一種分布式垃圾簡訊識別方法與流程
2023-12-03 19:54:32 1
本發明涉及一種分布式垃圾簡訊識別方法,屬於智能簡訊識別技術領域。
背景技術:
隨著資訊時代通信服務業的高速發展,垃圾簡訊已日益成為困擾運營商和手機用戶的難題,不僅侵害了電信客戶的合法權益,破壞了和諧的電信消費環境,而且嚴重影響到人們正常生活、侵害到運營商的社會形象以及危害著社會穩定,垃圾簡訊的存在給用戶與運營商均帶來了不少的煩惱,因此,研究垃圾簡訊的識別與處理具有重要意義。
目前垃圾簡訊的識別過濾主要有以下幾種技術:黑白名單識別技術、發送頻率限制識別技術、關鍵詞匹配識別技術、基於機器學習識別垃圾簡訊技術等。這些常用的垃圾簡訊識別技術均存在各自的局限性,比如黑白名單技術僅對已知的號碼有效,發送頻率限制識別技術的發送頻率規則易被相對應的方法所規避,關鍵字匹配識別技術對關鍵字的選取難以界定而易導致誤判,基於機器學習識別垃圾簡訊技術相對較複雜從而影響識別的效率。上述垃圾簡訊識別的研究成果的局限性較大地影響了垃圾簡訊的識別準確率和效率。垃圾簡訊識別技術已成為學術界和產業界的研究熱點,同時隨著如今信息化大數據的發展,需要識別處理的信息數據越來越多,傳統的識別方法已跟不上數據時代的步伐,因此需要一個高效的識別垃圾簡訊的方法,同時具有網絡化分布式計算與存儲大量信息數據的方法來應對垃圾簡訊識別和處理問題。
技術實現要素:
本發明所要解決的技術問題是提供一種針對常規垃圾簡訊識別方法的低準確率的特點,具有高準確率、快速識別、智能反饋等特點的分布式垃圾簡訊識別方法。
本發明為了解決上述技術問題採用以下技術方案:本發明設計了一種分布式垃圾簡訊識別方法,將待識別簡訊數據集合拆分成各個待識別簡訊子任務,各個待識別簡訊子任務分別包括至少一條待識別簡訊,各個待識別簡訊子任務分別發送至分布式系統中的各個節點進行處理,各個節點分別按如下步驟,根據預設檢測器庫中各個檢測器內的各個垃圾簡訊關鍵詞,針對所接收到的待識別簡訊子任務進行垃圾簡訊識別;
步驟000.根據預設垃圾關鍵詞庫,初始化檢測器庫中的各個檢測器,然後進入步驟001;
步驟001.由待識別簡訊子任務隊列中提取一條未處理的待識別簡訊,作為當前識別簡訊,獲取當前識別簡訊中的各個關鍵詞Gene1,Gene2,Gene3…Genei,進入步驟002;步驟002.將當前識別簡訊中的各個關鍵詞Gene1,Gene2,Gene3…Genei通過HashMap,獲得所有包含有這些關鍵詞的檢測器Index的索引值的集合,進入步驟003;
步驟003.將得到的索引值集合通過m個HashSet,判斷是否存在親和力大於或等於預設匹配率閾值brake的檢測器Index,是則判定當前識別簡訊為垃圾簡訊,將其加入垃圾簡訊庫,並由AVL樹中提取出利用該檢測器Index,進入步驟004;否則說明檢測器庫中不存在能與當前識別簡訊匹配率達到預設匹配率閾值brake的檢測器,則判定當前識別簡訊為正常簡訊,將其加入至正常簡訊庫,進入步驟009;其中,m=Testlength*brake;
