圖像編碼和解碼的方法、編碼和解碼設備以及電腦程式與流程
2023-04-22 18:51:11 2
本申請是申請號為201280031335.9,申請日為2012年6月20日,題為「用於對圖像編碼和解碼的方法、編碼和解碼設備以及相應的電腦程式」的中國發明專利申請的分案申請。
本發明一般屬於圖像處理的領域,且更準確地屬於數字圖像和數字圖像序列的編碼和解碼。
本發明由此可特別應用於在目前的數字視頻編碼器(mpeg,h.264等)或未來的視頻編碼器(itu-t/vceg(h.265)或iso/mpeg(hvc))中實現的視頻編碼。
背景技術:
目前的視頻編碼器(mpeg、h264等)使用視頻序列的逐塊表示。圖像被分為宏塊,每個宏塊本身可以被分為塊,並且每個塊或宏塊通過圖像內或圖像間預測來編碼。於是,特定的圖像通過空間預測(內預測)來編碼,而其他圖像在相對於一個或多個被編碼-解碼的參考圖像的時間預測(間預測)、在本領域技術人員已知的運動補償的幫助下進行編碼。此外,針對每個塊,可以對與原始塊減去預測相對應的殘留塊進行編碼。該塊的係數可以在變換之後被量化,然後被熵編碼器編碼。
內預測和間預測需要之前已經被編碼和解碼的特定塊可用,從而在解碼器上或在編碼器上被用於預測當前塊。圖1示出了這樣的預測編碼的示例性例子,其中,圖像in被分為塊,該圖像的當前塊mbi正在關於預訂數量的之前被編碼和解碼的塊mbr1、mbr2和mbr3進行預測編碼,例如如陰影箭頭所示。上述三個塊特別包含緊接當前塊mbi左側的塊mbr1,以及分別僅緊接當前塊mbi上方和右上方的兩個塊mbr2和mbr3。
熵編碼器在這裡更為感興趣。熵編碼器以其到達的順序來編碼信息。典型地實現「光柵掃描」類型的塊的逐行遍歷,如圖1所示通過引用prs,從圖像左上角的塊開始。對於每個塊,用來表示塊所必須的各個信息項(塊的類型、預測模式、殘留係數等)被順序分發到熵編碼器。
已知在avc壓縮標準(也被稱為iso-mpeg4第10部分和itu-th.264)中引入的被稱為「cabac」(上下文適應二進位算術編碼器)的足夠複雜的有效的算術編碼器。
熵編碼器實現各個概念:
-算術編碼:編碼器例如初始在文檔j.rissanenandg.g.langdonjr,「universalmodelingandcoding,」ieeetrans.inform.theory,vol.it-27,pp.12-23,jan.1981中描述的編碼器使用符號出現概率來對該符號進行編碼;
-上下文適應:在這裡,這包括適應要編碼的符號的出現概率。一方面,快速實現學習。另一方面,依賴於之前被編碼的信息的狀態,特定的上下文被用於編碼。對於每個上下文,存在固有的符號出現概率與之對應。例如,上下文對應於根據給定配置來編碼的符號的類型(殘留係數的表示、編碼模式的信號等),或者鄰居的狀態(例如在鄰居中選擇的「內」模式的數量等)。
-二進位化:實現要編碼的符號的比特序列的成形。隨後,這些各個比特被相繼分發到二進位熵編碼器。
於是,針對使用的每個上下文,該熵編碼器實現一種系統,針對所考慮的上下文來快速學習關於之前被編碼的符號的概率。該學習基於對這些符號進行編碼的順序。典型地,根據如上所述的「光柵掃描」類型的順序來遍歷圖像。
在可以是0或1的給定符號b的編碼期間,通過下列方式來更新當前塊mbi的該符號的出現概率pi的學習:
其中,α是預定值例如0.95,pi-1是在該符號最後出現時計算的符號出現概率。
圖1示出了這樣的熵編碼的示例性例子,其中,圖像in的當前塊mbi被熵編碼。在塊mbi的熵編碼開始時,所使用的符號出現概率是之前被編碼和解碼的塊的編碼之後獲得的概率,根據上述「光柵掃描」類型的塊的逐行遍歷,該塊正好在當前塊mbi的前面。僅為了圖的清楚,在圖1中通過細箭頭針對特定的塊來表示這樣的基於塊和塊的依賴性的學習。
該類型的熵編碼的缺點在於,考慮到塊的「光柵掃描」遍歷,在對位於一行開始的符號進行編碼時,使用的概率主要對應於在前一行結束位置的符號所看到的那些概率。現在,考慮到符號概率的可能的空間變化(例如,對於和運動信息項相關的符號,位於圖像右側部分的運動可以和在左側部分看到的不同,並且因此對於隨後的局部概率來說也是類似的),可以看到概率的局部一致性的缺失,由此可能增加編碼期間的效率損失。
為了限制該現象,已經提出了對塊的遍歷順序的調整,目標是確保更好的局部一致性,但編碼和解碼仍保持順序。
該類型的熵編碼器還有另一個缺點。確實,符號的編碼和解碼依賴於就此學習的概率,符號的解碼可以僅以與在編碼期間使用的順序相同的順序來實現。典型地,於是解碼可以只是順序的,由此阻止若干個符號的並行解碼(例如從多核架構中受益)。
文檔thomaswiegand,garyj.sullivan,gislebjontegaard,andajayluthra,″overviewoftheh.264/avcvideocodingstandard″,ieeetransactionsoncircuitsandsystemsforvideotechnology,vol.13,no.7,pp.560-576,july2003還指出,cabac熵編碼器具有將非整數數量的比特分配給要編碼的當前字母表的每個符號的特殊特徵,這對於大於0.5的符號出現概率是有利的。特別地,cabac編碼器等待直到它已經讀取了若干個符號,然後將預定數量的比特分配給讀取的該符號集,編碼器將該比特寫到要發送到解碼器的壓縮流中。這樣的規定由此使其可能使若干個符號上的比特「交互作用」,並對分數數量的比特上的符號進行編碼,該數量反映了與通過符號實際發送的信息更接近的信息。與讀取的符號關聯的其他比特未在壓縮流中發送,而是保持等候,等待被分配給cabac編碼器讀取的一個或多個新的符號,使其可能再次使這些其他比特交互作用。通過已知的方式,熵編碼器在給定的時刻「清空」這些未發送的比特。除非另外說明,在所述給定的時刻,編碼器提取還未被發送的比特,並將它們寫入到去往解碼器的壓縮流中。該清空例如在已經讀取要編碼的最後一個符號的時刻進行,以確保壓縮流確實包含所有比特,該比特將允許解碼器對字母表中的所有符號進行解碼。通過更一般的方式,作為專用於給定編碼器/解碼器的性能和功能的函數來確定進行清空的時刻。
