQ ID NO:35中所顯示的序列。
62.根據項1至61中任一項的方法,其中包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子在誘導型啟動子的控制下。
63.項56至62中任一項所述的方法,其中嗜肝DNA病毒e抗原是B型肝炎病毒e抗原(HBeAg)。
64.項62或63的方法,其中誘導型啟動子是四環素誘導型啟動子、強力黴素誘導型啟動子、抗生素誘導型啟動子、銅誘導型啟動子、醇誘導型啟動子、類固醇誘導型啟動子或除草劑誘導型啟動子。
65.根據項62至64中任一項的方法,其中誘導型啟動子是CMV啟動子或tet-EF-1α啟動子。
66.根據項23至65中任一項的方法,其中將一個或多個終止密碼子引入一種或多種嗜肝DNA病毒包膜蛋白的編碼區。
67.項66的方法,其中所述一種或多種嗜肝DNA病毒包膜蛋白是一種或多種HBV包膜蛋白。
68.項67的方法,其中一種或多種HBV包膜蛋白是表面大蛋白(L)、表面中等蛋白(M)和表面小蛋白(S)的一者或多者。
69.項67的方法,其中HBV包膜蛋白是表面小蛋白(S)。
70.根據67至69項中任一項的方法,其中一種或多種HBV包膜蛋白的編碼區在SEQ ID NO:36(L)、SEQ ID NO:37(M)和/或SEQ ID NO:38(S)中顯示。
71.項70的方法,其中將SEQ ID NO:38(S)的HBV核苷酸217至222(TTGTTG)突變成TAGTAG以阻止包膜蛋白的表達。
72.根據項1至71中任一項的方法,其中細胞是真核細胞。
73.項72的方法,其中真核細胞是肝細胞來源的。
74.項72或73的方法,其中真核細胞是肝瘤細胞或衍生自肝瘤細胞。
75.根據項72至74中任一項的方法,其中真核細胞是HepG2(ATCC#HB-8065)。
76.根據項1至75中任一項的方法,其中核酸分子或包含前者的載體穩定整合在細胞的基因組中。
77.根據項1至76中任一項的方法,其中所述步驟(a)還包括步驟(aa),所述步驟(aa)包括在以下條件培養包含核酸分子的細胞,所述核酸分子包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列,所述條件允許
(i)合成嗜肝DNA病毒前基因組(pg)RNA;
(ii)逆轉錄所述合成的pgRNA成為負鏈DNA;
(iii)合成第二正鏈DNA,從而所述負鏈DNA和所述正鏈DNA形成雙鏈鬆弛型環狀DNA;
(iv)從所述鬆弛型環狀雙鏈DNA形成cccDNA;
(v)任選地恢復允許翻譯加標籤的嗜肝DNA病毒e抗原的條件;
(vi)轉錄編碼加標籤的嗜肝DNA病毒e抗原的mRNA;
(vii)翻譯加標籤的嗜肝DNA病毒e抗原。
78.項77的方法,其中恢復允許翻譯加標籤的嗜肝DNA病毒e抗原的條件是恢復起始密碼子。
79.根據項1至78中任一項的方法,其中所述方法用於評估候選分子抑制嗜肝DNA病毒ccc DNA形成的能力。
80.項79的方法,其中細胞在cccDNA已經形成之前與候選分子接觸。
81.根據項1至78中任一項的方法,其中所述方法用於評估候選分子減少嗜肝DNA病毒ccc DNA的量或數目的能力。
82.根據項1至78中任一項的方法,其中所述方法用於評估候選分子減少嗜肝DNA病毒ccc DNA轉錄的能力。
83.項81或82的方法,其中細胞在cccDNA已經形成之後與候選分子接觸。
84.根據項1至83中任一項的方法,其中根據步驟(b)評估加標籤的嗜肝DNA病毒e抗原的水平通過ELISA、CLIA或AlphaLISA進行。
85.根據項1至84中任一項的方法,其中根據步驟(b)評估加標籤的嗜肝DNA病毒e抗原的水平包括使用特異性識別所述嗜肝DNA病毒e抗原的抗體和特異性識別一個或多個標籤的一種或多種抗體。