步驟004.由被判斷為垃圾簡訊的當前識別簡訊中的各個關鍵詞,構建若干新檢測器,接著判斷正常簡訊庫中正常簡訊的條數是否大於或等於預設正常簡訊庫比對條數閾值,是則進入步驟005;否則將各個新檢測器加入到檢測器庫中,並進入步驟009;
步驟005.由正常簡訊庫隊列中提取一條未參與針對各個新檢測器自檢的正常簡訊,分別針對各個新檢測器,將該正常簡訊中各個關鍵詞與新檢測器中各個垃圾簡訊關鍵詞進行匹配,獲得彼此匹配相同關鍵詞的數量Count,並獲得新檢測器中垃圾簡訊關鍵詞的數量N,再根據Count與N的比值,獲得新檢測器針對該正常簡訊的垃圾匹配率,進而分別獲得各個新檢測器針對該正常簡訊的垃圾匹配率,然後進入步驟006;
步驟006.分別針對各個新檢測器,判斷新檢測器針對該正常簡訊的垃圾匹配率是否大於或等於預設垃圾匹配率閾值,是則說明新檢測器把正常簡訊判斷為垃圾簡訊,即新檢測器為不合格檢測器,刪除該不合格的新檢測器,否則不做進一步操作,然後進入步驟007;
步驟007.判斷是否存在新檢測器,是則進入步驟008;否則進入步驟009;
步驟008.判斷正常簡訊庫中是否存在未參與針對該各個新檢測器自檢的正常簡訊,是則返回步驟005;否則判斷新檢測器為合格檢測器,將合格檢測器加入到檢測器庫中,並進入步驟009;
步驟009.判斷待識別簡訊子任務中是否存在未處理的待識別簡訊,是則返回步驟001;否則針對該待識別簡訊子任務垃圾簡訊識別方法結束。
作為本發明的一種優選技術方案:所述步驟000具體包括:根據預設垃圾關鍵詞庫,初始化檢測器庫中的各個檢測器,其中,使用AVL樹的數據結構將檢測器裝入內存,並利用HashMap存儲每個基因所在檢測器Index的集合,其中key為Gene,value為所有含有該Gene的檢測器Index的鍊表集合,然後進入步驟001。
作為本發明的一種優選技術方案:還包括針對所述檢測器庫中原有各個檢測器,以及新加入的各個檢測器,均定義生命周期時長屬性,並初始化生命周期時長檢測值;所述各個節點分別按所述步驟001至步驟009,針對所接收到待識別簡訊子任務執行垃圾簡訊識別的同時,進行計時,並分別針對檢測器庫中的各個檢測器,判斷在生命周期時長檢測值結束時,檢測器是否檢測出垃圾簡訊,是則將該檢測器的生命周期時長設置為永久,否則將該檢測器刪除。
作為本發明的一種優選技術方案:所述各個節點分別按所述步驟001至步驟009,針對所接收到待識別簡訊子任務執行垃圾簡訊識別的同時,還包括按預設第一時長周期間隔,分別針對生命周期時長為永久的各個檢測器,針對檢測器中未與簡訊關鍵詞成功匹配過的關鍵詞,由預設垃圾關鍵詞庫中隨機選擇垃圾關鍵詞進行替換。
