預測模型構建方法和設備以及實時預測方法和設備與流程
2023-11-09 08:52:56 12
本公開涉及預測技術領域,更特別地涉及一種用於構建預測模型的方法和設備以及用於執行實時預測的方法和設備。
背景技術:
預測技術是當下的一個熱點研究問題。預測技術可以在各個領域得到廣泛應用,諸如空氣品質預測、氣候預測、交通流量預測等。根據數據的特點和預測的問題的不同,已經提出了各種不同的預測模型,例如基於參數的時間序列預測、神經網絡、回歸分析等。
傳統的預測模型通常採用全局建模的方式,即利用一個統一的模型涵蓋各種預測過程,並對自變量與因變量之間的關係進行建模。然而,數據中變量間的關聯模式隨著時間、空間的不同通常有著較大變化,而這類統一的模型難以涵蓋數據中的所有情況,尤其是數據中的稀有事件。而這些事件往往會是預測中需要特別關注的重點,例如空氣品質預測中的重度汙染預測、交通流中的事故預測等。
傳統的預測方法,如神經網絡、回歸分析等方法,通常首先採集一些真實數據作為樣本,以用於訓練模型,然後用訓練好的模型進行預測。這樣預測的準確度非常依賴於訓練時所用樣本數據的數量和質量。而且待預測的數據與訓練樣本特徵差異較大時,其預測結果往往是不準確的。
多模型預測是傳統的空氣品質預測多採用的預測方式,這種預測方式已經被證明是有效的。例如,在US6535817B1中公開了一種基於多回歸模型的氣候預測方式。根據該專利中提出的技術方案,在訓練過程中,首先針對歷史氣候數據執行預處理,以使其滿足模型的輸入和輸出形式;接著隨機地將數據劃分為N個分組;然後,針對這N個分組進行訓練以得到相應的N個預測模型;隨後,基於歷史氣候數據針對這N個相應的預測模型進行評估,以便獲得他們各自的歷史性能。而在預測過程中,針對實時數據採用N個預測模型進行預測,以得到N個預測結果;然後,基於各個預測模型的歷史性能對這N個預測結果進行加權平均;最後,將得到的平均結果作為最終預測結果進行存儲。
在上述的美國專利所提出的技術中,採用了歷史性能作為模型性能的度量。然而,實時預測是一個相當複雜的問題,例如對於空氣品質而言,它不但受到最近歷史空氣品質因素和交通因素的影響,而且還受到實時氣象因素的影響。因而,包括上述專利在內的現有技術中基於多模型的預測方法目前對於實時預測而言有效性仍然不太理想,其預測結果的準確性和可靠性依然較低。
為此,在現有技術中存在針對實時預測技術的方案進行改進的需要。
技術實現要素:
有鑑於此,本公開公開了一種用於構建預測模型的方法和設備以及用於執行實時預測的方法和設備,以至少部分上消除或者緩解上述問題。
根據本公開的第一方面,提供了一種用於構建預測模型的方法。該方法包括:識別待訓練數據中的多種不同的關聯模式,其中所述多種不同的關聯模式描述所述待訓練數據中的影響因素與目標數據之間的多種不同的關聯關係;利用與所述多種不同的關聯模式相對應的多組數據分別進行訓練,以得到適用於所述多種不同的關聯模式的多個子預測模型;以及根據所述待訓練數據構建所述多種不同的關聯模式之間的關聯模式轉移模型。所述關聯模式轉移模型用於在預測過程中確定所述多個不同的子預測模型與待預測數據之間的匹配度。
在根據本公開的第一方面的實施方式中,所述識別待訓練數據中的多種不同的關聯模式包括:將所述待訓練數據按照時間劃分為多個數據分段;學習所述多個數據分段中的各個數據分段的關聯模式;以及通過合併相似的關聯模式和對應的數據分段來確定所述多種不同的關聯模式。
在根據本公開的第一方面的另一實施方式中,所述確定所述多種不同的關聯模式包括:基於層次聚類對所述各個數據分段的關聯模式進行聚類。
在根據本公開的第一方面的另一實施方式中,所述關聯模式轉移模型描述所述多種不同的關聯模式之間的模式轉移的概率。
