一種資源調度裝置、系統和方法與流程
2023-05-01 15:35:56 4
本發明涉及計算機技術領域,特別涉及一種資源調度裝置、系統和方法。
背景技術:
計算資源池化,作為一種新型集中式的計算體系,已逐漸應用到複雜計算任務需求中。為了使計算資源能夠均衡高效的工作,計算資源的調度越來越重要。
目前,計算資源的調度方式主要通過網絡實現,即各個計算節點資源與調度中心通過網絡連接,即調度中心通過網絡調度計算節點資源。而網絡在進行數據傳輸過程中,由於網絡帶寬等的影響,常常造成計算資源的調度延遲較高。
技術實現要素:
本發明實施例提供了一種資源調度裝置、系統和方法,能夠有效地降低資源調度的延遲。
第一方面,一種資源調度裝置,包括:數據鏈路交互模塊和資源動態控制模塊,其中,
所述數據鏈路交互模塊分別連接外部的伺服器、外部的至少兩個處理器以及所述資源動態控制模塊;
所述資源動態控制模塊連接所述外部的伺服器,用於監測所述外部的伺服器負載的預分配任務對應的任務量,根據所述負載量生成對應的路由切換指令,並將路由切換指令發送給所述數據鏈路交互模塊;
所述數據鏈路交互模塊,用於接收所述外部的伺服器分配的預分配任務以及所述資源動態控制模塊發送的路由切換指令,並根據所述路由切換指令將所述預分配任務傳輸給至少一個目標處理器。
優選地,所述數據鏈路交互模塊包括:第一FPGA晶片、第二FPGA晶片和×16帶寬PCIE總線,其中,
所述第一FPGA晶片,用於對所述×16帶寬PCIE總線進行一路轉四路;
所述第二FPGA晶片,用於對所述四路轉十六路,並通過所述十六路中的每一路與一個外部的所述處理器相連;
所述資源動態控制模塊連接所述第二FPGA晶片,用於發送所述路由切換指令給所述第二FPGA晶片;
所述第二FPGA晶片,用於根據所述路由切換指令,在所述十六路中選定至少一個任務傳輸鏈路,並通過所述至少一個任務傳輸鏈路將所述任務傳輸給所述至少一個任務傳輸鏈路對應的至少一個目標處理器。
優選地,所述資源動態控制模塊,包括:計算子模塊和指令生成子模塊,其中,
所述計算子模塊,用於確定單個所述外部的處理器的計算容量,並根據所述單個所述外部的處理器的計算容量和監測到的任務量,計算目標處理器的個數;
所述指令生成子模塊,用於獲取所述外部的伺服器提供的處理器使用情況,根據所述處理器使用情況和所述計算子單元計算出的目標處理器的個數,生成對應的路由切換指令。
優選地,所述計算子模塊,進一步用於:
根據下述計算公式,計算目標處理器的個數;
其中,Y表徵目標處理器的個數;M表徵任務量;N表徵單個所述外部的處理器的計算容量。
優選地,
所述資源動態控制模塊,進一步用於監測所述外部的伺服器負載的預分配任務對應的優先級,當所述預分配任務對應的優先級高於當前運行任務時,則發送中止指令給所述數據鏈路交互模塊;
所述數據鏈路交互模塊,進一步用於當接收到所述中止指令時,中止外部的處理器處理所述當前運行任務,並將所述預分配任務傳輸給至少一個目標處理器。
第二方面,一種資源調度系統,包括:上述任一所述的資源調度裝置、伺服器和至少兩個處理器,其中,
所述伺服器,用於接收外部輸入的預分配任務,並通過所述資源調度裝置將所述預分配任務分配給所述至少兩個處理器中的至少一個目標處理器。
優選地,
所述伺服器,進一步用於統計所述至少兩個處理器使用情況,並將所述兩個處理器使用情況發送給所述資源調度裝置;
所述資源調度裝置,根據所述至少兩個處理器使用情況,生成對應的路由切換指令,並通過所述路由切換指令將所述預分配任務分配給所述至少兩個處理器中的至少一個目標處理器。