在2011年4月15號的網際網路地址http://research.microsoft.com/en-us/um/people/jinl/paper_2002/msri_jpeg.htm上可用的文檔描述了一種對符合jpeg2000壓縮標準的靜態圖像進行編碼的方法。該靜態圖像經過離散小波變換,然後被量化,由此使其可能獲得量化的小波係數,量化索引分別與之關聯。在熵編碼器的幫助下對獲取的量化索引進行編碼。量化係數之前被分組為稱為代碼塊的矩形塊,大小典型為64x64或32x32。每個代碼塊然後被熵編碼獨立編碼。於是,在對當前的代碼塊進行編碼時,熵編碼器不會使用在之前的代碼塊的編碼期間計算的符號出現概率。熵編碼器由此在每次開始代碼塊的編碼時處於初始化狀態。該方法展示了對代碼塊的數據進行解碼而不用對相鄰的代碼塊進行解碼的好處。於是,例如,一個客戶端軟體可以請求一個伺服器軟體提供僅客戶需要的壓縮代碼塊來對圖像中識別的子部分進行解碼。該方法還展示了允許代碼塊的並行編碼和/或解碼的優勢。於是,代碼塊的大小越小,並行化級別就越高。例如,對於固定為2的並行化級別,兩個代碼塊將被並行編碼和/或解碼。理論上,並行化級別的值等於圖像中要編碼的代碼塊的數量。但是,考慮到該編碼沒有利用從當前代碼塊的中間環境出現的概率,該方法獲得的壓縮性能不是最優的。
技術實現要素:
本發明的一個目標是修復上述現有技術的缺陷。
為此,本發明的主題涉及一種對至少一個圖像進行編碼的方法,包括下列步驟:
-將圖像分割為可以包含屬於預定符號集的符號的多個塊,
-將所述塊分組為預定數量的塊子集,
-通過熵編碼模塊、通過將數字信息與所考慮的子集中的每個塊的符號進行關聯來對所述塊子集中的每個進行編碼,該編碼步驟包括針對圖像的第一塊來初始化熵編碼模塊的狀態變量的子步驟,
-生成表示被編碼的塊子集中的至少一個的至少一個數據子流,
根據本發明的方法值得注意,在於:
-在當前塊是所考慮的子集中要被編碼的第一塊的情形下,確定該第一當前塊的符號出現概率,該概率是針對至少一個其他子集的編碼和解碼的預定塊而已經確定的那些概率,
-在當前塊是所考慮的子集中最後編碼的塊的情形下:
●將在所考慮的所述子集中的塊的編碼期間與所述符號關聯的所有數字信息寫入到子流中,該子流表示所考慮的子集,
●實現初始化子步驟。
上述寫入步驟相當於,一旦塊子集中的最後一塊已被編碼,清空還未被發送的數字信息(比特),如上描述所解釋。
上述寫入步驟和重新初始化熵編碼模塊的步驟的耦合使其可能產生包含各個數據子流的被編碼的數據流,該數據子流分別對應於該至少一個被編碼的塊子集,所述流適合根據各種並行化級別來編碼,並且這與應用於塊子集的編碼類型不管是順序還是並行無關。於是,在編碼時可以在並行級別的選擇上有很大的自由度,該並行級別作為期望的編碼/解碼性能的函數。解碼的並行級別可變,且甚至可以與編碼的並行級別不同,因為在開始塊子集的解碼時,解碼器總是處於初始化狀態。
根據第一例子,熵編碼模塊的狀態變量是表示預定符號集的符號中的符號出現概率的區間的兩個邊界。
根據第二例子,熵編碼模塊的狀態變量是本領域技術人員熟知並且在2011年6月21日在下列網際網路地址http://en.wikipedia.org/wiki/lempel%e2%80%93ziv%e2%80%93welch中描述的lzw(lempel-ziv-welch)熵編碼器的轉換表中包含的符號的串。
使用在所考慮的塊子集的第一當前塊的熵編碼期間使用針對所述其他子集的第一塊來確定的符號出現概率的主要好處是,通過在後者中僅存儲所述符號出現概率的更新而不用考慮通過所述其他子集中的其他連續塊來學習的符號出現概率,來節省編碼器的緩衝存儲器。
在所考慮的塊子集中的第一當前塊的熵編碼期間使用針對所述子集中除了第一塊以外的塊例如第二塊來確定的符號出現概率的好處是獲得更準確且由此更好地學習符號出現概率,由此提升更好的視頻壓縮性能。
在特定的實施例中,塊子集被順序或者並行編碼。
子集塊被順序編碼的事實所具有的好處是展示符合h.264/mpeg-4avc標準的根據本發明的編碼方法。
子集塊被並行編碼的事實所具有的好處是加速編碼器處理時間且受益於圖像編碼的多平臺架構。
在另一特定實施例中,當至少兩個塊子集與至少一個其他的塊子集並行編碼時,該至少兩個被編碼的塊子集被包含在相同的數據子流中。
該規定使其特別可能節省數據子流的信令。確實,為了使解碼單元能夠儘可能早地對子流進行解碼,需要在壓縮文件中指示所考慮的子流在何處開始。當若干個塊子集被包含在相同的數據子流中時,需要單個指示符,由此降低壓縮文件的大小。
在又一特定實施例中,當所述被編碼的塊子集想要以預定的順序來並行編碼時,在對該塊子集中的每個分別編碼之後給出的數據子流在為了解碼而被發送之前根據該預定順序來預先排序。
該規定使其可能使被編碼的數據子流適應特定類型的解碼,而不需要對圖像進行解碼然後再次編碼。
相關地,本發明還涉及一種對至少一個圖像進行編碼的設備,包括:
-將圖像分割為多個塊的裝置,該多個塊可以包含屬於預定符號集的符號,
-用於將所述塊分組為預定數量的塊子集的裝置,
-對該塊子集中的每個進行編碼的裝置,該編碼裝置包括熵編碼模塊,能夠將數字信息與所考慮的子集中的每個塊的符號相關聯,該編碼裝置包含針對圖像中的第一塊來初始化熵編碼模塊的狀態變量的子裝置,