在根據本公開的第一方面的另一實施方式中,根據所述待訓練數據構建所述多種不同的關聯模式之間的關聯模式轉移模型包括:利用馬爾科夫鏈模型按照最大似然性原則根據所述待訓練數據來確定所述多種不同的關聯模式之間的轉移矩陣。
根據本公開的第二方面,提供了一種用於執行實時預測的方法。所述方法包括:利用多個不同的子預測模型針對實時數據執行預測,以得到多個初始預測結果,其中所述多個不同的子預測模型分別適用於多種不同的關聯模式;基於所述多種不同的關聯模式之間的關聯模式轉移模型確定所述實時數據與所述多個不同的子預測模型之間的匹配度;以及基於所述匹配度對所述多個初始預測結果進行加權平均,以確定針對所述實時數據的預測結果。
在根據本公開的第一方面的實施方式中,所述多個不同的子預測模型是通過識別待訓練數據中的所述多種不同的關聯模式並且利用與所述多種不同的關聯模式相對應的多組數據分別進行訓練而得到的。
在根據本公開的第一方面的另一實施方式中,所述關聯模式轉移模型描述所述多種不同的關聯模式之間的模式轉移的概率。
在根據本公開的第一方面的再一實施方式中,所述基於關聯模式轉移模型確定所述實時數據與所述多個不同的子預測模型之間的匹配度包括:通過根據所述實時數據之前的數據的關聯模式以及所述多種不同的關聯模式之間的模式轉移的概率計算所述實時數據處於所述多種不同的關聯模式的各個關聯模式的概率,來確定所述匹配度。
根據本公開的第三方面,提供了一種用於構建預測模型的設備。所述設備包括:模式識別模塊、模型訓練模塊和模型構建模塊。所述模式識別模塊被配置用於識別待訓練數據中的多種不同的關聯模式,其中所述多種不同的關聯模式描述所述待訓練數據中的影響因素與目標數據之間的多種不同的關聯關係。所述模型訓練模塊被配置用於利用與所述多種不同的關聯模式相對應的多組數據分別進行訓練,以得到適用於所述多種不同的關聯模式的多個子預測模型。所述模型構建模塊被配置用於根據所述待訓練數據構建所述多種不同的關聯模式之間的關聯模式轉移模型,其中所述關聯模式轉移模型用於在預測過程中確定所述多個不同的子預測模型與待預測數據之間的匹配度。
根據本公開的第四方面,提供了一種用於執行實時預測的設備。所述設備包括:預測執行模塊、匹配度確定模塊和結果平均模塊。所述預測執行模塊被配置用於利用多個不同的子預測模型針對實時數據執行預測,以得到多個初始預測結果,其中所述多個不同的子預測模型分別適用於多種不同的關聯模式。所述匹配度確定模塊被配置用於基於所述多種不同的關聯模式之間的關聯模式轉移模型確定所述實時數據與所述多個不同的子預測模型之間的匹配度。所述結果平均模塊被配置用於基於所述匹配度對所述多個初始預測結果進行加權平均,以確定針對所述實時數據的預測結果。
根據本公開的第五方面,提供了一種計算程序產品,其上包括有電腦程式代碼,當被加載到計算機設備中時,其可以使得該計算機設備執行根據本公開的第一方面的方法。
根據本公開的第六方面,提供了一種計算程序產品,其上包括有電腦程式代碼,當被加載到計算機設備中時,其可以使得該計算機設備執行根據本公開的第二方面的方法。
根據本公開的第七方面,還提供一種用於構建預測模型的設備,所述設備包括存儲器,和處理器,所述處理器可以被配置為執行根據本公開的第一方面的方法。
根據本公開的第八方面,還提供一種用於執行實時預測的設備,所述設備包括存儲器,和處理器,所述處理器可以被配置為執行根據本公開的第二方面的方法。
根據本公開的實施方式,可以得到與多個關聯模式對應的多個預測子模型,而所述關聯模式能夠反應數據本身的特徵。因此在實時預測時,就可以基於實時數據本身的數據特徵來動態調整各個預測子模型的權重,因而預測精度可以得到提高。