優選地,
所述伺服器,進一步用於對所述預分配任務進行優先級標記;
所述資源調度裝置,用於獲取所述伺服器標記的所述預分配任務的優先級,根據標記的所述預分配任務的優先級,當所述預分配任務的優先級大於當前處理器處理的當前運行任務時,則中斷所述當前處理器對所述當前運行任務的處理,並將所述預分配任務分配給所述當前處理器。
第三方面,一種資源調度方法,包括:
通過資源動態控制模塊監測外部的伺服器負載的預分配任務對應的任務量;
根據所述負載量,生成對應的路由切換指令,並將路由切換指令發送給數據鏈路交互模塊;
所述數據鏈路交互模塊根據所述路由切換指令將所述預分配任務傳輸給至少一個目標處理器。
優選地,上述方法進一步包括:通過資源動態控制模塊確定單個處理器的計算容量;
在所述監測外部的伺服器負載的預分配任務對應的任務量之後,在所述生成對應的路由切換指令之前,進一步包括:
根據所述單個所述外部的處理器的計算容量和監測到的任務量,計算目標處理器的個數,並獲取所述外部的伺服器提供的處理器使用情況;
所述生成對應的路由切換指令,包括:根據所述處理器使用情況和計算出的目標處理器的個數,生成對應的路由切換指令。
優選地,所述計算目標處理器的個數,包括:
根據下述計算公式,計算目標處理器的個數;
其中,Y表徵目標處理器的個數;M表徵任務量;N表徵單個所述外部的處理器的計算容量。
本發明實施例提供了一種資源調度裝置、系統和方法,通過數據鏈路交互模塊分別連接外部的伺服器、外部的至少兩個處理器以及所述資源動態控制模塊;資源動態控制模塊連接所述外部的伺服器,通過監測所述外部的伺服器負載的預分配任務對應的任務量,根據所述負載量生成對應的路由切換指令,並將路由切換指令發送給所述數據鏈路交互模塊;通過數據鏈路交互模塊接收所述外部的伺服器分配的預分配任務以及所述資源動態控制模塊發送的路由切換指令,並根據所述路由切換指令將所述預分配任務傳輸給至少一個目標處理器,任務分配給處理器的過程通過數據鏈路交互模塊,而數據鏈路交互模塊連通伺服器與處理器,實現伺服器與處理器間任務以及任務計算結果的交互,而無須網絡的進行數據分享,能夠有效地降低資源調度的延遲。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖是本發明的一些實施例,對於本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1是本發明一個實施例提供的一種資源調度裝置的結構示意圖;
圖2是本發明另一個實施例提供的一種資源調度裝置的結構示意圖;
圖3是本發明又一個實施例提供的一種資源調度裝置的結構示意圖;
圖4是本發明一個實施例提供的一種資源調度系統的結構示意圖;
圖5是本發明一個實施例提供的一種資源調度方法的流程圖;
圖6是本發明另一個實施例提供的一種資源調度系統的結構示意圖;
圖7是本發明另一個實施例提供的一種資源調度方法的流程圖。
具體實施方式
為使本發明實施例的目的、技術方案和優點更加清楚,下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例是本發明一部分實施例,而不是全部的實施例,基於本發明中的實施例,本領域普通技術人員在沒有做出創造性勞動的前提下所獲得的所有其他實施例,都屬於本發明保護的範圍。
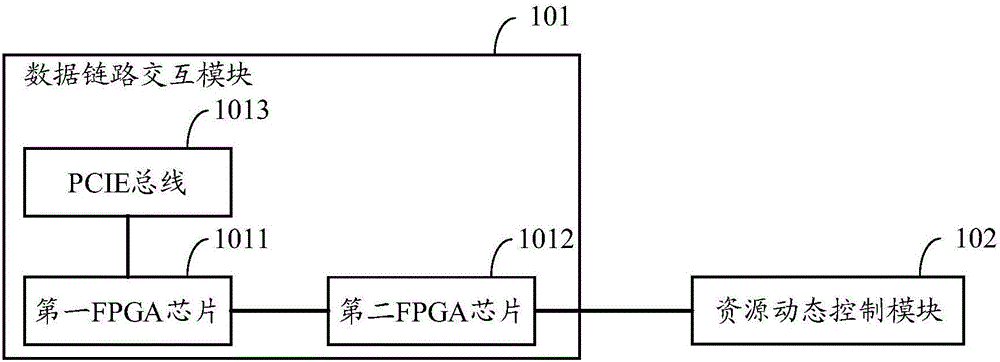