-用於生成數據的至少一個數據子流的裝置,該數據子流表示被編碼的塊子集中的至少一個。
該編碼裝置值得注意,在於它包括:
-用於確定當前塊的符號出現概率的裝置,在當前塊是所考慮的子集中要被編碼的第一塊的情形下,該裝置確定第一塊的符號出現概率為針對至少一個其他子集的編碼和解碼的預定塊所已經確定的那些概率,
-寫入裝置,在當前塊是所考慮的子集中最後編碼的塊的情形下,其被激活以將在所考慮的子集中的塊的編碼期間已經與所述符號關聯的所有數字信息寫入到子流中,該子流至少表示所考慮的子集,
初始化子裝置還被激活以重新初始化熵編碼模塊的狀態變量。
通過相應的方式,本發明還涉及一種用於對表示至少一個被編碼的圖像的流進行解碼的方法,包括下列步驟:
-在所述流中識別與要解碼的至少一個塊子集分別對應的預定數量的數據子流,所述塊能夠包含屬於預定符號集的符號,
-通過熵解碼模塊,通過在至少一個被識別的子流中讀取與對應於該至少一個所述被識別的子流的子集中的每個塊的符號相關聯的數字信息,來對所述被識別的塊子集進行解碼,該解碼步驟包括針對圖像中要被解碼的第一塊來初始化所述熵解碼模塊的狀態變量的子步驟,
該解碼方法值得注意,在於:
-在當前塊是所考慮的子集中要被解碼的第一塊的情形下,確定所考慮的子集中的第一塊的符號出現概率,該概率是針對至少一個其他子集的被解碼的預定塊而已經確定的那些概率,
-在當前塊是所考慮的子集中最後解碼的塊的情形下,實現所述初始化子步驟。
在特定的實施例中,所述塊子集被順序或並行地解碼。
在另一特定的實施例中,當至少兩個塊子集與至少一個其他的塊子集並行解碼時,被識別的數據子流中的一個表示所述至少兩個塊子集。
在又一特定的實施例中,當被編碼的塊子集想要以預定的順序來並行解碼時,與被編碼的塊子集分別對應的數據子流之前在所述要解碼的流中以該預定順序來排序。
相關地,本發明還涉及一種用於對表示至少一個被編碼的圖像的流進行解碼的設備,包括:
-用於在所述流中識別與要解碼的至少一個塊子集分別對應的預定數量的數據子流的裝置,所述塊能夠包含屬於預定符號集的符號,
-用於對被識別的塊子集進行解碼的裝置,該解碼裝置包括熵解碼模塊,其能夠在至少一個所述被識別的子流中讀取與對應於該至少一個被識別的子流的子集中的每個塊的符號相關聯的數字信息,該解碼裝置包括針對圖像中要被解碼的第一塊來初始化熵解碼模塊的狀態變量的子裝置,
該解碼裝置值得注意,在於它包括用於確定當前塊的符號出現概率的裝置,在當前塊是所考慮的子集中要被解碼的第一塊的情形下,該裝置確定該第一塊的符號出現概率,作為針對至少一個其他子集的被解碼的預定塊而已經確定的那些概率,
並且在於,在當前塊是所考慮的子集中最後解碼的塊的情形下,初始化子裝置被激活以重新初始化熵解碼模塊的狀態變量。
本發明的目標還在於一種包含指令的電腦程式,當程序被計算機執行時,用於執行上述編碼或解碼方法的步驟。
該程序可以使用任意程式語言,並且可以採用原始碼、目標代碼或介於原始碼和目標代碼之間的中間代碼的形式,例如部分編譯的形式或任意其他想要的形式。
本發明的又一主題還在於一種記錄介質,其可被計算機讀取,並且包含如上所述的電腦程式指令。
該記錄介質可以是能存儲程序的實體或裝置。例如,該介質可以包括存儲裝置例如rom如cdrom或微電子電路rom,或者磁存儲裝置如磁碟(軟盤)或硬碟。
此外,該記錄介質可以是可傳輸介質例如電或光信號,其可以通過電或光纜、通過無線電或其他方式來傳遞。根據本發明的程序特別地可以從網際網路類型的網絡上下載。
或者,該記錄介質可以是其中包含程序的集成電路,該電路適於執行所考慮的方法或者在後者執行時使用。
上述編碼裝置、解碼方法、解碼裝置和電腦程式展示了與根據本發明的編碼方法所具有的相同的優勢。
附圖說明
閱讀參考附圖來描述的兩個優選實施例,其他特徵和優勢將變得明顯,在附圖中:
-圖1表示現有技術的圖像編碼圖,
-圖2a表示根據本發明的編碼方法的主要步驟,
-圖2b詳細地表示在圖2a的編碼方法中實現的編碼,
-圖3a表示根據本發明的編碼裝置的第一實施例,
-圖3b表示圖3a中的編碼裝置的編碼單元,
-圖3c表示根據本發明的編碼裝置的第二實施例,
-圖4a表示根據第一優選實施例的圖像編碼/解碼圖,
-圖4b表示根據第二優選實施例的圖像編碼/解碼圖,
-圖5a表示根據本發明的解碼方法的主要步驟,
-圖5b詳細地表示在圖5a的解碼方法中實現的解碼,
-圖6a表示根據本發明的解碼裝置的實施例,
-圖6b表示圖6a中的解碼裝置的解碼單元,
-圖7a表示實現順序類型的編碼和並行類型的解碼的圖像編碼/解碼圖,
-圖7b表示以各自不同的並行級別來實現並行類型的編碼/解碼的圖像編碼/解碼圖。
具體實施方式
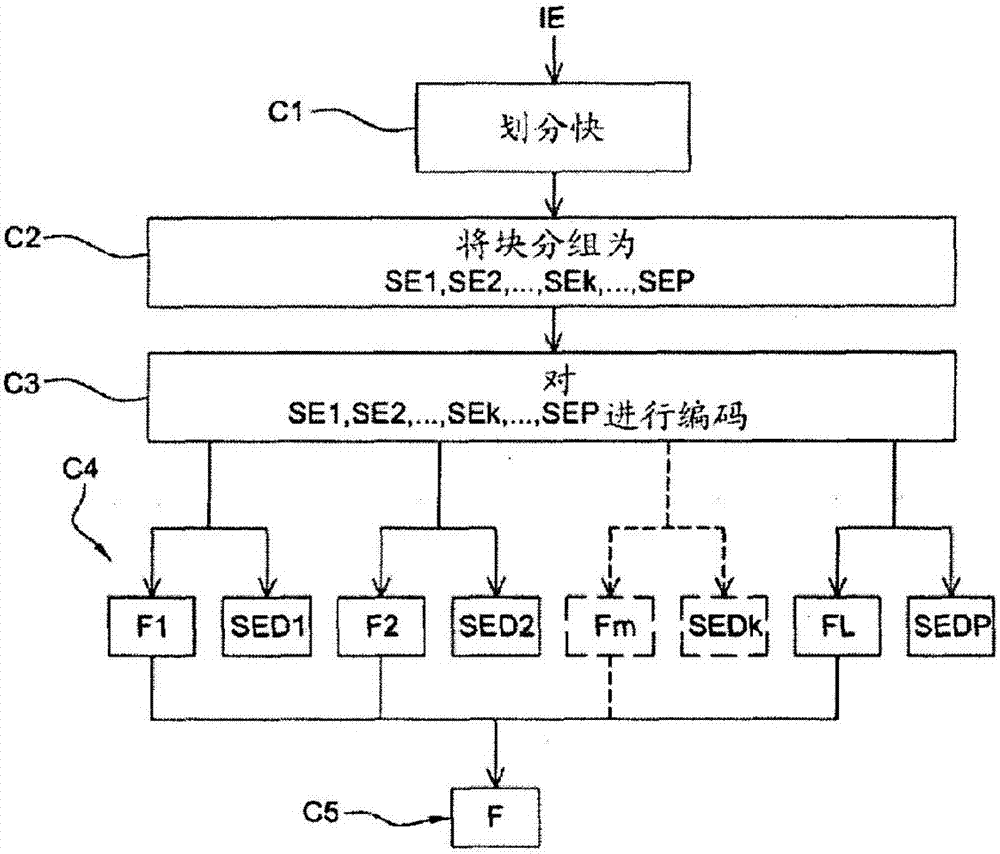
現在將描述本發明的實施例,其中,根據例如符合h.264/mpeg-4avc標準的編碼而獲得的二進位流,依據根據本發明的編碼方法被用於對圖像序列進行編碼。在該實施例中,通過對初始符合h.264/mpeg-4avc標準的編碼器的調整,根據本發明的編碼方法例如以軟體或硬體的方式來實現。根據本發明的編碼方法以包含步驟c1到c5的算法的形式來表示,如圖2a所示。
根據本發明的實施例,根據本發明的編碼方法在編碼裝置co中實現,其兩個實施例分別在圖3a和3c中表示。
參考圖2a,第一編碼步驟c1是將要編碼的圖像序列中的圖像ie劃分為多個塊或宏塊mb,如圖4a或4b所示。所述宏塊可以包含一個或多個符號,所述符號形成預定符號集的一部分。在所示例子中,所述塊mb具有正方形並且都具有相同的大小。作為圖像大小的函數,該圖像不必是塊大小的倍數,左側的最後一塊和底部的最後一塊可以不是正方形。在替代的實施例中,塊例如可以是長方形大小並且/或者互相不對齊。
