一種基於RTT監測的鏈路健康檢測系統及方法與流程
2023-11-07 02:36:02 5
本發明涉及網絡監測領域,特別涉及一種基於rtt監測的鏈路健康檢測系統及方法。
背景技術:
許多企業都意識到單條網際網路出口鏈路帶來的問題:鏈路一旦中斷,內部員工將無法訪問網際網路,分支機構vpn中斷,網站郵箱均無法對外服務。因此許多企業會部署多條運營商鏈路來解決單出口的不可靠。但是多鏈路引入後需要根據各鏈路的健康狀況來進行負載均衡策略部署。這就需要一種實時鏈路健康檢測方法與系統。
網絡延時作為直觀反映網絡性能好壞的技術指標,受到ietf標準化組織和幾乎所有的網絡性能研究機構的重視,紛紛以其作為對網絡性能進行全面分析、深入研究的首要指標。網絡延時小,說明網絡連接性能好,網絡路徑上的所有組件處於正常運行狀態。網絡延時大,且持續相當一段時間,則暗示該網絡路徑所經過的某些組件發生了異常行為,導致該連接性能變差,承載的高層業務性能也可能受到影響。因此,通過對網絡延時進行全天候、實時的測量和分析,可以及時了解網絡的運行情況。
但是目前的多數方法都沒有考慮到一個問題,那就是往返時間(round-triptime,rtt)分布具有一定周期性,依賴於每天時間的不同和用戶網絡行為的不同,正常的rtt曲線應該是有一定波動的,而不是一條直線。
技術實現要素:
本發明的目的在於克服已有的鏈路健康監測系統及方法沒有考慮往返時間分布具有周期性的缺陷,從而提供一種基準值更準確的鏈路健康監測系統及方法。
為了實現上述目的,本發明提供了一種基於rtt監測的鏈路健康檢測系統,包括:實時監測模塊101、計時模塊102、基準文件模塊103、異常統計模塊104以及自適應採樣模塊105;其中,
所述實時監測模塊101負責對鏈路上數據包往返時間進行實時檢測並與基準文件模塊103所提供的基準值進行對比;所述基準文件模塊103提供基準值,還負責對各時段歷史基準值進行加權更新;所述計時模塊102負責確定當前所處時段;所 述異常統計模塊104負責統計異常次數;所述自適應採樣模塊105根據異常統計模塊104所提供的異常計數值調整發送監測數據包的間隔。
本發明還提供了基於所述的基於rtt監測的鏈路健康檢測系統所實現的鏈路健康檢測方法,包括:
步驟1)、系統初始化,並輸入待監測鏈路;其中,所述系統初始化包括對系統參數的初始化以及基準文件模塊103的初始化;其中,所述系統參數至少包括異常判定閾值、異常統計閾值、發送探測數據包間隔以及異常計數值;
步驟2)、由計時模塊102獲得當前時段,基準文件模塊103準備好當前時段的歷史基準值;
步驟3)、判斷是否進入了一個新的時段,如果進入了一個新的時段,執行下一步,否則,執行步驟5);
步驟4)、對前一時段中記錄的rtt值求均值n,然後加權更新前一時段的rtt基準值,然後重新執行步驟2);
步驟5)、依然處於當前時段,實時監測模塊101開始以發送探測數據包間隔大小為t發送監測數據包並記錄獲得的rtt值;