如圖1所示,本發明實施例提供一種資源調度裝置,該資源調度裝置可包括:數據鏈路交互模塊101和資源動態控制模塊102,其中,
所述數據鏈路交互模塊101分別連接外部的伺服器、外部的至少兩個處理器以及所述資源動態控制模塊102;
所述資源動態控制模塊102連接所述外部的伺服器,用於監測所述外部的伺服器負載的預分配任務對應的任務量,根據所述負載量生成對應的路由切換指令,並將路由切換指令發送給所述數據鏈路交互模塊101;
所述數據鏈路交互模塊101,用於接收所述外部的伺服器分配的預分配任務以及所述資源動態控制模塊102發送的路由切換指令,並根據所述路由切換指令將所述預分配任務傳輸給至少一個目標處理器。
在圖1所示的實施例中,通過資源動態控制模塊連接所述外部的伺服器,通過監測所述外部的伺服器負載的預分配任務對應的任務量,根據所述負載量生成對應的路由切換指令,並將路由切換指令發送給所述數據鏈路交互模塊;通過數據鏈路交互模塊接收所述外部的伺服器分配的預分配任務以及所述資源動態控制模塊發送的路由切換指令,並根據所述路由切換指令將所述預分配任務傳輸給至少一個目標處理器,任務分配給處理器的過程通過數據鏈路交互模塊,而數據鏈路交互模塊連通伺服器與處理器,實現伺服器與處理器間任務以及任務計算結果的交互,而無須網絡的進行數據分享,能夠有效地降低資源調度的延遲。
在本發明另一實施例中,如圖2所示,所述數據鏈路交互模塊101包括:第一FPGA晶片1011、第二FPGA晶片1012和×16帶寬PCIE總線1013,其中,
所述第一FPGA晶片1011,用於對所述×16帶寬PCIE總線1013進行一路轉四路;
所述第二FPGA晶片1012,用於對所述四路轉十六路,並通過所述十六路中的每一路與一個外部的所述處理器相連;
所述資源動態控制模塊102連接所述第二FPGA晶片1012,用於發送所述路由切換指令給所述第二FPGA晶片1012;
所述第二FPGA晶片1012,用於根據所述路由切換指令,在所述十六路中選定至少一個任務傳輸鏈路,並通過所述至少一個任務傳輸鏈路將所述任務傳輸給所述至少一個任務傳輸鏈路對應的至少一個目標處理器。
上述FPGA晶片上具有多個埠,可以通過埠可以實現與處理器、其他FPGA晶片、傳輸總線以及資源動態控制模塊等,並為每個埠分配對應的功能,從而實現數據交互。
例如:X16帶寬的PCIE總線A一端連接外設的伺服器,另一端連接第一FPGA晶片,則PCIE總線A經過第一FPGA晶片實現PCIE總線數據的1路轉4路交換,即埠A1,A2,A3,A4。埠A1,A2,A3,A4分別經過第二FPGA晶片實現PCIE總線數據的4路轉16路交換,即形成數據下行鏈路接口A11,A12,A13,A14,A21,A22,A23,A24,A31,A32,A33,A34,A41,A42,A43,A44,從而實現1路轉16路的X16帶寬PCIE總線的交換傳輸。
如圖3所示,在本發明又一實施例中,所述資源動態控制模塊102,包括:計算子模塊1021和指令生成子模塊1022,其中,
所述計算子模塊1021,用於確定單個所述外部的處理器的計算容量,並根據所述單個所述外部的處理器的計算容量和監測到的任務量,計算目標處理器的個數;
所述指令生成子模塊1022,用於獲取所述外部的伺服器提供的處理器使用情況,根據所述處理器使用情況和所述計算子單元1021計算出的目標處理器的個數,生成對應的路由切換指令。
在本發明另一實施例中,所述計算子模塊,進一步用於:
根據下述計算公式,計算目標處理器的個數;