86.根據項77至85中任一項的方法,其中所述嗜肝DNA病毒是B型肝炎病毒(HBV))並且其中所述嗜肝DNA病毒e抗原是B型肝炎病毒e抗原(HBeAg)。
87.核酸分子,包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列。
88.項87的核酸分子,其中所述嗜肝DNA病毒e抗原是B型肝炎病毒e抗原(HBeAg)。
89.項87或88的核酸分子,其中所述加標籤的嗜肝DNA病毒e抗原僅含有一個標籤。
90.項89的核酸分子,其中所述標籤由6至22個胺基酸組成。
91.項89或90的核酸分子,其中所述標籤選自血凝素(HA)標籤、His標籤、Flag標籤、c-myc標籤、V5標籤和C9標籤。
92.項91的核酸分子,其中所述Flag標籤是1×Flag標籤或3×Flag標籤。
93.項87或88的核酸分子,其中所述加標籤的嗜肝DNA病毒e抗原含有兩個或更多個標籤。
94.項93的核酸分子,其中所述兩個或更多個標籤是不同的標籤。
95.項93或94的核酸分子,其中所述兩個或更多個標籤的整個長度是14至31個胺基酸。
96.項93至95中任一項的核酸分子,其中所述兩個或更多個標籤是以下兩者或更多者:血凝素(HA)標籤、His標籤、Flag標籤、c-myc標籤、V5標籤和/或C9標籤。
97.項96的核酸分子,其中所述Flag標籤是1×Flag標籤或3×Flag標籤。
98.項91或96中任一項的核酸分子,
其中編碼HA標籤的核酸序列在SEQ ID NO:1中顯示;其中編碼His標籤的核酸序列在SEQ ID NO:2中顯示;其中編碼c-myc標籤的核酸序列在SEQ ID NO:4中顯示;其中編碼V5標籤的核酸序列在SEQ ID NO:5中顯示;和/或其中編碼C9標籤的核酸序列在SEQ ID NO:6中顯示。
99.項92或97的核酸分子,
其中編碼1×Flag標籤的核酸序列在SEQ ID NO:3中顯示;或
其中編碼3×Flag標籤的核酸序列在SEQ ID NO:7中顯示。
100.項91或96的核酸分子,
其中HA標籤的胺基酸序列在SEQ ID NO:8中顯示;
其中His標籤的胺基酸序列在SEQ ID NO:9中顯示;
其中c-myc標籤的胺基酸序列在SEQ ID NO:11中顯示;
其中V5標籤的胺基酸序列在SEQ ID NO:12中顯示;和/或
其中C9標籤的胺基酸序列在SEQ ID NO:13中顯示。
101.項92或97的核酸分子,
其中1×Flag標籤的胺基酸序列在SEQ ID NO:10中顯示;或
其中3×Flag標籤的胺基酸序列在SEQ ID NO:14中顯示。
102.項88至101中任一項的核酸分子,其中編碼HBeAg的核酸序列在SEQ ID NO:16中顯示。
103.項88至101中任一項的核酸分子,其中HBeAg的胺基酸序列在SEQ ID NO:18中顯示。
104.項87至103中任一項的核酸分子,其中核酸分子包含編碼嗜肝DNA病毒前核心蛋白的核酸序列。
105.項104的核酸分子,其中編碼嗜肝DNA病毒前核心蛋白的核酸序列在SEQ ID NO:15中顯示。
106.項104的核酸分子,其中嗜肝DNA病毒前核心蛋白的胺基酸序列在SEQ ID NO:17中顯示。
107.項87至106中任一項的核酸分子,其中核酸分子包含編碼一個或多個標籤的核酸序列,其中所述序列在編碼嗜肝DNA病毒前核心蛋白的N端信號肽和接頭(「前核心蛋白」區域)的核酸序列的3'下遊。
108.項107的方法,其中所述編碼一個或多個標籤的核酸序列在編碼B型肝炎病毒前核心蛋白N端29個胺基酸的核酸序列的3』下遊。
109.項87至108中任一項的核酸分子,其中核酸分子包含嗜肝DNA病毒基因組。
110.項109的核酸分子,其中所述嗜肝DNA病毒基因組是B型肝炎病毒(HBV)基因組。
