一種智能語音交互機器人的製作方法
2023-11-09 12:33:12 5
本發明涉及機器人領域,尤其是語音交互機器人領域,具體為一種智能語音交互機器人。本發明通過對機器人的結構進行改進,提供一種全新的智能語音交互機器人,其採用類似熊貓外形的結構設計,並通過對內部結構進行改進,有效解決了現有語音交互機器人所存在的語音僅能單獨輸入或輸出的問題,對於推動語音交互機器人的發展,推動機器人語音交互技術的進步,具有重要的意義。
背景技術:
語音作為人類所特有的能力,是人類之間交流及獲取外界信息資源的重要的工具和渠道,對於人類文明的發展具有重要的意義。語音識別技術作為人機互動分支的重要組成,是人機互動的重要接口,對於人工智慧的發展具有重要的實際意義。語音識別技術經過數十年的發展,已經取得了顯著的進步,逐步開始從實驗室慢慢走向市場。目前,針對特定說話人的語音識別系統已經有較高的識別精度,並被廣泛應用於工業、家電、通信、汽車電子、醫療、家庭服務和消費電子類產品等領域。
近年來,隨著語音識別技術在機器人控制中的應用,機器人的應用領域不斷擴大。同時,國內外關於基於語音識別的機器人控制技術的研究也取得了一定的進展。例如,國內有白琳在基於語音識別的機器人控制技術的研究中對語音特徵參數提取方法進行了改進,將傳統的mfcc特徵參數與共振峰參數相結合,提出了新的語音特徵參數提取方法。
目前,現有的語音交互產品大多基於專用的語音識別晶片,其內核為單片機或數位訊號中央處理器,其實質是將麥克風輸入的聲音信號採樣編碼,再通過內部處理器與其事先錄製好的語音信息匹配,再將相應的語音信息通過片內的模塊經過外置的揚聲器輸出。例如,中國專利cn201620720668.8公開了一種具有語音交互功能的機器人系統,其包括由機器人頭部、機器人身部和底座組成的機器人,所述機器人身部內設有一pcb板,所述pcb板連接有一單片機,所述單片機連接有一信號發射電路,所述機器人頭部設有圖像採集傳感器和語音接收器,所述信號發射電路與所述語音接收器、圖像採集傳感器相連,所述信號發射電路與移動終端相連,所述單片機還連接有一信號接收電路和語音播放器,所述信號接收電路分別與移動終端和語音播放器相連,所述信號發射電路、信號接收電路均連接有一濾波器,所述機器人身部包括機器人手臂、顯示裝置和輸入按鈕,所述輸入按鈕與所述顯示裝置相連,其能實現語音交互的功能。
然而,申請人研究發現,現有的語音識別機器人具有較好的單向識別能力,但雙向語音識別能力較弱,主要有如下兩方面的問題:
1)機器人在移動過程中,由於步進電機等設備的基底噪聲幹擾,會給語音交互機器人帶來不可預知的結果;
2)當機器人在說話,或者播放音樂時,即使用戶發出指令,機器人也難以對用戶發出的指令進行識別,雙向語音識別能力幾乎喪失,這也是目前現有的機器人主要採用問答方式進行控制的主要原因。
基於現有語音交互機器人所存在的上述缺陷,人機互動的友好性和安全性不能得到保障,違背了機器人的三定律。為此,迫切需要一種新的裝置,以解決上述問題。
技術實現要素:
本發明的發明目的在於:針對目前現有的語音智能交互機器人僅能採用一問一答的方式進行控制,人機互動的友好性和安全性不能得到保障的問題,提供一種智能語音交互機器人。本發明的機器人通過對其結構的改進,能有效進行雙向語音識別,突破現有技術所存在的缺陷。另一方面,基於機器人內部結構的改進,機器人在移動過程中,由於步進電機等設備的基底噪聲幹擾,所導致的語音交互問題,得到有效解決。本發明能夠實現人與機器人的雙向互動交流,有效提升人機互動的友好性,具有顯著的進步意義。
為了實現上述目的,本發明採用如下技術方案:
一種智能語音交互機器人,包括底部支撐架、驅動機構、第一腔體、第二腔體、控制系統,所述驅動機構設置在底部支撐架上且驅動機構通過底部支撐架能帶動機器人運動,所述第一腔體、第二腔體相連構成機器人主體,所述機器人主體設置在底部支撐架上;
所述第二腔體上對稱設置有兩個第三腔體,所述第一腔體、第二腔體、第三腔體分別為中空結構;
所述第一腔體的空腔內設置有第一支撐架,所述第一支撐架與底部支撐架相連,所述第一腔體側壁上分別設置有第一語音播放裝置、第一空腔,所述第一腔體下方設置有第一隔音板,所述第一腔體的第一空腔內從下至上依次設置有上隔音抽屜、下隔音抽屜且第一支撐架能夠分別為上隔音抽屜、下隔音抽屜提供支撐,所述第一隔音板位於底部支撐架與下隔音抽屜之間;
所述第一腔體與第二腔體之間設置有第二隔音板,所述第三腔體上分別設置有第三語音播放裝置、與第三語音播放裝置相配合的喇叭孔、語音識別裝置,所述第三腔體呈球形,所述第三語音播放裝置為兩個且分別設置在第三腔體上,所述喇叭孔為若干個且喇叭孔呈扇形環帶狀,所述語音識別裝置位於第三語音播放裝置之間;
所述控制系統分別與第一語音播放裝置、第三語音播放裝置、語音識別裝置相連。
所述機器人主體下方設置有若干個散熱孔。
若干個散熱孔構成矩形設置於主體下方。
所述第一腔體上還設置有凹槽,所述凹槽內設置有與控制系統相連的信號接收器、扶手中的一種或多種。
所述信號接收器設置在第一支撐架上。
還包括與控制系統相連的顯示器,所述顯示器設置在第二腔體的側壁上,所述顯示器位於兩個第三腔體之間且語音識別裝置設置在顯示器下方。
所述顯示器與水平面之間的夾角為15~90°。
所述上隔音抽屜、下隔音抽屜之間設置有第三隔音板。
所述語音識別裝置位於第三語音播放裝置之間的中線上。
還包括攝像頭跟隨機構、避障機構,所述攝像頭跟隨機構、避障機構分別設置在機器人主體上且攝像頭跟隨機構、避障機構分別與控制系統相連,所述控制系統能夠接受、處理攝像頭跟隨機構傳輸的圖像信號以及避障機構所檢測的位置信號,進而控制驅動機構的動作。
還包括與控制系統相連的導航機構。
用於前述智能語音交互機器人交互系統的方法,包括如下步驟:
(一)判斷語音輸入類型
1)判斷語音輸入類型,若為輸入輸出雙向識別系統,則執行步驟(二),若為輸入單向識別系統,則執行步驟(三);
(二)預定義輸入輸出雙向識別系統;
2)預定義語音輸出表,並根據預定義語音輸出表採集語音播放裝置組成輸出樣本集和輸出測試集;
3)預定義語音詞彙表,並根據該語音詞彙表採集語音樣本數據組成輸入樣本集和輸入測試集;
4)分別對輸出樣本集內的n個語音樣本、輸入樣本集內的m個語音樣本全排列,得到n!m!個排列;分別將每一個排列輸入訓練系統中,得到一個訓練好的語音矢量中心;最後求出n!m!個語音矢量中心的平均矢量和方差參數,得到最終的語音訓練模板;其中,n、m為大於1的整數;