其中,Y表徵目標處理器的個數;M表徵任務量;N表徵單個所述外部的處理器的計算容量。
在本發明又一實施例中,所述資源動態控制模塊102,進一步用於監測所述外部的伺服器負載的預分配任務對應的優先級,當所述預分配任務對應的優先級高於當前運行任務時,則發送中止指令給所述數據鏈路交互模塊101;
所述數據鏈路交互模塊101,進一步用於當接收到所述中止指令時,中止外部的處理器處理所述當前運行任務,並將所述預分配任務傳輸給至少一個目標處理器。
在本發明另一實施例中,所述資源動態控制模塊102包括:ARM晶片。
如圖4所示,本發明實施例提供一種資源調度系統,包括:上述任一所述的資源調度裝置401、伺服器402和至少兩個處理器403,其中,
所述伺服器402,用於接收外部輸入的預分配任務,並通過所述資源調度裝置401將所述預分配任務分配給所述至少兩個處理器403中的至少一個目標處理器。
在本發明另一實施例中,所述伺服器402,進一步用於統計所述至少兩個處理器使用情況,並將所述兩個處理器使用情況發送給所述資源調度裝置401;
所述資源調度裝置401,根據所述至少兩個處理器使用情況,生成對應的路由切換指令,並通過所述路由切換指令將所述預分配任務分配給所述至少兩個處理器403中的至少一個目標處理器。
在本發明又一實施例中,所述伺服器402,進一步用於對所述預分配任務進行優先級標記;
所述資源調度裝置401,用於獲取所述伺服器402標記的所述預分配任務的優先級,根據標記的所述預分配任務的優先級,當所述預分配任務的優先級大於當前處理器處理的當前運行任務時,則中斷所述當前處理器對所述當前運行任務的處理,並將所述預分配任務分配給所述當前處理器。
如圖5所示,本發明實施例提供一種資源調度方法,該方法可以包括如下步驟:
步驟501:通過資源動態控制模塊監測外部的伺服器負載的預分配任務對應的任務量;
步驟502:根據所述負載量,生成對應的路由切換指令,並將路由切換指令發送給數據鏈路交互模塊;
步驟503:數據鏈路交互模塊根據所述路由切換指令將所述預分配任務傳輸給至少一個目標處理器。
在本發明一個實施例中,為了保證任務的處理效率,上述方法進一步包括:通過資源動態控制模塊確定單個處理器的計算容量;並在步驟501之後,在步驟502之前,進一步包括:根據所述單個所述外部的處理器的計算容量和監測到的任務量,計算目標處理器的個數,並獲取所述外部的伺服器提供的處理器使用情況;步驟502的具體實施方式,包括:根據所述處理器使用情況和計算出的目標處理器的個數,生成對應的路由切換指令。
在本發明一個實施例中,所述計算目標處理器的個數,包括:根據下述計算公式,計算目標處理器的個數;
其中,Y表徵目標處理器的個數;M表徵任務量;N表徵單個所述外部的處理器的計算容量。
在本發明一個實施例中,為了能夠實現對優先級較高的任務優先進行處理,上述方法進一步包括:通過資源動態控制模塊監測外部的伺服器負載的預分配任務對應的優先級,當所述預分配任務對應的優先級高於當前運行任務時,則發送中止指令給所述數據鏈路交互模塊;當數據鏈路交互模塊接收到所述中止指令時,中止外部的處理器處理所述當前運行任務,並將所述預分配任務傳輸給至少一個目標處理器。
下面以圖6所示的資源調度系統對任務A進行處理為例,進一步說明資源調度方法,如圖7所示,該資源調度方法可以包括如下步驟:
步驟701:伺服器接收到任務A的處理請求,並通過任務調度裝置中的數據鏈路交互模塊獲取各個處理器的使用情況;