每個塊或宏塊自身可以進一步被分為子塊,該子塊本身可以再細分。
該劃分是通過圖3a所示的劃分模塊pco來執行的,其使用眾所周知的劃分算法。
參考圖2a,第二編碼步驟c2是將上述塊分組為要被順序或並行編碼的預訂數量p的連續塊的子集se1,se2,...,sek,...,sep。在圖4a和4b所示的例子中,為了圖的清楚,僅展示了四個子集se1、se2、se3、se4。這四個塊子集每個用虛線表示,並且分別包含圖像ie的前四行的塊。
該分組是通過圖3a中所示的計算模塊grco在本身眾所周知的算法的輔助下執行的。
參考圖2a,第三編碼步驟c3包括對所述塊子集se1到se6中的每個進行編碼,根據例如順序類型的預定遍歷次序ps來對所考慮的子集中的塊進行編碼。在圖4a和4b所示的例子中,當前塊sek(l≤k≤p)中的塊如箭頭ps所示從左到右被依次編碼。
根據第一變體,該編碼是順序類型,並且通過如圖3a所示的單個編碼單元uc來實現。通過本身已知的方式,編碼器co包括緩衝存儲器mt,其被適配為包含在當前塊編碼時被逐漸重複更新的符號出現的概率。
如圖3b中更詳細地展示,編碼單元uc包括:
*關於至少一個之前被編碼和解碼的塊對當前塊進行預測編碼的模塊,被表示為mcp;
*使用針對所述之前被編碼和解碼的塊來計算的至少一個符號出現的概率來對所述當前塊進行熵編碼的模塊,被表示為mce。
預測編碼模塊mcp是軟體模塊,其能夠根據傳統的預測技術例如以內和/或間模式對當前塊進行預測編碼。
熵編碼模塊mce本身是cabac類型,但根據本發明來調整,在描述中將進一步描述。
作為變體,熵編碼模塊mce可以是本身已知的霍夫曼編碼器。
在圖4a和4b所示的例子中,單元uc對第一行se1中的塊從左到右進行編碼。當它到達第一行se1的最後一塊時,它傳遞到第二行se2的第一塊。當它到達第二行se2的最後一塊時,它傳遞到第三行se3的第一塊。當它到達第三行se3的最後一塊時,它傳遞到第四行se4的第一塊,等等,直到圖像ie的最後一塊被編碼。
與以上剛才描述的不同的其他類型的遍歷當然是可能的。於是,可以將圖像ie劃分為若干個子圖像並將該類型的劃分獨立應用於每個子圖像。編碼單元還可以不和以上解釋的那樣相繼處理各行,而是相繼(處理)各列。還可以以任意方向來遍歷行或列。
根據第二變體,該編碼是並行類型,並且,僅通過由預訂數量r的編碼單元uck(l≤k≤r)來實現的事實(在圖3c所示的例子中r=2),它與順序編碼的第一變體相區分。已知該並行編碼給編碼方法帶來了明顯的加速。
編碼單元uck中的每個等價於圖3b所示的編碼單元uc。通過相應的方式,編碼單元uck包括預測編碼模塊mcpk和熵編碼模塊mcek。
再次參考圖4a和4b,第一單元uc1對奇數排名的行中的塊進行編碼,而第二單元uc2對偶數排名的行中的塊進行編碼。更準確地說,第一單元uc1從左到右對第一行se1中的塊進行編碼。當它達到第一行se1的最後一塊時,它傳遞第(2n+1)行即第三行se3等的第一塊。與第一單元uc1執行的處理並行,第二單元uc2從左到右對第二行se2中的塊進行編碼。當它到達第二行se2的最後一塊,它傳遞到第(2n)行在這裡是第四行se4等的第一塊。上述兩個遍歷被重複,直到圖像ie的最後一塊被編碼。
參考圖2a,第四編碼步驟c4是產生比特的l個子流f1,f2,...,fm,...,fl(l≤m≤l≤p)來表示通過上述編碼單元uc或者上述編碼單元uck中的每個來壓縮的被處理的塊以及每個子集sek中被處理的塊的解碼版本。根據在描述中將進一步細化的同步機制,所考慮的子集中用sed1,sed2,...,sedk,...,sedp表示的被解碼的處理的塊可以被圖3a所示的編碼單元uc或圖3c所示的編碼單元uck中的每個復用。
參考圖3b,產生l個子流的步驟是通過流生成軟體模塊mgsf或msgfk來實現的,其被適配為產生數據流例如比特。
參考圖2a,第五編碼步驟c5包括基於上述l個子流f1,f2,...,fm,...,fl來構造全局流f。根據一個實施例,子流f1,f2,...,fm,...,fl被簡單地並置,用額外的信息項來向解碼器指示全局流f中的每個子流fm的位置。後者之後被通信網絡(未示出)發送到遠程終端。後者包括圖5a所示的解碼器do。根據另一實施例,這尤其有利,因為不需要對圖像解碼然後再次編碼,在將流f發送到解碼器do之前,解碼器do之前以預定的順序來對l個子流f1,f2,...,fm,...,fl進行排序,該順序對應於do能夠對子流進行解碼的順序。
於是,如描述中更詳細地描述,根據本發明的解碼器能夠在全局流f中分離子流f1,f2,...,fm,...,fl,並將它們分配給組成解碼器的一個或多個解碼單元。需要注意,全局流中的子流的該分解獨立於使用單個編碼單元或並行操作的若干個編碼單元的選擇,並且用該方法,可以只有編碼器或只有解碼器,其包含並行操作的單元。
全局流f的該構造是在例如圖3a和圖3c所示的流構造模塊cf中實現的。
現在將參考圖2b來描述本發明的各個特定子步驟,例如在上述編碼步驟c3期間在編碼單元uc或uck中實現的子步驟。
在步驟c31的過程中,編碼單元uc或uck選擇圖4a或4b所示的當前塊sek例如第一行se1中要編碼的第一塊作為當前塊。
在步驟c32的過程中,單元uc或uck測試當前塊是否是圖像ie的第一塊(位於頂部且位於左側),該圖像在上述步驟c1中已被劃分為塊。