111.項110的核酸分子,其中所述HBV基因組是HBV基因型A、B、C、D、E、F、G或H的基因組。
112.項110的核酸分子,其中所述HBV基因組是HBV基因型D的基因組。
113.項112的核酸分子,其中所述HBV基因型D的基因組是HBV亞基因型ayw的基因組。
114.項87至113中任一項的核酸分子,其中編碼一個或多個標籤的核酸在編碼嗜肝DNA病毒核心蛋白的核酸的5』上遊。
115.項114的核酸分子,其中核酸序列編碼HBV核心蛋白。
116.項115的核酸分子,其中編碼HBV核心蛋白的核酸序列在SEQ ID NO:23中顯示。
117.項114的核酸分子,其中核心蛋白是HBV核心蛋白。
118.項116的核酸分子,其中HBV核心蛋白的胺基酸序列在SEQ ID NO:24中顯示。
119.項87至118中任一項的核酸分子,其中將包含編碼一個或多個標籤的序列的核酸分子插入如嗜肝DNA病毒基因組編碼的ε結構。
120.項119的核酸分子,其中所述嗜肝DNA病毒基因組是HBV基因組。
121.項120的核酸分子,其中如HBV基因組編碼的ε結構的核酸序列在SEQ ID NO:25中顯示。
122.項87至121中任一項的核酸分子,其中將包含編碼一個或多個標籤的序列的核酸分子插入如嗜肝DNA病毒基因組編碼的ε結構的下部莖。
123.項122的核酸分子,其中所述嗜肝DNA病毒基因組是HBV基因組。
124.項87至123中任一項的核酸分子,其中將包含編碼一個或多個標籤的序列的核酸分子插入與HBV基因組的位置C1902和A1903相對應的核苷酸之間。
125.項87至124中任一項的核酸分子,其中核酸分子在編碼一個或多個標籤的序列的5』包含能夠與如嗜肝DNA病毒基因組編碼的ε結構的下部莖形成鹼基對的序列。
126.項125的核酸分子,其中能夠與如嗜肝DNA病毒基因組編碼的ε結構的下部莖形成鹼基對的序列能夠與對應於HBV基因組位置T1849至A1854的核苷酸形成鹼基對。
127.項125或126的核酸分子,其中能夠與如嗜肝DNA病毒基因組編碼的ε結構的下部莖形成鹼基對的序列由至多9個核苷酸組成。
128.項127的核酸分子,其中能夠與如嗜肝DNA病毒基因組編碼的ε結構的下部莖形成鹼基對的序列由SEQ ID NO:26中所示的序列組成,或其中能夠與如嗜肝DNA病毒基因組編碼的ε結構的下部莖形成鹼基對的序列編碼如SEQ ID NO:40中所顯示的多肽。
129.項87至128中任一項的核酸分子,其中核酸分子在編碼一個或多個標籤的序列的3』包含編碼接頭的序列。
130.項129的核酸分子,其中所述接頭由一個或多個胺基酸殘基組成。131.項129的核酸分子,其中所述接頭僅由一個胺基酸殘基組成。
132.項131的核酸分子,其中所述胺基酸是甘氨酸殘基。
133.項129至131中任一項的核酸分子,其中所述編碼接頭的序列由序列GGC組成;或其中所述序列編碼甘氨酸殘基。
134.項87至133中任一項的核酸分子,其中包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子包含如SEQ ID NO:41中所示的核酸序列,或
其中包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子包含編碼如SEQ ID NO:42中所示的胺基酸序列的核酸序列。
135.項87至134中任一項的核酸分子,其中所述一個或多個標籤符合可讀框地融合於嗜肝DNA病毒e抗原中。
136.項135的核酸分子,其中所述嗜肝DNA病毒e抗原是B型肝炎病毒e抗原(HBeAg)。
137.項88至136中任一項的核酸分子,其中編碼加標籤的HBeAg的核酸序列在SEQ ID NO:20中顯示。