如圖6所示,伺服器602通過任務調度裝置中的×16PCIE總線60113連接到第一FPGA晶片60111,第一FPGA晶片60111通過四個埠A1,A2,A3及A4連接到第二FPGA晶片60112上,通過第二FPGA晶片60112上的16個埠A11,A12,A13,A14,A21,A22,A23,A24,A31,A32,A33,A34,A41,A42,A43,A44分別連接一個處理器(GPU),即為伺服器掛載16個處理器(GPU)。上述×16PCIE總線60113、第一FPGA晶片60111以及第二FPGA晶片60112組合成為任務調度裝置601中的數據鏈路交互模塊6011。
由於伺服器602通過任務調度裝置601中的數據鏈路交互模塊6011與16個GPU連接,則在該步驟中,伺服器602通過數據鏈路交互模塊6011獲取各個處理器(GPU)的使用情況,該使用情況可包括:處於待機狀態或者處於工作狀態,以及處於工作狀態時,處理器處理的任務等。
步驟702:伺服器標記任務A的優先級;
在該步驟中,伺服器可以針對任務的類型等對任務的優先級進行標記,例如:任務A為某一正在處理任務B的前序任務,則任務A的優先級應該高於任務B的優先級。
步驟703:任務調度裝置中的資源動態控制模塊確定單個處理器的計算容量;
在圖6所示的任務調度系統中,每一個處理器(GPU)的計算容量相同,例如:計算容量為伺服器CPU的20%等。
步驟704:任務調度裝置中的資源動態控制模塊監測伺服器接收到的任務A的任務量及任務A的優先級;
如圖6所示,任務調度裝置601中的資源動態控制模塊6012與伺服器602相連,監測伺服器602接收到任務A的任務量和任務A的優先級,該資源動態控制模塊6012可以為ARM晶片。
步驟705:資源動態控制模塊根據單個處理器的計算容量和監測到的任務量,計算所需目標處理器的個數;
該步驟的計算結果,可以通過下述計算公式(1),計算得到:
其中,Y表徵目標處理器的個數;M表徵任務量;N表徵單個所述外部的處理器的計算容量。
另外,每一個目標處理器的處理量可以通過下述計算公式(2),計算得到:
其中,W表徵每個目標處理器的處理量,M表徵任務量;Y表徵目標處理器的個數。
通過計算公式(2)計算目標處理器的處理量,可以實現任務量均衡分擔,從而保證任務的處理效率。
另外,還可以按照單個處理器的計算容量為每一個目標處理器分配任務。
步驟706:根據計算出的所需目標處理器的個數,生成對應的路由切換指令;
該步驟生成的路由切換指令主要是控制圖6所示的數據鏈路交互模塊6011的連通線路,例如:將任務A分配給A11,A12以及A44埠連接的處理器時,則該步驟生成的路由切換指令使A11,A12以及A44埠所在的線路聯通,以方便伺服器與處理器間進行數據傳輸。
步驟707:根據各個處理器的使用情況,確定處於待機狀態的處理器個數;
步驟708:判斷處於待機狀態的處理器個數是否不小於所需目標處理器的個數,如果是,則執行步驟709;否則,執行步驟710;
該步驟主要是後續是否暫停其他處理器的基礎,當處於待機狀態的處理器個數不小於所需目標處理器的個數時,現有的處於待機狀態的處理器即可完成任務A的計算,則無需暫停其他處理器,當處於待機狀態的處理器個數小於所需目標處理器的個數時,現有的處於待機狀態的處理器不足以完成任務A的計算,則需要進一步根據任務A的優先級判斷是否需要為任務A暫停其他處理器。
步驟709:根據路由切換指令,在處於待機狀態的處理器中選定至少一個目標處理器,並將任務A傳輸給至少一個目標處理器,結束當前流程;