如果是這種情況,在步驟c33的過程中,熵編碼模塊mce或mcek對其狀態變量進行初始化。根據所示例子,其使用如前所述的算術編碼,這包含表示預定符號集中包含的符號的出現的概率的間隔的初始化。通過本身已知的方式,用兩個邊界l和h,分別為下邊界和上邊界,來初始化該間隔。下邊界l的值被固定為0,而上邊界的值被固定為1,由此對應於預定符號集的所有符號中的第一符號的出現的概率。該間隔的大小r因此在此刻由r=h-l=1來定義。被初始化的間隔被傳統地進一步劃分為多個預定的子間隔,其分別表示預定符號集中的符號的出現的概率。
作為變體,如果使用的熵編碼是lzw編碼,符號的串的轉換表被初始化,從而它包含所有可能的符號一次且僅一次。
如果在上述步驟c32之後,當前塊不是圖像ie的第一塊,則在後續描述中之後被描述的步驟c40的過程中確定必要的之前被編碼和解碼的塊的可用性。
在步驟c34的過程中,對圖4a或4b中表示的第一行se1中的第一當前塊mb1進行編碼。該步驟c34包括以下將描述的多個子步驟c341到c348。
在圖2b所示的第一子步驟c341的過程中,通過內和/或間預測的已知技術對當前塊mb1進行預測編碼,在其過程中,關於至少一個之前被編碼和解碼的塊來對塊mb1進行預測。
毋庸置疑,例如h.264標準中提出的其他模式的內預測也是可以的。
還可以以內模式對當前塊mb1進行預測編碼,在其過程中,關於在之前被編碼和解碼的圖像中出現的塊來對當前塊進行預測。其他類型的預測當然也是可能的。在對當前塊的可能的預測中,根據對於本領域技術人員來說眾所周知的比特率失真準則來選擇最優預測。
上述預測編碼步驟使其可能構造預測的塊mbp1,這是對當前塊mb1的近似。與預測編碼相關的信息後續將被寫入到流f中,該流f被發送到解碼器do。該信息特別包括預測類型(間或內(預測)),並且如果合適,包括內預測的類型、塊或宏塊(如果後者已經被細分)的劃分類型、在間預測模式中使用的參考圖像索引和位移矢量。該信息被編碼器co壓縮。
在之後的子步驟c342的過程中,從當前塊mb1中減去預測塊mbp1以產生殘留塊mbr1。
在之後的子步驟c343的過程中,根據傳統的直接變換操作例如dct類型的離散餘弦變換來對殘留塊mbr1進行變換,以產生變換後的塊mbt1。
在之後的子步驟c344的過程中,根據傳統的量化操作例如標量量化來對變換後的塊mbt1進行量化。然後得到係數被量化的塊mbq1。
在之後的子步驟c345的過程中,對係數被量化的塊mbq1進行熵編碼。在優選的實施例中,這包括cabac熵編碼。該步驟包括:
a)讀取與所述當前塊關聯的符號或預定符號集中的符號,
b)將數字信息例如比特與讀取的符號進行關聯。
在上述變體中(根據該變體,使用的編碼是lzw編碼),與當前轉換表中的符號的代碼相對應的數字信息項與要編碼的符號關聯,並根據本身已知的過程來更新該轉換表。
在之後的子步驟c346的過程中,根據傳統的反量化操作即與步驟c344中執行的量化相反的操作來對塊mbq1進行反量化。然後得到係數被反量化的塊mbdq1。
在之後的子步驟c347的過程中,對係數被反量化的塊mbdq1進行逆變換,這是與以上步驟c343中執行的直接變換相反的操作。然後得到被解碼的殘留塊mbdr1。
在之後的子步驟c348的過程中,通過將解碼的殘留塊mbdr1加到預測塊mbp1來構造被解碼的塊mbd1。需要注意,後一塊與在描述中將進一步描述的對圖像ie進行解碼的方法完成之後得到的被解碼的塊相同。被解碼的塊mbd1由此被呈現為可用,以被構成預定數量r的編碼單元的一部分的編碼單元uck或任意其他編碼單元使用。
在完成上述編碼步驟c34之後,例如如圖3b所示的熵編碼模塊mce或mcek包含在第一塊的編碼時被逐漸重複更新的所有概率。這些概率對應於可能的語法的各個元素或者各個關聯的編碼上下文。
在上述編碼步驟c34之後,在步驟c35的過程中執行測試以確定當前塊是否是同一行的第j塊,其中j是編碼器co已知的預定值,其至少等於1。
如果是該情況,在圖2b所示的步驟c36的過程中,針對第j塊來計算的概率集合被存儲在例如圖3a或3b以及圖4a和4b中所示的編碼器co的緩衝存儲器mt中,所述存儲器的大小被適配為存儲所計算的概率數量。
在圖2b所示的步驟c37的過程中,編碼單元uc或uck測試剛才被編碼的行sek的當前塊是否是圖像ie中的最後一塊。如果在步驟c35的過程中當前塊不是行se1的第j塊,該步驟也會被實現。
在當前塊是圖像ie的最後一塊時,在步驟c38的過程中,編碼方法結束。
如果不是該情況,在步驟c39的過程中,根據如圖4a或4b中的箭頭ps所示的遍歷順序來選擇要編碼的下一塊mbi。
在圖2b所示的步驟c40的過程中,確定對於當前塊mbi的編碼來說必須的之前被編碼和解碼的塊的可用性。
如果這是第一行se1,該步驟包括驗證位於要編碼的mbi的左側的至少一個塊的可用性。但是,針對圖4a或4b所示的實施例中選擇的遍歷順序ps,在所考慮的行sek中依次對各個塊進行編碼。結果,左側被編碼和解碼的塊總是可用的(除了一行的第一塊)。在圖4a或4b所示的例子中,這是直接位於要編碼的當前塊的左側的塊。
如果這是與第一行不同的行sek,所述確定步驟還包括驗證位於前一行sek-1中的預訂數量n』的塊例如分別位於當前塊的上方和右上方的兩個塊是否可用於當前塊的編碼,即,它們是否已經被編碼單元uc或uck-1編碼且然後被解碼。
由於該測試步驟容易降低編碼方法的速度,通過根據本發明的替代方式,在行的編碼是並行類型的情形下,圖3c所示的時鐘clk被適配為同步塊編碼的進展以確保分別位於當前塊的上方和右上方的兩個塊的可用性,而不需要驗證這兩塊的可用性。於是,編碼單元uck總是以被用於當前塊的編碼的前一行sek-1中的預訂數量n』(例如n』=2)的被編碼和解碼的塊的偏移來開始第一塊的編碼。從軟體的角度來看,這樣的時鐘的實現使其可能顯著加速編碼器co中對圖像ie中的塊的處理時間。