作為本發明的一種優選技術方案:所述各個節點分別按所述步驟001至步驟009,針對所接收到待識別簡訊子任務執行垃圾簡訊識別的同時,還包括按預設第二時長周期間隔,針對所述檢測器庫中的檢測器進行如下步驟操作:
步驟a01.分別獲得檢測器庫中各個檢測器的垃圾簡訊成功匹配率,按垃圾簡訊成功匹配率由高至低順序,選擇預設檢測器總數百分比數量的檢測器,作為各個高成功匹配率檢測器,並獲得高成功匹配率檢測器的個數M,然後進入步驟a02;
步驟a02.分別針對各個高成功匹配率檢測器,獲得高成功匹配率檢測器的垃圾簡訊成功匹配率與M的乘積,作為該高成功匹配率檢測器的複製數量,由此分別獲得各個高成功匹配率檢測器的複製數量,並獲得所有高成功匹配率檢測器的複製總數K,然後進入步驟a03;
步驟a03.分別按各個高成功匹配率檢測器的複製數量,針對各個高成功匹配率檢測器分別進行複製,並提取所有複製檢測器中的關鍵詞,構成複製關鍵詞集合,然後進入步驟a04;
步驟a04.將複製關鍵詞集合中的所有關鍵詞隨機分配為K組,構成K個重組檢測器,並進入步驟a05;
步驟a05.判斷正常簡訊庫中正常簡訊的條數是否大於或等於預設正常簡訊庫比對條數閾值,是則進入步驟a06;否則將該K個重組檢測器加入到檢測器庫中;
步驟a06.按所述步驟005至步驟008的方法,分別針對該K個重組檢測器進行自檢,刪除不合格重組檢測器,並將合格重組檢測器加入到檢測器庫中。
作為本發明的一種優選技術方案:所述步驟a06中,分別針對該K個重組檢測器,分別執行如下步驟進行重組檢測器自檢;
步驟b01.由正常簡訊庫中隨機提取一條未參與針對該重組檢測器自檢的正常簡訊,按所述步驟005的方法,獲得該重組檢測器針對該正常簡訊的垃圾匹配率,並判斷該垃圾匹配率是否大於或等於預設垃圾匹配率閾值,是則判斷該重組檢測器為不合格檢測器,刪除該不合格檢測器;否則進入步驟b02;
步驟b02.判斷是否還存在重組檢測器,以及正常簡訊庫中是否存在未參與針對該重組檢測器自檢的正常簡訊,是則返回步驟b01;否則判斷該重組檢測器為合格檢測器,將該合格檢測器加入到檢測器庫中。
本發明所述一種分布式垃圾簡訊識別方法採用以上技術方案與現有技術相比,具有以下技術效果:本發明設計的分布式垃圾簡訊識別方法,提出具有智能計算、學習、並行式、記憶性、動態性等特點垃圾簡訊識別方法,極大提高了垃圾簡訊的識別準確率;其中,引入分布式節點,實現對海量垃圾簡訊進行分布式計算和快速識別;通過反饋環節,實現智能識別,並且具有廣泛的推廣性,諸如推廣到垃圾郵件識別攔截,同時也可以推廣到人人網、QQ空間、朋友圈、微博等,對廣告或其他垃圾信息進行識別並屏蔽,具有廣泛的應用範疇。
附圖說明
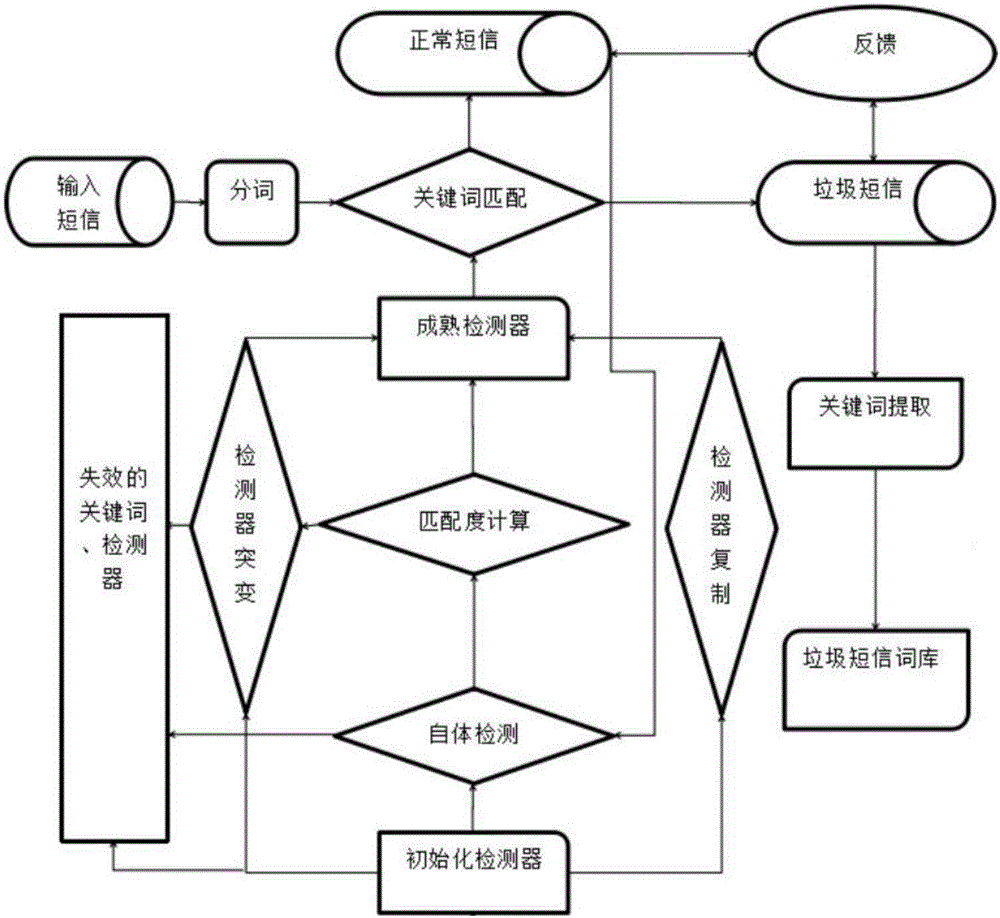
圖1是本發明所設計分布式垃圾簡訊識別方法的流程圖;