附圖說明
通過對結合附圖所示出的實施方式進行詳細說明,本公開的上述以及其他特徵將更加明顯,本公開的附圖中相同的標號表示相同或相似的部件。在附圖中:
圖1示意性地示出了根據本公開的一個實施方式的用於構建預測模型的方法的流程圖;
圖2示意性地示出了根據本公開的一個實施方式的樣本集形成的示意圖;
圖3示意性地示出了根據本公開的一個實施方式的關聯模式識別的流程圖;
圖4示意性地示出了根據本公開的一個實施方式的數據分段劃分的示意圖;
圖5示意性地示出了根據本公開的一個實施方式的關聯模式學習的示意圖;
圖6示意性地示出了根據本公開的一個實施方式的相似關聯模式合併的示意圖;
圖7示意性地示出了根據本公開的一個實施方式的模型訓練的示意圖;
圖8示意性地示出了根據本公開的一個實施方式的關聯模式轉移模型構建的示意圖;
圖9示意性地示出了根據本公開的一個實施方式的用於執行實時預測的方法的流程圖;
圖10示意性地示出了根據本公開的一個實施方式的用於匹配度計算的示意圖;
圖11示意性地示出了根據本公開的一個實施方式的預測結果平均的示意圖;
圖12示意性地示出了根據本公開的一個實施方式的預測系統的整體架構的方框圖;
圖13示意性地示出了根據本公開的一個實施方式的用於構建預測模型的設備的方框圖;以及
圖14示意性地示出了根據本公開的一個實施方式的用於執行實時預測的設備的方框圖。
具體實施方式
在下文中,將參考附圖詳細描述本公開的各個示例性實施方式。應當注意,這些附圖和描述涉及的僅僅是作為示例的優選實施方式。可以應該指出的是,根據隨後的描述,很容易設想出此處公開的結構和方法的替換實施方式,並且可以在不脫離本公開要求保護的公開的原理的情況下使用這些替代實施方式。
應當理解,給出這些示例性實施方式僅僅是為了使本領域技術人員能夠更好地理解進而實現本公開,而並非以任何方式限制本公開的範圍。此外在附圖中,出於說明的目的,將可選的步驟、模塊、模塊等以虛線框示出。
在此使用的術語「包括」、「包含」及類似術語應該被理解為是開放性的術語,即「包括/包含但不限於」。術語「基於」是「至少部分地基於」。術語「一個實施例」表示「至少一個實施例」;術語「另一實施例」表示「至少一個另外的實施例」。其他術語的相關定義將在下文描述中給出。
如前所述,在現有技術中,基於多模型的預測方法目前對於實時預測而言有效性仍然不太理想,其預測結果的準確性和可靠性依然較低。針對此問題,在本公開中提出一種新的技術方案,該方案是一種基於數據中的關聯模式劃分並組合使用多個預測模型的方法。根據該方案,將構建針對多種關聯模式的多個預測模型,同時在實時預測時,將根據實時數據與預測模型之間的匹配程度動態調整各個預測模型的權重,以便提高預測精度。
在下文中,將參考附圖對根據本公開的實施方式的用於預測模型構建和實時預測的方法和設備進行詳細描述。然而,需要說明的是,這些描述是僅僅是出於說明的目的,本公開並不局限於這些實施方式和附圖中的細節。此外,在下面的描述中,將主要參考空氣品質預測對本公開的實施方式進行描述。然而需要說明的是,本公開也可能應用在其他預測場合,例如氣候預測、交通流量預測等。
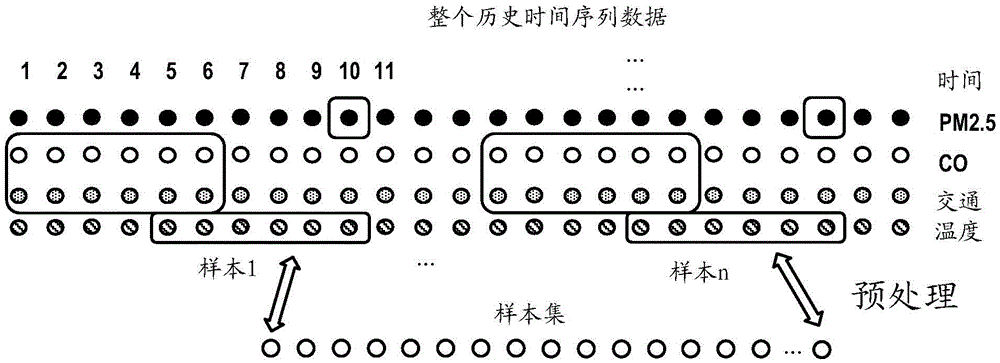
圖1示意性地示出了根據本公開的一個實施方式的用於構建預測模型的方法的流程圖。如圖1所示,首先在步驟S101,識別待訓練數據中的多種不同的關聯模式。如圖2所示,待訓練數據可以是從整個歷史時間序列數據中採樣得到的數據,例如包括目標數據以及影響因素數據。目標數據是與預測對象對應的數據,例如在PM2.5預測的場景下,目標數據是PM2.5。影響因素是影響目標數據的因素,例如在PM2.5預測的場景下,影響因素可以是空氣品質因素諸如CO、SO2,交通狀況等。