在圖2b所示的步驟c41的過程中,執行測試以確定當前塊是否是所考慮的行sek中的第一塊。
如果是這種情況,在步驟c42的過程中,在緩衝存儲器mt中僅讀取在前一行sek-1的第j塊的編碼期間計算的符號出現的概率。
根據圖4a所示的第一變體,第j塊是前一行sek-1的第一塊(j=1)。該讀取包括用緩衝存儲器mt中存在的概率來替換cabac編碼器的概率。為使其處理第二、第三和第四行se2、se3和se4中的各個第一塊,如細線所示的箭頭在圖4a中示出該讀取步驟。
根據圖4b所示的上述步驟c43的第二變體,第j塊是前一行sek-1的第二塊(j=2)。該讀取包括用在緩衝存儲器mt中存在的概率來替換cabac編碼器的概率。為使其處理第二、第三和第四行se2、se3和se4中的各個第一塊,如細虛線所示的箭頭在圖4b中示出該讀取步驟。
在步驟c42之後,通過重複上述步驟c34到c38來對當前塊進行編碼然後進行解碼。
如果在上述步驟c41之後,當前塊不是所考慮的行sek的第一塊,有利地不用讀取在位於同一行sek中的之前被編碼和解碼的塊即在所示例子中直接位於當前塊的左側的被編碼和解碼的塊中出現的概率。確實,考慮到如圖4a或4b所示的用於讀取位於同一行中的塊的遍歷順序ps,在開始當前塊的編碼時在cabac編碼器中存在的符號出現的概率正好是在該同一行中的前一塊的編碼/解碼後存在的那些概率。
結果,在圖2b所示的步驟c43的過程中,針對所述當前塊的熵編碼來學習符號出現的概率,這些(概率)僅對應於如圖4a或4b中的雙實線箭頭所示的針對同一行中的所述前一塊來計算的那些概率。
在步驟c43之後,重複上述步驟c34到c38來對當前塊進行編碼然後進行解碼。
在步驟c44的過程之後執行測試以確定當前塊是否是所考慮的行sek中的最後一塊。
如果不是該情況,在步驟c44之後,再次實現對要編碼的下一塊mbi進行選擇的步驟c39。
如果當前塊是所考慮的行sek的最後一塊,在步驟c45的過程中,圖3a或3c的編碼裝置co執行如上描述中提到的清空。為此,編碼單元uck將已經與在所考慮的所述行中的每個塊的編碼期間讀取的符號關聯的所有比特發送到相應的子流生成模塊mgsfk,通過這樣的方式從而模塊mgsfk將所有比特寫入到子流fm中,該子流包含的二進位串表示所考慮的所述行sek中被編碼的塊。這樣的情況在圖4a和4b中用每行sek的末端的三角形來表示。
在圖2b所示的步驟c46的過程中,編碼單元uc或uck執行與上述步驟c33相同的步驟,即再次初始化表示預定符號集中包含的符號的出現的概率的間隔。該重新初始化在圖4a和4b中用每行sek開始的黑點來表示。
在該編碼級別上執行步驟c45和c46的好處是,在編碼單元uc或編碼單元uck處理的下一塊的編碼期間,編碼器co處於初始化狀態。於是,如下將在描述中進一步描述,並行工作的解碼單元可能從該點開始對壓縮過的流f進行直接解碼,因為它滿足處於初始化狀態。
解碼部分的實施例的詳細描述
現在將描述根據本發明的解碼方法的實施例,其中,通過對初始符合h.264/mpeg-4avc標準的編碼器的調整,根據本發明的解碼方法例如以軟體或硬體的方式來實現。
根據本發明的編碼方法以包含步驟d1到d4的算法的形式來表示,如圖5a所示。
根據本發明的實施例,根據本發明的解碼方法在圖6a所示的解碼裝置do中實現。
參考圖5a,第一解碼步驟是在所述流f中識別l個子流f1,f2,...,fm,...,fl,該子流分別包含如圖4a或4b所示之前被編碼的塊或宏塊mb的p個子集se1,se2,...,sek,...,sep。為此,流f中的每個子流與指示符關聯,該指示符旨在允許解碼器do確定每個子流fm在流f中的位置。作為變體,在完成上述編碼步驟c3時,解碼器co以解碼器do期望的順序對流f中的子流f1,f2,...,fm,...,fl進行排序,由此避免在流f中插入子流標識符。該規定由此使其可能降低與數據流f的比特率相關的成本。
在圖4a或4b所示的例子中,所述塊mb具有正方形並且都具有相同的大小。取決於圖像大小,該圖像不必是塊大小的倍數,左側的最後一塊和底部的最後一塊可以不是正方形。在替代的實施例中,塊例如可以是長方形大小並且/或者互相不對齊。
每個塊或宏塊自身可以進一步被分為子塊,該子塊本身可以再細分。
該識別是通過例如圖6a所示的流提取模塊exdo來執行的。
在圖4a或4b所示的例子中,預定數量p等於6,並且為了圖的清楚,僅用虛線示出了四個子集se1、se2、se3、se4。
參考圖5a,第二解碼步驟d2是對所述塊子集se1、se2、se3和se4中的每個進行解碼,所考慮的子集中的塊是根據預定的遍歷順序ps來編碼的。在圖4a或4b所示的例子中,當前子集sek(l≤k≤p)中的塊如箭頭ps所示從左到右被依次被解碼。在步驟d2完成時,得到被解碼的塊子集sed1,sed2,sed3,...,sedk,...,sedp。
這樣的解碼可以是順序類型的,且因此在單個解碼單元的輔助下執行。
但是,為了能夠受益於多平臺解碼架構,塊子集的解碼是並行類型並且通過數量r的解碼單元udk(l≤k≤r)來實現,例如如圖6a所示r=4。該規定由此允許解碼方法的明顯加速。通過本身已知的方式,解碼器do包括緩衝存儲器mt,其被適配為包含在當前塊解碼時被逐漸重複更新的符號出現的概率。
如圖6b中更詳細的表示,每個解碼單元udk包括:
●通過學習針對至少一個之前被解碼的塊來計算的至少一個符號出現的概率來對所述當前塊進行熵解碼的模塊,用mdek來表示,
●關於所述之前被解碼的塊來對當前塊進行預測解碼的模塊,用mdpk來表示。
預測解碼模塊sudpk能夠根據傳統的預測技術例如內和/或間模式來對當前塊進行解碼。
熵解碼模塊mdek本身是cabac類型,但根據本發明來調整,如下在描述中將進一步描述。