如圖6所示,A11,A12,A33及A44埠對應的處理器處於待機狀態,而任務A僅需要3個處理器即可完成,則資源動態控制模塊6012可隨機將任務A分配給A11,A12及A44埠對應的處理器,即資源動態控制模塊6012生成對應的路由切換指令,該步驟根據路由切換指令,將任務A分配給A11,A12及A44埠對應的處理器。
步驟710:當任務A的優先級高於處理器正在處理的其他任務的優先級時,中止部分處理器處理其他任務;
例如:任務A需要5個目標處理器進行處理,而當前僅有4個處理器處於待機狀態,而處理器中正在處理的任務B的優先級低於任務A的優先級,則需要將任意一個運行有任務B的處理器中止,以滿足任務A所需要的5個目標處理器。
步驟711:將任務A分配給處於待機狀態的處理器和中止的部分處理器。
根據上述方案,本發明的各實施例,至少具有如下有益效果:
1.通過數據鏈路交互模塊分別連接外部的伺服器、外部的至少兩個處理器以及所述資源動態控制模塊;資源動態控制模塊連接所述外部的伺服器,通過監測所述外部的伺服器負載的預分配任務對應的任務量,根據所述負載量生成對應的路由切換指令,並將路由切換指令發送給所述數據鏈路交互模塊;通過數據鏈路交互模塊接收所述外部的伺服器分配的預分配任務以及所述資源動態控制模塊發送的路由切換指令,並根據所述路由切換指令將所述預分配任務傳輸給至少一個目標處理器,任務分配給處理器的過程通過數據鏈路交互模塊,而數據鏈路交互模塊連通伺服器與處理器,實現伺服器與處理器間任務以及任務計算結果的交互,而無須網絡的進行數據分享,能夠有效地降低資源調度的延遲。
2.由於數據間通過PCIE總線進行傳輸,與現有的網絡傳輸,能夠有效地提高數據傳輸的及時性和穩定性。
3.通過確定單個所述外部的處理器的計算容量,並根據所述單個所述外部的處理器的計算容量和監測到的任務量,計算目標處理器的個數,並根據獲取的外部的伺服器提供的處理器使用情況和計算出的目標處理器的個數,生成對應的路由切換指令,保證目標處理器的個數能夠滿足任務的處理,從而保證處理任務的高效性。
4.通過監測伺服器負載的預分配任務對應的優先級,當所述預分配任務對應的優先級高於當前運行任務時,通過中止指令中止外部的處理器處理當前運行任務,並將預分配任務傳輸給至少一個目標處理器,實現了按照優先級處理任務,進一步保證了計算性能。
需要說明的是,在本文中,諸如第一和第二之類的關係術語僅僅用來將一個實體或者操作與另一個實體或操作區分開來,而不一定要求或者暗示這些實體或操作之間存在任何這種實際的關係或者順序。而且,術語「包括」、「包含」或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者設備所固有的要素。在沒有更多限制的情況下,由語句「包括一個〃·····」限定的要素,並不排除在包括所述要素的過程、方法、物品或者設備中還存在另外的相同因素。
本領域普通技術人員可以理解:實現上述方法實施例的全部或部分步驟可以通過程序指令相關的硬體來完成,前述的程序可以存儲在計算機可讀取的存儲介質中,該程序在執行時,執行包括上述方法實施例的步驟;而前述的存儲介質包括:ROM、RAM、磁碟或者光碟等各種可以存儲程序代碼的介質中。
最後需要說明的是:以上所述僅為本發明的較佳實施例,僅用於說明本發明的技術方案,並非用於限定本發明的保護範圍。凡在本發明的精神和原則之內所做的任何修改、等同替換、改進等,均包含在本發明的保護範圍內。