目標數據及其影響因素的時間序列是由數據監測設備採集的一系列數據,諸如是氣象數據、空氣品質數據、交通數據、人口密度數據、汙染源數據等的時間序列。可以清楚的是,對於不同的數據,不同時間序列通常具有不同的尺度、採集間隔等。因此,首先可以對採集得到的數據進行預處理,以便將其轉化為待訓練的樣本集。例如,可以將在不同的時間(時間)和不同的位置(空間)採集得到的數據歸一化為具有相同時間尺度的數據序列,從而得到樣本集。Si=(Xi,Yi),即待訓練數據,其中Xi代表影響因素,Yi代表目標數據。由於在預測時,影響因素是輸入,目標數據是輸出,所以在下文中也將Xi稱為輸入,將Yi稱為輸出。
影響因素Xi可以包括兩個部分,即歷史序列部分和未來序列部分。在給定預測索引y和時間步長L的情況下,可以將Xi表示如下:
(式1)
該式代表可以獲得時刻i+R+1時刻的數據來預測Yi,並且其中代表第p個輸入變量(例如空氣品質,交通因素,比如CO和交通流量)在(i+t)時刻的歷史序列部分;代表第q個輸入變量(例如氣象因素,諸如風力,溼度)在(i+t+L)時刻的未來序列部分。
Yi=yi+R-1+L代表在(i+R-1+L)時刻的預測項,其中L是在Xi之後的時間步長;R是輸入變量的範圍,R通常大於時間步長L。需要注意的是,在i+R-1時刻,空氣品質和交通數據均是檢測數據,因此,只能夠使用截止到時刻i+R-1的歷史數據;而氣象數據可以是預測數據,因此可以使用直到(i+R-1+L)時刻的未來數據。
接著,可以針對訓練的樣本集Si=(Xi,Yi),執行關聯模式識別。此處的術語「關聯模式」指代在一個特定時段內的待訓練數據中的影響因素與目標數據之間的關聯關係。多種不同的關聯模式將描述待訓練數據中的影響因素與目標數據之間的多種不同的關聯關係。以PM2.5預測為例,第一種關聯模式可以指示一氧化碳CO對於PM2.5具有較大影響,第二種關聯模式可以指示交通情況對於PM2.5具有較大影響,第三種關聯模式可以指示溫度對於PM2.5具有較大影響等等。相同的關聯模式中的樣本數據將具有共同的特徵,因此這些樣本將會形成一個特定的關聯模式。
在下文中,將參考一個示例實施方式對關聯模式識別進行詳細描述,在該示例實施方式中,將基於Granger Lasso方法和層次聚類來實現關聯模式識別。然而需要說明的是,這僅僅是出於說明的目的,本公開也有可能採用任何其他適當的手段和算法來定義和學習關聯模式。
參考圖3,首先在步驟S1011,將所述待訓練數據按照時間劃分為多個數據分段。這裡如可以通過一個滑動時間窗口來實現。圖4示意性地示出了根據本公開的一個實施方式的分段劃分的示意圖。如圖4所示,該滑動時間窗口具有固定的長度Len例如為8,每次分段劃分例如移動一個樣本。這樣就可以得到例如P個分段Seci,其中i=1至P。然而需要說明的是,分段長度和移動步長是為了說明的目的而給出的,本公開並不局限於此。
對於給定的窗口長度Len和樣本集(S1,S2,...,Sn},樣本集可以被劃分為n-len+1個分段,其中Seci={Si,Si+1,...,Si+len-1}。
接著,在步驟S1012,學習所述多個數據分段中的各個數據分段的關聯模式。換句話講,針對每個數據分段,學習該組數據的關聯模式。圖5中示出了根據本公開的一個實施方式的關聯模式學習的示意圖。在該圖中,採用的是Granger Lasso圖模型方法。該Granger Lasso圖模型方法的目標函數可以通過下面的式子來表示:
(式2)