作為變體,熵解碼模塊mdek可以是本身已知的霍夫曼解碼器。
在圖4a或4b所示的例子中,第一單元ud1從左到右對第一行se1中的塊進行解碼。當它到達第一行se1的最後一塊,它傳遞到第(n+1)行在這裡是第5行等的第一塊。第二單元uc從左到右對第二行se2中的塊進行解碼。當它到達第二行se2的最後一塊,它傳遞到第(n+2)行這裡是第6行等的第一塊。該遍歷重複直到單元ud4,其從左到右對第四行進行解碼。當它到達第一行的最後一塊,它傳遞到第(n+4)行在這裡是第8行的第一塊,等待,直到最後被識別的子流中的最後一塊被解碼。
與上述剛才描述的不同的遍歷類型當然是可能的。例如,每個解碼單元可以不處理如上解釋的嵌入的行而是嵌入的列。還可以以任意方向來遍歷行或列。
參考圖5a,第三解碼步驟d3是基於在解碼步驟d2中得到的每個被解碼的子集sed1,sed2,...,sedk,...,sedp來重構被解碼的圖像id。更準確地說,每個被解碼的子集sed1,sed2,...,sedk,...,sedp中被解碼的塊被發送到例如如圖6a所示的圖像重構單元uri。在步驟d3的過程中,當這些變得可用時,單元uri將被解碼的塊寫入到被解碼的圖像。
在圖5a所示的第四解碼步驟d4的過程中,圖6a所示的單元uri給出被完全解碼的圖像id。
現在將參考圖5b來描述本發明的各個特定子步驟例如在並行解碼的上述步驟d2期間在解碼單元udk中實現的子步驟。
在步驟d21的過程中,解碼單元udk選擇圖4a或4b所示的當前塊sek中要解碼的第一塊作為當前塊。
在步驟d22的過程中,解碼單元udk測試當前塊是否是被解碼的圖像在的第一塊,在該情形下,是否是子流f1中的第一塊。
如果是該情況,在步驟d23的過程中,熵解碼模塊mde或mdek初始化其狀態變量。根據所示例子,這需要對表示預定符號集中包含的符號的出現的概率的間隔進行初始化。
作為變體,如果使用的熵解碼是lzw解碼,符號的串的轉換表被初始化,從而它包含所有可能的符號一次且僅一次。步驟d23等同於上述編碼步驟c33,後面不會再被描述。
如果在上述步驟d22之後,當前塊不是被解碼的圖像id中的第一塊,在後續描述中之後被描述的步驟d30的過程中確定必要的之前被解碼的塊的可用性。
在步驟d24的過程中,對圖4a或4b所示的第一行se1中的第一當前塊mb1進行解碼。該步驟d24包括將在下面描述的多個子步驟d241到d246。
在第一子步驟d241的過程中,對與當前塊相關的語法元素進行熵解碼。該步驟主要包括:
a)讀取與所述第一行se1關聯的子流中包含的比特,
b)基於讀取的比特來重構符號。
在上述變體中(根據該變體,使用的解碼是lzw解碼),讀取與當前轉換表中的符號代碼相對應的數字信息項,基於讀取的代碼來重構符號,並根據本身已知的過程來更新轉換表。
更準確地說,與當前塊相關的符號元素被例如如圖6b所示的cabac熵解碼模塊mde1解碼。後者對壓縮文件中的比特子流f1進行解碼以產生符號元素,並且同時以該方式來重新更新其概率,從而在後者對符號進行解碼時,該符號出現的概率等於在上述熵解碼步驟c345期間對該相同符號進行編碼時得到的那些概率。
在之後的子步驟d242的過程中,通過內和/或間預測的已知技術來對當前塊mb1進行預測解碼,在其過程中,關於至少一個之前被解碼的塊來預測塊mb1。
毋庸置疑,例如在h.264標準中提出的其他內預測模式也是可以的。
在該步驟的過程中,在前一步驟中解碼的語法元素的輔助下執行預測解碼,該語法元素特別包括(間或內)預測的類型,並且如果合適,包括內預測的模式、塊或宏塊(如果後者已經被細分)的劃分類型、在間預測模式中使用的參考圖像索引和位移矢量。
上述預測解碼步驟使其可能重構預測的塊mbp1。
在之後的子步驟d243的過程中,在之前被解碼的語法元素的輔助下重構量化的殘留塊mbq1。
在之後的子步驟d244的過程中,根據傳統的反量化操作即與上述步驟c344中執行的量化相反的操作來對被量化的殘留塊mbq1進行反量化,以產生被解碼的反量化的塊mbdt1。
在之後的子步驟d245的過程中,對被反量化的塊mbdt1進行逆變換即與上述步驟c343中執行的直接變換相反的操作。於是得到被解碼的殘留塊mbdr1。
在之後的子步驟d246的過程中,通過將被解碼的殘留塊mbdr1加到預測塊mbp1來構造被解碼的塊mbd1。被解碼的塊mbd1由此被呈現為可用,以被解碼單元ud1或構成預訂數量n的解碼單元的一部分的任意其他解碼單元使用。
在完成上述解碼步驟d246時,例如如圖6b所示的熵解碼模塊mde1包含在第一塊的解碼的同時被逐漸重複更新的所有概率。這些概率對應於可能的語法的各個元素並且對應於各個關聯的解碼上下文。
在上述解碼步驟d24之後,在步驟d25的過程中執行測試來確定當前塊是否是同一行的第j塊,其中j是解碼器do已知的預定值,其至少等於1。
如果是這種情況,在步驟d26的過程中,針對第j塊計算的概率集合被存儲在例如如圖6a所示以及圖4a或4b中的解碼器do中的緩衝存儲器mt,所述存儲器的大小被適配為存儲所計算的概率數量。
在步驟d27的過程中,單元udk測試剛才被解碼的當前塊是否是最後的子流中的最後一塊。
如果是這種情況,在步驟d28的過程中,解碼方法結束。
如果不是該情況,在步驟d29的過程中根據圖4a或4b中的箭頭ps所示的遍歷順序來選擇要解碼的下一塊mbi。
如果在上述步驟d25的過程中,當前塊不是所考慮的行sedk的第j塊,則執行以上步驟d27。