圖2是檢測器在AVL樹分布示意圖;
圖3是關鍵詞Gene與Index之間的查找示意圖;
具體實施方式
下面結合說明書附圖對本發明的具體實施方式作進一步詳細的說明。
本發明為了解決上述問題採用以下技術方案:基於文本識別和垃圾簡訊的特徵,本發明首先提出具有智能計算、深度學習、分布式識別等特點的垃圾簡訊識別方法,利用該方法可以實現較高的垃圾簡訊識別準確率;同時部署分布式平臺,把海量的待測簡訊數據的識別處理任務利用分塊方法拆分成多個垃圾簡訊識別子任務,並把這些子任務發送到分布式模式的若干個節點上去計算識別,每個計算識別的節點均採用本發明提出的垃圾簡訊方法,然後對每一個子任務的識別結果進行匯總,實現分布式處理識別垃圾簡訊;同時本發明做出了一個基於智能計算、深度學習的垃圾簡訊識別方法和分布式模型之上的多功能可視化系統,對垃圾簡訊識別的輸入數據及輸出結果進行顯示,並可以對簡訊進行反饋等智能化相關性操作。
如圖1所示,本發明設計了一種分布式垃圾簡訊識別方法,實際應用過程當中,將待識別簡訊數據集合拆分成各個待識別簡訊子任務,各個待識別簡訊子任務分別包括至少一條待識別簡訊,各個待識別簡訊子任務分別發送至分布式系統中的各個節點進行處理,各個節點分別具體按如下步驟,根據預設檢測器庫中各個檢測器內的各個垃圾簡訊關鍵詞,針對所接收到的待識別簡訊子任務進行垃圾簡訊識別;
步驟000.根據預設垃圾關鍵詞庫,初始化檢測器庫中的各個檢測器,然後進入步驟001;具體具體包括:根據預設垃圾關鍵詞庫,初始化檢測器庫中的各個檢測器,其中,使用AVL樹的數據結構將檢測器裝入內存,AVL示意圖如圖2所示,並利用HashMap存儲每個基因所在檢測器Index的集合,其中key為Gene,value為所有含有該Gene的檢測器Index的鍊表集合,關鍵詞Gene與Index之間的查找示意圖,如圖3所示,然後進入步驟001。
步驟001.由待識別簡訊子任務隊列中提取一條未處理的待識別簡訊,作為當前識別簡訊,利用開源IK-Analyzer-2012FF分詞器針對當前識別簡訊進行分詞,獲取當前識別簡訊中的各個關鍵詞Gene1,Gene2,Gene3…Genei,進入步驟002。步驟002.將當前識別簡訊中的各個關鍵詞Gene1,Gene2,Gene3…Genei通過HashMap,獲得所有包含有這些關鍵詞的檢測器Index的索引值的集合,進入步驟003。
步驟003.將得到的索引值集合通過m個HashSet,判斷是否存在親和力大於或等於預設匹配率閾值brake的檢測器Index,是則判定當前識別簡訊為垃圾簡訊,將其加入垃圾簡訊庫,並由AVL樹中提取出利用該檢測器Index,進入步驟004;否則說明檢測器庫中不存在能與當前識別簡訊匹配率達到預設匹配率閾值brake的檢測器,則判定當前識別簡訊為正常簡訊,將其加入至正常簡訊庫,進入步驟009;其中,m=Testlength*brake。