5)同時使用輸出測試集、輸入測試集中的語音樣本作為待測語音進行測試,得到不同語音樣本下的魯棒性程度,包括每個語音樣本的正確識別率和語音樣本平均正確識別率;
6)按照語音樣本正確識別率的大小對語音樣本進行排序,選擇單詞正確識別率大於平均正確識別率的語音樣本組成雙向候選詞彙表;
7)針對雙向候選詞彙表,再次使用步驟4)訓練語音模板,得到各個語音模板的平均矢量μ1和平均方差σ1;
8)當待測語音輸入時,計算待測語音與各語音模板的匹配距離,選擇最小匹配距離對應的語音模板為識別結果;
9)輸出待測語音的識別結果;
(三)預定義輸入單向識別系統;
10)對步驟3)內輸入樣本集內的m個語音樣本全排列,得到m!個排列;分別將每一個排列輸入訓練系統中,得到一個訓練好的語音矢量中心;最後求出m!個語音矢量中心的平均矢量和方差參數,得到最終的語音訓練模板;其中,m為大於1的整數;
11)使用輸入測試集中的語音樣本作為待測語音進行測試,得到相應語音樣本的魯棒性程度,包括每個語音樣本的正確識別率和語音樣本平均正確識別率;
12)按照語音樣本正確識別率的大小對語音樣本進行排序,選擇單詞正確識別率大於平均正確識別率的語音樣本組成單向候選詞彙表;
13)針對單向候選詞彙表,再次使用步驟10)訓練語音模板,得到各個語音模板的平均矢量μ2和平均方差σ2;
14)當待測語音輸入時,計算待測語音與各語音模板的匹配距離,選擇最小匹配距離對應的語音模板為識別結果;
15)輸出待測語音的識別結果。
在現有結構中,主要是採用一問一答的方式進行控制,這主要是由於機器人自身的輸出會對語音識別效果產生極大影響的問題。目前,通用採用對晶片進行改進的方式,以解決前述問題。而發明中,通過對機器人的整體結構進行改進,有效減少語音輸出對語音輸入的幹擾,進而達到語音輸入輸出雙向交互的目的。
該結構包括底部支撐架、驅動機構、第一腔體、第二腔體、控制系統;其中,底部支撐架為其他部件提供支撐,驅動機構與底部支撐架相連,驅動機構帶動底部支撐架及其上的其他部件運動。驅動機構包括一組主動輪、從動輪,主動輪分別與控制系統相連。本發明中,從動輪可以為萬向輪,主動輪為兩個且分別通過電機帶動主動輪轉動。進一步,主動輪可以為麥克拉姆輪,主動輪、從動輪呈等腰三角形分布。
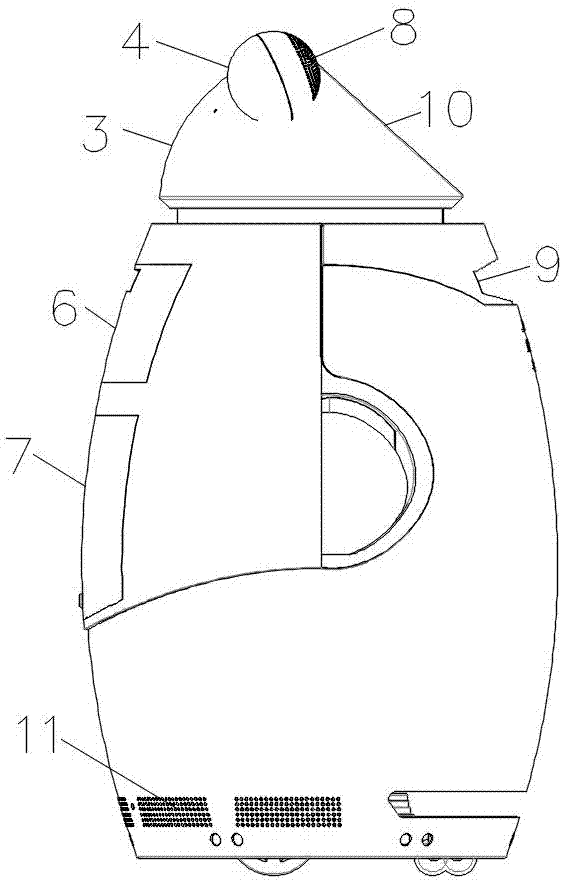
第一腔體、第二腔體相連,構成機器人主體,第一腔體、第二腔體從下至上依次設置;並且,第二腔體上對稱設置有兩個第三腔體,第一腔體、第二腔體、第三腔體分別為中空結構,第三腔體呈球形。第一腔體大於第二腔體,第二腔體大於第三腔體。採用該結構,形成下大上小、上部有兩個耳朵的熊貓形態的智慧機器人。
第一腔體側壁上分別設置有第一語音播放裝置、第一開口,第一腔體的空腔內設置有第一支撐架,第一支撐架為第一腔體內的其他部件提供支撐。通過第一語音播放裝置,能夠實現機器人的語音輸出。
本發明中,在第一腔體的空腔內從下至上依次設置有上隔音抽屜、下隔音抽屜,通過上隔音抽屜、下隔音抽屜起到隔音、減震的作用。第一腔體下方設置有第一隔音板,第一隔音板位於底部支撐架與下隔音抽屜之間,第一腔體與第二腔體之間設置有第二隔音板。第三腔體上分別設置有第三語音播放裝置、與第三語音播放裝置相配合的喇叭孔、語音識別裝置,第三語音播放裝置為兩個且分別設置在第三腔體上,喇叭孔呈扇形環帶狀分布,語音識別裝置位於兩個第三語音播放裝置之間,優選為中線上。