138.項88至137中任一項的核酸分子,其中加標籤的HBeAg的胺基酸序列在SEQ ID NO:22中顯示。
139.項88至138中任一項的核酸分子,其中編碼加標籤的HBV前核心蛋白的核酸序列在SEQ ID NO:19中顯示。
140.項88至139中任一項的核酸分子,其中加標籤的HBV前核心蛋白的胺基酸序列在SEQ ID NO:21中顯示。
141.項110至140中任一項的核酸分子,其中HBV基因組的核酸序列在SEQ ID NO:27、28、29、30、31、32、33或34的任一項中顯示。
142.項109至141中任一項的核酸分子,其中核酸轉錄成前基因組(pg)嗜肝DNA病毒RNA。
143.項142的核酸分子,其中所述嗜肝DNA病毒RNA是HBV RNA。
144.項87至143中任一項的核酸分子,其中包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子包含於載體中。
145.項144的核酸分子,其中所述嗜肝DNA病毒e抗原是B型肝炎病毒e抗原(HBeAg)。
146.項87至145中任一項的核酸分子,其中所述核酸允許加標籤的嗜肝DNA病毒e抗原的翻譯。
147.項146的核酸分子,其中所述嗜肝DNA病毒e抗原是B型肝炎病毒e抗原(HBeAg)。
148.項147的核酸分子,其中核酸包含於包含如SEQ ID NO:39中所顯示的序列的載體中。
149.項87至148中任一項的核酸分子,其中所述核酸阻止加標籤的嗜肝DNA病毒e抗原的翻譯。
150.項149的核酸分子,其中所述核酸不含有在編碼加標籤的嗜肝DNA病毒e抗原的核酸5』上遊的起始密碼子ATG。
151.項147或150的核酸分子,其中在編碼加標籤的嗜肝DNA病毒e抗原的核酸5』上遊的起始密碼子ATG已經由核酸TG替換。
152.項147至151中任一項的核酸分子,其中所述核酸已經通過點突變被修飾以阻止加標籤的嗜肝DNA病毒e抗原的翻譯。
153.項144、145和149至152中任一項的核酸分子,其中載體包含如SEQ ID NO:35中所顯示的序列。
154.項87至153中任一項的核酸分子,其中包含編碼加標籤的嗜肝DNA病毒e抗原的核酸序列的核酸分子在誘導型啟動子的控制下。
155.項149至154中任一項的核酸分子,其中嗜肝DNA病毒e抗原是B型肝炎病毒e抗原(HBeAg)。
156.項154或155的核酸分子,其中誘導型啟動子是四環素誘導型啟動子、強力黴素誘導型啟動子、抗生素誘導型啟動子、銅誘導型啟動子、醇誘導型啟動子、類固醇誘導型啟動子,或除草劑誘導型啟動子。
157.項154至156中任一項的核酸分子,其中誘導型啟動子是CMV啟動子或tet-EF-1α啟動子。
158.項110至157中任一項的核酸分子,其中將一個或多個終止密碼子引入一種或多種嗜肝DNA病毒包膜蛋白的編碼區。
159.項158的核酸分子,其中所述一種或多種嗜肝DNA病毒包膜蛋白是一種或多種HBV包膜蛋白。
160.項159的核酸分子,其中一種或多種HBV包膜蛋白是以下一者或多者:L、M和/或S。
161.項159的核酸分子,其中HBV包膜蛋白是S。
162.項159至161中任一項的核酸分子,其中一種或多種HBV包膜蛋白的編碼區在SEQ ID NO:36(L)、37(M)或38(S)中顯示。
163.項162的核酸分子,其中將SEQ ID NO:38(S)的HBV核苷酸217至222(TTGTTG)突變成TAGTAG以阻止包膜蛋白的表達。
164.蛋白質,如項87至163中任一項中所限定的核酸分子編碼。
165.蛋白質,包含加標籤的嗜肝DNA病毒e抗原。
166.項165的蛋白質,其中所述嗜肝DNA病毒e抗原是B型肝炎病毒e抗原(HBeAg)。