步驟004.由被判斷為垃圾簡訊的當前識別簡訊中的各個關鍵詞,構建若干新檢測器,接著判斷正常簡訊庫中正常簡訊的條數是否大於或等於預設正常簡訊庫比對條數閾值,是則進入步驟005;否則將各個新檢測器加入到檢測器庫中,並進入步驟009。
步驟005.由正常簡訊庫隊列中提取一條未參與針對各個新檢測器自檢的正常簡訊,分別針對各個新檢測器,將該正常簡訊中各個關鍵詞與新檢測器中各個垃圾簡訊關鍵詞進行匹配,獲得彼此匹配相同關鍵詞的數量Count,並獲得新檢測器中垃圾簡訊關鍵詞的數量N,再根據Count與N的比值,獲得新檢測器針對該正常簡訊的垃圾匹配率,進而分別獲得各個新檢測器針對該正常簡訊的垃圾匹配率,然後進入步驟006。
步驟006.分別針對各個新檢測器,判斷新檢測器針對該正常簡訊的垃圾匹配率是否大於或等於預設垃圾匹配率閾值,是則說明新檢測器把正常簡訊判斷為垃圾簡訊,即新檢測器為不合格檢測器,刪除該不合格的新檢測器,否則不做進一步操作,然後進入步驟007。
步驟007.判斷是否存在新檢測器,是則進入步驟008;否則進入步驟009。
步驟008.判斷正常簡訊庫中是否存在未參與針對該各個新檢測器自檢的正常簡訊,是則返回步驟005;否則判斷新檢測器為合格檢測器,將合格檢測器加入到檢測器庫中,並進入步驟009。
步驟009.判斷待識別簡訊子任務中是否存在未處理的待識別簡訊,是則返回步驟001;否則針對該待識別簡訊子任務垃圾簡訊識別方法結束。
上述實際應用的同時,還包括針對所述檢測器庫中原有各個檢測器,以及新加入的各個檢測器,均定義生命周期時長屬性,並初始化生命周期時長檢測值;所述各個節點分別按所述步驟001至步驟009,針對所接收到待識別簡訊子任務執行垃圾簡訊識別的同時,進行計時,並分別針對檢測器庫中的各個檢測器,判斷在生命周期時長檢測值結束時,檢測器是否檢測出垃圾簡訊,是則將該檢測器的生命周期時長設置為永久,否則將該檢測器刪除。並且各個節點分別按所述步驟001至步驟009,針對所接收到待識別簡訊子任務執行垃圾簡訊識別的同時,還包括按預設第一時長周期間隔,分別針對生命周期時長為永久的各個檢測器,針對檢測器中未與簡訊關鍵詞成功匹配過的關鍵詞,由預設垃圾關鍵詞庫中隨機選擇垃圾關鍵詞進行替換。與此同時,各個節點分別按所述步驟001至步驟009,針對所接收到待識別簡訊子任務執行垃圾簡訊識別的同時,還包括按預設第二時長周期間隔,針對所述檢測器庫中的檢測器進行如下步驟操作:
步驟a01.分別獲得檢測器庫中各個檢測器的垃圾簡訊成功匹配率,按垃圾簡訊成功匹配率由高至低順序,選擇預設檢測器總數百分比數量的檢測器,作為各個高成功匹配率檢測器,並獲得高成功匹配率檢測器的個數M,然後進入步驟a02。