申請人分析後認為,現有迎賓類、家用小型擬人或仿動物形態智慧機器人無法實現語音雙向輸入輸出的問題在於,機器人自身的結構上;現有迎賓類、家用小型擬人或仿動物形態智慧機器人採用單獨的腔體結構,其內部會形成一個巨大的音腔,音腔會嚴重影響語音識別的效果。為此,本發明在結構上進行了如下幾方面的改進:1)將現有技術中單獨的腔體結構改進為第一腔體、第二腔體兩個單獨的腔體,2)在第一腔體與第二腔體之間設置有第二隔音板,阻斷第一腔體音腔對識別裝置的影響,3)並將第一腔體的空腔內從下至上依次設置上隔音抽屜、下隔音抽屜,通過上隔音抽屜、下隔音抽屜的設置,一方面有利於用戶物品等的放置,起到置物的作用,另一方面則能破壞第一腔體原有的音腔,儘可能減少第一語音播放裝置對語音識別裝置的影響;4)第三語音播放裝置對稱設置在第三腔體上,喇叭孔呈扇形環帶狀,採用該方式,第三語音播放裝置形成一個對稱的語音輸出,極大降低第三語音播放裝置對於語音識別裝置的影響。基於上述結構的改進,本發明能夠實現機器人的語音輸出與用戶的語音輸入的雙向互動,極大提高用戶的雙向語音識別效率,有效解決現有技術所存在的問題和缺陷。
進一步,機器人主體下方設置有若干個散熱孔;通過散熱孔能夠有效散發機器人內部的熱量,保證機器人的正常運行。
進一步,第一腔體上還設置有凹槽,所述凹槽內設置有與控制系統相連的信號接收器、扶手中的一種或多種。採用該方式,用戶可以通過扶手對機器人進行操作;用戶除直接使用語音之另外,可以通過信號接收器,向機器人發送相應的控制指令。
進一步,還包括與控制系統相連的顯示器,顯示器設置在第二腔體的側壁上,顯示器位於兩個第三語音播放裝置之間且語音識別裝置設置在顯示器下方。採用該方式,顯示器形成類似熊貓的可愛的臉,第三腔體則形成熊貓的耳朵,給人以更好的親近感,增強用戶交互的友好性。
進一步,顯示器與水平面之間的夾角為15~90°。採用該方式,能夠便於用戶對顯示器的觀看。
進一步,為了提高隔音效果,本發明在上隔音抽屜、下隔音抽屜之間設置有第三隔音板,以進一步降低第一語音播放裝置對語音識別裝置的影響。
進一步,還包括攝像頭跟隨機構、避障機構,攝像頭跟隨機構、避障機構分別設置在機器人主體上且攝像頭跟隨機構、避障機構分別與控制系統相連,控制系統能夠接受、處理攝像頭跟隨機構傳輸的圖像信號以及避障機構所檢測的位置信號,進而控制驅動機構的動作。採用該方式,本發明的機器人通過攝像頭跟隨機構識別用戶的運動軌跡,並將圖像信息傳遞給控制系統;同時,避障機構將所檢測的位置信號傳遞給控制系統;控制系統接受、處理攝像頭跟隨機構傳輸的圖像信號以及避障機構所檢測的位置信號,並控制驅動機構的動作,實現對用戶的智能跟隨。
進一步,還包括與控制系統相連的導航機構。通過導航機構,本發明能夠為用戶提供導航指導;同時,基於導航機構,本發明也能夠自動運動到設定的位置。