167.項166的蛋白質,其中B型肝炎病毒e抗原(HBeAg)包含如SEQ ID NO:18中所示的胺基酸序列。
168.項165至167中任一項的蛋白質,其中所述加標籤的嗜肝DNA病毒e抗原僅含有一個標籤。
169.項168的蛋白質,其中所述標籤由6至22個胺基酸組成。
170.項165至169中任一項的蛋白質,其中所述標籤選自血凝素(HA)標籤、His標籤、Flag標籤、c-myc標籤、V5標籤和C9標籤。
171.項170的蛋白質,其中所述Flag標籤是1×Flag標籤或3×Flag標籤。
172.項165至167中任一項的蛋白質,其中所述加標籤的嗜肝DNA病毒e抗原含有兩個或更多個標籤。
173.項172的蛋白質,其中所述兩個或更多個標籤是不同的標籤。
174.項172或173的蛋白質,其中所述兩個或更多個標籤的整個長度是14至31個胺基酸。
175.項172至174中任一項的蛋白質,其中所述兩個或更多個標籤是以下兩者或更多者:血凝素(HA)標籤、His標籤、Flag標籤、c-myc標籤、V5標籤和/或C9標籤。
176.項175的蛋白質,其中所述Flag標籤是1×Flag標籤或3×Flag標籤。
177.項170或175的蛋白質,
其中編碼HA標籤的核酸序列在SEQ ID NO:1中顯示;其中編碼His標籤的核酸序列在SEQ ID NO:2中顯示;其中編碼c-myc標籤的核酸序列在SEQ ID NO:4中顯示;其中編碼V5標籤的核酸序列在SEQ ID NO:5中顯示;和/或其中編碼C9標籤的核酸序列在SEQ ID NO:6中顯示。
178.項171或176的蛋白質,
其中編碼1×Flag標籤的核酸序列在SEQ ID NO:3中顯示;或
其中編碼3×Flag標籤的核酸序列在SEQ ID NO:7中顯示。
179.項170或175的蛋白質,
其中HA標籤的胺基酸序列在SEQ ID NO:8中顯示;
其中His標籤的胺基酸序列在SEQ ID NO:9中顯示;
其中c-myc標籤的胺基酸序列在SEQ ID NO:11中顯示;
其中V5標籤的胺基酸序列在SEQ ID NO:12中顯示;和/或
其中C9標籤的胺基酸序列在SEQ ID NO:13中顯示。
180.項171或176的蛋白質,
其中1×Flag標籤的胺基酸序列在SEQ ID NO:10中顯示;或
其中3×Flag標籤的胺基酸序列在SEQ ID NO:14中顯示。
181.項165至180中任一項的蛋白質,包含嗜肝DNA病毒前核心蛋白。
182.項181的蛋白質,其中編碼嗜肝DNA病毒前核心蛋白的核酸序列在SEQ ID NO:15中顯示。
183.項181的蛋白質,其中嗜肝DNA病毒前核心蛋白的胺基酸序列在SEQ ID NO:17中顯示。
184.項165至183中任一項的蛋白質,其中蛋白質包含一個或多個標籤的胺基酸序列,其中所述序列在嗜肝DNA病毒前核心蛋白的信號肽和接頭的胺基酸序列序列的C末端。
185.項184的蛋白質,其中所述包含一個或多個標籤的胺基酸序的蛋白質在B型肝炎病毒前核心蛋白N端29個胺基酸的胺基酸序列的C末端。
186.項165至183中任一項的蛋白質,其中蛋白質包含一個或多個標籤的胺基酸序列,其中所述序列在嗜肝DNA病毒核心蛋白的胺基酸序列的N末端。
187.項186的蛋白質,其中嗜肝DNA病毒核心蛋白是HBV核心蛋白。
188.項187的蛋白質,其中編碼HBV核心蛋白的核酸在SEQ ID NO:23中顯示。
189.項187的蛋白質,其中HBV核心蛋白的胺基酸序列在SEQ ID NO:24中顯示。
190.項165至189中任一項的蛋白質,其中將一個或多個標籤的胺基酸序列插入如嗜肝DNA病毒基因組編碼的ε結構編碼的胺基酸序列。
191.項190的蛋白質,其中嗜肝DNA病毒基因組是HBV基因組。