步驟6)、實時監測模塊101每獲得一次rtt值,都要與基準文件中當前時段的歷史基準值進行對比,判斷兩者之差有沒有超過異常判定閾值,如果超過,則執行步驟11),如果沒有超過,執行下一步;
步驟7)、判斷異常計數值是否大於1,如果大於1,執行下一步,否則,重新執行步驟2);
步驟8)、記錄rtt值,並將異常計數值減1;
步驟9)、判斷異常計數值是否大於0,如果是,重新執行步驟2),如果不是,執行下一步;
步驟10)、將發送探測數據包的間隔大小變為t,然後重新執行步驟2);
步驟11)、將異常統計值加1,並丟棄當前獲得的rtt值;
步驟12)、判斷異常計數值是否達到了異常統計閾值,如果是,執行下一步,否則,執行步驟14);
步驟13)、發出鏈路異常報警,檢測結束;
步驟14)、判斷異常計數值是否大於異常統計閾值b的一半,如果是,執行下一步,否則,重新執行步驟2);
步驟15)、將發送探測數據包的間隔大小由t變為t/2,然後重新執行步驟2)。
上述技術方案中,初始化異常判定閾值時為其賦值100ms,初始化異常統計閾值時為其賦值5,初始化發送探測數據包間隔時為其賦值10s,初始化異常計數值時為其賦值0。
上述技術方案中,在步驟4)中,加權更新前一時段的rtt基準值的更新公式為:
new=c1×h+c2×n;
其中,h為前一時段rtt的歷史基準值,n為前一時段實時監測rtt值的均值,new為更新後前一時段rtt基準值,c1為與歷史基準值有關的加權更新時的權值,c2為與實時基準值有關的加權更新的權值,c1+c2=1,且c2的值大於c1的值。
上述技術方案中,c1=0.3,c2=0.7。
本發明的優點在於:
1、本發明將rtt的波動性納入考慮,為鏈路檢測提供了更加準確的基準值。
2、本發明在更新基準值時採取加權更新的方法,可以利用賦予歷史值一定的權值來平滑掉一些可能由於某一特殊事件引起的rtt變化過大,同時也能利用為新測得的值賦予較大的權值來保留rtt的總體變化趨勢。
3、本發明中的異常統計模塊可以有效的消除一些由於鏈路延時抖動所造成的誤報警。
4、本發明中的自適應採樣模塊能夠有效的降低功耗。
5、本發明的方法在實時監測時只引入減法運算,在更新基準時,也只需要簡單的加法和乘法運算,整體的運算複雜度比較低,不會為整個系統增加過多的負擔,有利於工程實現。
附圖說明
圖1是本發明的鏈路健康檢測系統的結構示意圖;
圖2是本發明的鏈路健康檢測方法的流程圖。
具體實施方式
現結合附圖對本發明作進一步的描述。
如圖1所示,本發明的鏈路健康檢測系統包括:實時監測模塊101、計時模塊102、基準文件模塊103、異常統計模塊104以及自適應採樣模塊105;其中,
所述的實時監測模塊101負責對鏈路上數據包往返時間進行實時檢測並與基準文件模塊103所提供的基準值進行對比;所述基準文件模塊103除了提供基準值外,還負責對各時段歷史基準值進行加權更新;所述計時模塊102負責確定當前所處時段;所述異常統計模塊104負責統計異常次數;所述自適應採樣模塊105根據異常統計模塊104所提供的異常計數值調整發送監測數據包的間隔。