本發明還提供基於前述智能語音交互機器人的交互系統的實現方法,該方法中,針對不同的語音情景進行判斷,並基於判斷的結果,執行相應的識別操作。該方法中,採用單獨的語音識別裝置,即可實現對語音的識別處理,而無需採用多個語音識別裝置,進行語音降噪處理。同時,該方法不依賴於特定的說明者,通過對語音輸出表、語音詞彙表的定義,並依靠語音訓練模板等後續處理,使得本發明在抗噪聲和與說話人無關方面得以改進,弱化了不同說話人的個性信息。另一方面,基於本發明的方法,可以用於在線聯網識別,也能實現無網離線識別,識別率高,識別效果好。
採用該方法,能夠有效修正識別結果,實現單向語音輸入和雙向語音輸入輸出,且在單向語音輸入和雙向語音輸入輸出中,均具有較好的識別效果。經實際測試,本發明的識別精度能達到95%以上,有效實現了說話人與機器人雙向語音輸入輸出的雙向進行,使得說話人與機器人之間的友好性和互動性得到極大增強,具有顯著的進步意義。
附圖說明
本發明將通過例子並參照附圖的方式說明,其中:
圖1為實施例1中裝置的側視圖。
圖2為實施例1中裝置的後視圖。
圖中標記:1為驅動機構,2為第一腔體,3為第二腔體,4為第三腔體,6為上隔音抽屜,7為下隔音抽屜,8為喇叭孔,9為信號接收器,10為顯示器,11為散熱孔。
具體實施方式
本說明書中公開的所有特徵,或公開的所有方法或過程中的步驟,除了互相排斥的特徵和/或步驟以外,均可以以任何方式組合。
本說明書中公開的任一特徵,除非特別敘述,均可被其他等效或具有類似目的的替代特徵加以替換。即,除非特別敘述,每個特徵只是一系列等效或類似特徵中的一個例子而已。
實施例1
本實施例的智能語音交互機器人包括底部支撐架、驅動機構、第一腔體、第二腔體、控制系統。其中,驅動機構設置在底部支撐架上,第一腔體、第二腔體相連構成機器人主體,機器人主體設置在底部支撐架上。第二腔體上對稱設置有兩個第三腔體,第一腔體、第二腔體、第三腔體分別為中空結構。
本實施例中,驅動機構包括一個從動輪和兩個主動輪、兩個與主動輪相連的驅動電機。採用該結構,驅動機構能夠帶動機器人相對地面進行移動。
同時,第一腔體的空腔內設置有第一支撐架,第一支撐架與底部支撐架相連,第一腔體側壁上分別設置有第一語音播放裝置、第一空腔,第一腔體下方設置有位於底部支撐架與下隔音抽屜之間的第一隔音板,第一腔體的第一空腔內從下至上依次設置有上隔音抽屜、下隔音抽屜,第一支撐架能夠分別為上隔音抽屜、下隔音抽屜提供支撐。
本實施例中,第一腔體與第二腔體之間設置有第二隔音板,第三腔體上分別設置有第三語音播放裝置、與第三語音播放裝置相配合的喇叭孔、語音識別裝置,第三腔體呈球形,第三語音播放裝置為兩個且分別設置在第三腔體上,喇叭孔為若干個且喇叭孔呈扇形環帶狀(如圖所示),語音識別裝置位於第三語音播放裝置之間。
本實施例中,驅動電機、第一語音播放裝置、第三語音播放裝置、語音識別裝置分別與控制系統相連。
本實施例中,第一腔體下方還設置有若干個散熱孔,散熱孔呈矩形布置;第一腔體上還設置有凹槽,凹槽內設置有與控制系統相連的信號接收器;第二腔體的側壁上還設置與控制系統相連的顯示器,顯示器位於兩個第三腔體之間,語音識別裝置位於顯示器下方。本實施例中,顯示器與水平面之間的夾角為45°,語音識別裝置位於兩個第三語音播放裝置之間的中線上。
本實施例中,還包括攝像頭跟隨機構、避障機構、導航機構,攝像頭跟隨機構、避障機構分別設置在機器人主體上。攝像頭跟隨機構、避障機構、導航機構分別與控制系統相連,控制系統能夠接受、處理攝像頭跟隨機構傳輸的圖像信號以及避障機構所檢測的位置信號,進而控制驅動機構的動作。