其中為輸入數據的向量,其由各個時間序列變量xi的一段數據組成;y為對應的輸出;為係數向量,其反映了特定的輸入xi與輸出y之間的關聯;n為待訓練的各個數據分段的樣本數目,λ為正則項係數。
將Granger Lasso方法應用於各個數據分段Seci,以便學習輸入與輸出之間的關聯關係。結果將針對每個數據分段Seci得到一個對應的權重向量Wi,其中如圖5所示。此處將Seci的關聯模式表示為Pi,並使用該權重向量Wi作為關聯模式Pi的特徵空間。
然後,在步驟S1013,通過合併相似的關聯模式和對應的數據分段來確定所述多種不同的關聯模式。針對圖5中得到的多個關聯模式,可以確定他們之間的相似度,並基於相似閾值,來對這些關聯模式進行合併,最終得到多種不同的關聯模式PA-PQ。
在根據本公開的一個實施方式中,關聯模式之間的相似度可以通過特徵空間中的每個元素的權重來計算。例如可以通過下面給出的式子來度量相似度:
(式3)
通過該式子可以確定出兩個關聯模式Wi和Wj之間的相似度。
在根據本公開的一個實施方式中,使用層次聚類對關聯模式進行聚類。特別地,在初始狀態時,每個關聯模式Pi單獨為一類,即Ci=Pi。此後,逐層地構造聚類樹,在每一層將當前最相似的兩個類聚為一個新的模式類,如圖6所示。兩個類Ca和Cb之間的相似度可以定義如下:
Sim_Ca,b=max{Sim_Pi,j|Pi∈Ca,Pj∈Cb}
(式4)
需要說明的是,按照上述定義,Sim_Ca,b越小,類Ca和Cb越相似。對於一個預定的相似度閾值δ,當某層出現min{Sim_Ca,b}>δ時,則該層聚類停止,這表示此時各個類之間已足夠不相似。假設兩個類Ca、Cb合併為新類Cab(對應的新關聯模式記為Pab),則兩個類對應的樣本數據也被合併在一起,並且樣本對應的關聯模式也被更新為Pab。
最終,假設我們得到了K個關聯模式的聚類,記為對每一個聚類中的數據,重新用Granger Lasso方法計算出一個新的權重向量。這樣將會得到K個對應的權重向量這K個權重向量就是對應的關聯模式的特徵空間。
這樣,通過例如圖3中所示的方法,就可以識別出待訓練數據中的多個不同的關聯模式。
現在返回繼續參考圖1。如圖1所示,在識別出待訓練數據中的多種不同的關聯模式之後,可以在步驟S102,利用所述多種不同的關聯模式相對應的對組數據分組分別進行訓練,以得到適用於所述多種不同的關聯模式的多個子預測模型。例如,可以針對得到的K個關聯模式及其對應的K個數據分組,分別訓練K個預測模型,如圖7所示。預測模型可以根據數據情況進行不同的選擇,如果分組中的數據量較小則使用Lasso回歸模型,數據量較大,則可以使用深度神經網絡模型。在下面將以Lasso回歸模型為例進行說明。對於K種關聯模式,可以學習K個Lasso回歸模型。對於樣本集為Seti={Si1,Si2,...,Sim}的Lasso回歸模型的目標函數可以表示為:
(式5)
在選定的預測模型的情況下,利用待訓練數據來訓練模型可以採用本領域任何適當的方法,這對於本領域技術人員而言是已知的。因此,此處為了簡化起見不再進行詳細說明。
接下來,在步驟S103,根據所述待訓練的數據構建多種不同的關聯模式之間的關聯模式轉移模型。關聯模式轉移模型描述所述多種不同的關聯模式之間的模式轉移規律的模型,例如可以描述所述多種不同的關聯模式之間的模式轉移的概率。基於該模型,可以確定例如一個關聯模式在下一步轉移到各個關聯模式的概率。
在本公開的一個實施方式中,利用馬爾科夫鏈模型按照最大似然性原則根據所述待訓練數據來確定所述多種不同的關聯模式之間的轉移矩陣。然而需要說明的是,也可以採用任何其他適當的技術來構建關聯模式轉移模型。特別地,對於每個歷史樣本,都存在一個對應的關聯模式,這樣可以針對樣本集和得到關聯模式的序列:
{S1,S2,...,Sn}→{P(1),P(2),...,P(n)},
(式6)
其中St為t時刻的樣本;P(t)為t時刻的關聯模式。根據Markov鏈模型,一階轉移矩陣A可以按最大似然估計原則計算如下:
(式7)
其中表示轉移到的次數。這樣就得到了關聯模式轉移模型,例如如圖8所示。然而需要說明的是,儘管在上式5中給出了一階轉移矩陣,但是本公開不僅限於此,也有可能採用更高階矩陣。
這樣,通過上面給出的方法,可以得到適用於多種不同模式的子預測模型,並且獲得了多種不同的關聯模式之間的模式轉移模型。該模式轉移模型可以用於在預測過程中確定所述多個不同的子預測模型與待預測數據之間的匹配度。這樣,執行預測時,就可以基於待預測的實時數據與各個子預測模型的匹配度來動態調整各個預測子模型的權重。在下文中,將繼續參考圖9至圖11來描述本公開中提供的一種用於執行實時預測的方法。
參考圖9,首先在步驟S901,利用多個不同的子預測模型針對實時數據執行預測,以得到多個初始預測結果。所述多個不同的子預測模型分別適用於多種不同的關聯模式。因此,在該步驟使用的子預測模型與傳統方法中使用的多個預測模型是不同的。傳統方法中使用的多個預測模型是通過訓練隨機劃分的數據分組而得到的多個預測模型,而本公開中的多個子預測模型,是針對各個不同的關聯模式的子模型。當監測的實時數據輸入時,可以利用在訓練階段得到的多個不同的子預測模型分別執行預測,這樣可以得到多個初始預測結果。
接著,在步驟S902可以基於所述多種不同的關聯模式之間的關聯模式轉移模型確定所述實時數據與所述多個不同的子預測模型之間的匹配度。例如,對於t時刻的實時數據St,時刻t之前一段時間的數據序列為{St-k,...,St-1},對應的關聯模式序列為{P{t-k},...,P(t-1)}。此處使用idx(t)指示P(t)的下標,例如則idx(t-k)=3);使用f(j)指示的轉移概率,則f(j)可以被表示為:
(式8)
其中A(t-i)為(t-i)-階轉移矩陣,且其可以被計算為C-K函數A(n)=A(n-1)A。這樣,對於實時數據St,其屬於各個關聯模式的概率為f(i)。
在根據本公開的一個方式中,直接使用該概率f(i)來表示實時數據St與關聯模式之間的匹配度Di,即Di=f(i)。然而,需要說明的是,本公開並不局限於此。事實上,匹配度Di也可以是基於該概率f(i)通過其他方式計算得到的值。換言之匹配度Di可以是概率f(i)的函數。匹配度Di反映了實時數據St屬於一個特定的關聯模式的概率的大小。Di越大,則該實時數據與該關聯模式越為匹配。因此,Di越大,也就意味著該實時數據與適用於該關聯模式的預測模型更為匹配,該預測模型的可靠性越高。在下面將參考圖10來描述匹配度計算的是一個示例。
參考圖10,該圖示意性地示出了根據本公開的一個實施方式的用於匹配度計算的示意圖。如圖10所示,對於實時數據S100,其之前時間最近的三個樣本S99,S98和S97的關聯模式分別為P2、P3和P1。基於這三個樣本的關聯模式和轉移概率矩陣,並利用式6中示出的轉移概率計算公式,可以確定出實時樣本S100與P1、P2、P3和P4的匹配度分別為0.79、1.08、0.47和0.66。也就是說,該實時數據S100與關聯模式P2具有最大的匹配度而與關聯模式P3具有最小的匹配度。
返回參考圖9,然後在步驟S903,基於所述匹配度對上面所述的多個初始預測結果進行加權平均,以確定出針對所述實時數據的最終預測結果。例如,對於K個初始預測結果,可以利用K個對應的關聯模式匹配度對初始預測結果進行加權平均。