在上述步驟d29之後的步驟d30的過程中,確定對於當前塊mbi的解碼來說必要的之前被解碼的塊的可用性。考慮到這需要通過不同解碼單元udk來對塊進行並行解碼的事實,可能出現這些塊沒有被指定對這些塊進行解碼的解碼單元來解碼,且因此它們還不可用。所述確定步驟包括驗證位於前一行sek-1中的預訂數量n』的塊例如分別位於當前塊的上方和右上方的兩個塊是否可用於當前塊的解碼,即,它們是否已經被指定對其進行解碼的解碼單元udk-1解碼。所述確定步驟還包括確定位於要編碼的當前塊mbi的左側的至少一塊的可用性。但是,考慮到圖4a或4b所示的實施例中選擇的遍歷順序ps,所考慮的行sek中的塊被依次解碼。結果,左側被解碼的塊總是可用的(除了一行中的第一塊)。在圖4a或4b所示的例子中,這需要直接位於當前塊的左側的塊被解碼。為此,只有分別位於當前塊的上方和右上方的兩個塊的可用性被測試。
由於該測試步驟容易降低解碼方法的速度,通過根據本發明的替代方式,圖6a所示的時鐘clk被適配為同步塊解碼的進展以確保分別位於當前塊的上方和右上方的兩個塊的可用性,而不需要驗證這兩塊的可用性。於是,如圖4a或4b所示,解碼單元udk總是以被用於當前塊的解碼的前一行sek-1中的預訂數量n』(這裡n』=2)的被解碼的塊的偏移來開始第一塊的解碼。從軟體的角度來看,這樣的時鐘的實現使其可能顯著加速解碼器do中對每個子集sek中的塊進行處理的時間。
在步驟d31的過程中,執行測試以確定當前塊是否是所考慮的行sek中的第一塊。
如果是這種情況,在步驟d32的過程中,在緩衝存儲器mt中僅讀取在前一行sek-1的第j塊的解碼期間計算的符號出現的概率。
根據圖4a所示的第一變體,第j塊是前一行sek-1的第一塊(j=1)。該讀取包括用緩衝存儲器mt中存在的概率來替換cabac解碼器的概率。為使其處理第二、第三和第四行se2、se3和se4中的各個第一塊,如細線所示的箭頭在圖4a中示出該讀取步驟。
根據圖4b所示的上述步驟d32的第二變體,第j塊是前一行sek-1的第二塊(j=2)。該讀取包括用在緩衝存儲器mt中存在的概率來替換cabac解碼器的概率。為使其處理第二、第三和第四行se2、se3和se4中的各個第一塊,如細虛線所示的箭頭在圖4b中示出該讀取步驟。
在步驟d32之後,通過重複上述步驟d24到d28來對當前塊進行解碼。
如果在上述步驟d31之後,當前塊不是所考慮的行sek的第一塊,有利地不用讀取在位於同一行sek中的之前被解碼的塊即在所示例子中直接位於當前塊的左側的被解碼的塊中出現的概率。確實,考慮到如圖4a或4b所示的用於讀取位於同一行中的塊的遍歷順序ps,在開始當前塊的解碼時在cabac解碼器中存在的符號出現的概率正好是在該同一行中的前一塊的解碼後存在的那些概率。
結果,在步驟d33的過程中,針對所述當前塊的熵解碼來學習符號出現的概率,所述概率僅對應於如圖4a或4b中的雙實線箭頭所示的針對同一行中的所述前一塊來計算的那些概率。
在步驟d33之後,重複上述步驟d24到d28來對當前塊進行解碼。
在步驟d34的過程之後執行測試以確定當前塊是否是所考慮的行sek中的最後一塊。
如果不是該情況,在步驟d34之後,再次實現對要解碼的下一塊mbi進行選擇的步驟d29。
如果當前塊是所考慮的行sek的最後一塊,在步驟d35的過程中,解碼裝置udk執行與上述步驟d23相同的步驟,即再次初始化表示預定符號集中包含的符號的出現的概率的間隔。該重新初始化在圖4a和4b中用每行sek開始的黑點來表示。
於是,解碼器do在每行開始時處於初始化狀態,由此從選擇解碼的並行級別以及優化解碼的處理時間的角度來看允許更大的靈活性。
在圖7a所示的示例性編碼/解碼圖中,編碼器co包括單個編碼單元uc,如圖3a所示,而解碼器do包括六個解碼單元。
解碼單元對行se1、se2、se3、se4、se5和se6順序進行編碼。在所示例子中,行se1到se4被完全編碼,行se5正在被編碼的過程中且行se6還沒有被編碼。考慮到編碼的順序性,編碼單元uc被適配為給出流f,該流包含依次排序的子流f1、f2、f3、f4,以對行se1、se2、se3和se4進行編碼。為此,子流f1、f2、f3和f4用與分別表示被編碼的行se1、se2、se3、se4的相同的陰影來表示。通過在所述被編碼的行的編碼結束時的清空步驟以及在開始對要編碼/解碼的下一行的編碼或解碼時重新初始化概率的間隔,當解碼器do每次讀取子流來解碼時,解碼器處於初始化狀態,並且可以以優化的方式用例如可被安裝在四個不同平臺上的解碼單元ud1、ud2、ud3和ud4對四個子流f1、f2、f3和f4進行並行解碼。
在圖7b所示的示例性編碼/解碼圖中,編碼器co包括如圖3c所示的兩個編碼單元uc1和uc2,而解碼器do包括六個解碼單元。
編碼單元uc1對奇數排名的行se1、se3和se5進行順序編碼,而編碼單元uc2對偶數排名的行se2、se4和se6進行順序編碼。為此,行se1、se3和se5表現為白色背景,而行se2、se4和se6表現為帶點的背景。在所示例子中,行se1到se4被完全編碼,行se5正在被編碼的過程中而行se6還沒有被編碼。考慮到所執行的編碼的級別為2的並行類型的事實,編碼單元uc1被適配為給出子流f2n,該子流可被分解為在對行se2和se4分別解碼之後得到的兩個部分f2和f4。解碼器co因此被適配為向解碼器do發送流f,該流包含兩個子流f2n+1和f2n的並置,以及因此與圖7a所示不同的子流排序f1、f3、f2、f4。為此,子流f1、f2、f3和f4用與分別表示被編碼的行se1、se2、se3、se4的相同的陰影來表示,子流f1和f3表現為白色背景(奇數排序的行的編碼),且子流f2和f4表現為帶點的背景(偶數排序的行的編碼)。
關於結合圖7a所述的優勢,該編碼/解碼圖還展示了能夠清空解碼器的優勢,該解碼器的解碼並行級別完全獨立於編碼的並行級別,由此使其可能進一步優化編碼器/解碼器的操作。