採用該方式,本實施例的機器人通過攝像頭跟隨機構識別用戶的運動軌跡,並將圖像信息傳遞給控制系統;同時,避障機構將所檢測的位置信號傳遞給控制系統;控制系統接受、處理攝像頭跟隨機構傳輸的圖像信號以及避障機構所檢測的位置信號,並控制驅動機構的動作,實現對用戶的智能跟隨。而基於導航機構,控制系統能夠控制本實施例的機器人自動運動到設定位置。
本實施例中,採用訊飛語音識別接口進行語音識別,雙向語音輸入輸出識別精確度達到88%以上,單向語音輸入識別精度達95%左右,具有較好的效果。
實施例2
以實施例1的裝置為基礎,本實施例提供一種不同的語音交互系統的實現方法,其包括如下步驟:
(一)判斷語音輸入類型
1)判斷語音輸入類型,若為輸入輸出雙向識別系統,則執行步驟(二),若為輸入單向識別系統,則執行步驟(三);
(二)預定義輸入輸出雙向識別系統;
2)預定義語音輸出表,並根據預定義語音輸出表採集語音播放裝置組成輸出樣本集和輸出測試集;
3)預定義語音詞彙表,並根據該語音詞彙表採集語音樣本數據組成輸入樣本集和輸入測試集;
4)分別對輸出樣本集內的n個語音樣本、輸入樣本集內的m個語音樣本全排列,得到n!m!個排列;分別將每一個排列輸入訓練系統中,得到一個訓練好的語音矢量中心;最後求出n!m!個語音矢量中心的平均矢量和方差參數,得到最終的語音訓練模板;其中,n、m為大於1的整數;
5)同時使用輸出測試集、輸入測試集中的語音樣本作為待測語音進行測試,得到不同語音樣本下的魯棒性程度,包括每個語音樣本的正確識別率和語音樣本平均正確識別率;
6)按照語音樣本正確識別率的大小對語音樣本進行排序,選擇單詞正確識別率大於平均正確識別率的語音樣本組成雙向候選詞彙表;
7)針對雙向候選詞彙表,再次使用步驟4)訓練語音模板,得到各個語音模板的平均矢量μ1和平均方差σ1;
8)當待測語音輸入時,計算待測語音與各語音模板的匹配距離,選擇最小匹配距離對應的語音模板為識別結果;
9)輸出待測語音的識別結果;
(三)預定義輸入單向識別系統;
10)對步驟3)內輸入樣本集內的m個語音樣本全排列,得到m!個排列;分別將每一個排列輸入訓練系統中,得到一個訓練好的語音矢量中心;最後求出m!個語音矢量中心的平均矢量和方差參數,得到最終的語音訓練模板;其中,m為大於1的整數;
11)使用輸入測試集中的語音樣本作為待測語音進行測試,得到相應語音樣本的魯棒性程度,包括每個語音樣本的正確識別率和語音樣本平均正確識別率;
12)按照語音樣本正確識別率的大小對語音樣本進行排序,選擇單詞正確識別率大於平均正確識別率的語音樣本組成單向候選詞彙表;
13)針對單向候選詞彙表,再次使用步驟10)訓練語音模板,得到各個語音模板的平均矢量μ2和平均方差σ2;
14)當待測語音輸入時,計算待測語音與各語音模板的匹配距離,選擇最小匹配距離對應的語音模板為識別結果;
15)輸出待測語音的識別結果。
本實施例中,雙向語音輸入輸出識別精確度達到95%以上,單向語音輸入識別精度達97%左右,具有較好的效果。
本發明並不局限於前述的具體實施方式。本發明擴展到任何在本說明書中披露的新特徵或任何新的組合,以及披露的任一新的方法或過程的步驟或任何新的組合。