該預測結果平均例如可以通過以下方式來執行。首先,可以針對得到的K個匹配度執行歸一化,該歸一化可以通過下面的式子給出:
(式9)
然後利用歸一化後的匹配度執行加權平均,因此最後的輸出結過可以通過下面的式子表示:
Rfinal=ΣD_normi·Ri
其中Ri指示利用多個預測模型得到的多個預測結果。
出於說明的目的,在圖11中示出了根據本公開的一個實施方式的預測結果加權平均的示意圖。如圖11所示,其中初始的預測結果A至Q分別利用對應的匹配度值(0.79,0.47,…,1.08)進行加權平均,進而將加權平均後的輸出作為最終預測結果。最後,可以實時存儲最終的預測結果。
需要說明的是,在上面的描述中,將步驟S901描述為在S902之前進行操作。然而,本公開並不局限於此,實際上步驟S902也有可能在步驟S901之前執行,或者並行地執行兩個步驟。
下面將參考圖12來描述根據本公開的一個實施方式的預測系統的整體架構的方框圖,以使得本領域技術人員對於本公開的預測系統的總體架構有個更加深入的理解。如圖12所示,該預測系統架構可以被劃分為訓練過程和預測過程,其中在訓練過程中將使用歷史數據進行訓練,以確定出針對多個不同的關聯模式的多個子預測模型以及多個不同的關聯模式之間的關聯轉移模型。在預測階段中,將基於訓練過程中得到的預測模型和關聯模式轉移模型執行預測。
具體地,如圖12所示,在訓練過程中,首先針對歷史數據執行預處理,以便對各種數據執行歸一化。接著,執行關聯模式識別,例如可以通過滑動時間窗間該數據劃分為P個數據分段,然後學習每個數據分段的關聯模式;接著對相似的關聯模式進行合併,進而得到K種關聯模式。然後針對每種關聯模式,利用對應的數據分組執行訓練,進而得到多個預測模型,即預測模型A至K。與此同時,可以根據歷史數據構建K種不同的關聯模式之間的關聯模式轉移模型。在預測過程中,針對採集到的實時數據,基於在訓練階段得到多個預測模型執行實時預測,進而得到多個初始預測結果,即預測結果A至預測結果K。同時,可以例如基於式5和關聯模式轉移模型計算出該實時數據與多個預測模型之間的匹配度。然後基於計算的匹配度對預測結果A至預測結果K進行加權平均,並最終將經過加權平均的預測結果作為最終預測結果輸出。
從上文中針對本公開的實施方式的描述可以看出,在本公開中,可以得到與多個關聯模式對應的多個預測子模型,而所述關聯模式能夠反應出數據本身的特徵。因此在實時預測時,就可以基於實時數據本身的數據特徵來動態調整各個預測子模型的權重,因而預測精度可以得到提高。
在上文中,針對本公開中提供過的用於構建預測模型的方法和用於實時預測的方法進行了描述。此外,本公開中還提供了一種用於構建預測模型的設備和一種用於執行實時預測的設備。在下文中將參考圖13和圖14對這些設備進行詳細地描述。
圖13示出了根據本公開的一個實施方式的用於構建預測模型的設備的方框圖。該設備1300包括模式識別模塊1310、模型訓練模塊1320以及模型構建模塊1330。所述模式識別模塊1310可以被配置用於識別待訓練數據中的多種不同的關聯模式,其中所述多種不同的關聯模式描述所述待訓練數據中的影響因素與目標數據之間的多種不同的關聯關係。所述模型訓練模塊1320可以被配置用於利用與所述多種不同的關聯模式相對應的多組數據分別進行訓練,以得到適用於所述多種不同的關聯模式的多個子預測模型。所述模型構建模塊1330可以被配置用於根據所述待訓練數據構建所述多種不同的關聯模式之間的關聯模式轉移模型,其中所述關聯模式轉移模型用於在預測過程中確定所述多個不同的子預測模型與待預測數據之間的匹配度。所述關聯模式轉移模型可以描述所述多種不同的關聯模式之間的模式轉移規律。特別地,在一個實施方式中,所述關聯模式轉移模型可以描述所述多種不同的關聯模式之間的模式轉移的概率。