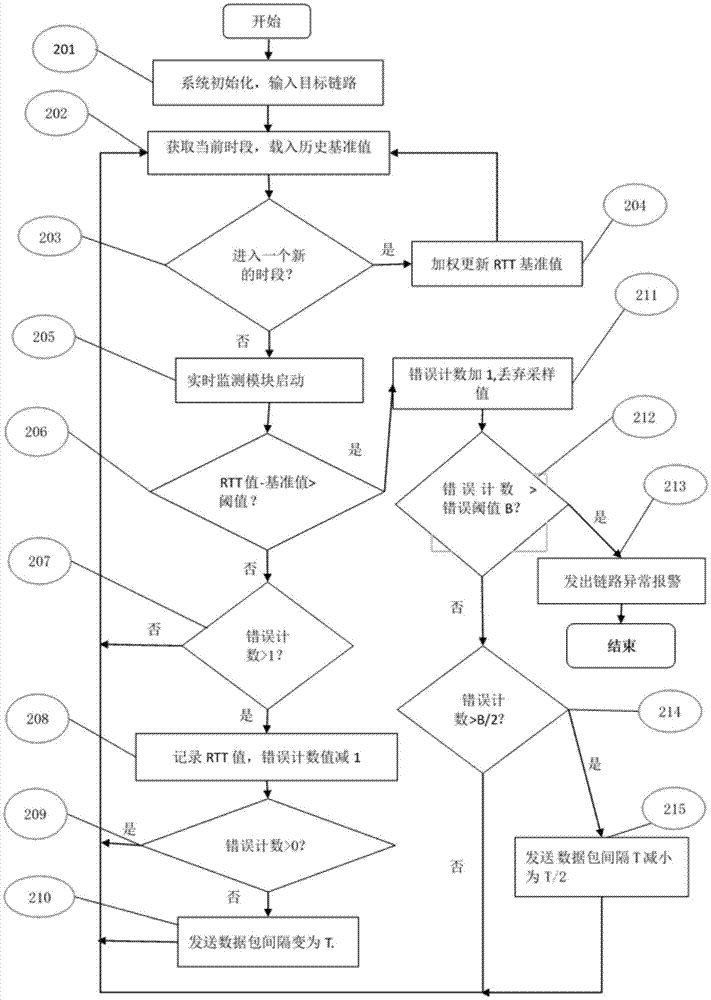
參考圖2,基於本發明的鏈路健康檢測系統所實現的檢測方法包括:
步驟201、系統初始化,並輸入待監測鏈路;其中,系統初始化包括:初始化異常判定閾值a、異常統計閾值b、發送探測數據包間隔t在內的參數,如在一個實施例中,初始化時為這些參數分別賦值為a=100ms、b=5、t=10s,在其他實施例中,也可根據實際需要為這些參數賦予其他的值;初始化異常計數值為0;初始化基準文件模塊103,讀入歷史基準文件。
步驟202、由計時模塊102獲得當前時段,基準文件模塊103準備好當前時段的歷史基準值。
步驟203、判斷是否進入了一個新的時段,如果進入了一個新的時段,執行下一步,否則,執行步驟205。
步驟204、對前一時段中記錄的rtt值求均值n,然後加權更新前一時段的rtt基準值,更新公式為:new=c1×h+c2×n,其中,h為前一時段rtt的歷史基準值,n為前一時段實時監測rtt值的均值,new為更新後前一時段rtt基準值,c1為與歷史基準值有關的加權更新時的權值,c2為與實時基準值有關的加權更新的權值,c1+c2=1,為了更好地反映變化趨勢,通常為c2賦予較大的值,為c1賦予較小的值,如c1=0.3,c2=0.7;然後回到步驟202繼續執行。
步驟205、依然處於當前時段,實時監測模塊101開始以間隔t發送監測數據包並記錄獲得的rtt值。
步驟206、實時監測模塊101每獲得一次rtt值,都要與基準文件中當前時段的歷史基準值進行對比,判斷兩者之差有沒有超過異常判定閾值a,如果超過,則 執行步驟211,如果沒有超過,執行下一步。
步驟207、判斷異常計數值是否大於1,如果大於1,執行下一步,否則,重新執行步驟202。
步驟208、記錄rtt值,並將異常計數值減1。
步驟209、判斷異常計數值是否大於0,如果是,重新執行步驟202,如果不是,執行下一步。
步驟210、將發送探測數據包的間隔大小變為t,然後重新執行步驟202。
步驟211、將異常統計值加1,並丟棄當前獲得的rtt值。
步驟212、判斷異常計數值是否達到了異常統計閾值b,如果是,執行下一步,否則,執行步驟214。
步驟213、發出鏈路異常報警,檢測結束。
步驟214、判斷異常計數值是否大於異常統計閾值b的一半,如果是,執行下一步,否則,重新執行步驟202。
步驟215、將發送探測數據包的間隔大小由t變為t/2,然後重新執行步驟202。
最後所應說明的是,以上實施例僅用以說明本發明的技術方案而非限制。儘管參照實施例對本發明進行了詳細說明,本領域的普通技術人員應當理解,對本發明的技術方案進行修改或者等同替換,都不脫離本發明技術方案的精神和範圍,其均應涵蓋在本發明的權利要求範圍當中。