步驟a02.分別針對各個高成功匹配率檢測器,獲得高成功匹配率檢測器的垃圾簡訊成功匹配率與M的乘積,作為該高成功匹配率檢測器的複製數量,由此分別獲得各個高成功匹配率檢測器的複製數量,並獲得所有高成功匹配率檢測器的複製總數K,然後進入步驟a03。
步驟a03.分別按各個高成功匹配率檢測器的複製數量,針對各個高成功匹配率檢測器分別進行複製,並提取所有複製檢測器中的關鍵詞,構成複製關鍵詞集合,然後進入步驟a04。
步驟a04.將複製關鍵詞集合中的所有關鍵詞隨機分配為K組,構成K個重組檢測器,並進入步驟a05。
步驟a05.判斷正常簡訊庫中正常簡訊的條數是否大於或等於預設正常簡訊庫比對條數閾值,是則進入步驟a06;否則將該K個重組檢測器加入到檢測器庫中。
步驟a06.按所述步驟005至步驟008的方法,分別針對該K個重組檢測器進行自檢,刪除不合格重組檢測器,並將合格重組檢測器加入到檢測器庫中。
上述步驟a06中,分別針對該K個重組檢測器,分別執行如下步驟進行重組檢測器自檢;
步驟b01.由正常簡訊庫中隨機提取一條未參與針對該重組檢測器自檢的正常簡訊,按所述步驟005的方法,獲得該重組檢測器針對該正常簡訊的垃圾匹配率,並判斷該垃圾匹配率是否大於或等於預設垃圾匹配率閾值,是則判斷該重組檢測器為不合格檢測器,刪除該不合格檢測器;否則進入步驟b02。
步驟b02.判斷是否還存在重組檢測器,以及正常簡訊庫中是否存在未參與針對該重組檢測器自檢的正常簡訊,是則返回步驟b01;否則判斷該重組檢測器為合格檢測器,將該合格檢測器加入到檢測器庫中。
上述設計分布式垃圾簡訊識別方法在實際應用中,在垃圾簡訊識別算法層和分布式服務層之上,還引入可視化軟體層,我們用JavaSwing實現系統的可視化界面,其中包括如下一些功能:
(1)可視化顯示信息:顯示識別出的垃圾短息的文本內容和正常簡訊的文本內容和識別正常簡訊和垃圾簡訊統計的數目,以及顯示檢測器及其每個關鍵詞的匹配情況;
(2)基本功能按鍵:開始檢測、停止檢測、統計檢測簡訊相關數目;
(3)智能功能按鍵:加入正常簡訊、加入垃圾簡訊。基於算法層的反饋環節和垃圾簡訊的兩層定義,本發明把正常的簡訊添加到垃圾簡訊庫,也可以把垃圾簡訊添加到正常簡訊中,實現智能化、人性化垃圾簡訊的識別。
上述技術方案所設計分布式垃圾簡訊識別方法,實際應用中,提出具有智能計算、學習、並行式、記憶性、動態性等特點垃圾簡訊識別方法,極大提高了垃圾簡訊的識別準確率;其中,引入分布式節點,實現對海量垃圾簡訊進行分布式計算和快速識別;通過反饋環節,實現智能識別,並且具有廣泛的推廣性,諸如推廣到垃圾郵件識別攔截,同時也可以推廣到人人網、QQ空間、朋友圈、微博等,對廣告或其他垃圾信息進行識別並屏蔽,具有廣泛的應用範疇。
上面結合附圖對本發明的實施方式作了詳細說明,但是本發明並不限於上述實施方式,在本領域普通技術人員所具備的知識範圍內,還可以在不脫離本發明宗旨的前提下做出各種變化。