此外,所述模式識別模塊1310可以進一步包括數據劃分模塊1312、模式學習模塊1314和模式確定模塊1316。所述數據劃分模塊1312可以被配置用於將所述待訓練數據按照時間劃分為多個數據分段。所述模式學習模塊1314可以被配置用於學習所述多個數據分段中的各個數據分段的關聯模式。所述模式確定模塊1316可以被配置用於通過合併相似的關聯模式和對應的數據分段來確定所述多種不同的關聯模式。
另外,所述模式確定模塊1316進一步被配置用於通過基於層次聚類對所述各個數據分段的關聯模式進行聚類來確定出所述多種不同的關聯模式。
在一個實施方式中,所述模型構建模塊1330可以被配置用於:利用馬爾科夫鏈模型按照最大似然性原則根據所述待訓練數據,來確定所述多種不同的關聯模式之間的轉移矩陣。
接著參考圖14,圖14示意性地示出了根據本公開的一個實施方式的用於實時預測的設備的方框圖。如圖14所示,設備1400包括結果預測模塊1410、匹配度確定模塊1420和結果平均模塊1430。所述結果預測模塊1410可以被配置用於利用多個不同的子預測模型針對實時數據執行預測,以得到多個初始預測結果,其中所述多個不同的子預測模型分別適用於多種不同的關聯模式。所述匹配度確定模塊1420可以被配置用於基於所述多種不同的關聯模式之間的關聯模式轉移模型確定所述實時數據與所述多個不同的子預測模型之間的匹配度。所述結果平均模塊1430可以被配置用於基於所述匹配度對所述多個初始預測結果進行加權平均,以確定針對所述實時數據的預測結果。所述多個不同的子預測模型可以是通過識別待訓練數據中的所述多種不同的關聯模式並且利用與所述多種不同的關聯模式相對應的多組數據分別進行訓練而得到的。另外,所述關聯模式轉移模型可以描述所述多種不同的關聯模式之間的模式轉移規律。特別地,在一個實施方式中,所述關聯模式轉移模型可以描述所述多種不同的關聯模式之間的模式轉移的概率。
此外,所述匹配度確定模塊1420可以被配置為:通過根據所述實時數據之前的數據的關聯模式以及所述多種不同的關聯模式之間的模式轉移的概率計算所述實時數據處於所述多種不同的關聯模式的各個關聯模式的概率,來確定所述匹配度。
需要說明的是,上面參考圖13和14所描述的設備1300和1400中的各個模塊可以被配置為執行與參考圖1至圖12所描述的方法相對應的操作。因此,此處不再詳細描述設備1300和1400的各個模塊的具體操作。關於這些模塊的具體操作的細節,可以參考結合圖1至圖12針對相應方法的各個步驟進行的描述。
另外還需理解的是,本公開的實施方式可以以軟體、硬體或者軟體和硬體的結合來實現。硬體部分可以利用專用邏輯來實現;軟體部分可以存儲在存儲器中,由適當的指令執行系統,例如微處理器或者專用設計硬體來執行。本領域的普通技術人員可以理解上述的方法和設備可以使用計算機可執行指令和/或包含在處理器控制代碼中來實現,例如在諸如磁碟、CD或DVD-ROM的載體介質、諸如只讀存儲器(固件)的可編程的存儲器或者諸如光學或電子信號載體的數據載體上提供了這樣的代碼。本實施例的設備及其組件可以由諸如超大規模集成電路或門陣列、諸如邏輯晶片、電晶體等的半導體、或者諸如現場可編程門陣列、可編程邏輯設備等的可編程硬體設備的硬體電路實現,也可以用由各種類型的處理器執行的軟體實現,也可以由上述硬體電路和軟體的結合例如固件來實現。
雖然已經參考目前考慮到的實施方式描述了本公開,但是應該理解本公開不限於所公開的實施方式。相反,本公開旨在涵蓋所附權利要求的精神和範圍內所包括的各種修改和等同布置。以下權利要求的範圍符合最廣泛解釋,以便包含所有這樣的修改及等同結構和功能。