192.項191的蛋白質,其中如HBV基因組編碼的ε結構的核酸序列在SEQ ID NO:25中顯示。
193.項165至192中任一項的蛋白質,其中將一個或多個標籤的胺基酸序列插入如嗜肝DNA病毒基因組編碼的ε結構的下部莖編碼的胺基酸序列。
194.項193的蛋白質,其中嗜肝DNA病毒基因組是HBV基因組。
195.項165至194中任一項的蛋白質,其中將一個或多個標籤的胺基酸序列插入與HBV前核心蛋白(如SEQ ID NO:17中所顯示的一種)的位置G29和位置M30相對應的胺基酸殘之間。
196.項165至195中任一項的蛋白質,還在一個或多個標籤的胺基酸序列的N末端包含至多3個胺基酸的胺基酸序列,其中所述至多3個胺基酸的胺基酸序列由能夠與如嗜肝DNA病毒基因組編碼的ε結構的下部莖形成鹼基配對的核酸序列編碼。
197.項196的蛋白質,其中能夠與如嗜肝DNA病毒基因組編碼的ε結構的下部莖形成鹼基對的核酸序列能夠與對應於HBV基因組位置T1849至A1854的核苷酸形成鹼基對。
198.項198的蛋白質,其中能夠與如嗜肝DNA病毒基因組編碼的ε結構的下部莖形成鹼基對的核酸序列由SEQ ID NO:26中所示的序列組成。
199.項196至198中任一項的蛋白質,其中所述至多3個胺基酸的胺基酸序列在SEQ ID NO:40中顯示。
200.項165至199中任一項的蛋白質,還在一個或多個標籤的胺基酸序列的C末端包含接頭。
201.項200的蛋白質,其中所述接頭由一個或多個胺基酸殘基組成。202.項201的蛋白質,其中所述接頭僅由一個胺基酸殘基組成。
203.項202的蛋白質,其中所述胺基酸是甘氨酸殘基。
204.項1至46中任一項的蛋白質,其中加標籤的嗜肝DNA病毒e抗原的胺基酸序列包含如SEQ ID NO:41中所示的核酸序列編碼的胺基酸序列;或
其中加標籤的嗜肝DNA病毒e抗原的胺基酸序列包含如SEQ ID NO:42中所示的胺基酸序列。
205.項165至204中任一項的蛋白質,其中所述一個或多個標籤符合可讀框地融合入嗜肝DNA病毒e抗原。
206.項205的蛋白質,其中嗜肝DNA病毒e抗原是B型肝炎病毒e抗原(HBeAg)。
207.項166至206中任一項的蛋白質,其中編碼加標籤的HBeAg的核酸序列在SEQ ID NO:20中顯示。
208.項166至207中任一項的蛋白質,其中加標籤的HBeAg的胺基酸序列在SEQ ID NO:22中顯示。
209.項166至208中任一項的蛋白質,其中編碼加標籤的HBV前核心蛋白的核酸序列在SEQ ID NO:19中顯示。
210.項166至209中任一項的蛋白質,其中加標籤的HBV前核心蛋白的胺基酸序列在SEQ ID NO:21中顯示。
211.宿主細胞,包含項87至163中任一項的核酸分子或項164至210中任一項的蛋白質。
212.項211的宿主細胞,其中細胞是真核細胞。
213.項212的宿主細胞,其中真核細胞是肝細胞來源的。
214.項212或213的宿主細胞,其中真核細胞是肝瘤細胞或衍生自肝瘤細胞。
215.項212至214中任一項的宿主細胞,其中真核細胞是HepG2(ATCC#HB-8065)。
216.用於產生如項164至210中任一項所限定的蛋白質的方法,所述方法包括在允許蛋白質表達的條件下培養項210至215中任一項的宿主並且從培養物回收產生的蛋白質。
217.試劑盒,用於項1至86中任一項的方法中。
218.試劑盒,包含特異性識別如項165至167中任一項所限定的嗜肝DNA病毒抗原e的抗體和特異性識別如項168至180中任一項所限定的一個或多個標籤的一種或多種抗體。
219.項87至163中任一項的核酸分子、項164至210中任一項的蛋白質和/或項中211至215任一項的宿主細胞的用途,用於篩選疑似能夠抑制嗜肝DNA病毒共價閉合環狀DNA的候選分子。